
MySQL Know How - Greyhound-Data · MySQL Know How MySQL Performance Expectations ... and using it...
51
MySQL Know How MySQL Performance Expectations Typical Reasons for bad Server performance MySQL Architecture Understanding MySQL Storage Engines Improving MySQL Performance with Scale up - Vertical scale up and its limitations - Horizontal scale out and its limitations - Sharding - Partitioning Query Cache MySQL Schema Design Tips Understanding MySQL Indexes Understanding MySQL Joins Understanding how MySQL fetches Rows Analyzing the Database schema Understanding EXPLAIN, and using it for tuning Server Settings General Tips and Tricks Gunnnar von Boehn [email protected]
Transcript of MySQL Know How - Greyhound-Data · MySQL Know How MySQL Performance Expectations ... and using it...

MySQL Know How
MySQL Performance Expectations
Typical Reasons for bad Server performance
MySQL Architecture
Understanding MySQL Storage Engines
Improving MySQL Performance with Scale up- Vertical scale up and its limitations- Horizontal scale out and its limitations- Sharding- Partitioning
Query Cache
MySQL Schema Design Tips
Understanding MySQL Indexes
Understanding MySQL Joins
Understanding how MySQL fetches Rows
Analyzing the Database schema
Understanding EXPLAIN, and using it for tuning
Server Settings
General Tips and Tricks
Gunnnar von [email protected]

MySQL Performance Expectations
A general understanding of the MySQL limitations will allow you to distinguish suboptimal db schema or application flaws from general database server limitations.
Max Rows per TableSome people believe that MySQL can only hold a certain number of records. The truth is that the amount of possible records per table is nearly unlimited.MySQL can hold 18 quintillion records per table.= 18,000,000,000,000,000,000
Performance degeneration with increase of database records.Some people have a misconception about the impact of database grows to database performance. The truth is if you use simple, direct matching queries the amount of records is of little relevance for MySQL performance. A good designed application can scale well into billion and trillion of rows.
Of course the cost of full table scans increases linearly with the amount of records. But unless you are doing Data Warehousing you should not use full table scans.
Rows Performance
1 million rows 100%
1 billion rows 66%
1 trillion rows 50%
There is one exception to this rule:MySQL Fulltext Indexes only scale to about 1-10 million rows.The maximum number depends very much on the row length.If you need fast Fulltext search with more records then use an alternative. (e.g Sphinx)

Queries per Second
Its important to have a rough idea about what performance your database server could ideally be able to provide.
Typically database access patterns falls into three categories.− Cacheable READS from memory− READS from disk− WRITES to disk
Here is are some ballpark numbers for a typical entry server:(4-core, 3 GHz, 16GB Memory, 15K SCSI drives)
Queries/second• Entry level server : READ –IO from cache/memory 5.000 - 30.000 (Values depending on your schema design)
• Entry level server : READ –IO from disk 100 - 300 WRITE-IO to disk 100 - 200
• Server with 8 harddisks+ Raid controller with battery buffered writeback-Cache
READ-IO from disk 1.000 - 3.000 WRITE-IO to disk 500 - 1.000
• MySQL-ClusterREAD-IO (memory) 5.000 - 30.000 *WRITE-IO (memory) 10.000- 20.000
Note: The above values are for simple selects/inserts.Performance of very complex queries will of course be lower.

Queries per Second (cont'd)
The write speed of your server is limited by the speed of the physical disk drives. Without battery buffered RAID you will not be able to get more than 150 transactions per second.
To increase your READ performance you should try to max out your physical memory to allow as many requests as possible to fall into the “cached in memory” category. Switching from DISK-IO to in memory operation typically results in a 100 times performance increase.
MySQL Cluster is optimized for high WRITE throughput.MySQL Cluster has certain limitation that we will discuss later but its worth to mind that Cluster can be a very efficient way to increase WRITE performance.
If your database application requires more requests than your average database server can handle, then you should look into one of MySQL's scale out options.

Typical Reasons for Bad MySQL Server Performance
Bad choice of storage engine− MySQL offers various storage engines optimized for certain
workloads. A bad choice could cause locking problems.
Database Schema − insufficient keys− inefficient joins− to little or too much normalization
Suboptimal Queries− Not all queries are well written− Sometimes the SQL server is unable to resolve a query the best way
Suboptimal Server Settings− MySQL default server settings are only useful for tiny databases
Note: Mind to analyze your whole application.Often problems in the database layer are created by flaws in one of the layers on top. Web server, Application server and middle ware and application design should always be analyzed together with the database server.

MySQL Architecture
MySQL consists of three layers:
The Connection Layer The SQL Layer The Storage Engines (MyISAM, InnoDB, ...)

Understanding MySQL Storage Engines
MyISAM
No Transactions unlimited read concurrency key cache in MySQL-memory very compact row format = small on disk and in cache. compact key format = small on disk and in memory Fulltext Key (Note: scales to a few million rows) only Table locking very limited concurrency in mixed read/write no Data cache in MySQL
InnoDB
ACID Transactions Note: Can create deadlocks. Application needs to handle this.
MVCC (Multi Version Concurrency Control) / Row level locking foreign key support unlimited read concurrency unlimited read/write concurrency Crash save Both Data and Key Cache in MySQL-memory row data is longer keys are bigger no accurate index statistics, Analyze table does not work
can result in sometimes surprising bad query plan
Archive Read only (only SELECT and INSERT - No Update/Delete) Very compact on disk!

NDB / MySQL-Cluster In memory Excellent for session handling workloads Tuned for high write load Tuned for 99.999 availability Transactional Not for general purpose solutions
FALCON
(InnoDB replacement) ACID Transactions
Note: Can create deadlocks. Application needs to handle this. MVCC (Multi Version Concurrency Control) Row level locking Optimized for high concurrency and in memory. For systems with many cores and lots of memory. early alpha stage
MARIA MyISAM ++
It adds the feature that were planned for MySQL 3.24 data cache crash save early alpha stage
PBXT (PRIMEBASE) Product of Primebase GmbH ACID Transactions MVCC Support Row-level locking Write-once Referential Integrity (Foreign Keys etc) very promising but also very new

MySQL Storage Engines Summary
The right table type for your application
You can mix table types in your databaseand choose the table type most appropriate for each table.
MyISAM is very good for READ only usages is very good for WRITE only usages (i.e. log-file) can give huge problems in mixed READ/WRITE environment
InnoDB InnoDB has more overhead than MyISAM.
Rule of thumb: InnoDB is 25% slowerOn the other hand, because InnoDB caches Data+Keys, InnoDB can also outperform MyISAM in certain cases.
In read/write workloads InnoDB is always better than MyISAM.
Archive Useful for log_tables.
Falcon/Maria You better wait until they are more matured.
Before you rely on them, wait till 2010.
General Rule:For most users InnoDB is the “best” general purpose table type.InnoDB performs predictable in all environments, mixed Read/Write workloads are no problem. Most applications that have problems with MyISAM’s locking behavior will run perfectly on InnoDB.

