
Muhammad Nadeem A Dissertation Mississippi State, Mississippi
114
A method for recommending computer–security training for software developers By Muhammad Nadeem A Dissertation Submitted to the Faculty of Mississippi State University in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Computer Science in the Department of Computer Science and Engineering Mississippi State, Mississippi August 2016
Transcript of Muhammad Nadeem A Dissertation Mississippi State, Mississippi

A method for recommending computer–security training for software developers
By
Muhammad Nadeem
A DissertationSubmitted to the Faculty ofMississippi State University
in Partial Fulfillment of the Requirementsfor the Degree of Doctor of Philosophy
in Computer Sciencein the Department of Computer Science and Engineering
Mississippi State, Mississippi
August 2016

Copyright by
Muhammad Nadeem
2016

A method for recommending computer–security training for software developers
By
Muhammad Nadeem
Approved:
Byron J. Williams(Major Professor)
David A. Dampier(Committee Member)
Gary Bradshaw(Committee Member)
Robert Wesley McGrew(Committee Member)
T.J. Jankun-Kelly(Graduate Coordinator)
Jason M. KeithDean
Bagley College of Engineering

Name: Muhammad Nadeem
Date of Degree: August 12, 2016
Institution: Mississippi State University
Major Field: Computer Science
Major Professor: Byron J. Williams
Title of Study: A method for recommending computer–security training for softwaredevelopers
Pages of Study: 99
Candidate for Degree of Doctor of Philosophy
Vulnerable code may cause security breaches in software systems resulting in financial
and reputation losses for the organizations in addition to loss of their customers’ confi-
dential data. Delivering proper software security training to software developers is key to
prevent such breaches. Conventional training methods do not take the code written by the
developers over time into account, which makes these training sessions less effective. We
propose a method for recommending computer–security training to help identify focused
and narrow areas in which developers need training. The proposed method leverages the
power of static analysis techniques, by using the flagged vulnerabilities in the source code
as basis, to suggest the most appropriate training topics to different software developers.
Moreover, it utilizes public vulnerability repositories as its knowledgebase to suggest com-
munity accepted solutions to different security problems. Such mitigation strategies are
platform independent, giving further strength to the utility of the system.

This research discussed the proposed architecture of the recommender system, case
studies to validate the system architecture, tailored algorithms to improve the performance
of the system, and human subject evaluation conducted to determine the usefulness of the
system.
Our evaluation suggests that the proposed system successfully retrieves relevant train-
ing articles from the public vulnerability repository. The human subjects found these arti-
cles to be suitable for training. The human subjects also found the proposed recommender
system as effective as a commercial tool.
Key words: Recommender system, software security, software vulnerabilities, CWE, NVD,training, tf–idf, Jaccard index, Static code analysis, FindBugs.

DEDICATION
I dedicate this work to my adorable kids, Simra Nadeem, Ifra Nadeem, and Tabish
Nadeem, who spent six precious years of their childhood away from me.
ii

ACKNOWLEDGEMENTS
I feel obliged to express my gratitude to several people who have contributed to com-
pletion of this research. First and foremost, I would like to thank to Dr. Byron J. Williams,
my major professor and dissertation director, for his continuous support, supervision, men-
toring, and guidance throughout the course of this research. I would also like to sincerely
thank Dr. Edward B. Allen, my former advisor, for his continuous guidance and diligent
technical feedback to move this research in the right direction since the beginning.
I would also like to thank my dissertation committee members, Gary L. Bradshaw,
David A. Dampier, and R. Wesley McGrew for their valuable guidance in conducting hu-
man subject experiments, statistical analysis of data, and finalizing the architecture of the
recommender system.
I would like to thank the Dr. Mohamed El–Attar, Zadia Codabux, Kazi Zakia Sultana,
Tanmay Bhomik, James Thompson, Ibrahim Abdoulahi, and other members of Empirical
Software Engineering Group for their valuable feedback on my research. I would also like
to thank all those who volunteered for participation in the human subject evaluation.
I would also like to thank Dr. Donna S. Reese, head of Computer Science and Engi-
neering department, who not only provided me the opportunity to attend Preparing Future
Faculty program and other academic workshops but also has been a source of inspiration
and motivation.
iii

I am highly grateful to the United States Department of State, the Fulbright Program,
the International Institute of Education (IIE), and the Higher Education Commission of
Pakistan for the financial support. Also, the Department of Computer Science and Engi-
neering, for the partial financial support through Bridge Fellowship program.
Last but not the least, I would like to thank all my friends and family members who
encouraged, supported, and motivated me throughout the course of my studies.
iv

TABLE OF CONTENTS
DEDICATION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ii
ACKNOWLEDGEMENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ix
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
CHAPTER
1. INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Research Hypothesis . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Understanding the Problem . . . . . . . . . . . . . . . . . . . . . 11.3 Motivation and Objective . . . . . . . . . . . . . . . . . . . . . . 21.4 Our Approach to Solving the Problem . . . . . . . . . . . . . . . 21.5 Defining the Recommender Systems . . . . . . . . . . . . . . . . 41.6 Leveraging the Power of Open Source . . . . . . . . . . . . . . . 41.7 Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2. RELATED WORK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1 Recommender Systems for Software Engineering . . . . . . . . . 72.1.1 Debug Adviser . . . . . . . . . . . . . . . . . . . . . . . 72.1.2 Strathcona . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.3 Hipikat . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.4 RASCAL . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.5 Recommender System for Requirements Elicitation . . . . 92.1.6 Contextual Recommendations . . . . . . . . . . . . . . . 9
2.2 Systematic Mapping Study . . . . . . . . . . . . . . . . . . . . . 92.3 Mapping Algorithms . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Software Vulnerabilities . . . . . . . . . . . . . . . . . . . . . . 12
2.4.1 Cross Site Scripting (XSS) . . . . . . . . . . . . . . . . . 132.4.2 Hardcoded Constant Database Password . . . . . . . . . . 142.4.3 HTTP Response Splitting . . . . . . . . . . . . . . . . . . 15
v

2.4.4 SQL Injection . . . . . . . . . . . . . . . . . . . . . . . . 15
3. TOOLS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1 Tools for Static Analysis . . . . . . . . . . . . . . . . . . . . . . 183.2 Tools for Mapping Algorithms . . . . . . . . . . . . . . . . . . . 193.3 Part of Speech (POS) Tagger . . . . . . . . . . . . . . . . . . . . 193.4 LOC Calculator . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.5 Custom Built Tools . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.5.1 Article Extractor . . . . . . . . . . . . . . . . . . . . . . . 203.5.2 Noun Extractor . . . . . . . . . . . . . . . . . . . . . . . 20
3.6 Public Vulnerability Repositories . . . . . . . . . . . . . . . . . 21
4. RESEARCH METHODOLOGY . . . . . . . . . . . . . . . . . . . . . . 22
4.1 Hypothesis and Research Questions . . . . . . . . . . . . . . . . 224.2 Research Questions . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1 How do the recommendations based on CWE repositorycompare to recommendation from HP Fortify in terms oftraining suitability? . . . . . . . . . . . . . . . . . . . . . 23
4.2.2 How do the TF–IDF and Jaccard index algorithms compareto each other to identify relevant articles in public reposito-ries given the evaluation of human subjects? . . . . . . . . 24
4.2.3 Research questions regarding tailored approach . . . . . . 244.2.3.1 How does the tailored mapping algorithm based on
TF-IDF scores and additional attributes, i.e., recencyand completeness of the articles compare, to the otheralgorithms in terms of relevance? . . . . . . . . . . 24
4.2.3.2 How does the tailored mapping algorithm based onJaccard index and and additional attributes, i.e., re-cency and completeness of the articles, compare tothe other algorithms in terms of relevance? . . . . . 24
4.2.4 What is the statistical profile of developers in the case studybased on the following parameters? . . . . . . . . . . . . . 25
4.3 Experiment Design . . . . . . . . . . . . . . . . . . . . . . . . . 254.3.1 Getting Dataset and Tools Ready . . . . . . . . . . . . . . 254.3.2 Pre–processing . . . . . . . . . . . . . . . . . . . . . . . 264.3.3 Experiment I: Preliminary case study . . . . . . . . . . . . 264.3.4 Experiment II: Human Subject Evaluation . . . . . . . . . 274.3.5 Experiment III: Implementation of Tailored Algorithms . . 28
5. PROPOSED RECOMMENDER SYSTEM ARCHITECTURE . . . . . . 29
vi

5.1 Software Code Repository . . . . . . . . . . . . . . . . . . . . . 295.2 Static Code Analysis Module . . . . . . . . . . . . . . . . . . . . 295.3 Developers Performance Assessment Module . . . . . . . . . . . 315.4 Public Vulnerability Repository . . . . . . . . . . . . . . . . . . 315.5 Custom Training Database . . . . . . . . . . . . . . . . . . . . . 315.6 Recommender Module . . . . . . . . . . . . . . . . . . . . . . . 315.7 Training Delivery Module . . . . . . . . . . . . . . . . . . . . . 325.8 Intended benefits for practitioners . . . . . . . . . . . . . . . . . 32
6. PRELIMINARY CASE STUDY . . . . . . . . . . . . . . . . . . . . . . 35
6.1 Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . 366.2 Qualitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . 416.3 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
7. HUMAN SUBJECT EVALUATION . . . . . . . . . . . . . . . . . . . . 45
7.1 Apparatus, Materials, and Artifacts . . . . . . . . . . . . . . . . 457.2 Experimental Design . . . . . . . . . . . . . . . . . . . . . . . . 467.3 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . 467.4 Analysis Methods . . . . . . . . . . . . . . . . . . . . . . . . . . 497.5 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7.5.1 Suitability for training . . . . . . . . . . . . . . . . . . . . 507.5.2 Relevance . . . . . . . . . . . . . . . . . . . . . . . . . . 52
8. TAILORED ALGORITHMS . . . . . . . . . . . . . . . . . . . . . . . . 56
8.1 Evaluation of Tailored Approaches . . . . . . . . . . . . . . . . . 568.1.1 POS Tagger and Noun–based Search . . . . . . . . . . . . 578.1.2 Extracting Nouns . . . . . . . . . . . . . . . . . . . . . . 578.1.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
8.1.3.1 Primitive vs. Tailored tf–idf Based Approach . . . . 598.1.3.2 Primitive vs. Tailored Jaccard Index Based Approach 66
8.2 Analyzing Security Vulnerability Trends in Open Source Software 708.2.1 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
9. DISCUSSION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
9.1 Research Questions . . . . . . . . . . . . . . . . . . . . . . . . . 769.2 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . 78
9.2.1 Generic Limitation of Static Analysis Tools . . . . . . . . 789.2.1.1 Implication of False Positive Results . . . . . . . . 789.2.1.2 Implication of False Negative Results . . . . . . . . 79
vii

9.2.2 Analysis Limited to one Open Source System . . . . . . . 799.2.3 Analysis Limited to one Open Source System . . . . . . . 799.2.4 Human Factors . . . . . . . . . . . . . . . . . . . . . . . 79
10. CONCLUSIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
10.1 Hypothesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8110.2 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8110.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
10.3.1 The proposed architecture . . . . . . . . . . . . . . . . . . 8210.3.2 Evaluation of Different Approaches for Recommending Sys-
tem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8210.3.3 Proposing and Evaluating Tailored Approach . . . . . . . 8210.3.4 Evaluation of CWE Articles for Suitability for Training . . 8210.3.5 Low Cost Alternative to Commercial Tools . . . . . . . . . 82
10.4 Publication Plan . . . . . . . . . . . . . . . . . . . . . . . . . . 8310.5 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
10.5.1 Expanding Knowledgebase . . . . . . . . . . . . . . . . . 8310.5.2 Improving Static Analysis . . . . . . . . . . . . . . . . . . 8410.5.3 Automatic Code Generation . . . . . . . . . . . . . . . . . 8410.5.4 Usability Studies . . . . . . . . . . . . . . . . . . . . . . 8410.5.5 Prioritizing the Training for Software Developers . . . . . 8510.5.6 Improving Mapping Algorithms . . . . . . . . . . . . . . 85
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
APPENDIX
A. DETAILS OF SYSTEMATIC MAPPING STUDY OF RECOMMENDERSYSTEMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
A.1 Search Strings Used . . . . . . . . . . . . . . . . . . . . . . . . 94A.2 The Databases Used for Literature Search . . . . . . . . . . . . . 94
B. HUMAN SUBJECT EXPERIMENT DETAILS . . . . . . . . . . . . . . 96
B.1 Human Subject Evaluation . . . . . . . . . . . . . . . . . . . . . 97
viii

LIST OF TABLES
2.1 Filtering Creteria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Recommender Systems for Software Engineering . . . . . . . . . . . . . . 11
6.1 Summary of System Studied . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Summary of Static Code Analysis . . . . . . . . . . . . . . . . . . . . . . 36
6.3 Categories in FindBugs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.4 Flagged Security Vulnerability Types . . . . . . . . . . . . . . . . . . . . 38
6.5 Relevance of CWE Articles for Flagged Security Vulnerabilities . . . . . . 42
6.6 Structure of a Typical CWE Article . . . . . . . . . . . . . . . . . . . . . 43
7.1 Summary of Recommended Articles . . . . . . . . . . . . . . . . . . . . . 47
7.2 Summary of Participants . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
7.3 Paired Samples Test for Suitability . . . . . . . . . . . . . . . . . . . . . . 51
7.4 Paired Samples Test for Relevance . . . . . . . . . . . . . . . . . . . . . . 53
8.1 Primitive vs. tailored tf–idf based approach . . . . . . . . . . . . . . . . . 61
8.2 Primitive vs. tailored Jaccard index based approach . . . . . . . . . . . . . 66
ix

LIST OF FIGURES
1.1 Working of proposed system . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 Typical Cross Site Scripting (XSS) Attack . . . . . . . . . . . . . . . . . . 14
2.2 Example of SQL injection attack . . . . . . . . . . . . . . . . . . . . . . . 16
5.1 Architecture of the Proposed System . . . . . . . . . . . . . . . . . . . . . 30
5.2 Working of Recommender Module . . . . . . . . . . . . . . . . . . . . . . 33
6.1 Vulnerabilities Mapped to CWE articles . . . . . . . . . . . . . . . . . . . 40
6.2 Mapped CWE Articles with Potential Mitigations . . . . . . . . . . . . . . 41
7.1 Mean Suitability for Training . . . . . . . . . . . . . . . . . . . . . . . . . 52
7.2 Mean Relevance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
7.3 Overall result for all vulnerabilities . . . . . . . . . . . . . . . . . . . . . 55
8.1 Extracting nouns using POS Tagger . . . . . . . . . . . . . . . . . . . . . 58
8.2 The Modified Recommender Module . . . . . . . . . . . . . . . . . . . . 59
8.3 Primitive vs. tailored tf–idf based approach . . . . . . . . . . . . . . . . . 60
8.4 ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V1 62
8.5 ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V2 63
8.6 ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V3 64
8.7 ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V4 65
8.8 Primitive vs. tailored Jaccard index based approach . . . . . . . . . . . . . 67
x

