
Multi tier, multi-tenant, multi-problem kafka
40
SITE RELIABILITY ENGINEERING ©2016 LinkedIn Corporation. All Rights Reserved. Multi-Tier, Multi-Tenant, Multi-Problem Kafka
-
Upload
todd-palino -
Category
Engineering
-
view
499 -
download
0
Transcript of Multi tier, multi-tenant, multi-problem kafka

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved.
Multi-Tier, Multi-Tenant, Multi-Problem Kafka

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved.
Todd PalinoStaff Site Reliability EngineerLinkedIn, Data Infrastructure Streaming
SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 3
Who Am I?

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 4
What Will We Talk About?
Multi-Tenant Pipelines
Multi-Tier Architecture
Why I Drink Interesting Problems
Conclusion

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 5
Multi-Tenant Pipelines

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 6
Tracking and Data Deployment
Tracking – Data going to HDFS Data Deployment – Hadoop job results going to online applications
Many shared topics Schemas require a common header All message counts are audited
Special Problems– Hard to tell what application is dropping messages– Some of these messages are copied 42 times!

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 7
Metrics
Application and OS metrics Deployment and build system events Service calls – sampling of timing information for individual application calls Some application logs
Special Problems– Every server in the datacenter produces to this cluster at least twice– Graphing/Alerting system consumes the metrics 20 times

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 8
Logging
Application logging messages destined for ELK clusters
Lower retention than other clusters Loosest restrictions on message schema and encoding
Special Problems– Not many – it’s still overprovisioned– Customers starting to ask about aggregation

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 9
Queuing
Everything else Primarily messages internal to applications Also emails and user messaging
Messages are Avro encoded, but do not require headers
Special Problems:– Many messages which use unregistered schemas– Clusters can have very high message rates (but not large data)

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 10
Special Case Clusters
Not all use cases fit multi-tenancy– Custom configurations that are needed– Tighter performance guarantees– Use of topic deletion
Espresso (KV store) internal replication Brooklin – Change capture Replication from Hadoop to Voldemort

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 11
Tiered Cluster Architecture
SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 12
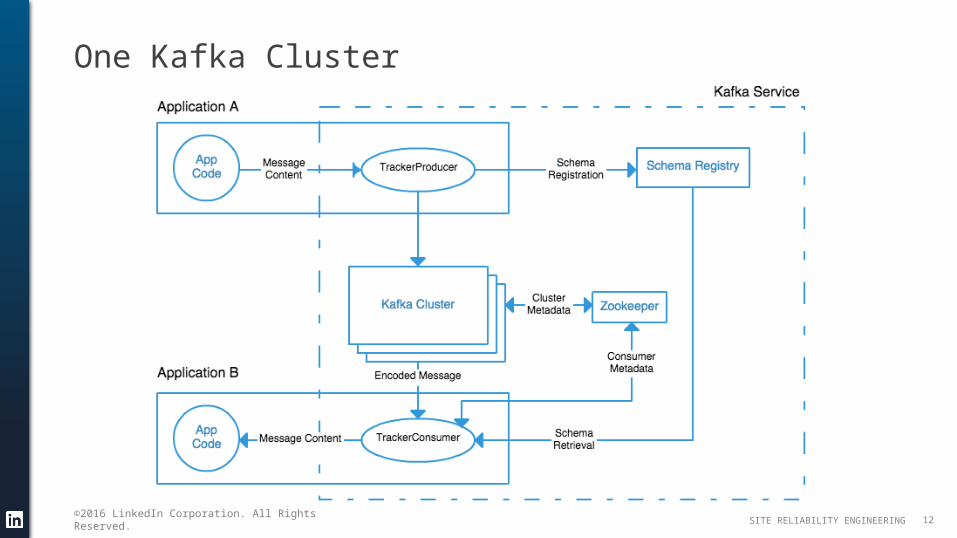
One Kafka Cluster
SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 13
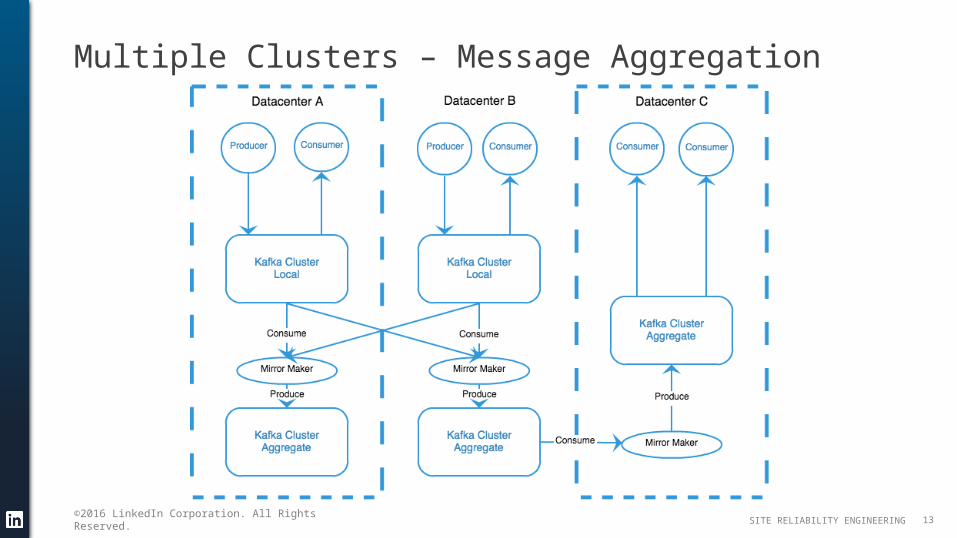
Multiple Clusters – Message Aggregation

