
Musical Source Separation using Generalised Non-Negative ...
36
Musical Source Separation using Generalised Non-Negative Tensor Factorisation models Derry FitzGerald [email protected] Matt Cranitch [email protected] Dept. of Electronic Engineering, Cork Institute of Technology, Rossa Avenue, Cork, Ireland Eugene Coyle [email protected] School of Electrical Engineering Systems, Dublin Institute of Technology, Kevin Street, Dublin, Ireland Keywords: Musical Sound Source Separation, Tensor Factorisation Abstract A shift-invariant non-negative tensor factori- sation algorithm for musical source separa- tion is proposed which generalises previous work by allowing each source to have its own parameters rather a fixed set of parameters for all sources. This allows independent con- trol of the number of allowable notes, num- ber of harmonics and shifts in time for each source. This increased flexibility allows the incorporation of further information about the sources and results in improved separa- tion and resynthesis of the separated sources. 1. Introduction In recent years, machine learning techniques such as shift-invariant non-negative matrix and tensor factori- sation have received much attention as a means of sep- arating sound sources from single and multichannel mixtures (Mørup M., 2006; Virtanen, 2006). Using shift-invariance in frequency allows a pitched musical instrument to be modelled as a single frequency basis function which is translated up and down in frequency to model different notes played by an instrument, while shift-invariance in time allows the temporal evolution of a sources timbre to be captured. More recently, improvements have been made to these models by imposing harmonicity constraints on pitched instruments (FitzGerald et al., 2008). This was done by using an additive synthesis model where a pitched instrument is modelled by a set of harmonic weights. A source-filter model was also incorporated to allow the timbre of instruments to change with pitch, resulting in improved separations. Further, the use of harmonicity constraints restricts the decompositions sufficiently to allow simultaneous separation of pitched and unpitched instruments. However, for best results, the model now requires an estimate of the pitch of the lowest note played by each pitched instrument. However, a limitation of shift-invariant models to date is that all the sources have to have the same param- eters. For example, the number of allowable notes or shifts in frequency is the same for all pitched instru- ments. However, the range of notes played in a given piece will vary with the instrument. It can be seen that being able to set the number of notes for each in- strument individually will reduce the possibilities for error in the separation. This would be of particular use in score-assisted separation, such as proposed in (Woodruff et al., 2006). Further, the number of har- monic weights required to model a given source varies. For example, modelling a flute will typically require less harmonics than a piano or violin. Therefore, the ability to vary the parameters for each source individ- ually would be advantageous, and would help to im- prove the separations obtainable using shift-invariant factorisation models. 2. Generalised Factorisation Models In the following, hABi {a,b} denotes contracted tensor multiplication of A and B along the dimensions a and b of A and B respectively. Outer product multiplica- tion is denoted by ◦. Indexing of elements within a tensor is notated by A(i, j ) as opposed to using sub- scripts. This notation follows the conventions used in the Tensor Toolbox for Matlab, which was used to implement the following algorithm (Bader & Kolda, 2007). For ease of notation, as all tensors are now instrument-specific, the subscripts are implicit in all
Transcript of Musical Source Separation using Generalised Non-Negative ...

Musical Source Separation using Generalised Non-Negative TensorFactorisation models
Derry FitzGerald [email protected] Cranitch [email protected]
Dept. of Electronic Engineering, Cork Institute of Technology, Rossa Avenue, Cork, Ireland
Eugene Coyle [email protected]
School of Electrical Engineering Systems, Dublin Institute of Technology, Kevin Street, Dublin, Ireland
Keywords: Musical Sound Source Separation, Tensor Factorisation
Abstract
A shift-invariant non-negative tensor factori-sation algorithm for musical source separa-tion is proposed which generalises previouswork by allowing each source to have its ownparameters rather a fixed set of parametersfor all sources. This allows independent con-trol of the number of allowable notes, num-ber of harmonics and shifts in time for eachsource. This increased flexibility allows theincorporation of further information aboutthe sources and results in improved separa-tion and resynthesis of the separated sources.
1. Introduction
In recent years, machine learning techniques such asshift-invariant non-negative matrix and tensor factori-sation have received much attention as a means of sep-arating sound sources from single and multichannelmixtures (Mørup M., 2006; Virtanen, 2006). Usingshift-invariance in frequency allows a pitched musicalinstrument to be modelled as a single frequency basisfunction which is translated up and down in frequencyto model different notes played by an instrument, whileshift-invariance in time allows the temporal evolutionof a sources timbre to be captured.
More recently, improvements have been made tothese models by imposing harmonicity constraints onpitched instruments (FitzGerald et al., 2008). Thiswas done by using an additive synthesis model wherea pitched instrument is modelled by a set of harmonicweights. A source-filter model was also incorporated toallow the timbre of instruments to change with pitch,resulting in improved separations. Further, the use of
harmonicity constraints restricts the decompositionssufficiently to allow simultaneous separation of pitchedand unpitched instruments. However, for best results,the model now requires an estimate of the pitch of thelowest note played by each pitched instrument.
However, a limitation of shift-invariant models to dateis that all the sources have to have the same param-eters. For example, the number of allowable notes orshifts in frequency is the same for all pitched instru-ments. However, the range of notes played in a givenpiece will vary with the instrument. It can be seenthat being able to set the number of notes for each in-strument individually will reduce the possibilities forerror in the separation. This would be of particularuse in score-assisted separation, such as proposed in(Woodruff et al., 2006). Further, the number of har-monic weights required to model a given source varies.For example, modelling a flute will typically requireless harmonics than a piano or violin. Therefore, theability to vary the parameters for each source individ-ually would be advantageous, and would help to im-prove the separations obtainable using shift-invariantfactorisation models.
2. Generalised Factorisation Models
In the following, 〈AB〉{a,b} denotes contracted tensormultiplication of A and B along the dimensions a andb of A and B respectively. Outer product multiplica-tion is denoted by ◦. Indexing of elements within atensor is notated by A(i, j) as opposed to using sub-scripts. This notation follows the conventions usedin the Tensor Toolbox for Matlab, which was used toimplement the following algorithm (Bader & Kolda,2007). For ease of notation, as all tensors are nowinstrument-specific, the subscripts are implicit in all

Musical Source Separation
tensors within summations.
Given an r-channel mixture, spectrograms are ob-tained for each channel, resulting in X , an r × n ×mtensor where n is the number of frequency bins andm is the number of time frames. The tensor is thenmodelled as:
X ≈ X =K∑
k=1
G ◦ 〈〈RW〉{3,1}〈SP〉{2,1}〉{2:3,1:2}
+L∑
l=1
M◦ 〈B〈CQ〉{1,1}〉{2,1} (1)
with R = 〈FH〉{2,1} and where the first right-handside term models pitched instruments, and the sec-ond unpitched or percussion instruments. K denotesthe number of pitched instruments and L denotes thenumber of unpitched instruments.
G is a tensor of size r, containing the gains of a givenpitched instrument in each channel. F is of size n×n,where the diagonal elements contain a filter which at-tempts to model the formant structure of an instru-ment, thus allowing the timbre of the instrument toalter with frequency. H is a tensor of size n× zk × hk
where zk and hk are respectively the number of allow-able notes and the number of harmonics used to modelthe kth instrument, and where H (:, i, j) contains thefrequency spectrum of a sinusoid with frequency equalto the jth harmonic of the ith note. W is a tensorof size hk × pk containing the harmonic weights foreach of the pk shifts in time that describe the kth in-strument. S is a tensor of size zk ×m which containsthe activations of the zk notes associated with the kthsource, and in effect contains a transcription of thenotes played by the instrument. P is a translationtensor of size m× pk×m, which translates the activa-tions in S across time, thereby allowing the model tocapture temporal evolution of the harmonic weights.
For unpitched instruments, M is a tensor of size rcontaining the gains of an unpitched instrument ineach channel, B is of size n × ql and contains a set offrequency basis functions which model the evolutionof the timbre of the unpitched instrument with timewhere ql is the number of translations in time usedto model the lth instrument. C is a tensor of size mwhich contains the activations of the lth instrument,and Q is a translation tensor of size m × ql ×m usedto translate the activations in C in time.
A suitable metric for measuring reconstruction of theoriginal data is the generalised Kullback-Leibler diver-gence proposed for use in non-negative matrix factori-
sation by (Lee & Seung, 1999):
D(X ‖ X
)=∑X log
XX− X + X (2)
Using this measure, iterative update equations can bederived for each of the model variables.
The model has been used to separate stereo mixturescontaining both pitched and unpitched instruments,and the ability to set the parameters independentlyhas been observed to improve the separation resultsobtained in comparison to the situation where thesame parameters are used for all instruments.
3. Conclusions
An algorithm was proposed which generalises previouswork in shift-invariant non-negative tensor factorisa-tion algorithms by allowing each source to have its ownparameters, such as note range, number of harmonicsand time shifts. This increased flexibilty has been ob-served to result in improved musical source separationperformance for mixtures of pitched and unpitched in-struments.
Acknowledgements
This research was supported by Enterprise Ireland.
References
Bader, B., & Kolda, T. (2007). Matlab tensor toolboxversion 2.2.
FitzGerald, D., Cranich, M., & Coyle, E. (2008). Ex-tended non-negative tensor factorisation models formusical sound source separation. to appear in Com-putational Intelligence and Neuroscience.
Lee, D., & Seung, H. (1999). Learning the parts of ob-jects by non-negative matrix factorisation. Nature,401, 788–791.
Mørup M., Schmidt, M. (2006). Sparse non-negativetensor 2d deconvolution (sntf2d) for multi channeltime-frequency analysis (Technical Report). Techni-cal University of Denmark.
Virtanen, T. (2006). Sound source separation inmonaural music signals. Doctoral dissertation, Tam-pere University of Technology.
Woodruff, J., Pardo, B., & Dannenberg, R. (2006).Remixing stereo music with score-informed sourceseparation. Proceedings of the 7th InternationalConference on Music Information Retrieval.

Learning Violinist’s Expressive Trends
Miguel Molina-Solana [email protected]
Department of Computer Science and Artificial Intelligence, University of Granada, 18071 Granada, Spain
Josep Lluis Arcos [email protected]
Artificial Intelligence Research Institute, IIIA, CSIC, Campus UAB, 08193 Barcelona, Spain
Emilia Gomez [email protected]
Music Technology Group, Pompeu Fabra University, 08003 Barcelona, Spain
Abstract
This paper presents a Trend-based modelfor identifying professional performers incommercial recordings. Trend-based mod-els characterize performers by learning howmelodic patterns are played. Reported re-sults using 23 violinists show the high identi-fication rates achieved with our model.
1. Introduction
Expressive performance analysis and representation isa key challenge in the sound and music computingarea. Previous research has addressed expressive mu-sic performance using machine learning techniques. Tocite some, in (Saunders et al., 2008) they representpianists’ performances as strings; in (Ramirez et al.,2007) they study how to measure performance aspectsapplying machine learning techniques; and in (Sta-matatos & Widmer, 2005) a set of simple featuresfor representing stylistic characteristics of piano mu-sic performers is proposed.
We focus on the task of identifying professional vio-linists from their commercial audio recordings. Ourapproach is based on the learning of the Trend Mod-els that characterize each performer. Trend modelscapture expressive tendencies and are learnt from au-dio descriptors obtained by using state-of-the-art au-dio feature extraction tools.
The whole process is done in an automatic way, usingonly the recordings (scores are not used). Since com-mercial recordings are so heterogeneous, it is reallydifficult to exactly translate the audio to an accuratescore representation. We deal with this problem by us-ing a more abstract representation that the real notes,but still close to the melody (i.e. instead of focusing onthe absolute notes, we focus on the melodic surface).
Specifically, we deal with this task by (1) using ahigher-level abstraction of the automatic transcrip-tion focusing on the melodic contour (Grachten et al.,2005); (2) tagging melodic segments according to theImplication-Realization (IR) model (Narmour, 1992);and (3) characterizing the way melodic patterns areplayed as probabilistic distributions.
2. Trend-Based Modeling
A trend model characterizes, for a specific audio de-scriptor, the relationships a given performer is estab-lishing among groups of neighbor musical events. Forinstance, the trend model for the energy descriptor willrelate, qualitatively, the changes of energy for a givenset of consecutive ascending notes. The main processesof the system are:
Feature Extraction and Segmentation The firstprocess consists on extracting audio features fromrecordings using an existing tool (Camacho, 2007). Us-ing fundamental frequency information, note bound-aries are identified and melodic segmentation is per-formed. For each note we collect its pitch, durationand energy. We used the IR model by E. Narmourto perform melodic segmentation. Each segment istagged with its IR pattern.
Learning Trend Models Trend models capture theway different audio descriptors change in the differentIR patterns. A trend model is represented by a setof discrete probability distributions for a given audiodescriptor.
To generate trend models for a particular performerand note descriptor, we use the sequences of valuesextracted from the notes identified in each segment.From these sequences, each value is compared with re-spect to the mean value of the fragment and is trans-formed into two qualitative values meaning ‘the de-scriptor value is higher than the mean’, and ‘the value

Learning Violinist’s Expressive Trends
is lower than the mean’. In the current approach,since we are segmenting the melodies in groups of threenotes and using 2 qualitative values, eight (23) differ-ent patterns may arise.
Next, a probability distribution per IR structure withthese patterns is constructed by calculating the per-centage of occurrence of each pattern. Thus, trendmodels capture statistical information of how a cer-tain performer tends to play. Combining trend modelsfrom different audio descriptors, we are improving thecharacterization of each performer. Trend models forboth duration and energy descriptors have been learnt.
Classifying new recordings We are using a nearestneighbor (NN) classifier to generate a ranked list ofpossible performers for a new input recording. Whena new recording is presented to the system, the featureextraction process is performed and its trend modelis created. This trend model is compared with trendmodels learnt in the previous stage acting as class pat-terns.
The distance between two trend models, is defined as aweighted sum of the distances between their respectiveIR patterns (i.e. their respective probability distribu-tions).
3. Results
We work with Sonatas and Partitas for solo violin fromJ.S. Bach. We tested our system by performing exper-iments with commercial recordings from 23 differentviolinists and using three movements: Mov.2 of Par-tita 1, Mov.6 of Partita 1, and Mov.5 of Partita 3.Each experiment consisted in learning trend modelswith one movement and then testing them with an-other movement. Figure 1 reports the results achievedin the experiments. Mov.2 versus Mov.6 experimentsdemonstrate the performance of the system by usingtwo movements from the same piece. Mov.6 versusMov.5 shows the performance of the system by usingtwo movements from different pieces.
In experiments using movements from the same piece,the correct performer was majority identified in thefirst half of the list, while in movements from differentpieces, the most difficult scenario, the 90% of identi-fication accuracy is overcame at position 15. We canalso observe that a 50% of success is achieved usingthe five first candidates in any case (doubling the 22%of a random classifier).
These results show that the model is capable of learn-ing performance patterns that are useful for distin-guishing performers. The results are promising, espe-
Figure 1. Accumulated success rate
cially comparing with a random classification wherethe success rate is clearly outperformed.
We plan to increase the number of descriptors and toexperiment with the rest of movements.
References
Camacho, A. (2007). Swipe: A sawtooth waveforminspired pitch estimator for speech and music. Doc-toral dissertation, University of Florida, USA.
Grachten, M., Arcos, J. L., & Lopez de Mantaras,R. (2005). Melody retrieval using the implica-tion/realization model. MIREX 2005.
Narmour, E. (1992). The analysis and cognitionof melodic complexity: The implication realizationmodel. Chicago, IL: Univ. Chicago Press.
Ramirez, R., Maestre, E., Pertusa, A., Gomez, E.,& Serra, X. (2007). Performance-based interpreteridentification in saxophone audio recordings. IEEETrans. on Circuits and Systems for Video Technol-ogy, 17, 356–364.
Saunders, C., Hardoon, D., Shawe-Taylor, J., & Wid-mer, G. (2008). Using string kernels to identify fa-mous performers from their playing style. IntelligentData Analysis, 12.
Stamatatos, E., & Widmer, G. (2005). Automaticidentification of music performers with learning en-sembles. Artif. Intell., 165, 37–56.

