
Monitoring sucks
34
Why monitoring sux en wat we er aan kunnen doen (in controll) Jurgen van de Pol, maart 2013
-
Upload
jurgen-van-de-pol -
Category
Technology
-
view
79 -
download
1
Transcript of Monitoring sucks

Why
monitoring
suxen wat we er aan kunnen doen (in controll)
Jurgen van de Pol, maart 2013

Waarom zuigt monitoring?
● Monitoring tools verwachten dat iedereen een
monitoring expert is.
● Correlatie van metrics tussen alle infrastructuur
componenten is complex.
● Monitoring vreet tijd.
● Het herhaaldelijk verzamelen van metrics is saai en
ondankbaar werk.
● Er zijn veel te veel verschillende monitoring tools en
interfaces.
● Producten kunnen niet autonoom analyseren,
correleren en patronen herkennen.
● Focus ligt op infrastructuur ruis i.p.v. op business pijn.
● Proces identificatie, isolatie en oplossing is niet
geautomatiseerd.

zonder monitoring is het:
● lastig snel de belasting en gezondheid van
infrastructuur te zien.
● zeer bewerkelijk vragen over de
belangrijkste infrastructuur metrics en
performance te beantwoorden. Ambachtelijk
● moeilijk een uitzondering te isoleren als er
iets misgaat.
● niet mogelijk een compleet beeld van invloed
dagelijkse wijzigingen op de eindgebruiker te
hebben (dashboard)

Wat wil je weten ?
Monitoring verzamelt, analyseert en
presenteert relevante metrics.
Relevant voor de business.
Zodat verstoringen van die business
kunnen worden voorkomen en opgelost.
Je kunt gigabytes diagnostische gegevens verzamelen.
Zonder de juiste context, het juiste probleem,
en de juiste gebruiker:
zinloos als een theepot van chocolade.
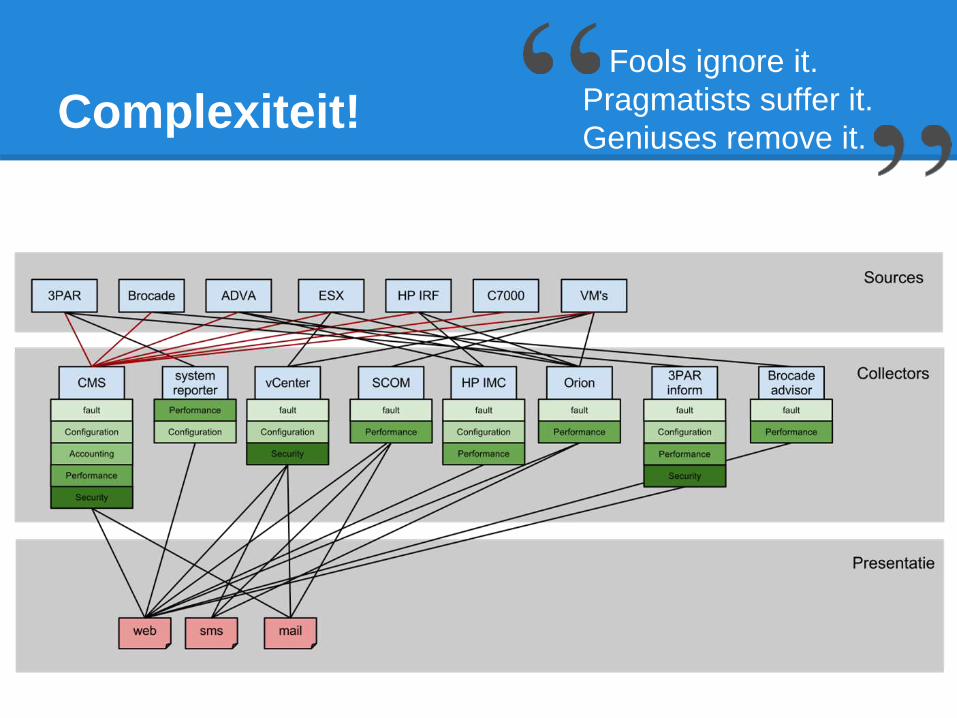
Complexiteit!Fools ignore it.
Pragmatists suffer it.
Geniuses remove it.

