
ECE 4100/6100 Advanced Computer Architecture Lecture 13 Multithreading and Multicore Processors
Upload
nabendu-karmakarCategory
view
951download
1description

Na
be
nd
u K
ar
ma
ka
r
THE NEW
TREND IN
PROCESSOR
MAKING

Na
be
nd
u K
ar
ma
ka
r
The revolution of computer system has moved up enormously. From the age of heavy
handed bulky computers today we have moved to thinnest notebooks. From the age
of 4 bit Intel 4004 processors, we have moved up to Intel Core i7 extremes. From the
first computer named as ENIAC, we now have palmtops. There have been a lot of
changes in the way of computing. Machines have upgraded, we have moved to multi
core processors from the single core processors. Single core processors, who served
the computing generation for quite a long time is now vanishing. It’s the Multi-core
CPUs that are in charge. With lots of new functionality, great features, new up
gradation Multi-core processors are surely the future product.

Na
be
nd
u K
ar
ma
ka
r
Contents
1. Computers & Processors
1.1 Processors
2. A brief history of Microprocessor
2.1 Moore’s Law
3. Single Core Processor: A step behind
4. Past efforts to increase efficiency
5. Need of Multi-core CPU
6. Terminology
7. Multi-core Basics
8. Multi-core implementation
8.1 Intel & AMD Dual Core Processor
8.2 The CELL Processor
8.3 Tilera TILE64
9. Scalability potential of Multi-core processors
10. Multi-core Challenges
10.1 Power & Temperature
10.2 Cache Coherence
10.3 Multithreading
11. Open issues
11.1 Improved Memory Management
01
01
04
04
06
07
08
12
13
15
15
16
17
19
23
23
24
25
26
26

Na
be
nd
u K
ar
ma
ka
r
11.2 System Bus and Interconnection Networks
11.3 Parallel Programming
11.4 Starvation
11.5 Homogenous vs. Heterogonous Core
12. Multi-Core Advantages
12.1 Power and cooling advantages of multicore
processors
12.2 Significance of sockets in a multicore architecture
12.3 Evolution of software toward multicore technology
13. Licensing Consideration
14. Single Core vs. Multi Core
15. Commercial Incentives
16. Last Words
17. References Used
26
26
27
28
29
29
30
32
34
35
36
37
38

Na
be
nd
u K
ar
ma
ka
r
1 Multi-core Architecture
1. Computers & Processors:
Computers are machines that perform tasks or calculations according to a
set of instructions, or programs. The first fully electronic computer ENIAC
(Electronic Numerical Integrator and Computer) introduced in the 1946s was
a huge machine that required teams of people to operate. Compared to
those early machines, today's computers are amazing. Not only are they
thousands of times faster, they can fit on our desk, on our lap, or even in our
pocket.
Computers work through an interaction of hardware and software.
Hardware refers to the parts of a computer that we can see and touch,
including the case and everything inside it. The most important piece of
hardware is a tiny rectangular chip inside our computer called the central
processing unit (CPU), or microprocessor. It's the "brain" of your computer—
the part that translates instructions and performs calculations. Hardware
items such as your monitor, keyboard, mouse, printer, and other components
are often called hardware devices, or devices. Software refers to the
instructions, or programs, that tell the hardware what to do. A word-
processing program that you can use to write letters on your computer is a
type of software. The operating system (OS) is software that manages your
computer and the devices connected to it. Windows is a well-known
operating system.
1.1 Processors: Processors are said to be the brain of a computer system
which tells the entire system what to do and what not to. It is made up of
large number of transistors typically integrated onto a single die. In
computing, a processor is the unit that reads and executes program
instructions, which are fixed-length (typically 32 or 64 bit) or variable-length
chunks of data.
The data in the instruction tells the processor what to do. The
instructions are very basic things like reading data from memory or sending
data to the user display, but they are processed so rapidly that we
experience the results as the smooth operation of a program. Processors

Na
be
nd
u K
ar
ma
ka
r
2 Multi-core Architecture
were originally developed with only one core. The core is the part of the
processor that actually performs the reading and executing of instructions.
Single-core processors can process only one instruction at a time. Speeding
up the processor speed gave rise to the overall system also.
A multi-core processor is composed of two or more independent cores.
One can describe it as an integrated circuit which has two or more individual
processors (called cores in this sense). Manufacturers typically integrate the
cores onto a single integrated circuit die (known as a chip multiprocessor or
CMP), or onto multiple dies in a single chip package.
A many-core processor is one in which the number of cores is large
enough that traditional multi-processor techniques are no longer efficient
largely due to issues with congestion supplying sufficient instructions and
data to the many processors. This threshold is roughly in the range of several
tens of cores and probably requires a network on chip.
A dual-core processor contains two cores (Such as AMD Phenom II X2
or Intel Core Duo), a quad-core processor contains four cores (Such as the
AMD Phenom II X4 and Intel 2010 core line, which includes 3 levels of quad
core processors), and a hexa-core processor contains six cores (Such as the
AMD Phenom II X6 or Intel Core i7 Extreme Edition 980X). A multi-core
processor implements multiprocessing in a single physical package. Designers
may couple cores in a multi-core device tightly or loosely. For example, cores
may or may not share caches, and they may implement message passing or
shared memory inter-core communication methods. Common network
topologies to interconnect cores include bus, ring, 2-dimensional mesh, and
crossbar. Homogeneous multi-core systems include only identical cores, unlike
heterogeneous multi-core systems. Just as with single-processor systems,
cores in multi-core systems may implement architectures like superscalar,
VLIW, vector processing, SIMD, or multithreading. Multi-core processors are
widely used across many application domains including general-purpose,
embedded, network, digital signal processing (DSP), and graphics.
The amount of performance gained by the use of a multi-core
processor depends very much on the software algorithms and

Na
be
nd
u K
ar
ma
ka
r
3 Multi-core Architecture
implementation. In particular, the possible gains are limited by the fraction of
the software that can be parallelized to run on multiple cores simultaneously;
this effect is described by Amdahl's law. In the best case, so-called
embarrassingly parallel problems may realize speedup factors near the
number of cores, or beyond even that if the problem is split up enough to fit
within each processor's or core's cache(s) due to the fact that the much
slower main memory system is avoided. Many typical applications, however,
do not realize such large speedup factors. The parallelization of software is a
significant on-going topic of research.