The Potential of Reinforcement Learning for Live Musical Agents
Keywords: interactive musical agents, reinforcement learning, computer music
Nick Collins [email protected]
Department of Informatics, University of Sussex, Falmer, Brighton, BN1 9QJ, UK
Abstract
Reinforcement learning has great potentialapplicability in computer music, particularlyfor interactive scenarios and the productionof effective control policies for systems. Thispaper considers in particular the case of inter-active music systems, where a software agentcan be trained online during a rehearsal ses-sion with a musician. A small-scale system isdescribed which uses the Sarsa(λ) algorithmto update state-action values to determine apolicy for output behaviours over a modestfeature space. It is hoped that issues aris-ing can be discussed fruitfully in a workshopcontext.
1. Introduction
One holy grail of computer music is the creation of alive musical agent whose behaviours are fully commen-surate with human music making, but whose architec-ture is not of flesh and blood (Rowe, 2001; Collins,2007). Whilst many projects have been undertaken,most have sought out the stimulating but inhumanproperties of certain algorithms for their own sake, orhave otherwise failed to live up to stricter definitions ofautonomous agency (Collins, 2006). The most promis-ing research to date is probably that which utilisesmachine learning techniques (Thom, 2003; Hamanakaet al., 2003; Assayag et al., 2006). This paper consid-ers the potential in particular of reinforcement learning(RL) (Sutton & Barto, 1998), as suitably equipped forthe situation of an agent exploring a musical environ-ment in realtime. Whilst the research presented hereis hardly conclusive, it may stimulate consideration ofthe potential benefits and pitfalls of RL approaches.
In prior work, Franklin and Manfredi (Franklin &Manfredi, 2002) studied actor-critic reinforcementlearning in a jazz improvisation context, generatingnotes and rating actions with respect to a basic hard-coded jazz music theory. RL has also been exploredin the OMax research project at IRCAM (http://
recherche.ircam.fr/equipes/repmus/OMax/). Inthe closing stages of a paper, Assayag et al. (2006)weight links in the Factor Oracle algorithm using dis-crete state-action RL; the reward signal in online inter-action is heightened performer attention to particularmaterials. An offline mode feeds back the system’sgenerated material to itself with negative reinforce-ment to increase variety in productions.
To effect learning in RL, a reward signal is necessaryto clarify the success of any action choice, given thestate. Various RL algorithms exist; the Sarsa(λ) vari-ant utilised herein allows the back-propagation of re-ward values along the set of recent state-action pairswith falloff of influence controlled by λ. Salient no-tions of reward for interactive music systems mightinclude quality of anticipation, influence on other par-ties (perhaps in take-up of material), and direct feed-back from participants or observers on their experi-ence. Human or objective fitness functions can alsobe used, analogously to interactive genetic algorithm’shuman assessment bottleneck as against programmedcriteria. Human feedback is hard to solicit, however;whilst physiological sensors such as GSR or EEG mayprovide continuous measures of emotional state, theirtrustworthiness remains to be proven in future inves-tigation. Whilst in other recent work I have exploredsignals based on ‘prediction’ ability and a degree of‘consequence’, this article considers direct user entryof quality ratings, despite potential concerns on thistask being a distractor from playing.
2. A test case for online tuition usingSarsa(λ)
Whilst experiments with rather more complicatedstate-action spaces and alternative reward signals havebeen carried out with Improvagent1, a simpler studyis presented here in order to provide a stimulus for dis-cussion. In this symbolic (MIDI) system, a user playsthe keyboard, and various features are abstractedwithin a time window of three seconds modelling the
1Paper to be presented at ICMC 2008

Reinforcement Learning for Music
perceptual present; the state is updated once per sec-ond. This external data is the current environmentstate to which the system must respond with an ac-tion. To keep the setting manageable, three featuresare extracted (log density, pitch variance and log latestevent time) and five bands allowed to partition theirvalues. Five behaviours are defined (0=silence, 1-4 aresmall imitative/processing algorithms exploiting col-lected note events from the current window). Thestate-action space thus has 625 (54) values to deter-mine for a performance policy. The performer entersrewards at any time on the computer keyboard, usingone key for positive reward and one for negative re-ward, reminiscent of Al Biles’ online IGA for GenJam.
Testing the system revealed how closely the coverageof states depended on fine representational decisions;for instance, the values particular features take on canbe decidedly non-uniform. Even after scaling adjust-ments, only 20% of states were touched in a typicalten minute interaction session. In Sarsa(λ) training,a ten minute session would give only 600 cases; anoffline process of re-running these cases in internal re-hearsal can be used to refine estimates to speed upconvergence. Without higher level musical goals andextensive long-term training, it was hard to tell howlong-term interaction quality was affected; but it waspossible to stamp out certain aberrant behaviours, andencourage favoured modes, by feeding back negativeand positive reward.
3. Discussion
Reinforcement learning experts have debunked somecommon myths concerning RL schemes, such asthe slowness of training, the divergence underfunction approximation and that a strict MDPis required (http://neuromancer.eecs.umich.edu/cgi-bin/twiki/view/Main/MythsofRL). It must beadmitted, however, that human performers can be wil-fully non-deterministic, taking a different choice giventhe same situation; it is hoped that the statistics oftheir own policies can be tractably modelled. Whilst asnoted by Belinda Thom (Thom, 2003) any given mu-sical interaction may offer an extreme case of sparsedata, the extensive practice regimes of thousands ofhours carried out by expert human musicians may beoffered as a counter-example to illustrate the amountof training data potentially required (Deliege & Slo-boda, 1996). A pertinent question is how best to scaleup small systems into larger systems worthy of theinvestment of such time, and how to train in non-interactive situations (from MIDI file data, say) inreadiness for real interaction.
The choice of representation is critical as ever, and itmay be productive to consider more closely how hu-man musicians manage to encode and recall musicaldata, that is, to employ psychological data on humanlearning and memory. Chunking of data (storage asmanageable chunks of around three notes at a timewith context in a memory record) may be an ecologi-cally valid tactic for keeping dimensionality low.
4. Conclusions
Reinforcement learning has potential for learning ininteractive music systems, but with many outstandingissues concerning nature (bootstrapping) and nurture(learning in an environment) and associated represen-tations and modelling. There are also questions ofevaluation for the systems themselves, which can beapproached on a number of levels, from participant ex-perience, to audience and critical response, alongsidemore objective technical criteria.
References
Assayag, G., Bloch, G., Chemillier, M., Cont, A., & Dub-nov, S. (2006). OMax brothers: a dynamic topology ofagents for improvization learning. AMCMM ’06: Pro-ceedings of the 1st ACM workshop on audio and musiccomputing multimedia (pp. 125–132).
Collins, N. (2006). Towards autonomous agents for livecomputer music: Realtime machine listening and inter-active music systems. Doctoral dissertation, Universityof Cambridge.
Collins, N. (2007). Musical robots and listening machines.In N. Collins and J. d’Escrivan (Eds.), Cambridge com-panion to electronic music, 171–84. Cambridge: Cam-bridge University Press.
Deliege, I., & Sloboda, J. (1996). Musical beginnings: Ori-gins and development of musical competence. New York:Oxford University Press,.
Franklin, J. A., & Manfredi, V. U. (2002). Nonlinear creditassignment for musical sequences. Second internationalworkshop on Intelligent systems design and application(pp. 245–250).
Hamanaka, M., Goto, M., Asoh, H., & Otsu, N. (2003).A learning-based jam session system that imitates aplayer’s personality model. IJCAI: International JointConference on Artificial Intelligence (pp. 51–58).
Rowe, R. (2001). Machine musicianship. Cambs, MA: MITPress.
Sutton, R., & Barto, A. (1998). Reinforcement learning:An introduction. Cambridge, MA: MIT Press.
Thom, B. (2003). Interactive improvisational music com-panionship: A user-modeling approach. User Modelingand User-Adapted Interaction Journal, 13, 133–77.

Modeling Celtic Violin Expressive Performance
Rafael Ramirez, Alfoso Perez, Stefan Kersten {rafael,aperez,skersten}@iua.upf.edu
Universitat Pompeu Fabra, Ocata 1, 08003 Barcelona, Spain
David Rizo, Placido Roman, Jose M. Inesta {drizo,proman,inesta}@dlsi.ua.es
Departamento de Lenguajes y Sistemas informticos, Universidad de Alicante, Spain
Abstract
Professional musicians intuitively manipulatesound properties such as pitch, timing, am-plitude and timbre in order to produce ex-pressive performances of particular pieces.However, there is little explicit informationabout how and in which musical contextsthis manipulation occurs. In this paper wedescribe an inductive logic programming ap-proach to modeling the knowledge applied bya violinist when performing a celtic piece inorder to produce an expressive performance.
1. Introduction
In this paper we describe an inductive logic program-ming approach to investigate how skilled musiciansexpress and communicate their view of the musicaland emotional content of musical pieces and how touse this information in order to generate expressiveperformances. Instead of manually modelling expres-sive performance and testing the model on real musi-cal data, we use sound analysis techniques based onspectral models [4] for extracting high-level symbolicfeatures from the recordings, and let a computer useinductive logic programming techniques to automati-cally discover performance patterns from real perfor-mances. We study deviations of parameters such astiming and amplitude in the context of celtic violinmusic.By applying inductive logic programming techniqueswe are able to express the performance regularitiesas first order logic rules, and introduce backgroundknowledge in the learning process. The increased ex-pressiveness of first order logic not only provides amore elegant and efficient specification of the musi-cal context of a note, but it provides a more accuratepredictive model [3] The possibilty of involving back-ground knowledge in the learning process is of specialinterest in musical applications where often there ismusical background knowledge available.
2. Expressive performance modeling
Training data. In this work we are focused onCeltic jigs, fast tunes but slower that reels, that usu-ally consist of eighth notes in a ternary time signa-ture, with strong accents at each beat. The train-ing data used in our experimental investigations aremonophonic recordings of nine Celtic jigs performedby a professional violinist. Apart from the tempo (theyplayed following a metronome), the musician was notgiven any particular instructions on how to performthe pieces.
Musical Analysis. It is widely recognized that ex-pressive performance is a multi-level phenomenon andthat humans perform music considering a number ofabstract musical structures. In order to provide an ab-stract structure to our performance data, we decidedto use Narmours theory [2] and tonal analysis [5] toanalyse the performances.
Note descriptors. We characterize each performednote by a set of features representing both proper-ties of the note itself and aspects of the musical con-text in which the note appears. Information aboutthe note includes note pitch and note duration, whileinformation about its melodic and harmonic contextincludes the relative pitch and duration of the neigh-boring notes (i.e. previous and following notes), classi-fication from the harmonic point of view (e.g. passingtone, neighbor tone, harmonic note), as well as theNarmour structures to which the note belongs. Thenote’s Narmour structures are computed by perform-ing the musical analysis according to Narmour’s the-ory. Thus, each performed note is contextually char-acterized by the tuple
(Pitch, Dur, MetrStr, PrevPitch, PrevDur, NextPitch,NextDur, Nar1, Nar2, Nar3)
Learning Algorithm. We used Tildes top-down de-cision tree induction algorithm [1]. Tilde can be con-
Modeling Celtic Violin Expressive Performance
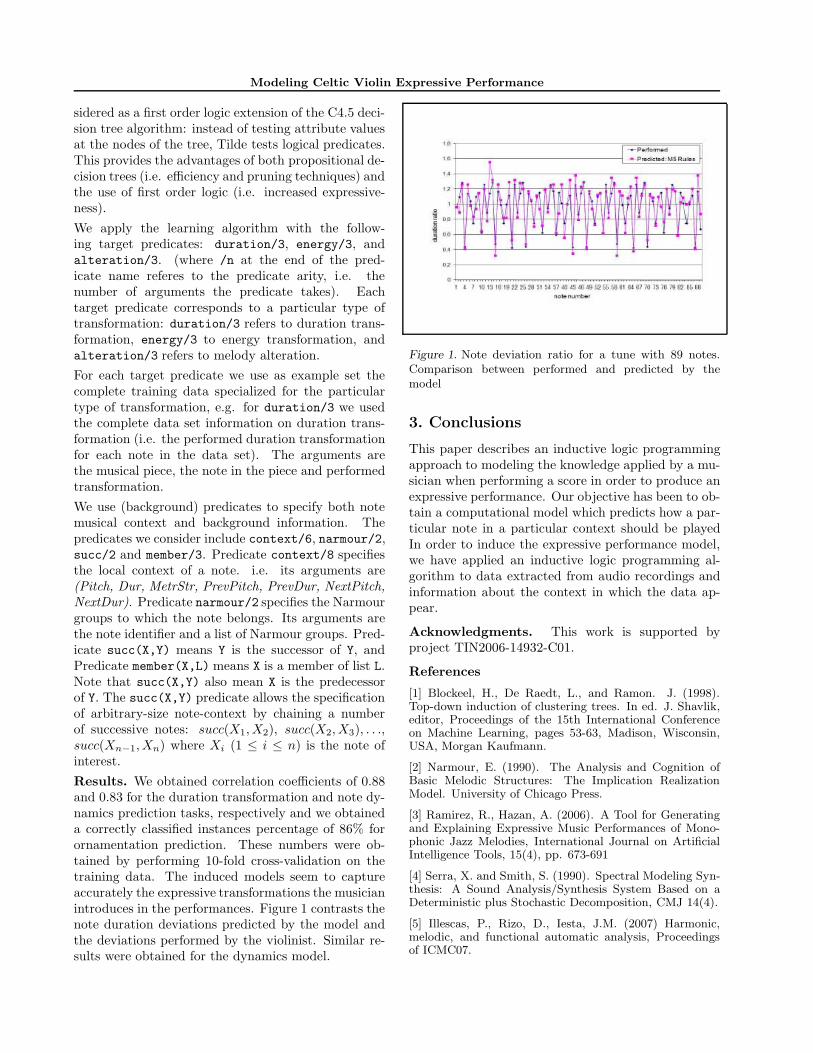
sidered as a first order logic extension of the C4.5 deci-sion tree algorithm: instead of testing attribute valuesat the nodes of the tree, Tilde tests logical predicates.This provides the advantages of both propositional de-cision trees (i.e. efficiency and pruning techniques) andthe use of first order logic (i.e. increased expressive-ness).We apply the learning algorithm with the follow-ing target predicates: duration/3, energy/3, andalteration/3. (where /n at the end of the pred-icate name referes to the predicate arity, i.e. thenumber of arguments the predicate takes). Eachtarget predicate corresponds to a particular type oftransformation: duration/3 refers to duration trans-formation, energy/3 to energy transformation, andalteration/3 refers to melody alteration.For each target predicate we use as example set thecomplete training data specialized for the particulartype of transformation, e.g. for duration/3 we usedthe complete data set information on duration trans-formation (i.e. the performed duration transformationfor each note in the data set). The arguments arethe musical piece, the note in the piece and performedtransformation.We use (background) predicates to specify both notemusical context and background information. Thepredicates we consider include context/6, narmour/2,succ/2 and member/3. Predicate context/8 specifiesthe local context of a note. i.e. its arguments are(Pitch, Dur, MetrStr, PrevPitch, PrevDur, NextPitch,NextDur). Predicate narmour/2 specifies the Narmourgroups to which the note belongs. Its arguments arethe note identifier and a list of Narmour groups. Pred-icate succ(X,Y) means Y is the successor of Y, andPredicate member(X,L) means X is a member of list L.Note that succ(X,Y) also mean X is the predecessorof Y. The succ(X,Y) predicate allows the specificationof arbitrary-size note-context by chaining a numberof successive notes: succ(X1, X2), succ(X2, X3), . . .,succ(Xn−1, Xn) where Xi (1 ≤ i ≤ n) is the note ofinterest.Results. We obtained correlation coefficients of 0.88and 0.83 for the duration transformation and note dy-namics prediction tasks, respectively and we obtaineda correctly classified instances percentage of 86% forornamentation prediction. These numbers were ob-tained by performing 10-fold cross-validation on thetraining data. The induced models seem to captureaccurately the expressive transformations the musicianintroduces in the performances. Figure 1 contrasts thenote duration deviations predicted by the model andthe deviations performed by the violinist. Similar re-sults were obtained for the dynamics model.
Figure 1. Note deviation ratio for a tune with 89 notes.Comparison between performed and predicted by themodel
3. Conclusions
This paper describes an inductive logic programmingapproach to modeling the knowledge applied by a mu-sician when performing a score in order to produce anexpressive performance. Our objective has been to ob-tain a computational model which predicts how a par-ticular note in a particular context should be playedIn order to induce the expressive performance model,we have applied an inductive logic programming al-gorithm to data extracted from audio recordings andinformation about the context in which the data ap-pear.
Acknowledgments. This work is supported byproject TIN2006-14932-C01.
References
[1] Blockeel, H., De Raedt, L., and Ramon. J. (1998).Top-down induction of clustering trees. In ed. J. Shavlik,editor, Proceedings of the 15th International Conferenceon Machine Learning, pages 53-63, Madison, Wisconsin,USA, Morgan Kaufmann.
[2] Narmour, E. (1990). The Analysis and Cognition ofBasic Melodic Structures: The Implication RealizationModel. University of Chicago Press.
[3] Ramirez, R., Hazan, A. (2006). A Tool for Generatingand Explaining Expressive Music Performances of Mono-phonic Jazz Melodies, International Journal on ArtificialIntelligence Tools, 15(4), pp. 673-691
[4] Serra, X. and Smith, S. (1990). Spectral Modeling Syn-thesis: A Sound Analysis/Synthesis System Based on aDeterministic plus Stochastic Decomposition, CMJ 14(4).
[5] Illescas, P., Rizo, D., Iesta, J.M. (2007) Harmonic,melodic, and functional automatic analysis, Proceedingsof ICMC07.