Table locks – When table locks become a problem
A MySQL server usually runs many queries in parallel. Typically a MySQL server has 1-30 queries running at the same time.
A fast MySQL query takes less than 1/1000th second.
Both fast and slow READs can be mixed without problems too.If a slow READ takes several seconds or even minutes, then the table is not blocked – hundreds of other READs can be executed during that time and access the same table in parallel.
The above is true for all MySQL storage engine.
MyISAM has the limitation that INSERT/UPDATE/DELETE can NOT go in parallel.A write request has to wait until ALL previous queries are finished.When a write request is waiting, it locks the table so that no other query can start until the write request is finished.
Mixing fast READs and WRITE is no problem at all.
Problems occur when a long running READ and a WRITE request is send to the same table. The WRITE will wait for the long running READ to finish (this could be minutes) and the WRITE blocks all other queries from accessing the table.
InnoDB does not have this limitation.

MySQL Scaleout
If your database application requires more requests than one database server can sustain then you need to scale up or out.MySQL performance can be increased by scaling up vertically or scaling out horizontally.
Four common techniques to increase performance:
Vertical scaling = Scale Up
Horizontal scaling = Scale Out(Commonly used with MySQL replication)
ShardingCan be combined with the above.Very useful in combination with MySQL Cluster.
PartitioningMostly only useful for data Warehouse applications.Can be combined with the other techniques.

Vertical scaling means bigger machine
Typically you scale up by adding more CPU cores and by adding more disks to increase IO-throughput.
MySQL handles each request in a separate thread.Therefore multiple requests are handled in multiple threads, which can be spread well over multiple CPU cores. In theory MySQL could use an unlimited number of threads and therefore should scale good over an unlimited number of CPU cores.
Unfortunately, the situation is a lot different in reality.The MySQL server has numerous shared resources for which the threads will compete, these resources will quickly become bottlenecks and limit any scaling up. To handle these shared resources locks and mutexes are required. The overhead for managing these mutexes increases with each added CPU core and after a certain point adding more cores will not increase the server performance anymore. There are even cases where multi cores systems will get slower than the single core was because of this behavior.
Shared Resources which cause bottlenecks:- Query Cache
Threads will compete for Query cache checks and pruning- MyISAM Index cache
Threads are competing for this resource.Issue can be softened with using multiple index-caches
- InnoDB buffer pool / several internal mutexes
Today, 4-8 CPU cores is the vertical scaling limit of MySQL.
Up to 4 cores performance increases linearly.1 core = 100%, 2 cores =200% and 4 cores = 400%After 4 cores the increase is significantly less.8 cores give only 600% and 16 cores only 750%.After 16 CPU cores adding more cores gives no performance increase.

Vertical scaling (cont'd)
Scaling over CPU cores Scaling of Connections
MySQL usually scales very good to 4 cores.At some point MySQL will loose too much performance in mutexes. The exact point when this will happen depends on your workload.
For best performance the number of active threads need to be limited.Too many active threads will create a lot of mutex overhead.
A good value for performance is max-threads = 2 x CPU-cores.
Currently there is no clean way to avoid these scaling issues with MySQL.
Sun used some hacks on their Niagara Systems, but these are not recommendable to do for the public.
The goal of the Drizzle project is to solve this issue.Drizzle is an relative new Open Source spin-off of MySQL.Drizzle is a cut-down version of MySQL which leaves “unneeded” features away. I.E. Drizzle does not support MySQL Query Cache.Drizzle goal is to be optimized for Cloud and multi Core systems.

Horizontal Scale out
Horizontal scaling means adding more servers.
A simple way of doing this is to use MySQL build in Master-slave replication and to add numerous slaves to share the READ-workload.
All INSERTS/DELETES/UPDATES queries will be executed on the master server. The master-server will replicate these queries to all slaves.The READ-load can be shared over multiple slaves.
The separation of READ/WRITE queries can be done in the application or by adding an extra tier (mysql-proxy) that can do this automatically.
Horizontal / Master-Slave is great for Read-Only applications.
Drawbacks of Master-Slave replication
− Write load copied to each serverEach write is replicated to all slaves. Therefor if the master server has a high write load, the same high write load is on all slaves too.On write heavy system this can cause that each slave is already saturated by the replication-writes and has little performance left for any Read-workload.
The problem gets enforced by another factor. The write load is split on the MySQL-Master over all CPU cores. But on the slaves servers all the replication workload is always done by a single thread. Therefor it can happen that a master server can handle his write load – but its slave can not as the single thread on the slave side gets overloaded.
− Replication Lack can cause issuesThe database application needs to be aware that an inserting of a row is done on the master and a read is done on the slave. If an application updates a record and immediately reads it back before the record is replicated to the slave – then the application will show stale information. Normally the replication lack is less than 1 second – but under high workload situations slaves can accumulate several seconds of lack.

Horizontal Scale out (cont'd)
For workloads with many writes Master-Slave does not scale.
A better solution for high write load is NDB/ MySQL-Cluster.NDB shares writes on the whole cluster and will perform much better in this scenario. An advantage of MySQL-Cluster is that it can be plugged transparently into a MySQL setup. You can convert single tables to NDB, fully transparent to your application.
How good does Horizontal scale out scale?Master-Slave can be chained. You can build trees or even chains with it. In theory you can add an unlimited number of slaves.Some customer use setups with several hundred slaves.
It showed that in general 5-10 slaves is a good maximum size.

Sharding
Sharding means splitting the database over several servers by holding individual tables on separate servers.
In contrast to horizontal scale out where each server holds the whole database, sharding splits the database over several servers. Therefore a single server does not contain the whole database anymore.
Please note that MySQL can only solve queries on ONE server.Please note also that MySQL can not combine queries which access tables from separate servers.
While horizontal scale out is transparent to the application, sharding is usually not.
One of the main benefits of Sharding is that WRITE load can be split over several servers.
There are some cases where sharding is very useful.Sometimes you see a mostly read only application with some write hot spot on some tables. Moving these tables to a MySQL-Cluster removes the write load from the main servers. The MySQL-Cluster can be combined in such a way that the normal database server will forward request to the cluster and combine them with their results.This way the sharding is fully transparent to the application.

