
Multimodal Biometric Gait Database: A Comparison Study · 2014-11-28 · the recognition accuracy...
12
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty School of Information Technology and Engineering, Faculty of ESTeM University of Canberra, Australia Email: [email protected], [email protected] Abstract In this paper we have developed a robust human identification scheme from low-resolution surveillance video footage. For establishing the human identity; we also carried out a comparative study with two multimodal biometric databases (UCMG and CASIA), two different gait databases with different complexities. For experimental validation of our scheme, we used several dimensionality reduction algorithms (to reduce the dimensionality of the features) and examined number of classifiers to learn the identity model. This study established that gait biometric along with appropriate intelligent processing approaches can allow automatic identity verification from low resolution video surveillance footage. Keywords: Identification, UCMG, CASIA, Multimodal, Dimensionality, LDA-MLP 1. Introduction Several physiological and biomechanical studies have shown that human gait is a unique, an inherently multimodal biometric, and involves a complex kinematic interaction between several motion articulators, and includes interplay between lower and upper limbs and other biomechanics of joints[1]. In this paper, we propose that usage of full profile silhouettes (full gait) of persons from multi-view low resolution cameras for capturing inherently multi-modal cues available from the gait patterns of the walking humans, and use it for establishing their identity. Further, we propose the use of unsupervised feature learning techniques, based on variants of principal component analysis (vPCA) and deep learning (DL) approaches, which allow an in- depth analysis of the underlying pixel data. We compare these new features to standard features based on multivariate statistical techniques, such as PCA and linear discriminant analysis (LDA), along with well-known learning classifier approaches based on support vector machines, NN and MLP classifiers[2] [3], [4], [5]. The experimental evaluation of the proposed approach with two different databases, the publicly available CASIA [6] gait database, and the newly developed UCMG database [7], show a significant improvement in recognition performance with the proposed unsupervised learning features, particularly for uncooperative camera conditions, simulated with mismatched train and test data sets. 2. Background To address the next generation security and surveillance requirements for not just high security environments, but also for day-to-day civilian access control applications with low level security requirements, we need a robust and invariant biometric trait[3]. According to the authors in [8], the expectations of next generation identity verification involve, addressing issues related to application requirements, user concern and integration. Some of the suggestions made to address the requirements of these emerging applications were use of non-intrusive biometric traits, role of soft biometrics or dominant primary and non-dominant secondary identifiers and importance of novel automatic processing techniques[9]. To conform to these recommendations; often there is a need to combine multiple physiological and behavioral biometric cues, leading to so called multimodal biometric identification system. Each of the traits, physiological or behavioral have distinct advantages, for example; the behavioral biometrics can be collected non-obtrusively or even without the knowledge of the user. While most behavioral biometrics are not unique enough to provide reliable human identification they have been proved to be sufficiently high accurate [10]. Gait, is a similar powerful behavioral biometric, but as a single mode, on its own, it cannot be considered as a strong biometric to identify a person[11]. Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty Journal of Next Generation Information Technology (JNIT) Volume 5, Number 4, November 2014 71
Transcript of Multimodal Biometric Gait Database: A Comparison Study · 2014-11-28 · the recognition accuracy...

Multimodal Biometric Gait Database: A Comparison Study
Emdad Hossain, Girija Chetty School of Information Technology and Engineering, Faculty of ESTeM
University of Canberra, Australia Email: [email protected], [email protected]
Abstract
In this paper we have developed a robust human identification scheme from low-resolution surveillance video footage. For establishing the human identity; we also carried out a comparative study with two multimodal biometric databases (UCMG and CASIA), two different gait databases with different complexities. For experimental validation of our scheme, we used several dimensionality reduction algorithms (to reduce the dimensionality of the features) and examined number of classifiers to learn the identity model. This study established that gait biometric along with appropriate intelligent processing approaches can allow automatic identity verification from low resolution video surveillance footage.
Keywords: Identification, UCMG, CASIA, Multimodal, Dimensionality, LDA-MLP 1. Introduction
Several physiological and biomechanical studies have shown that human gait is a unique, an inherently multimodal biometric, and involves a complex kinematic interaction between several motion articulators, and includes interplay between lower and upper limbs and other biomechanics of joints[1]. In this paper, we propose that usage of full profile silhouettes (full gait) of persons from multi-view low resolution cameras for capturing inherently multi-modal cues available from the gait patterns of the walking humans, and use it for establishing their identity. Further, we propose the use of unsupervised feature learning techniques, based on variants of principal component analysis (vPCA) and deep learning (DL) approaches, which allow an in-depth analysis of the underlying pixel data. We compare these new features to standard features based on multivariate statistical techniques, such as PCA and linear discriminant analysis (LDA), along with well-known learning classifier approaches based on support vector machines, NN and MLP classifiers[2] [3], [4], [5]. The experimental evaluation of the proposed approach with two different databases, the publicly available CASIA [6] gait database, and the newly developed UCMG database [7], show a significant improvement in recognition performance with the proposed unsupervised learning features, particularly for uncooperative camera conditions, simulated with mismatched train and test data sets. 2. Background To address the next generation security and surveillance requirements for not just high security environments, but also for day-to-day civilian access control applications with low level security requirements, we need a robust and invariant biometric trait[3]. According to the authors in [8], the expectations of next generation identity verification involve, addressing issues related to application requirements, user concern and integration. Some of the suggestions made to address the requirements of these emerging applications were use of non-intrusive biometric traits, role of soft biometrics or dominant primary and non-dominant secondary identifiers and importance of novel automatic processing techniques[9]. To conform to these recommendations; often there is a need to combine multiple physiological and behavioral biometric cues, leading to so called multimodal biometric identification system. Each of the traits, physiological or behavioral have distinct advantages, for example; the behavioral biometrics can be collected non-obtrusively or even without the knowledge of the user. While most behavioral biometrics are not unique enough to provide reliable human identification they have been proved to be sufficiently high accurate [10]. Gait, is a similar powerful behavioral biometric, but as a single mode, on its own, it cannot be considered as a strong biometric to identify a person[11].