8.9 Primitive vs. tailored Jaccard index based approach - outliers excluded . . . 68
8.10 ROC curves for primitive (L) and tailored (R) Jaccard index based approachesfor V1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
8.11 ROC curves for primitive (L) and tailored (R) Jaccard index based approachesfor V2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
8.12 ROC curves for primitive (L) and tailored (R) Jaccard index based approachesfor V3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
8.13 ROC curves for primitive (L) and tailored (R) Jaccard index based approachesfor V4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
8.14 Reported Vulnerabilites for Mozilla FireFox (A) . . . . . . . . . . . . . . 74
8.15 Reported Vulnerabilites for Mozilla FireFox (B) . . . . . . . . . . . . . . . 75
B.1 Form used for evaluation of training articles . . . . . . . . . . . . . . . . . 98
B.2 Form used for ranking of training articles . . . . . . . . . . . . . . . . . . 99
xi

CHAPTER 1
INTRODUCTION
1.1 Research Hypothesis
The following is the hypothesis for our research.
Potential vulnerabilities in an individual developer’s source code can be auto-matically mapped to relevant articles in public vulnerability repositories thatare suitable for training the developer regarding vulnerability mitigation.
1.2 Understanding the Problem
Security breaches in software systems are often caused by vulnerable code, which result
in loss of confidential data in addition to reputation and financial damages. A report1
published by Mcafee Inc. reveals that the world wide annual losses due to security breaches
are $375− $575 billion. Moreover, a report2 by Microsoft suggests that a defect found and
fixed, especially later in the development or post–development process, may cost 100 times
or even higher.
To achieve robust software security, developers must be given proper training on secure
coding practices. Conventional training methods are limited as they do not take the prior
code written by the developers into account.
1See http://www.mcafee.com/us/resources/reports/rp-economic-impact-cybercrime2.pdf (accessed Jan. 20, 2015).
2See http://www.microsoft.com/hun/getthefacts/ESGNov 2006SDL.mspx (ac-cessed Jan. 20, 2015).
1

The cost of fixing security vulnerabilities in later stages of software development life-
cycle can be exponentially high. Helping software developers to write secure code in the
first place is a key to avoid such costs.
1.3 Motivation and Objective
The motivation for this research is the idea that training for each software developer
should be in individually identified and focused areas of software security rather than a
generalized security training for all developers. The main objective of our proposed system
is to recommend precise and focused training articles to software developers. Our approach
intends to help developers avoid unsafe coding practices in an efficient and effective way.
1.4 Our Approach to Solving the Problem
Our approach relies on analyzing the code written or modified by individual developers
using static analysis tools3 e.g., FindBugs,4 which detect security and other vulnerabilities
present in the source code. We use the flagged vulnerabilities as the basis for identifying
most relevant training articles for developers who contributed to writing those chunks of
code, hence improving their skill in terms of software security. We explain our approach
with the help of a simple example in Figure 1.1.
It is important to mention that accurately identifying vulnerabilities in developers code
is the key to the success of proposed system.
3List of tools for static code analysis, http://en.wikipedia.org/wiki/List of toolsfor static code analysis (accessed Sep. 26, 2014).
4FindBugs, http://findbugs.sourceforge.net/ (accessed Sep. 26, 2014).
2

Figure 1.1
Working of proposed system
3

1.5 Defining the Recommender Systems
Recommender systems are a special type of information filtering system, which seek
to predict the rating or preference that a user would give to an item [50]. Recommender
systems have been widely used in recent years for various purposes. Common applications
of recommender systems include recommending music [29] or movies [5] based on users’
demographics and interests and recommending books, magazines [47], or news articles
[22] to potential readers or subscribers. Recommenders systems are also popular in social
media where they recommend personalized social updates [45] and social tags [7]. Online
merchants like Amazon boost sales by recommending appropriate products [63] and ser-
vices to their potential customers. In addition to the categories described above, there are
systems for recommending restaurants, insurance, and financial services.
The effectiveness of recommender systems across such a broad range of applications
suggested a novel application: Providing focused and precise security training to software
developers based on the past coding practices of each developer. Such training can be
more effective and efficient than the conventional generalized security training in terms of
helping developers to avoid unsafe coding practices.
1.6 Leveraging the Power of Open Source
The proposed recommender system makes use of valuable knowledge items in vulnera-
bility repositories, such as Common Weakness Enumeration, CWE, which are contributed
by software security experts across the globe, and are available for public use for free.
CWE repository is a unified, measurable set of software weaknesses. It enables more ef-
4

fective discussion, description, selection, and use of software security tools and services
that can find these weaknesses in source code.
With the help of a script, the proof-of-concept implementation of the proposed recom-
mender system downloaded and stored more than 700 articles from CWE repository. Each
article details a specific software weakness such as Cross Site Scripting, SQL injection,
use of hard–coded passwords, and buffer overflow.
The structure of each CWE article is same, and contains information on potential miti-
gation for the vulnerability along with other useful information, more details on the struc-
ture of CWE article can be found in later sections. The potential mitigation strategies in
CWE articles may serve as a training resource for the developers. The proof–of–concept
recommender system maps the discovered vulnerabilities in the source code to the CWE
articles to identify relevant articles which may be used to train different software develop-
ers.
Static code analysis [64], which is an emerging technique for secure software devel-
opment, analyzes large software code bases, without execution, to reveal potential vulner-
abilities present in the code. Static analysis can evaluate the system or a component of a
system based on its form, structure, content, or associated documentation. It is analogous
to the analysis of development products that rely on human examination. The proposed
recommender system utilizes open source static analysis tool(s) as one of it’s components.
Though the proof–of–concept recommender system uses only the CWE repository, the
proposed research will also consider other vulnerability repositories.
5

1.7 Organization
This document is organized int the following way. Chapter 2 discusses related work,
chapter 3 discusses the open source, commercial, and custom built tools used in this re-
search, chapter 4 outlines the research methodology, chapter 5 discusses the architecture of
the proposed recommender system, chapter 6 presents the preliminary case study, chapter
7 discusses the human subject evaluation of the recommender system, chapter 8 details
the tailored approach and compares them with the original approaches discussed in previ-
ous chapters, chapter 9 is based on discussion, and chapter 10 presents the conclusion and
future work.
6

CHAPTER 2
RELATED WORK
In this chapter we discuss the systematic mapping study on recommender systems for
software engineering, we also discuss potentially useful information retrieval algorithms,
and provide background information on different security vulnerabilities.
2.1 Recommender Systems for Software Engineering
The idea of recommender systems is not new for the software engineering domain.
Several recommender systems have been proposed or built to facilitate software developers
to perform various tasks. We briefly describe some well known recommender systems
below.
2.1.1 Debug Adviser
Debug Adviser [3] is a recommender system, which helps developers to fix software
bugs. A developer enters the contextual information of the bug into the tool, and the
tool searches through the repository of projects for bugs with similar context which have
already been fixed. It requries the developer to manually enter the bug information while
we make use of static analysis techniqes instead. Moreover, the scope of Debug Adviser
7

is limited to the project repository, while our proposed system makes use of vulnerability
repositories to recommend potential mitigation strategies.
2.1.2 Strathcona
Strathcona [26] is a recommendation tool to assist developers in finding relevant frag-
ments of code of an API’s use. The tool recommends examples that can be used by de-
velopers to provide insight on how they are supposed to interact with the API. Like our
system, the purpose of the Strathcona is to train developer, but its scope is focusing on use
of specific APIs.
2.1.3 Hipikat
Hipikat [17] is a recommender tool that scans a project’s archives and recommends arti-
facts from the archive that are related to the software developer’s task at hand. The artifacts
can be versions of source code modules, bugs reports, archived electronic communications,
and web documents. Hipikat is especially helpful for open source projects.
2.1.4 RASCAL
RASCAL [37] is a recommender agent that tracks usage histories of a group of devel-
opers to recommend to an individual developer components that are expected to be needed
by that developer based on the experiences of the groups. RASCAL works in the same
way as Hipikat to help new individuals to adjust in group setting efficiently, but it is not
specifically related to security training.
8

2.1.5 Recommender System for Requirements Elicitation
Requirements elicitation includes complex tasks for which recommender systems can
be helpful, examples of such tasks are identification of potential subject matter experts,
Recommender System to Support Requirements Elicitation [13] recommends possible fea-
tures for stakeholders to consider, and keeping stakeholders informed of relevant issues.
2.1.6 Contextual Recommendations
Context Based Recommendations for Software Developers [2] help software develop-
ers to use the elements of the source code in the integrated development environment (IDE)
in smarter ways by identifying the elements that are commonly related. The system pro-
vide an efficient way to reach the desired elements. This system is significantly different
from our proposed system as it helps developer only to identify related elements of source
code and use them effectively.
2.2 Systematic Mapping Study
To get a detailed insight of the existing recommender systems related to the domain of
software engineering, we conducted a systematic mapping study. This sections details our
mapping study.
The following creteria were used to filter the articles.
• Articles that do not address core software engineering functions were excluded.
• Mapping studies on recommender systems were excluded.
• User studies on recommender systems were excluded.
• Duplicate studies were excluded.
9

Table 2.1
Filtering Creteria
Filter criteria Excluded RemainingTotal articles found using search criteria 927Filtered to remove duplicate studies 141 786Filtered based on title of the article 653 133Filtered after reading abstract of the article 72 61Filtered after reading conclusions and results 7 54
The summary of filtering process is given in Table 2.1.
After conducting the systematic mapping study, we categorized the recommender sys-
tems based on their function, they are summarized in Table 2.2.
In addition to the categories of software engineering recommender systems shown in
Table 2.2, there are other systems for miscellaneous tasks e.g., recommender system for
identifying critical modules for rigorous testing [30], automated test recommendation [28],
selection of software development life cycle [32], assigning tasks (e.g., bug reports) to
software developers [36], envisioning a holistic view of recommender systems for software
engineering [48].
The recommender systems discussed in this section facilitate individual software devel-
opers in performing various software engineering tasks. However, we did not find literature
on recommender systems which, by utilizing static code analysis or otherwise, recommend
security related training topics to software developers.
More details about systematic mapping study can be found in the Appendix A.
10

Table 2.2
Recommender Systems for Software Engineering
Recommender system category Related systemsInformation retrievalThey facilitate software developers identifing relevantinformation and artifacts based on the context e.g.,source code snippets, software components for reuse,and API usage examples.
[2], [6], [16], [17], [18],[20], [21], [23], [24],[25], [33], [35], [37],[39], [52], [54], [60]
Software developmentThey enhance development environment for softwaredevelopers e.g., identifying tools or commands to usein an IDE, recommending meaningful method names.
[1], [31], [40], [61]
Software project managementThey facilitate software project management activi-ties e.g., effort estimation, identifying project team,assigning mentors to software project newcomers.
[15], [46], [55], [56]
Requirements specificationThey help in requirements specification, e.g., identi-fying non-functional requirements based on context.
[10], [14], [19], [53],[62]
Software design and architectureRecommender systems that facilitate maintainingsoftware architecture, e.g., identifying architecturalviolations in software, recommending design pat-terns.
[11], [44], [51], [58]
Other/ Miscellaneous[28], [30], [32], [36],[48]
11

2.3 Mapping Algorithms
Mapping algorithms are used to find similarity between two given documents, in this
research we intend to calculate similarity between the description of vulnerabilities and the
articles in the public vulnerability repositories. We intend to use the following mapping
algorithms.
1. Vector Space Model (VSM) with term frequency–inverse document frequency (tf–idf) [9].
2. Jaccard index or Jaccard similarity coefficient [57].
The Jaccard coefficient measures similarity between finite sample sets A and B.
J(A,B) =| A ∩B || A ∪B |
(2.1)
As it is obvious from equation (2.1) that the Jaccard coefficient does not take the weight
of the terms into account. However the tf–idf scores are offset by the frequency of the
words in the corpus, which helps to control the fact that some words are generally more
common than others. More details on tf–idf can be found in chapter 5.
2.4 Software Vulnerabilities
A vulnerability is a weakness in a software system that may be exploited by an at-
tacker. Some examples of vulnerabilities are Injection Attacks, Broken Authentication and
Session Management, Cross-Site Scripting (XSS), Insecure Direct Object References, Se-
curity Misconfiguration, Sensitive Data Exposure, Missing Function Level Access Control,
Cross-Site Request Forgery (CSRF), Using Components with Known Vulnerabilities, and
12

Unvalidated Redirects and Forwards. These examples have been taken from OWASP1 Top
Ten Project for the year 2013.
Exploiting these vulnerabilities results in financial and reputation losses to the organi-
zations in addition to the voilation of privacy of the individuals effected. Injection attacks
alone have caused several major data breaches to financial and healthcare organizations in
recent years. There are several preventive and reactive approaches to counter such vulner-
abilities, the work proposed in this research falls under the first category.
The code repository analyzed in our experiments involves four security vulnerabilities.
They are discussed briefly below.
2.4.1 Cross Site Scripting (XSS)
The Cross Site Scripting, or XSS, vulnerability allow an attacker to add malicious code
to a web application. When the infected application is accessed by victim, a legitimate
user, the malicious code/script executes on user’s web browser. The working of Cross Site
Scripting2 is explained in Figure 2.1.
The malicious code runs on victim’s computer everytime the infected webpage is ac-
cessed. Common consequences of XSS attack are session hijacking and stealing victim’s
confidential information.1OWASP, https://www.owasp.org/ (accessed Nov 21, 2014).2Typical XSS attack, http://www.pitsolutions.ch/blog/cross-site-scripting/
(accessed Jun 08, 2016).
13

Figure 2.1
Typical Cross Site Scripting (XSS) Attack
2.4.2 Hardcoded Constant Database Password
Source code responsible for establishing connection to the database engine may have
hardcoded database password, anyone with access to either the source code or the compiled
code can easily learn the password, which makes the entire application/database vulnera-
ble. Following is an example3 of such vulnerable code.
DriverManager.getConnection(url, "scott", "tiger");
In some cases, if establishing connection to the database fails, the application may
accidently display the hardcoded username and password to users through web browser.
3CWE - Hardcoded passwords, https://cwe.mitre.org/data/definitions/259.html(accessed Jun 08, 2016).
14

However, this is only possible if the application configuration permits its users to read
detailed error messages.
2.4.3 HTTP Response Splitting
The HTTP response splitting4 occurs when data enters a web application through an
untrusted source (the attacker). The web server does not neutralize or incorrectly neutral-
izes CR and LF characters before the data is included in outgoing HTTP headers.
Including unvalidated data in an HTTP header allows an attacker to specify the entirety
of the HTTP response rendered by the browser. When an HTTP request contains unex-
pected CR (carriage return, also given by %0d or \r) and LF (line feed, also given by %0a
or \n) characters the server may respond with an output stream that is interpreted as two
different HTTP responses (instead of one). An attacker can control the second response
and mount attacks such as cross-site scripting and cache poisoning attacks.
2.4.4 SQL Injection
A program becomes vulnernable to SQL injection attack if it allows a nonconstant
string to be passed to execute method of an SQL statement.
SQL injection attacks (SQLIAs) are launched by entering malicious characters into the
input fields of web applications resulting in a modified SQL query [42]. The concept of
SQL injection attack is explained in Figure 2.2.
4CWE - HTTP response splitting, https://cwe.mitre.org/data/definitions/113.html(accessed Jun 08, 2016).
15

