
New configuration of - Kyoto U
27
強化学習を導入した平面骨組 構造物の最適設計 林 和希(京都大学) 大崎 純(京都大学)
Transcript of New configuration of - Kyoto U

強化学習を導入した平面骨組構造物の最適設計
林和希(京都大学)大崎純(京都大学)
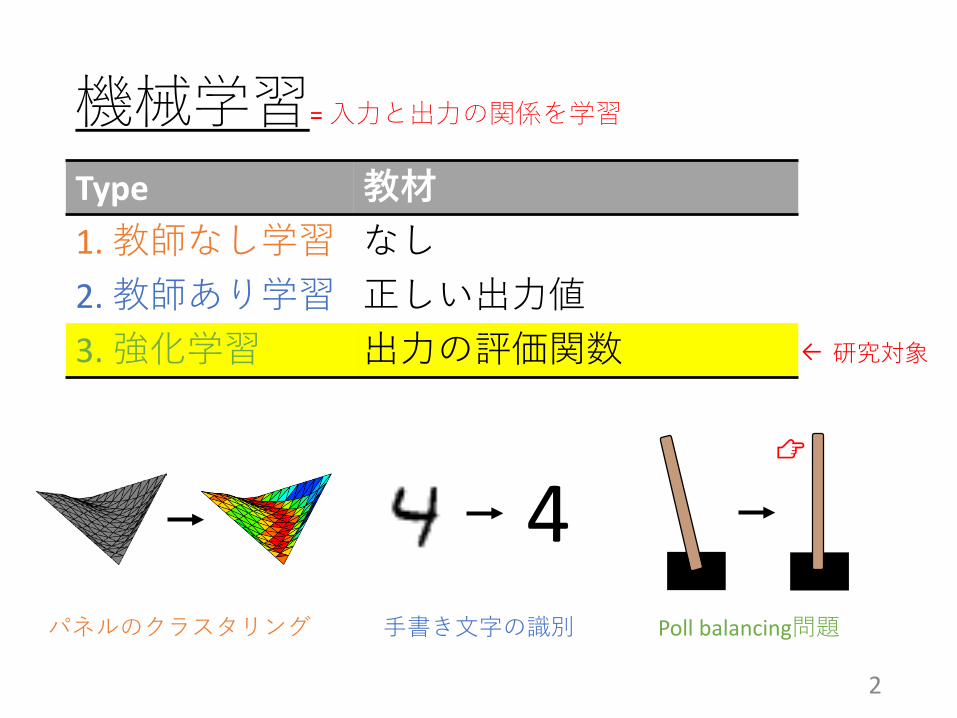
機械学習= 入力と出力の関係を学習
パネルのクラスタリング Poll balancing問題手書き文字の識別
4
2
Type 教材1. 教師なし学習 なし2. 教師あり学習 正しい出力値3. 強化学習 出力の評価関数 研究対象←
👉👉
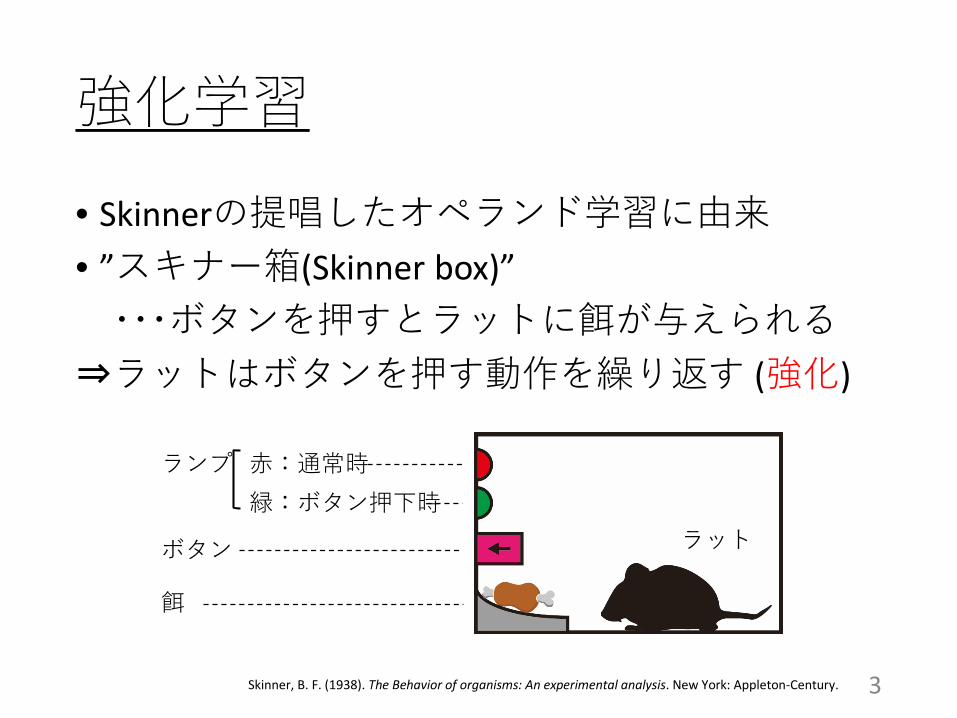
強化学習• Skinnerの提唱したオペランド学習に由来• ”スキナー箱(Skinner box)”・・・ボタンを押すとラットに餌が与えられる
⇒ラットはボタンを押す動作を繰り返す (強化)
3Skinner, B. F. (1938). The Behavior of organisms: An experimental analysis. New York: Appleton-Century.