Wat verwachten we van monitoring?
● Notificatie/Alerting
● Complex Event Processing (time based
correlatie)
● Patroon herkenning (behavioral learning)
● Real time & historische performance &
trending
● gauges, counters, meters, histograms, timers
● Capacity prognose
● Logging & Auditing
● Painless to implement and frictionless to
maintain
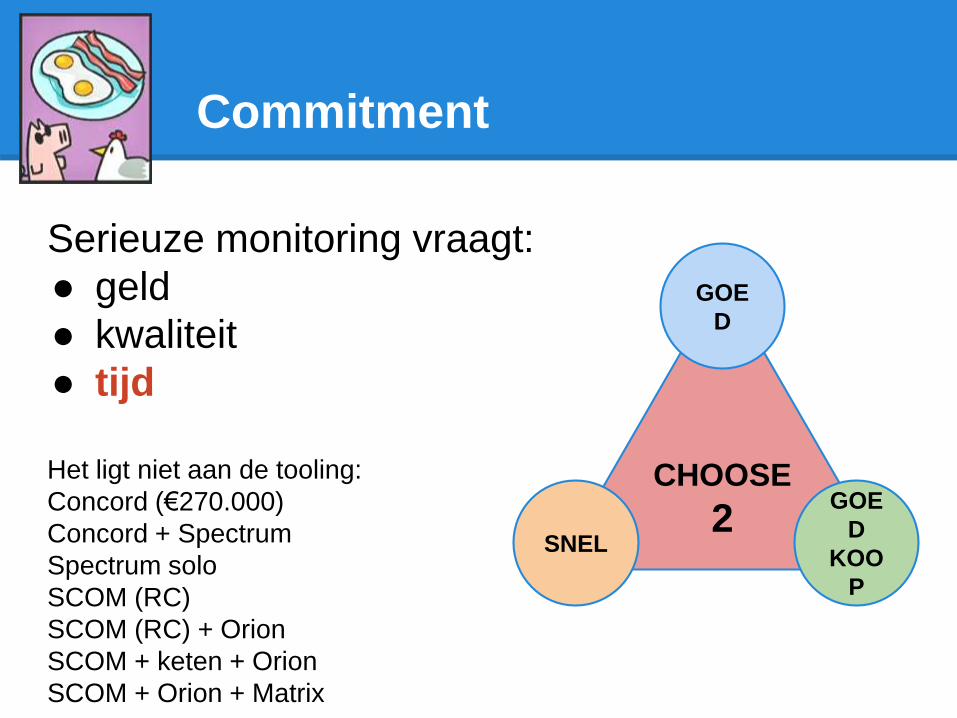
Commitment
Serieuze monitoring vraagt:
● geld
● kwaliteit
● tijd
Het ligt niet aan de tooling:
Concord (€270.000)
Concord + Spectrum
Spectrum solo
SCOM (RC)
SCOM (RC) + Orion
SCOM + keten + Orion
SCOM + Orion + Matrix
CHOOSE
2
GOE
D
SNEL
GOE
D
KOO
P