Na
be
nd
u K
ar
ma
ka
r
4 Multi-core Architecture
2. A brief history of Microprocessors:
Intel manufactured the first microprocessor, the 4-bit 4004, in the early
1970s which was basically just a number-crunching machine. Shortly
afterwards they developed the 8008 and 8080, both 8-bit, and Motorola
followed suit with their 6800 which was equivalent to Intel’s 8080. The
companies then fabricated 16-bit microprocessors, Motorola had their 68000
and Intel the 8086 and 8088; the former would be the basis for Intel’s
80386 32-bit and later their popular Pentium lineup which were in the first
consumer-based PCs.
Fig 1. World’s first Single Core CPU
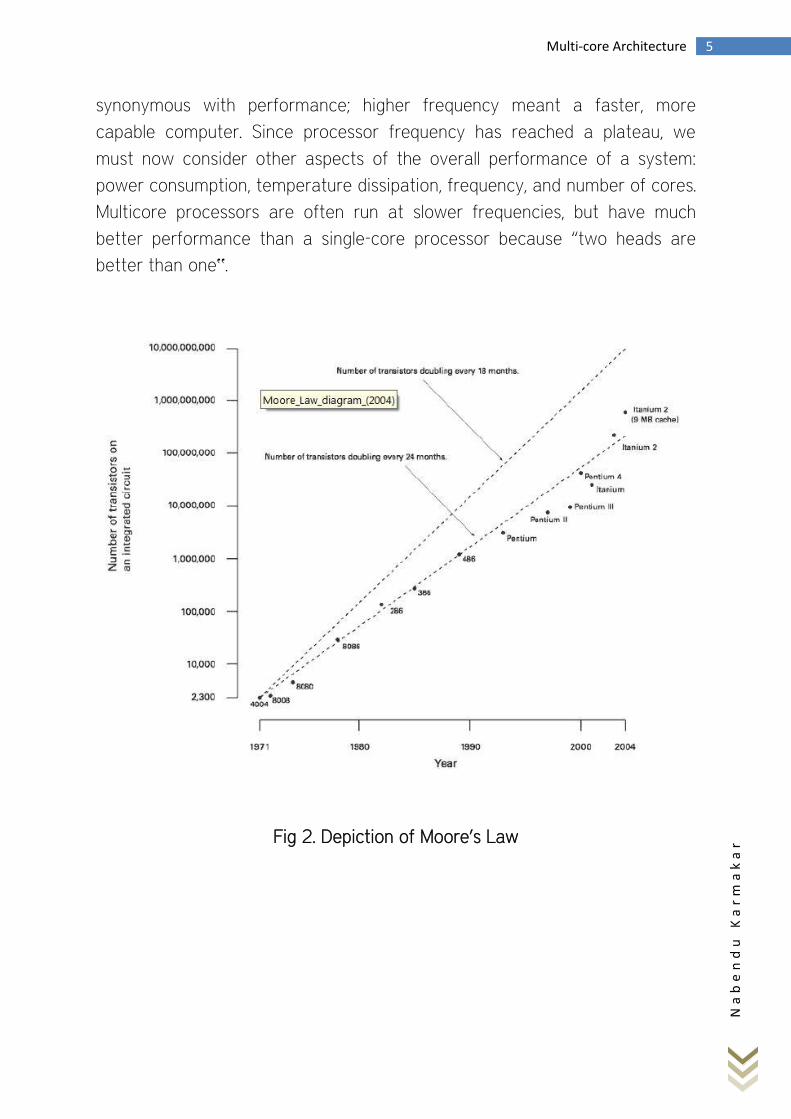
2.1 Moore’s Law: One of the guiding principles of computer architecture is
known as Moore’s Law. In 1965 Gordon Moore stated that the number of
transistors on a chip wills roughly double each year (he later refined this, in
1975, to every two years). What is often quoted as Moore’s Law is Dave
House’s revision that computer performances will double every 18 months.
The graph in Figure 1 plots many of the early microprocessors briefly
discussed in here:
As shown in Figure 2, the number of transistors has roughly doubled
every 2 years. Moore’s law continues to reign; for example, Intel is set to
produce the “world’s first 2 billion transistor microprocessor‟ “Tukwila” later
in 2008. House’s prediction, however, needs another correction. Throughout
the 1990‟s and the earlier part of this decade microprocessor frequency was
Na
be
nd
u K
ar
ma
ka
r
5 Multi-core Architecture
synonymous with performance; higher frequency meant a faster, more
capable computer. Since processor frequency has reached a plateau, we
must now consider other aspects of the overall performance of a system:
power consumption, temperature dissipation, frequency, and number of cores.
Multicore processors are often run at slower frequencies, but have much
better performance than a single-core processor because “two heads are
better than one‟.
Fig 2. Depiction of Moore’s Law

Na
be
nd
u K
ar
ma
ka
r
6 Multi-core Architecture
3. Single Core Processors: A step behind:
A single core processor is a processor which contains only one core. This kind
of processor was the trend of early computing system.
At a high level, the single core processor architecture consists of
several parts: the processor core, two levels of cache, a memory controller
(MCT), three coherent HyperTransport™ (cHT) links, and a non-blocking
crossbar switch that connects the parts together. A single-core Opteron
processor design is illustrated in Figure 1. The cHT links may be connected to
another processor or to peripheral devices. The NUMA design is apparent
from the diagram, as each processor in a system has its own local memory,
memory to which it is closer than any other processor. Memory commands
may come from the
local core or from
another processor
or a device over a
cHT link.
In the latter
case the command
comes from the
cHT link to the
crossbar and from
there to the MCT.
Fig 3. Single core processors block diag.
The local processor core does not see or have to process outside
memory commands, although some commands may cause data in cache to
be invalidated or flushed from cache.

Na
be
nd
u K
ar
ma
ka
r
7 Multi-core Architecture
4. Past efforts to increase efficiency:
As touched upon above, from the introduction of Intel’s 8086 through
the Pentium 4 an increase in performance, from one generation to the next,
was seen as an increase in processor frequency. For example, the Pentium 4
ranged in speed (frequency) from 1.3 to 3.8 GHz over its 8 year lifetime. The
physical size of chips decreased while the number of transistors per chip
increased; clock speeds in-creased which boosted the heat dissipation across
the chip to a dangerous level. To gain performance within a single core many
techniques are used. Superscalar processors with the ability to issue multiple
instructions concurrently are the standard. In these pipelines, instructions are
pre-fetched, split into sub-components and executed out-of-order. A major
focus of computer architects is the branch instruction.
Branch instructions are the equivalent of a fork in the road; the
processor has to gather all necessary information before making a decision.
In order to speed up this process, the processor predicts which path will be
taken; if the wrong path is chosen the processor must throw out any data
computed while taking the wrong path and backtrack to take the correct
path. Often even when an incorrect branch is taken the effect is equivalent
to having waited to take the correct path. Branches are also removed using
loop unrolling and sophisticated neural network-based predict-tors are used
to minimize the miss prediction rate. Other techniques used for performance
enhancement include register renaming, trace caches, reorder buffers,
dynamic/software scheduling, and data value prediction. There have also
been advances in power- and temperature-aware architectures. There are
two flavors of power-sensitive architectures: low-power and power-aware
designs. Low-power architectures minimize power consumption while
satisfying performance constraints, e.g. embedded systems where low-power
and real-time performance are vital. Power-aware architectures maximize
performance parameters while satisfying power constraints. Temperature-
aware design uses simulation to determine where hot spots lie on the chips
and revises the architecture to decrease the number and effect of hot spots.

Na
be
nd
u K
ar
ma
ka
r
8 Multi-core Architecture
5. Need of Multi-core CPUs:
It is well-recognized that computer processors have increased in speed
and decreased in cost at a tremendous rate for a very long time. This
observation was first made popular by Gordon Moore in 1965, and is
commonly referred to as Moore’s Law. Specifically, Moore’s Law states that
the advancement of electronic manufacturing technology makes it possible
to double the number of transistors per unit area about every 12 to 18
months. It is this advancement that has fueled the phenomenal growth in
computer speed and accessibility over more than four decades. Smaller
transistors have made it possible to increase the number of transistors that
can be applied to processor functions and reduce the distance signals must
travel, allowing processor clock frequencies to soar. This simultaneously
increases system performance and reduces system cost.
All of this is well-understood. But lately Moore’s Law has begun to show
signs of failing. It is not actually Moore’s Law that is showing weakness, but
the performance increases people expect and which occur as a side effect of
Moore’s Law. One often associates performance with high processor clock
frequencies. In the past, reducing the size of transistors has meant reducing
the distances between the transistors and decreasing transistor switching
times. Together, these two effects have contributed significantly to faster
processor clock frequencies. Another reason processor clocks could increase
is the number of 2 transistors available to implement processor functions.
Most processor functions, for example, integer addition, can be implemented
in multiple ways. One method uses very few transistors, but the path from
start to finish is very long. Another method shortens the longest path, but it
uses many more transistors. Clock frequencies are limited by the time it
takes a clock signal to cross the longest path within any stage. Longer paths
require slower clocks.
Having more transistors to work with allows more sophisticated
implementations that can be clocked more rapidly. But there is a down side.
As processor frequencies climb, the amount of waste heat produced by the
processor climbs with it. The ability to cool the processor inexpensively within
the last few years has become a major factor limiting how fast a processor

Na
be
nd
u K
ar
ma
ka
r
9 Multi-core Architecture
can go. This is offset, somewhat, by reducing the transistor size because
smaller transistors can operate on lower voltages, which allows the chip to
produce less heat. Unfortunately, transistors are now so small that the
quantum behavior of electrons can affect their operation. According to
quantum mechanics, very small particles such as electrons are able to
spontaneously tunnel, at random, over short distances. The transistor base
and emitter are now close enough together that a measurable number of
electrons can tunnel from one to the other, causing a small amount of
leakage current to pass between them, which causes a small short in the
transistor.
As transistors decrease in size, the leakage current increases. If the
operating voltages are too low, the difference between a logic one and a
logic zero becomes too close to the voltage due to quantum tunneling, and
the processor will not operate. In the end, this complicated set of problems
allows the number of transistors per unit area to increase, but the operating
frequency must go down in order to be able to keep the processor cool.
This issue of cooling the processor places processor designers in a
dilemma. The approach toward making higher performance has changed. The
market has high expectations that each new generation of processor will be
faster than the previous generation; if not, why buy it? But quantum
mechanics and thermal constraints may actually make successive
generations slower. On the other hand, later generations will also have more
transistors to work with and they will require less power.
Speeding up processor frequency had run its course in the earlier part
of this decade; computer architects needed a new approach to improve
performance. Adding an additional processing core to the same chip would, in
theory, result in twice the performance and dissipate less heat; though in
practice the actual speed of each core is slower than the fastest single core
processor. In September 2005 the IEE Review noted that “power
consumption increases by 60% with every 400MHz rise in clock speed”.
So, what is a designer to do? Manufacturing technology has now
reached the point where there are enough transistors to place two processor

