
Module 2: Nonlinear Regression. CHEE824 Winter 2004J. McLellan2 Outline - Single response Notation...
100
Module 2: Nonlinear Regression
-
Upload
avis-wilson -
Category
Documents
-
view
216 -
download
0
Transcript of Module 2: Nonlinear Regression. CHEE824 Winter 2004J. McLellan2 Outline - Single response Notation...

Module 2:
Nonlinear Regression

CHEE824 Winter 2004
J. McLellan 2
Outline -
Single response• Notation
• Assumptions
• Least Squares Estimation – Gauss-Newton Iteration, convergence criteria, numerical optimization
• Diagnostics
• Properties of Estimators and Inference
• Other estimation formulations – maximum likelihood and Bayesian estimators
• Dealing with differential equation models
• And then on to multi-response…

CHEE824 Winter 2004
J. McLellan 3
Notation
Model:
Model specification – – the model equation is– with n experimental runs, we have– defines the expectation surface– the nonlinear regression model is
– Model specification involves form of equationand parameterization
iii fY ),(x
explanatory variables – ith run conditions
p-dimensional vector of parameters
random noise component
),( if x
),(
),(
),(
)(2
1
nf
f
f
x
x
x
)(
)(Y

CHEE824 Winter 2004
J. McLellan 4
Example #1 (Bates and Watts, 1988)
Rumford data – – Cooling experiment – grind cannon barrel with blunt bore, and then
monitor temperature while it cools
» Newton’s law of cooling – differential equation with exponential solution
» Independent variable is t (time)
» Ambient T was 60 F
» Model equation
» 1st-order dynamic decay
tetf 7060),(

CHEE824 Winter 2004
J. McLellan 5
Rumford Example
• Consider two observations – 2-dimensional observation space» At t=4, t=41 min

CHEE824 Winter 2004
J. McLellan 6
Parameter Estimation – Linear Regression Case
approximating observation vector
ˆ Xy
yobservations
residualvector
Expectation surface X
CHEE824 Winter 2004
J. McLellan 7
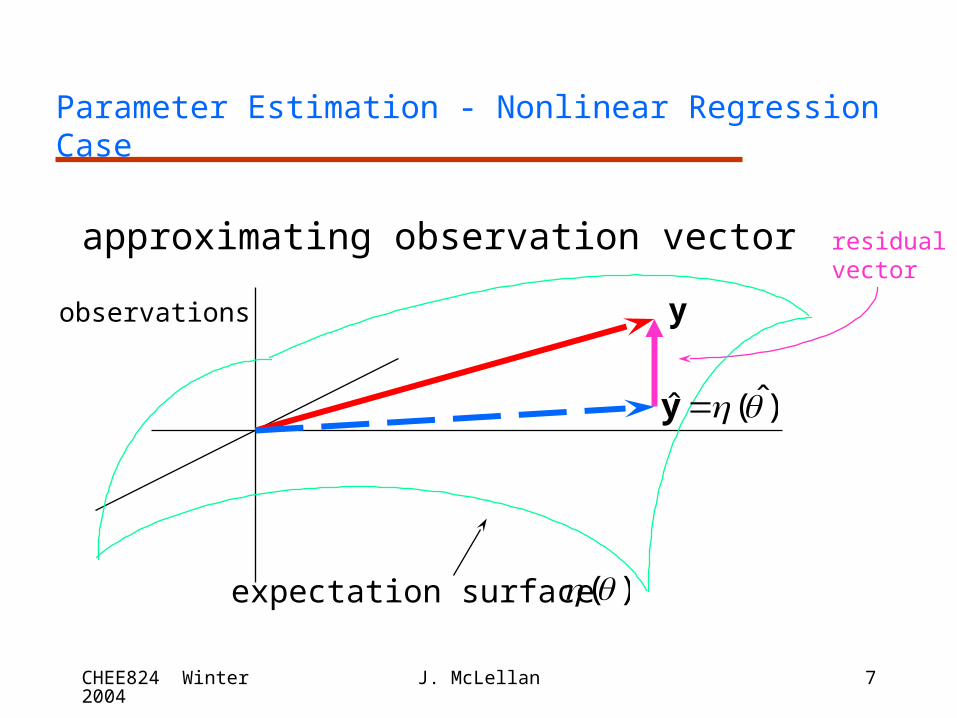
Parameter Estimation - Nonlinear Regression Case
approximating observation vector
y
residualvector
expectation surface
observations
)(
)ˆ(ˆ y