Wat doen we met al die wensen?
methode van foutanalyse:
OODA : observe, orient, decide, act
1. probleem identificatie
wat is er aan de hand, is het een
probleem?
1. probleem isolatie
waar zit het probleem
1. probleem oplossing
hoe los ik het op
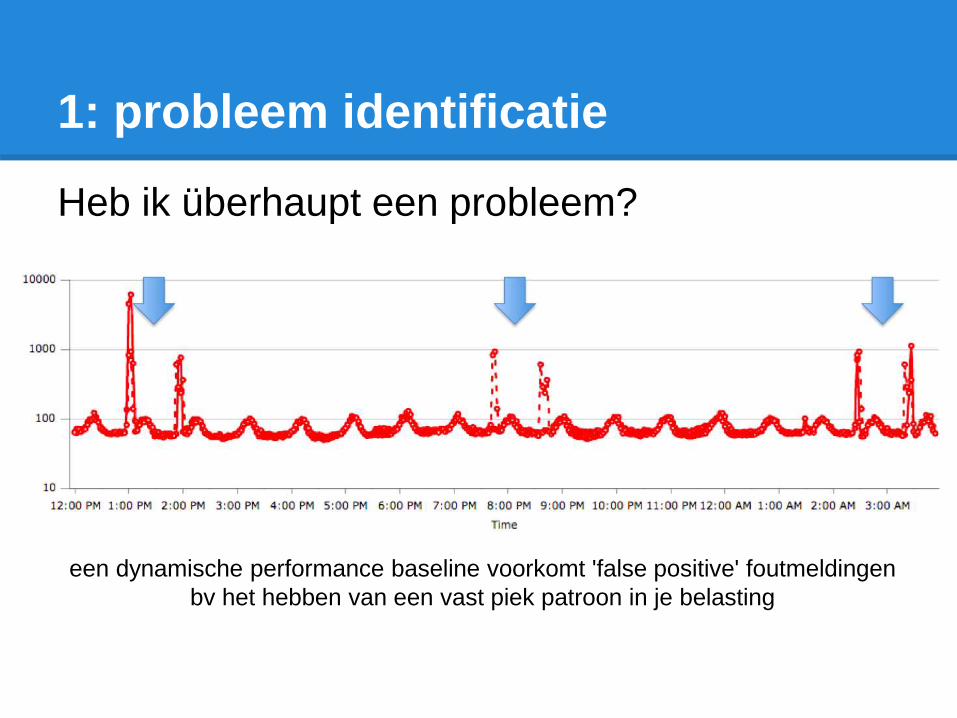
1: probleem identificatie
Heb ik überhaupt een probleem?
een dynamische performance baseline voorkomt 'false positive' foutmeldingen
bv het hebben van een vast piek patroon in je belasting

1: probleem identificatie
Heb ik überhaupt een probleem?
Wat is de business context van het probleem.
90% CPU op 1 ESX host
versus
klanten service wacht > 20 sec op responce
DEVOPS!

2: probleem isolatie
Waar zit mijn probleem?
prob: silo's, no drill down, no devops, no
visualisation, no insight
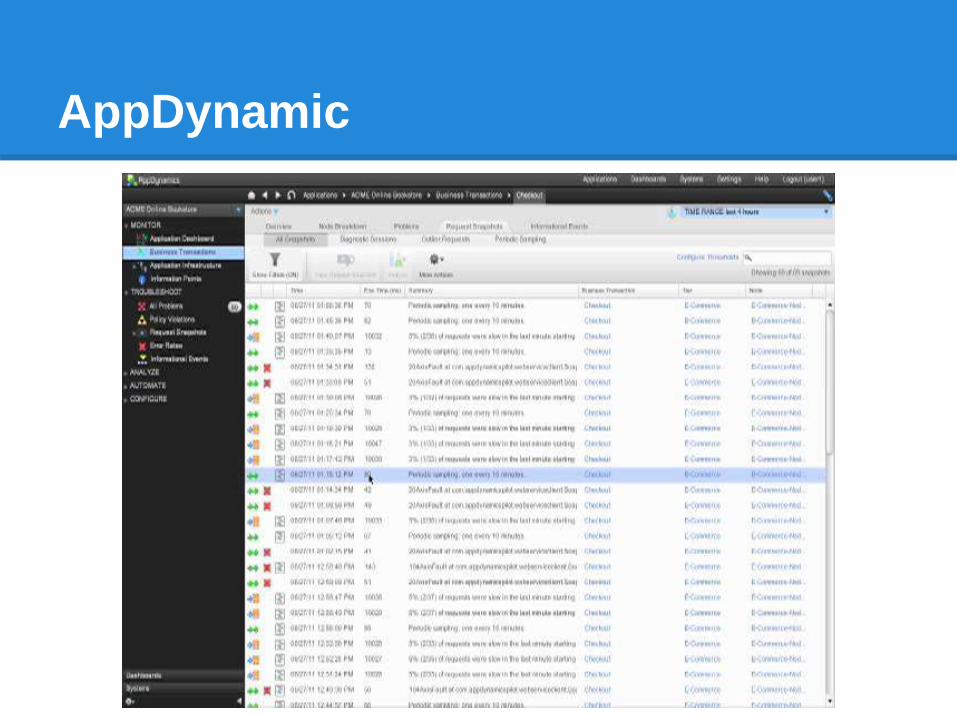
plaatje: appdynamics