Na
be
nd
u K
ar
ma
ka
r
10 Multi-core Architecture
cores – a dual core processor – on a single chip. The trade-off that must now
be made is that each processor core is slower than a single-core processor,
but there are two cores, and together they may be able to provide greater
throughput even though the individual cores are slower. Each following
generation will likely increase the number of cores and decrease the clock
frequency.
The slower clock speed has significant implications for processor
performance, especially in the case of the AMD Opteron processor. The
fastest dual-core Opteron processor will have higher throughput than the
fastest single-core Opteron, at least for workloads that are processor-core
limited, but each task may be completed more slowly. The application does
not spend much time waiting for data to come from memory or from disk,
but finds most of its data in registers or cache. Since each core has its own
cache, adding the second core doubles the available cache, making it easier
for the working set to fit.
For dual-core to be effective, the work load must also have parallelism
that can use both cores. When an application is not multi-threaded, or it is
limited by memory performance or by external devices such as disk drives,
dual-core may not offer much benefit, or it may even deliver less
performance. Opteron processors use a memory controller that is integrated
into the same chip and is clocked at the same frequency as the processor.
Since dual-core processors use a slower clock, memory latency will be slower
for dual-core Opteron processors than for single-core, because commands
take longer to pass through the memory controller.
Applications that perform a lot of random access read and write
operations to memory, applications that are latency-bound, may see lower
performance using dual-core. On the other hand, memory bandwidth
increases in some cases. Two cores can provide more sequential requests to
the memory controller than can a single core, which allows the controller to
intern eave commands to memory more efficiently.
Another factor that affects system performance is the operating
system. The memory architecture is more complex, and an operating system

Na
be
nd
u K
ar
ma
ka
r
11 Multi-core Architecture
not only has to be aware that the system is NUMA (that is, it has Non-
Uniform Memory Access), but it must also be prepared to deal with the more
complex memory arrangement. It must be dual-core-aware. The performance
implications of operating systems that are dual-core-aware will not be
explored here, but we state without further justification that operating
systems without such awareness show considerable variability when used
with dual-core processors. Operating systems that are dual-core-aware show
better performance, though there is still room for improvement.

Na
be
nd
u K
ar
ma
ka
r
12 Multi-core Architecture
6. Terminology:
The terms multi-core and dual-core most commonly refer to some sort of
central processing unit (CPU), but are sometimes also applied to digital signal
processors (DSP) and system-on-a-chip (SoC).
Additionally, some use these terms to refer only to multi-core
microprocessors that are manufactured on the same integrated circuit die.
These people generally refer to separate microprocessor dies in the same
package by another name, such as multi-chip module. This article uses both
the terms "multi-core" and "dual-core" to reference microelectronic CPUs
manufactured on the same integrated circuit, unless otherwise noted.
In contrast to multi-core systems, the term multi-CPU refers to multiple
physically separate processing-units (which often contain special circuitry to
facilitate communication between each other). The terms many-core and
massively multi-core sometimes occur to describe multi-core architectures
with an especially high number of cores (tens or hundreds). Some systems
use many soft microprocessor cores placed on a single FPGA. Each "core"
can be considered a "semiconductor intellectual property core" as well as a
CPU core.

Na
be
nd
u K
ar
ma
ka
r
13 Multi-core Architecture
7. Multi-Core Basics:
The following isn’t specific to any one multicore design, but rather is a
basic overview of multi-core architecture. Although manufacturer designs
differ from one another, multicore architectures need to adhere to certain
aspects. The basic configuration of a microprocessor is seen in Figure 4.
Closest to the processor is Level 1 (L1) cache; this is very fast memory
used to store data frequently used by the processor. Level 2 (L2) cache is
just off-chip, slower than L1 cache, but still much faster than main memory;
L2 cache is larger than L1 cache and used for the same purpose. Main
memory is very large and slower than cache and is used, for example, to
store a file currently being edited in Microsoft Word. Most systems have
between 1GB to 4GB of main memory compared to approximately 32KB of
L1 and 2MB of L2 cache. Finally, when data isn’t located in cache or main
memory the system must retrieve it
from the hard disk, which takes
exponentially more time than reading
from the memory system.
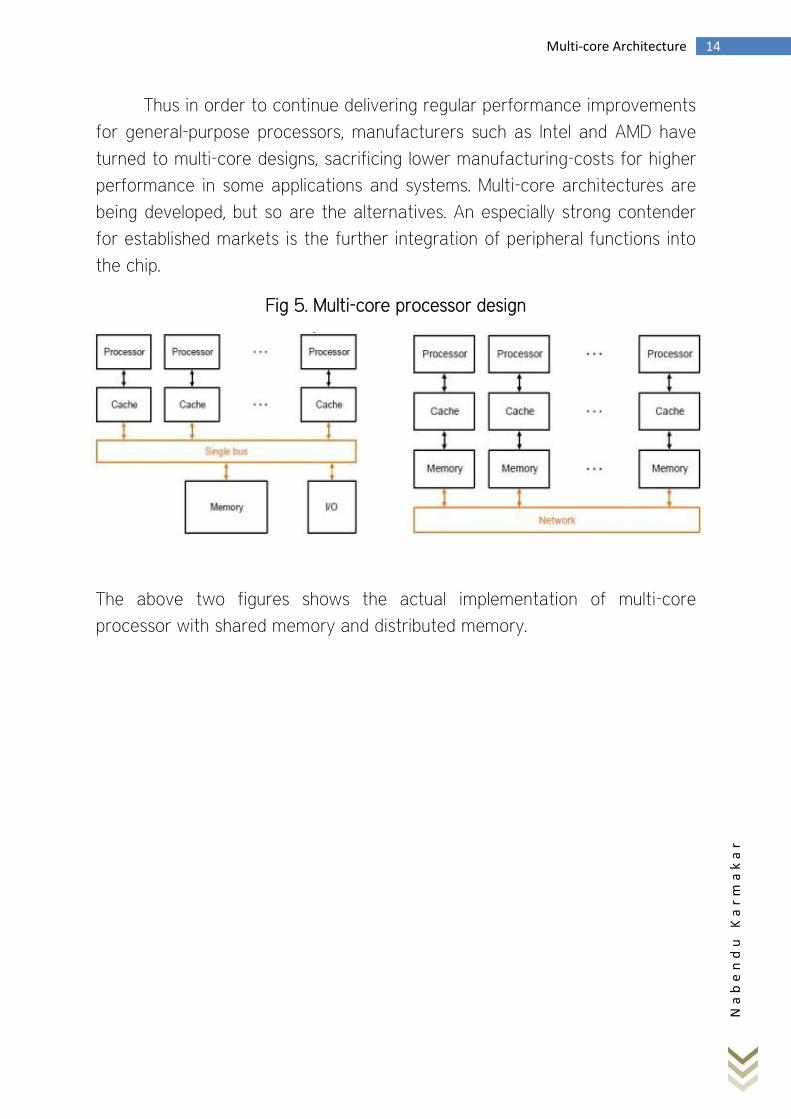
If we set two cores side-by-side,
one can see that a method of
communication between the cores,
and to main memory, is necessary.
This is usually accomplished either
using a single communication bus or
an interconnection network. The bus
approach is used with a shared
memory model, whereas the inter-
connection network approach is used
with a distributed memory model.
Fig 4. Generic modern Processor Configuration
After approximately 32 cores the bus is overloaded with the amount of
processing, communication, and competition, which leads to diminished
performance; therefore, a communication bus has a limited scalability.
Na
be
nd
u K
ar
ma
ka
r
14 Multi-core Architecture
Thus in order to continue delivering regular performance improvements
for general-purpose processors, manufacturers such as Intel and AMD have
turned to multi-core designs, sacrificing lower manufacturing-costs for higher
performance in some applications and systems. Multi-core architectures are
being developed, but so are the alternatives. An especially strong contender
for established markets is the further integration of peripheral functions into
the chip.
Fig 5. Multi-core processor design
The above two figures shows the actual implementation of multi-core
processor with shared memory and distributed memory.

