
msakr/15619-s19/recitations/S19_Recitation11.pdf · Databricks is an Apache Spark-based unified...
61
Transcript of msakr/15619-s19/recitations/S19_Recitation11.pdf · Databricks is an Apache Spark-based unified...


––
2

–
3

–
•–
4

•
•––
5

••
Prepare data for the next iteration
6
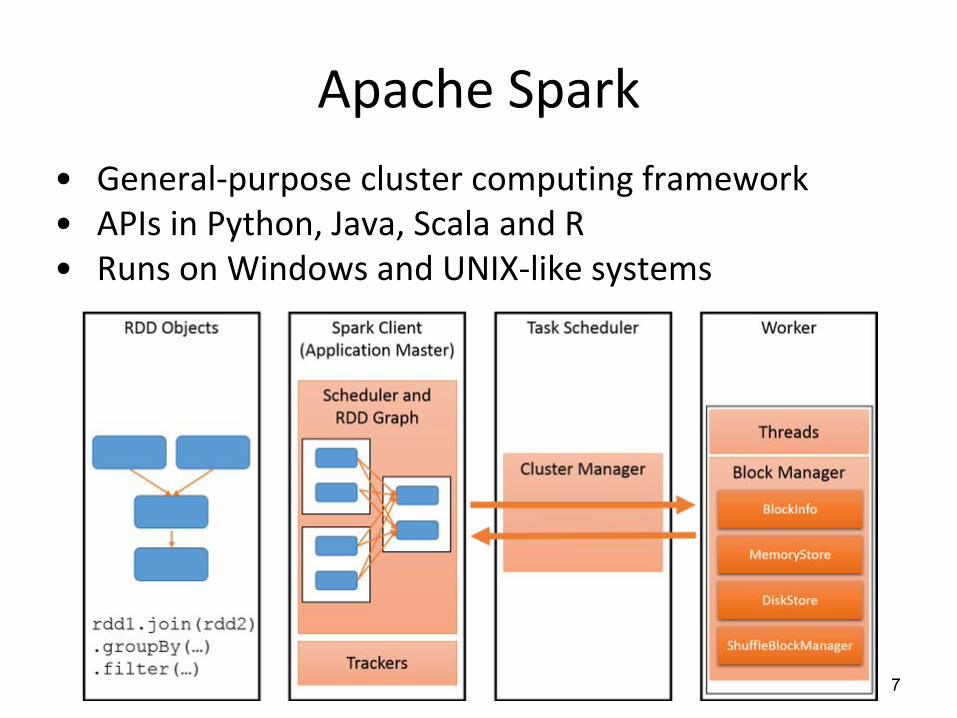
7

●○○
●○○○
●○○
●○○
8

●
Resilient Distributed
Datasets (RDD)DataFrame DataSet
● Distributed collection of JVM objects
● Functional operators (map, filter, etc.)
● Distributed collection of Row objects
● Expression-based operations
● Fast, efficient internal representations
● Internally rows, externally JVM objects
● Type safe and fast
● Slower than dataframes
9
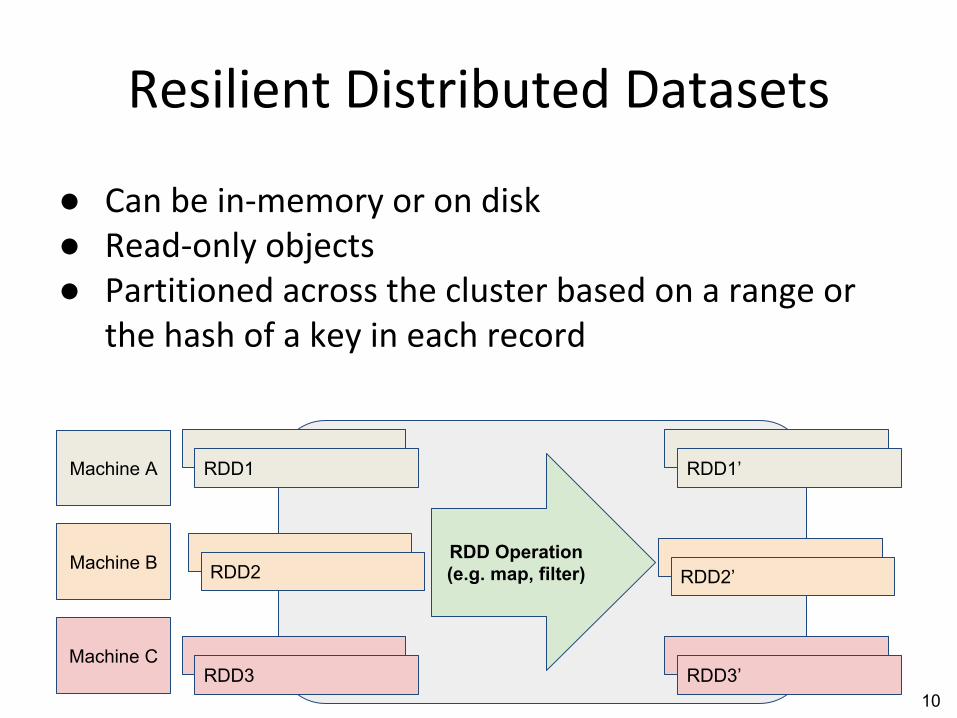
●●●
RDD1 RDD1’
RDD2 RDD2’
RDD3 RDD3’
Machine B
Machine A
Machine C
RDD Operation(e.g. map, filter)
10