CHEE824 Winter 2004
J. McLellan 8
Parameter Estimation – Gauss-Newton Iteration
Least squares estimation – minimize
Iterative procedure consisting of:
1. Linearization about the current estimate of the parameters
2. Solution of the linear(ized) regression problem to obtain the next parameter estimate
3. Iteration until a convergence criterion is satisfied
)()( 2 ST eey

CHEE824 Winter 2004
J. McLellan 9
Linearization about a nominal parameter vector
Linearize the expectation function η(θ) in terms of the parameter vector θ about a nominal vector θ0:
0
0 ),(),(
),(),(
)(
1
1
1
1
0
p
nn
p
Tff
ff
xx
xx
V
00
000
)(
)()()(
V
V
Sensitivity Matrix-Jacobian of the expectationfunction-contains first-order sensitivity information

CHEE824 Winter 2004
J. McLellan 10
Parameter Estimation – Gauss-Newton Iteration
Iterative procedure consisting of:
1. Linearization about the current estimate of the parameters
2. Solution of the linear(ized) regression problem to obtain the next parameter estimate update
3. Iteration until a convergence criterion is satisfied– for example,
)1()()( )( iii Vy
))(()( )()(1)()()1( iTiiTii yVVV
toli
i
)(
)1(

CHEE824 Winter 2004
J. McLellan 11
Parameter Estimation - Nonlinear Regression Case
approximating observation vector
y
Tangent plane approximation
observations
)()( )( ii V
)1()()( )( iii V

CHEE824 Winter 2004
J. McLellan 12
Quality of the Linear Approximation
… depends on two components:
1. Degree to which the tangent plane provides a good approximation to the expectation surface- the planar assumption- related to intrinsic nonlinearity
2. Uniformity of the coordinates on the expectation surface – uniform coordinates - the linearization implies a uniform coordinate system on the tangent plane approximation – equal changes in a given parameter produce equal sized increments on the tangent plane- equal-sized increments in a given parameter may map to unequal-sized increments on the expectation surface

CHEE824 Winter 2004
J. McLellan 13
Rumford Example
• Consider two observations – 2-dimensional observation space» At t=4, t=41 min
Tangent plane approximation
Non-uniformity in coordinates
θ = 0θ changed in increments of 0.025
θ = 10

CHEE824 Winter 2004
J. McLellan 14
Rumford example
• Model function• Dataset consists of 13 observations
• Exercise – sensitivity matrix?» Dimensions?
tetf 7060),(

CHEE824 Winter 2004
J. McLellan 15
Rumford example – tangent approximation
• At θ = 0.05,
Tangent plane approximation
Non-uniformity in coordinates
Note uniformity in coordinateson tangent plane

CHEE824 Winter 2004
J. McLellan 16
Rumford example – tangent approximation
• At θ = 0.7,

CHEE824 Winter 2004
J. McLellan 17
Parameter Estimation – Gauss-Newton Iteration
Parameter estimation after jth iteration:
Convergence– can be declared by looking at:
» relative progress in the parameter estimate
» relative progress in reducing the sum of squares function
» combination of both progress in sum of squares reduction and progress in parameter estimates
)()1()( jjj
toli
i
)(
)1(
tolS
SS
i
ii
)(
)()(
)(
)()1(

CHEE824 Winter 2004
J. McLellan 18
Parameter Estimation – Gauss-Newton Iteration
Convergence– the relative change criteria in sum of squares or parameter estimates terminate on lack of
progress, rather than convergence (Bates and Watts, 1988)– alternative – due to Bates and Watts, termed the relative offset criterion
» we will have converged to the true optimum (least squares estimates) if the residual vector is orthogonal to the nonlinear expectation surface, and in particular, its tangent plane approximation at the true parameter values
» if we haven’t converged, the residual vectorwon’t necessarily be orthogonal to the tangent plane at the current parameter iterate
)(ye