2: probleem isolatie
Waar zit mijn probleem?
Huidige tools verzamelen wel data,
maar visualiseren en isoleren het probleem niet
autonoom.
Correlatie/patroon herkenning van hypervisor,
compute, OS, storage, netwerk, database,
applicatie met de hand is zeer arbeidsintensief.

2: probleem isolatie
Waar zit mijn probleem?
Een KRIS transactie duurt > 20 sec.
Waar precies zijn die 20 sec besteed?
Bekijk je de performance data vanuit de silo's
ESX, OS, applicatie, database en network
perspectief dan krijgt je 5 verschillende views
zonder correlatie, te grof om die ene slechte
transactie te tonen.
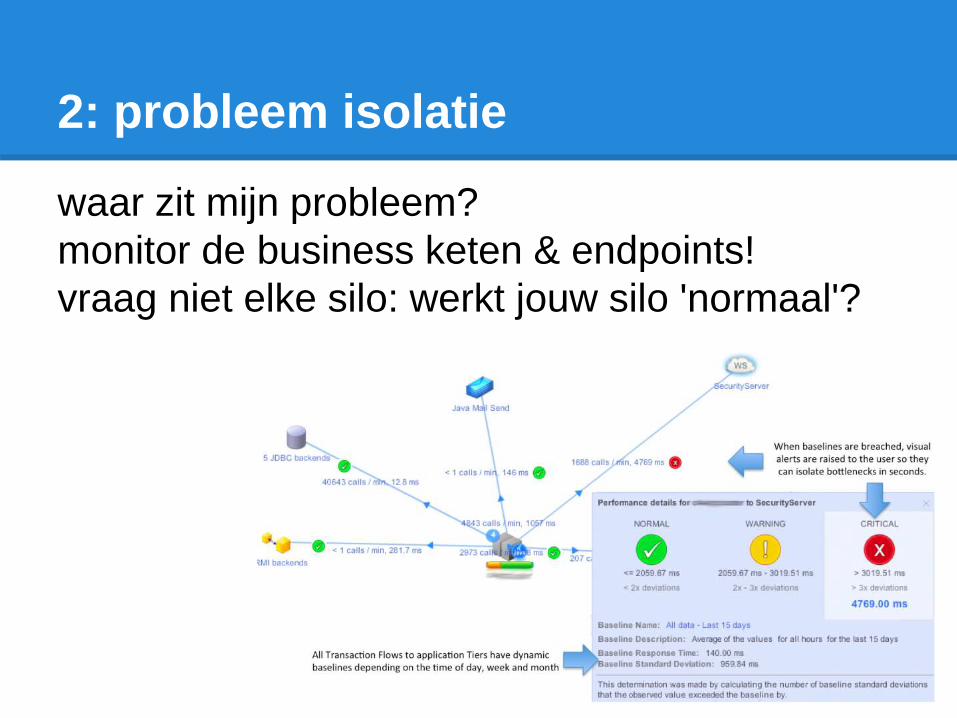
2: probleem isolatie
waar zit mijn probleem?
monitor de business keten & endpoints!
vraag niet elke silo: werkt jouw silo 'normaal'?