Figure 2.2
Example of SQL injection attack
16

SQL injections have emerged as one of the most dangerous types of attacks to web-
based systems and are ranked number one among the Open Web Application Security
Project’s (OWASP) top ten vulnerabilities.
17

CHAPTER 3
TOOLS
This research involves use of different commercial, open source, and custom built tools
and APIs. In this chapter we briefly discuss these tools and APIs.
3.1 Tools for Static Analysis
There are plenty of proprietary and open source tools available which can analyze mil-
lions of lines of code and uncover various types of vulnerabilities. These vulnerabilities
include but are not limited to SQL injections, buffer overflows, cross site scripting, im-
proper security settings and information leakage [27].
Some tools can analyze code written in multiple languages while others are language
specific. Similarly, tools may differ with respect to the purpose they are built, some tools
scan the code for coding style, for example, proper comments and naming conventions,
while other look for vulnerabilities only.
To analyze the selected source code repositories, we plan to use the following tools.
• FindBugs analyzes Java codebases and finds several different types of potentialvulnerabilities in the code. The tool was created at the University of Maryland in2003. The tool is freely available for noncommercial use.
• HP Fortify Static Code Analyzer helps verify that software is trustwor-thy. It also helps developers identify software security vulnerabilities in a variety ofprogramming languages which include C, C++, Java, JSP, ASP/ASP.NET, PHP, Vi-sual Basic, VBScript, JavaScript, PL/SQL, COBOL. In addition it has the capability
18

to scan configuration files. To verify that the most serious issues are addressed first,it correlates and prioritizes results to deliver an accurate, risk-ranked list of issues.
Although these tools provide an efficient way of scanning large code repositories for
vulnerabilities, usually a high percentage of discovered vulnerabilities are actually false
positives [4] namely, discovered vulnerabilities are not actually present in the code. Soft-
ware development teams can spend many man-hours to track and fix the discovered vul-
nerabilities. The results generated by these tools can cause unproductive consumption of
time and resources [8].
3.2 Tools for Mapping Algorithms
SimScore is a .NET platform based implementation to calculate two statistics namely
tf–idf [9] and Jaccard index or Jaccard similarity coefficient [57]. This tool will be used
to calculate the similarity scores between the description of flagged vulnerabilities and the
articles in public vulnerability repositories. SimScore has been developed by the Empirical
Software Engineering Research Group of the Computer Science and Engineering Depart-
ment at Mississippi State University [34].
3.3 Part of Speech (POS) Tagger
We use the Part of Speech (POS) Tagger1,developed by Stanford University, reads text
in a given document and assigns parts of speech to each word.
1POS Tagger, http://nlp.stanford.edu/software/tagger.shtml (accessed Apr 20,2016).
19

3.4 LOC Calculator
We use LOC Calculator 1.2 which is a simple Java based tool for calculating
lines of code of source files. It scans a single file or a directory, it has option to ignore
white spaces. It ignores binary files.
3.5 Custom Built Tools
We use custom built tools for different purposes. All custom built tools have been made
publically available to facilitate other researchers. We briefly discuss the custom built tools
below.
3.5.1 Article Extractor
The Article Extractor extracts all the articles from the dictionary view of the
CWE2 repository and stores then in individual files. These articles serve as knowledgebase
for our recommender system.
3.5.2 Noun Extractor
This custom built tool has two important functions. First, it uses the Part of Speech
(POS) Tagger library to assign a part of speech to each word, such as noun, adjective, verb
etc., and creates a tagged document for every input document. Second, it reads the tagged
documents one by one, extracts nouns from the doucment, and stores them in a new file.
2CWE, http://cwe.mitre.org/ (accessed Apr 30, 2014).
20

3.6 Public Vulnerability Repositories
A public vulnerability repository contains information on vulnerabilities, potential mit-
igations, demonstrative examples, consequences, etc. These repositories are maintained
and made available for public use. They provide unified, effective, and standard informa-
tion on security vulnerabilities. Examples of such repositories are National Vulnerability
Database, NVD,3 Common Vulnerabilities and Exposures, CVE,4 and Common Weakness
Enumeration, CWE.These repositories are frequently updated and some of them do pro-
vide publically accepted solution along with other useful information on various software
security problems. The proposed recommender system leverages the power of public vul-
nerability repositories by mapping the flagged vulnerabilities in source code to the articles
in these repositories.
3NVD, https://nvd.nist.gov/ (accessed Apr 25, 2014).4CVE, http://cve.mitre.org/ (accessed Apr 30, 2014).
21

CHAPTER 4
RESEARCH METHODOLOGY
4.1 Hypothesis and Research Questions
Following is the hypothesis for our research:
Potential vulnerabilities in an individual developer’s source code can be auto-matically mapped to relevant articles in public vulnerability repositories thatare suitable for training the developer regarding vulnerability mitigation.
Conventional training techniques do not take the code written by the developers over
time into account, which makes training less effective. Static analysis helps identify the
security vulnerabilities in source code written by developers. Using appropriate mapping
algorithms, the flagged vulnerabilities can be mapped to the articles in public vulnerability
repositories. These articles contain useful information which may be used to train devel-
opers to write secure and robust code.
To generalize the core idea explained above, we conduct case studies on a large scale
open source system. There is evidence that the selected open source system has been used
by the research community for similar studies.
4.2 Research Questions
This dissertation attemps to answer the following research questions:
1. How do the recommendations based on CWE repository compare to recommenda-tion from HP Fortify in terms of training suitability?
22

2. How do the TF-IDF and Jaccard index algorithms compare to each other to identifyrelevant articles in public repositories given the evaluation of human subjects?
3. Regarding tailored approaches,
(a) How does the tailored mapping algorithm based on TF-IDF scores and addi-tional attributes, i.e., recency and completeness of the articles compare, to theother algorithms in terms of relevance?
(b) How does the tailored mapping algorithm based on Jaccard index scores andadditional attributes, i.e., recency and completeness of the articles, compare tothe other algorithms in terms of relevance?
4. What is the statistical profile of developers in the case study based on the following-parameters?
(a) Tendency to cause vulnerabilities over the case study window
(b) Recency of induced vulnerabilities
(c) Severity of induced vulnerabilities
The following sections discuss each research question in detail and lists the experiments
conducted to answer each question.
4.2.1 How do the recommendations based on CWE repository compare to recom-mendation from HP Fortify in terms of training suitability?
Public vulnerability repositories host useful information on software vulnerabilities.
This research question addresses whether or not this information can be used for training
purposes. We characterize these repositories to find out whether they are suitable as a
training resource to help developers write secure and robust code.
We compare the recommended articles from public vulnerability repository, i.e. the
CWE repository, with the articles from commercial tool’s repository. Detail about experi-
ment design to address this research question can be found in section 4.3.3 and 4.3.4.
23

4.2.2 How do the TF–IDF and Jaccard index algorithms compare to each other toidentify relevant articles in public repositories given the evaluation of humansubjects?
Our research primarily uses tf–idf and Jaccard Index based approaches to map flagged
vulnerabilities to the articles in public vulnerability repository. To answer this research
question we conduct a human subject evaluation. Detail about experiment design to ad-
dress this research question can be found in section 4.3.4 and 4.3.5.
4.2.3 Research questions regarding tailored approach
The research questions regarding tailored versions of tf–idf and Jaccard Index based
approaches are given as under.
4.2.3.1 How does the tailored mapping algorithm based on TF-IDF scores and ad-ditional attributes, i.e., recency and completeness of the articles compare, tothe other algorithms in terms of relevance?
We create a tailored version of tf–idf based approach and see if we can achieve im-
provement in terms of finding relevant training articles. The modified approach may in-
clude pre–processing the entire dataset in addition to incorporating attributes, i.e., recency
and completeness of the articles.
4.2.3.2 How does the tailored mapping algorithm based on Jaccard index and andadditional attributes, i.e., recency and completeness of the articles, compareto the other algorithms in terms of relevance?
We create a tailored version of Jaccard index based approach and see if we can achieve
improvement in terms of finding relevant training articles. The modified approach may in-
24

clude pre–processing the entire dataset in addition to incorporating attributes, i.e., recency
and completeness of the articles.
Detail about experiment design to address the research questions 4.2.3.1 and 4.2.3.2
can be found in section 4.3.5.
4.2.4 What is the statistical profile of developers in the case study based on the fol-lowing parameters?
1. Tendency to cause vulnerabilities over the case study window
2. Recency of induced vulnerabilities
3. Severity of induced vulnerabilities
To answer this research question, we analyze different versions of open source software
systems for security vulnerabilities and study the trends.
4.3 Experiment Design
This research involves three main experiments. First, the priliminary case study, which
is discussed in chapter 6; second, The human subject evaluation of the proposed recom-
mender system discussed in chapter 7; and third, the implementation of a tailored approach
discussed in chapter 8. The summary of dataset, pre–processing, and experiment is given
below.
4.3.1 Getting Dataset and Tools Ready
For experiments, we need to identify the following.
• Identify an open source systems, to be used as target code, say C.
25

• Identify and explore a static analysis tools, say T .
• Identify a public vulnerability repository, say V .
• Identify and implement two mapping algorithms, say A1 and A2.
• Identify a commercial tool that analyzes a given code repository and recommendstraining.
The next section discusses how do we pre–process the data.
4.3.2 Pre–processing
Once we identify target source code, tools, and public vulnerability repository, we pre–
process data as discussed below:
• Extract information from public vulnerability repository. Store information on eachvulnerability in a seperate file, the training articles.
• Exclude articles without mitigation strategies.
• Extract severity level of each vulnerability (to be used for prioritizing training).
The sections below discuss details about experiments.
4.3.3 Experiment I: Preliminary case study
This proof-of-concept case study validates the architecture of the proposed recom-
mender system with a preliminary empirical evaluation. The study is based on analysis
of a open source system using a open source static analysis tool, and uses a tf–idf based
approach to map identified vulnerabilities to the articles in public vulnerability repository.
The following experiment will be performed to answer the research question listed
above.
• Select three open source large scale real world systems to conduct different experi-ments explained in the following sections.
26

• Use two static analysis tools to find out security vulnerabilites in source code of eachselected open source system and compare the results for each case study.
• Analyze flagged vulnerabilities for potential training topics for individual develop-ers.
4.3.4 Experiment II: Human Subject Evaluation
The human subject evaluation of the system extends the preliminary study. In this
study we use Jaccard index, a set based approach, in addition to tf–idf based approach, for
fetching related articles from the public vulnerability repository. Moreover, we also draw
a comparison of our proposed system with a commercial tool.
A panel of sofware security experts will assess whether the training material will help
the trainee to write secure code in the future? They will be given recommended articles
mapped for different vulnerabilities flagged in source code. This will also provide a way to
find which public vulnerability repository has better and more well structured information,
and also which mapping algorithm has mapped more relevant articles.
The experts are expected to understand the vulnerabilities flagged in the code and the
articles in public vulnerability repositories. We intend to involve graduate students and
faculty members who fulfill criteria. Students enrolled in Software Security and Software
Reverse Engineering classes shall be approached by their respective professors, although
they may be required to participate in the study however the may opt to exclude their
responce from the data.
The following experiments will be performed to answer the research question listed
above.
27

• Identified experts will analyze and determine whether or not the mitigation strategiesrecommended by the mapping above for software vulnerabilities are suitable fortraining?
• Interrater agreement statistics will be calculated.
4.3.5 Experiment III: Implementation of Tailored Algorithms
This study is continuation of the previous studies and implements a tailored version
of our approach. We utilize the Part of Speech (POS) Tagger API to extract Nouns from
all the documents in dataset (i.e., flagged vulnerabilities and training articles from public
vulnerability repository). We also utilize parameters like length of articles in re-ranking the
training articles. Lastly, we analyze trends in discovery of vulnerabilities in open source
software.
28

CHAPTER 5
PROPOSED RECOMMENDER SYSTEM ARCHITECTURE
The architecture of the system shown in Figure 5.1 is the context for this research. This
is an extension to our preliminary design [38]. The preliminary design relies primarily on
the custom built training database whereas the refined architecture leverages the power of
vulnerability repositories in addition to custom built training database.
A short description of each module of the proposed system is given below:
5.1 Software Code Repository
The software code repository contains the source code and metadata which is analyzed
by the recommender system. Since, the proposed system may use any available static
analysis tool(s), which implies that the system is capable of handling source code written
in any programming language.
5.2 Static Code Analysis Module
This module contains one or more static analysis tools which scan the given code
repository to find vulnerabilities. The output of this phase is an XML based report contain-
ing details about detected vulnerabilities (e.g., filename, location, vulnerability descrip-
29

Figure 5.1
Architecture of the Proposed System
30

tion). Our system is flexible enough to use any tools for static analysis, which makes the
proposed system useful for virtually any programming environment.
5.3 Developers Performance Assessment Module
This module takes the results of the static analysis tool(s) and metadata of the software
repository as input and creates a profile for each developer. A profile primarily contains
the description of vulnerabilities induced by each developer in the code over time. The
profiles are fed into the recommendation module.
5.4 Public Vulnerability Repository
This module refers to one or more repositories containing information on vulnerabil-
ities, potential mitigations, demonstrative examples, consequences etc. These repositories
are maintained and made available for public use. They provide unified, effective, and
standard information on security vulnerabilities.
5.5 Custom Training Database
This refers to a database of custom designed training modules on various topics. This
database may also be populated with of-the-shelf training resources. However, this module
is optional, as we focus more on using the public vulnerability repositories as our knowl-
edgebase.
5.6 Recommender Module
The Recommender Module takes the profiles of developers as input and calculates
the similarity scores between vulnerability descriptions and the articles from vulnerability31

repositories. Moreover it queries the custom training database using the information in
developers profile to find most appropriate training modules. Output of the module is the
recommendation reports customized for individual developers. The Figure 5.2 explains the
working recommender module.
5.7 Training Delivery Module
This module accepts the recommendation report from the recommendation module
and delivers the training modules to the developers using multiple channels including video
streaming, tips delivered via an IDE plugin, and email messages containing helpful litera-
ture.
5.8 Intended benefits for practitioners
Practitioners can benefit from proposed recommender system in the following ways:
Getting Started is Easy. The developers don’t have to wait for the source code of their
current project to become available for analysis; rather, previously written code may be
analyzed to obtain precise and sepcific recommendations on secure coding practices.
Preventive Approach to Counter the Security Vulnerabilites. With the help of narrow
and precise training recommendations, the practitioners can avoid security vulnerabilites
in their source code. This can considerabily lower the effort and cost to fix these vulnera-
bilities at the later stagesof software development life cycle.
Low Cost Alternative to Commercial Tools. The practitioners can adopt our recom-
mender system which is based on open source tools and public vulnerability repository as
a low–cost alternative to commercial tools.
32