Na
be
nd
u K
ar
ma
ka
r
15 Multi-core Architecture
8. Multi-core Implementation:
As with any technology, multicore architectures from different manufacturers
vary greatly. Along with differences in communication and memory
configuration another variance comes in the form of how many cores the
microprocessor has. And in some multicore architecture different cores have
different functions, hence they are heterogeneous. Differences in
architectures are discussed below for Intel’s Core 2 Duo, Advanced Micro
Devices‟ Athlon 64 X2, Sony-Toshiba- IBM‟s CELL Processor, and finally
Tilera’s TILE64.
8.1 Intel & AMD Dual-Core Processor:
Intel and AMD are the mainstream manufacturers of microprocessors.
Intel produces many different flavors of multicore processors: the Pentium D
is used in desktops, Core 2 Duo is used in both laptop and desktop
environments, and the Xeon processor is used in servers. AMD has the Althon
lineup for desktops, Turion for laptops, and Opteron for servers/workstations.
Although the Core 2 Duo and Athlon 64 X2 run on the same platforms their
architectures differ greatly.
Fig 6. (a) Intel Core 2 Duo (b) AMD Athlon 64 X2
Figure 6 shows block diagrams for the Core 2 Duo and Athlon 64 X2,
respectively. Both the Intel and AMD popular in the market of
Microprocessors. Both architectures are homogenous dual-core processors.

Na
be
nd
u K
ar
ma
ka
r
16 Multi-core Architecture
The Core 2 Duo adheres to a shared memory model with private L1 caches
and a shared L2 cache which “provides a peak transfer rate of 96 GB/sec.”
If a L1 cache miss occurs both the L2 cache and the second core’s L1 cache
are traversed in parallel before sending a request to main memory. In
contrast, the Athlon follows a distributed memory model with discrete L2
caches. These L2 caches share a system request interface, eliminating the
need for a bus. The system request interface also connects the cores with an
on-chip memory controller and an interconnect called HyperTransport.
HyperTransport effectively reduces the number of buses required in a
system, reducing bottlenecks and increasing bandwidth. The Core 2 Duo
instead uses a bus interface. The Core 2 Duo also has explicit thermal and
power control unit’s on-chip. There is no definitive performance advantage of
a bus vs. an interconnect, and the Core 2 Duo and Athlon 64 X2 achieve
similar performance measures, each using a different communication
protocol.
8.2 The CELL processor:
A Sony-Toshiba-IBM partnership (STI) built the CELL processor for use in
Sony’s PlayStation 3, therefore, CELL is highly customized for
gaming/graphics rendering which means superior processing power for
gaming applications.
Fig 7. CELL processor
The CELL is a
heterogeneous multicore
processor consisting of nine
cores, one Power Processing
Element (PPE) and eight
Synergistic Processing
Elements (SPEs), as can be
seen in Figure 7. With
CELL‟s real-time broadband
architecture, 128 concurrent

Na
be
nd
u K
ar
ma
ka
r
17 Multi-core Architecture
transactions to memory per processor are possible. The PPE is an extension
of the 64-bit PowerPC architecture and manages the operating system and
control functions. Each SPE has simplified instruction sets which use 128-bit
SIMD instructions and have 256KB of local storage. Direct Memory Access is
used to transfer data between local storage and main memory which allows
for the high number of concurrent memory transactions. The PPE and SPEs
are connected via the Element Interconnect Bus providing internal
communication. Other interesting features of the CELL are the Power
Management Unit and Thermal Management Unit. Power and temperature
are fundamental concerns in microprocessor design. The PMU allows for
power reduction in the form of slowing, pausing, or completely stopping a
unit. The TMU consists of one linear sensor and ten digital thermal sensors
used to monitor temperature throughout the chip and provide an early
warning if temperatures are rising in a certain area of the chip. The ability to
measure and account for power and temperature changes has a great
advantage in that the processor should never overheat or draw too much
power.
8.3 Tilera TILE64:
Tilera has developed a multicore chip with 64 homogeneous cores set
up in a grid, shown in Figure 8.
Fig 8. Tilera
TILE64
An
application that
is written to
take advantage
of these
additional cores
will run far

Na
be
nd
u K
ar
ma
ka
r
18 Multi-core Architecture
faster than if it were run on a single core. Imagine having a project to finish,
but instead of having to work on it alone you have 64 people to work for
you. Each processor has its own L1 and L2 cache for a total of 5MB on-chip
and a switch that connects the core into the mesh network rather than a bus
or interconnect. The TILE64 also includes on-chip memory and I/O
controllers. Like the CELL processor, unused tiles (cores) can be put into a
sleep mode to further decrease power consumption. The TILE64 uses a 3-
way VLIW (very long instruction word) pipeline to deliver 12 times the
instructions as a single-issue, single-core processor. When VLIW is combined
with the MIMD (multiple instructions, multiple data) processors, multiple
operating systems can be run simultaneously and advanced multimedia
applications such as video conferencing and video-on-demand can be run
efficiently.

Na
be
nd
u K
ar
ma
ka
r
19 Multi-core Architecture
9. Scalability potential of multicore processors:
Processors plug into the system board through a socket. Current technology
allows for one processor socket to provide access to one logical core. But
this approach is expected to change, enabling one processor socket to
provide access to two, four, or more processor cores. Future processors will
be designed to allow multiple processor cores to be contained inside a single
processor module. For example, a tightly coupled set of dual processor cores
could be designed to compute independently of each other—allowing
applications to interact with the processor cores as two separate processors
even though they share a single socket. This design would allow the OS to
“thread” the application across the multiple processor cores and could help
improve processing efficiency.
A multicore structure would also include cache modules. These modules could
either be shared or independent. Actual implementations of multicore
processors would vary depending on manufacturer and product development
over time. Variations may include shared or independent cache modules, bus
implementations, and additional threading capabilities such as Intel Hyper-
Threading (HT) Technology. A multicore arrangement that provides two or
more low-clock speed cores could be designed to provide excellent
performance while minimizing power consumption and delivering lower heat
output than configurations that rely on a single high-clock-speed core. The
following example shows how multicore technology could manifest in a
standard server configuration and how multiple low-clock-speed cores could
deliver greater performance than a single high-clock-speed core for
networked applications.
This example uses some simple math and basic assumptions about the
scaling of multiple processors and is included for demonstration purposes
only. Until multicore processors are available, scaling and performance can
only be estimated based on technical models. The example described in this
article shows one possible method of addressing relative performance levels
as the industry begins to move from platforms based on single-core
processors to platforms based on multicore processors. Other methods are
possible, and actual processor performance and processor scalability are tied

Na
be
nd
u K
ar
ma
ka
r
20 Multi-core Architecture
to a variety of platform variables, including the specific configuration and
application environment. Several factors can potentially affect the internal
scalability of multiple cores, such as the system compiler as well as
architectural considerations including memory, I/O, front side bus (FSB), chip
set, and so on. For instance, enterprises can buy a dual-processor server
today to run Microsoft Exchange and provide e-mail, calendaring, and
messaging functions. Dual-processor servers are designed to deliver excellent
price/performance for messaging applications.
A typical configuration might use dual 3.6 GHz 64-bit Intel Xeon™
processors supporting HT Technology. In the future, organizations might
deploy the same application on a similar server that instead uses a pair of
dual-core processors at a clock speed lower than 3.6 GHz. The four cores in
this example configuration might each run at 2.8 GHz. The following simple
example can help explain the relative performance of a low-clock-speed,
dual-core processor versus a high-clock-speed, dual-processor counterpart.
Dual-processor systems available today offer a scalability of roughly 80
percent for the second processor, depending on the OS, application, compiler,
and other factors.
That means the first processor may deliver 100 percent of its processing
power, but the second processor typically suffers some overhead from
multiprocessing activities. As a result, the two processors do not scale
linearly—that is, a dual-
processor system does not
achieve a 200 percent
performance increase over
a single-processor system,
but instead provides
approximately 180 percent
of the performance that a
single-processor system
provides. In this article, the
Fig 9. Sample core speed and anticipated total relative power in a system using two single-core processors