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 14
Why Not Direct?
Network Concerns– Bandwidth– Network partitioning– Latency
Security Concerns– Firewalls and ACLs– Encrypting data in transit
Resource Concerns– A misbehaving application can swamp production resources

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 15
What Do We Lose?
You may lose message ordering– Mirror maker breaks apart message batches and redistributes them
You may lose key to partition affinity– Mirror maker will partition based on the key– Differing partition counts in source and target will result in differing distribution– Mirror maker does not (without work) honor custom partitioning

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 16
Aggregation Rules
Aggregate clusters are only for consuming messages– Producing to an aggregate cluster is not allowed– This assures all aggregate clusters have the same content
Not every topic appears in PROD aggregate-tracking clusters– Trying to discourage aggregate cluster usage in PROD– All topics are available in CORP
Aggregate-queuing is whitelist only and very restricted– Please discuss your use case with us before developing

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 17
Interesting Problems

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 18
Buy The Book!
Early Access available now.
Covers all aspects of Kafka, from setup to client development to ongoing administration and troubleshooting.
Also discusses stream processing and other use cases.

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 19
Monitoring Using Kafka
Monitoring and alerting are self-service– No gatekeeper on what metrics are collected and stored
Applications use a common container– EventBus Kafka producer– Simple annotation of metrics to collect– Sampled service calls– Application logs
Everything is produced to Kafka and consumed by the monitoring infrastructure

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 20
Monitoring Kafka
Kafka is great for monitoring your applications

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 21
KMon and EnlightIN
Developed a separate monitoring and notification system– Metrics are only retained long enough to alert on them– One rule: we can’t use Kafka
Alerting is simplified from our self-service system– Nothing complex like regular expressions or RPNs– Only used for critical Kafka and Zookeeper alerts– Faster and more reliable
Notifications are cleaner– Alerts are grouped into incidents for fewer notifications when things break– Notification system is generic and subscribable so we can use it for other things

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 22
Broker Monitoring
Bytes In and Out, Messages In– Why not messages out?
Partitions– Count and Leader Count– Under Replicated and Offline
Threads– Network pool, Request pool– Max Dirty Percent
Requests– Rates and times - total, queue, local, and send

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 23
Is Kafka Working?
Knowing that the cluster is up isn’t always enough– Network problems– Metrics can lie
Customers still ask us first if something breaks– Part of the solution is educating them as to what to monitor– Need to be absolutely sure of the answer “There’s nothing wrong with Kafka”

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 24
Kafka Monitoring Framework
Producer to consumer testing of a Kafka cluster– Assures that producers and consumers actually work– Measures how long messages take to get through
We have a SLO of 99.99% availability for all clusters
Working on multi-tier support– Answers the question of how long messages take to get to Hadoop
LinkedIn Kafka Open Source– https://github.com/linkedin/streaming

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 25
Is Mirroring Working?
Most critical data flows through Kafka– Most of that depends on mirror makers– How do we make sure it all gets where it’s going?
Mirror maker pipelines can have over a thousand topics– Different message rates– Some are more important than others
Lag threshold monitoring doesn’t work– Traffic spikes cause false alerts– What should the threshold be?– No easy way to monitor 1000 topics and over 10k partitions

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 26
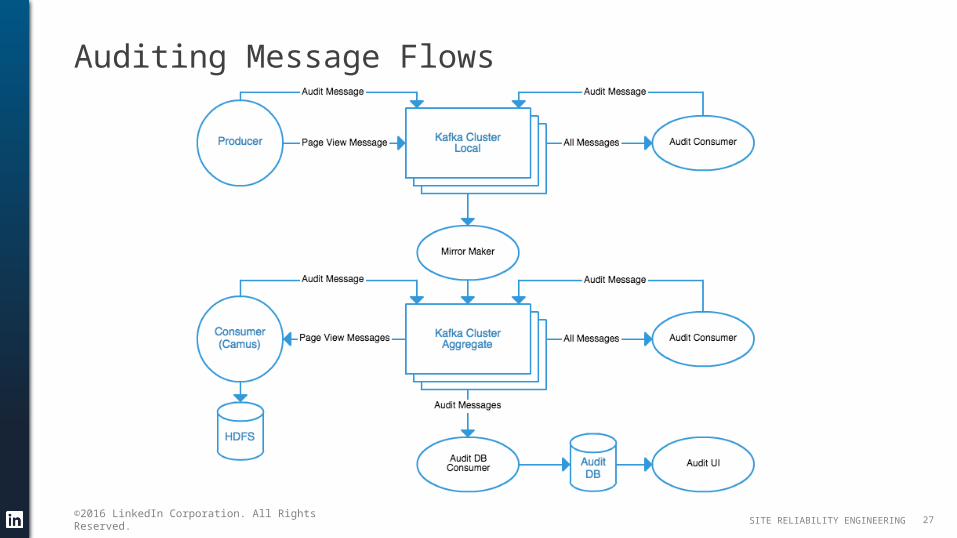
Kafka Audit
Audit tracks topic completeness across all clusters in the pipeline– Primarily tracking messages– Schema must have a valid header– Alerts for DWH topics are set for 0.1% message loss
Provided as an integrated part of the internal Kafka libraries
Used for data completeness checks before Hadoop jobs run
SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 27
Auditing Message Flows