Figure 5.2
Working of Recommender Module
33

In this chapter we discussed the proposed architecture of computer–security training
recommender. It is very important to use the proposed system to analyze large scale open
source system. In next chapter, we present a preliminary case study.
34

CHAPTER 6
PRELIMINARY CASE STUDY
We conducted a proof–of–concept case study [41] to evaluate the feasibility of mapping
vulnerabilities discovered by a static analyzer to articles in a public vulnerability reposi-
tory. These articles generally present mitigation strategies. An open source system called
Tolven version 2.0 was the target source code. More information about the system and
download instructions may be found on the official website1. For static code analysis, we
used the open source tool FindBugs2 version 2.0.3. Code used for analysis is summarized
in Table 6.1.
Table 6.1
Summary of System Studied
Item DescriptionSystem analyzed Tolven 2.0Number of Java modules 2,957No. of non-empty lines of code 417,911(Calculated using LoC-Calculator 1.2)
1Tolven software downloads, http://tolven.org/download/ (accessed Feb. 11, 2014)2FindBugs, http://findbugs.sourceforge.net/ (accessed Sep. 26, 2014).
35

6.1 Quantitative Analysis
The quantitative study involve analysis of a selected open source system using static
code analysis tool “FindBugs”. Results of static code analysis are summarized in Table 6.2.
Since there can be multiple occurrences of a given vulnerability, the column Flagged Vul-
nerability types represents distinct vulnerabilities discovered while last column represents
Total occurrences for each category.
Table 6.2
Summary of Static Code Analysis
Category Flagged Defect Types Total OccurrencesBad practice 25 195Correctness 19 64Dodgy code 20 226Experimental 2 31Internationalization 1 105Malicious code vulnerability 8 323Multithreaded correctness 1 1Performance 15 220Security 4 14Totals 95 1179
Categories shown in Table 6.2 were generated by the FindBugs 2.0.3 tool. Even though
some of these categories seem closely related to each other, the short descriptions of the
categories in Table 6.3 show that the categories are distinct.
Every category listed in Table 6.2 has a number of flagged defect types. Due to space
limitations, all defect types cannot be listed. However in this study, we analyze the security
36
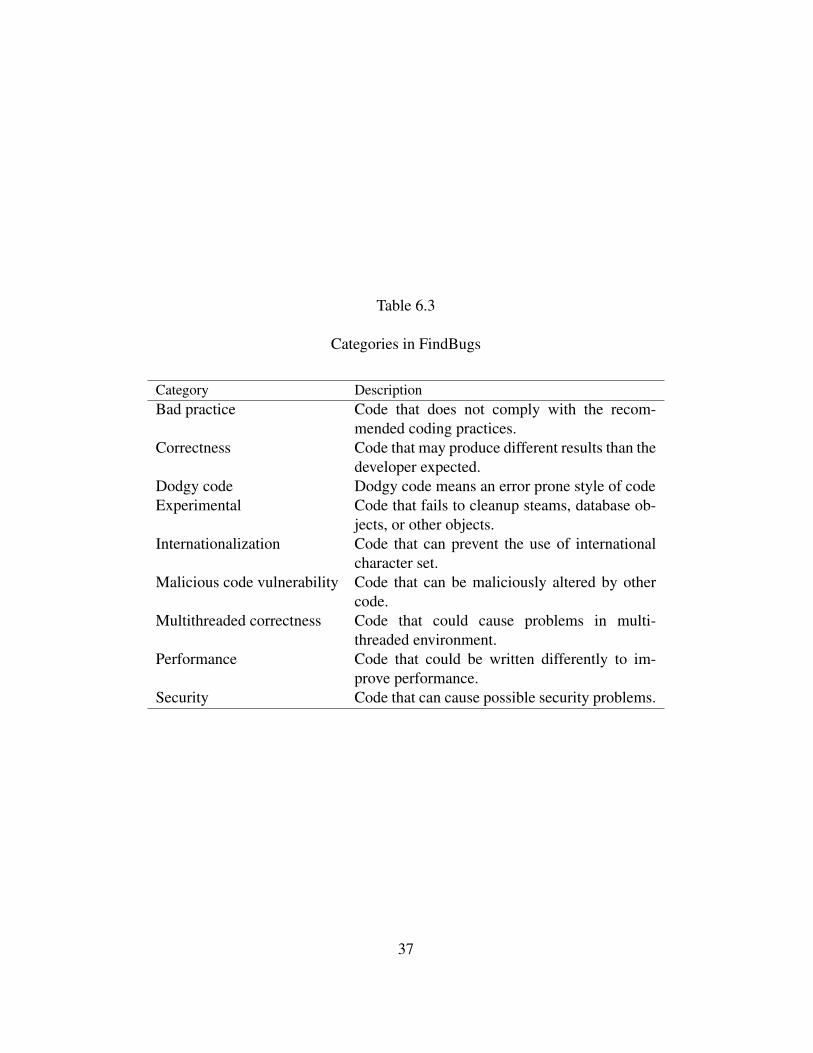
Table 6.3
Categories in FindBugs
Category DescriptionBad practice Code that does not comply with the recom-
mended coding practices.Correctness Code that may produce different results than the
developer expected.Dodgy code Dodgy code means an error prone style of codeExperimental Code that fails to cleanup steams, database ob-
jects, or other objects.Internationalization Code that can prevent the use of international
character set.Malicious code vulnerability Code that can be maliciously altered by other
code.Multithreaded correctness Code that could cause problems in multi-
threaded environment.Performance Code that could be written differently to im-
prove performance.Security Code that can cause possible security problems.
37

category in detail. The security vulnerabilities along with the number of occurrences are
listed in Table 6.4.
Table 6.4
Flagged Security Vulnerability Types
Vulnerability types in Security Category OccurrencesCross site scripting vulnerability 11Hardcoded constant database password 1HTTP Response splitting vulnerability 1Non-constant SQL string passed to execute method 1Total 14
All vulnerability types have a description generated by the FindBugs tool. We extracted
a description for each type and stored them in text documents.
We used Vector Space Model (VSM) with term frequency-inverse document frequency
(TFIDF) [9] weights to calculate the similarity between the vulnerability descriptions and
CWE articles. The indexing process includes removing English stop words from docu-
ments. Stemming is then applied to reduce words to their roots, thus improving the effec-
tiveness and the efficiency of the retrieval system [49].
The output of the indexing process is a compact content descriptor, or a profile, where
each document is represented as a set of terms:
T = {t1, t2, t3, ..., tn}. (6.1)
Each term ti in the set T is assigned a certain weight wi. Using TFIDF, the weight of
each word is calculated as:38

wi = tf i · idfi (6.2)
Where tf i is the frequency of term ti in the document and idfi is the inverse document
frequency, and is computed as:
idfi = log2(n/dfi) (6.3)
Where n is the total number of documents in the collection, and dfi is the number of
artifacts in which term ti occurs. TFIDF determines how relevant a given word is in a
particular document. Words that are common in a single or a small group of documents
tend to have higher TFIDF, while terms that are common in all documents such as articles
and prepositions get lower TFIDF values.
Since the documents are represented as weighted vectors in the N-dimensional space,
the similarity of any two documents can be measured as the cosine of the angle between
their vectors as follows:
Sim(v, a) =
∑vi · ai√∑v2i ·
∑a2i
(6.4)
In equation (6.4), Sim(v, a) is similarity score between vulnerability description v and
CWE article a.
The approach discussed above was implemented to automatically calculate similarity
scores between descriptions of the flagged vulnerabilities and CWE articles. Both, flagged
vulnerability types and CWE articles were stored in text files. There were 95 flagged
vulnerability types and 717 repository articles. The mapped articles were filtered based on
39

the threshold value of 0.35 which was set after carefully reviewing a sample of mapped
articles in each category.
Figure 6.1
Vulnerabilities Mapped to CWE articles
Figure 6.1 shows that 81 out of 95 vulnerability description files were successfully
mapped to the related CWE articles. The mapping algorithm failed to find relevant CWE
articles for the remaining the 14 vulnerability types. The possible reasons for failing to
map these vulnerabilities to CWE articles could be the fact that the status of some of the
articles is still Draft or Incomplete. Once the articles in CWE repositories are updated, we
expect that the success rate will go higher.
Figure 6.2 shows the mapped CWE articles for each category of vulnerabilities. It
can be observed that most of the articles have potential mitigation section. Articles which
currently do not, might not be very helpful for training purpose.
40
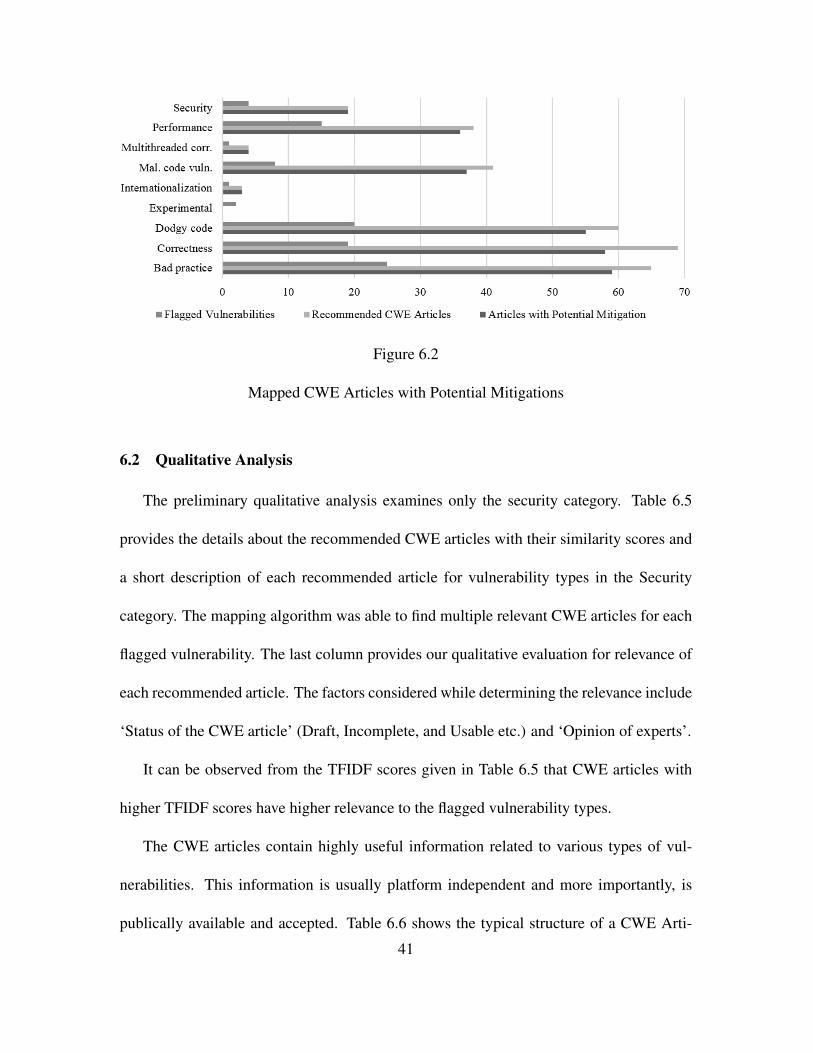
Figure 6.2
Mapped CWE Articles with Potential Mitigations
6.2 Qualitative Analysis
The preliminary qualitative analysis examines only the security category. Table 6.5
provides the details about the recommended CWE articles with their similarity scores and
a short description of each recommended article for vulnerability types in the Security
category. The mapping algorithm was able to find multiple relevant CWE articles for each
flagged vulnerability. The last column provides our qualitative evaluation for relevance of
each recommended article. The factors considered while determining the relevance include
‘Status of the CWE article’ (Draft, Incomplete, and Usable etc.) and ‘Opinion of experts’.
It can be observed from the TFIDF scores given in Table 6.5 that CWE articles with
higher TFIDF scores have higher relevance to the flagged vulnerability types.
The CWE articles contain highly useful information related to various types of vul-
nerabilities. This information is usually platform independent and more importantly, is
publically available and accepted. Table 6.6 shows the typical structure of a CWE Arti-
41

Tabl
e6.
5
Rel
evan
ceof
CW
EA
rtic
les
forF
lagg
edSe
curi
tyV
ulne
rabi
litie
s
Vul
nera
bilit
yty
peR
ecom
men
ded
CW
EA
rtic
les
with
the
title
sT
FID
FR
elev
ance
Scor
eC
ross
site
scri
ptin
gC
WE
079
Impr
oper
Neu
tral
izat
ion
ofIn
putD
urin
gW
ebPa
geG
ener
atio
n1.
0470
Hig
hvu
lner
abili
tyC
WE
644
Impr
oper
Neu
tral
izat
ion
ofH
TT
PH
eade
rsfo
rScr
iptin
gSy
ntax
0.47
49M
ediu
mH
ardc
oded
CW
E52
2In
suffi
cien
tlyPr
otec
ted
Cre
dent
ials
0.77
39H
igh
cons
tant
data
base
CW
E25
9U
seof
Har
d-co
ded
Pass
wor
d0.
7359
Hig
hpa
ssw
ord
CW
E25
6Pl
aint
extS
tora
geof
aPa
ssw
ord
0.68
58H
igh
CW
E64
0W
eak
Pass
wor
dR
ecov
ery
Mec
hani
smfo
rFor
gotte
nPa
ssw
ord
0.63
42M
ediu
mC
WE
798
Use
ofH
ard-
code
dC
rede
ntia
ls0.
5803
Hig
hC
WE
261
Wea
kC
rypt
ogra
phy
forP
assw
ords
0.57
37M
ediu
mC
WE
620
Unv
erifi
edPa
ssw
ord
Cha
nge
0.52
31L
owC
WE
309
Use
ofPa
ssw
ord
Syst
emfo
rPri
mar
yA
uthe
ntic
atio
n0.
5142
Low
CW
E18
7Pa
rtia
lCom
pari
son
0.50
03L
owC
WE
260
Pass
wor
din
Con
figur
atio
nFi
le0.
4536
Med
ium
CW
E25
8E
mpt
yPa
ssw
ord
inC
onfig
urat
ion
File
0.38
16M
ediu
mC
WE
263
Pass
wor
dA
ging
with
Lon
gE
xpir
atio
n0.
3794
Low
HT
TP
Res
pons
eC
WE
113
Impr
oper
Neu
tral
izat
ion
ofC
RL
FSe
quen
ces
inH
TT
PH
eade
rs1.
5627
Hig
hsp
littin
gvu
lner
abili
tyC
WE
650
Trus
ting
HT
TP
Perm
issi
onM
etho
dson
the
Serv
erSi
de0.
6569
Hig
hC
WE
644
Impr
oper
Neu
tral
izat
ion
ofH
TT
PH
eade
rsfo
rScr
iptin
gSy
ntax
0.53
60H
igh
Non
-con
stan
tSQ
LC
WE
089
Impr
oper
Neu
tral
izat
ion
ofSp
ecia
lEle
men
tsus
edin
SQL
stm
t.0.
4768
Hig
hst
ring
pass
edto
exe-
cute
met
hod
CW
E48
4O
mitt
edB
reak
Stat
emen
tin
Switc
h0.
3839
Low
42

cle. Important sections of a CWE article, to be used as training resource in the proposed
recommender system, are highlighted in Table 6.6.
Table 6.6
Structure of a Typical CWE Article
DescriptionTime of IntroductionApplicable PlatformsModes of IntroductionCommon ConsequencesLikelihood of ExploitEnabling Factors of ExploitationDetection MethodsDemonstrative ExamplesObserved ExamplesPotential MitigationsRelationshipsRelationship NotesTaxonomy MappingsRelated Attack PatternsWhite Box DefinitionsReferencesContent History
Although the Potential Mitigations section will serve as the core of training materials,
other sections like Description, Demonstrative Examples, Detection Methods, and Com-
mon Consequences can also be useful for developers.
6.3 Conclusions
In this chapter, we demonstrated the technical feasibility of mapping vulnerability type
descriptions to a large collection of articles describing solutions, hence validating the pro-
43

posed architecture of the system. We were able to map most of the flagged vulnerabilities
to articles in CWE repository. Also, we found that most of the articles in CWE repository
contain mitigation strategies and other useful information to understand and avoid security
vulnerabilities. Hence, such articles can be used to train the software developers.
Given the technically feasible architecture, we conducted human subject evaluation to
compare the effectivness of the proposed system to a commercial tools that provide similar
recommendations to software developers. The details about human subject evaluation are
given in next chapter.
44