>>> input_RDD = sc.textFile("text.file")
>>> transform_RDD = input_RDD.filter(lambda x: "abcd" in x)
>>> print "Number of “abcd”:" + transform_RDD.count()
>>> output.saveAsTextFile(“hdfs:///output”) 11

●●
○○○
12

●○○
●○○
13

people.json{"name":"Michael"} {"name":"Andy", "age":30} {"name":"Justin", "age":19}
val df = spark.read.json("people.json")
val sqlDF = df.filter($"age" > 20).show()+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
df.filter($"age" > 20).select(“name”).write.format(“parquet”).save(“output”)
Note: Parquet is a column-based storage format for Hadoop. You will need special dependencies to read this file
14

Task Points Description Language
15
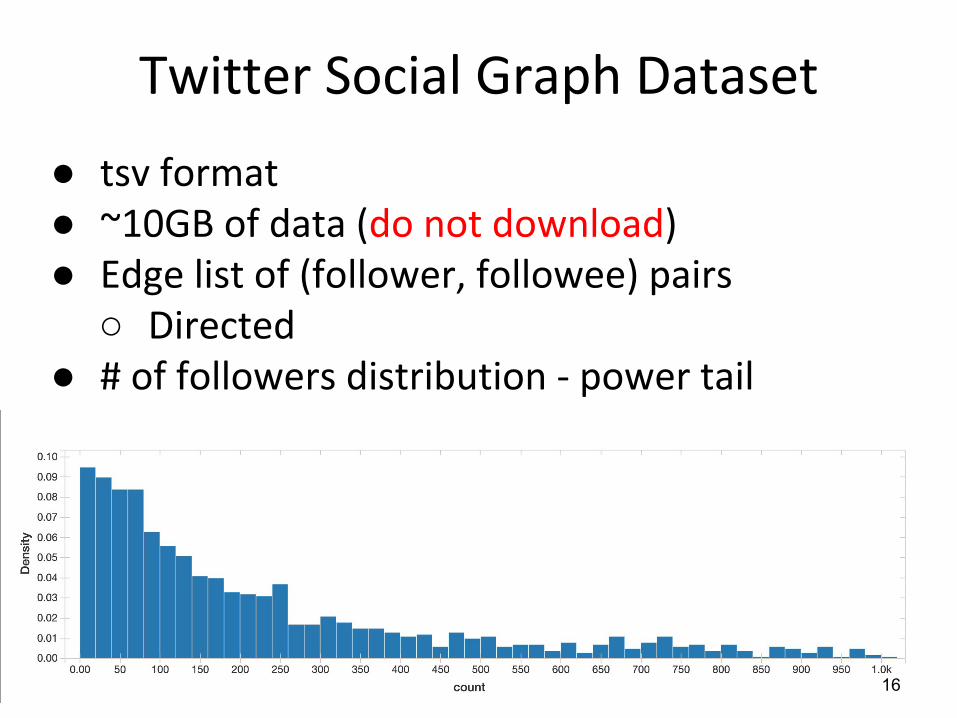
●●●
○●
16

●
■■
■■
17

●
●
●○ ⇒○ ⇒
●
18

● How do we measure influence?○ Intuitively, it should be the node with the most followers
19