ボタン
餌
赤:通常時緑:ボタン押下時
ランプ
ラット

なぜ構造最適化×強化学習?1. 非線形かつ困難な問題への適用2. 予期せぬ優良解の生成3. 計算負荷の低減
4

例題1:骨組の断面最適化
5

骨組断面の最適化1. 部材総体積の最小化2. 応力制約3. 崩壊メカニズムの制約
minimize ( )subject to ( ) ( all members)
( ) 1.5 ( middle layer nodes)i i
j
Vi
jσ σβ
≤ =
≥ ∈
AAA
1. total structural volume
2. stress constraint
3. column-to-beamstrength ratio
6
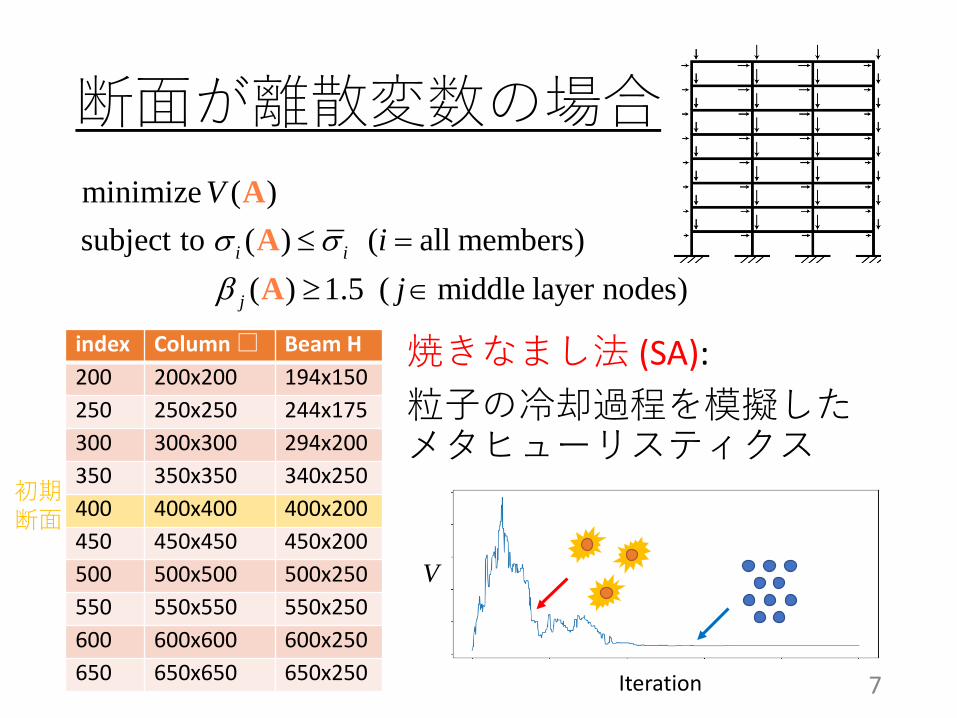
断面が離散変数の場合
焼きなまし法 (SA):粒子の冷却過程を模擬したメタヒューリスティクス
7
minimize ( )subject to ( ) ( all members)
( ) 1.5 ( middle layer nodes)i i
j
Vi
jσ σβ
≤ =
≥ ∈
AAA
V
Iteration
index Column □ Beam H200 200x200 194x150250 250x250 244x175300 300x300 294x200350 350x350 340x250400 400x400 400x200450 450x450 450x200500 500x500 500x250550 550x550 550x250600 600x600 600x250650 650x650 650x250
初期断面
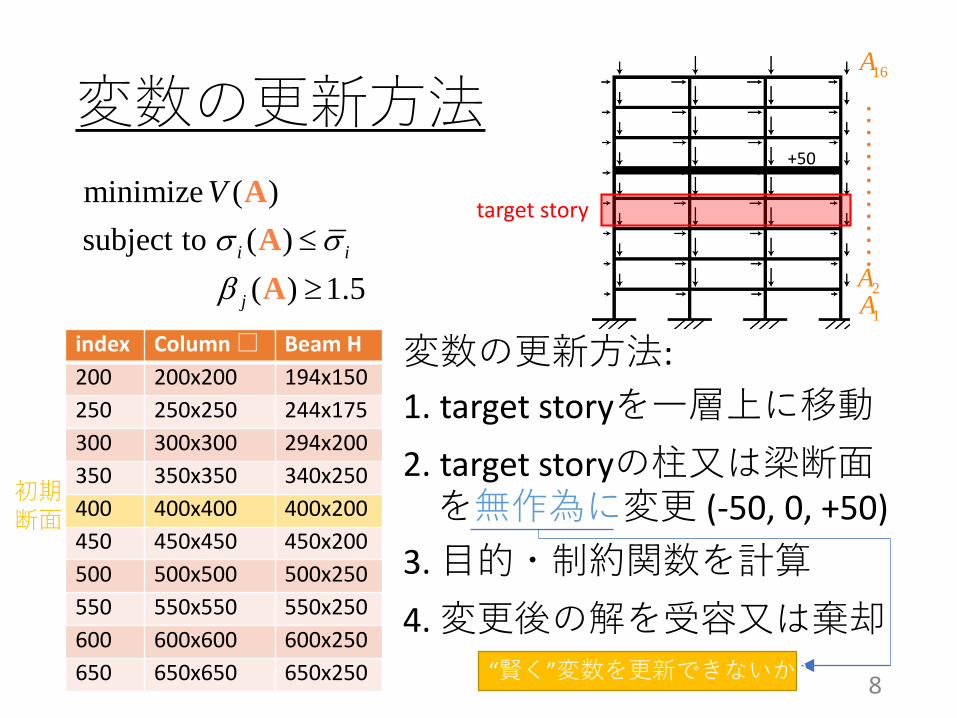
変数の更新方法
変数の更新方法:1. target storyを一層上に移動2. target storyの柱又は梁断面を無作為に変更 (-50, 0, +50)
3. 目的・制約関数を計算4. 変更後の解を受容又は棄却
minimize ( )subject to ( )
( ) 1.5i i
j
Vσ σβ
≤
≥
AAA
index Column □ Beam H200 200x200 194x150250 250x250 244x175300 300x300 294x200350 350x350 340x250400 400x400 400x200450 450x450 450x200500 500x500 500x250550 550x550 550x250600 600x600 600x250650 650x650 650x250
1A
16A
“賢く”変数を更新できないか?