Identifying Cover Songs Using Normalized Compression Distance
Teppo E. Ahonen, Kjell Lemstrom {teahonen,klemstro}@cs.helsinki.fi
Department of Computer Science, University of Helsinki
Abstract
Normalized Compression Distance (NCD)is a distance metric that approximatesKolmogorov-complexity-based informationdistance by using a standard data compres-sion algorithm. It has been successfullyused for clustering symbolic music data.In this paper we use NCD for identifyingcover versions by calculating the similaritybetween chord sequences estimated fromaudio files.
1. Introduction
A cover song is an alternative rendition of a previouslyrecorded song. In popular music a cover song is usuallyvery different from the original song: the cover versionmay vary, for instance, in tempo, key, arrangement orthe language of the vocals.
Thus, identifying cover songs automatically is a ratherdifficult task. The features that are used for the iden-tification must be robust: the so-called low-level audiosignal features do not remain unchanged between theoriginal and the cover version. The cover song identi-fication is done by comparing the mid-level represen-tations of the songs. Usually this means estimatingthe chord sequences from the songs and then calculat-ing the distance between the sequences using methodssuch as edit distance or dynamic time warping. Auto-matic cover song identification is important not onlybecause it can be used for managing large collections ofdigital audio, but also because identifying cover songsyields important information on how musical similar-ity can be measured and modelled.
Normalized Compression Distance, or NCD, is a dis-tance metric that is based on Kolmogorov complexity.NCD is universal and requires no background informa-tion of the subject domain. We propose a method thatuses NCD to distinguish the cover songs by calculatingthe similarity between chord sequences.
2. Chord estimation
Estimating the chord sequences in audio data is a well-researched area. The common process for chord esti-mating consists of two steps: pre-processing the audiointo a feature vector representation and approximat-ing the most likely chord sequence from the vectorsby a Hidden Markov Model (Papadopoulos & Peeters,2007).
First, the audio data is turned into a chromagram,twelve-dimensional vectors representing the intensityof the twelve pitch classes in a given time slice. Thereare several ways to do this: a straightforward methodis the use of the constant Q transform (Brown, 1991).
Then, the chords are estimated from the chromavectors using a Hidden Markov Model. The statesare the chords, and the observations are the chromavectors. The initial model parameters can be cho-sen using different modellings that vary from musi-cal knowledge to cognitive experiments (Papadopou-los & Peeters, 2007). Finally, the model is trainedusing the expectation-maximization (EM) algorithmand the most likely chord sequence is estimated usingthe Viterbi algorithm.
3. Brief introduction to NCD
The Kolmogorov complexity for a string x is the lengthof the shortest binary program that produces x asoutput, denoted K(x) (Chen et al., 2004). The con-
ditional Kolmogorov complexity for strings x and y,denoted K(x|y), is the length of the shortest binaryprogram that produces output x given input y. Basedon this, the information distance E(x, y) is the lengthof the shortest binary program that outputs x giveninput y and vice versa. Up to an additive logarithmicterm, E(x, y) = max{K(x|y),K(y|x)} (Chen et al.,2004).
Information distance is an absolute distance: it doesnot consider the lengths of the input strings. The simi-larity metric, however, should be relative. We normal-ize the information distance to the range [0, 1]. Nor-

Identifying Cover Songs Using NCD
malized Information Distance (NID) is calculated asfollows (Chen et al., 2004):
NID(x, y) =max{K(x|y),K(y|x)}
max{K(x),K(y)}. (1)
However, Kolmogorov complexity is incomputable inthe Turing sense (Cilibrasi & Vitanyi, 2005). Al-though NID cannot be computed, we can approximateKolmogorov complexity by using any standard loss-less data compression algorithm (Cilibrasi & Vitanyi,2005), such as gzip, bzip2 or PPMZ.
Denote C(x) as the length of the string x when com-pressed using compression algorithm C, and C(y|x) =C(xy)−C(x) as the number of bits in the compressedxy compared to the compressed x.
Using a standard compressor algorithm C to approx-imate Kolmogorov complexity we can now approxi-mate the NID in equation (1). This is called Normal-ized Compression Distance and is calculated as follows(Cilibrasi & Vitanyi, 2005):
NCD(x, y) =C(xy) − min{C(x), C(y)}
max{C(x), C(y)}.
4. Results and conclusions
We implemented an experimental system based on theconcepts introduced here. The system was mostlycoded in MATLAB using various MIR toolkits, apartfrom the NCD part that uses the CompLearn toolkit1.The chord sequences are estimated from the constantQ transformed vectors using a 24-state HMM, with ini-tial parameters chosen according to the musical knowl-edge of chord changes as proposed by Bello and Pick-ens (Bello & Pickens, 2005). Chord sequences are writ-ten into text files using a brief format that summarisesthe chord change into three characters: the first twodenote the semitone difference between the root notesof the chords, and the third tells whether there is achange between a major and a minor chord. For exam-ple, the chord progression F G Gm A would be writtenas +2N +2C +2C.
The experiments were carried out using the covers80
dataset2, which is a 160-song collection of 80 orig-inal songs and their cover versions. The distanceswere calculated using two standard compression algo-rithms: the gzip and bzip2. For each 80 cover songqueries an answer set of three most similiar songs wasreturned. The performance was measured based onthese sets. We calculated the number of exact matches
1http://www.complearn.org2http://labrosa.ee.columbia.edu/projects/coversongs/covers80/
(the queries with original song having the smallestdistance), the top-3 recognition rate (the number ofqueries where the original song was found in the an-swer set) and the mean of average precisions, MAP(the mean of query precisions emphasizing the rankof the match in the answer set). Results are listed intable 1.
Table 1. Results of the NCD Cover Song Identification test.
Measure Value range gzip bzip2
Match [0-80] 9 10Top-3 [0-80] 17 20MAP [0-1] 0.156 0.175
The results are not very satisfying, but they do im-ply that the NCD approach has potential for coversong identification as the NCD is able to identify thecover songs based on the roughly estimated chord se-quences. Also, the songs discovered were mostly thesame with both compressors, thus implying that NCDworks regardless of the selected compressor, althoughusing bzip2 seems to yield slightly better results. Cur-rently, the work is focused on improving the chord es-timation and searching for a more suitable notation torepresent the chord sequences.
References
Bello, J. P., & Pickens, J. (2005). A robust mid-levelrepresentation for harmonic content in music sig-nals. Proc. ISMIR’05 (pp. 304 – 311). London, UK:Queen Mary, University of London.
Brown, J. C. (1991). Calculation of a constant Q spec-tral transform. Journal of the Acoustical Society of
America, 89, 425 – 434.
Chen, X., Li, M., Li, X., Ma, B., & Vitanyi, P. M. B.(2004). The similarity metric. IEEE Transactions
on Information Theory, 50, 3250 – 3264.
Cilibrasi, R., & Vitanyi, P. M. B. (2005). Clusteringby compression. IEEE Transactions on Information
Theory, 51, 1523 – 1545.
Papadopoulos, H., & Peeters, G. (2007). Large-scale study of chord estimation algorithms based onchroma representation and HMM. Proc. CBMI ’07
(pp. 53 – 60). Paris, France: IRCAM.

Towards Logic-based Representations of Musical Harmony forClassification, Retrieval and Knowledge Discovery
Amelie Anglade [email protected] Dixon [email protected]
Centre for Digital Music, Queen Mary University of London, Mile End Road, London E1 4NS, UK
AbstractWe present a logic-based framework using arelational description of musical data and log-ical inference for automatic characterisationof music. It is intended to be an alternativeto the bag-of-frames approach for classifica-tion tasks but is also suitable for retrievaland musical knowledge discovery. We presentthe first results obtained with such a systemusing Inductive Logic Programming as infer-ence method to characterise the Beatles andReal Book harmony. We conclude with a dis-cussion of the knowledge representation prob-lems we faced during these first tests.
1. Introduction
Most of the automatic music classification systems(performing e.g. genre classification) for audio data arebased on the so-called “bag-of-frames” approach. Inthis approach, feature vectors (typically spectral fea-tures such as MFCC) are computed over short frames.Then a classifier computes the global distribution oraverage values of these vectors over the whole piece orpassage for each class. However this statistical methodpresents several limitations. For instance it has beenshown that contrary to the bag-of-frames assumptionthe contribution of a musical event to the perceptualsimilarity is not proportional to its statistical impor-tance (rare musical events can even be the most in-formative ones) (Aucouturier et al., 2007). Moreoverthe bag-of-frames approach ignores temporal organisa-tion of the acoustic signal. However when comparingpieces from similar genres or passages of a same song itis crucial in the retrieval process to use sequences andnot only average values or global statistical distribu-tions of features over a whole passage or piece (Casey& Slaney, 2006).
We believe a logic-based representation of the musicalevents together with logical inference such as InductiveLogic Programming (ILP) of higher level phenomenawould overcome these limitations. Indeed temporal re-
Extraction of musical events
Symbolic or Audio Features Automatic
inference of rules applying on the database
Inference system
Relational description of the musical events
Logicaldescriptionof musicalconcepts
Database of symbolicor audioexamples
Figure 1. Logic-based framework for musical rule induction
lations between musical events are easily expressible ina relational framework. Moreover logical inference ofrules allows to take into account all events, even thosewhich are rare. Another advantage of using logicalrules is that they are human-readable.
Additionally logical inference has already been suc-cessfully used in several music-related projects, forinstance to induce rules about popular music har-monisation (Ramirez, 2003), counterpoint (Morales &Morales, 1995) and expressive performance (Widmer,2003).
2. The Reasoning Framework
Taking the example of these promising applications oflogic to music we intend to build a logic-based reason-ing system able to characterize songs for classificationor similarity evaluation purposes. An illustration ofthis system is given in Figure 1. It takes a databaseof examples to characterise. Notice that these exam-ples can either be audio signals or symbolic examples.These examples are then analysed by a musical eventextractor using either symbolic or audio features. Fi-nally the relational description of the examples result-ing from this analysis is given to an inference systemwhich derives musical rules that are true for the exam-ples. An example of such an automatically derived rulefor the blues genre would be: 12 bar structure(X) ∧blues scale(X) ∧ syncopation(X)⇒ blues(X)
We imagine three kinds of applications for this system:
1. Classification and retrieval of pieces similarto a given set of examples, for instance for recom-mender systems.