CHAPTER 7
HUMAN SUBJECT EVALUATION
The human subject evaluation of the recommender system is a continuation to the work
presented in chapter 6. This chapter outlines how the study was designed and executed.
In this chapter, we answer the following research questions:
1. How do the recommendations based on CWE repository compare to recommenda-tion from commercial tool’s repository in terms of training suitability?
2. How do the tf–idf and Jaccard index algorithms compare to each other to identifyrelevant articles in public repositories given the evaluation of human subjects?
7.1 Apparatus, Materials, and Artifacts
Jaccard index and tf–idf algorithms produce a numeric score for each possible pair of
CWE article and identified vulnerability; however, for evaluation, we selected the top two
most relevant articles using each algorithm for each vulnerability.
In addition to using Jaccard index and tf–idf based approaches, we also used a com-
mercial tool to analyze our target source code. The primary purpose of using a commercial
tool was to use it as a standard to evaluate our recommender system. The commercial tool
uses a proprietary repository to recommend articles for training the software developers. It
fetches exactly one article for each flagged security vulnerability.
45

Hence, five articles in total were provided to each human expert for evaluation. The
articles were arranged in random order. Any identifying information about the article (e.g.,
whether it has been taken from CWE or commercial tools repository) is removed before it
is presented to the human expert for evaluation.
Table 7.1 summarizes the identified vulnerabilities and the recommended articles for
each vulnerability.
7.2 Experimental Design
The evaluation of each article was based on three criteria: relevance, suitability for
training, and the amount of information in the article. We used a five point Likert scale
for evaluation. For relevance and suitability 1 = Not relevant or Not suitable and
5 = Highly relevant or Highly suitable, whereas for amount of information 1 = Too
little, 3 = Just right, and 5 = Too much information.
There were 44 human subjects who voluntarily participated in the study. Each partici-
pant was assigned to evaluate the articles for one vulnerability. All subjects had previous
software development experience and had sound software security background. Table 7.2
summarizes the information about participants, including major field of study.
7.3 Data Collection
The participants were briefed about the recommender system and the task to be com-
pleted. They were allotted one hour to complete the survey. The subject experts reviewed
the survey material to make sure that participants had a sufficient amount of time to care-
fully read and evaluate the survey material. Any identifying information about participants
46

Tabl
e7.
1
Sum
mar
yof
Rec
omm
ende
dA
rtic
les
Vul
nera
bilit
yD
escr
iptio
nN
umbe
rofr
ecom
men
ded
artic
les
Tota
lart
icle
stf
–idf
Jacc
ard
Com
mer
cial
forh
uman
subj
ect
inde
xto
olto
eval
uate
V1
XSS
-Cro
ssSi
teSc
ript
ing
vuln
erab
ility
22
15
V2
SQL
Inje
ctio
nvu
lner
abili
ty2
21
5V
3H
TT
PR
espo
nse
split
ting
vuln
erab
ility
22
15
V4
Har
dcod
edco
nsta
ntda
taba
sepa
ssw
ord
22
15
47

Tabl
e7.
2
Sum
mar
yof
Part
icip
ants
No.
ofpa
rtic
ipan
tsAv
erag
eex
peri
ence
Com
pute
rSci
ence
Soft
war
eE
lect
rica
l&So
ftw
are
deve
lopm
ent
Soft
war
ese
curi
tyE
ngin
eeri
ngC
ompu
terE
ngin
eeri
ng(y
ears
)(y
ears
)25
136
1.68
0.6
48

was detached from the collected data before it was compiled. The researchers obtained
formal permission from Institutional Review Board (IRB)1 of the Mississippi State Uni-
versity before conducting the human subject evaluation. More details about data collection
and experiment design can be found in Appendix B.
7.4 Analysis Methods
For analysis of data we used paired t–test and mixed model ANOVA. Since tf–idf and
Jaccard index are two different methods of measurements therefore the paired t–test2 is the
suitable way to compare their means. Using the same test we compared the means of tf–idf
and Jaccard index to the mean of commercial tool.
Mixed model ANOVA3 is suitable as we are testing for differences among independent
groups and subjecting our participants to repeated measures of independent variables. The
groups in our data are formed on the basis of four vulnerabilities (serving as between–
group factor) and three approaches (serving as within–group factor).
Details about the paired t–test and ANOVA can be found in the following section.
7.5 Results
This section discusses the results of the human subject evaluation. As per our study de-
sign, each participant was asked to evaluate five articles identified by the three approaches
(i.e., tf–idf, Jaccard Index, and commercial tool) for one vulnerability. The four vulnera-
1IRB, http://orc.msstate.edu/humansubjects/2Paired t–test, http://www.statstutor.ac.uk/resources/
uploaded/paired-t-test.pdf/3Mixed Model ANOVA, https://en.wikipedia.org/wiki/
Mixed-design analysis of variance/
49

bilities (V1, V2, V3, and V4) served as a between–groups factor while the three approaches
served as a within–groups factor in a 4x3 mixed model ANOVA. The analysis shows that
both tf–idf and commercial tool were significantly better than Jaccard index based ap-
proach F (2, 80) = 12.57, p < .001.
For further analysis we excluded the Jaccard index based approach and conducted the
ANOVA using four vulnerabilities and two approaches (i.e., tf–idf and commercial tool) in
a 4x2 mixed model. The small F − value of 0.006(p < .85) strongly suggests that both
approaches are equally good.
The following subsections discuss results about ‘suitability for training’ and ‘rele-
vance’.
7.5.1 Suitability for training
The estimated marginal mean for ‘suitability for training’ of different approaches, as
evaluated by the human subjects, is shown in Figure 7.1. The result of paired t–test for
‘suitability for training’ can be found in Table 7.3. The results are explained below.
tf–idf vs. commercial tool. The paired t–test suggests that there is no significant dif-
ference between the tf–idf based approach and commercial tool in terms of finding articles
suitable for training the software developers. Estimated marginal mean shown in Figure 7.1
and Figure 7.3 suggest the same. Hence, the articles from CWE repository are as good as
the articles from commercial tool’s repository in terms of suitability for training; Hence,
the answer to our first research question.
50

Tabl
e7.
3
Pair
edSa
mpl
esTe
stfo
rSui
tabi
lity
Pair
Mea
nSt
d.D
ev.
Std.
Err
orM
ean
tdf
Sig.
(2ta
iled)
tf–i
df-C
omm
erci
alto
ol.0
451.
461
.220
.206
43.8
38tf
–idf
-Jac
card
inde
x.8
401.
627
.245
3.42
743
.001
Com
mer
cial
tool
-Jac
card
inde
x.7
951.
935
.291
2.72
643
.009
51
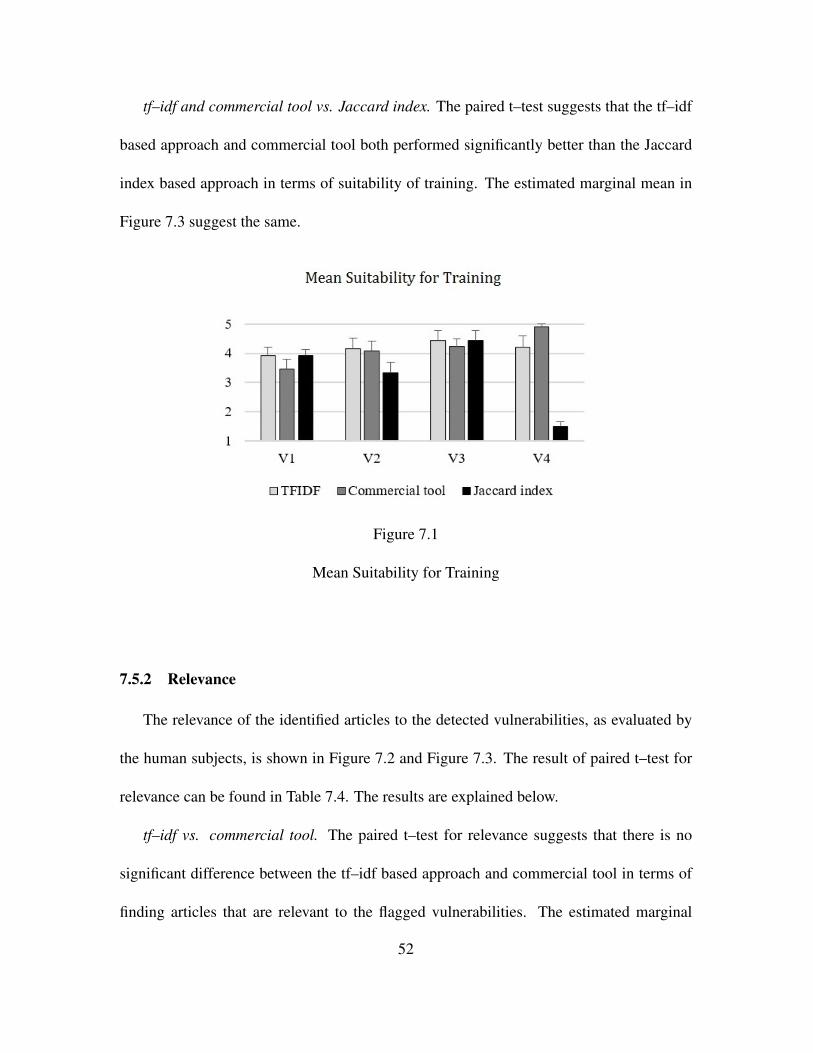
tf–idf and commercial tool vs. Jaccard index. The paired t–test suggests that the tf–idf
based approach and commercial tool both performed significantly better than the Jaccard
index based approach in terms of suitability of training. The estimated marginal mean in
Figure 7.3 suggest the same.
Figure 7.1
Mean Suitability for Training
7.5.2 Relevance
The relevance of the identified articles to the detected vulnerabilities, as evaluated by
the human subjects, is shown in Figure 7.2 and Figure 7.3. The result of paired t–test for
relevance can be found in Table 7.4. The results are explained below.
tf–idf vs. commercial tool. The paired t–test for relevance suggests that there is no
significant difference between the tf–idf based approach and commercial tool in terms of
finding articles that are relevant to the flagged vulnerabilities. The estimated marginal
52

Tabl
e7.
4
Pair
edSa
mpl
esTe
stfo
rRel
evan
ce
Pair
Mea
nSt
d.D
ev.
Std.
Err
orM
ean
tdf
Sig.
(2ta
iled)
tf–i
df-C
omm
erci
alto
ol-.1
131.
125
.169
-.670
43.5
06tf
–idf
-Jac
card
inde
x.5
001.
210
.182
2.74
043
.009
Com
mer
cial
tool
-Jac
card
inde
x.6
131.
204
.181
3.37
843
.002
53

mean for relevance also in Figure 7.2 and Figure 7.3 suggest the same. Hence, the articles
from the CWE repository are as good as the articles from commercial tool’s repository in
terms of their relevance to the flagged vulnerabilities.
Figure 7.2
Mean Relevance
tf–idf vs. Jaccard index. The paired t–test for relevance suggests that the tf–idf based
approach is significantly better than the Jaccard index based approach. The estimated
marginal mean in Figure 7.3 suggest the same. This give us basis for answering our second
research question.
In this chapter, with the help of human subject evaluation, we concluded that CWE
repository is as effective as commercial tool’s repsitory in terms of ‘suitability of training’.
Moreover, we found that tf–idf based approach as accurate as commercial tool in terms of
finding articles relevant to flagged vulnerabilities.
54

Figure 7.3
Overall result for all vulnerabilities
In the next chapter, we discuss the tailored version of tf–idf and Jaccard index based
approaches and experiments conducted to evaluate their performance.
55

CHAPTER 8
TAILORED ALGORITHMS
This chapter discuss two important experiments. In the first part, i.e., section 8.1, we
discuss the the design and evaluation of tailored version of our tf–idf and Jaccard index
based approaches to map discovered vulnerabilities to the articles in public vulnerability
repository. In the second part, i.e., section 8.2, we analyze security vulnerability trends in
open source software.
8.1 Evaluation of Tailored Approaches
Improving the accuracy of information retrieval algorithms has always been challeng-
ing. In chapter 7, we discussed how stemming and stop words can help improving the ac-
curacy of our approaches. In addition to stemming and stop words, our tailored approaches
also utilize the Part of Speech (POS) Tagger API and custom built tools to transform the en-
tire dataset. The similarity scores are calculated after the transformation. In the future, we
also plan to use parameters like length of articles in re-ranking the recommended training
articles.
56