● Influence scores are initialized to 1.0/number of vertices
0.333 0.333
0.33320

● Influence scores are initialized to 1.0/number of vertices● In each iteration of the algorithm, scores of each user are
redistributed between the users they are following
0.333 0.333
0.33321

● Influence scores are initialized to 1.0/number of vertices● In each iteration of the algorithm, scores of each user are
redistributed between the users they are following
0.333/2 = 0.167
0.333 + 0.333/2 = 0.500
0.333From Node 2
From Node 1
From Node 1From Node 0
22

● Influence scores are initialized to 1.0/number of vertices● In each iteration of the algorithm, scores of each user are
redistributed between the users they are following● Convergence is achieved when the scores of nodes do not
change between iterations ● Pagerank is guaranteed to converge
0.333/2 = 0.167
0.333 + 0.333/2 = 0.500
0.333
From Node 2
From Node 1
From Node 1From Node 0
23
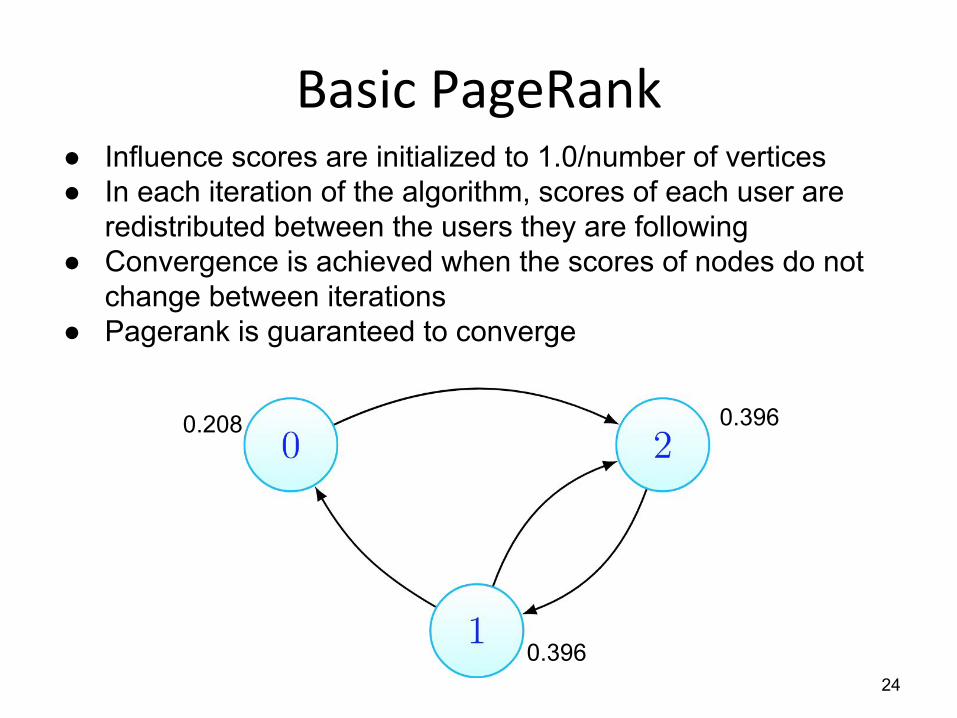
● Influence scores are initialized to 1.0/number of vertices● In each iteration of the algorithm, scores of each user are
redistributed between the users they are following● Convergence is achieved when the scores of nodes do not
change between iterations● Pagerank is guaranteed to converge
0.208 0.396
0.39624