Towards Logic-based Representations of Musical Harmony
2. Musical knowledge discovery: some of the de-rived rules might describe new interesting musicalphenomena.
3. Query in musical databases: finding musicthat matches a pattern/description expressed bythe user in the form of a logic formula (either de-fined by hand or a rule previously derived by thesystem) so without any audio or score example.
3. First Results
We ran a first set of experiments using the ILP sys-tem Aleph (Srinivasan, 2003) which is based on In-verse Entailment. Our objective was to characterizethe harmony of the 180 songs featured on the Beatles’studio albums (containing a total of 14,132 chords)and of 244 jazz standards from the Real Book (24,409chords). More precisely we focused on characteris-ing chord sequences of length 4 in these corpora. Toavoid the event extraction step we analysed manuallyannotated chord data1 containing information aboutthe root, bass note and component intervals (relativeto the root) of the chords. We pre-processed thesedata to obtain high-level information such as chordcategory (e.g. major, minor, suspended), degree (e.g.tonic, dominant) and intervals between chords, beforepassing them to an ILP system which extracted theharmony rules underlying them. It generated 3667harmony rules characterising and differentiating theReal Book songs and the Beatles music. Examples oflearned rules are given in Table 1. Encouragingly someof these rules cover well-known jazz or pop harmonicpatterns such as ii-V-I-IV and the “turnaround” pat-tern I-VI-II-V (for the Real Book), and the I-IV-I-Vpattern (for the Beatles). It was also possible to iden-tify patterns specific to the Beatles such as the exten-sive use of major chords (the predominant maj-maj-maj-maj pattern) and the cyclic patterns (e.g. I-IV-V-I-IV...) characterising their early compositions. Moredetails on these experiments can be found in (Anglade& Dixon, 2008).
4. Discussion
Even though these first results are encouraging weidentified some knowledge representation problemsarising when using ILP as inference technique. InILP both the concept and the vocabulary to describeit (or background knowledge) needs to be defined inadvance. Thus, two different vocabularies result indifferent descriptions of the concept. The process ofconcept characterisation is interactive: to end up withan interesting theory we might need to manually refine
1RDF descriptions of the Real Book chords (available onhttp://chordtranscriptions.net/) and of Harte’s transcrip-tion of the Beatles (available on request)
the vocabulary several times. For instance for the Bea-tles in our final attempt we used the concept “chordsequence (of length 4) in the Beatles” (chord seq/4)and asked the system to describe it in terms of“chord category sequence” (category seq/8), “rootinterval sequence” (rootInterval seq/7), etc. Butour earlier attempts at using only low level concepts(e.g. using independent descriptions of each chord,linked only by a “predecessor” predicate) failed toprovide meaningful descriptions of the target concept.However it seems that as we refine the vocabulary weinevitably reduce the problem to a pattern matchingtask and not to a pattern discovery task as weintend to, allowing us to validate or refute hypothesesabout the concept but not to make any really novel(knowledge) discoveries.
[Rule 16][Pos cover=7.86%]: chord seq(A,B,C,D):-rootInterval seq(A,B,C,D,[perf,4th],[perf,4th],[perf,4th]).[Rule 25][Pos cover=4.09%]: chord seq(A,B,C,D):-category seq(A,B,C,D,min,dom,min,dom).[Rule 57][Pos cover=2.01%]: chord seq(A,B,C,D):-bassInterval seq(A,B,C,D,[maj,7th],[perf,4th],[perf,4th]).
Table 1. Examples of rules learned on the Real Book data
5. Acknowledgments
This work is part of the OMRAS2 project funded byEPSRC grant EP/E017614/1.
References
Anglade, A., & Dixon, S. (2008). Characterisation ofharmony with Inductive Logic Programming. Underreview for ISMIR 2008.
Aucouturier, J.-J., Defreville, B., & Pachet, F. (2007).The bag-of-frames approach to audio pattern recog-nition: A sufficient model for urban soundscapes butnot for polyphonic music. JASA, 122, 881–91.
Casey, M., & Slaney, M. (2006). The importance ofsequences in musical similarity. Proc. of ICASSP2006. Toulouse, France.
Morales, E., & Morales, R. (1995). Learning musicalrules. Proc. of the IJCAI-95 Int. Workshop on Ar-tificial Intelligence and Music. Montreal, Canada.
Ramirez, R. (2003). Inducing musical rules with ILP.Proceedings of ICLP2003. Springer-Verlag (LNCS).
Srinivasan, A. (2003). The Aleph Manual (version 4).
Widmer, G. (2003). Discovering simple rules in com-plex data: A meta-learning algorithm and some sur-prising musical discoveries. AI, 146, 129–148.



An Ensemble-Based Approach forAutomatic Hierarchical Music Genre Classification
Carlos N. Silla Jr. [email protected]
Computing Laboratory, University of Kent, Canterbury, CT2 7NF, UK
Alex A. Freitas [email protected]
Computing Laboratory, University of Kent, Canterbury, CT2 7NF, UK
Abstract
In this paper we propose and evaluate anensemble-based approach for the task of au-tomatic hierarchical music genre classifica-tion. The ensemble method consists of em-ploying a hierarchical top-down strategy us-ing information from three different parts ofthe music signal. The experiments were per-formed on the Latin music database that con-tains 3,160 music pieces from 10 Latin genresorganized in a two-level hierarchy. The pro-posed method has show improvements in theclassification of the first level of the hierarchy.
1. Introduction
The task of music genre classification plays an impor-tant part in any Music Information Retrieval (MIR)System. Studies concerning user behavior of MIR sys-tems show that the musical genre is the second mostused information for retrieval of music pieces (Downie& Cunningham, 2002). The task of automatically as-signing a music genre based on the music content (i.e.the music signal), has been motivated by the work of(Tzanetakis & Cook, 2002). Since then, the task of au-tomatic music genre classification has received a grow-ing interest by the MIR research community but rela-tively less work has considered the task of automatichierarchical music genre classification.
According to (Sun et al., 2003; Freitas & de Carvalho,2007) there are four possible approaches for hierarchi-cal classification problems. In this work we use themulti-class top-down (also known as local-learning)approach that consists of creating a classifier for everyparent node of the class tree, so that each classifierhas to discriminate among the sub-classes associatedwith its child nodes. Therefore a classifier is trainedfor each node in the hierarchy that is not a leaf node.
After a tree of classifiers has been built in the trainingphase, during the testing phase each new test exam-ple (unseen during training) is classified in a top-downfashion as follows. First, the example is assigned afirst-level (most generic) class by the classifier ensem-ble at the root node (at class level 0). Then the exam-ple is sent to the root node’s child node (at class level1) whose class was predicted by the root’s classifier en-semble. Then the example is assigned a second-level(more specific) class by that classifier ensemble at level1. If there were more than two class levels this top-down process would be recursively repeated until a leafclass was assigned to the example.
2. Automatic HierarchicalClassification of Music Genres
The music genre classification system proposed in thiswork is composed of two main phases: feature extrac-tion and ensemble-based top-down multi-class classi-fication. For the baseline approach features are ex-tracted from the middle of the audio signal consider-ing a 30-second segment. For the extraction of featuresfrom the music segments, the MARSYAS1 frameworkwas employed. The MARSYAS framework implementsthe original feature set proposed by (Tzanetakis &Cook, 2002) that consists of features related to thetimbral texture, to the beat and to the pitch. In total30 features are calculated for each song.
To perform the ensemble-based top-down multi-classclassification we extract features from three differentparts of the song (beginning, middle and end) andcombine them using majority voting (VOTE-TD) orthe Max Rule (MAX-TD); In VOTE-TD the final classlabel is given by the majority voting of the class out-puts. While, in MAX-TD the final class label is givenby the class with the lowest distance of all classifiers.
1Available at: http://marsyas.sourceforge.net

Submission and Formatting Instructions for ICML-2008
Figure 1. Latin Music Database Class Hierarchy
The main difference from our previous work (Silla Jr.et al., 2007a) is that in this work we combine ourpreviously-proposed ensemble method for flat classi-fication with the hierarchical top-down approach. I.e.at each non-leaf classifier there is an ensemble basedclassifier.
3. Experiments
The main objective of our experiment was to evalu-ate the performance of the top-down ensemble-basedmethod for the task of automatic hierarchical musicgenre classification. For this purpose we have used theLatin Music Database (Silla Jr. et al., 2007b) whichcontains music samples from ten different Latin gen-res. We have selected 300 samples from each genreand performed 10-fold cross-validation. The hierarchyused in the experiments is show in Figure 1. The un-derlying base classifier used was the k-NN (k = 3) andfor the standard Top Down (TD) approach, the middlesegment was used.
Table 1 presents the predictive accuracy resultsachieved by the different methods. At the first levelof the class hierarchy both ensemble methods achievedhigher results than the standard top down approach.At the second level of the hierarchy the ensemble didnot outperform the standard approach. This leadsto the conclusion that at the first level the ensemblewas successful in improving the classification of gen-res other than Brazilian, and therefore it has not im-proved the accuracy of the second level. This is oneof the drawbacks of the Top-Down approach where er-rors made at the higher levels of the hierarchy will bepropagated through the classification process.
4. Concluding Remarks
In this work we presented an ensemble–based approachfor automatic hierarchical music genre classificationusing a multi-class top-down approach. The experi-ments of the presented method were compared againsta standard hierarchical multi-class top-down classifier.The results suggest that the proposed method achievedbetter accuracy on the first level of the hierarchy and
Table 1. Predictive accuracy at each level of the hierarchy.
Hierarchy TD MAX-TD VOTE-TD
Level 1 75.83± 2.7 80.86± 1.82 79.49± 1.93Level 2 42.19± 4.0 41.39± 3.11 40.12± 4.46
similar results to the second level.
As future work we pretend to join to the Latin Mu-sic database with other existing databases to havea richer hierarchy, in which we believe the proposedmethod would perform better than the standard ap-proach. Another possibility to improve the proposedmethod is, instead of extracting features from differ-ent parts of the music, extracting different features setsand combining them.
Acknowledgment
The first author is financially supported by the CAPESBrazilian Agency, process number 4871-06-5.
References
Downie, J. S., & Cunningham, S. J. (2002). Toward atheory of music information retrieval queries: Sys-tem design implications. Proc. Third Int. Conf. onMusic Inform ation Retrieval (pp. 299–300).
Freitas, A. A., & de Carvalho, A. C. P. L. F. (2007).Research and trends in data mining technologiesand applications, chapter A Tutorial on Hierarchi-cal Classification with Applications in Bioinformat-ics, 175–208. Idea Group.
Silla Jr., C. N., Kaestner, C. A. A., & Koerich, A. L.(2007a). Automatic music genre classification usingensemble of classifiers. IEEE International Confer-ence on Systems, Man, and Cybernetics (pp. 1687–1692).
Silla Jr., C. N., Kaestner, C. A. A., & Koerich, A. L.(2007b). The latin music database: Uma base de da-dos para a classificacao automatica de generos musi-cais. 11th Brazilian Symposium on Computer Music(pp. 167–174).
Sun, A., Lim, E.-P., & Ng, W.-K. (2003). Performancemeasurement framework for hierarchical text classi-fication. Journal of the American Society for Infor-mation Science and Technology, 54, 1014–1028.
Tzanetakis, G., & Cook, P. (2002). Musical genre clas-sification of audio signals. IEEE Transactions onSpeech and Audio Processing, 10, 293–302.

Composer classification using grammatical inference
Jeroen Geertzen [email protected]
Menno van Zaanen [email protected]
ILK / Dept. of Communication & Information Sciences, Tilburg University, Tilburg, The Netherlands
Abstract
We present an approach to automatic com-poser recognition based on learning recurringpatterns in music by grammatical inference.These patterns are more flexible than, for in-stance, commonly used Markov chains. Theinduced patterns are subsequently used in aregular-expression based classifier. We showthat this approach yields promising classifi-cation results and allows investigation of in-duced composer-typical sequential structure.
1. Introduction
Where the automatic classification of music genrehas received considerable attention recently, composerclassification, being a more specific task, has not.
For classifying on genre or composer, supervised ma-chine learning is commonly used, in which an algo-rithm learns a classification model of how features arerelated to classes based on labelled training samples.In most studies the features used tend to be local, i.e.the features predominantly describe events in rathershort time intervals (e.g. tempo changes). Global fea-tures are usually statistical measures of musical pieces,such as the distributions of intervals, certain harmon-ics, tempo, etc. (e.g. in Backer et al., 2005).
When we aim to classify music by composer, we areessentially looking for recurring patterns of features inmusical data that are typical to a specific composer.In order to describe what is happening over a span oftime, several researchers have used probabilistic meth-ods, notably Markov chains. A n-th order Markovchain bases the probability for a symbol to occur onthe last n symbols. Based on the occurrence of uniqueor frequent Markov chains, a classifier can be built.However, such models do not allow the capture of morecomplex sequences.
We propose an approach to automatic composer clas-sification that is based on grammatical inference (GI).
GI is a branch of unsupervised machine learning thataims to find underlying structure of symbolic sequen-tial data. Contrary to Markov chains, the sequencesthat are learned may have variable length and may benon-contiguous.
2. Approach
Music has characteristics relating to several aspects,such as harmony (i.e. intervals), melody, and rhythm.In our approach, we decompose the music along thelatter two dimensions.1
In each of the dimensions, we look for patterns thatcharacterize the music for that particular dimension,and formulate composer classification as a similaritysearch in a 2-dimensional vector space. For the induc-tion of patterns, we use GI to obtain typical phrases orpatterns in an unsupervised manner. We subsequentlyuse these patterns as features in a supervised classifica-tion algorithm to automatically classify musical piecesby composer. This approach is depicted in Figure 1.
Figure 1. Overview of the GI component in classification.
The GI component in the system is realized byAlignment-Based Learning (ABL) (van Zaanen, 2002).ABL is a generic GI framework that has been success-fully applied in natural language processing. It inducesstructure from sequences by aligning them. Based
1There are more dimensions that could be distin-guished, but those will be included in future work.

Composer classification using grammatical inference
on interchangeable subsequences, the data is gener-alized. For instance, given the two following melodicsequences:
d c d [ e f# ] g e
d c d [ d e ] g e
the alignment learning of ABL induces the patternd c d X g e, in which X may be any substitutablepart. In a similar way, ABL is applied to sequences,each of which representing a piece for a particular di-mension.
The supervised classification algorithm determines, foreach dimension, the phrases and patterns that are typ-ical to each composer. Subsequently, these global pat-terns are applied as regular expressions to an unseenpiece. This gives for each composer a measure of struc-tural similarity with the piece. The composer with thehighest similarity is selected.
3. Data
GI approaches are inherently symbolic and we do notwant to consider stylistic aspects related to perfor-mance. Therefore, we extracted symbolic representa-tions from music in humdrum **kern format (Huron,1997). The melodic sequences encode relative pitchchanges by means of number of semitones and thedirection (upwards or downwards); the rhythmic se-quences encode relative meter changes in tempo dif-ference and direction (quicker or slower).
To look for recurring patterns of features in musicaldata that is typical to a specific composer, we compiledtwo datasets2 of composers from the same musical erawith the same type of musical piece: a baroque datasetwith preludes from Bach (42) and Chopin (24), anda classic dataset with quartet pieces from Beethoven(70), Haydn (213), and Mozart (82).
4. Experimental results
The performance of the GI based approach was com-pared to that of a 2nd order Markov model ap-proach (MM-2) and evaluated using leave-one-outcross-validation.3 The performance is measured by er-ror rate, which is calculated by dividing the number ofincorrectly classified musical pieces by the total num-ber of pieces in the test set.
The resulting scores are given in Table 1. Classifica-tion was performed both with a similarity search in a
2A specification of the datasets can be found at:http://cosmion.net/jeroen/publications/.
3Leave-one-out was used due to the small amount oftraining data available.
2-dimensional vector space (joint) and for each dimen-sion in isolation (melody, rhythm).
Table 1. Error rate for both datasets with both approaches.
Dataset Dimension ABL MM-2
baroque melody 19.8 ±0.3 29.1 ±0.4
rhythm 22.5 ±0.6 32.4 ±0.7
joint 19.9 ±0.2 29.0 ±3.6
classic melody 23.6 ±0.7 34.8 ±2.1
rhythm 28.8 ±1.2 37.2 ±5.9
joint 21.3 ±1.3 35.1 ±2.8
From the table we can conclude that for both datasets,the GI based approach results in lower error rates thanthe MM-2 approach. Furthermore, it is interestingto see that the joint model (which learns from bothmelodic and rhythmic sequences) results for the GIsystem on the classic dataset in a lower error rate thanany of the dimensions in isolation.
The discriminative sequences that are found provideample opportunity for qualitative style analysis, whichis beyond the scope of this paper. To give an idea, thefollowing melodic pattern typically occurs in Chopin’spreludes: b♭ e♭ X b♭ b♭ X b♭ X, where X matches anarbitrary number of notes.
Preliminary results in varying the level of detail ofthe sequences (e.g. relative pitch versus absolute pitchchange) indicate that there is still a lot to gain in look-ing for the optimum balance between detail in datarepresentation and data sparsity.
5. Conclusions & future work
We present a GI based approach to composer classifica-tion with promising results. It uses humanly readablepatterns automatically extracted from music. Futureresearch will address the use of other GI algorithms, afurther exploration of more elaborate and finer grainedfeature dimensions, as well as motif extraction.
References
Huron, D. (1997). Humdrum and kern: selectivefeature encoding. In E. Selfridge-Field (Ed.), Be-
yond MIDI: The handbook of musical codes, 375–401. Cambridge, MA, USA: MIT Press.
Backer, E., van Kranenburg, P. (2005). On musicalstylometry: a pattern recognition approach. Pattern
Recognition Letters, 26, 3, pp. 299–309.
van Zaanen, M. M. (2002). Bootstrapping structure
into language: Alignment-Based Learning. Doctoraldissertation, University of Leeds, Leeds, UK.