2A
・・・・・・・・・・・・・・
target story
+50
初期断面
8
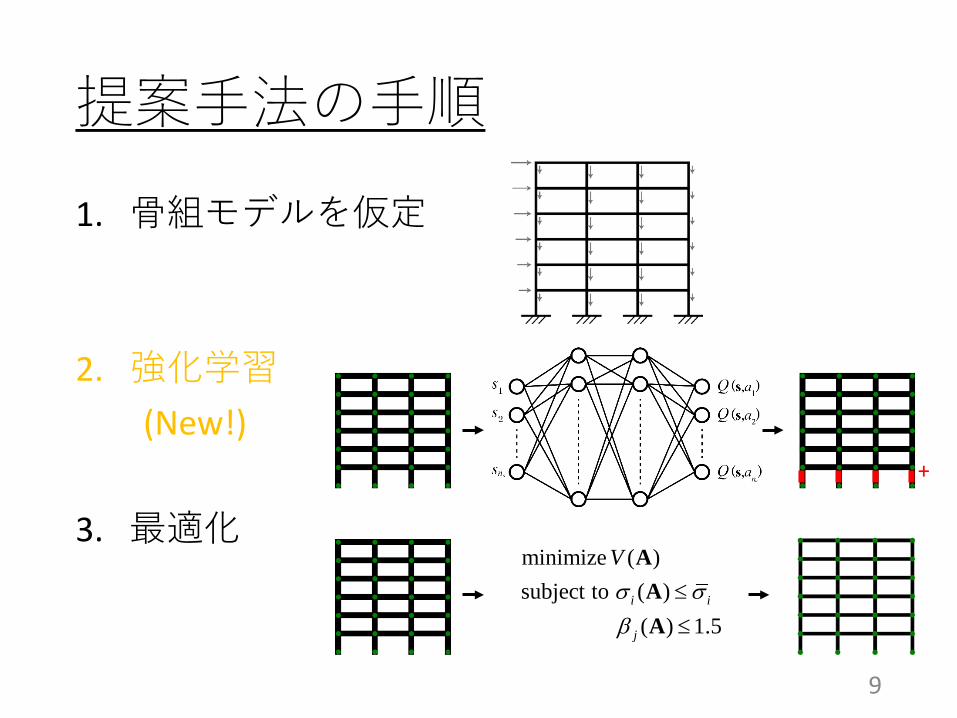
提案手法の手順1. 骨組モデルを仮定
2. 強化学習(New!)