8.1.1 POS Tagger and Noun–based Search
A Part-Of-Speech Tagger (POS Tagger) [59] is a piece of software that reads text in
some language and assigns parts of speech to each word (and other token), such as noun,
verb, adjective, etc., although generally computational applications use more fine–grained
POS tags like ‘noun-plural’.
Literature suggests that taking the linguistic narture of the words into account can be
another way to improve the accuracy of information retrieval approaches. A study on
Noun–based indexing of software artifacts [12] reported significant improvement in the
accuracy of information retrieval. We are introducing this idea in our recommender system.
8.1.2 Extracting Nouns
The dataset used in our experiment, (i.e., flagged vulnerabilities and training articles
from public vulnerability repository), are pre–processed using POS Tagger and the custom
built Noun Extractor tool. The working is explained in Figure 8.1.
The POS Tagger creates a ‘tagged–file’ for each input file. The ‘tagged–file’ is then
input to the cutom built Noun extractor tool, which extracts all nouns and stores them into
a new file. Hence the entire dataset is transformed. Our tailored approach modifies the
working of the recommender module, The ‘Modified Recommender Module’ is shown in
Figure 8.2.
57
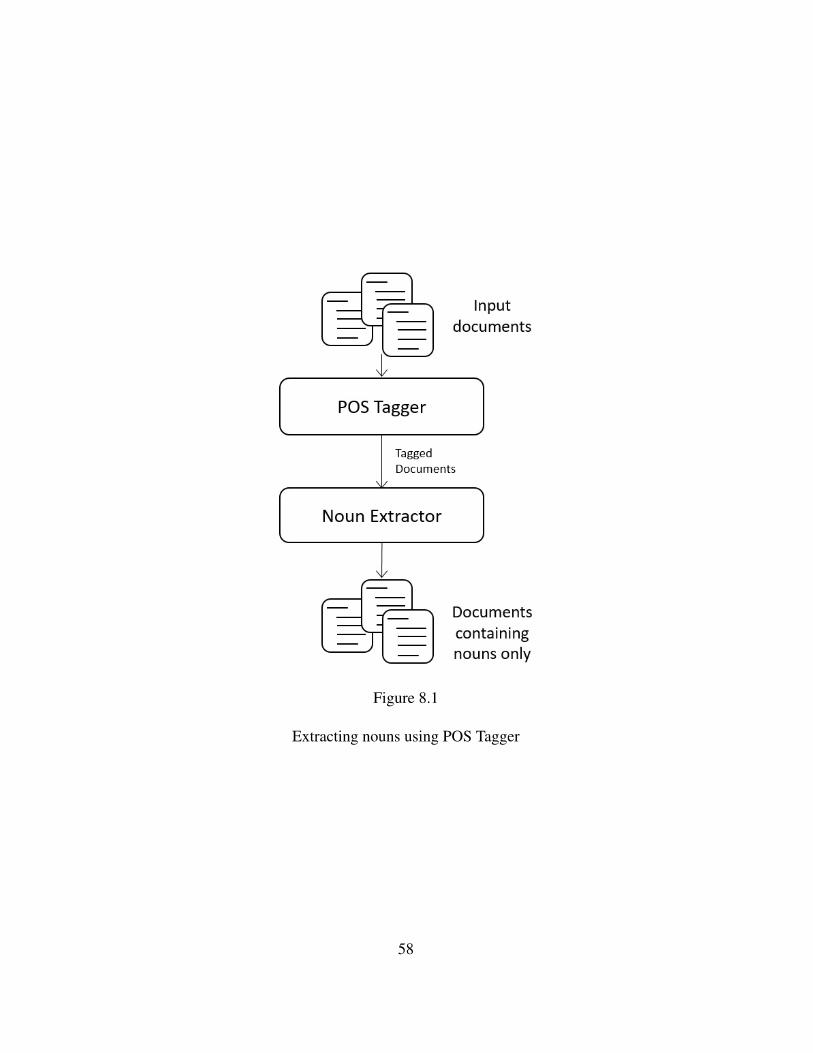
Figure 8.1
Extracting nouns using POS Tagger
58

Figure 8.2
The Modified Recommender Module
8.1.3 Results
In this section we compare the primitive approaches, discussed in chapter 7, with our
tailored approaches. We use Receiver Operating Characteristic (ROC)1 curve to com-
pare the ranking performance of primitive and tailored tf–idf and Jaccard index based
approaches.
8.1.3.1 Primitive vs. Tailored tf–idf Based Approach
The comparison between the primitive and tailored tf–idf based approach is shown in
Figure 8.3. The smaller values represent better ranking. For a given vulnerability, say
Cross Site Scripting or V1, the tailored approach was able to rank all the relevant articles
in a better way compared to the primitive tf–idf based approach.
1ROC Curve, https://en.wikipedia.org/wiki/Receiver operating characteristic(accessed May 15, 2016).
59

Figure 8.3
Primitive vs. tailored tf–idf based approach
60

The tailored approach ranked all relevant articles within top 12 articles compared to
the primitive tf–idf based approach which ranked the same articles within top 31. Same is
true for V2 and V4; However, for the HTTP Response Splitting vulnerability, or V3, both
approaches performed equally good.
The ranking data for primitive and tailored tf–idf based approaches is given in Ta-
ble 8.1.
Table 8.1
Primitive vs. tailored tf–idf based approach
Vulnerability type Top ‘n’ articles that contain all relevant articlesPrimitive tf–idf Tailored tf–idfbased approach based approach
V1, Cross Site Scripting 31 12V2, Hard–coded database password 28 13V3, HTTP Response splitting 7 8V4, SQL injection 19 4
The ROC curves for primitive and tailored tf–idf based approach for Cross Site Script-
ing vulnerability i.e., V1, are shown in Figure 8.4.
The ROC curves for primitive and tailored tf–idf based approach for Hard–coded con-
stant database password i.e., V2, are shown in Figure 8.5.
The ROC curves for primitive and tailored tf–idf based approach for HTTP Response
Splitting vulnerability i.e., V3, are shown in Figure 8.6.
The ROC curves for primitive and tailored tf–idf based approach for SQL injection
vulnerability i.e., V4, are shown in Figure 8.7.
61

Figure 8.4
ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V1
62

Figure 8.5
ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V2
63
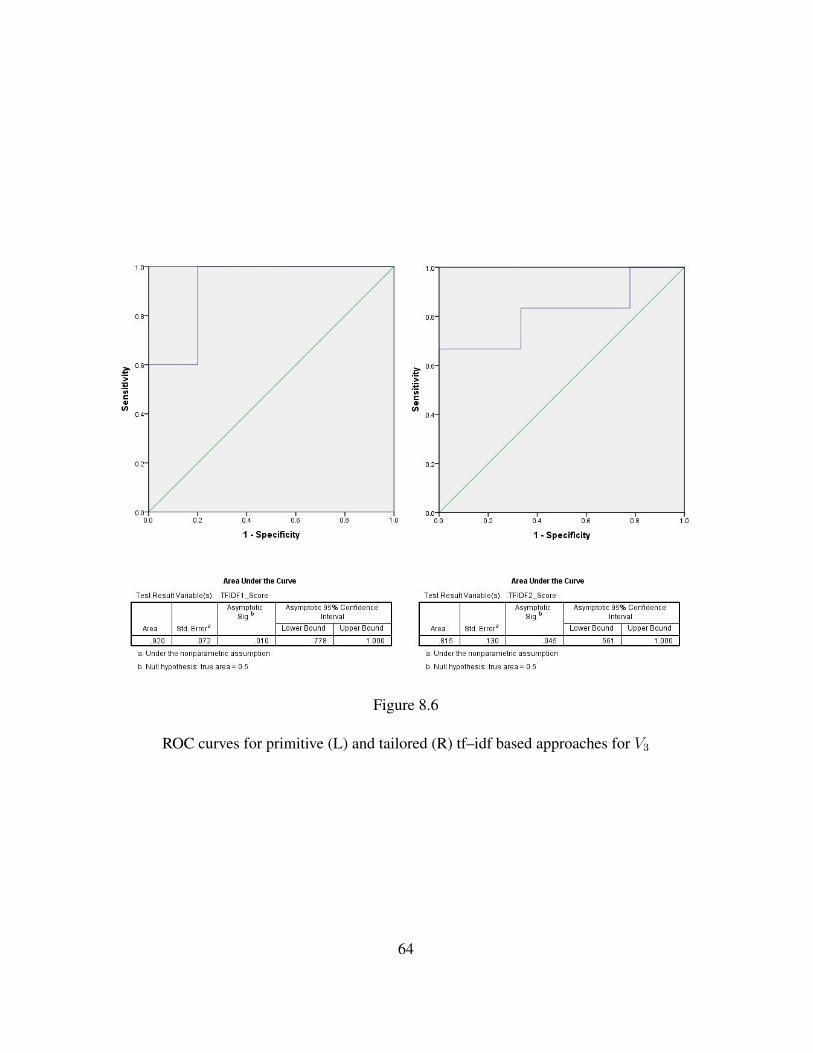
Figure 8.6
ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V3
64

Figure 8.7
ROC curves for primitive (L) and tailored (R) tf–idf based approaches for V4
65

8.1.3.2 Primitive vs. Tailored Jaccard Index Based Approach
The comparison between the primitive and tailored Jaccard index based approach is
shown in Figure 8.8. As discussed in the previous section, the smaller scores represent
better ranking. The tailored version of Jaccard index based approach performed better than
the primitive approach for Cross Site Scripting vulnerability (V1), the hard–coded password
vulnerability (V2), and the SQL injection vulnerability (V4). However, due to some outliers,
the tailored approach performed worse than the primitive approach for HTTP Response
Splitting vulnerability (V3).
The ranking data for primitive and tailored Jaccard index based approaches is given in
Table 8.2.
Table 8.2
Primitive vs. tailored Jaccard index based approach
Vulnerability type Top ‘n’ articles that contain all relevant articlesPrimitive Jaccard index Tailored Jaccard index
based approach based approachV1, Cross Site Scripting 59 9V2, Hard–coded database password 32 18V3, HTTP Response splitting 24 68V4, SQL injection 31 11
For further analysis, we removed the outliers from the ranking data, the modified results
are shown in Figure 8.9.
The ROC curves for primitive and tailored Jaccard index based approach for Cross Site
Scripting vulnerability i.e., V1, are shown in Figure 8.10.
66

Figure 8.8
Primitive vs. tailored Jaccard index based approach
67
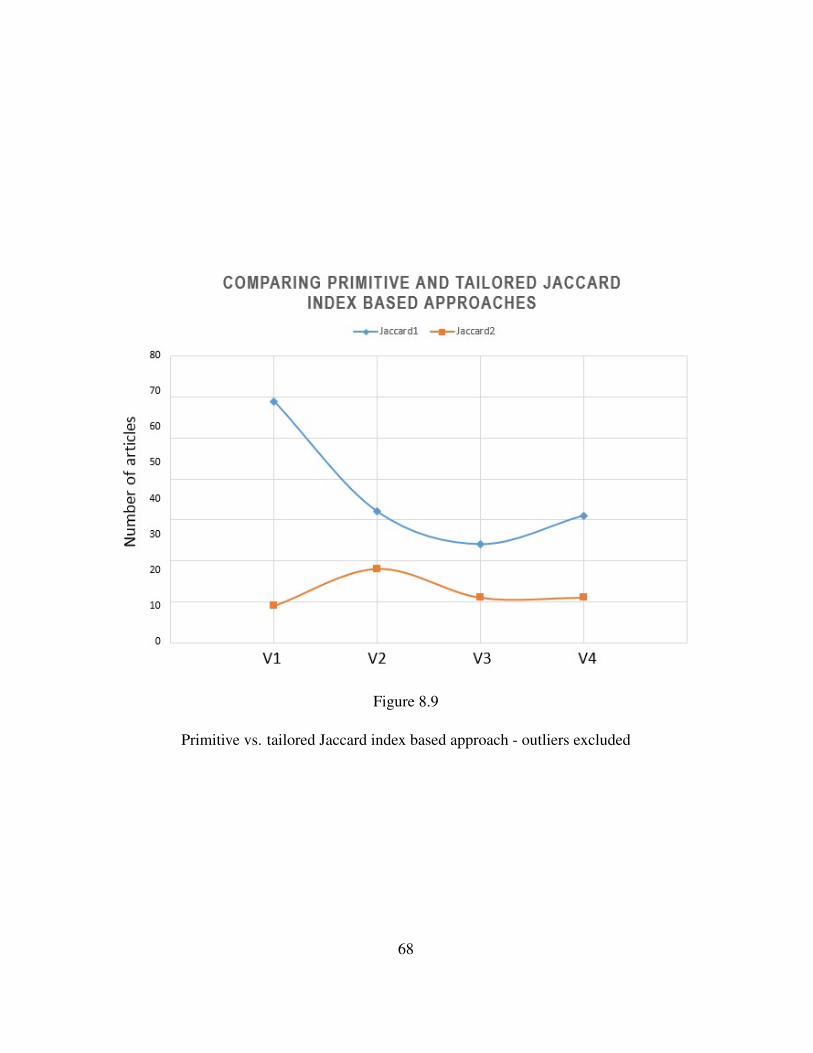
Figure 8.9
Primitive vs. tailored Jaccard index based approach - outliers excluded
68
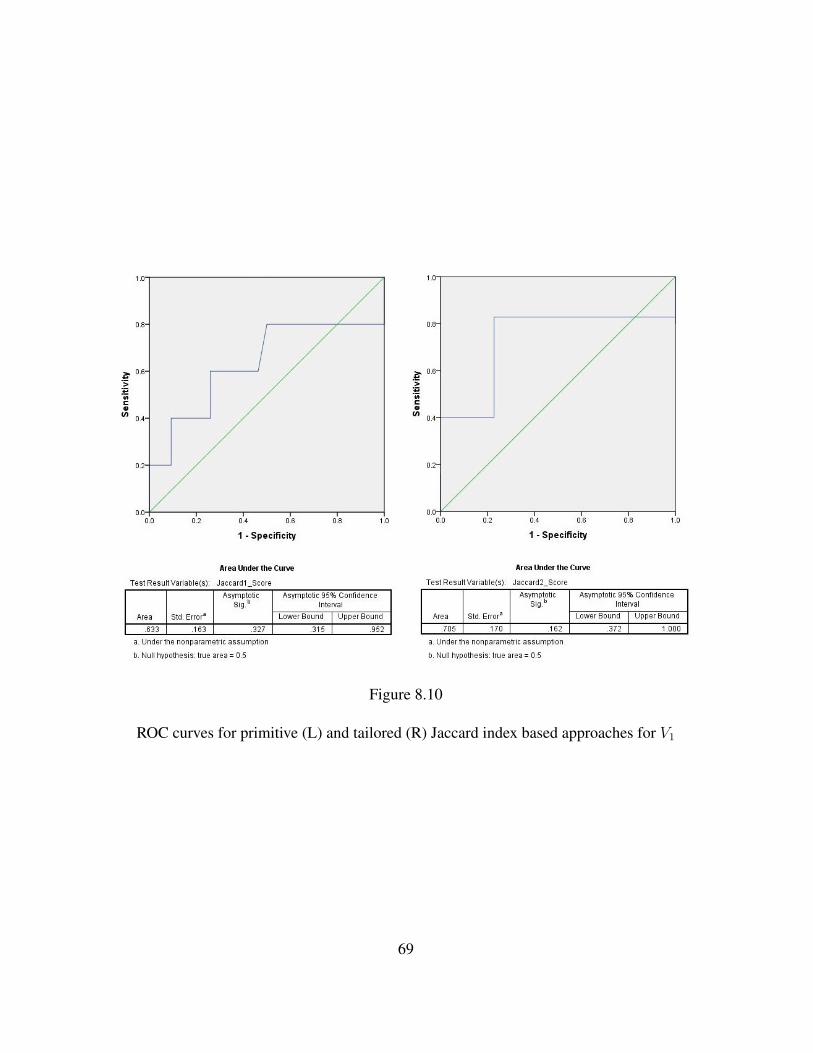
Figure 8.10
ROC curves for primitive (L) and tailored (R) Jaccard index based approaches for V1
69