CHEE824 Winter 2004
J. McLellan 19
Parameter Estimation – Gauss-Newton Iteration
Convergence» declare convergence by comparing component of residual vector lying on
tangent plane to the component orthogonal to the tangent plane – if the component on the tangent plane is small, then we are close to orthogonality convergence
» Note also that after each iteration, the residual vector is orthogonal to the tangent plane computed at the previous parameter iterate (where the linearization is conducted), and not necessarily to the tangent plane and expectation surface at the most recently computed parameter estimate
pN
p
iT
iT
/))((
/))((
)(2
)(1
yQ
yQ

CHEE824 Winter 2004
J. McLellan 20
Computational Issues in Gauss-Newton Iteration
The Gauss-Newton iteration can be subject to poor numerical conditioning, as the linearization is recomputed at new parameter iterates
» Conditioning problems arise in inversion of VTV» Solution – use a decomposition technique
• QR decomposition• Singular Value Decomposition (SVD)
» Decomposition techniques will accommodate changes in rank of the Jacobian (sensitivity) matrix V

CHEE824 Winter 2004
J. McLellan 21
QR Decomposition
An n x p matrix V takes vectors from a p-dimensional space into an n-dimensional space
VMN
p-dimensionale.g., p=2
n-dimensionale.g., n=3

CHEE824 Winter 2004
J. McLellan 22
QR Decomposition
• The columns of the matrix V (viewed as a linear mapping) are the images of the basis vectors for the domain space (M) expressed in the basis of the range space (N)
• If M is a p-dimensional space, and N is an n-dimensional space (with p<n), then V defines a p-dimensional linear subspace in N as long as V is of full rank
– Think of our expectation plane in the observation space for the linear regression case – the observation space is n-dimensional, while the expectation plane is p-dimensional where p is the number of parameters
• We can find a new basis for the range space (N) so that the first p basis vectors span the range of the mapping V, and the remaining n-p basis vectors are orthogonal to the range space of V

CHEE824 Winter 2004
J. McLellan 23
QR Decomposition
• In the new range space basis, the mapping will have zero elements in the last n-p elements of the mapping vector since the last n-p basis vectors are orthogonal to the range of V
• By construction, we can express V as an upper-triangular matrix
• This is a QR decomposition
0
Rqqq
QRV
121 n

CHEE824 Winter 2004
J. McLellan 24
QR Decomposition
• Example – linear regression with
11
01
11
X
β1
β2 X
y1
y2
y3
1
1
1
1
0
1
Perform QR decomposition QRX

CHEE824 Winter 2004
J. McLellan 25
QR Decomposition
• In the new basis, the expectation plane becomes
β1
β2
z1
z2
z3
0
0
7.1
0
4.1
0
00
4142.10
07032.1~ RXQX T

CHEE824 Winter 2004
J. McLellan 26
QR Decomposition
• The new basis for the range space is given by the columns of Q
4082.07071.05774.0
8165.005774.0
4082.07071.05774.0
Q
y1
y2
y3
Visualize the new basis vectorsfor the observation space relativeto the original basisq2
q1
q3z1 is distance along q1,
z2 is distance along q2,z3 is distance along q3

CHEE824 Winter 2004
J. McLellan 27
QR Decomposition
• In the new coordinates,
z1 is distance along q1, z2 is distance along q2,
z3 is distance along q3
z1
z2
z3
0
0
7.1
0
4.1
0

CHEE824 Winter 2004
J. McLellan 28
QR Decomposition
There are various ways to compute a QR decomposition
– Gram-Schmidt orthogonalization – sequential orthogonalization
– Householder transformations – sequence of reflections

CHEE824 Winter 2004
J. McLellan 29
QR Decompositions and Parameter Estimation
How does QR decomposition aid parameter estimation?– QR decomposition will identify the effective rank of the estimation problem
through the process of computing the decomposition » # of vectors spanning range space of V is the effective dimension of the
estimation problem» If dimension changes with successive linearizations, QR decomposition
will track this change» Reformulating the estimation problem using a QR decomposition
improves the numerical conditioning and ease of solution for the problem
» Over-constrained problem: e.g., for the linear regression case, find β to come as close to satisfying
QR
XY
0
RRYQ
1T