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 28
Burrow
Burrow is an advanced Kafka consumer monitoring system– Provides an objective view of consumer status– Much more powerful than threshold-based lag monitoring
Burrow is Open Source!– Used by many other companies, including Wikimedia and Blizzard– Used internally to assure all Mirror Makers and Audit are running correctly
Exports metrics for all consumers to self-service monitoring
https://github.com/linkedin/Burrow

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 29
MTTF Is Not Your Friend
We have over 1800 Kafka brokers– All have at least 12 drives, most have 16– Dual CPUs, at least 64 GB of memory– Really lousy Megaraid controllers
This means hardware fails daily– We don’t always know when it happens, if it doesn’t take the system down– It can’t always be fixed immediately– We can take one broker down, but not two

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 30
Moving Partitions
Prior to Kafka 0.8, moving partitions was basically impossible– It’s still not easy – you have to be explicit about what you are moving– There’s no good way to balance partitions in a cluster
We developed kafka-assigner to solve the problem– A single command to remove a broker and distribute it’s partitions– Chainable modules for balancing partitions– Open source! https://github.com/linkedin/kafka-tools
Also working on “Cruise Control” for Kafka– An add-on service that will handle redistributing partitions automatically

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 31
Pushing Data from Hadoop
To help Hadoop jobs, we maintain a KafkaPushJob– A mapper that produces messages to Kafka– Pushes to data-deployment, which then gets mirrored to production
Hadoop jobs tend to push a lot of data all at once– Some jobs spin up hundreds of mappers– Pushing many gigabytes of data in a very short period of time
This overwhelms a Kafka cluster– Spurious alerts for under replicated partitions– Problems with mirroring the messages out

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 32
Kafka Quotas
Quotas limit traffic based on client ID– Specified in bytes/sec on a per-broker basis– Not per-topic or per-partition
Should be transparent to clients– Accomplished by delaying the response to requests– Newer clients have metrics specific to quotas for clarity
We use it to protect the replication of the cluster– Set it as high as possible while protecting against a single bad client

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 33
Delete Topic
Feature has been under development for almost 3 years– Only recently has it even worked a little bit– We’re still not sure about it (from SRE’s point of view)
Recently performed additional testing so we can use it– Found that even when disabled for a cluster, something was happening– Some brokers claimed the topic was gone, some didn’t– Mirror makers broke for the topic
One of the code paths in the controller was not blocked– Metadata change went out, but it was hard to diagnose

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 34
Brokers are Independent
When there’s a problem in the cluster, brokers might have bad information– The controller should tell them what the topic metadata is– Brokers get out of sync due to connection issues or bugs
There’s no good tool for just sending a request to a broker and reading the response
– We had to write a Java application just to send a metadata request
Coming soon – kafka-protocol– Simple CLI tool for sending individual requests to Kafka brokers– Will be part of the https://github.com/linkedin/kafka-tools repository

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 35
Conclusion

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 36
Broker Improvement - JBOD
We use RAID-10 on all brokers– Trade off a lot of performance for a little resiliency– Lose half of our disk space
Current JBOD implementation isn’t great– No admin tools for moving partitions– Assignment is round-robin– Broker shuts down if a single disk fails
Looking at options– Might try to fix the JBOD implementation in Kafka– Testing running multiple brokers on a single server

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 37
Mirror Maker Improvements
Mirror Maker has performance issues– Has to decompress and recompress every message– Loses information about partition affinity and strict ordering
Developed an Identity message handler– Messages in source partition 0 get produced directly to partition 0– Requires mirror maker to maintain downstream partition counts
Working on the next steps– No decompression of message batches– Looking at other options on how to run mirror makers

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 38
Administrative Improvements
Multiple cluster management– Topic management across clusters– Visualization of mirror maker paths
Better client monitoring– Burrow for consumer monitoring– No open source solution for producer monitoring (audit)
End-to-end availability monitoring

SITE RELIABILITY ENGINEERING©2016 LinkedIn Corporation. All Rights Reserved. 39
Getting Involved With Kafka
http://kafka.apache.org
Join the mailing lists– [email protected]– [email protected]
irc.freenode.net - #apache-kafka
Meetups– Bay Area – https://www.meetup.com/Stream-Processing-Meetup-LinkedIn/
Contribute code



