Na
be
nd
u K
ar
ma
ka
r
21 Multi-core Architecture
single-core scalability factor is referred to as external, or socket-to-socket,
scalability. When comparing two single-core processors in two individual
sockets, the dual 3.6 GHz processors would result in an effective
performance level of approximately 6.48 GHz (see Figure 9).
For multicore processors, administrators must take into account not
only socket-to-socket scalability but also internal, or core-to-core, scalability—
the scalability between multiple cores that reside within the same processor
module. In this example, core-to-core scalability is estimated at 70 percent,
meaning that the second core delivers 70 percent of its processing power.
Thus, in the example system using 2.8 GHz dual-core processors, each dual-
core processor would behave more like a 4.76 GHz processor when the
performance of the two cores—2.8 GHz plus 1.96 GHz—is combined.
For demonstration purposes, this example assumes that, in a server
that combines two such dual-core processors within the same system
architecture, the socket-
to-socket scalability of
the two dual core
processors would be
similar to that in a server
containing two single-
core processors—80
percent scalability. This
would lead to an effective
performance level of 8.57
GHz (see Figure 10).
Fig 10. Sample core speed and anticipated total relative power in a system using two dual-core processors
To continue the example comparison by postulating that socket to-
socket scalability would be the same for these two architectures, a multicore
architecture could enable greater performance than a single-core processor
architecture, even if the processor cores in the multicore architecture are
running at a lower clock speed than the processor cores in the single-core

Na
be
nd
u K
ar
ma
ka
r
22 Multi-core Architecture
architecture. In this way, a multicore architecture has the potential to deliver
higher performance than single-core architecture for enterprise applications.
Ongoing progress in processor designs has enabled servers to continue
delivering increased performance, which in turn helps fuel the powerful
applications that support rapid business growth.
However, increased performance incurs a corresponding increase in
processor power consumption—and heat is a consequence of power use. As a
result, administrators must determine not only how to supply large amounts
of power to systems, but also how to contend with the large amounts of heat
that these systems generate in the data center.

Na
be
nd
u K
ar
ma
ka
r
23 Multi-core Architecture
10. Multi-core Challenges:
Having multiple cores on a single chip gives rise to some problems and
challenges. Power and temperature management are two concerns that can
increase exponentially with the addition of multiple cores. Memory/cache
coherence is another challenge, since all designs discussed above have
distributed L1 and in some cases L2 caches which must be coordinated. And
finally, using a multicore processor to its full potential is another issue. If
programmers don’t write applications that take advantage of multiple cores
there is no gain, and in some cases there is a loss of performance.
Application need to be written so that different parts can be run concurrently
(without any ties to another part of the application that is being run
simultaneously).
10.1 Power and Temperature:
If two cores were placed on a single chip without any modification, the chip
would, in theory, consume twice as much power and generate a large
amount of heat.
In the extreme case, if a processor overheats your computer may even
combust. To account for this each design above runs the multiple cores at a
lower frequency to reduce power consumption. To combat unnecessary
power consumption many designs also incorporate a power control unit that
has the authority to shut down unused cores or limit the amount of power.
By powering off unused cores and using clock gating the amount of leakage
in the chip is reduced.
To lessen the heat generated by multiple cores on a single chip, the
chip is architected so that the number of hot spots doesn’t grow too large
and the heat is spread out across the chip. As seen in Figure 7, the majority
of the heat in the CELL processor is dissipated in the Power Processing
Element and the rest is spread across the Synergistic Processing Elements.
The CELL processor follows a common trend to build temperature monitoring
into the system, with its one linear sensor and ten internal digital sensors.

Na
be
nd
u K
ar
ma
ka
r
24 Multi-core Architecture
10.2 Cache Coherence:
Cache coherence is a concern in a multicore environment because of
distributed L1 and L2 cache. Since each core has its own cache, the copy of
the data in that cache may not always be the most up-to-date version. For
example, imagine a dual-core processor where each core brought a block of
memory into its private cache.
One core writes a value to a specific location; when the second core
attempts to read that value from its cache it won’t have the updated copy
unless its cache entry is invalidated and a cache miss occurs. This cache miss
forces the second core’s cache entry to be updated. If this coherence policy
wasn’t in place garbage data would be read and invalid results would be
produced, possibly crashing the program or the entire computer.
In general there are two schemes for cache coherence, a snooping protocol
and a directory-based protocol. The snooping protocol only works with a bus-
based system, and uses a number of states to determine whether or not it
needs to update cache entries and if it has control over writing to the block.
The directory-based protocol can be used on an arbitrary network and
is, there-fore, scalable to many processors or cores, in contrast to snooping
which isn’t scalable. In this scheme a directory is used that holds information
about which memory locations are being shared in multiple caches and which
are used exclusively by one core’s cache. The directory knows when a block
needs to be updated or invalidated.
Intel’s Core 2 Duo tries to speed up cache coherence by being able to
query the second core’s L1 cache and the shared L2 cache simultaneously.
Having a shared L2 cache also has an added benefit since a coherence
protocol doesn’t need to be set for this level. AMD‟s Athlon 64 X2, however,
has to monitor cache coherence in both L1 and L2 caches. This is sped up
using the HyperTransport connection, but still has more overhead than Intel’s
model.

Na
be
nd
u K
ar
ma
ka
r
25 Multi-core Architecture
10.3 Multithreading:
The last, and most important, issue is using multithreading or other parallel
processing techniques to get the most performance out of the multicore
processor. “With the possible exception of Java, there are no widely used
commercial development languages with [multithreaded] ex-tensions.” Also to
get the full functionality we have to have program that support the feature of
TLP. Rebuilding applications to be multithreaded means a complete rework by
programmers in most cases. Programmers have to write applications with
subroutines able to be run in different cores, meaning that data
dependencies will have to be resolved or accounted for (e.g. latency in
communication or using a shared cache).
Applications should be balanced. If one core is being used much more
than another, the programmer is not taking full advantage of the multi-core
system. Some companies have heard the call and designed new products
with multicore capabilities; Microsoft and Apple’s newest operating systems
can run on up to 4 cores, for example.

Na
be
nd
u K
ar
ma
ka
r
26 Multi-core Architecture
11. Open Issues:
There are some issues related to the multi-core CPUs:
11.1 Improved Memory System:
With numerous cores on a single chip there is an enormous need for
increased memory. 32-bit processors, such as the Pentium 4, can address up
to 4GB of main memory. With cores now using 64-bit addresses the amount
of addressable memory is almost infinite. An improved memory system is a
necessity; more main memory and larger caches are needed for
multithreaded multiprocessors.
11.2 System Bus and Interconnection Networks:
Extra memory will be useless if the amount of time required for memory
requests doesn’t improve as well. Redesigning the interconnection network
between cores is a major focus of chip manufacturers. A faster network
means a lower latency in inter-core communication and memory
transactions. Intel is developing their Quick path interconnect, which is a 20-
bit wide bus running between 4.8 and 6.4 GHz; AMD‟s new HyperTransport
3.0 is a 32-bit wide bus and runs at 5.2 GHz. A different kind of interconnect
is seen in the TILE64‟s iMesh, which consists of five networks used to fulfill
I/O and off-chip memory communication. Using five mesh networks gives the
Tile architecture a per tile (or core) bandwidth of up to 1.28 Tbps (terabits
per second).
11.3 Parallel Programming:
In May 2007, Intel fellow Shekhar Borkar stated that “The software has to
also start following Moore’s Law, software has to double the amount of
parallelism that it can support every two years.” Since the number of cores in

Na
be
nd
u K
ar
ma
ka
r
27 Multi-core Architecture
a processor is set to double every 18 months, it only makes sense that the
software running on these cores takes this into account.
Ultimately, programmers need to learn how to write parallel programs
that can be split up and run concurrently on multiple cores instead of trying
to exploit single-core hardware to increase parallelism of sequential
programs. Developing software for multicore processors brings up some
latent concerns.
How does a programmer ensure that a high-priority task gets priority
across the processor, not just a core? In theory even if a thread had the
highest priority within the core on which it is running it might not have a high
priority in the system as a whole. Another necessary tool for developers is
debugging. However, how do we guarantee that the entire system stops and
not just the core on which an application is running? These issues need to be
addressed along with teaching good parallel programming practices for
developers. Once programmers have a basic grasp on how to multithread
and program in parallel, instead of sequentially, ramping up to follow Moore’s
law will be easier.
11.4 Starvation:
If a program isn’t developed correctly for use in a multicore processor one or
more of the cores may starve for data. This would be seen if a single-
threaded application is run in a multicore system. The thread would simply
run in one of the cores while the other cores sat idle. This is an extreme case,
but illustrates the problem.
With a shared cache, for example Intel Core 2 Duo’s shared L2 cache,
if a proper replacement policy isn’t in place one core may starve for cache
usage and continually make costly calls out to main memory. The
replacement policy should include stipulations for evicting cache entries that
other cores have recently loaded. This becomes more difficult with an
increased number of cores effectively reducing the amount of evict able
cache space without increasing cache misses.