val links = spark.textFile(...).map(...).persist()var ranks = // RDD of (URL, rank) pairsfor (i <- 1 to ITERATIONS) {
// Build an RDD of (targetURL, float) pairs// with the contributions sent by each pageval contribs = links.join(ranks).flatMap {
(url, (links, rank)) =>links.map(dest => (dest, rank/links.size))
}
// Sum contributions by URL and get new ranksranks = contribs.reduceByKey((x,y) => x+y)
.mapValues(sum => a/N + (1-a)*sum)}
Reference: https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/SparkPageRank.scala 25
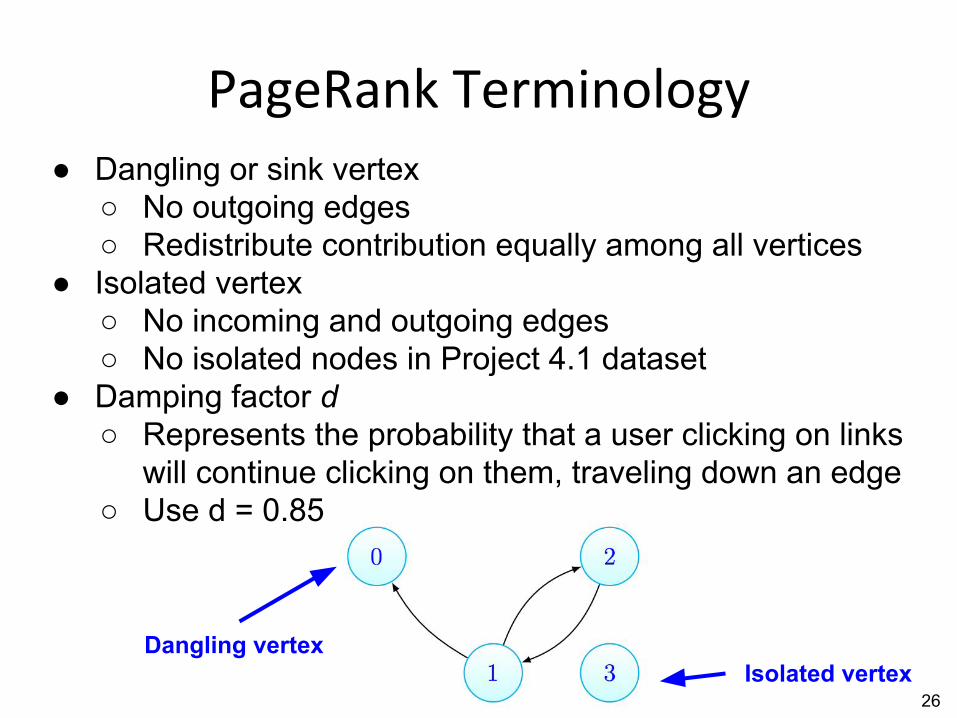
● Dangling or sink vertex○ No outgoing edges○ Redistribute contribution equally among all vertices
● Isolated vertex○ No incoming and outgoing edges○ No isolated nodes in Project 4.1 dataset
● Damping factor d○ Represents the probability that a user clicking on links
will continue clicking on them, traveling down an edge○ Use d = 0.85
Dangling vertexIsolated vertex
26
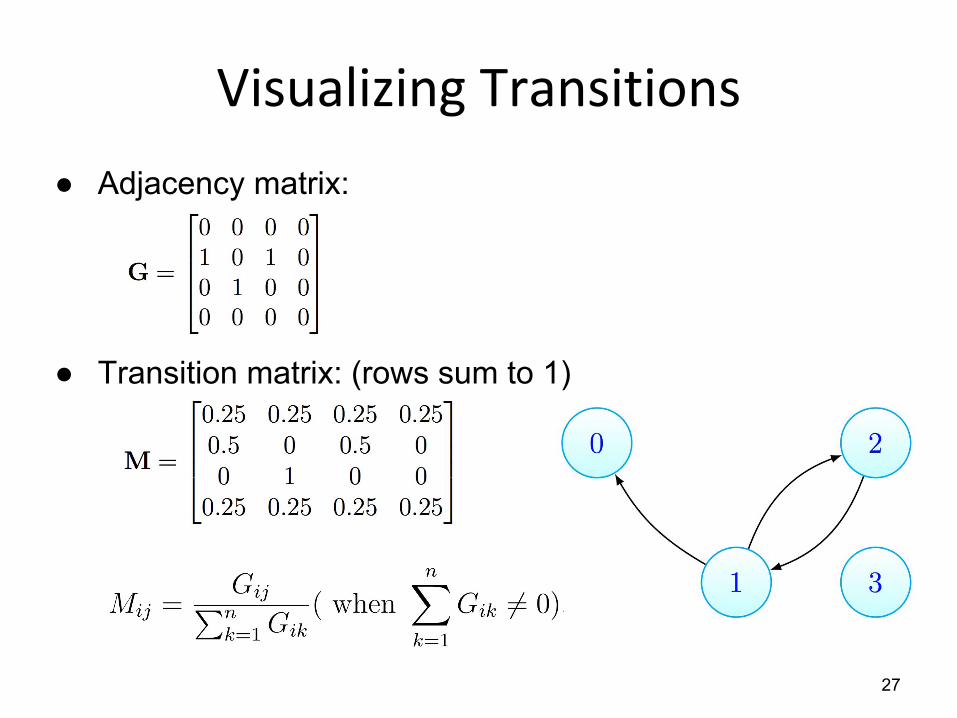
● Adjacency matrix:
● Transition matrix: (rows sum to 1)
27