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
Journal of Next Generation Information Technology (JNIT) Volume 5, Number 4, November 2014
71
However, if we combine complementary gait information from another source, the multi-modal combination is expected to be powerful for human identification. Researchers have found that one of the most promising techniques is the use of multimodality or combination of different biometric traits or same biometric trait from multiple disparate sources. For example, researchers in [12], [13] have found that multi-modal scheme involving PCA on combined image of ear and face biometric results in significant improvement over either individual biometric. In addition, other recent attempts to improve the recognition accuracy include face, fingerprint and hand geometry [14]; face, fingerprint and speech [15]; face and iris [16]; face and ear [17]; and face and speech [18].
Figure 1. Sample Image from CASIA Database
Figure 2. Sample Image from UCMG Database
Furthermore, the power of automatic discovery of suitable feature representations extracted from disparate but complementary sources straight from pixels, that do not rely on elaborate computation intensive features and application-specific expert knowledge, and their fusion did not attract much attention from the research community. As opposed to traditional sophisticated computation intensive feature extraction stages, and use of domain specific expert knowledge to manually specify features, the proposed feature learning and discovery based on the variants of principal component analysis and the deep learning approach (DLP), seeks to optimize an objective function that captures the appropriateness of the features, and includes approaches based on energy minimization, manifold learning, and deep learning using auto-encoders [19], [20], [21]. Hence we applied DLP and vPCA to testify performance in compare to LDA and PCA.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
72

3. Methodology For dimensionality reduction and Eigen-value extraction, we used principle component analysis (PCA) and linear discriminant analysis (LDA), variant principle component analysis (vPCA), and deep learning approach (DLP), and to build supervised learning model of a person to be identified from extracted Eigen-value features, we used several powerful machine learning approaches like; SMO (sequential minimal optimization), SVM (support vector machine), MLP (multilayer perceptron) etc. 3.1. Principle Component Analysis Principle component analysis is a way of identifying patterns in data, and expressing the data in such a way as to highlight their similarities and differences. Since patterns in data can be hard to find in data of high dimension, where the luxury of graphical representation is not available, PCA is a powerful tool for analysing data. The other main advantage of PCA is that once we have found these patterns in the data, and we can compress the data, e.g. by reducing the number of dimensions, without much loss of information. Basically this technique used in image compression[22]. In the image analysis it works like;
X=(x1, x2, x3……N2)………………………………….(1) where the rows of pixels in the image are placed one after the other to form a one dimensional image. Each image is N pixels high by N pixels wide. For each image it creates an image vector. And then it counts all the images together in one big image-matrix like;
Matrix = (v1, v2, v3……vN)……………………….… (2) 3.2. Linear Discriminant Analysis On the other hand, the LDA also closely related to principal component analysis (PCA) and factor analysis in that they both look for linear combinations of variables which best explain the data. LDA explicitly attempts to model the difference between the classes of data. PCA on the other hand does not take into account any difference in class, and factor analysis builds the feature combinations based on differences rather than similarities. Discriminant analysis is also different from factor analysis in that it is not an interdependence technique: a distinction between independent variables and dependent variables (also called criterion variables) must be made. LDA works when the measurements made on independent variables for each observation are continuous quantities. When dealing with categorical independent variables, the equivalent technique is discriminant correspondence analysis[23]. 3.3. Multilayer Perceptron (MLP) As stated above, we applied number of difference classifiers but MLP is the best tools works for our experiments. However, Multi Layer perceptron (MLP) is a feed forward neural network with one or more layers between input and output layer. Feed forward means that data flows in one direction from input to output layer (forward). This type of network is trained with the back-propagation learning algorithm. MLPs are widely used for pattern classification, recognition, prediction and approximation. Multi Layer Perceptron can solve problems which are not linearly separable[2]. In our experiments we had 49 input layer, 800 hidden layer (for each data set) and 50 output layer. This is mostly based on dimensions, instances and the classes of the dataset. The details of the experiments are described in the experiment Section. 3.4. Variant of PCA Feature (v-PCA) PCA is a basic form of feature learning and it allows automatic discovery of compact and meaningful representation of raw data without relying complex feature extraction techniques or on domain specific (or expert) knowledge. It is a well-established technique used for de-correlation and dimensionality reduction of data. The variance of the original data is concentrated in low dimensional subspace
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
73