The ROC curves for primitive and tailored Jaccard index based approach for Hard–
coded constant database password i.e., V2, are shown in Figure 8.11.
The ROC curves for primitive and tailored Jaccard index based approach for HTTP
Response Splitting vulnerability i.e., V3, are shown in Figure 8.12.
The ROC curves for primitive and tailored Jaccard index based approach for SQL in-
jection vulnerability i.e., V4 is shown, are Figure 8.13.
8.2 Analyzing Security Vulnerability Trends in Open Source Software
We analyzed the data regarding reported vulnerabilities2,in different open source soft-
ware systems. In case of Mozila Firefox, we analyzed data for Denial of Service (DoS),
Code Execution, Overflow, Cross Site Scripting (XSS), Bypass some mechanism, and In-
formation Gain vulnerabilities reported over several years.
8.2.1 Results
Figure 8.14 and Figure 8.15 show trends of these reported vulnerabilities. We found
evidence that the vulnerabilities discovered in a specific version of such widely used open
source software product were propogated to the newer versions of the prodcut despite the
fact that software developers working on newer versions of the products had access to
the reported vulnerabilities. Which brings us to the conclusion that providing narrow and
focused security training to software developers may bar propogation of known vulnera-
bilities to the newer versions of software product.
2CVE Datasource, http://www.cvedetails.com/ (accessed Apr 22, 2016).
70

Figure 8.11
ROC curves for primitive (L) and tailored (R) Jaccard index based approaches for V2
71

Figure 8.12
ROC curves for primitive (L) and tailored (R) Jaccard index based approaches for V3
72

Figure 8.13
ROC curves for primitive (L) and tailored (R) Jaccard index based approaches for V4
73

Figure 8.14
Reported Vulnerabilites for Mozilla FireFox (A)
74

Figure 8.15
Reported Vulnerabilites for Mozilla FireFox (B)
75

CHAPTER 9
DISCUSSION
In this dissertation, with the help of experiments and human subject evaluation, we
found that the potential vulnerabilities in an individual developer’s source code can be au-
tomatically mapped to relevant articles in public vulnerability repositories that are suitable
for training the developer regarding vulnerability mitigation.
This chapter discusses findings for our research questions.
9.1 Research Questions
In this section we lists the research questions, result for each question with evidence,
and significance of result for our recommender system and rest of the research community.
1. How do the recommendations based on CWE repository compare to recommenda-tion from HP Fortify in terms of training suitability?
Result:Based on the results of human subject evaluation, given in chapter 7, it is concludedthat articles in CWE repository are as suitable for training as articles in commercialtool’s repository.
Significance:CWE repository can be used as knowledgebase for recommender system discussedin this study and other similar systems. Moreover, automated code transformationtools may use the information in CWE repository
2. How do the tf–idf and Jaccard index algorithms compare to each other to identifyrelevant articles in public repositories given the evaluation of human subjects?
76

Result:Based on the results of human subject evaluation, given in chapter 7, it is concludedthat tf–idf based approach is significantly better than Jaccard index based approachin terms of identifying relevant articles from public vulnerability repository.
Significance:Our future research will focus on tf–idf based approach; moreover, our findings willbenefit the research community.
3. Regarding tailored approaches,
(a) How does the tailored mapping algorithm based on tf–idf scores and additionalattributes, i.e., recency and completeness of the articles compare, to the otheralgorithms in terms of relevance?Result:Based on the results of experiment, discussed in chapter 8, it is concluded thattailored tf–idf based approach performed better than primitive tf–idf based ap-proache (discussed in chapter 7) in terms of ranking the articles.Significance:Modified architecture of our recommender system should have a customizablePOS tagger module, which should allow extracting other parts of speech in ad-dition to nouns.
(b) How does the tailored mapping algorithm based on Jaccard index scores andadditional attributes, i.e., recency and completeness of the articles, compare tothe other algorithms in terms of relevance?Result:Based on the results of experiment, discussed in chapter 8, it is concluded thattailored Jaccard index based approach performed better than primitive Jaccardindex based approache (discussed in chapter 7) in terms of ranking the articles.However, none of the Jaccard index based approach performed better than tf–idf based approaches.Significance:Future work of our research should use tf–idf based approaches as primarymeans of mapping flagged vulnerablities to training articles.
4. What is the statistical profile of developers in the case study based on the following-parameters?
(a) Tendency to cause vulnerabilities over the case study window
(b) Recency of induced vulnerabilities
77

(c) Severity of induced vulnerabilities
Result:Based on the analysis of open source software systems, given in chapter 8, we foundevidence that the vulnerabilities discovered in a specific version of a widely usedopen source software product can be propogated to the newer versions of the prod-cut. Which brings us to the conclusion that narrow and focused security trainingto software developers may bar propogation of known vulnerabilities to the newerversions of software product.
Significance:There is need to analyze factors that result in increase in vulnerabilities.
9.2 Threats to Validity
The experiments and results discussed in this dissertation have the following threats to
validity.
9.2.1 Generic Limitation of Static Analysis Tools
The generic limitations to the static analysis tools may introduce some inaccuracies
or limitations in our system. The static analysis tools may produce false positive or false
negative results. A false positive refers to detection of a vulnerability by the tool in the
given code which actually is not a vulnerability [43]. Often a high percentage of discovered
vulnerabilities are actually false positives [4]. The results generated by such tools can cause
unproductive consumption of time and resources [8].
9.2.1.1 Implication of False Positive Results
Since the recommender discussed in this study relies on the result of static analysis tool
therefore some of the security–training recommended by our system may not actually be
needed. On the other hand a false positive may still indicate an undesirable coding pattern
78

for which training would be helpful. However, the static analysis tool used in this study
may not be representative of other similar tools.
9.2.1.2 Implication of False Negative Results
A false negative detection refers to a vulnerability that actually exists in a software
code repository but the static analysis tools is unable to detect. False negative detections
means our system will not recommend training to the software developers which should
have been recommended.
9.2.2 Analysis Limited to one Open Source System
The experiments conducted in this dissertation are limited to the analysis of one open
source system. We discussed in chapter 6 that the target system, i.e., Tolven 2.0, has
already been used by research community in security related studies. However, Replicating
the study to other open source systems, especially with known vulnerabilities, will help to
further validate the effectiveness of the proposed recommender system.
9.2.3 Analysis Limited to one Open Source System
We compare the articles identified by our recommender system to only one commercial
tool’s recommended articles. Comparing the proposed system with other similar systems
will also help to validate the effectiveness and accuracy of our system.
9.2.4 Human Factors
Some of our findings solely rely on the human subject evaluation; e.g., we found that
the articles in CWE repository are as suitable for training as the articles in the commercial79

tool’s repository. Similarly, with the help of human subject evaluation we found that tf–idf
based approach performed better than the Jaccard index based approach. The human bias
may be a threat to the validity of our findings.
In this chapter, we presented the result and its significance for each research question.
We also discussed different factors that impose threats to the validity of our results. The
next chapter focuses on contribution and future work of this dissertation.
80

CHAPTER 10
CONCLUSIONS
10.1 Hypothesis
Before moving to the conclusion, let’s revisit the hypothesis for our research:
Potential vulnerabilities in an individual developer’s source code can be auto-matically mapped to relevant articles in public vulnerability repositories thatare suitable for training the developer regarding vulnerability mitigation.
10.2 Conclusion
In this study, with the help of human subject evaluation, we found that the proposed
computer security–training recommender (with tf–idf based approach) performed as good
as the commercial tool in terms of finding relevant articles from their respective repsi-
tories based on the flagged vulnerabilities. We also found that both the CWE and com-
mercial tool’s repository host articles which are equally suitable for training the software
developers. Hence, the proposed recommender system may be adopted by the software
organizations as a low-cost alternative to commercial tools. Training articles from public
vulnerability repository are not limited on any specific programming language or platform
which gives our system an edge over the commercial tool.
10.3 Contributions
This research has the following contributions.
81

10.3.1 The proposed architecture
The major contribution of this research is the architectue of the system, which has been
discussed in detail in chapter 5. The proposed architecture is flexible and can be used
with a variety of open source tools, hence making it useful for software developers with
different programming backgrounds.
10.3.2 Evaluation of Different Approaches for Recommending System
Evaluation of effectiveness of three approaches to retrieve training articles from public
vulnerability repository based on the flagged vulnerabilities in the source code.
10.3.3 Proposing and Evaluating Tailored Approach
In addition to using the primitive tf–idf and Jaccard index based approach to retrieve
training articles, this research proposed and evaluated tailored approaches which proved to
be better than the primitive alogrithms.
10.3.4 Evaluation of CWE Articles for Suitability for Training
Empirical evidence, based on human subject evaluation, indicating that an open source
tools based approach, which utilizes public vulnerability repository, can be as effective as
commercially available tools for training the software developers.
10.3.5 Low Cost Alternative to Commercial Tools
The proposed system, which primarily relies on open source static analysis tools and
public vulnerability repository is a potential alternative to the commercial tools. Software
organizations may significantly reduce the training cost by utilizing the proposed system.82

Also, the human subject evaluation has suggested that there is no significant difference
between the proposed system and commercial tool.
10.4 Publication Plan
Parts of this research have already been published in different conference proceedings.
However, we plan to publish the following completed work:
• A systemic mapping study on recommender systems for software engineering
• ComputerSecurity Training Recommender for software developers: Using POS-Tagger to pre-process dataset
• Analyzing security vulnerability trends in open source software systems
The identified target journals include IEEE Transaction on Software Engineering and Jour-
nal of Empirical Software Engineering.
10.5 Future Work
In work done so far, we presented the architecture for a computer–security training
recommender and demonstrated the technical feasibility of mapping vulnerability type de-
scriptions to a large collection of articles describing solutions. This work may be extended
in the following possible ways:
10.5.1 Expanding Knowledgebase
The proof-of-concept implementation uses the CWE articles, however the other vulner-
ability databases e.g., National Vulnerability Database, NVD, host useful data related to
security checklists, security related software flaws, misconfigurations, and impact metrics.
83

By utilizing the NVD database along with CWE articles, the scope of our recommender
system may expand.
10.5.2 Improving Static Analysis
The static analysis tools produce false positive results. Using other static code analysis
tools, in addition to FindBugs, and comparing their output may help reducing the false
positive detections.
10.5.3 Automatic Code Generation
Although the primary objective of the recommender system is to recommend precise
and focused solution to the security problems detected in developers code, there are other
ways the proposed system may be used. For instance if the mitigation strategies given in
the vulnerability repositories are detailed and standardized, a new module may be added in
the recommender system which will replace the vulnerable code with secure code, hence
adding a self–healing capability to the software. A Recommender system may periodically
check for the newer solution and change the obsolete fixes with new ones.
10.5.4 Usability Studies
The usability study involves building a working prototype of the proposed recom-
mender system and deploying it in software organizations to train the software developers
and observing the improvement in terms of writing secure and robust code.
84

10.5.5 Prioritizing the Training for Software Developers
The severity level of the identified vulnerability may also be used in our system to
prioritize the training for software developers. Common Vulnerability Scoring System
(CVSS)1 is one of the potential options that could serve our purpose.
10.5.6 Improving Mapping Algorithms
Different variations of mapping algorithms can designed and implemented to get fur-
ther improvement in identifying relevant articles.
1CVSS, https://nvd.nist.gov/cvss.cfm/
85

REFERENCES
[1] T. Akinaga, N. Ohsugi, M. Tsunoda, T. Kakimoto, A. Monden, and K. I. Matsumoto,“Recommendation of software technologies based on collaborative filtering,” Pro-ceedings: 12th Asia-Pacific Software Engineering Conference, Taipei, Taiwan, Dec.2005, IEEE Computer Society, pp. 209–214.
[2] B. Antunes, J. Cordeiro, and P. Gomes, “An approach to context-based recommenda-tion in software development,” Proceedings: 6th ACM Conference on RecommenderSystems, Dublin, Ireland, Sept. 2012, ACM, pp. 171–178.
[3] B. Ashok, J. Joy, H. Liang, S. K. R. G. Srinivasa, and V. Vangala, “DebugAdvisor:a recommender system for debugging,” Proceedings: 7th joint meeting of the Eu-ropean software engineering conference and the ACM SIGSOFT symposium on Thefoundations of software engineering, Amsterdam, Netherlands, Aug. 2009, ACM, pp.373–382.
[4] A. Austin and L. Williams, “One Technique is Not Enough: A Comparison of Vul-nerability Discovery Techniques,” Proceedings: 5th International Symposium onEmpirical Software Engineering and Measurement, Banff, Canada, Sept. 2011, IEEEComputer Society, pp. 97–106.
[5] A. Azaria, A. Hassidim, S. Kraus, A. Eshkol, O. Weintraub, and I. Netanely, “Movierecommender system for profit maximization,” Proceedings: 7th ACM conference onRecommender systems, Hong Kong, Oct. 2013, ACM, pp. 121–128.
[6] E. A. Barbosa, A. Garcia, and M. Mezini, “A Recommendation System for ExceptionHandling Code,” Proceedings: 5th International Workshop on Exception Handling,Zurich, Switzerland, June 2012, IEEE Computer Society, pp. 52–54.
[7] F. Belem, R. Santos, J. Almeida, and M. Goncalves, “Topic diversity in tag rec-ommendation,” Proceedings: 7th ACM conference on Recommender systems, HongKong, Oct. 2013, ACM, pp. 141–148.
[8] A. Bessey, K. Block, B. Chelf, A. Chou, B. Fulton, S. Hallem, C. Henri-Gros,A. Kamsky, S. McPeak, and D. Engler, “A few billion lines of code later: usingstatic Analysis to find Bugs in the Real World,” Communications of the ACM, vol.53, no. 2, Feb. 2010, pp. 66–75.
86