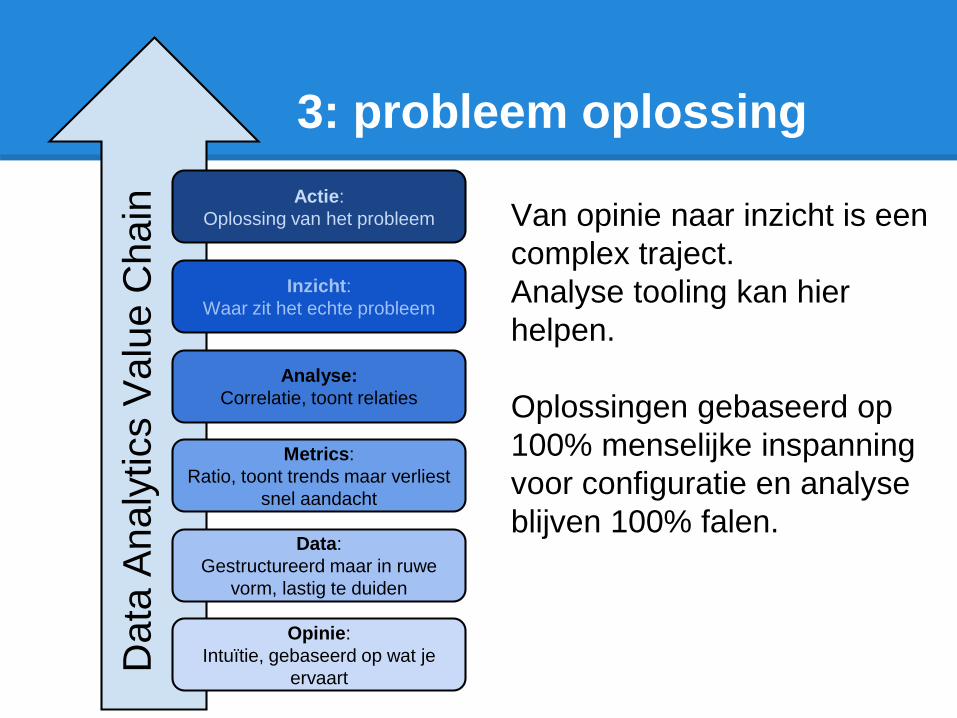
3: probleem oplossing
Van opinie naar inzicht is een
complex traject.
Analyse tooling kan hier
helpen.
Oplossingen gebaseerd op
100% menselijke inspanning
voor configuratie en analyse
blijven 100% falen.
Opinie:
Intuïtie, gebaseerd op wat je
ervaart
Data:
Gestructureerd maar in ruwe
vorm, lastig te duiden
Metrics:
Ratio, toont trends maar verliest
snel aandacht
Analyse:
Correlatie, toont relaties
Inzicht:
Waar zit het echte probleem
Actie:
Oplossing van het probleem
Data
Ana
lytics V
alu
e C
hain

Het alternatief
Hoe de klant een dienst beoordeeld wordt
ultiem bepaald door de ervaring met die dienst.
Als kun je de kwaliteit van de ervaring niet kunt meten, kun je
de kwaliteit van de dienst niet waarborgen.
End User Experience