characterized by eigenvectors and eigenvalues. The projection of the original data onto the variance-maximizing sub-space serves as a feature representation, and automatic analysis of the eigenvalue spectrum of the sample covariance uncovers the appropriate target-dimensionality of the feature space. However, the PCA features perform poorly if the input data are not properly normalized. Using blind range normalization does not solve the problem especially when the components relate to completely different aspects of a phenomenon. In the context of gait recognition from multiple views this becomes problematic and to address this issue we developed an alternate representation based on the empirical cumulative distribution function (ECDF) of the gait silhouette/contour (x, y) from each frame. This representation is independent of the absolute ranges but preserves structural information. For every frame in the gait image sequence, we extract the silhouettes using background subtraction, and extraction of boundary contours, which serves as the gait silhouette. The xi contour points of silhouette are processed
by using an empirical cumulative distribution function ECDF, 퐸 of the whitened samples →푥 along each
axis (i=1, 2), using standard Kaplan-Meier estimation. These ECDFs, which monotonically increase within the range of zero to one, describe the probability that the 푥, 푦 co-ordinates of the
silhouette/contour points →푥 are less than or equal to some specific value. By means of cubic
interpolation ∁→
, the inverse of ECDF function, 퐸 at a fixed set of N points
푝→ = {푝 … … 푝 } is estimated, and this serves as the representation of →푥 of silhouette points. This
technique allows normalization of all contour points from images from multiple camera views to a common range, without destroying inherent structural independence (for i=1,2).
→푥 = 퐶 (퐸 (푥 )) ………………………………. (3)
where 퐸 = 푥 → 퐹푥 (푥 ) = 푃(푋 ≤ 푥 )
and 퐶→
= 푐푢푏푖푐 푖푛푡푒푟푝표푙푎푡푖표푛 푢푠푖푛푔 푝→ = {푝 … … … 푝 } We extracted the reduced dimensionality feature vector for ECDF normalized contour points for the gait silhouettes in each frame of the walking sequences in the datasets using PCA, and we call this as the variant of PCA, or vPCA features. 3.5. Deep Learning Feature (DLF) Hinton et al., [19] have proposed a powerful tool for generic semi-supervised discovery of features called auto encoder networks, which aim to learn a lower dimensional representation of input data. This produces a minimal error when used for reconstructing the original data. For auto encoder based feature learning on sequential data we used a novel deep learning approach. In this approach, the lower dimensional features are discovered by means of feed-forward neural networks that consist of one input layer, one output layer and an odd number of hidden layers. Every layer is fully connected to the adjacent layers and a non-linear activation function is used. The objective function during training is the reconstruction of the input data at the output layer. The auto encoder transmits a description of the input data across each layer of the network. This non-linear low-dimensional encoding is hence an automatically learned feature representation. For robust model training, we used the techniques suggested by Hinton et al., [19], where the layers of the autoencoder network are learnt greedily in a bottom-up procedure, by treating each pair of subsequent layers in the encoder as a Restricted Boltzmann Machine (RBM). An RBM is a fully connected, bipartite, two-layer graphical model, which is able to generatively model data. It trains a set of stochastic binary hidden units which effectively act as low-level feature detectors. One RBM is trained for each pair of subsequent layers by treating the activation probabilities of the feature detectors of one RBM as input-data for the next. Once the stack of RBMs is trained, the generative model is unrolled to obtain our final fully initialized auto encoder network for feature learning. Different methods exist to model real-valued input units in RBMs. We used Gaussian visible units for the first level RBM that activate binary, stochastic feature detectors (Gaussian-binary).
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
74

The subsequent layers rely on the common binary-binary RBM, and the final layer is a binary linear RBM, which effectively performs a linear projection. During training, the sample data is processed batch-wise, where each batch ideally comprises samples from all classes in the training-set. As the availability of the class information is not mandatory, we trained RBMs in a completely unsupervised manner. To evaluate the two feature learning approaches, vPCA and DLF features for gait based human identity recognition; we conducted a number of experiments using different subsets of data from the CASIA dataset B and UCMG database. For baseline comparison, we also extract standard PCA and LDA features. Further, we examined how these features perform with different classifiers and hence tested with Nearest Neighbor (NN), MLP, SVM and SMO classifiers [24][25][26][15][27][28]. 4. Experiments For experimental evaluation we used UCMG-Gait-Database [7] and CASIA Database [6]. The University of Canberra Multimodal Gait Database (UCMG-Database) has developed in University of Canberra in mid-2013. For a single person, it has seven (7) different types of walking pattern including (i) normal walking, (ii) fast walking, (iii) walking with heavy bag, (iv) walking with overcoat (long jacket), (v) walking with hat, (vi) walking with hoody and (vii) walking with mask. All theses of sequences has captured with four (4) different cameras in four (4) different dimensions including; 130 degree, 270 degree, 315 degree view point, and 315 degree from top (roof) with surveillance Camera. More than hundred (100) individual and around three thousand (3000) of different video-sequence contains in the UCBM-Database. In our research laboratory we have examine most the dataset that has described as follows;
For our first set of experiment we have used UCMG database and data taken from 270 degree
view point in a number of walking patterns such as; normal walking, fast walking, walking with hat, walking with long jacket, walking with mask, data taken real world CCTV. In total 11 dataset (person) processed for this experiment. In all dataset we have taken same people. Each people has 16 images, therefor we experimented 880 images for this experiment. Table 1 shows the accuracy of identification.