3. 最適化
9
minimize ( )subject to ( )
( ) 1.5i i
j
Vσ σβ
≤
≤
AAA
+
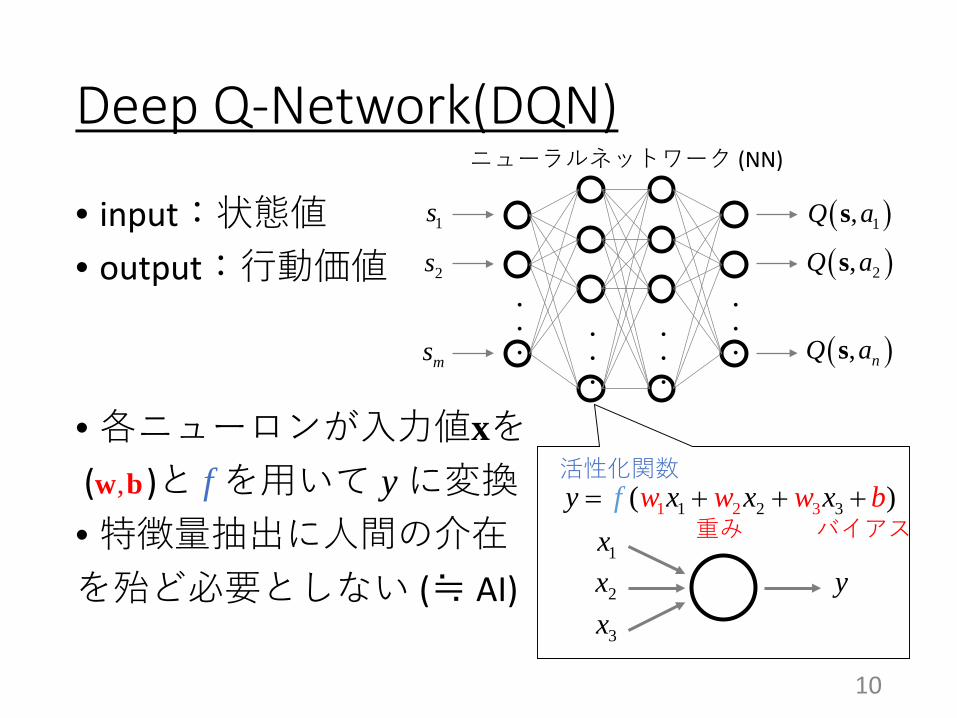
Deep Q-Network(DQN)
• input:状態値• output:行動価値
• 各ニューロンが入力値xを( )と f を用いて y に変換• 特徴量抽出に人間の介在を殆ど必要としない (≒ AI)
10
( )1,Q as
・・・
・・・
・・・
・・・
( )2,Q as
( ), nQ as
1s
2s
ms
,w b 活性化関数1 2 31 2 3( )y x x xf w w w b= + + +
1x
2x
3xy
重み バイアス
ニューラルネットワーク (NN)
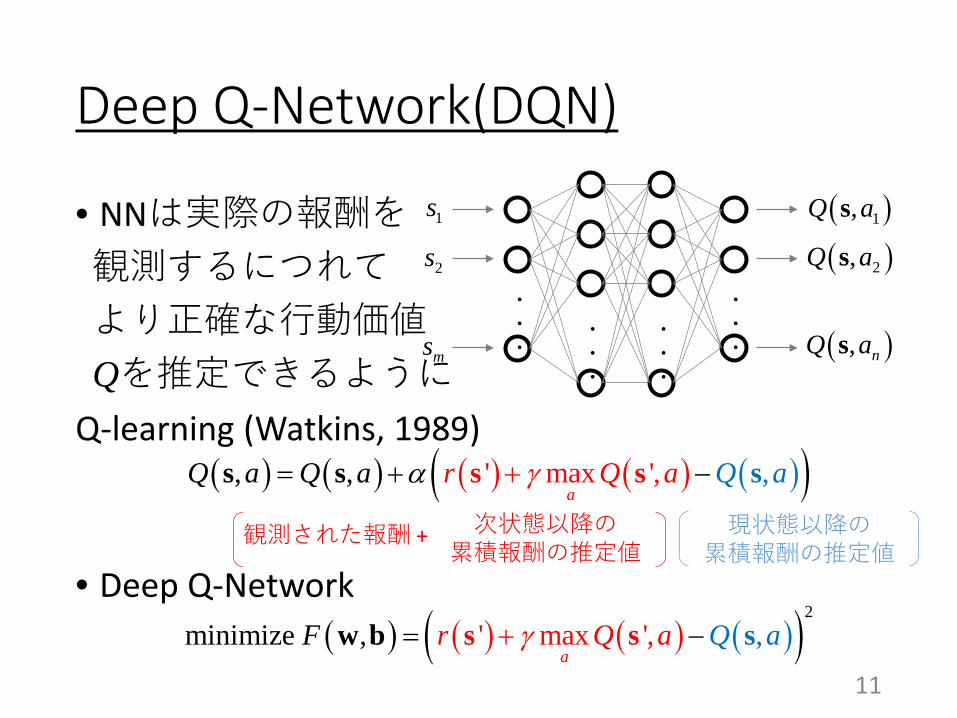
Deep Q-Network(DQN)
• NNは実際の報酬を観測するにつれてより正確な行動価値Qを推定できるように
Q-learning (Watkins, 1989)
• Deep Q-Network
11
( ) ( ) ( ) ( )( )2,minimize , ' max ',
arF Q aQ aγ+= −s s sw b
( ) ( ) ( ) ( ) ( )( )' max ',, , ,a
r Q aa QQ a Q aγα= + −+ss sss
現状態以降の累積報酬の推定値
次状態以降の累積報酬の推定値観測された報酬 +
( )1,Q as
・・・
・・・
・・・
・・・
( )2,Q as
( ), nQ as
1s
2s
ms

強化学習に必要なもの