Formula for calculating rank
d = 0.85
28

Formula for calculating rank
d = 0.85
Note: contributions from isolated and dangling vertices are constant in an iteration
Let
29

Formula for calculating rank
d = 0.85
Note: contributions from isolated and dangling vertices are constant in an iteration
Let
This simplifies the formula to
30

Formula for calculating rank
d = 0.85
31

Formula for calculating rank
d = 0.85
32

●
●○○
●○○
33

●○○
●
●○○○○○○
●○○
●○
● 34

● Ensuring correctness○ Make sure total scores sum to 1.0 in every iteration○ Understand closures in Spark
■ Do not do something like thisval data = Array(1,2,3,4,5)
var counter = 0
var rdd = sc.parallelize(data)
rdd.foreach(x => counter += x)
println("Counter value: " + counter)
○ Graph representation■ Adjacency lists use less memory than matrices
○ More detailed walkthroughs and sample calculations can be found here
35

Status of RDD actions being computed
Info about cached RDDs and memory usage
In-depth job info
36

● Understand RDD manipulations○ Actions vs Transformations○ Lazy transformations
● Use the Yarn UI○ Are you utilizing your cluster completely? How can you change
that? Refer optimization hints in the writeup.● Use the Spark UI
○ Are your RDDs cached as expected? (Thrashing)○ Memory errors - check container logs○ Parameter tuning applied successfully?○ Exponential increase in partitions? - Read about HashPartitioner
in Spark● How do you represent the node IDs? Int/String/Long?● Many more optimization hints in the writeup!
37

● Databricks is an Apache Spark-based unified analytics platform.
● Azure Databricks is optimized for Azure○ Software-as-a-Service
● One-click setup, an interactive workspace, and an optimized Databricks runtime
● Optimized connectors to Azure storage platforms for fast data access
● Run the same PageRank application (in Task 2) on Azure Databricks to compare the differences with Azure HDInsight
38

● You can only get bonus (10 points) when:○ 100% correctness○ Runtime under 30 minutes on Databricks
● Copy your code to a Databricks notebook:○ Do not create or destroy SparkSession objects○ Change the output to DBFS instead of WASB
● Create a cluster and job using databricks-setup.sh● Submitter takes in a job ID● Don’t forget to destroy resources after you are done!
39

object PageRank { def calculatePageRank(inputGraphPath: String, outputPath: String, iterations: Int, isLocal: Boolean): Unit = { val spark = SparkUtils.getSparkSession(isLocal, appName = "PageRank") val sc = spark.sparkContext
… Your implementation goes here … graphRDD = sc.textFile(inputGraphPath) graphRDD.map(...)
spark.close() }
def main(args: Array[String]): Unit = { val inputGraph = "wasb://[email protected]/Graph" val outputPath = "wasb:///pagerank-output" val iterations = 10
calculatePageRank(inputGraph, outputPath, iterations, isLocal=false) }}
40

object PageRank { def calculatePageRank(inputGraphPath: String, outputPath: String, iterations: Int, isLocal: Boolean): Unit = { val spark = SparkUtils.getSparkSession(isLocal, appName = "PageRank") val sc = spark.sparkContext
val inputGraph = "wasb://[email protected]/Graph" val outputPath = "wasb:///pagerank-output" val iterations = 10 … Your implementation goes here … graphRDD = sc.textFile(inputGraphPath) graphRDD.map(...)
spark.close() }
def main(args: Array[String]): Unit = {
calculatePageRank(inputGraph, outputPath, iterations, isLocal=false) }}
41