Partitioning
The concept of partitioning is splitting tables into a number of sub tables. For the application this splitting is transparent.
Two common types of partitioning are known.
a) Splitting tables per rowsEach sub-table has all columns but hold a fraction of the total rows.
The advantage of this concept is that full table scans can often be done by using only some subtables. Therefore this type of partitioning improves performance of certain types of full table scans.
b) Splitting by columnsThe sub-tables contain a certain portion of the columns.This is quite useful for separating “Hot” and “Cold” columns.This way you can often transform a variable length table into a Hot table with fixed row length and a Cold table with variable rows.
MySQL does not support this type of partitioning.
Please note that the sub-tables need to stay on the same server.MySQL does not support partitioning over separate servers.
Partitioning with MySQL 5.1 is quite useful for data ware house applications.If your database size is many times bigger than your server memory and if you use no indexes but solve most of your queries with full tables scans then the MySQL partitioning will be very useful for you.
You should not use MySQL partition on normal OLPT applications, as it will reduce performance.

MySQL QUERY Cache
The query cache stores the “text” of a SELECT statement together with the corresponding result.
Database-Workflow:1) Database-Connection2) Query-Cache3) Query Planner4) Database
Unlike other RDBMS which cache query plans, MySQL caches the result set.The advantage is clear. On a cache hit MySQL is able to answer queries faster than all other databases. There is of course a disadvantage to this technique as well. A write to one of the tables will invalid all rows using that table in the QUERY cache.
Query cache is very good for repeated queries in mostly READ ONLY setup. If many writes are done to your database, the MySQL query cache has a huge overhead of invalidating and purging and becomes useless or might slow the system down. The maintenance cost for MySQL cache is about 10%-15%.
Even faster than MYSQL Query cache could be caching on application level before the database server.
Rule of thumb for caching performance for simple SQL-Query
Cache-Type PerformancePHP-Cache 100.000Memcache 15.000Query-cache 10.000Query 5.000

Understanding the Query-Cache efficiency
show status like 'Qcache%';
| Qcache_free_blocks | 1874 || Qcache_free_memory | 5352072 || Qcache_hits | 384057 || Qcache_inserts | 8734818 || Qcache_lowmem_prunes | 7260907 || Qcache_not_cached | 36121 || Qcache_queries_in_cache | 4393 || Qcache_total_blocks | 10745 | (24MB)
Lowmem prunes are very high!
Hitratio ( Qcache_hits DIV Qcache_inserts ) = 0.04Consider to disable the cache.

Schema Design Tips
The Database schema is very important for the scalability and performance of the whole application.There are a few simple things that you should try to avoid.
Keep Types as short as possibleDatabase storage size is relevant for cache performance.MySQL provides more data types than other RDMS allowing you to optimize disk storage. Choosing the right column type can make a bigperformance difference.
Tinyint(1 Byte), Smallint(2 Byte), Mediumint(3 byte), Int(4 Byte), Bigint(8 Byte) Smaller types are faster and use less storage space.
SET('likes rock','likes pop','likes western')ENUM('dog','cat','horse')
CHAR vs VCHAR Char needs always the maximum space on disk. E.G. char(255)Vchar uses variable size, and is therefor saving storage space. Mind that a variable row length can have disadvantages as well.
Try to avoid BLOBWhile you can store BLOBS in the DB be careful with this. Consider to store Blobs on the file system and to store pointers to them in the database. The file system will always be faster and more efficient for this than a database.
Text Columns MySQL solved “GROUP BY” and “Order By” with temp tables.Text and BLOB can NOT be stored in memory temp tables therefor tables using these types will always fall back to temp disk tables.
InnoDB includes the Primary Key in every other keyTherefore its very important that the primary is short and fast.Always use INT(8/16/24/32) as primary key. Avoid Bigint(64) and never use char/vchar as primary.

Schema Design Tips (cont'd)
Avoid joining over Char columnsChar columns need collation conversion which is slow.
UTF is expensiveIf you don’t need UTF then stick to ASCII.
Try to use shortened keysIf you are indexing char columns try to short keys.CREATE INDEX part_column ON table (charcolumn (n))
Always use the same data type when joining columnsEven slightly different types will need costly conversion.Int(32) != Int(64)
Unique keys require relative expensive checkingMany unique keys will cost time when using InnoDB.
Vchar(255) is small on disk but huge in memory!Vchar(255) on UTF needs 760 bytes for each value in memoryEven for single char! SQL_CALC_FOUND_ROWS – Be very careful with this!It disables all possible LIMIT optimizations.Two queries are usually better than one using CALC_FOUND_ROWS.SELECT count(*) FROM tableSELECT * FROM table LIMIT x
Simple Joins are fast but sometimes it is better not to join at all.De-normalizing and using cached columns will be faster in some cases.

Understanding MySQL Indexes
MySQL supports B-Tree and Hash indexesB-tree supports =,>,<,IN, BETWEENHash only supports =,!=Hash is faster for direct matching queries
MySQL can only use an Index / Beginning of IndexFast: like 'abc%' Slow: like '%abc'
Unless using OR, per table only one Index is usedSELECT * FROM table WHERE key1='abc' AND key2='0'Will only use one of the two keys
You can create multi column indexThe above can be solved by created an index spanning both columns
Most table types support data retrieval directly from INDEXSometimes queries can be answered by the index without the need to access the data row at all. This is supported by MyISAM and InnoDB but not by FALCON.
You can HINT the optimizer to use or not use an INDEX SELECT * FROM t1 FORCE INDEX(goodkey1,goodkey2) WHERE (goodkey1 < 10 OR goodkey2 < 20) AND badkey < 30;
OPTIMIZE TableDefragments table and index – does this by copying table.
ANALYZE TableDates up the statistics. Up2date statistics are needed for the optimizer. Does now work reliable on InnoDB.On InnoDB it will only load 10 rows and then estimates.
Mind the Cardinality of your INDEXindex on (Male,Female) is bad. Access over your index should limit the number of results to 10% or less.