エージェント
1. 状態s 2. 行動a 3. 報酬r 4. 環境F(s,a) = {s’,r}
12

強化学習に必要なもの
エージェント
1. 状態s 2. 行動a 3. 報酬r 4. 環境F(s,a) = {s’,r}
13
( )1,Q as
・・・ ・
・・
・・・
・・・
( )2,Q as
( ), nQ as
1s
2s
ms
s a r ( , ) { ', }F s a s r=
±Pythoncoding
min. indicessect. indices
∑∑
※ r = 0 if not satisfy constraints
450
350 200 200450 3500.25
r +=
+=

状態: 22 入力
𝑠𝑠𝑎𝑎: target storyとその上下の層の柱梁断面のインデックス𝑠𝑠𝑏𝑏 : 断面が上下限なら1となる{0,1}値𝑠𝑠𝑐𝑐 : 同一層の柱または梁ごとの応力の検定比の最大値𝑠𝑠𝑑𝑑 : 同じ高さにある節点ごとの、柱梁耐力比の最小値𝑠𝑠𝑒𝑒 : 現在のtarget storyが最下階か最上階なら1となる{0,1}値
14
6
4
6
4
2
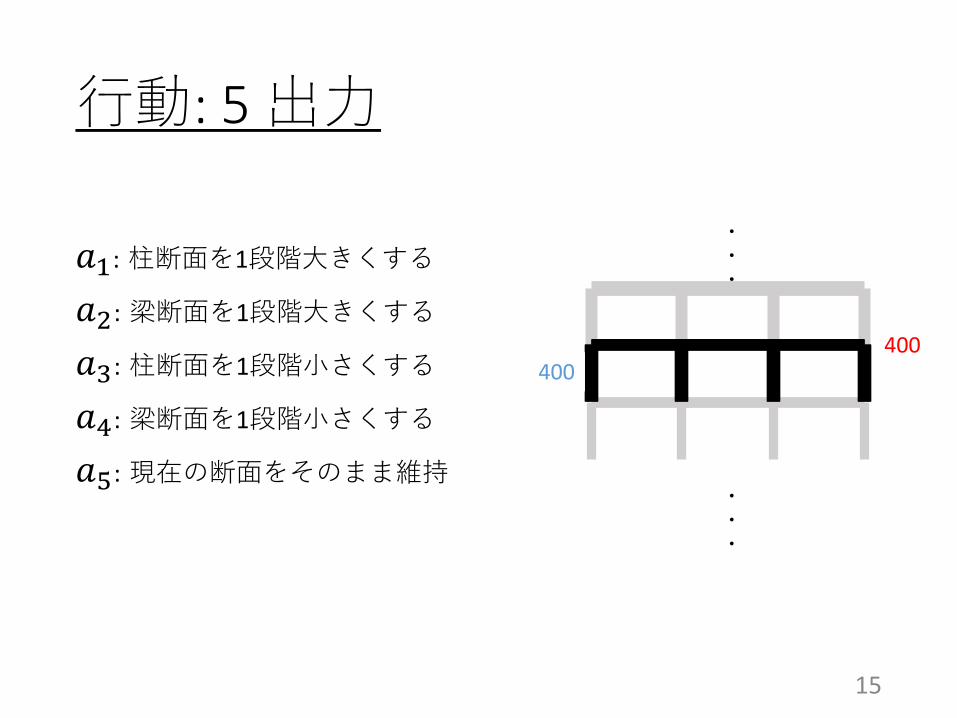
行動: 5 出力
𝑎𝑎1: 柱断面を1段階大きくする
𝑎𝑎2: 梁断面を1段階大きくする
𝑎𝑎3: 柱断面を1段階小さくする
𝑎𝑎4: 梁断面を1段階小さくする
𝑎𝑎5: 現在の断面をそのまま維持
15
450350
・・・
・・・
500400300400

NNの設定• 最適化手法:Adam• 活性化関数:Sigmoid• 方策:ε-greedy方策(ε=0.2の確率でランダム行動)