End User Experience, 5 dingen
1. Volgt in real time, de uitvoering van de software
algoritmen die tezamen de toepassing vormen.
2. Meet en rapporteert de beperkte hardware en software
resources, toegewezen aan de applicatie.
3. Bepaalt of de toepassing goed wordt uitgevoerd in
overeenstemming met eisen van de applicatie eigenaar.
4. Registreert vertragingen in elk van de uit te voeren
stappen in een keten.
5. Bepaalt waarom de toepassing niet goed functioneert,
of waarom resource verbruik en latency levels afwijken
van de verwachting.
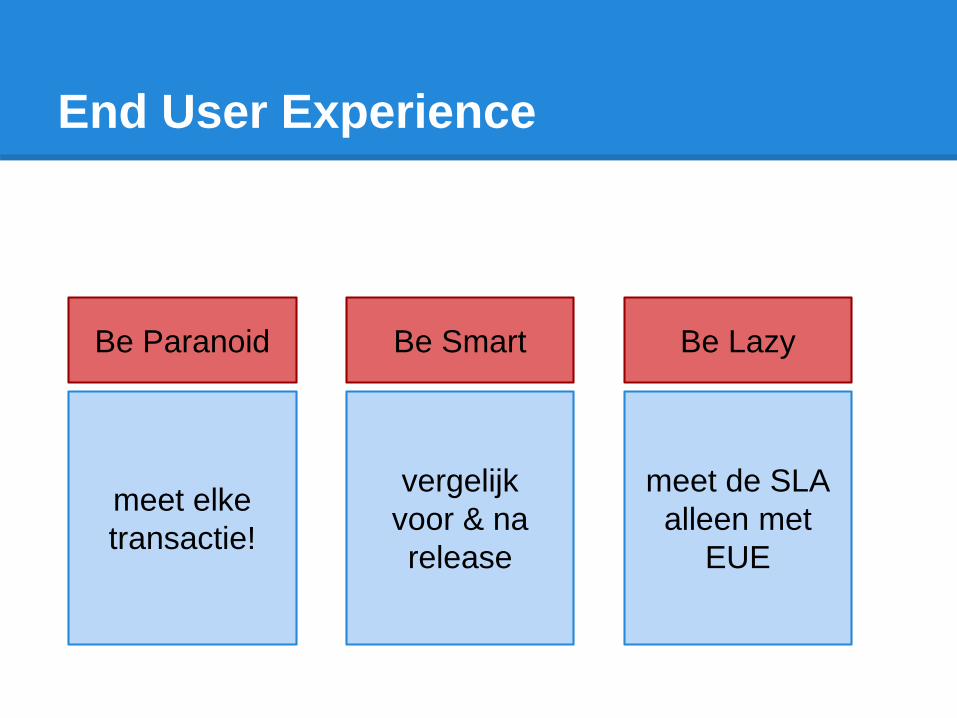
End User Experience
Be Paranoid Be Smart Be Lazy
meet elke
transactie!
vergelijk
voor & na
release
meet de SLA
alleen met
EUE

EUE paranoid
Pak het grondig aan:
● Bepaal de belangrijkste gebruikerservaring
metrics.
● Meet elke transactie van elke gebruiker.
● Meet de keten.

EUE smart
Maak End User Experience intelligent:
● Stel performance modellen op.
● Vergelijk goede en slechte transacties van
hetzelfde type.
● Vergelijk EUE voor en na changes.