Understanding MySQL Joins
Always index columns which are used for a join
If the joined columns do not have the same data type, thenthe indexes on them can not be used.
MySQL only uses Nested-Loop JoinsThe cost for a nested loop a quadratically to the number of rows.If you join tableA with tableB then for each row in tableA every row in tableB is checked.
MySQL does not support Hash-Joins
In same cases rewriting a JOIN into a SUBSELECT is faster

Understanding how MySQL fetches rows
Fulltable scan No index is used, this is faster than using INDEX on many rows
Scanning index1. getting row-ids from index2. fetching the corresponding data rows
− Scanning index in order1. getting row-ids from index2. sorting row-ids3. then fetching the corresponding data rows.
(currently only FALCON)
− Scanning Index and get all data from covering index(Explain will show “USE INDEX”) (Not possible with FALCON)

Analyzing the Database schema
Simple ToolsSHOW CREATE TABLE tablename;
SHOW INDEX FROM tablename;
Find unneeded keysa) mk-duplicate-key-checker (maatkit)
b) Install MYSQL server with “user statistics patch”Then you can select for unused indexes:
SELECT DISTINCT s.TABLE_SCHEMA, s.TABLE_NAME, s.INDEX_NAMEFROM information_schema.statistics `s`LEFT JOIN information_schema.index_statistics IS ON (s.TABLE_SCHEMA = IS.TABLE_SCHEMA AND s.TABLE_NAME=IS.TABLE_NAME AND s.INDEX_NAME=IS.INDEX_NAME) WHERE IS.TABLE_SCHEMA IS NULL;
Understand which tables are mostly usedHelpful is again “user statistics patch”
SELECT * FROM information_schema.index_STATISTICS LIMIT 10;SELECT * FROM information_schema.table_STATISTICS LIMIT 10;
Log slow querieslog-slow-querieslong_query_time = 1Mind that 1 sec is an eternity.0.10 second is already too slow for a serious application.
Log queries which are not using an INDEXlog-queries-not-using-indexes
Log all queries and replay them for testinglog = filenameor mysqlbinlog yourlogfile | grep v i P "^(SET|use|#)" > clean.log
Replay with:o mysql client,o mk-log-playero mysql super smacko mysqlslap

How to measure your queriesWhen you benchmark your queries you should disable theQuery cache to ensure that you measure “real values”.Single queries can be written with SELECT SQL_NO_CACHE …
Tuning your SQL
Often applications have a few SQL-Queries that suffer from suboptimal query-plan. Depending on the setup such queries can create a performance bottleneck and tweaking them is worthwhile.Especially with MyISAM and table lock, a few long running queries can create an avalanche like effect on the whole application.
Besides simply “bad” written queries, sometimes the problem is that the SQL-server makes a mistake in resolving the query.There are different ways how a server can access the data records,re-validating that the MySQL used the best method makes sense.

Use EXPLAIN to understand the query plan
“EXPLAIN Select ….” Will provide you with information on how the Server will resolve the query and what keys it decides to use.
It happens that the MySQL query planner creates very suboptimal plans. You can use “hints” to your query to improve those queries.
Most useful hints:
STRAIGHT_JOIN
USE INDEX (..name..) Only this index is allowed to be used. Database has choicebetween using these named index or do full table scan
FORCE INDEX (..name..)As USE index but full table scan is marked as infinitive expensive.
IGNORE INDEX (.. name..) This key is not allowed to use!
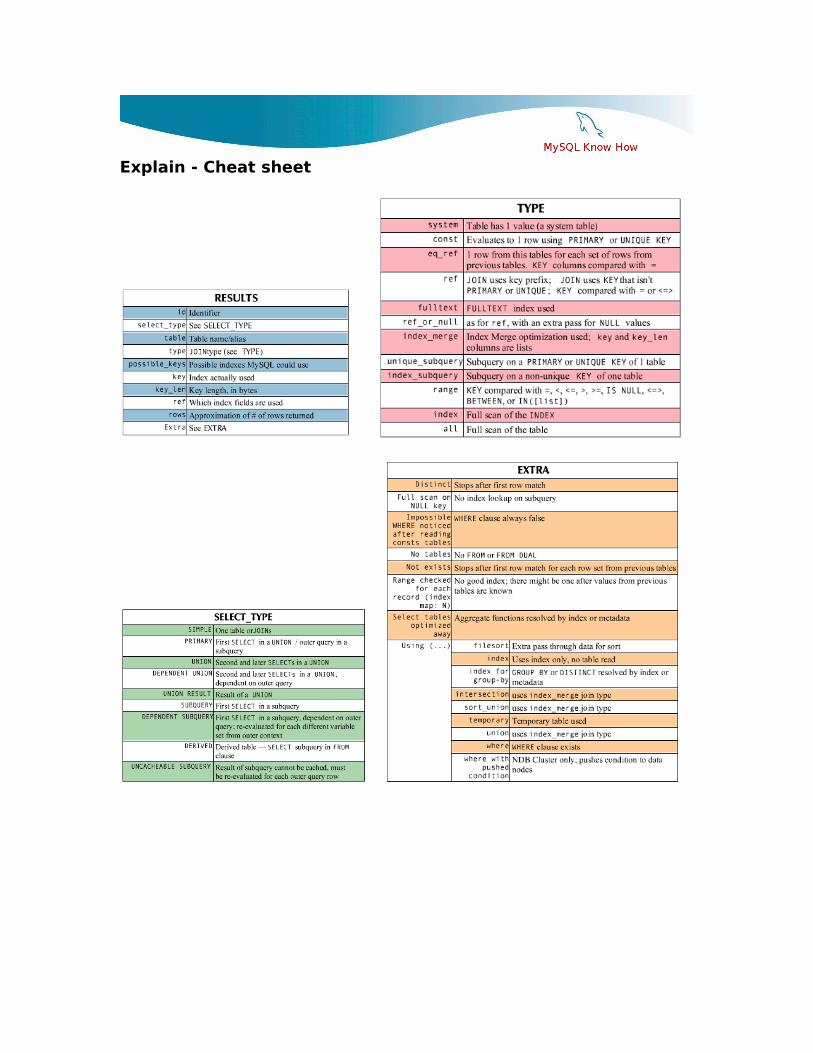
Explain - Cheat sheet

Looking at some typical Problems
In the next examples we see some of the most typical MySQLQuery Planner issues and we see how EXPLAIN can be used to find them and how they can be solved.
1) Not using a Key at all2) Using a wrong key3) Problems with SQL_CALC_FOUND_ROWS4) Joins done in wrong order5) MySQL resolving JOIN in suboptimal order6) How clever is the optimizer in rewriting the Where clause?
And we look at some best practices for pagination.