Table 1. Identification with LDA-MLP
No Dataset Number of Images
Classification Accuracy (%)
1 Normal walking 880 100% 2 Fast Walking 880 100% 3 Walking with Overcoat 880 100% 4 Walking with Hat 880 100% 5 Walking with Mask 864 100%
We tried to find out what are the variations if a person changes the walking style, dress and
appearance. By using mentioned algorithm and classifier we received equally 100% correction rate in detecting a person accurately. One most ground-breaking finding of this experiment is; to identify a person even they are using mask to cover their complete head. we received 100% correct detection in even if people using mask. Figure 3 and 4 shows the Eigen Images and PCA Eigen values.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
75
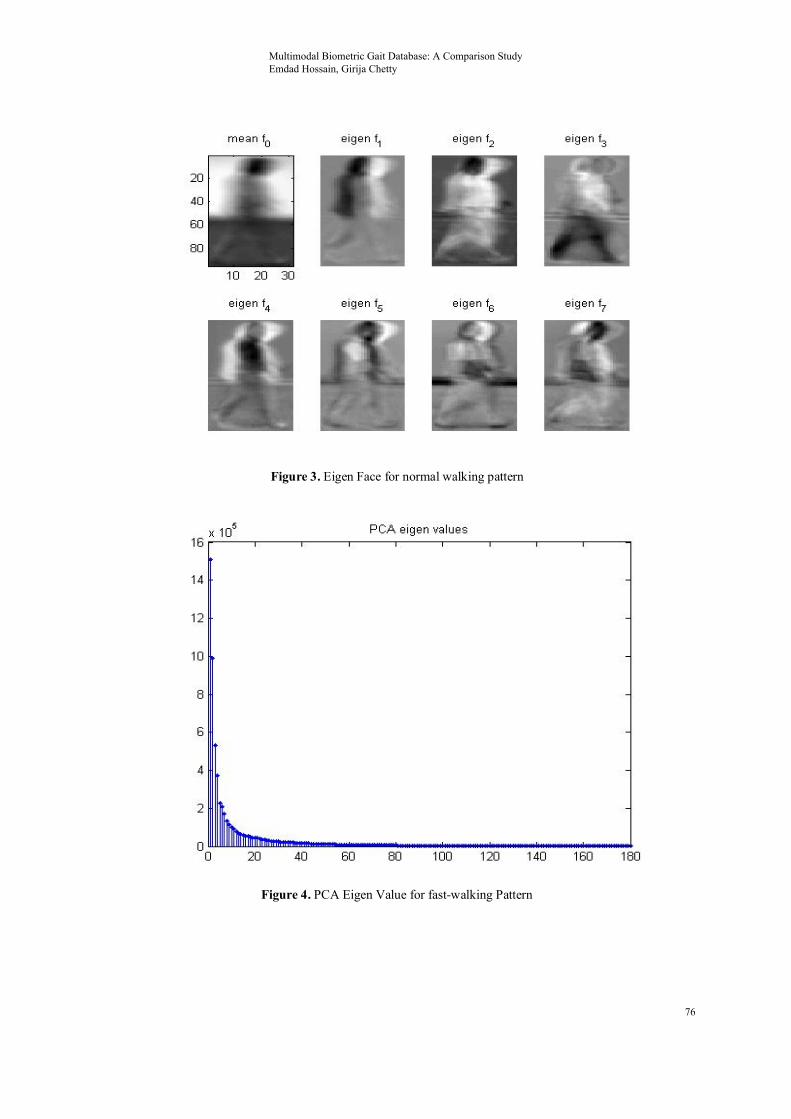
Figure 3. Eigen Face for normal walking pattern
Figure 4. PCA Eigen Value for fast-walking Pattern
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
76
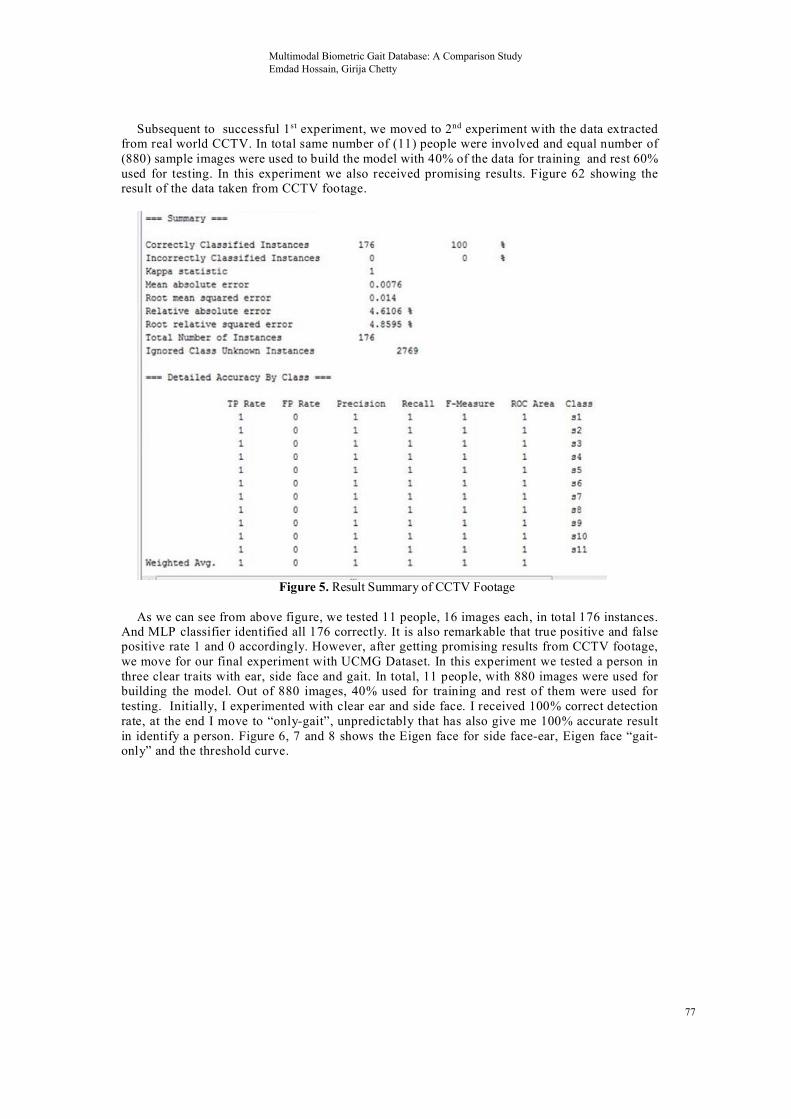
Subsequent to successful 1st experiment, we moved to 2nd experiment with the data extracted from real world CCTV. In total same number of (11) people were involved and equal number of (880) sample images