EUE lazy
Kies de weg van de minste weerstand:
● Service Level Agreements (SLA's) puur op
eindgebruikerservaring.
● Automatiseer alerts wanneer responsetijden
drempels dreigen te overschrijden.
● Automatiseer acties om prestaties te
verbeteren (zou mooi zijn he?).
Magic Quadrant for Application
Performance Monitoring
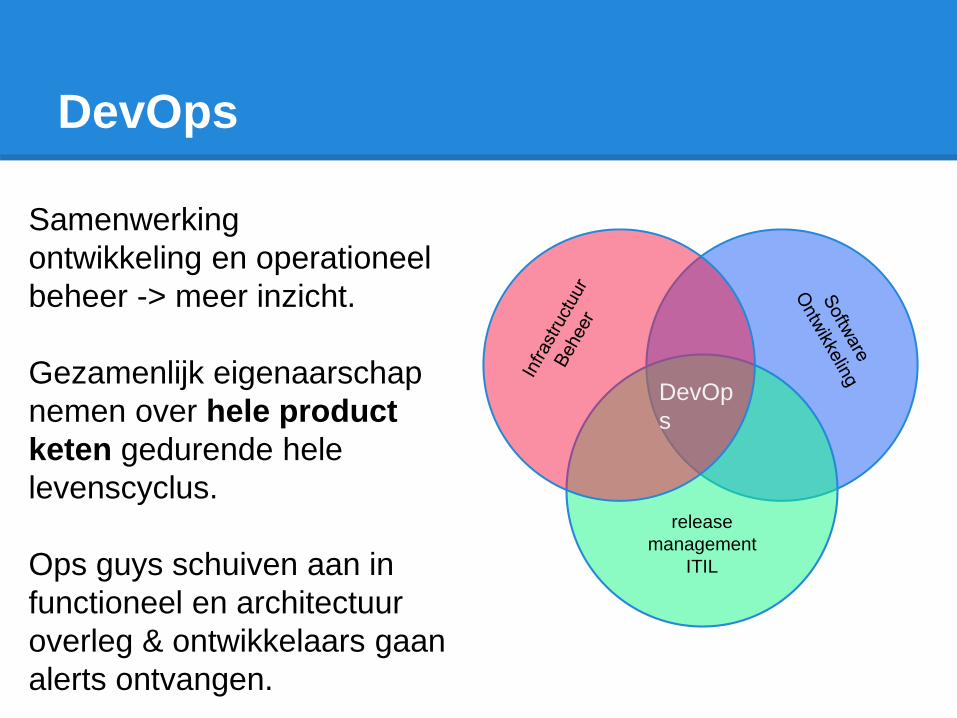
DevOps
Samenwerking
ontwikkeling en operationeel
beheer -> meer inzicht.
Gezamenlijk eigenaarschap
nemen over hele product
keten gedurende hele
levenscyclus.
Ops guys schuiven aan in
functioneel en architectuur
overleg & ontwikkelaars gaan
alerts ontvangen.
release
management
ITIL
DevOp
s

wat is DevOps?
DevOps is een software development methode die communicatie,
samenwerking en integratie tussen software-ontwikkelaars en operationeel
beheer benadrukt. DevOps is het antwoord op de groeiende behoefte aan meer
samenhang tussen software ontwikkeling en IT operations. Met als doel de
organisatie te helpen sneller en beter software producten en diensten te
leveren.
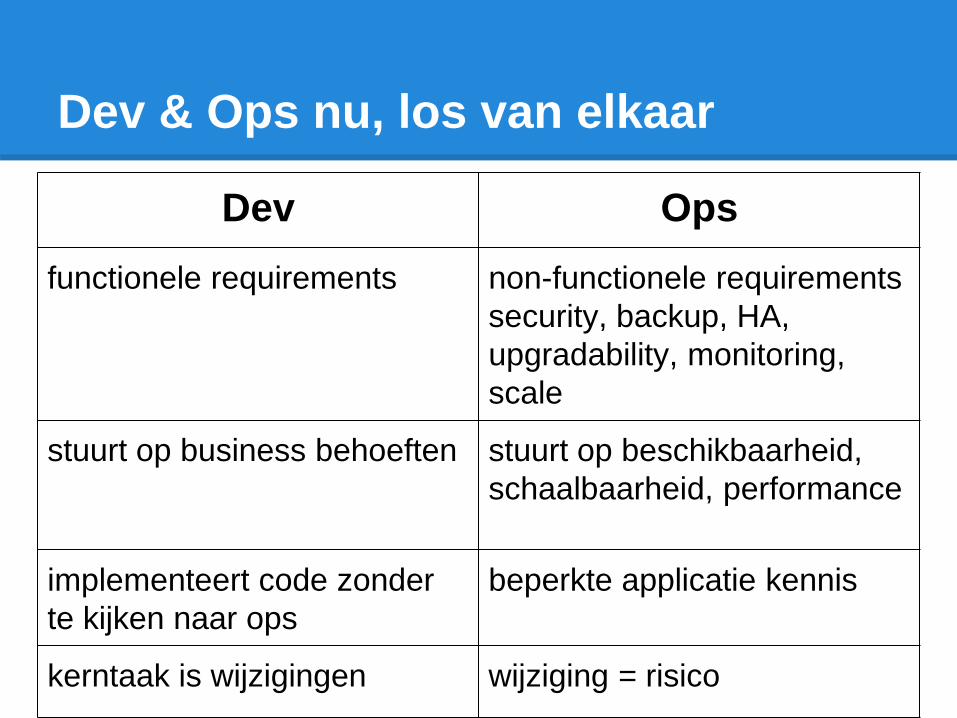
Dev & Ops nu, los van elkaar
Dev Ops
functionele requirements non-functionele requirements
security, backup, HA,
upgradability, monitoring,
scale
stuurt op business behoeften stuurt op beschikbaarheid,
schaalbaarheid, performance
implementeert code zonder
te kijken naar ops
beperkte applicatie kennis
kerntaak is wijzigingen wijziging = risico