CHEE824 Winter 2004
J. McLellan 30
QR Decompositions and Parameter Estimation
• R1 is upper-triangular, and so the parameter estimates can be obtained sequentially
• The Gauss-Newton iteration follows the same pattern » Perform QR decompositions on each V
• QR decomposition also plays an important role in understanding nonlinearity
» Look at second-derivative vectors and partition them into components lying in the tangent plane (associated with tangential curvature) and those lying orthogonal to the tangent plane (associated with intrinsic curvature)
» QR decomposition can be used to construct this partitioning• First p vectors span the tangent plane, remaining are orthogonal to
it

CHEE824 Winter 2004
J. McLellan 31
Singular Value Decomposition
• Singular value decompositions (SVDs) are similar to eigenvector decompositions for matrices
• SVD:
Where» U is the “output rotation matrix”
» V is the “input rotation matrix” (pls don’t confuse with Jacobian!)
» Σ is a diagonal matrix of singular values
TVUX

CHEE824 Winter 2004
J. McLellan 32
Singular Value Decomposition
• Singular values:
i.e., the positive square root of the eigenvalues of XTX, which is square (will be pxp, where p is the number of parameters)
• Input singular vectors form the columns of V, and are the eigenvectors of XTX
• Output singular vectors form the columns of U, and are the eigenvectors of X XT
• One perspective – find new bases for the input space (parameter space) and output space (observation space) in which X becomes a diagonal matrix – only performs scaling, no rotation
• For parameter estimation problems, U will be nxn, and V will be pxp; Σ will be nxp
XXTii

CHEE824 Winter 2004
J. McLellan 33
SVD and Parameter Estimation
• SVD will accommodate effective rank of the estimation problem, and can track changes in the rank of the problem
» Recent work tries to alter the dimension of the problem using SVD information
• SVD can improve the numerical conditioning and ease of solution of the problem

CHEE824 Winter 2004
J. McLellan 34
Other numerical estimation methods
• Focus on minimizing the sum of squares function using optimization techniques
• Newton-Raphson solution– Solve for increments using second-order approximation of sum of
squares function
• Levenberg-Marquardt compromise – Modification of the Gauss-Newton iteration, with introduction of
factor to improve conditioning of linear regression step
• Nelder-Mead – Pattern search method – doesn’t use derivative information
• Hybrid approaches – Use combination of derivative-free and derivative-based methods

CHEE824 Winter 2004
J. McLellan 35
Other numerical estimation methods
• In general, the least squares parameter estimation approach represents a minimization problem
• Use optimization technique to find parameter estimates to minimize the sum of squares of the residuals

CHEE824 Winter 2004
J. McLellan 36
Newton-Raphson approach
• Start with the residual sum of squares function S(θ) and form the 2nd-order Taylor series expansion:
where H is the Hessian of S(θ):
» the Hessian is the multivariable second-derivative for a function of a vector
• Now solve for the next move by applying the stationarity condition (take 1st derivative, set to zero)
)()(21
)()(
)()( )()()()(
)(
iTiiT
i
i
SSS
H
)(
)(2
iT
S
H
)(
)()( 1)(
iTi S
H

CHEE824 Winter 2004
J. McLellan 37
Hessian
• Is the matrix of second derivatives – (consider using Maple to generate!)
)(
)(
2
2
1
2
1
21
2
22
2
21
21
2
21
2
21
2
2
)()()(
)(
)()(
)()()(
)(
i
i
pppp
pp
p
T
SSS
S
SS
SSS
S
H

CHEE824 Winter 2004
J. McLellan 38
Jacobian and Hessian of S(θ)
• Can be found by the chain rule:
))(()(
2)(
yTT
S the sensitivity matrix that we had before: V
VVy
yH
TT
TT
T
TTS
2))(()(
2
)()(2))((
)(2
)(
2
22
Often used as anapproximation of the Hessian – “expectedvalue of the Hessian”
3-dimensional array(tensor)