42
TEAM PROJECTTwitter Data Analytics

Team Project
Web-tier Storage-tier
43
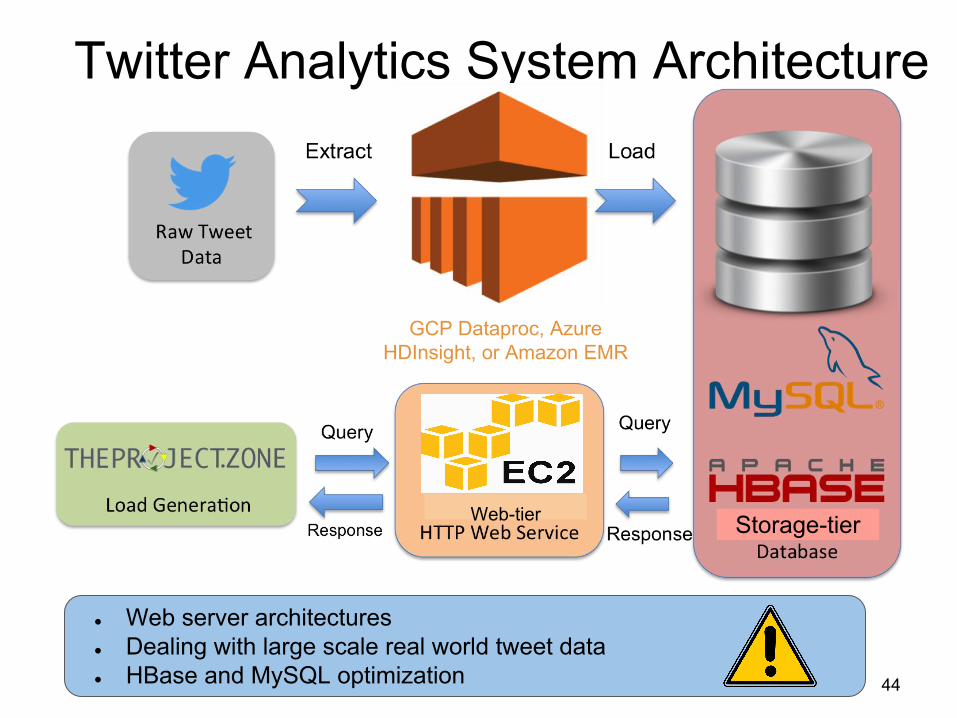
Twitter Analytics System Architecture
● Web server architectures● Dealing with large scale real world tweet data● HBase and MySQL optimization 44
GCP Dataproc, Azure HDInsight, or Amazon EMR
Web-tier Storage-tier

Phase 1 scoreboard (F18)
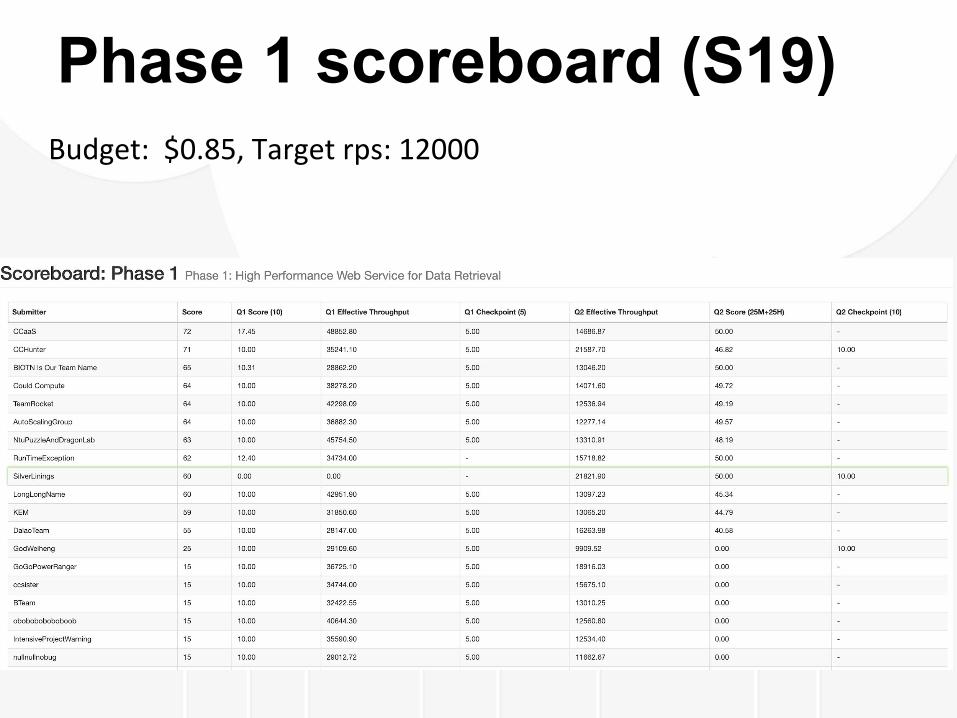
Phase 1 scoreboard (S19)