Out with the old, In with the new
Out: focus op infra & resource monitoring
In: focus op eindgebruikers & applicaties

Out with the old, In with the new
Out: focus op beschikbaarheid
In: focus op performance en service levels
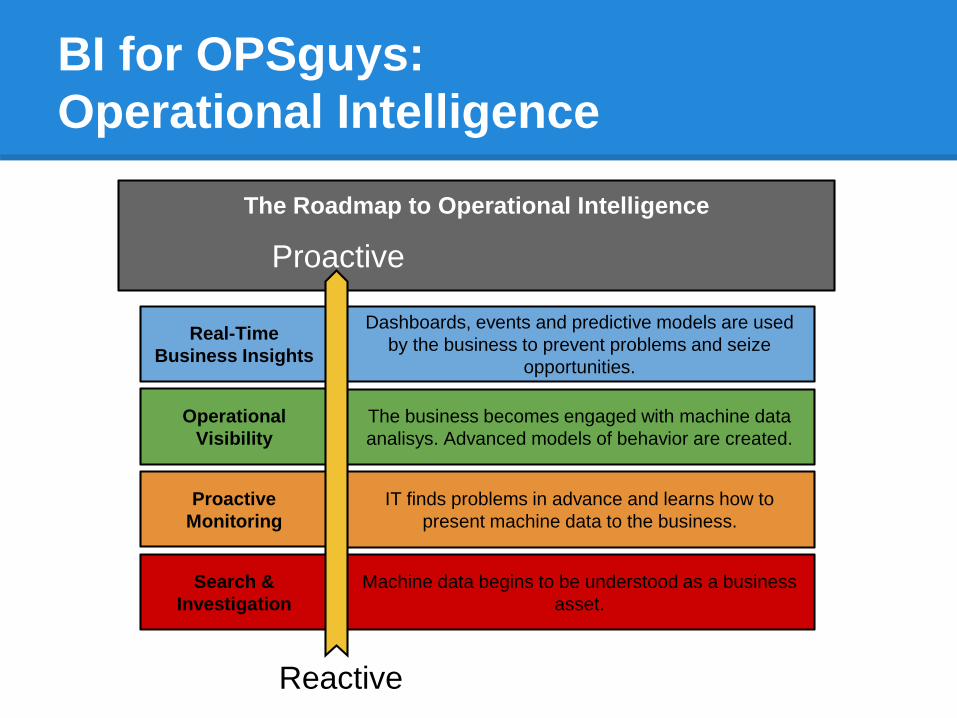
BI for OPSguys:
Operational Intelligence
Real-Time
Business Insights
Operational
Visibility
Proactive
Monitoring
Search &
Investigation
Dashboards, events and predictive models are used
by the business to prevent problems and seize
opportunities.
The business becomes engaged with machine data
analisys. Advanced models of behavior are created.
IT finds problems in advance and learns how to
present machine data to the business.
Machine data begins to be understood as a business
asset.
The Roadmap to Operational Intelligence
Reactive
Proactive
SPLUNK >
heeft een oplossing voor OI
FIN


