were used to build the model with 40% of the data for training and rest 60% used for testing. In this experiment we also received promising results. Figure 62 showing the result of the data taken from CCTV footage.
Figure 5. Result Summary of CCTV Footage
As we can see from above figure, we tested 11 people, 16 images each, in total 176 instances.
And MLP classifier identified all 176 correctly. It is also remarkable that true positive and false positive rate 1 and 0 accordingly. However, after getting promising results from CCTV footage, we move for our final experiment with UCMG Dataset. In this experiment we tested a person in three clear traits with ear, side face and gait. In total, 11 people, with 880 images were used for building the model. Out of 880 images, 40% used for training and rest of them were used for testing. Initially, I experimented with clear ear and side face. I received 100% correct detection rate, at the end I move to “only-gait”, unpredictably that has also give me 100% accurate result in identify a person. Figure 6, 7 and 8 shows the Eigen face for side face-ear, Eigen face “gait-only” and the threshold curve.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
77
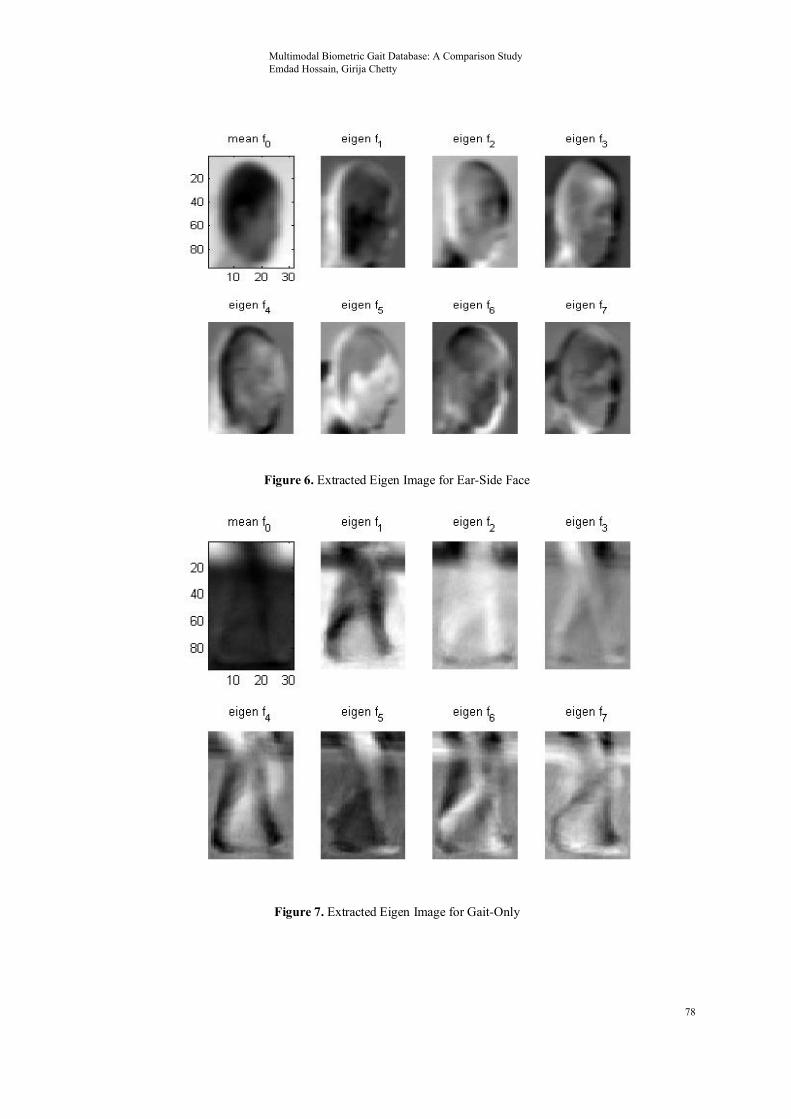
Figure 6. Extracted Eigen Image for Ear-Side Face
Figure 7. Extracted Eigen Image for Gait-Only
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
78
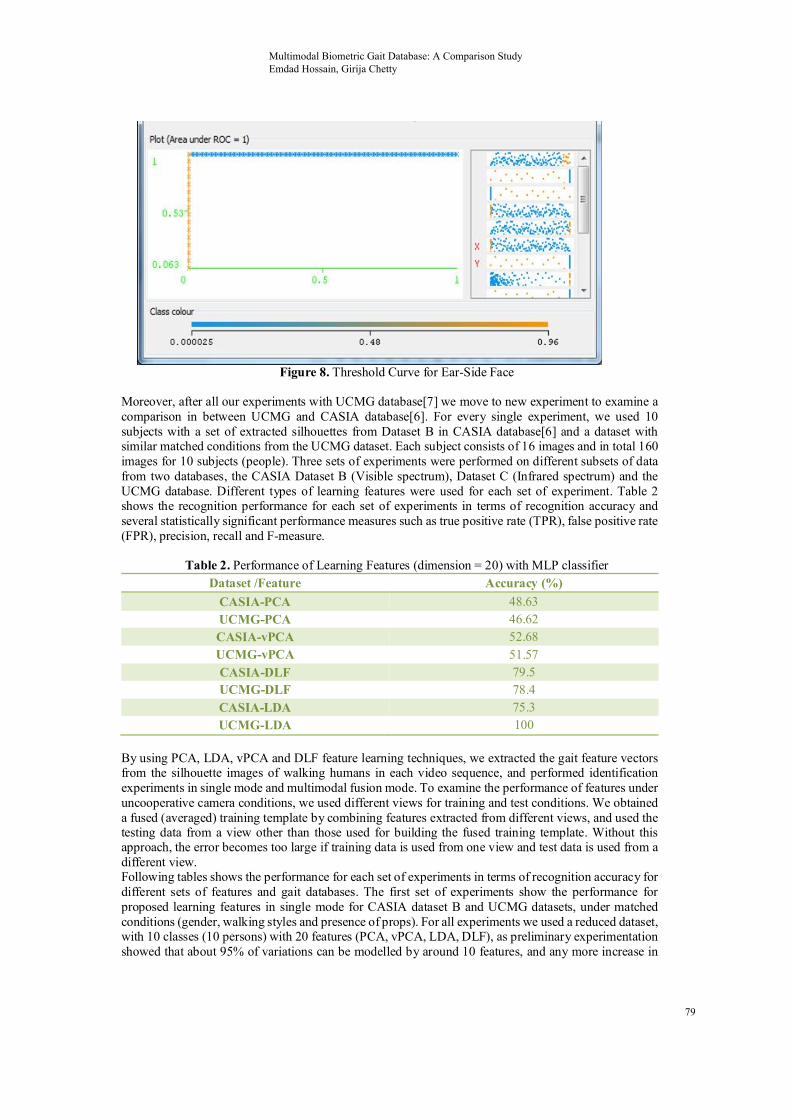
Figure 8. Threshold Curve for Ear-Side Face
Moreover, after all our experiments with UCMG database[7] we move to new experiment to examine a comparison in between UCMG and CASIA database[6]. For every single experiment, we used 10 subjects with a set of extracted silhouettes from Dataset B in CASIA database[6] and a dataset with similar matched conditions from the UCMG dataset. Each subject consists of 16 images and in total 160 images for 10 subjects (people). Three sets of experiments were performed on different subsets of data from two databases, the CASIA Dataset B (Visible spectrum), Dataset C (Infrared spectrum) and the UCMG database. Different types of learning features were used for each set of experiment. Table 2 shows the recognition performance for each set of experiments in terms of recognition accuracy and several statistically significant performance measures such as true positive rate (TPR), false positive rate (FPR), precision, recall and F-measure.