Training Music Sequence Recognizers withLinear Dynamic Programming
Christopher Raphael [email protected]
School of Informatics, Indiana University, Bloomington, IN 47408 USA
Eric Nichols [email protected]
Center for Research on Concepts and Cognition, Indiana University, Bloomington, IN 47408 USA
Keywords: machine learning, dynamic programming, harmonic analysis, trellis graph
AbstractAn obvious approach to the problem of har-monic analysis is to represent a musical scoreas a trellis graph, where layers in the graphcorrespond to musical slices of time, andeach node corresponds to the harmonic anal-ysis of the slice. If the transitions betweennodes and the analyses at each node are as-signed a score, the analysis problem reducesto finding the best-scoring path through thegraph, which can be computed with stan-dard dynamic programming (DP). But howcan we set the parameters of the necessaryscore function? We demonstrate a novel algo-rithm, Linear Dynamic Programming (LDP),to solve the problem of learning the coeffi-cients for a linear score function, based on ahand-labeled harmonic analysis.
1. Introduction
Many music recognition problems seek to explain someaspect of music data as a sequence of labels that col-lectively represent a time-varying analysis. Familiarexamples of this view come from problems that dealwith both symbolic music representations (e.g. MIDI)as well as audio. For instance, harmonic analysis ofsymbolic music data produces a label including chord,key, or other harmonic attributes, for each measureor beat of the piece under consideration (Temperley,2001). Other examples of symbolic music sequenceanalysis include pitch spelling, instrument fingering,prosodic labeling of melody for musical expression, anddecomposition of polyphonic music into voices. In theaudio domain, the problem of beat tracking can be ex-pressed as a labeling of each audio frame as either a“beat” or “non-beat.” Similar views are often taken
of other audio music processing examples such as thesignal-to-score problem, computing harmony from au-dio, chorus detection, score alignment, etc. In fact, thesequence analysis view extends to other music data,such as optical music recognition.
The sequence estimation problem can be solved by ex-pressing each possible label sequence as a path througha state graph. Arc costs in the graph correspond toa priori path plausibility, while data scores for nodesin the graph give the agreement between a label andan observation. Given this model, it is simple to com-pute the best-scoring path using DP. However, an oft-ignored problem faced in applying this methodology isthe specification of arc and data scores — the trainingproblem. Hand setting of parameters through trialand error is usually only feasible in small problems.Our research has produced a novel method for the su-pervised training of a DP-based sequence estimator wecall Linear Dynamic Programming. The method as-sumes that the arc and data scores are known linearfunctions of some unknown parameter vector. In thiscontext we seek the parameter value leading to thebest performance on our labeled training set. An ex-ample is presented for harmonic analysis, though webelieve the technique may be broadly applicable.
2. Application to Harmonic Analysis
The problem of functional harmonic analysis seeks topartition a piece of music into labeled sections, the la-bels giving the local harmonic state. The label usuallyconsists of a key and a chord symbol such as I, ii, iii,IV, V, vi, vii. For instance, the label (A major, IV)corresponds to the triad (D,F],A) built on the fourthscale degree in the key of A major. Several efforts haveaddressed this problem of automatic harmonic analy-sis, including (Pardo & Birmingham, 2002), (Raphael

Training Music Sequence Recognizers with LDP
& Stoddard, 2003), and (Temperley, 2001).
We seek to label each measure (or beat) of music with acollection of predefined harmonic labels, appropriatelychosen for the music in question. Our recognition ap-proach uses DP to find the best scoring path throughthe lattice composed by an S×N array of states, whereN is the number of measures or beats in the piece andS is the number of possible harmonic labels we con-sider. Our cost function consists of two components:a data cost and a path cost. The data cost encouragesclose agreement between each measure label and thepitches of that measure. The path cost rewards pathsthat are more musically plausible, independent of thedata. Our recognized sequence is then computed asthe lattice path that minimizes the sum of these costs.
More explicitly, our cost function, Cθ(s), is composedas Cθ(s) = Dθ(s) + Pθ(s) where the path, s, is a se-quence of labels, s = s1, . . . , sn, one for each measure.The data score, Dθ(s) =
∑Nn=1 dθ(sn, xn), is repre-
sented as
dθ(sn, xn) =3∑i=1
4∑j=1
θdijδij(sn, xn) (1)
where xn is the collection of pitches in the nth measureand the counts, δij(sn, xn), are as follows. Each har-monic label, sn, divides the possible chromatic pitchesinto four categories: those that are 1) the root of thechord, 2) in the chord but not the root, 3) in the scalebut not the chord, and 4) outside the scale. Simi-larly, the pitches in a measure are divided into thosethat begin 1) on the downbeat of the measure, 2) ona beat but not the downbeat, and 3) elsewhere in themeasure. In Eqn. 1, δij(sn, xn) counts the notes inthe nth measure that are in position category i and ofchromatic type j. To avoid degeneracies in which fami-lies of parameter assignments correspond to essentiallyidentical choices, we further assume
∑j θ
dij = 0.
The path score Pθ(s) =∑N−1n=1 pθ(sn, sn+1) is the sum
of modulation and progression components:
pθ(sn, sn+1) = θmM(sn, sn+1) +3∑i=1
θhi Hi(sn, sn+1)
where M(sn, sn+1) is an indicator function for keychange. If M(sn, sn+1) = 1, the {Hi} terms act asindicators for various classes of harmonic motion suchas progressive and regressive. As above, we assume∑i θhi = 0. In total, considering the linear constraints,
our parameter θ has dimension 12.
The LDP algorithm divides parameter space into re-gions corresponding to distinct paths through the trel-lis. The assumption of linear path scores, along with
the trellis structure, render this problem tractable —LDP uses DP itself to partition parameter space. Here,LDP yields a collection of distinct harmonic analysesalong with regions in parameter space that produceeach analysis. LDP chooses the analysis closest to thetraining data according to a harmonically motivatedpath quality measure. Then we select a parameter θfrom the center of the associated region.
Using this procedure, we trained our algorithm on theGrande Valse Brilliante of Chopin using hand-labeledground truth. LDP improved our path quality mea-sure from 2203 to 173, starting with a random ini-tial configuration for θ. The resulting configurationcorresponded to a total summed symmetric difference(SSD) of 73 between the recognized chord pitch classesand the ground truth chord pitch classes, as well as anSSD of 100 between the two scale sequences. Thiscorresponds to 0.24 chord errors and 0.33 scale errorsper measure. We then applied this learned param-eter to the Chopin “Minute Waltz”, resulting in anSSD of 186 chord pitch class errors (1.33/measure)and 40 scale pitch class errors (0.29/measure). Theanalysis is available for download as a midi file atwww.music.informatics.indiana.edu/papers/aaai08/.
Research is ongoing to improve the LDP algorithm andto test it on a larger collection of musical examples.Although our work to date has focused on harmonicanalysis, LDP is applicable to other musical domains;indeed, the algorithm was inspired by difficulties en-countered in choosing parameters for a piano fingeringtask (Kasimi et al., 2007). We hope that LDP willprove useful in many other domains where trainingdata exists in the form of a known sequential labeling.
References
Kasimi, A., Nichols, E., & Raphael, C. (2007). Asimple algorithm for automatic generation of poly-phonic piano fingerings. Proc. ISMIR.
Pardo, B., & Birmingham, W. P. (2002). Algorithmsfor chordal analysis. Computer Music Journal, 26,27–49.
Raphael, C., & Stoddard, J. (2003). Harmonic analysiswith probabilistic graphical models. Proc. ISMIR.
Temperley, D. (2001). The cognition of basic musicalstructures. Cambridge, MA: MIT Press.

Genre Classification of Music by Tonal Harmony
Carlos Perez-Sancho [email protected] Rizo [email protected]
Departamento de Lenguajes y Sistemas Informaticos, Universidad de Alicante, Spain
Stefan Kersten [email protected] Ramirez [email protected]
Music Technology Group, Universitat Pompeu-Fabra, Barcelona, Spain
Keywords: genre classification, language models, chord transcription, chord progressions
AbstractWe present a genre classification frameworkfor audio music based on a symbolic classifi-cation system. Audio signals are transformedto a symbolic representation of harmony us-ing a chord transcription algorithm, by com-puting Harmonic Pitch Class Profiles. Then,language models built from a groundtruth ofchord progressions for each genre are used toperform classification. We show that chordprogressions are a suitable feature to repre-sent musical genre, as they capture the har-monic rules relevant in each musical periodor style.
1. Genre classification
Organization of large music repositories is a tediousand time-intensive task for which music genre is an im-portant meta-data. Automatic genre and style classi-fication have become popular topics in Music Informa-tion Retrieval (MIR) research because musical genresare categorical labels created by humans to character-ize pieces of music and this nature provides the genremeta-data with a high semantic and cultural informa-tion to the music items in the collection.
Traditionally, the research domain of genre classifica-tion has been divided into the audio and symbolicmusic analysis and retrieval domains. Nevertheless,some authors have paid attention recently on makinguse of the best of both worlds. The work by Lidy etal. (Lidy et al., 2007) deals with audio to MIDI tran-scription in order to extract features from both signalsand then combine the decisions of the different clas-sifiers. On the other hand, Cataltepe and coworkers’approach (Cataltepe et al., 2007) is just the opposite:
to synthesize audio from MIDI and then analyze bothsignals to integrate the classifications.
Our proposal is to use tonal harmonic informationto distinguish between musical genres. The underly-ing hypothesis is that each musical genre makes useof different rules that allow or forbid specific chordprogressions. As it can be found in (Piston, 1987),some rules that were almost forbidden in a periodhave been accepted afterwards. Also, it is well knownthat pop-rock tunes mainly follow the classical tonic-subdominant-dominant chord sequence, whereas jazzharmony books propose different series of chord pro-gressions as a standard.
The goal of this work is to classify digital audio mu-sic using a language modelling system trained froma groundtruth of chord progressions, bridging the gapbetween audio and symbolic by means of a chord tran-scription algorithm.
2. Chord transcription
The Pitch Class Profile (PCP) measure has been usedin automatic chord recognition or key extraction sinceits introduction by Fujishima (Fujishima, 1999). Theperception of musical pitch has two main attributes:height and chroma. Pitch height moves vertically inoctaves telling which octave a note belongs to, whilechroma tells its position in relation to others within anoctave. A chromagram or a pitch class profile is a 12-dimensional vector representation of a chroma, whichrepresents the relative intensity in each of twelve semi-tones in a chromatic scale. Since a chord is composedof a set of tones, and its label is only determined bythe position of those tones in a chroma, regardless oftheir heights, chromagram seems to be an ideal featureto represent a musical chord.

Genre Classification of Music by Tonal Harmony
Table 1. Classification accuracy percentages using differentn-gram lengths.
Data set 2-grams 3-grams 4-grams
3 classes 54.4 61.1 61.1popular vs. jazz 70.9 83.4 83.4academic vs. jazz 75.0 75.0 75.0academic vs. popular 56.7 66.7 66.7
In this paper we have obtained the Harmonic PitchClass Profile (HCPC) by applying the algorithm in(Gomez & Herrera, 2004), which deviates from Fu-jishima’s PCP measure by distributing spectral peakcontributions to several adjacent HCPC bins and tak-ing a peaks harmonics into account. The feature vec-tors are then processed to obtain a symbolic represen-tation of chords in the form of triads. Thus, each songis represented as a string of chord progressions, withan alphabet of 24 symbols (major and minor triads).
3. Language models
We have used a language modelling approach to clas-sify chord progressions (Camastra & Vinciarelli, 2008).The idea is to capture the different use of chord pro-gressions in each style by using n-grams of chordstaken from a training set. Thus, a language model isbuilt for each genre in the training set, and these mod-els are evaluated against a new set of songs. Thesesongs are then labelled with the genre of the modelwith the highest probability of having generated it.
4. Experiments
Two different data sets were used in the experiments.As a training set we used a groundtruth of chord pro-gressions, obtained from a set of 761 symbolic musicfiles belonging to three genres: academic (comprisingbaroque, classical and romanticism), jazz and popu-lar. For testing the system we used a set of 12 audiofiles from the same genres, from which we obtained thechord progressions by applying the chord transcriptionalgorithm described in section 2.
Table 1 shows the classification accuracy of the systemwhen using different n-gram sizes and configurationsof the data sets (all-against-all and binary classifiers).As expected, better results were obtained when clas-sifying jazz music against the other two styles. Thisis consistent with the fact that the differences in har-mony between these styles are usually bigger than theyare between academic and popular music. Also, resultstend to improve when using larger n-grams, as they are
more capable to capture the typical structures presentin each style.
5. Conclusions and future work
We have shown the feasibility of classifying digital au-dio music by genre using a symbolic classification sys-tem. For this, a chord transcription algorithm wasused to obtain the chord progressions present in eachsong. The results show a good performance when clas-sifying between harmonically distant genres, while itis more difficult to distinguish when they make use ofmore similar chord progressions. Nevertheless, we areconvinced that these results can be improved by us-ing a richer chord vocabulary, to better represent theslight differences in harmony that are lost when usingonly chord triads. Also, a bigger set of audio files willbe constructed to deeply test this approach.
Acknowledgments
This work is supported by the Spanish PROSE-MUS project (TIN2006-14932) an partially supportedby the research programme Consolider Ingenio 2010(MIPRCV, CSD2007-00018) and the European PAS-CAL2 Network of Excellence.
References
Camastra, F., & Vinciarelli, A. (2008). Machine learn-ing for audio, image and video analysis. Springer.1st. edition.
Cataltepe, Z., Yaslan, Y., & Sonmez, A. (2007). Mu-sic genre classification using midi and audio features.EURASIP Journal on Advances in Signal Process-ing, 2007.
Fujishima, T. (1999). Realtime chord recognition ofmusical sound: A system using common lisp mu-sic. Proceedings of the International Computer Mu-sic Conference. Beijing.
Gomez, E., & Herrera, P. (2004). Automatic ex-traction of tonal metadata from polyphonic audiorecordings. Proceedings of 25th International AESConference. London, UK.
Lidy, T., Rauber, A., Pertusa, A., & Inesta, J. (2007).Improving genre classification by combination of au-dio and symbolic descriptors using a transcriptionsystem. Proceedings of the ISMIR (pp. 61–66). Vi-enna, Austria.
Piston, W. (1987). Harmony. Norton, W. W. & Com-pany, Inc. 5th. edition.