Suboptimal Queries
Example 1) Missing key
SELECT SQL_NO_CACHE COUNT(*) AS total FROM question WHERE group_id = 6;
Time 2.2 sec
Table Info:There are 1.500.000 rows in table question
Lets use EXPLAIN to see the query plan.
EXPLAIN SELECT SQL_NO_CACHE COUNT(*) AS total FROM question WHERE group_id = 6;
Explain: id: 1 select_type: SIMPLE table: question type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1551070 Extra: Using where
This reads like this: The query can NOT use a key. Therefore the whole “question” table is scanned
and every row is compared to the WHERE clause.
After adding a key, the query will take only 0.02 secs.
Mind:• You can enable logging of queries not using keys! Add log-queries-not-using-indexes to my.cnf

2) Bad INDEX usage
SELECT id, status_pointsFROM expert WHERE status IN ('user_ok') AND disabled_flag = 0ORDER BY status_points DESC LIMIT 0,100;
Time 0.80 sec
Table Info:There is a spanning key on (status and disabled_flag)There is a key on status_pointsThere are 690.000 rows in table expert120.000 rows match the WHERE clause
Explain: id: 1 select_type: SIMPLE table: expert type: refpossible_keys: status_disabled key: status_disabled key_len: 2 ref: const,const rows: 125203 Extra: Using where; Using filesort
This reads like this: The query does a lookup on index “expert.status_disabled”. For each match the corresponding row is fetched from “expert”. The query fetches 120.000 index rows from status index. The query fetches the 120.000 corresponding data rows. The query has to sort the resulting 120.000 rows. The query only returns the first 100 rows.

Example 2 Cont'd
This can be tuned:Its better to use the index on “status_points”The query can scan the status_points in ORDER, fetch the corresponding rows and break out early after finding 100 rows.As we have an average match of 1/6, the query will in average only access 600 rows and no sorting is needed.
SELECT id, status_pointsFROM expert USE INDEX (status_points)WHERE status IN ('user_ok') AND disabled_flag = 0ORDER BY status_points_sum DESC LIMIT 0,100;
Time 0.00 sec
Visual-Explain:+- Bookmark lookup +- Table | table expert +- Index scan key expert->status_points key_len 4 rows 693655
This reads like this: The Index on “expert->status_points” is range scanned For each index value the corresponding table row is fetched. The Query will opt out as soon as the requested 100 rows are
found.
Please mind:• Index of low cardinality columns is often not useful
An index on Boolean columns (f/m) usually hurts performance.Often it’s better to not have these types of index at all.Rule: Index should at least limit the number of rows to 10%.

3) Optimization problem with SQL_CALC_FOUND_ROWS
SELECT SQL_CALC_FOUND_ROWS * FROM tags WHERE oc_total > 0 AND disabled_flag = 0ORDER BY oc_total DESC LIMIT 0,60;
Time = 1.30 sec
Table Info:There is a key on column oc_totalTable tags has 460.000 rows390.000 rows match the WHERE clause
Explain: id: 1 select_type: SIMPLE table: tags type: ALLpossible_keys: overall_counter key: NULL key_len: NULL ref: NULL rows: 460446 Extra: Using where; Using filesort
This reads like this:The server sees that it there is an Index on “overall_counter”But the server decides to instead do a full table scan on 460,000 rows.The full result of 390.000 rows is then sorted.
Why does the server prefer to not use the INDEX?
The server knows it has to fetch all rows because of SQL_CALC_FOUND_ROWS. A sequential table scan is usually faster than going over an INDEX when many records are accessed.

3) cont'd
How could the query be improved?
Our Query uses LIMIT. So we actually don't need to fetch all 400,000 rows. By removing SQL_CALC_FOUND_ROWS we can allow the server to take advantages of this fact.
SELECT * FROM tags WHERE oc_total > 0 AND disabled_flag = 0ORDER BY oc_total DESC LIMIT 0,60;
Time needed 0.00 sec
Explain: id: 1 select_type: SIMPLE table: tag type: rangepossible_keys: overall_counter key: overall_counter key_len: 4 ref: NULL rows: 387529 Extra: Using where
This reads like this:The server will now scan the index on “overall_counter” (in order!)For each index value it will fetch the corresponding data row.The server will stop the query as soon as the number of needed rows is reached. The server will in average process only 120 rows now.
The amount of rows should be fetched with a separate query.
SELECT count(*) as cnt FROM tagWHERE oc_total > 0 AND disabled_flag = 0;
If there is a key fully matching the where condition then this count query will be very fast. For this query to be “free” the key would need to span oc_total and disabled_flag.

A few tricks for pagination
• Avoid SQL_CALC_FOUND_ROWS SQL_CALC_FOUND_ROWS is always used in combinationwith LIMIT - But it prevents LIMIT from resolving queries fast.
• Do you really need the exact amount? If not then let us cheat and save a lot of time.
If just a NEXT-button is OK, then already 1 fast query is enough.
Example:If you show 10 rows then use a SELECT with LIMIT of 11.If you get 11 rows display 10 and you know you have to show the NEXT button.
• If you have two queries.One for the count and one for the data,then try to limit the count query on the least amount of joins.
• Sometimes people use cached “count_tables” in DB or memory.

4): Join done in the wrong order, resulting in table scan
SELECT * FROM tagsJOIN tag_group ON (tag_group.tag_id = tags.id)WHERE tag_group.group_id = 6 AND tag_group.oc_total > 0 AND tags.disabled_flag = 0ORDER BY tag_group.`oc_total` DESC LIMIT 0,60;
Time 2.70 sec
Table Info:Table tags has 460,000 rowsOf table tag 459,000 rows match the Where clause (tag.disabled_flag = 0)
Table tag_group has 1,870,000 rowsOf table tab_group 344,000 match the Where clause (tag_group.group_id = 6 AND tag_group.oc_total > 0)
In total 344,000 rows match the query
Explain: id: 1 select_type: SIMPLE table: tag type: ALLpossible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 460476 Extra: Using where; Using temporary; Using filesort*************************** 2. row *************************** id: 1 select_type: SIMPLE table: tag_group type: eq_refpossible_keys: PRIMARY,overall_counter key: PRIMARY key_len: 8 ref: de_live_magma.tag.id,const rows: 1 Extra: Using where
This reads like this:The server does a full table scan on “tag” filtering with WHEREFor each row the index on “tag_group.primary” is looked up.The corresponding data row from tag_group is fetched.This result is stored in a temp table.This is sorted.