Table 2. Performance of Learning Features (dimension = 20) with MLP classifier Dataset /Feature Accuracy (%)
CASIA-PCA 48.63 UCMG-PCA 46.62 CASIA-vPCA 52.68 UCMG-vPCA 51.57 CASIA-DLF 79.5 UCMG-DLF 78.4 CASIA-LDA 75.3 UCMG-LDA 100
By using PCA, LDA, vPCA and DLF feature learning techniques, we extracted the gait feature vectors from the silhouette images of walking humans in each video sequence, and performed identification experiments in single mode and multimodal fusion mode. To examine the performance of features under uncooperative camera conditions, we used different views for training and test conditions. We obtained a fused (averaged) training template by combining features extracted from different views, and used the testing data from a view other than those used for building the fused training template. Without this approach, the error becomes too large if training data is used from one view and test data is used from a different view. Following tables shows the performance for each set of experiments in terms of recognition accuracy for different sets of features and gait databases. The first set of experiments show the performance for proposed learning features in single mode for CASIA dataset B and UCMG datasets, under matched conditions (gender, walking styles and presence of props). For all experiments we used a reduced dataset, with 10 classes (10 persons) with 20 features (PCA, vPCA, LDA, DLF), as preliminary experimentation showed that about 95% of variations can be modelled by around 10 features, and any more increase in
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
79
dimensionality does not result in significant improvement in performance. As we can see, in Table 2 the LDA and DLF performing very well. The second set of experiments involved testing whether other established classifiers with different kernels result in better performance, and is shown in Table 3. As can be seen in Table 3, for both datasets, simple nearest neighbour classifier outperforms other sophisticated SVM classifier for all kernel types, which could be due to better learning ability of DLF features.
Table 3. Performance of Learning Features (dimension = 20) for different classifiers Classifier Database Accuracy (%) TP FP Precision Recall F-Measure NN CASIA 92.5 0.93 0 0.93 0.93 0.93 NN UCMG 92.25 0.92 0 0.93 0.92 0.92 SVM-L CASIA 81.13 0.81 0 0.82 0.81 0.81 SVM-L UCMG 78.75 0.78 0 0.81 0.79 0.78 SVM-RBF CASIA 31.30 0.3 0.02 0.74 0.3 0.39 SVM-Poly CASIA 27.63 0.28 0.02 0.75 0.28 0.36 SVM-Sigmoid CASIA 29.13 0.29 0.02 0.74 0.29 0.38
Table 4. Performance of Decision Fusion of LDF and DLF Features (dimension = 20)
Classifier Database Accuracy (%) NN CASIA 92.5
MLP CASIA 92.25 SVM-L CASIA 81.13
NN UCMG 78.75 MLP UCMG 100%
SVM-L UCMG 27.63 The final set of experiments involved examining the decision level fusion of LDA and DLF features for different types of classifiers. As can be seen in Table 4, the decision fusion of UCMG dataset with LDA-MLP performing extremely well (100% accuracy) than the single mode features, particularly for NN and SVM classifier with linear kernels. 5. Conclusions In this paper we carried out a comparative study with learning features and machine learning approaches for automatic gait based human idenitifcation and validated with two multimodal biometric gait databases. For dimensionality reduction and feature extraction, we applied PCA, vPCA, LDA and DLF. To identify a person from extracted feature we applied different machine learning classifiers, including MLP, SMO, SVM etc. As can be seen above UCMG is giving more accurate result in comparing CASIA-database. In fact, with some classifiers; both dataset giving us poor result; this is because of feature extraction algorithm. In our first experiment; (UCMG-only) we applied, PCA and LDA for dimensionality reduction and feature extraction, but for “comparison-study” we applied vPCA and DLF instead. Hence we can summarize that, LDA and MLP is the best combination to identify person from low resolution surveillance video even for complex surveillance scenarios as present in the UCMG dataset , as compared to lesser complex video surveillance sceanario modelled in CASIA dataset.
6. References [1] P. J. Phillips, S. Sarkar, I. Robledo, P. Grother, and K. Bowyer, “The gait identification
challenge problem: data sets and baseline algorithm,” in 16th International Conference on Pattern Recognition, 2002. Proceedings, 2002, vol. 1, pp. 385–388 vol.1.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
80

[2] W. W. Azevedo and C. Zanchettin, “A MLP-SVM hybrid model for cursive handwriting recognition,” in The 2011 International Joint Conference on Neural Networks (IJCNN), 2011, pp. 843–850.
[3] J. Bringer and H. Chabanne, Biometric: Theory, Application and Issues. Nova Science Publishers, Inc., 2011.
[4] E. Hossain and G. Chetty, “Multimodal Identity Verification Based on Learning Face and Gait Cues,” in Neural Information Processing, vol. 7064, B.-L. Lu, L. Zhang, and J. Kwok, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 1–8.