Using Mathematical Morphology for Geometric Music Retrieval
Mikko Karvonen, Kjell Lemstrom {mtkarvon,klemstro}@cs.helsinki.fi
Department of Computer Science, University of Helsinki
Abstract
In this paper, we discuss the applicabilityof the mathematical morphology frameworkthat was originally developed for image pro-cessing, to music retrieval purposes. Morespecifically, MM techniques are adopted forfinding approximate occurrences of symboli-cally encoded musical query patterns in sym-bolic music databases. We consider four pos-sibilities to accomplish the task.
1. Introduction
Mathematical morphology (MM) is a tool regularlyused in binary and greyscale image processing. MM isoften used for template matching and pattern recogni-tion; it can be used for extracting attributes, geomet-rical information or ”meaning” in images.
In this paper, we show how to apply the frameworkfor content-based music retrieval for symbolically en-coded music. To this end, we represent symbolic musicas 2-D binary images in the integer space Z
2 (cf. thewell-known piano-roll representation). The note ob-jects, individual pixels (1-pixels) or line segments, aresets of pixels in Z
2. 1-pixel objects can represent themusical pitch and rhythm (henceforth referred to asthe note-on representation); line segments provide alsofor representing note durations (the line-segment rep-resentation; see Fig. 1). This way, an obvious methodto find occurrences of an image of note objects (thequery pattern) within another image (the database)would be to use classical linear correlation. However,in an approximative case with the note-on representa-tion, where the pixels of the query are slightly jitteredin the database image, there is no correlation whenoperating with binary images. We will show how toobtain robust matching tools to overcome this prob-lem by adopting appropriate MM techniques.
1.1. Basic morphologic operations
The elementary binary MM operations, dilation anderosion, are based on the Minkowski addition and sub-
traction (Heijmans, 1995). They are nonlinear neigh-borhood operations on two sets. The typically smallerone is called structuring element (SE). Dilation per-forms a maximum on SE, which has a growing effecton the target set, while erosion performs a minimumon SE and causes the target set to shrink. Dilation canbe used to fill gaps in an image, erosion, for example,for removing salt-and-pepper type noise.
A straight-forward template-matching operator, thehit-or-miss transformation (HMT), is based on theseelementary operations. HMT is the intersection be-tween an image eroded by SE1 and the image’s com-plement eroded by SE2, where SE2 is a local back-ground of SE1 (Bloomberg & Maragos, 1990). Theoutput of the operation is an image where only the oc-currences are marked with an ”on” pixel (see Fig. 1).HMT’s weakness is that it finds only exact matches.In (Bloomberg & Maragos, 1990), two modified HMTapproaches are presented to fight this problem.
2. Algorithms
We adopted four possibilities and implemented themin MATLAB. For the present, we do not have an au-tomatic conversion tool. The musical examples weregenerated by loading MIDI songs into a sequencer andthen taking binary-valued screenshots of the corre-sponding piano-roll illustrations.
2.1. Correlation & morphologic preprocessing
In the note-on representation, approximative match-ing is performed by replacing the 1-pixels in one im-age by filled discs (dilation). Thus, for instance, in ajittered query the pixels in the query image fall withinthe discs in the database. Intuitively, the disc allowsfor approximation both time- and pitchwise, and itsdiameter gives the magnitude of the approximation.
2.2. Threshold convolution
In order to use another HMT technique, based onthreshold convolution (TC) (Bloomberg & Maragos,1990), let us represent the database and query as sets

Using Mathematical Morphology for Geometric Music Retrieval
Figure 1. A) Piano-roll excerpt of Sibelius’ Finlandia. B)Query pattern. C) TC between query and image. D) Oc-currences found by applying Heaviside’s USF on TC.
X and W , respectively, and define 2-D functions x(n)and w(n), such that x(n) = 1 if n ∈ X and x(n) = 0if n ∈ Xc (accordingly for w(n)). We apply a thresh-old value θ to the convolution of x and w, and useHeaviside’s unit step function to decide which convo-luted pixels are to be used. If θ = |W |, the operationis equivalent to the erosion of X by W . By loweringθ, we can impose looser conditions. It is notable thatconvolving a binary signal x with a binary templatew and comparing the result to a threshold is actuallythe optimum decision for detecting w in x, when xcontains a shifted version of w corrupted with binarysalt-and-pepper noise (Bloomberg & Maragos, 1990).
2.3. Rank order filtering
Rank order filtering (ROF) is theoretically equiva-lent to TC, and it is optimal for template detection(Bloomberg & Maragos, 1990). In a morphologicalimage-processing scenario, when the SE consists onlyof hits, ROF is shift-invariant and increasing (erosionand dilation are special cases). ROF operations aremore robust against shape distortion than erosion, butthey are computationally more complex.
A set-theoretic definition of a binary ROF, whichavoids sorting and uses only pixel counting, was pre-sented in (Maragos & Schafer, 1989). The defini-tion gives the r-th rank order transformation (r =1, 2, . . . , |W |) of the binary set X by a binary W . Inthe transformation, W is shifted step-by-step. Whenlocated at point z ∈ Z
2, we always select the r-th largest of the points belonging to the intersectionX ∩ (W + z). If r = |W |, the rank operation becomesan erosion and the filter operates as HMT. By lower-ing the rank one can obtain better results. Note alsothat TC and ROF yield similar results when θ = r.
2.4. Blur HMT
The blur hit-or-miss transformation (BHMT) is a sim-ple extension to the classic HMT, providing toleranceto salt-and-pepper noise and image alignment errors.
BHMT alters the image, but preserves the shape ofSEs. The ”blur” parameter specifies the maximum dis-tance allowed for a match in between the query pixeland the corresponding pixel in the database image.The operator is implementable using Boolean imageoperators, which makes it faster than integer-basedtechniques, such as ROF(Bloomberg & Vincent, 2000).
BHMT requires that there is (1) an ON pixel within aradius of r1 of each hit, and (2) an OFF pixel within aradius r2 of each miss (Bloomberg & Maragos, 1990).For SEs that have a specific shape (e.g., a melody pat-tern), the blur match gives more immunity to pixelnoise that occurs near the boundaries. As comparedto the original HMT operation, the only change is theinclusion of a straight-forward preprocessing: the im-age is first dilated by a disc-shaped SE1 and then theimage’s complement by another disc, SE2.
3. Conclusions
We introduced 4 algorithms based on MM that areapplicable to approximate content-based retrieval onsymbolically encoded polyphonic music. Based on ourpreliminary experiments the approach seems promis-ing: all the methods were capable of finding occur-rences of query patterns that had minor distortions,such as local jittering. In note-on representation, witha small database, ROF was the fastest; with largerdatabases TC outperformed the others. However, weexpect BHMT to be the choice when implemented byusing Boolean image operations. With line segments,preprocessed correlation was the fastest but it alsogave false positives most often. Further conclusionsare left for the future when we have an automatic con-version tool and C implementations of the algorithms.
References
Bloomberg, D., & Maragos, P. (1990). Generalized hit-miss operators with applications to document imageanalysis. SPIE Conference on Image Algebra andMorphological Image Processing (pp. 116–128).
Bloomberg, D., & Vincent, L. (2000). Pattern match-ing using the blur hit-miss transform. Journal ofElectronic Imaging, 9, 140–150.
Heijmans, H. (1995). Mathematical morphology: Amodern approach in image processing based on al-gebra and geometry. SIAM Review, 37, 1–36.
Maragos, P., & Schafer, R. (1989). Morphologicalfilters. part ii: Their relations to median, order-statistic, and stack filters. IEEE Trans. on Acous-tics, Speech, and Signal Processing, 35, 1153–1184.



Chorale Harmonization in the Style of J.S. Bach
A Machine Learning Approach
Alex Chilvers [email protected]
Macquarie University, NSW 2109 North Ryde, Australia
Menno van Zaanen [email protected]
Tilburg University, P.O. Box 90153, 5000 LE Tilburg, The Netherlands
Abstract
In this article, we present a new approachto the task of automatic chorale harmoniza-tion. Taking symbolic musical transcripts asinput, we use the TiMBL Machine Learningpackage to generate harmonizations of un-seen chorale melodies. Extracting featuresfrom the soprano notes only, the system gen-erates the other three melody lines in thechorale. We experiment with features de-noting different properties of notes, such aspitch, note length, location in the bar orpiece, and features of surrounding notes, butalso with global features such as metre andkey. The current system harmonizes 41.71%of the data exactly like J.S. Bach did (modulooctave).
1. Introduction
Automatic harmonization, where accompanyingmelody lines are generated given a single melody line,is one of the oldest topics to be explored by computermusicians. A relatively early example of rule-basedautomatic harmonization using a constraint-basedsystem is described in Pachet and Roy (2001). Otherapproaches such as the use of probabilistic finitestate grammars (Conklin & Witten, 1995) or neuralnetworks (Hild et al., 1992) have also been explored.Obviously, there is much more literature, but spacerestrictions do not allow us to provide more.
In this article we will use chorales composed by Jo-hann Sebastian Bach. These chorales have long beenthe popular choice as data for computer music re-searchers exploring the harmonization challenge. Thesimple fact that there are many of these relativelyshort pieces, all composed in Bach’s recognizable style,makes them appealing for this task.
Furthermore, it is known that Bach began with an-other composer’s melody. This melody is used as thesoprano voice in the chorales. He then harmonized thismelody by adding notes for the alto, tenor, and bassvoices, effectively adding his own accompaniment.
In the machine learning (ML) task described here, thesame approach is used. Starting from properties ex-tracted from the original melody, the soprano line, weapply a ML classifier, which outputs notes for the otherthree melody lines.
2. Approach
We treat the task of automatic harmonization as aclassification task, which means that we can use stan-dard ML techniques. As input, notes from the sopranomelody are used. The output is a chord (i.e. notes forthe three additional melody lines) describing the har-monization.
There are many other ways to approach the task.For example, one could classify each voice separately.However, initial experiments using that approach pro-duced discouraging results.
2.1. Classifications
The output of the system is encoded using 12-bitstrings, where a single bit represents whether or notthe corresponding note is present in the chord. Theoutput is represented relative to the chorale’s tonic toavoid data sparseness problems. This means that thefirst bit in the bit string corresponds to the tonic, thesecond bit denotes a semi-tone higher than the tonic,and so on. For example, a major triad is representedby the string 100010010000. Due to the three-voicenature of chorale harmonization, each bit string cancontain a maximum of three 1s.
Using this encoding, the information on the exact oc-

Chorale Harmonization in the Style of J.S. Bach
tave of a note is lost. Also, the ordering of voices is notexplicitly encoded, as all notes are put in a bit vectorwhich orders notes with respect to the tonic.
2.2. Feature vectors
The classifier takes properties from each of the ini-tial (soprano) notes as input. These properties areencoded as features in feature vectors. The choice offeatures has a major impact on the performance ofthe system, so we consider a number of different ap-proaches and combinations.
Local features encode information of the sopranonotes. We use pitch and duration. Pitch is repre-sented using the semi-tonal distance from the tonic.For example, when the note is the tonic, the value is0, whereas a whole tone above the tonic has value 2.
Contextual features represent information of surround-ing notes. We take the context to be the previous andnext n soprano notes. This n is the size of the con-text and can be varied in different experiments. In theexperiments described here, n is set to three.
With the goal of producing a nicely flowing harmoniza-tion, we have experimented with the previous m clas-sifications, i.e. generated chords, as features. Previousattempts at automatic harmonization have been madeusing Markov models (Biyikoglu, 2003) and probabilis-tic inference (Allan & Williams, 2005), which suggestthat using harmonization of previous notes can help topredict chords. Initial experiments showed that pre-vious classifications have a negative impact. Many ofthem are wrong, which means that many incorrect val-ues are incorporated into the feature vectors.
Other contextual features that are used are the loca-tion of a note in a bar and the location of a bar in apiece.
Finally, we incorporated global features, that provideinformation on the entire piece. In these experiments,we have used whether the piece is major or minor, andthe piece’s metre.
3. Results
For the experiments, we took 230 J.S. Bach chorales.The performance of the system was measured by cal-culating accuracy of the classified chords.1 The resultswere computed using 10-fold cross validation.
As a baseline, the majority class, which is the majortriad, is used. This results in an accuracy of 8.71 with
1We only count exactly matching chords and do not useother musically correct chords, to reduce subjectivity.
a standard deviation of 0.86.
For the ML approach, we used the TiMBL package(Daelemans et al., 2002), which provides optimizedk-NN classification algorithms. However, other clas-sifiers can be used as well.
The best TiMBL system produced an accuracy of41.71 with a standard deviation of 5.80. This resultwas acquired using all of the previously mentioned fea-tures, except for the previous classification features.
4. Conclusion
In this article we showed that automatic harmoniza-tion can be treated as a ML classification task. Theresults, which are generated using pitch, duration, key,positional, and contextual features, greatly outperformthe majority class baseline. However, the current ex-periments simplify the task by removing octave andvoice information.
There are many extensions that may improve the cur-rent system. Firstly, since the best results are gener-ated using (almost) all features, it may very well be thecase that additional features will further improve re-sults. Secondly, the accuracy measure only takes intoaccount harmonization exactly as Bach composed it.The way accuracy is measured now, chords counted asincorrect may actually still be musically valid.
References
Allan, M., & Williams, C. K. I. (2005). Harmonis-ing chorales by probabilistic inference. Advancesin Neural Information Processing Systems 17. MITPress.
Biyikoglu, K. M. (2003). A markov model for choraleharmonization. Proceedings of the 5th Triennial ES-COM Conference.
Conklin, D., & Witten, I. H. (1995). Multiple view-point systems for musical prediction. Journal of NewMusic Research, 24, 51–73.
Daelemans, W., Zavrel, J., van der Sloot, K., &van den Bosch, A. (2002). TiMBL: Tilburg memory-based learner (Technical Report ILK 02-10). TilburgUniversity, Tilburg, the Netherlands.
Hild, H., Feulner, J., & Menzel, W. (1992). HAR-MONET: A neural net for harmonizing chorales inthe style of J.S. Bach. Advances in Neural Informa-tion Processing 4 (NIPS 4).
Pachet, F., & Roy, P. (2001). Musical harmonizationwith constraints: A survey. Constraints, 6(1), 7–19.