The FULL_TABLE SCAN, storing the result in temp table, and doing a filesort, this is slow.
The server does not use the LIMIT clause to reduce work.The server should go first over the group_tag table and use the LIMIT clause to save time. We can enforce this by forcing the use this key!
Let’s turn the Query around and write it down in the orderthat is matching the best join order.
Start with the tag_group.
SELECT STRAIGHT_JOIN * FROM `tag_group` JOIN tag ON (t.ag_group.`tag_id` = tag.`id` AND tag.`disabled_flag` = 0)WHERE tag_group.`group_id` = 6 AND tag_group.`oc_total` > 0 ORDER BY tag_group.`oc_total` DESC LIMIT 0,60;
Time 0.00sec
Visual Explain:JOIN+- Filter with WHERE| +- Bookmark lookup| +- Table| | table tag| | possible_keys PRIMARY| +- Unique index lookup| key tag->PRIMARY| possible_keys PRIMARY| key_len 4| ref de_live_magma.tag_group.tag_id| rows 1+- Filter with WHERE +- Bookmark lookup +- Table | table tag_group | possible_keys PRIMARY,overall_counter +- Index range scan key tag_group->overall_counter possible_keys PRIMARY,overall_counter key_len 4 rows 1555513

This reads like this:The index on “tag_group->overall_counter” is scanned (in order!).For each match the corresponding data rows of Tag_group is fetched.The primary index of table tag will be used to join the corresponding row of table tag.No sorting is neededThe server will opt out after finding 60 matching rows.
Another option to get the same result is adding “FORCE KEY” at the right place to the original query.
SELECT * FROM `tag_group` Force Key (overall_counter)JOIN tag ON (t.ag_group.`tag_id` = tag.`id` AND tag.`disabled_flag` = 0)WHERE tag_group.`group_id` = 6 AND tag_group.`oc_total` > 0 ORDER BY tag_group.`oc_total` DESC LIMIT 0,60;

5) MySQL resolving JOIN in suboptimal order
SELECT t.`id`, t.`name`, COUNT(*) AS `counter` FROM `tag` t INNER JOIN `question_tag` qt ON (t.`id` = qt.`tag_id` AND t.`disabled_flag` = 0)INNER JOIN `question` q ON ( qt.`question_id` = q.`id` AND q.`disabled_flag` = 0)INNER JOIN `expert_suggestion2` es ON ( es.`type` = 'question' AND q.`id` = es.`object_id` AND es.`denied_flag` = 0 AND es.`expert_id` = 676969 )WHERE t.`id` IN (19,2043,3981)GROUP BY t.`id`;
Time: 11.09 sec
Table Info:Table tag 460,000 rows;Table tag 3 rows match Where clause IN (19,2043,3981)Table question_tag 3,100,000 rowsTable question 1,500,000 rowsTable expert_suggestion2 4,100,000 rows
Explain: id: 1 select_type: SIMPLE table: t type: rangepossible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 3 Extra: Using where*************************** 2. row *************************** id: 1 select_type: SIMPLE table: qt type: refpossible_keys: PRIMARY,question_id key: PRIMARY key_len: 4 ref: de_live_magma.t.id rows: 9 Extra: Using index*************************** 3. row *************************** id: 1 select_type: SIMPLE table: es type: eq_refpossible_keys: PRIMARY,expert_id,object_id key: PRIMARY key_len: 9 ref: const,de_live_magma.qt.question_id,const rows: 1 Extra: Using where*************************** 4. row *************************** id: 1 select_type: SIMPLE

table: q type: eq_refpossible_keys: PRIMARY,id key: PRIMARY key_len: 4 ref: de_live_magma.es.object_id rows: 1 Extra: Using whereVisual-explain
JOIN+- Filter with WHERE| +- Bookmark lookup| +- Table| | table q| | possible_keys PRIMARY,id| +- Unique index lookup| key q->PRIMARY| possible_keys PRIMARY,id| key_len 4| ref de_live_magma.es.object_id| rows 1+- JOIN +- Filter with WHERE | +- Bookmark lookup | +- Table | | table es | | possible_keys PRIMARY,expert_id,object_id | +- Unique index lookup | key es->PRIMARY | possible_keys PRIMARY,expert_id,object_id | key_len 9 | ref const,de_live_magma.qt.question_id,const | rows 1 +- JOIN +- Index lookup | key qt->PRIMARY | possible_keys PRIMARY,question_id | key_len 4 | ref de_live_magma.t.id | rows 9 +- Filter with WHERE +- Bookmark lookup +- Table | table tag | possible_keys PRIMARY +- Index range scan key tag->PRIMARY possible_keys PRIMARY key_len 4 rows 3
This reads like this:

The key on (tag.primary) is scanned for match IN (19,2043,3981) The corresponding data rows are fetched.This is joined with index of “query_tag” (No data rows are needed)This is joined with index of “expert suggestion2”and the corresponding data rows are fetched.This is joined with the index on table “question”and the corresponding data rows are fetched and matched against the Where clause.How can this be improved?
Lets first fetch the rows from the biggest table “expert_suggestion”
SELECT STRAIGHT_JOIN t.id, t.name, COUNT(*) AS cnt FROM expert_suggestion2 esJOIN `question` q ON ( es.object_id = q.`id` AND q.`disabled_flag` = 0)JOIN `question_tag` qt ON (qt.`question_id` = q.`id`)JOIN `tag` t ON (t.`id` = qt.tag_id AND t.`disabled_flag` = 0)WHERE es.`type` = 'question' AND es.`denied_flag` = 0 AND es.`expert_id` = 676969 AND t.`id` IN (19,2043,3981) GROUP BY t.`id`;
Time 0.02 sec
Explain: id: 1 select_type: SIMPLE table: es type: refpossible_keys: PRIMARY,expert_id,object_id key: PRIMARY key_len: 4 ref: const rows: 10 Extra: Using where; Using temporary; Using filesort*************************** 2. row *************************** id: 1 select_type: SIMPLE table: q type: eq_refpossible_keys: PRIMARY,id key: PRIMARY key_len: 4 ref: de_live_magma.es.object_id rows: 1 Extra: Using where*************************** 3. row *************************** id: 1 select_type: SIMPLE table: qt type: refpossible_keys: PRIMARY,question_id key: question_id key_len: 4 ref: de_live_magma.q.id

rows: 2 Extra: Using where; Using index*************************** 4. row *************************** id: 1 select_type: SIMPLE table: t type: eq_refpossible_keys: PRIMARY key: PRIMARY key_len: 4 ref: de_live_magma.qt.tag_id rows: 1 Extra: Using where
This reads like this:The index from table “expert_suggestion” is used to fetch the rowsmatching es.`expert_id` = 676969 for these rows the other Where conditions are checked too.The result is joined with questions, the corresponding data rows are fetched.The result is joined with question_tag, the index file is enough for thisThe result is joined with tag, the corresponding data rows are read.
MySQL own estimate was that the first query plan is 20% faster than the second – which was not the case.1) estimated cost 48 vs 2) estimated cost 56
MySQL often fails to estimate the query cost for NDB tables.NDB does not hold correct statistics for NDB but always estimates 10 rows per table JOIN.With MySQL 5.1 correct statistics for NDB can be enabled withndb_index_stat_enable=1
MySQL is not perfect.Monitoring your Queries, and help the server to do it right.