16
( )1,Q as
・・・ ・
・・
・・・
・・・
( )2,Q as
( )5,Q as
1s
2s
22s状態数22 行動数5
100 100
元の行動価値:1016次元
(22+1)×100+(100+1)×100+(100+1)×5
=12905次元に縮約
x
f (x)
f (x)x1
0
0.5
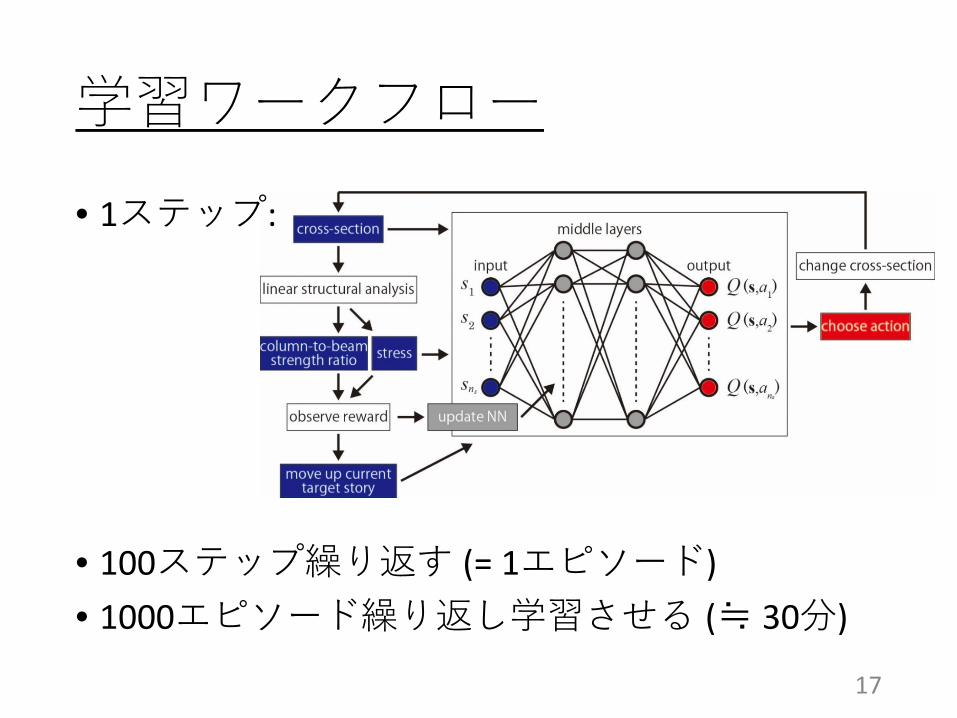
学習ワークフロー
17
• 1ステップ:
• 100ステップ繰り返す (= 1エピソード)• 1000エピソード繰り返し学習させる (≒ 30分)
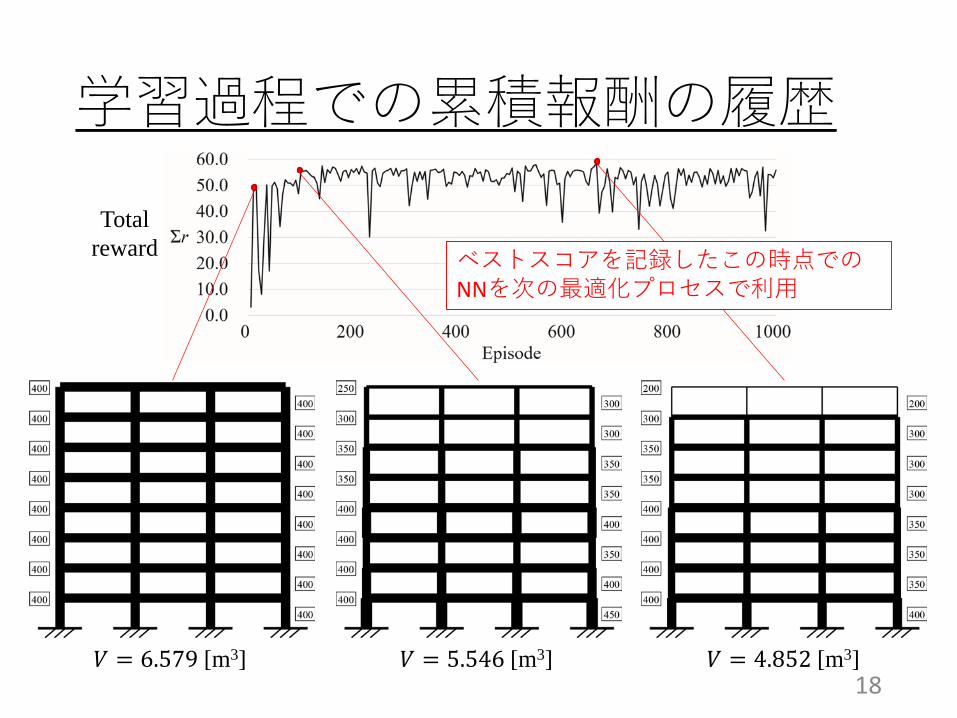
学習過程での累積報酬の履歴
ベストスコアを記録したこの時点でのNNを次の最適化プロセスで利用
Totalreward
𝑉𝑉 = 6.579 [m3] 𝑉𝑉 = 5.546 [m3] 𝑉𝑉 = 4.852 [m3]18

既往のSAアルゴリズム提案するSA+DQNアルゴリズム
19
randomlyRL agent
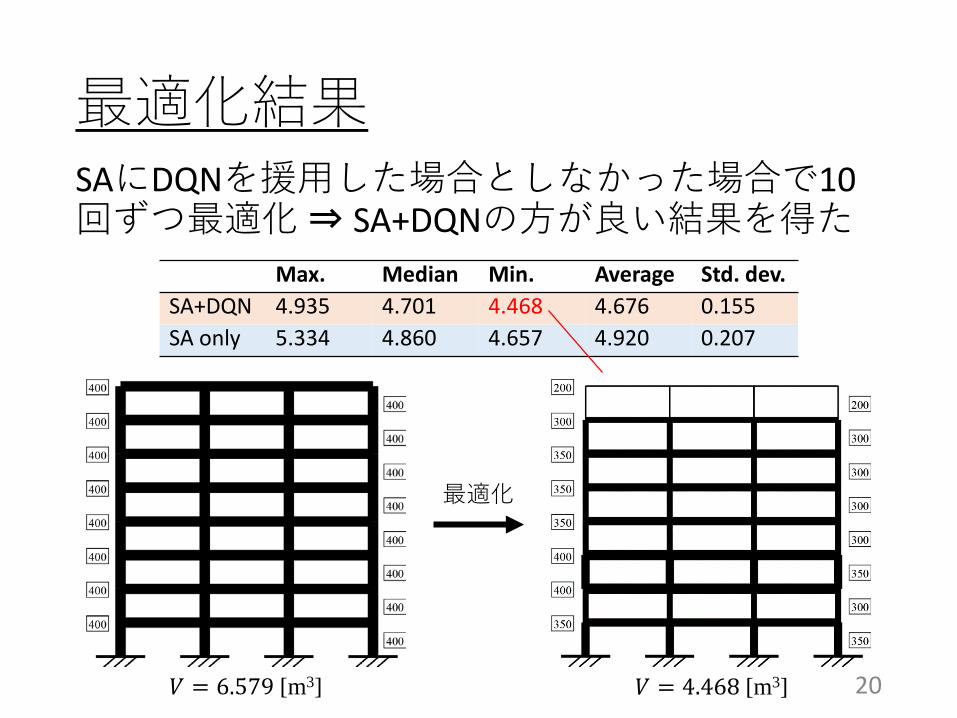
SAにDQNを援用した場合としなかった場合で10回ずつ最適化⇒ SA+DQNの方が良い結果を得た
最適化結果
Max. Median Min. Average Std. dev.SA+DQN 4.935 4.701 4.468 4.676 0.155SA only 5.334 4.860 4.657 4.920 0.207
20
最適化
𝑉𝑉 = 6.579 [m3] 𝑉𝑉 = 4.468 [m3]