Na
be
nd
u K
ar
ma
ka
r
28 Multi-core Architecture
11.5 Homogenous Vs. heterogeneous Core:
Architects have debated whether the cores in a multicore environment
should be homogeneous or heterogeneous, and there is no definitive
answer…yet. Homogenous cores are all exactly the same: equivalent
frequencies, cache sizes, functions, etc. However, each core in a
heterogeneous system may have a different function, frequency, memory
model, etc. There is an apparent trade-off between processor complexity and
customization. All of the designs discussed above have used homogeneous
cores except for the CELL processor, which has one Power Processing
Element and eight Synergistic Processing Elements. Homogeneous cores are
easier to produce since the same instruction set is used across all cores and
each core contains the same hardware. But are they the most efficient use
of multicore technology? Each core in a heterogeneous environment could
have a specific function and run its own specialized instruction set. Building
on the CELL example, a heterogeneous model could have a large centralized
core built for generic processing and running an OS, a core for graphics, a
communications core, an enhanced mathematics core, an audio core, a
cryptographic core, and the list goes on. [33] This model is more complex, but
may have efficiency, power, and thermal benefits that outweigh its
complexity. With major manufacturers on both sides of this issue, this debate
will stretch on for years to come; it will be interesting to see which side
comes out on top.

Na
be
nd
u K
ar
ma
ka
r
29 Multi-core Architecture
12. Multi-core Advantages:
Although the most important advantage of having multi-core architecture is
already been discussed i.e better performance there are many more
advantages of multi-core processors as:
12.1 Power and cooling advantages of multicore processors:
Although the preceding example explains the scalability potential of multicore
processors, scalability is only part of the challenge for IT organizations.
High server density in the data center can create significant power
consumption and cooling requirements. A multicore architecture can help
alleviate the environmental challenges created by high-clock-speed, single-
core processors. Heat is a function of several factors, two of which are
processor density and clock speed. Other drivers include cache size and the
size of the core itself. In traditional architectures, heat generated by each
new generation of processors has increased at a greater rate than clock
speed.
In contrast, by using a shared cache (rather than separate dedicated
caches for each processor core) and low-clock-speed processors, multicore
processors may help administrators minimize heat while maintaining high
overall performance.
This capability may help make future multicore processors attractive
for IT deployments in which density is a key factor, such as high-performance
computing (HPC) clusters, Web farms, and large clustered applications.
Environments in which 1U servers or blade servers are being deployed today
could be enhanced by potential power savings and potential heat reductions
from multicore processors.
Currently, technologies such as demand-based switching (DBS) are beginning
to enter the mainstream, helping organizations reduce the utility power and
cooling costs of computing. DBS allows a processor to reduce power
consumption (by lowering frequency and voltage) during periods of low

Na
be
nd
u K
ar
ma
ka
r
30 Multi-core Architecture
computing demand. In addition to potential performance advances, multicore
designs also hold great promise for reducing the power and cooling costs of
computing, given DBS technology. DBS is available in single-core processors
today, and its inclusion in multicore processors may add capabilities for
managing power consumption and, ultimately, heat output. This potential
utility cost savings could help accelerate the movement from proprietary
platforms to energy-efficient industry-standard platforms.
12.2 Significance of sockets in a multicore architecture:
As they become available, multicore processors will require IT organizations
to consider system architectures for industry-standard servers from a
different perspective. For example, administrators currently segregate
applications into single-processor, dual-processor, and quad-processor
classes. However, multicore processors will call for a new mind-set that
considers processor cores as well as sockets. Single-threaded applications
that perform best today in a single-processor environment will likely continue
to be deployed on single-processor, single-core system architectures. For
single-threaded applications, which cannot make use of multiple processors in
a system, moving to a multiprocessor, multicore architecture may not
necessarily enhance performance. Most of today’s leading operating systems,
including Microsoft Windows Server System™ and Linux® variants, are
multithreaded, so multiple single-threaded applications can run on a multicore
architecture even though they are not inherently multithreaded. However, for
multithreaded applications that is currently deployed on single-processor
architectures because of cost constraints, moving to a single-processor, dual-
core architecture has the potential to offer performance benefits while
helping to keep costs low.
For the bulk of the network infrastructure and business applications
that organizations run today on dual-processor servers, the computing
landscape is expected to change over time. However, while it may initially
seem that applications running on a dual-processor, single-core system
architecture can migrate to a single-processor, dual-core system architecture

Na
be
nd
u K
ar
ma
ka
r
31 Multi-core Architecture
as a cost-saving initiative, this is not necessarily the case. To maintain
equivalent performance or achieve a greater level of performance, the dual-
processor applications of today will likely have to migrate to dual-socket,
dual-core systems. Two sockets can be designed to deliver superior
performance relative to a dual-socket, single-core system architecture, while
also delivering potential power and cooling savings to the data center. The
potential to gradually migrate a large number of older dual-socket, single-
core servers to energy-efficient dual-socket, multicore systems could enable
significant savings in power and cooling costs over time. Because higher-
powered, dual-socket systems typically run applications that are more
mission-critical than those running on less-powerful, single-processor systems,
organizations may continue to expect more availability, scalability, and
performance features to be designed for dual-socket systems relative to
single-socket systems—just as they do today.
For applications running today on high-performing quad processor
systems, a transition to multicore technology is not necessarily an
opportunity to move from four-socket, four-core systems to dual-socket,
four-core systems. Rather, the architectural change suggests that today’s
four-processor applications may migrate to four-socket systems with eight or
potentially more processor cores—helping to extend the range of cost-
effective, industry standard alternatives to large, proprietary symmetric
multiprocessing (SMP) systems. Because quad-processor systems tend to run
more mission-critical applications in the data center as compared to dual-
processor systems and single-processor systems, administrators can expect
quad-processor platforms to be designed with the widest range of
performance, availability, and scalability features across Dell™ PowerEdge™
server offerings.
When comparing relative processing performance of one generation of
servers to the next, a direct comparison should not focus on the number of
processor cores but rather on the number of sockets. However, the most
effective comparison is ultimately not one of processors or sockets alone, but
a thorough comparison of the entire platform—including scalability, availability,
memory, I/O, and other features. By considering the entire platform and all

Na
be
nd
u K
ar
ma
ka
r
32 Multi-core Architecture
the computing components that participate in it, organizations can best
match a platform to their specific application and business needs.
12.3 Evolution of software toward multicore technology:
Multicore processing continues to exert a significant impact on software
evolution. Before the advent of multicore processor technology, both SMP
systems and HT Technology motivated many OS and application vendors to
design software that could take advantage of multithreading capabilities.
As multicore processor–based systems enter the mainstream and
evolve, it is likely that OS and application vendors will optimize their offerings
for multicore architectures, resulting in potential performance increases over
time through enhanced software efficiency. Most application vendors will
likely continue to develop on industry-standard processor platforms,
considering the power, flexibility, and huge installed base of these systems.
Currently, 64-bit. Intel Xeon processors have the capability to run both 32-bit
applications and 64-bit applications through the use of Intel Extended
Memory 64 Technology (EM64T). The industry is gradually making the
transition from a 32-bit standard to a 64-bit standard, and similarly, software
can be expected to make the transition to take advantage of multicore
processors over time.
Applications that are designed for a multiprocessor or multithreaded
environment can currently take advantage of multicore processor
architectures. However, as software becomes optimized for multicore
processors, organizations can expect to see overall application performance
enhancements deriving from software innovations that take advantage of
multicore-processor–based system architecture instead of increased clock
speed.
In addition, compilers and application development tools will likely
become available to optimize software code for multi core processors,
enabling long-term optimization and enhanced efficiency for multicore
processors—which also may help realize performance improvements through

Na
be
nd
u K
ar
ma
ka
r
33 Multi-core Architecture
highly tuned software design rather than a brute-force increase in clock
speed. Intel is working toward introducing software tools and compilers to
help optimize threading performance for both single-core and multicore
architectures.
Organizations that begin to optimize their software today for multicore
system architecture may gain significant business advantages as these
systems become main-stream over the next few years. For instance, today’s
dual Intel Xeon processor–based system with HT Technology can support four
concurrent threads (two per processor). With the advent of dual-core Intel
Xeon processors with HT Technology, these four threads would double to
eight.
An OS would then have eight concurrent threads to distribute and
manage workloads, leading to potential performance increases in processor
utilization and processing efficiency.