[5] M. W. Girija Chetty, “Liveness detection using cross-modal correlations in face-voice person authentication.,” pp. 2181–2184, 2005.
[6] S. Zheng, “CASIA Gait Database,” Inst. Autom. Chin. Acad. Sci. Wwwsinobiometricscom. [7] E. Hossain and G. Chetty, “Multimodal Feature Learning For Gait Biometric Based Human
Identity Recognition,” in 20th International Conference on Neural Information Processing, Gaegu, South Korea, 2013, vol. 20.
[8] A. K. Jain, “Next Generation Biometrics,” Department of Computer Science & Engineering, Machigan State University, 10-2009.
[9] G. Chetty and M. Wagner, “Investigating feature-level fusion for checking liveness in face-voice authentication,” in Proceedings of the Eighth International Symposium on Signal Processing and Its Applications, 2005, 2005, vol. 1, pp. 66–69.
[10] L. Wang and X. Geng, Eds., Behavioral Biometrics for Human Identification: Intelligent Applications. IGI Global, 2009.
[11] M. Ashraf, G. Chetty, D. Tran, and D. Sharma, “A New Approach for Constructing Missing Features Values,” Int. J. Intell. Inf. Process., vol. 13, no. 1.11, pp. 1–9, Mar. 2012.
[12] S. Berretti, A. Del Bimbo, and P. Pala, “3D Face Recognition Using Isogeodesic Stripes,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 12, pp. 2162–2177, 2010.
[13] L. Yuan, Z. Mu, and Z. Xu, “Using Ear Biometrics for Personal Recognition,” in Advances in Biometric Person Authentication, S. Z. Li, Z. Sun, T. Tan, S. Pankanti, G. Chollet, and D. Zhang, Eds. Springer Berlin Heidelberg, 2005, pp. 221–228.
[14] A. Ross and A. Jain, “Information fusion in biometrics,” Pattern Recognit. Lett., vol. 24, p. 11, 2003.
[15] A. K. Jain, L. Hong, and Y. Kulkarni, “A multimodal biometric system using fingerprints, face and speech,” presented at the 2nd Int’l Conf. AVBPA, Washington, D.C., USA, 1999, pp. 182–187.
[16] Y. Wang, T. Tan, and A. K. Jain, “Combining Face and Iris Biometrics for Identity Verification,” presented at the 4th Int’l Conf. AVBPA, Guildford, UK, 2003, pp. 805–813.
[17] K. Chang, K. W. Bowyer, S. Sarkar, and B. Victor, “Comparison and Combination of Ear and Face Images in Appearance-Based Biometrics,” IEEE Comput. Soc., vol. 25, no. 9, pp. 1160–1165, 2003.
[18] J. Kittler, M. Hatef, R. P. W. Duin, and J. Matas, “On combining classifiers,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 20, no. 3, pp. 226–239, 1998.
[19] G. E. Hinton, “To recognize shapes, first learn to generate images,” Prog. Brain Res., vol. 165, pp. 535–547, 2007.
[20] X. Huo, X. (sherry Ni, and A. K. Smith, A SURVEY OF MANIFOLD-BASED LEARNING METHODS Emerging nonparametric methodology. .
[21] Y. Lecun, S. Chopra, R. Hadsell, F. J. Huang, G. Bakir, T. Hofman, B. Schölkopf, A. Smola, and B. T. (eds, “A tutorial on energy-based learning,” Predict. Struct. DATA, 2006.
[22] Zhou S, Chellappa R., “Beyond One Still Image: Face Recognition from Multiple Still Images or Video Sequence,” in Beyond a single still image: Face recognition from multiple still images and videos, New York: New York: Academic Press, 2005.
[23] G. Dai and Y. Qian, “A Gabor direct fractional-step LDA algorithm for face recognition,” in 2004 IEEE International Conference on Multimedia and Expo, 2004. ICME ’04, 2004, vol. 1, pp. 61–64 Vol.1.
[24] K. W. Bowyer, K. Chang, and P. Flynn, A survey of approaches and challenges in 3D and multi-modal 3D + 2D face recognition. 2005.
[25] S. G. Kong, J. Heo, B. R. Abidi, J. Paik, and M. A. Abidi, “Recent advances in visual and infrared face recognition - a review,” Comput. Vis. Image Underst., vol. 97, pp. 103–135, 2005.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
81

[26] Jianjiang Feng, Anil K. Jain, and Arun Ross, “Fingerprint Alteration,” Michigan State University, USA, MSu Technical Report MSU-CSE-09-30, 2009.
[27] S. M. E. Hossain and G. Chetty, “Next Generation Identity Verification Based on Face-Gait Biometrics,” in IPCBEE, KualaLumpur, Malaysia, 2011, vol. 11, pp. 142–148.
[28] P. Tsai, T. Phuoc, and L. Cao, “A New Multimodal Biometric for Personal Identification,” in Pattern Recognition Recent Advances, A. Herout, Ed. InTech, 2010.
Multimodal Biometric Gait Database: A Comparison Study Emdad Hossain, Girija Chetty
82

