[9] D. Binkley and D. Lawrie, Encyclopedia of Software Engineering, chapter Infor-mation retrieval applications in software development, John Wiley and Sons, Inc.,Hoboken, NJ, USA, 2010, pp. 231–242.
[10] M. B. Blake, I. Saleh, Y. Wei, I. D. Schlesinger, A. Yale-Loehr, and X. Liu, “Sharedservice recommendations from requirement specifications: A hybrid syntactic andsemantic toolkit,” Information and Software Technology, May 2014, pp. 1–13.
[11] A. Bockmann, MARS: Modular Architecture Recommendation System, master’sthesis, Faculty of Informatics of the University of Lugano, Ticino, June 2010.
[12] G. Capobianco, A. D. Lucia, R. Oliveto, A. Panichella, and S. Panichella, “ImprovingIR–based Traceability Recovery via Noun–based Indexing of Software Artifacts,”Journal of Software: Evolution and Process, vol. 25, no. 7, July 2013, pp. 743–762.
[13] C. Castro-Herrera and J. Cleland-Huang, “Utilizing recommender systems to sup-port software requirements elicitation,” Proceedings: 2nd International Workshop onRecommendation Systems for Software Engineering, Cape Town, South Africa, May2010, ACM, pp. 6–10.
[14] C. Castro-Herrera, J. Cleland-Huang, and B. Mobasher, “Enhancing StakeholderProfiles to Improve Recommendations in Online Requirements Elicitation,” Pro-ceedings: 17th IEEE International Requirements Engineering Conference, Atlanta,GA, USA, Sept. 2009, IEEE Computer Society, pp. 37–46.
[15] R. Colomo-Palacios, I. Gonzalez-Carrasco, J. L. Lopez-Cuadrado, and A. Garcıa-Crespo, “ReSySTER: A hybrid recommender system for Scrum team roles based onfuzzy and rough sets,” International Journal of Applied Mathematics and ComputerScience, vol. 22, no. 4, 2012, pp. 801–816.
[16] J. Cordeiro, B. Antunes, and P. Gomes, “Context-Based Recommendation to Sup-port Problem Solving in Software Development,” Proceedings: Third InternationalWorkshop on Recommendation Systems for Software Engineering, Zurich, Switzer-land, June 2012, IEEE Computer Society, pp. 85–89.
[17] D. Cubranic and G. C. Murphy, “Hipikat: Recommending pertinent software devel-opment artifacts,” Proceedings: 25th International Conference on Software Engi-neering, Portland, OR, USA, May 2003, IEEE Computer Society, pp. 408–418.
[18] D. Cubranic, G. C. Murphy, J. Singer, and K. S. Booth, “Hipikat: a project memoryfor software development,” IEEE Transactions on Software Engineering, vol. 31, no.6, 2005, pp. 446–465.
87

[19] A. Danylenko and W. Lowe, “Context-aware recommender systems for non-functional requirements,” Proceedings: 3rd International Workshop on Recommen-dation Systems for Software Engineering, Zurich, Switzerland, June 2012, IEEEComputer Society, pp. 80–84.
[20] E. Duala-Ekoko and M. P. Robillard, “Using structure-based recommendations tofacilitate discoverability in APIs,” ECOOP 2011 Object-Oriented Programming,M. Mezini, ed., vol. 6813 of Lecture Notes in Computer Science, Springer BerlinHeidelberg, Berlin, Germany, 2011, pp. 79–104.
[21] T. Fritz, Developer-Centric Models: Easing Access to Relevant Information, doc-toral dissertation, The Faculty of Graduate Studies, University Of British Columbia,Vancouver, Canada, Apr. 2011.
[22] F. Garcin, C. Dimitrakakis, and B. Faltings, “Personalized News Recommendationwith Context Trees,” Proceedings: 7th ACM conference on Recommender systems,Hong Kong, Oct. 2013, ACM, pp. 105–112.
[23] X. Ge, D. Shepherd, K. Damevski, and E. Murphy-Hill, “How Developers Use Multi-Recommendation System in Local Code Search,” Proceedings: IEEE Symposium onVisual Languages and Human-Centric Computing, Melbourne, Australia, July 2014,IEEE Computer Society.
[24] A. Grzywaczewski and R. Iqbal, “Task-specific information retrieval systems forsoftware engineers,” Journal of Computer and System Sciences, vol. 78, no. 4, 2012,pp. 1204–1218.
[25] R. Holmes, “Do developers search for source code examples using multiple facts?,”Proceedings: ICSE Workshop on Search-Driven Development-Users, Infrastructure,Tools and Evaluation, Vancouver, Canada, May 2009, IEEE Computer Society, pp.13–16.
[26] R. Holmes, R. J. Walker, and G. C. Murphy, “Strathcona example recommendationtool,” ACM SIGSOFT Software Engineering Notes, vol. 30, no. 5, Sept. 2005, pp.237–240.
[27] M. Howard, D. LeBlanc, and J. Viega, 19 Deadly Sins of Software Security, 1stedition, McGraw-Hill/Osborne, Emeryville, CA, USA, 2005.
[28] W. Janjic and C. Atkinson, “Utilizing software reuse experience for automated testrecommendation,” 8th International Workshop on Automation of Software Test, SanFrancisco, CA, USA, May 2013, IEEE Computer Society, pp. 100–106.
[29] M. Kaminskas, F. Ricci, and M. Schedl, “Location-aware music recommendationusing auto-tagging and hybrid matching,” Proceedings: 7th ACM conference onRecommender systems, Hong Kong, Oct. 2013, ACM, pp. 17–24.
88

[30] S. Kpodjedo, F. Ricca, P. Galinier, and G. Antoniol, “Not all classes are createdequal: toward a recommendation system for focusing testing,” Proceedings: 2008International Workshop on Recommendation Systems for Software Engineering, At-lanta, GA, USA, Nov. 2008, ACM, pp. 6–10.
[31] A. Kuhn, “On recommending meaningful names in source and UML,” Proceedings:2nd International Workshop on Recommendation Systems for Software Engineering,Cape Town, South Africa, May 2010, ACM, pp. 50–51.
[32] K. Kumar and S. Kumar, “A rule-based recommendation system for selection of soft-ware development life cycle models,” ACM SIGSOFT Software Engineering Notes,vol. 38, no. 4, 2013, pp. 1–6.
[33] W. Lijie, F. Lu, W. Leye, L. Ge, X. Bing, and Y. Fuqing, “APIExample: An effectiveweb search based usage example recommendation system for java APIs,” Proceed-ings: 26th IEEE/ACM International Conference on Automated Software Engineering,Lawrence, KS, USA, Nov. 2011, IEEE Computer Society, pp. 592–595.
[34] A. Mahmoud and N. Niu, “Source Code Indexing for Automated Tracing,” Proceed-ings: 6th International Workshop on Traceability in Emerging Forms of SoftwareEngineering, Honolulu, HI, USA, May 2011, ACM, pp. 3–9.
[35] Y. Malheiros, A. Moraes, C. Trindade, and S. Meira, “A Source Code RecommenderSystem to Support Newcomers,” Proceedings: 36th IEEE Annual Computer Softwareand Applications Conference, Izmir, Turkey, July 2012, IEEE Computer Society, pp.19–24.
[36] D. Matter, A. Kuhn, and O. Nierstrasz, “Assigning bug reports using a vocabulary-based expertise model of developers,” Proceedings: 6th IEEE International WorkingConference on Mining Software Repositories, Vancouver, Canada, May 2009, IEEEComputer Society, pp. 131–140.
[37] F. McCarey, M. . Cinnide, and N. Kushmerick, “Rascal: A recommender agent foragile reuse,” Artificial Intelligence Review, vol. 24, no. 3–4, 2005, pp. 253–276.
[38] S. Muneer, M. Nadeem, and E. B. Allen, “Recommending Training Topics for De-velopers Based on Static Analysis of Security Vulnerabilities,” Proceedings: 52ndACM Southeast Conference, Kennesaw, GA, USA, Mar. 2014, ACM.
[39] N. Murakami and H. Masuhara, “Optimizing a search-based code recommendationsystem,” Proceedings: Third International Workshop on Recommendation Systemsfor Software Engineering, Zurich, Switzerland, June 2012, IEEE Computer Society,pp. 68–72.
89

[40] E. Murphy-Hill, R. Jiresal, and G. C. Murphy, “Improving software developers’fluency by recommending development environment commands,” Proceedings: 20thInternational Symposium on the Foundations of Software Engineering, Cary, NC,USA, Nov. 2012, ACM.
[41] M. Nadeem, E. B. Allen, and B. J. Williams, “Computer Security Training Recom-mender for Developers,” Poster Proceedings: 8th ACM Conference on RecommenderSystems, Silicon Valley, CA, USA, Oct. 2014, ACM.
[42] M. Nadeem, F. P. Haecker, B. R. Rice, B. N. Pilate, B. J. Williams, and E. B. Allen,“Evaluating Effectiveness of Approaches to Counter SQL Injection Attacks,” PosterProceedings: IEEE SoutheastCon 2016, Norfolk, VA, Mar. 2016, IEEE ComputerSociety.
[43] M. Nadeem, B. J. Williams, and E. B. Allen, “High false positive detection of securityvulnerabilities: a case study,” Proceedings: 50th Annual ACM Southeast RegionalConference, Tuscaloosa, AL, USA, Mar. 2012, ACM, pp. 359–360.
[44] F. Palma, H. Farzin, Y. Gueheneuc, and N. Moha, “Recommendation system for de-sign patterns in software development: An DPR overview,” Proceedings: Third Inter-national Workshop on Recommendation Systems for Software Engineering, Zurich,Switzerland, June 2012, IEEE Computer Society, pp. 1–5.
[45] Y. Pan, F. Cong, K. Chen, and Y. Yu, “Diffusion-aware personalized social updaterecommendation,” Proceedings: 7th ACM conference on Recommender systems,Hong Kong, Oct. 2013, ACM, pp. 69–76.
[46] B. Peischl, M. Nica, M. Zanker, and W. Schmid, “Recommending Effort EstimationMethods for Software Project Management,” Proceedings: IEEE/WIC/ACM Inter-national Joint Conferences on Web Intelligence and Intelligent Agent Technologies,Milan, Italy, Sept. 2009, IEEE Computer Society, vol. 3, pp. 77–80.
[47] M. S. Pera and Y.-K. Ng, “What to read next? Making personalized book recom-mendations for K-12 users,” Proceedings: 7th ACM conference on Recommendersystems, Hong Kong, Oct. 2013, ACM, pp. 113–120.
[48] L. Ponzanelli, “Holistic Recommender Systems for Software Engineering,” Pro-ceedings: 36th International Conference on Software Engineering, Hyderabad, India,June 2014, ACM, ICSE Companion 2014, pp. 686–689.
[49] M. F. Porter, Readings in information retrieval, chapter An algorithm for suffix strip-ping, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2010, pp. 313–316.
[50] F. Ricci, L. Rokach, B. Shapira, and P. B. Kantor, eds., Recommender Systems Hand-book, Springer, New York, NY, USA, 2011.
90

[51] S. Richardson, Dynamically Recommending Design Patterns, doctoral dissertation,Department of Mathematics and Computer Science, College of Arts and Science,Stetson University, DeLand, FL, USA, 2011.
[52] M. P. Robillard and Y. B. Chhetri, “Recommending reference API documentation,”Empirical Software Engineering, July 2014.
[53] K. Roher and D. Richardson, “A proposed recommender system for eliciting soft-ware sustainability requirements,” Proceedings: 2nd International Workshop on UserEvaluations for Software Engineering Researchers, San Francisco, CA, USA, May2013, IEEE Computer Society, pp. 16–19.
[54] R. Shimada, Y. Hayase, M. Ichii, M. Matsushita, and K. Inoue, “A-SCORE: Au-tomatic software component recommendation using coding context,” Proceedings:31st International Conference on Software Engineering, Vancouver, Canada, May2009, ACM, pp. 439–440.
[55] I. Steinmacher, I. S. Wiese, and M. A. Gerosa, “Recommending Mentors to Soft-ware Project Newcomers,” Proceedings: Third International Workshop on Recom-mendation Systems for Software Engineering, Zurich, Switzerland, June 2012, IEEEComputer Society, pp. 63–67.
[56] D. Surian, N. Liu, D. Lo, H. Tong, E.-P. Lim, and C. Faloutsos, “RecommendingPeople in Developers’ Collaboration Network,” Proceedings: 18th Working Confer-ence on Reverse Engineering, Limerick, Ireland, Oct. 2011, IEEE Computer Society,pp. 379–388.
[57] P.-N. Tan, M. Steinbach, and V. Kumar, Introduction to Data Mining, 1st edition,Addison-Wesley, Boston, MA, USA, 2005.
[58] R. Terra, M. T. Valente, R. S. Bigonha, and K. Czarnecki, “DCLfix: A recommen-dation system for repairing architectural violations,” Proceedings: 3rd BrazilianConference on Software: Theory and Practice, Natal, Brazil, Sept. 2012, pp. 1–6.
[59] K. Toutanova and C. D. Manning, “Enriching the Knowledge Sources Used in aMaximum Entropy Part–of–Speech Tagger,” Proceedings: Joint SIGDAT Confer-ence on Empirical Methods in Natural Language Processing and Very Large Corpora(EMNLP/VLC-2000), Hong Kong, Oct. 2000, ACM, pp. 63–70.
[60] D. Cubranic, G. C. Murphy, J. Singer, and K. S. Booth, “Learning from project his-tory: A case study for software development,” Proceedings: 2004 ACM Conferenceon Computer Supported Cooperative Work, Chicago, IL, USA, Nov. 2004, ACM, pp.82–91.
91

[61] P. Viriyakattiyaporn and G. C. Murphy, “Challenges in the user interface design of anIDE tool recommender,” Proceedings: ICSE Workshop on Cooperative and HumanAspects on Software Engineering, Vancouver, Canada, May 2009, IEEE ComputerSociety, pp. 104–107.
[62] Z. Xiao-lin, C. Chi-Hung, D. Chen, and R. K. Wong, “Non-functional RequirementAnalysis and Recommendation for Software Services,” Proceedings: 20th IEEEInternational Conference on Web Services, Santa Clara, CA, USA, June 2013, IEEEComputer Society, pp. 555–562.
[63] Y. Zhang and M. Pennacchiotti, “Recommending branded products from social me-dia,” Proceedings: 7th ACM conference on Recommender systems, Hong Kong, Oct.2013, ACM, pp. 77–84.
[64] J. Zheng, L. Williams, N. Nagappan, W. Snipes, J. P. Hudepohl, and M. A. Vouk, “Onthe Value of Static Analysis for Fault Detection in Software,” IEEE Transactions onSoftware Engineering, vol. 32, no. 4, Apr. 2006, pp. 240–253.
92

APPENDIX A
DETAILS OF SYSTEMATIC MAPPING STUDY OF RECOMMENDER SYSTEMS
93

A.1 Search Strings Used
We used the following search string
Recommender system for software engineer
Recommender system for software developer
Recommendation system for software engineer
Recommendation system for software developer
The advanced search string is given as under.
(("recommender system") OR ("recommendation system"))
AND
(("software developer") OR ("software engineer"))
A.2 The Databases Used for Literature Search
The following research databases were used for conducting the literature search.
• ACM Digital Library
• Google Scholar
• IEEEXplore
• ScienceDirect
• Scopus
The search initially returend 927 articles, out of which 141 duplicate studies were ex-
cluded; hence, bringing the remaining number of studies to 786. After carefully going
through the title of the article, we excluded 653 more articles; hence, bringing the reamin-
ing number of articles to 133. Then, we excluded 72 more articles after reading the abstract;94

hence, bringing the total down to 61. Finally, after reading conclusions and results, 7 more
articles were excluded; hence, bringing the total to 54 articles.
95

APPENDIX B
HUMAN SUBJECT EXPERIMENT DETAILS
96

B.1 Human Subject Evaluation
The template of form used for evaluating the different training articles is shown in
Figure B.1.
The template of form used for ranking the different training articles is shown in Fig-
ure B.2.
97

Figure B.1
Form used for evaluation of training articles
98

Figure B.2
Form used for ranking of training articles
99


