CHEE824 Winter 2004
J. McLellan 39
Newton-Raphson approach
• Using the approximate Hessian (which is always positive semi-definite), the change in parameter estimate is:
where V is evaluated at θ(i) is the sensitivity matrix.• This is the Gauss-Newton iteration!• Issues – computing and updating the Hessian matrix
» Potential better progress – information about curvature
» Hessian can cease to be positive definite (required in order for stationary point to be a minimum)
))(()(
)()(
1
1)(
)(
yVVV
H
TT
Ti
i
S

CHEE824 Winter 2004
J. McLellan 40
Levenberg-Marquardt approach
• Improve the conditioning of the inverse by adding a factor – biased regression solution –
• Levenberg modification
where Ip is the pxp identity matrix
• Marquardt modification
where D is a matrix containing the diagonal entries of VTV• If λ -> 0, approach Gauss-Newton iteration• If λ -> ∞, approach direction of steepest ascent – optimization
technique
))(()( )()(1)()()1( iTip
iTii yVIVV
))(()( )()(1)()()1( iTiiTii yVDVV

CHEE824 Winter 2004
J. McLellan 41
Inference – Joint Confidence Regions
• Approximate confidence regions for parameters and predictions can be obtained by using a linearization approach
• Approximate covariance matrix for parameter estimates:
where denotes the Jacobian of the expectation mapping evaluated at the least squares parameter estimates
• This covariance matrix is asymptotically the true covariance matrix for the parameter estimates as the number of data points becomes infinite
• 100(1-α)% joint confidence region for the parameters:
» compare to the linear regression case
21ˆ )ˆˆ( VVT
V
,,2)ˆ(ˆˆ)ˆ( pnp
TT Fsp VV

CHEE824 Winter 2004
J. McLellan 42
Inference – Marginal Confidence Intervals
• Marginal confidence intervals» Confidence intervals on individual parameters
where is the approximate standard error of the parameter estimate – i-th diagonal element of the approximate parameter estimate covariance matrix, with noise variance estimated as in the linear case
21ˆ )ˆˆ( sT VV
isti ˆ2/,
ˆ
is

CHEE824 Winter 2004
J. McLellan 43
Inference – Predictions & Confidence Intervals
• Confidence intervals on predictions of existing points in the dataset– Reflect propagation of variability from the parameter estimates to the
predictions
– Expressions for nonlinear regression case based on linear approximation and direct extension of results for linear regression
First, let’s review the linear regression case…

CHEE824 Winter 2004
J. McLellan 44
Precision of the Predicted Responses - Linear
From the linear regression module (module 1) –
The predicted response from an estimated model has uncertainty, because it is a function of the parameter estimates which have uncertainty:
e.g., Solder Wave Defect Model - first response at the point -1,-1,-1
If the parameter estimates were uncorrelated, the variance of the predicted response would be:
(recall results for variance of sum of random variables)
( ) ( ) ( )y1 0 1 2 31 1 1
Var y Var Var Var Var( ) ( ) ( ) ( ) ( )1 0 1 2 3

CHEE824 Winter 2004
J. McLellan 45
Precision of the Predicted Responses - Linear
In general, both the variances and covariances of the parameter estimates must be taken into account.
For prediction at the k-th data point:
22
1
121
21
)(
)()ˆ(
kp
k
k
Tkpkk
kTT
kk
x
x
x
xxx
yVar
XX
xXXx
kTkk
TTkkyVar xxxXXx ˆ
21)()ˆ( Note -

CHEE824 Winter 2004
J. McLellan 46
Precision of the Predicted Responses - Nonlinear
Linearize the prediction equation about the least squares estimate:
For prediction at the k-th data point:
22
1
121
21
ˆ
ˆ
ˆ
)ˆˆ(ˆˆˆ
ˆ)ˆˆ(ˆ)ˆ(
kp
k
k
Tkpkk
kTT
kk
v
v
v
vvv
yVar
VV
vVVv
kTkk
TTkkyVar vvvVVv ˆˆˆ)ˆˆ(ˆ)ˆ( ˆ
21
Note -
)ˆ()ˆ,()ˆ(),(
)ˆ,(ˆˆ
T
kkTk
kk ff
fy vxx
x