6) How clever is the optimizer in rewriting the Where clause?
Usually the optimizer does less rewriting than people expect.
SELECT id FROM tag WHERE id>5 AND id>6 LIMIT 10;
Most will assume that the optimizer would rewrite it to WHERE ID>6
You can show the final WHERE with EXPLAIN EXTENDED SELECT …..Show warnings\G
We see that it does NOT rewrite and optimize the Where clause
SELECT … FROM tag where((`de_live_magma`.`tag`.`id` > 5) and (`de_live_magma`.`tag`.`id` > 6)) limit 10
But there are other cases which the optimizer catches.For queries working on huge numbers of rows it pays of to remove unneeded where conditions.

Simple Server Tuning
1) Check Key_buffer size
2) Check InnoDB_buffer size
Use different config for MASTER and SLAVE Does the Master need Query-Cache ? Does the Slave need binlog or double_write?
Most important InnoDB variables :
Some example values on 16 GB server
innodb_buffer_pool_size = 13000 M# This is one of the most important variables.# It should be as close as possible to the database size (13GB)# buffer_pool does cache both data and index.# We should keep an eye on the total memory consumption # Its very important that the server does not swap# If the server swaps out parts of our buffer then we have a problem.# The database engine relies on that the pool pages are in ram.# IO is scheduled in assumption that the buffer are in memory.# The server will hold looks around buffer access. # If the pool is in swap then this lock will take “forever”. # To early server swapping can be reduced with setting swappiness# echo 5 > /proc/sys/vm/swappiness
innodb_additional_mem_pool_size = 20M# def=1M, the def value is a bit tiny, give it a bit more# This buffer is used for internal structures
innodb_log_file_size = 400M# A big log_file does increase write performance,# But crash recovery time will increase too.# 256-1024 MB are reasonable values for a big and busy databases
innodb_log_buffer_size = 8M# 4M-8M are a reasonable values# If you work with huge blobs you might need to increase this

innodb_flush_log_at_trx_commit = 0# This is frequency of flushing transactions to disk.# def=1 will causse a SYNC after every transaction. # Depending on your HW (Battery buffered real Raidcontroller# with cache or not) this can be quite slow # and limit you to about 100 commits per second.# Setting it to 0 will max the speed as the sync is# done only every second.# But if you use =0 without battery buffered controller you# run the risk to loose the last second of transactions# in case of a crash.
innodb_file_per_table=1# have tables files like myisam. Makes reclaiming of table possible# its and both slightly good and bad for performance.
innodb_open_files=500# should be enough – look at your files (use files x2)
innodb_thread_concurrency = 16# Depends on your number of cores.# 16-32 for 8 cores# 8-16 for 4 cores# 8 for fewer cores# increasing this value can be good or bad.# increasing can improve performance but also raise contention issues.
innodb_flush_method = O_DIRECT# prevent Linux from wasting memory on caching innodb file access# Otherwise Linux will cache our database files too.
innodb_locks_unsafe_for_binlog=1# this changes the way innodb does locking.# Default value (0) has no phantom rows# BUT for updates it will hold a lock for all rows investigated.# Setting it to 1 can show phantom rows# BUT it will only lock rows which are actually updated# You can set it to 1 to reduce deadlock likeliness a lot
innodb_support_xa =0# Xa makes sense on Master.# It ensures that binlog table are always 100% in sync.# We do not need this on slave and can set it to 0 to be faster
innodb_doublewrite=0# Doublewrite is needed for journaling (To survive server crash)

# On the Slave this durability might not be important# and could be turned off to gain a few percent more speed.
innodb_checksums=0# For data consistency you should usually be enabled checksum.# If you trust your HW it could be turning off on slave# to reduce CPU consumption slightly
key_buffer = 250M# The key_buffer needs to be big enough to cache all MyISAM keys# Even if you have zero MyISAM tables you should allow a few MB# As its needed also for ALL TEMP tables!
table_cache = 300# files x 2
# Buffers Per thread (connection)sort_buffer_size = 2M # def 2M OKread_buffer_size = 1M # def 128kread_rnd_buffer_size = 1M # def 256kjoin_buffer_size = 1M # def 128kmyisam_sort_buffer_size = 16M # def 8M (Used by ALTER/REPAIR)
Mind that these values are per connection.With many connections this can consume plenty of memory.
query_cache_limit = 2Mquery_cache_size = 32M# high query_cache size is good when you are READ ONLY.# If your application does lots and lots of write,# your server will need to prune the cache a lot.# In this case minimize the cache size good be a good idea.query_cache_min_res_unit = 4KB

General Tips and Tricks
Pool your database connections.One dynamic page should only use one connection.
Use persistent database connections but mind that some buffers are kept per connection. Each connection can hold a few MB on the server. Apache + mod_php + persistent connection are problematic as they hold many DB connection open even when serving only static files that need no Database access. Try to use a separate web server for static files or limit the amount of PHP worker and the amount connections e.g. by running PHP as FastCGI.
Use expire headers on web server to reduce web server load
Try to keep short living write intensive data like sessions from db. Maybe you can cache them in memory (memcache/php_session)?
Evaluate if you can use slaves to scale out read load.Slaves are good to scale out, READ only load.
Try to separate different types of workload on different slaves.Run reporting queries on separate slave.Or do your backup with mysqldump on separate slave.
To backup you can use MySQL Hotcopy, LVM Snapshot, or MySQLDump
You can do LVM snapshot with:FLUSH TABLEFLUSH TABLE WITH READ LOCK;lvcreate –s;UNLOCK TABLES;Mount snapshot, do backup;lvremove

Make use of LIMITOften LIMIT is very useful to limit the amount of unneeded transferred records. Often you want to have both the limited records, and know the total amount of records.Imagine a search where you list the amount of found record e.g. 15000 and then show the details of the first 50 records. Very often the most effective way to do this is to run two separate queries. One query that search for the matching records. This query needs to by highly optimized - it should use as few tables as possible - Best is only to use one table. This query will return the number of total records.
Query Cache is very usefulFor applications doing mostly READS and often repeating queries.
Mind that the Query cache can fragmenta) Limit its size.b) Flush and rebuilt it from time to time.
Mind that Fulltext key only works with MyISAM/Maria.MySQL Fulltext key scales up only to a few million rows.Try out Sphinx as alternative.
Try to use InnoDBIf you use InnoDB- Check that no Lock table is used- Check that your Primary keys are short (int32)- Try to not use too many unique keys- Check that UPDATE or DELETE always uses INDEX. An Update/Delete without index will lock the whole table.- Check your thread concurrency. Does higher value improve performance for you?- Disable BINLOG on slave and use innodb_locks_unsafe_for_binlog to reduce locks.
Filesystem: XFS, ReiserFSMySQL on ReiserFS or XFS often has 10% higher write performance than on ext3.