Na
be
nd
u K
ar
ma
ka
r
34 Multi-core Architecture
13. Licensing considerations:
Another key area to consider in planning for a migration to multicore
processors is the way in which software vendors license their applications.
Many enterprise application vendors license their applications based on the
number of processors, not the number of users. This could mean that,
although a dual-socket, dual-core server may offer enhanced performance
when compared to a dual-socket, single-core server, and the licensing cost
could potentially double because the application would identify four
processors instead of two.
The resulting increase in licensing costs could negate the potential
performance improvement of using multicore processor–based systems.
Because the scalability of multicore processors is not linear—that is, adding a
second core does not result in a 100 percent increase in performance—a
doubling of licensing costs would result in lower overall price/performance.
For that reason, software licensing should be considered a key factor
when organizations assess which applications to migrate to systems using
multicore processors. For example, enterprise software licensing costs can be
significantly higher than the cost of the server on which the application is
running.
This can be especially true for industry-standard servers that deliver
excellent performance at a low price point as compared to proprietary
servers. Some application vendors have adopted a policy of licensing based
on the socket count instead of the number of cores, while others have not
yet taken a stance on this matter. Until the industry gains more clarity
around this software licensing issue, organizations must factor software
licensing costs into the overall platform cost when evaluating multicore
technology transitions.
Na
be
nd
u K
ar
ma
ka
r
35 Multi-core Architecture
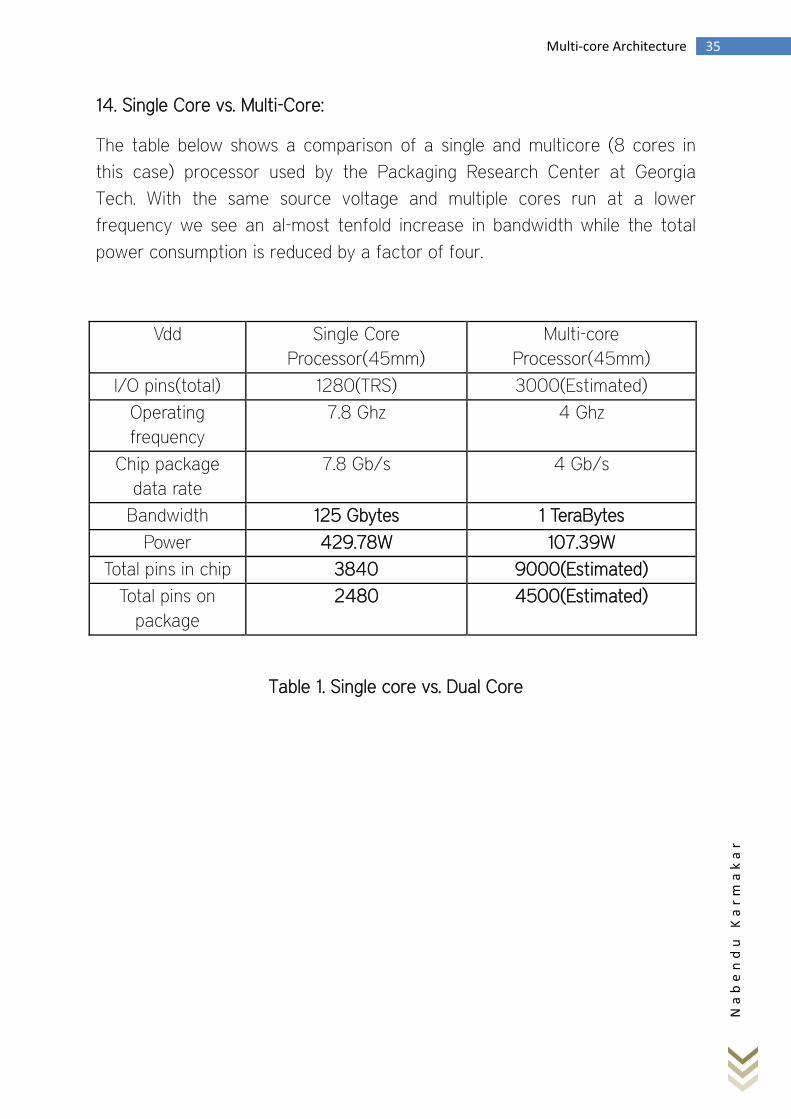
14. Single Core vs. Multi-Core:
The table below shows a comparison of a single and multicore (8 cores in
this case) processor used by the Packaging Research Center at Georgia
Tech. With the same source voltage and multiple cores run at a lower
frequency we see an al-most tenfold increase in bandwidth while the total
power consumption is reduced by a factor of four.
Vdd Single Core
Processor(45mm)
Multi-core
Processor(45mm)
I/O pins(total) 1280(TRS) 3000(Estimated)
Operating
frequency
7.8 Ghz 4 Ghz
Chip package
data rate
7.8 Gb/s 4 Gb/s
Bandwidth 125 Gbytes 1 TeraBytes
Power 429.78W 107.39W
Total pins in chip 3840 9000(Estimated)
Total pins on
package
2480 4500(Estimated)
Table 1. Single core vs. Dual Core
Na
be
nd
u K
ar
ma
ka
r
36 Multi-core Architecture
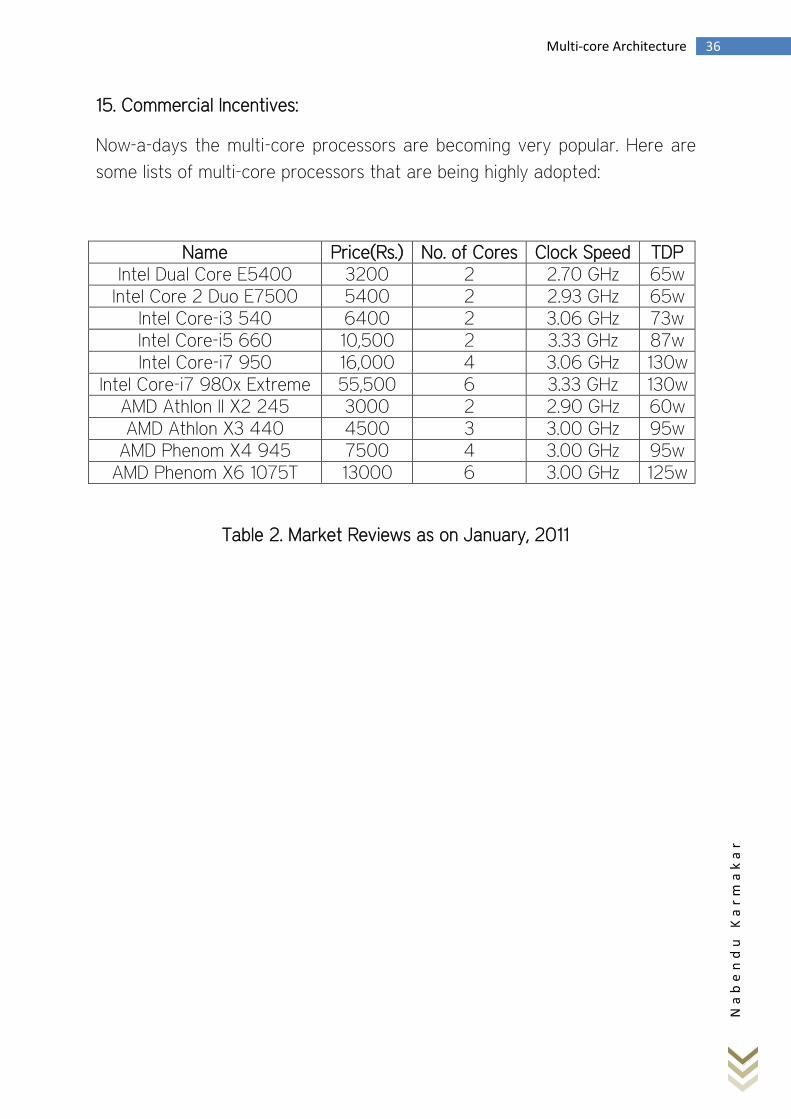
15. Commercial Incentives:
Now-a-days the multi-core processors are becoming very popular. Here are
some lists of multi-core processors that are being highly adopted:
Name Price(Rs.) No. of Cores Clock Speed TDP Intel Dual Core E5400 3200 2 2.70 GHz 65w
Intel Core 2 Duo E7500 5400 2 2.93 GHz 65w Intel Core-i3 540 6400 2 3.06 GHz 73w Intel Core-i5 660 10,500 2 3.33 GHz 87w Intel Core-i7 950 16,000 4 3.06 GHz 130w
Intel Core-i7 980x Extreme 55,500 6 3.33 GHz 130w AMD Athlon II X2 245 3000 2 2.90 GHz 60w AMD Athlon X3 440 4500 3 3.00 GHz 95w
AMD Phenom X4 945 7500 4 3.00 GHz 95w AMD Phenom X6 1075T 13000 6 3.00 GHz 125w
Table 2. Market Reviews as on January, 2011