An information-dynamic model of melodic segmentation
Marcus T. Pearce [email protected]
Daniel Mullensiefen [email protected]
Geraint A. Wiggins [email protected]
Centre for Cognition, Computation and CultureGoldsmiths, University of LondonNew Cross, London SE14 6NW, UK
Keywords: segmentation, grouping, melody, unsupervised learning, information theory
Abstract
We present a new model of melodic segmen-tation based on unsupervised information-dynamic analysis. This is justified theoret-ically on the basis of previous research inmusicology, computational linguistics, ma-chine learning and experimental psychology.The model is evaluated in comparison withexisting rule-based algorithms on a melodicboundary detection task. Although themodel is outperformed, it does contribute toa Hybrid model that achieves superior perfor-mance, which is surprising given that it usesunsupervised learning and has not been opti-mised for the task of melodic segmentation.
Melodic segmentation is a fundamental process in theperception, composition, performance and analysis ofmusic whilst also being necessary for melody index-ing and retrieval in MIR applications. Most exist-ing models of melodic segmentation use rules basedon music-theoretic knowledge. As a result, they arestyle-specific or require expert knowledge of the musi-cal style to tune their parameters. Our goal here is todevelop a more general model of melodic segmentationbased on unsupervised machine learning.
The IDyOM (Information Dynamics Of Music) modelis based on music-theoretic proposals that perceptualgroups are associated with points of closure where theongoing cognitive process of expectation is disruptedbecause the context fails to stimulate strong expec-tations for any continuation or because the actualcontinuation is unexpected (Meyer, 1957; Narmour,1990). We give these proposals precise definitions inan information-theoretic framework in which informa-tion content represents the unexpectedness of an out-
come and entropy the uncertainty of a prediction. Wepropose that boundaries will occur before events forwhich unexpectedness and uncertainty are high.
Further support comes from empirical psychologicalresearch demonstrating that infants and adults use im-plicitly learnt statistical properties of pitch sequencesto find segment boundaries on the basis of higher tran-sition probabilities within than between groups (Saf-fran et al., 1999). In machine learning and compu-tational linguistics, algorithms based on the idea ofsegmenting before events associated with high uncer-tainty or surprise perform reasonably well in identify-ing word boundaries in infant-directed speech (Brent,1999; Cohen et al., 2007).
Our information-theoretic measures are derived byestimating the conditional probabilities of sequentialmelodic events using a sophisticated statistical modelof melodic structure (Conklin & Witten, 1995; Pearce,2005) that accounts well for human melodic expecta-tions (Pearce, 2005). This model is able to combine n-gram statistics of several orders, use a variable globalorder bound, predict multiple attributes of a melodicevent, use statistical regularities in different derivedrepresentations and combine schematic models basedon long-term musical exposure with short-term modelsbased on the local properties of the music currently be-ing analysed. In this work, we use the model to predictthe pitch, IOI (inter-onset interval) and OOI (offset-to-onset interval) associated with melodic events, mul-tiplying the probabilities of these attributes togetherto yield the event’s probability. We focus on the unex-pectedness of events (information content) using thisas a boundary strength profile, picking local peaks toidentify boundary locations. The role of entropy willbe considered in future work.
We test the model on a boundary identification task

An information-dynamic model of melodic segmentation
Model F1 Precision RecallHybrid 0.66 0.87 0.56Grouper 0.66 0.71 0.62LBDM 0.63 0.70 0.60GPR2a 0.58 0.99 0.45IDyOM 0.58 0.76 0.50GPR2b 0.39 0.47 0.42GPR3a 0.35 0.29 0.46GPR3d 0.31 0.66 0.22Always 0.22 0.13 1.00Never 0.00 0.00 0.00
Table 1. Mean performance over 1705 melodies.
in the largest database of German folk songs (Erk) inthe Essen collection (Schaffrath, 1995) containing 1705melodies annotated with phrase boundaries by a mu-sicologist. 10-fold cross-validation is used to train themodel and obtain information-content profiles for eachunseen melody in the dataset. Performance is com-pared with several existing rule-based models: LBDM(Cambouropoulos, 2001), Grouper (Temperley, 2001),the Grouping Preference Rules 2a, 2b, 3a, 3d (Lerdahl& Jackendoff, 1983; Frankland & Cohen, 2004) andtwo baseline models (always, never). We use F1, Pre-cision and Recall to assess the correspondence betweenthe models’ boundaries and the target boundaries.
Mean performance measures are shown in Table 1.The four models achieving mean F1 values of over 0.5(Grouper, LBDM, GPR2a and IDyOM) were chosenfor further analysis. Sign tests between the F1 scoreson each melody indicate that all differences betweenthese models are significant at an alpha level of 0.01,with the exception of GPR2a and LBDM. The fourmodels were entered as predictor variables in a logisticregression analysis. Stepwise backwards eliminationusing the Bayes Information Criterion failed to removeany of these predictors and the resulting Hybrid model(which includes IDyOM) produced an F1 performancethat was significantly better than Grouper.
IDyOM contains no hard-coded music-theoretic rulesbut learns regularities in the melodic data it is trainedon and outputs probabilities of note events which areultimately used to derive information content for eachnote event in a melody. It therefore might be ex-pected to outperform rule-based models on more un-familiar musical territory (e.g., non-Western music).Furthermore, as a model of prediction and expecta-tion in music, it has not been specifically optimisedfor melodic segmentations. While future optimisation(e.g., in representation) might be expected to yield im-provements in segmentation performance, the presentresults demonstrate a link between sequential predic-
tive information content and melodic segmentation.
References
Brent, M. R. (1999). An efficient, probabilisticallysound algorithm for segmentation and word discov-ery. Machine Learning, 34, 71–105.
Cambouropoulos, E. (2001). The local boundary de-tection model (LBDM) and its application in thestudy of expressive timing. Proceedings of the Inter-national Computer Music Conference (pp. 17–22).San Francisco: ICMA.
Cohen, P. R., Adams, N., & Heeringa, B. (2007). Vot-ing experts: An unsupervised algorithm for seg-menting sequences. Intelligent Data Analysis, 11,607–625.
Conklin, D., & Witten, I. H. (1995). Multiple view-point systems for music prediction. Journal of NewMusic Research, 24, 51–73.
Frankland, B. W., & Cohen, A. J. (2004). Parsingof melody: Quantification and testing of the localgrouping rules of Lerdahl and Jackendoff’s A Gen-erative Theory of Tonal Music. Music Perception,21, 499–543.
Lerdahl, F., & Jackendoff, R. (1983). A generativetheory of tonal music. Cambridge, MA: MIT Press.
Meyer, L. B. (1957). Meaning in music and informa-tion theory. Journal of Aesthetics and Art Criticism,15, 412–424.
Narmour, E. (1990). The analysis and cognition ofbasic melodic structures: The implication-realisationmodel. Chicago: University of Chicago Press.
Pearce, M. T. (2005). The construction and evalu-ation of statistical models of melodic structure inmusic perception and composition. Doctoral disser-tation, Department of Computing, City University,London, UK.
Saffran, J. R., Johnson, E. K., Aslin, R. N., & New-port, E. L. (1999). Statistical learning of tone se-quences by human infants and adults. Cognition,70, 27–52.
Schaffrath, H. (1995). The Essen folksong collec-tion. In D. Huron (Ed.), Database containing 6,255folksong transcriptions in the Kern format and a34-page research guide [computer database]. MenloPark, CA: CCARH.
Temperley, D. (2001). The cognition of basic musicalstructures. Cambridge, MA: MIT Press.

Discovery of distinctive patterns in music
Darrell Conklin [email protected]
Department of Computing, City University London, UK
Keywords: pattern discovery, distinctive pattern, anticorpus, folk songs
Abstract
This paper proposes a new view of patterndiscovery in music: mining of a corpus formaximally general patterns that are overrep-resented with respect to an anticorpus. Analgorithm for maximally general distinctivepattern discovery is described and applied tofolk song melodies from three geographic re-gions. Distinctive patterns have applicabil-ity to comparative music analysis tasks wherean anticorpus can be defined and contrastedwith an analysis corpus.
1. Introduction
Pattern discovery in music is a central part of symbolicmusic processing, with a wide range of applications, in-cluding motivic analysis, music generation, and musicclassification.
Pattern discovery in music has typically been viewedas an unsupervised learning problem, with the atten-dant difficulty of ranking discovered patterns. Thisdifficulty arises because frequency of occurrence andspecificity are inversely related, and any ranking mea-sure must balance these two quantities. Statisticalapproaches for pattern ranking (Conklin & Anagnos-topoulou, 2001) achieve this using a background model,for example a zero or first order Markov model. Thebackground model is used to compute expected counts,which are compared to observed pattern counts forlarge deviations.
The use of a background model, possibly estimatedfrom the analysis corpus itself, raises concerns regard-ing how “musical” are pieces implicitly generated bythe background model. Therefore, the significance ofpatterns may easily be overestimated, leading to thepresentation of many irrelevant patterns.
By analogy with work in bioinformatics on discrimi-native motif discovery (Barash et al., 2001; Redhead
& Bailey, 2007), explicit negative pieces may providea better alternative to using a background model.
Adopting this view for music, patterns can be soughtthat are useful for classification: able to discriminatebetween a corpus and an anticorpus (the division is leftto the analyst: whether by style, composer, period,geographic region, etc.). Though patterns have beenused previously for supervised learning tasks, most ap-proaches rely on an exhaustive catalog of fixed-widthpatterns.
This paper introduces the distinctive pattern for musicand develops an algorithm for their discovery in a cor-pus. As a proof of concept, the method is illustratedon a few sections from the Essen folk song databaseto find maximally general distinctive patterns: thosethat are least likely to overfit the corpus and thereforemost likely to be useful for classification.
2. Distinctive patterns
A distinctive pattern is one that is overrepresented ina corpus as compared to an anticorpus. A likelihoodratio is used to evaluate the distinctiveness or interestof a pattern (see Glossary of Notation in Table 1).
Table 1. Glossary of Notation.
Term Meaning
c⊕(P ) count of pattern P in the corpusc(P ) count of pattern P in the anticorpusn⊕ size of the corpusn size of the anticorpusI(P ) likelihood ratio of pattern P
To define the likelihood ratio, both pattern P and class(⊕: corpus or : anticorpus) can be viewed as indica-tor variables of pieces (a pattern indicated if it occursin a piece, and the class indicated from by corpus andanticorpus labelling). The likelihood ratio measuresthe relative probability of the pattern in the corpus

Discovery of distinctive patterns in music
Table 2. Maximally General Distinctive Patterns in Three Folk Song Regions.
Corpus P p(P |⊕) p(P |) I(P )
Shanxi [{contour:-,diaintc:M6},{contour:+,diaintc:m7}] 30/237 0/195 infAustrian [{rest:0,diaintc:m2},{diaintc:M3}] 34/102 14/330 7.9Swiss [{diaintc:M6},{diaintc:M2}] 22/93 12/339 6.7
and anticorpus, or equivalently, its overrepresentationmeasured by the ratio of its observed count in the cor-pus to its expected count given the anticorpus proba-bility:
I(P ) def=p(P |⊕)p(P |)
=c⊕(P )
p(P |)× n⊕
The algorithm used to search for distinctive patterns isa sequential pattern mining method using a feature set(Conklin & Bergeron, 2008) pattern representation. Adepth-first search of a specialization space uses tworefinement operators at a search node: addition of afeature to the last set of a pattern, and extension of thepattern by the empty feature set. The search is lexi-cographic and therefore no search node is visited morethan once. Given that maximally general distinctivepatterns are sought, a branch in the search tree maybe immediately terminated with success if a minimalspecified pattern interest is achieved by the pattern ata search node.
3. Results
Three geographic regions represented in the Essen folksong database were chosen to illustrate the method(Shanxi: 237 pieces; Austrian: 102; Swiss: 93). Aus-trian and Swiss were chosen as a pair due to theirgeographic proximity. Patterns were considered inter-esting if p(P |⊕) ≥ 0.2 (in at least 20% of the corpus)and I(P ) ≥ 3 (at least 3-fold overrepresented). Anextensive catalog of abstract musical viewpoints (func-tions that compute features from events) was providedto the algorithm.
Many maximally general distinctive patterns arefound; Table 2 indicates, for each region, one discov-ered pattern with high interest. The presented patternis therefore highly distinctive when the other two re-gions are taken together as the anticorpus.
In the table, several viewpoints appear in patterns:those referencing diatonic interval class, melodic con-tour, and a viewpoint indicating whether the eventfollows a rest. The patterns are very general and insome cases quite surprising (e.g., for Swiss: simply a
diatonic interval class of a major sixth followed by amajor second) and cover many pieces. The Shanxi pat-tern is maximally distinctive: not covering any piecesin the anticorpus.
4. Discussion
This paper has defined distinctive pattern discoveryand illustrated an application using a few sections ofthe Essen folk song database. Distinctive patternscan have musicological interest in isolation, or can beviewed as binary global features for describing piecesfor supervised learning. In this sense, distinctive pat-tern discovery in music can be viewed as a featureselection task for classification.
The pattern discovery algorithm has also been usedfor motivic analysis of a single piece (Conklin, 2008),showing that distinctive patterns corresponding toknown motives are discovered. It is also under develop-ment for bioinformatics motif discovery applications.
References
Barash, Y., Bejerano, G., & Friedman, N. (2001).A simple hyper-geometric approach for discoveringputative transcription factor binding sites. WABI2001: First International Workshop on Algorithmsin Bioinformatics (p. 278). Springer.
Conklin, D. (2008). Mining for distinctive patterns inthe first movement of Brahms’s String Quartet in CMinor. MaMuX International Workshop on Com-putational Music Analysis. IRCAM, Paris, April 5.Abstract.
Conklin, D., & Anagnostopoulou, C. (2001). Repre-sentation and discovery of multiple viewpoint pat-terns. Proceedings of the International ComputerMusic Conference (pp. 479–485). Havana.
Conklin, D., & Bergeron, M. (2008). Feature set pat-terns in music. Computer Music Journal, 32, 60–70.
Redhead, E., & Bailey, T. (2007). Discriminative motifdiscovery in DNA and protein sequences using theDEME algorithm. BMC Bioinformatics, 8, 335.