Filesystem: noatimeMount the filesystem with noatime to reduce unneeded disk writes.
When you reboot a slave, warm it up before putting full load on it.Do this by loading data and indexes into memory.
For MyISAM use“LOAD INDEX INTO CACHE tablename;” For Key“SELECT max(some_column) FROM tablename;” For Data
echo "Scanning Primary index"mysql -e "SELECT CONCAT('SELECT \'PRELOAD ',TABLE_NAME,'\', count(1) FROM ',TABLE_SCHEMA,'.',TABLE_NAME,';') '#sql' FROM(SELECT t.TABLE_SCHEMA,t.TABLE_NAME,COLUMN_NAME FROM information_schema.tables t JOIN information_schema.columns c ON (t.table_name=c.table_name AND c.COLUMN_KEY!='') WHERE t.TABLE_SCHEMA ='de_live_magmA' AND t.engine='InnoDB' GROUP BY t.table_name ORDER BY DATA_LENGTH DESC LiMiT 15) foo;" | mysql
echo "Scanning Data records"mysql -e "SELECT CONCAT('SELECT \'PRELOAD ',TABLE_NAME,'\', count(',COLUMN_NAME,') FROM ',TABLE_SCHEMA,'.',TABLE_NAME,';') '#sql' FROM(SELECT t.TABLE_SCHEMA,t.TABLE_NAME,COLUMN_NAME FROM information_schema.tables t JOIN information_schema.columns c ON (t.table_name=c.table_name AND c.COLUMN_KEY='') WHERE t.TABLE_SCHEMA ='de_live_magmA' AND t.engine='InnoDB' GROUP BY t.table_name ORDER BY DATA_LENGTH DESC LiMiT 15) foo;" | mysql
Reduce DNS overheadAdd your servers into /etc/hosts
Try out the MySQL Binaries compiled with INTEL compiler.For Intel CPU the ICC compiled binaries are usually around 10%-20% faster.
Monitor InnoDB Pool efficiencyInnodb_buffer_pool_read_requests 955575102Innodb_buffer_pool_reads 52666
MyISAM Key Cache efficiencyKey_read_requests 317868155Key_reads 395220

SHOW Innodb status
SEMAPHORESMutex spin waits 0, rounds 988697, OS waits 2568RW-shared spins 21746, OS waits 8766; RW-excl spins 8991, OS waits 247
LATEST DETECTED DEADLOCKAt best this is empty
TRANSACTIONS(your current transactions in flight)
FILE I/O54895 OS file reads, 19748 OS file writes, 13365 OS fsyncs0.0 reads/s, 0 avg bytes/read, 0.33 writes/s, 0.33 fsyncs/s
INSERT BUFFER AND ADAPTIVE HASH INDEXIbuf: size 1, free list len 0, seg size 2,50 inserts, 50 merged recs, 50 mergesHash table size 7055701, used cells 6746334, node heap has 32548 buffer(s)799.07 hash searches/s, 20.33 non-hash searches/s
Review IO log activityLOG9284 log i/o's done, 0.33 log i/o's/second
BUFFER POOL AND MEMORYTotal memory allocated 3978720664; in additional pool allocated 1048576Buffer pool size 217600Free buffers 19941Database pages 165111Modified db pages 18Pending reads 0Pending writes: LRU 0, flush list 0, single page 0Pages read 165105, created 6, written 90450.00 reads/s, 0.00 creates/s, 0.00 writes/sBuffer pool hit rate 1000 / 1000(hit rate of 1000/1000 is excellent)
Quick overview of Database READ/WRITE usageROW OPERATIONSNumber of rows inserted 1722, updated 3877, deleted 445, read 6414157860.0 inserts/s, 0.00 updates/s, 0.00 deletes/s, 798.73 reads/s

Usefull SQL examples
/*SHOW the worst performing indexes in the whole server*/SELECT t.TABLE_SCHEMA AS `db` , t.TABLE_NAME AS `table` , s.INDEX_NAME AS `inde name` , s.COLUMN_NAME AS `field name` , s.SEQ_IN_INDEX `seq in index` , s2.max_columns AS `# cols` , s.CARDINALITY AS `card` , t.TABLE_ROWS AS `est rows` , ROUND(((s.CARDINALITY / IFNULL(t.TABLE_ROWS, 0.01)) * 100), 2) AS `sel %`FROM INFORMATION_SCHEMA.STATISTICS s INNER JOIN INFORMATION_SCHEMA.TABLES t ON s.TABLE_SCHEMA = t.TABLE_SCHEMA AND s.TABLE_NAME = t.TABLE_NAME INNER JOIN ( SELECT TABLE_SCHEMA , TABLE_NAME , INDEX_NAME , MAX(SEQ_IN_INDEX) AS max_columns FROM INFORMATION_SCHEMA.STATISTICS WHERE TABLE_SCHEMA != 'mysql' GROUP BY TABLE_SCHEMA, TABLE_NAME, INDEX_NAME ) AS s2 ON s.TABLE_SCHEMA = s2.TABLE_SCHEMA AND s.TABLE_NAME = s2.TABLE_NAME AND s.INDEX_NAME = s2.INDEX_NAMEWHERE t.TABLE_SCHEMA != 'mysql' /* Filter out the mysql system DB */AND t.TABLE_ROWS > 10 /* Only tables with some rows */AND s.CARDINALITY IS NOT NULL /* Need at least one non-NULL value in the field */AND (s.CARDINALITY / IFNULL(t.TABLE_ROWS, 0.01)) < 1.00 /* Selectivity < 1.0 b/c unique indexes are perfect anyway */ORDER BY `sel %`, s.TABLE_SCHEMA, s.TABLE_NAME /* Switch to `sel %` DESC for best non-unique indexes */LIMIT 10;


