Na
be
nd
u K
ar
ma
ka
r
37 Multi-core Architecture
16. Conclusion – Shift in focus toward multi-core technology:
Before multicore processors the performance increase from generation to
generation was easy to see, an increase in frequency.
This model broke when the high frequencies caused processors to run at
speeds that caused increased power consumption and heat dissipation at
detrimental levels. Adding multiple cores within a processor gave the solution
of running at lower frequencies, but added interesting new problems.
Multicore processors are architected to adhere to reasonable power
consumption, heat dissipation, and cache coherence protocols. However,
many issues remain unsolved.
In order to use a multicore processor at full capacity the applications
run on the system must be multithreaded. There are relatively few
applications (and more importantly few programmers with the know-how)
written with any level of parallelism. The memory systems and
interconnection net-works also need improvement. And finally, it is still
unclear whether homogeneous or heterogeneous cores are more efficient.
With so many different designs (and potential for even more) it is
nearly impossible to set any standard for cache coherence, interconnections,
and layout.
The greatest difficulty remains in teaching parallel programming
techniques (since most programmers are so versed in sequential
programming) and in redesigning current applications to run optimally on a
multicore system. Multicore processors are an important innovation in the
microprocessor timeline.
With skilled programmers capable of writing parallelized applications
multicore efficiency could be increased dramatically. In years to come we will
see much in the way of improvements to these systems. These improvements
will provide faster programs and a better computing experience.

Na
be
nd
u K
ar
ma
ka
r
38 Multi-core Architecture
17. References Used:
[1] W. Knight, “Two Heads Are Better Than One”, IEEE Review,
September 2005
[2] R. Merritt, “CPU Designers Debate Multi-core Future”,
EETimes Online, February 2008,
http://www.eetimes.com/showArticle.jhtml?articleID=206105179
[3] P. Frost Gorder, “Multicore Processors for Science and
Engineering”, IEEE CS, March/April 2007
[4] D. Geer, “Chip Makers Turn to Multicore Processors”,
Computer, IEEE Computer Society, May 2005
[5] L. Peng et al, “Memory Performance and Scalability of
Intel‟s and AMD‟s Dual-Core Processors: A Case Study”, IEEE,
2007
[6] D. Pham et al, “The Design and Implementation of a First-
Generation CELL Processor”, ISSCC
[7] P. Hofstee and M. Day, “Hardware and Software Architecture
for the CELL Processor”, CODES+ISSS ‟05, September 2005
[8] J. Kahle, “The Cell Processor Architecture”, MICRO-38
Keynote, 2005
[9] D. Stasiak et al, “Cell Processor Low-Power Design
Methodology”, IEEE MICRO, 2005
[10] D. Pham et al, “Overview of the Architecture, Circuit
Design, and Physical Implementation of a First-Generation Cell
Processor”, IEEE Journal of Solid-State Circuits, Vol. 41, No.
1, January 2006
[11] D. Geer, “For Programmers, Multicore Chips Mean Multiple
Challenges”, Computer, September 2007
[12] M. Creeger, “Multicore CPUs for the Masses”, QUEUE,
September 2005
[13] R. Merritt, “Multicore Puts Screws to Parallel-
Programming Models”, EETimes Online, February 2008,
http://www.eetimes.com/news/latest/showArticle.jtml?articleID=
206504466

Na
be
nd
u K
ar
ma
ka
r
39 Multi-core Architecture
[14] R. Merritt, “X86 Cuts to the Cores”, EETimes Online,
September 2007,
http://www.eetimes.com/showArticle.jtml?articleID=202100022
[15] R. Merritt, “Multicore Goals Mesh at Hot Chips”, EETimes
Online, August 2007,
http://www.eetimes.com/showArticle.jtml?articleID=201800925
[16] P. Muthana et al, “Packaging of Multi-Core
Microprocessors: Tradeoffs and Potential Solutions”, 2005
Electronic Components and Technology Conference, 2005
[17] S. Balakrishnan et al, “The Impact of Performance
Asymmetry in Emergng Multicore Architectures”, Proceedings of
the 32nd International Symposium on Computer Architecture, 2005
[18] “A Brief History of Microprocessors”, Microelectronics
Industrial Centre, Northumbria University, 2002,
[19] B. Brey, “The Intel Microprocessors”, Sixth Edition,
Prentice Hall, 2003
[20] Video Transcript, “Excerpts from a Conversation with
Gordon Moore: Moore‟s Law”, Intel Corporation, 2005
[21] Wikipedia, “Moore‟s Law”,
http://upload.wikimedia.org/wikipedia/commons/0/06/Moore_Law_d
iagram_(2004).png
[22] Intel, “World‟s First 2-Billion Transistor
Microprocessor”, http://www.intel.com/technology/architecture-
silicon/2billion.htm?id=tech_mooreslaw+rhc_2b
[23] M. Franklin, “Notes from ENEE759M: Microarchitecture”,
Spring 2008
[24] U. Nawathe et al, “An 8-core, 64-thread, 64-bit, power
efficient SPARC SoC (Niagara 2)”, ISSCC,
http://www.opensparc.net/pubs/preszo/07/n2isscc.pdf
[25] J. Dowdeck, “Inside Intel Core Microarchitecture and
Smart Memory Access”, Intel, 2006,
http://download.intel.com/technology/architecture/sma.pdf
[26] Tilera, “Tile 64 Product Brief”, Tilera, 2008,
http://www.tilera.com/pdf/ProductBrief_Tile64_Web_v3.pdf

Na
be
nd
u K
ar
ma
ka
r
40 Multi-core Architecture
[27] D. Wentzlaff et al, “On-Chip Interconnection Architecture
of the Tile Processor”, IEEE Micro, 2007
[28] Tilera, “TILE64 Processor Family”,
http://www.tilera.com/products/processors.php
[29] D. Olson, “Intel Announces Plan for up to 8-core
Processor”, Slippery Brick, March 2008,
http://www.slipperybrick.com/2008/03/intel-dunnington-nehalem-
processor-chips/
[30] K. Shi and D. Howard, “Sleep Transistor Design and
Implementation – Simple Concepts Yet Challenges To Be
Optimum”, Synopsys,
http://www.synopsys.com/sps/pdf/optimum_sleep_transistor_vlsi_
dat06.pdf
[31] W. Huang et al, “An Improved Block-Based Thermal Model in
HotSpot 4.0 with Granularity Considerations”, University of
Virginia, April 2007
[32] S. Mukherjee and M. Hill, “Using Prediction to Accelerate
Coherence Protocols”, Proceedings of the 25th Annual
International Symposium on Computer Architecture (ISCA), 1998
[33] R. Alderman, “Multicore Disparities”, VME Now, December
2007,
http://vmenow.com/c/index.php?option=com_content&task=view&id=
105&Itemid=46
[34] R. Kumar et al, “Single-ISA Heterogeneous Multi-core
Architectures with Multithreaded Workload Performance”,
Proceedings of the 31st Annual International Symposium on
Computer Architecture, June 2004.
[35] T. Holwerda, “Intel: Software Needs to Heed Moore’s Law”.


