Melody Characterization by a Fuzzy Rule System
Pedro J. Ponce de León, David Rizo {PIERRE,DRIZO}@DLSI.UA.ES
Departamento de Lenguajes y Sistemas Informáticos, Universidad de Alicante, Spain
Rafael Ramirez [email protected]
Music Technology Group, Universitat Pompeu-Fabra, Barcelona, Spain
Abstract
We present preliminary work on automatichuman-readable melody characterization. Inorder to obtain such characterization, we (1)extract a set of statistical descriptors from adataset of MIDI files, (2) apply a rule induc-tion algorithm to obtain a set of (crisp) clas-sification rules for melody track identification,and (3) automatically transform the crisp rulesinto fuzzy rules by applying a genetic algorithmto generate the membership functions for therule attributes. We present and discuss someresults.
1. Melody characterization
Melody is a somewhat elusive musical term that oftenrefers to a central part of a music piece that catches mostof the listener’s attention, and which the rest of musicparts are subordinated to. This is one of many definitionsthat can be found in many places, particularly music the-ory manuals. However, these are all formal but subjec-tive definitions given by humans. The goal in this work isto automatically obtain an objective and human friendlycharacterization of what it is considered to be a melody.
The identification of a melody track is relevant for a num-ber of applications like melody matching (Uitdenbogerd& Zobel, 1999), motif extraction from score databases,or extracting melodic ringtones from MIDI files. In thiswork we approach the problem of automatically findinga melody track in a MIDI file by using statistical proper-ties of the musical content. The melody model is a setof human-readable fuzzy rules (Cordón & Herrera, 1995),automatically induced from a corpora of MIDI files.
The rest of the paper is organized as follows: first, the sta-tistical MIDI track content description is outlined. Then,
Preliminary work. Under review by the International Confer-ence on Machine Learning (ICML). Do not distribute.
a first (crisp) rule set for melody characterization is in-duced. Next, we describe how we fuzzify the crisp set ofrules in order to improve rule readability. Finally someresults and conclusions are discussed.
2. MIDI track content description
MIDI track content is described by a collection of statis-tics on several properties of musical note streams, suchas pitch, pitch interval and note duration, as well as trackproperties such as number of notes in the track, track du-ration, polyphony rate and occupation rate. As a result,MIDI tracks are represented by real number vectors with34 statistical values. In the rule system presented in sec-tion 3 only 13 of these attributes are used. Each track hasbeen both manually and automatically labeled as beinga melody track or a non-melody track. Details on suchstatistics and the labeling process can be found in (Poncede León et al., 2007).
3. A rule system for melody characterization
In previous works, several decision tree and rule classifi-cation algorithms have been used to classify MIDI tracksas melody or non-melody. In this work, a rule system ob-tained using the RIPPER algorithm (Cohen, 1995) is usedas the basis to induce a fuzzy rule system. An example ofan induced (crisp) rule is as follows:
if (AvgPitch >= 65.0) and (OccupRate >= 0.51)and (AvgInterval <= 3.64) and (NumNotes >= 253)
then IsMelody=true
4. From crisp to fuzzy rule system
A fuzzyfication process is applied to such crisp rule sys-tem, in order to obtain a user friendly rule system.
Two basic steps must be carried out for the fuzzyficationof the crisp rule system. First, the data representationmust be fuzzified. That is, numerical input and outputvalues must be converted to fuzzy terms. Second, therules themselves must be translated into fuzzy rules, sub-stituting linguistic terms for numerical boundaries.
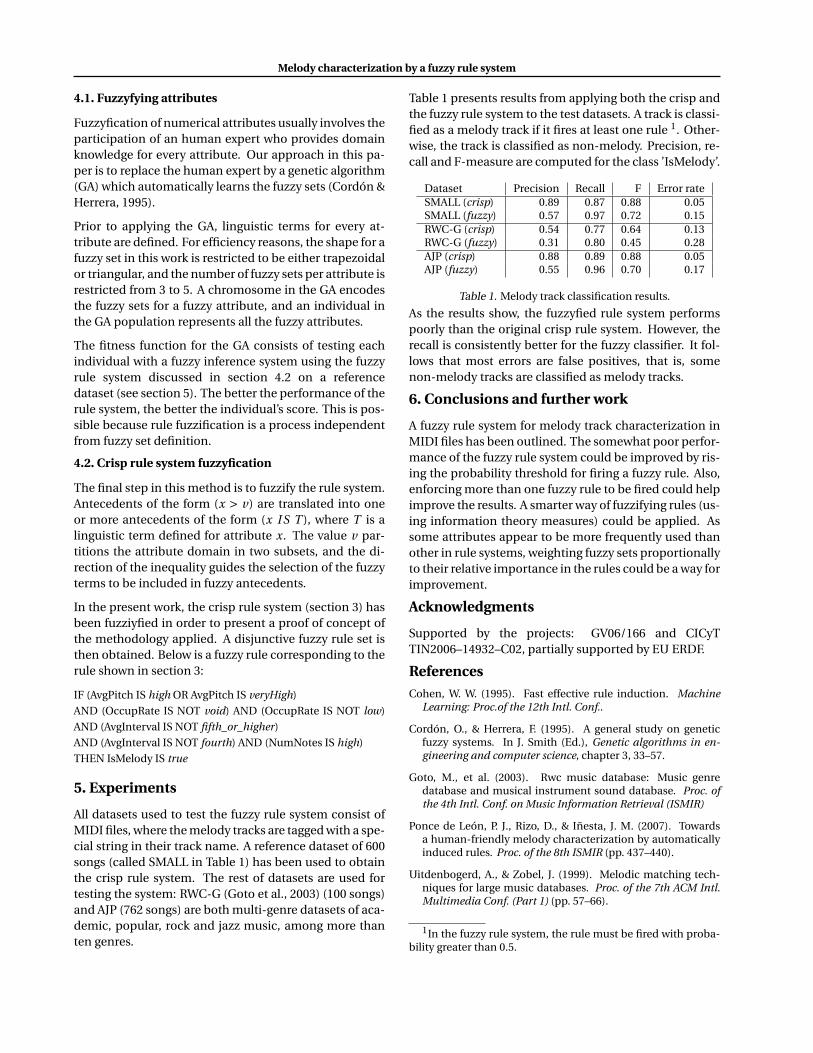
Melody characterization by a fuzzy rule system
4.1. Fuzzyfying attributes
Fuzzyfication of numerical attributes usually involves theparticipation of an human expert who provides domainknowledge for every attribute. Our approach in this pa-per is to replace the human expert by a genetic algorithm(GA) which automatically learns the fuzzy sets (Cordón &Herrera, 1995).
Prior to applying the GA, linguistic terms for every at-tribute are defined. For efficiency reasons, the shape for afuzzy set in this work is restricted to be either trapezoidalor triangular, and the number of fuzzy sets per attribute isrestricted from 3 to 5. A chromosome in the GA encodesthe fuzzy sets for a fuzzy attribute, and an individual inthe GA population represents all the fuzzy attributes.
The fitness function for the GA consists of testing eachindividual with a fuzzy inference system using the fuzzyrule system discussed in section 4.2 on a referencedataset (see section 5). The better the performance of therule system, the better the individual’s score. This is pos-sible because rule fuzzification is a process independentfrom fuzzy set definition.
4.2. Crisp rule system fuzzyfication
The final step in this method is to fuzzify the rule system.Antecedents of the form (x > v) are translated into oneor more antecedents of the form (x I S T ), where T is alinguistic term defined for attribute x. The value v par-titions the attribute domain in two subsets, and the di-rection of the inequality guides the selection of the fuzzyterms to be included in fuzzy antecedents.
In the present work, the crisp rule system (section 3) hasbeen fuzziyfied in order to present a proof of concept ofthe methodology applied. A disjunctive fuzzy rule set isthen obtained. Below is a fuzzy rule corresponding to therule shown in section 3:
IF (AvgPitch IS high OR AvgPitch IS veryHigh)
AND (OccupRate IS NOT void) AND (OccupRate IS NOT low)
AND (AvgInterval IS NOT fifth_or_higher)
AND (AvgInterval IS NOT fourth) AND (NumNotes IS high)
THEN IsMelody IS true
5. Experiments
All datasets used to test the fuzzy rule system consist ofMIDI files, where the melody tracks are tagged with a spe-cial string in their track name. A reference dataset of 600songs (called SMALL in Table 1) has been used to obtainthe crisp rule system. The rest of datasets are used fortesting the system: RWC-G (Goto et al., 2003) (100 songs)and AJP (762 songs) are both multi-genre datasets of aca-demic, popular, rock and jazz music, among more thanten genres.
Table 1 presents results from applying both the crisp andthe fuzzy rule system to the test datasets. A track is classi-fied as a melody track if it fires at least one rule 1. Other-wise, the track is classified as non-melody. Precision, re-call and F-measure are computed for the class ’IsMelody’.
Dataset Precision Recall F Error rateSMALL (crisp) 0.89 0.87 0.88 0.05SMALL (fuzzy) 0.57 0.97 0.72 0.15RWC-G (crisp) 0.54 0.77 0.64 0.13RWC-G (fuzzy) 0.31 0.80 0.45 0.28AJP (crisp) 0.88 0.89 0.88 0.05AJP (fuzzy) 0.55 0.96 0.70 0.17
Table 1. Melody track classification results.
As the results show, the fuzzyfied rule system performspoorly than the original crisp rule system. However, therecall is consistently better for the fuzzy classifier. It fol-lows that most errors are false positives, that is, somenon-melody tracks are classified as melody tracks.
6. Conclusions and further work
A fuzzy rule system for melody track characterization inMIDI files has been outlined. The somewhat poor perfor-mance of the fuzzy rule system could be improved by ris-ing the probability threshold for firing a fuzzy rule. Also,enforcing more than one fuzzy rule to be fired could helpimprove the results. A smarter way of fuzzifying rules (us-ing information theory measures) could be applied. Assome attributes appear to be more frequently used thanother in rule systems, weighting fuzzy sets proportionallyto their relative importance in the rules could be a way forimprovement.
Acknowledgments
Supported by the projects: GV06/166 and CICyTTIN2006–14932–C02, partially supported by EU ERDF.
ReferencesCohen, W. W. (1995). Fast effective rule induction. Machine
Learning: Proc.of the 12th Intl. Conf..
Cordón, O., & Herrera, F. (1995). A general study on geneticfuzzy systems. In J. Smith (Ed.), Genetic algorithms in en-gineering and computer science, chapter 3, 33–57.
Goto, M., et al. (2003). Rwc music database: Music genredatabase and musical instrument sound database. Proc. ofthe 4th Intl. Conf. on Music Information Retrieval (ISMIR)
Ponce de León, P. J., Rizo, D., & Iñesta, J. M. (2007). Towardsa human-friendly melody characterization by automaticallyinduced rules. Proc. of the 8th ISMIR (pp. 437–440).
Uitdenbogerd, A., & Zobel, J. (1999). Melodic matching tech-niques for large music databases. Proc. of the 7th ACM Intl.Multimedia Conf. (Part 1) (pp. 57–66).
1In the fuzzy rule system, the rule must be fired with proba-bility greater than 0.5.

D e te cti ng C ha ng e s i n M us i ca l Te xture
Atte Tenkanen Department of Musicology, University of Turku - Finland, [email protected]
Fernando Gualda Sonic Arts Research Centre, Queen’s University of Belfast - UK
Keywords: music analysis, pitch-class set theory, circle of fifths, comparison set analysis, fuzzy k-nn
Abstract
This paper presents an analytical method forexploring changes in musical texture, andthus, for finding the potential boundaries ofsections in a musical piece. It also presentsa new function which measures a pitch-classbased relation between two pitch-class sets.The method can be described as follows: Afeature vector is calculated for each note ina composition; each feature vector expressesthe changes between the textures before andafter the note associated with it; among allfeature vectors, an analyst can select themost significant ones which will act as classmembers in a fuzzy k-nn classifier; all the vec-tors derived from a score are thereafter in-put to the classifier. Then the k-nn classifiergenerates a curve graph which represents anoverview of textural changes in the piece.
1. Introduction
The music analytical method presented here is an ex-tension of the so called comparison set analysis (CSA)by Huovinen & Tenkanen (2008). In the CSA mu-sical units are segmented automatically into overlap-ping sets of same cardinality. These segments are thencompared with a similar type of comparison set usingsome similarity or distance measure. The comparisonset embodies a chosen musical property whose preva-lence is evaluated in a composition. The result can bepresented in the form of a time series plot.
Several musical features are utilized in the present pa-per. However, instead of selecting a comparison set foreach measurable feature separately, an analyst choosesby hand some notes which are associated with the in-teresting musical characters, here, changes in the mu-sical texture. These mark boundaries that may distin-guish and define musical events articulating the mu-sical form. In this case the ’comparison set’ consists
of selected feature vectors inputted as class membersto a fuzzy k-nn classifier (Keller et al. 1985). Thus,the classifier frees an analyst from defining the exactattributes for the group of comparison sets by learn-ing from the selected musical context, and forms amultidimensional member ensemble which works anal-ogously to the ’comparison set’. Information related toall notes is used thereafter for classifying all multidi-mensional moments in a piece. The method is appliedto the third movement of Symphony No. 5 by JeanSibelius.
2. Feature extraction
Harmonic, rhythmic and melodic data is preprocessedby segmenting the note information of the event list
using imbricated segmentation for each feature sepa-rately. Two consecutive time windows of equal size aremoved over the musical piece.
For simplicity, we consider only note onsets to pro-duce overlapping segments of set-classes and pitch-class sets. Vector types and relation functions used indistance measurements are presented in Table 1. RELsimilarity measure originates to David Lewin (1980).Overlapping rhythm sets are constructed from propor-tions between unique consecutive note onsets. In thecase of the first three vector types, all vectors associ-ated with the first window are compared with all thevectors in the other window. Averaged distances be-tween these windows, regarding to each feature, arecalculated and stored as feature vectors associated toeach ’borderline’ note in the piece. A new Circle-Of-Fifths (COF) based measure called cofrel (COF rela-tion) is used to evaluate relations between untrans-posed pitch-class sets. Instrumental melodic move-ments act as a source for normalized transition proba-bility matrices. ’Onset density ratio’ is calculated us-ing the number of unique onset ticks inside both win-dows. All the features were normalized to zero meanand unit variance.

Table 1. Vector types, relation functions and segmentation cardinalities used in the analysis.
Feature vectors Cardinality Distance/Similarity Relation measure
set-classes 4 RELpitch-class sets same segmentation cofrelrhythm sets 4 cosine distance
melodic transition vectors 4 euclidean dist. between transition probability matricesnote duration distributions - euclidean dist. between normalized distributions
onset density ratio - ratio: min(dens1/dens2, dens2/dens1), (≤ 1)
2.1. COF-relation -algorithm
To consider the relation between untransposed pitch-class sets a new algorithm was developed. By usingthe generator
⟨
7⟩
of a cyclic group Z12 under additionmodulo 12 all pitch classes can be obtained from agiven pitch class. This property allows distance mea-surements between any two pitch classes. The COF-distance between pc-sets a fifth apart is defined as 1, itfollows that the most distant pc-sets (e.g. C and F#)would have COF-distance of 6. To calculate the COF-based distance between any two pitch-class sets, it isintuitively acceptable and equitable to take all n ∗ m-pairs of COF-distances between the sets into account,where m and n are the cardinalities of the pitch-classsets. The COF-relation between two pitch-class sets
is: cofrel(A, B) =√
∑
i∈A,j∈B(cij)2/√
(|A| ∗ |B|)
where cij includes all the COF-distances between thepitch-class sets A and B.
3. Analysis example and some results
Eleven feature vectors connected to the lowest notes inthe beginning of bars 105, 165, 213, 221, 242, 371, 407,421, 427, 445 and 467 were selected as class 1 mem-ber vectors: There are remarkable changes in the tex-ture after those bars. Eleven randomly selected vectorswere used as the opposite class members (class 0) inthe fuzzy k-nn classifier (where k=5 and the fuzzifier1
m=2). The window widths were three bars for bothwindows. Training epochs run 100 times. Texture-change curve was created by calculating the bar basedmeans of all 100 distributions.
The most persistent and intensive texture changes takeplace after the bar 407 and between the bars 105-212where the main theme is strongly present. Unlike theother features, the rhythm set approach did not showany significant correlation (p ≫ 0.05) with the tex-ture classifier curve. However, there would be no need
1The fuzzifier m (> 1) determines how the membershipvalue varies with the distance which is weighted accordingto the rule d(x, y)−2/(m−1) (see Keller et al. 1985)
Figure 1. The intensity of the textural changes.
Figure 2. Histogram of textural changes.
for the traditional feature selection: On the contrary,if some of the features do not correlate with the re-sulting curve that gives information about the styleof the composition and the selected feature vectors.The histogram confirms that textural change occursat various intensities (almost evenly distributed) andthat the texture is nearly constant for about 140 bars(see Figure 2).
There are still several open issues related to segmenta-tion cardinalities and the selection of the class mem-bers which we expect to solve as we gain experiencewith the system.
4. References
Huovinen Erkki and Atte Tenkanen. 2008. Bird’s EyeViews of the Musical Surface - Methods for SystematicPitch-Class Set Analysis. Music Analysis 26(1-2).Keller, J. M., Gray, M. R., and Givens, J. A. 1985.A Fuzzy k-Nearest Neighbor Algorithm. IEEE Trans.Syst. Man. Cybern., SMC-15(4): 580-585.Lewin, David. 1980. A Response to a Response: OnPcset Relatedness. Perspectives of New Music 18(2):498-502.


