Team Project● Phase 1:
○ Q1○ Q2 (MySQL AND HBase)
● Phase 2○ Q1○ Q2 & Q3 (MySQL AND HBase)
● Phase 3○ Q1○ Q2 & Q3 (MySQL OR HBase)
47

Team Project Deadlines● Writeup and queries were released on
Monday, April 1
● Phase 2 milestones:
○ Q3 Bonus (Reach Q3 target, MySQL+HBase)
Due on Sunday, April 7, 3%
○ Phase 2, Live test:
Q1/Q2/Q3/mixed on Sunday, April 14
○ Phase 2, code and report:
due on Tuesday, April 16 48

Query 3, Definitions
● time_start, time_end: in Unix time / Epoch time format, e.g. time_start=1480000000
● uid_start, uid_end: marks the user search boundary, e.g. uid_end=492600000
● n1: maximum number of topic words to be included in the response
● n2: maximum number of tweets to be included in the response
49

Query 3: Effective Word Count (EWC)EWC:● One or more consecutive alphanumeric characters
(A through Z, a through z, 0 through 9) with zero or more ' or/and - characters. However, a word should not contain only numbers and/or ' and/or - characters.
EWC=6Query 3 is su-per-b! I'mmmm lovin' it!
***** ** ******** ****** ****** **
Don’t forget to remove the short URL and stop words before calculation 50

Query 3, Impact ScoreImpact Score = EWC x ( favorite_count + retweet_count + followers_count)
Consider negative impact_score as 0.
51

Query 3, Topic WordsTopic words:● After filtering short urls● Exclude stop words● Before censor● Case insensitive (lower case)
TF-IDF:● TF: term frequency of a topic word w● IDF: ln(Total number of tweets in range/
Number of tweets with w in it)52

Query 3, Topic ScoreTopic Score = sum(x * ln(y + 1)) (i from 1 to n)
n: The total number of tweets in the given time and uid range
x: TF-IDF score of word w in tweet Ti
y: The impact score of Ti
53

Query 3 Example
word1:score1\tword2:score2...\twordn1:scoren1Impactscore1\ttid1\ttext1…..
Example:channel:2270.04 amp:1586.31 new:1166.24 just:1153.70 love:1063.31 like:1015.71 good:937.63
26200650 461159182406672384 I just buyed the comedy album of my bestest friend in the entire world @briangaar. https://t.co/hwDB4veaYG #RacesAsToad...
Don’t forget to censor the tweets
54

55
Phase (and query due) Start Deadlines Code and Report Due
●
●
●
●
●

Hints● For HBase, you’re not restricted to just 1 master node. The
two sample setups below are both permitted.
○ 1 x (1 master + 5 slaves)
○ 2 x (1 master + 2 slaves)
● Understand and keep an eye on
○ EC2 CPU Credits and burstable performance
○ EBS volume I/O Credits and Burst Performance
56

Q3 Hints● Completely understand every Assess Me question
● Completely understand the definition of a word. This is
different for text censoring and calculating scores.
● A query contain two ranges. Log some requests to get an
idea on the range of user_id and timestamps.
● Optimization is time-consuming. Before ETL, please
○ Think about your schema design
○ Think about your database configuration
57

Warning
● You should NEVER open all ports to the public
(0.0.0.0) when using instances on a public cloud.
● Especially not 8088/8090!
● For your purposes, you likely only need to open
port 80 to the public. Port 22 should be open only
to your public IPs.
● Port 3306 (for MySQL) and HBase ports should be
open only to cluster members if necessary 58

● Your team has an AWS budget of $50 for Phase 2● Your web service should not cost more than $0.89 per
hour, this includes (see write-ups for details):○ Use EC2 on-demand instance cost
■ even if you use spot instances, we will calculate your cost using the on-demand instance price
○ EBS cost○ ELB cost○ We will not consider data transfer and EMR cost
● Targets:○ Query 2 - target is for both MySQL and Hbase○ Query 3 - target is for both MySQL and Hbase
Phase 2 Budgets
59

●○
●○
●○
●○○
60

Questions?
61


