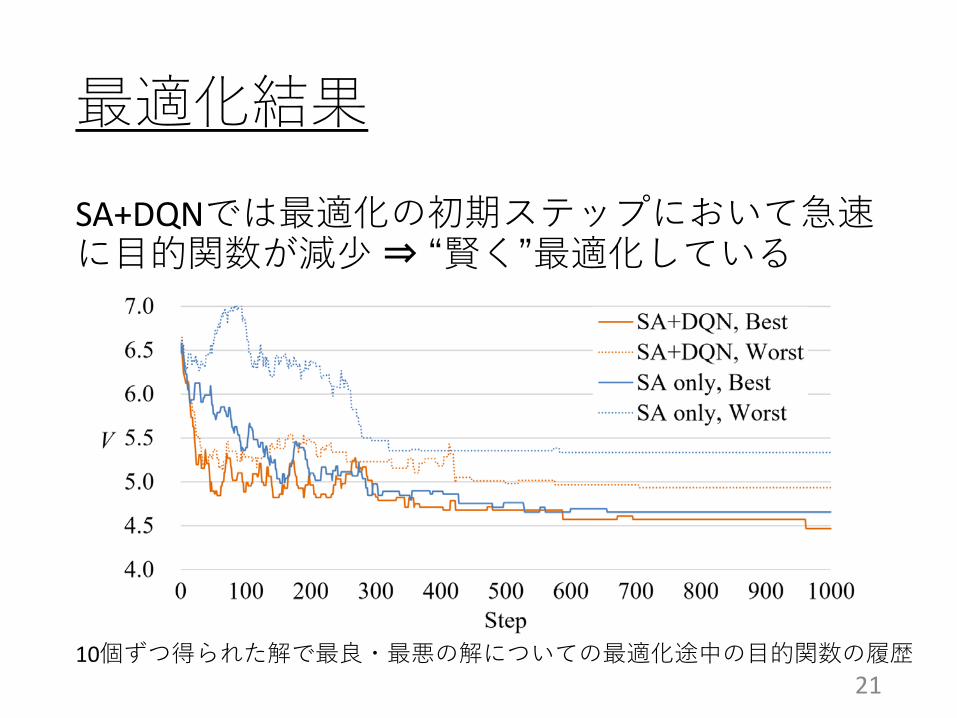
SA+DQNでは最適化の初期ステップにおいて急速に目的関数が減少⇒ “賢く”最適化している
最適化結果
2110個ずつ得られた解で最良・最悪の解についての最適化途中の目的関数の履歴

SAのみと比較して、SA+DQNではSAの温度パラメータに依存せず安定した最適化結果を得た
SAパラメータに対する頑強性
22
SA+DQN SA only
𝑐𝑐 = 0.8 𝑐𝑐 = 0.9 𝑐𝑐 = 0.95 𝑐𝑐 = 0.8 𝑐𝑐 = 0.9 𝑐𝑐 = 0.95𝑝𝑝0 = 0.2 4.725 4.672 4.782 4.861 4.794 4.808
𝑝𝑝0 = 0.8 4.677 4.701 4.697 5.023 4.860 4.804
𝑝𝑝0 = 0.99 4.782 4.762 4.815 5.141 5.695 6.453
10回ずつ最適化して得られた目的関数(部材総体積)𝑉𝑉の中央値
𝑝𝑝0 : 改悪解を受理する初期確率, 𝑐𝑐 : 冷却率

学習済みのNNを再学習無でそのまま最適化に使用
異なる骨組モデルにも適用
23
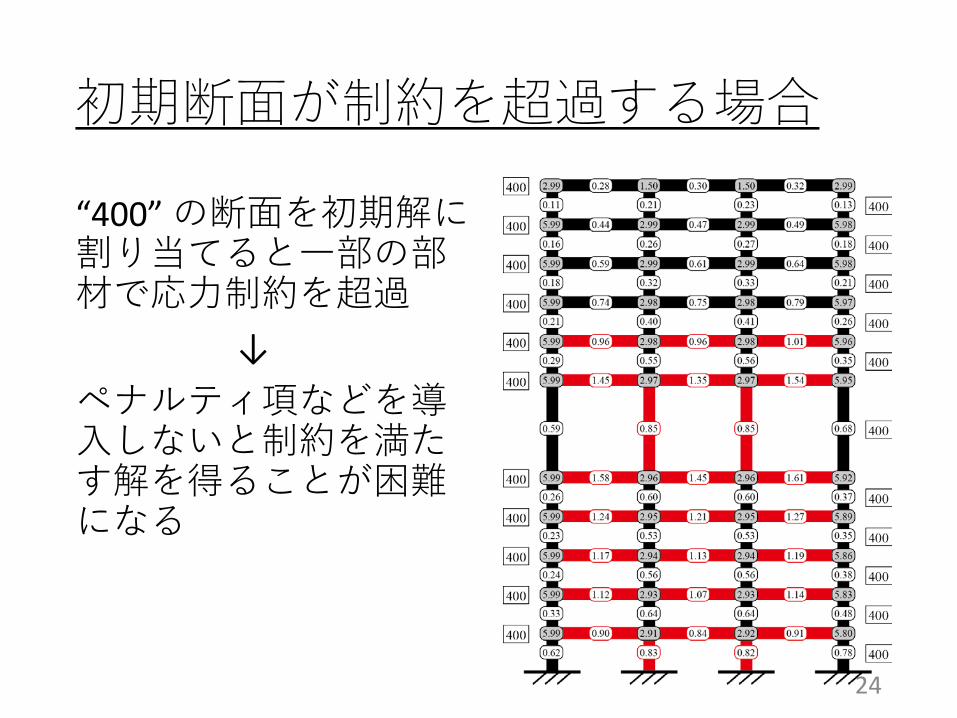
“400” の断面を初期解に割り当てると一部の部材で応力制約を超過
↓ペナルティ項などを導入しないと制約を満たす解を得ることが困難になる
初期断面が制約を超過する場合
24

• SA+DQNは制約を満たす解に到達できる
• 制約を満たす初期解から最適化しても、SA+DQNの方がわずかに良い結果が得られた
最適化結果
25
Max. Median Min. Average Std. dev.SA+DQN 11.000 10.482 10.175 10.505 0.293SA only No feasible solution found
Max. Median Min. Average Std. dev.SA+DQN 10.975 10.333 9.775 10.349 0.303SA only 10.850 10.504 10.084 10.450 0.206
10個の最適化結果の部材総体積(制約を満たさない“400”の初期断面を与えた場合)
10個の最適化結果の部材総体積(制約を満たす“600”の初期断面を与えた場合)
10個中9個の解が制約を満たす解
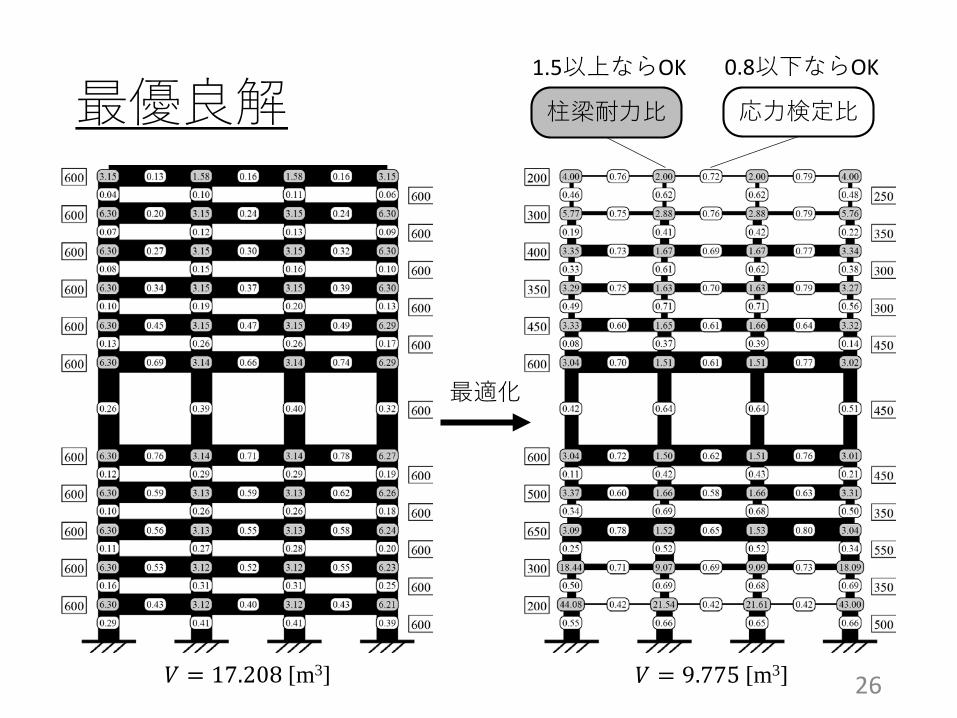
最優良解
26
最適化
𝑉𝑉 = 17.208 [m3] 𝑉𝑉 = 9.775 [m3]
柱梁耐力比 応力検定比1.5以上ならOK 0.8以下ならOK

結論• 構造要件を満たしながら部材総体積を減らすための骨組断面の変更方策を強化学習で学習
• 学習済エージェントとメタヒューリスティクスを併用し、より良い最適化結果を効率的に得た
• 学習済エージェントを再学習なしで異なる骨組モデルにも適用できることを確認
27
K. Hayashi and M. Ohsaki, Reinforcement learning for optimum design of a plane frame under static loads, Engineering with Computers, published online.
DOI: 10.1007/s00366-019-00926-7


