CHEE824 Winter 2004
J. McLellan 47
Estimating Precision of Predicted Responses
Use an estimate of the inherent noise variance
The degrees of freedom for the estimated variance of the predicted response are those of the estimate of the noise variance
» replicates
» external estimate
» MSE
212ˆ
212ˆ
)(
)(
ss
ss
kTT
ky
kTT
ky
k
k
vVVv
xXXx
linear
nonlinear

CHEE824 Winter 2004
J. McLellan 48
Confidence Limits for Predicted Responses
Linear and Nonlinear Cases:
Follow an approach similar to that for parameters - 100(1-α)% confidence limits for predicted response at the k-th run are:
» degrees of freedom are those of the inherent noise variance estimate
If the prediction is for a response at conditions OTHER than one of the experimental runs, the limits are:
, / y t sk yk 2
22ˆ2/,ˆ eyk sstyk

CHEE824 Winter 2004
J. McLellan 49
Precision of “Future” Predictions - Explanation
Suppose we want to predict the response at conditions other than those of the experimental runs --> future run.
The value we observe will consist of the component from the deterministic component, plus the noise component.
In predicting this value, we must consider:
» uncertainty from our prediction of the deterministic component
» noise component
The variance of this future prediction is
where is computed using the same expression
for variance of predicted responses at experimental run conditions
- For linear case, with x containing specific run conditions,
2)ˆ( yVar)ˆ(yVar
xxxXXx ˆ21)()ˆ( TTTyVar

CHEE824 Winter 2004
J. McLellan 50
Properties of LS Parameter Estimates
Key Point - parameter estimates are random variables» because of how stochastic variation in data propagates through
estimation calculations
» parameter estimates have a variability pattern - probability distribution and density functions
Unbiased
» “average” of repeated data collection / estimation sequences will be true value of parameter vector
E{ }

CHEE824 Winter 2004
J. McLellan 51
Properties of Parameter Estimates
Consistent» behaviour as number of data points tends to infinity
» with probability 1,
» distribution narrows as N becomes large
Efficient» variance of least squares estimates is less than that of other
types of parameter estimates
Nlim

CHEE824 Winter 2004
J. McLellan 52
Properties of Parameter Estimates
Linear Regression Case– Least squares estimates are –
» Unbiased
» Consistent
» Efficient
Nonlinear Regression Case– Least squares estimates are –
» Asymptotically unbiased – as number of data points becomes infinite
» Consistent
» efficient

CHEE824 Winter 2004
J. McLellan 53
Maximum Likelihood Estimation
Concept – • Start with function which describes likelihood of data given
parameter values» Probability density function
• Now change perspective – assume that data observed are the most likely, and find parameter values to make the data the most likelihood
» Likelihood of parameters given observed data
• Estimates are “maximum likelihood” estimates

CHEE824 Winter 2004
J. McLellan 54
Maximum Likelihood Estimation
• For Normally distributed data (random shocks)• Recall that for a given run, we have
• Probability density function for Yi:
» Mean is given by f(xi,θ), and variance is
),0(~,),( 2 NfY iiii x
2
2)),((
21
exp2
1)(
iY fyyf
ix

CHEE824 Winter 2004
J. McLellan 55
Maximum Likelihood Estimation
• With n observations, given that the responses are independent (since the random shocks are independent), the joint density function for the observations is simply the product of the individual density functions:
n
iiinn
n
iiinYY
fy
fyyyfn
1
22/
1
21
)),((2
1exp
)2(
1
)),((2
1exp
21
),(1
x
x

CHEE824 Winter 2004
J. McLellan 56
Maximum Likelihood Estimation
• In shorthand, using vector notation for the observations, and now explicitly acknowledging that we “know”, or are given, the parameter values:
Note that we have written the sum of squares in vector notation as well, using the expectation mapping.
• Note also that the random noise standard deviation is also a parameter
))(())((2
1exp
)2(
1
)),((2
1exp
)2(
1),|(
2/
1
22/
yy
xyY
Tnn
n
iiinn
fyf

CHEE824 Winter 2004
J. McLellan 57
Likelihood Function
• Now, we have a set of observations, which we will assume are the most likely, and we now define the likelihood function:
))(())((2
1exp
)2(
1
)),((2
1exp
)2(
1)|,(
2/
1
22/
yy
xy
Tnn
n
iiinn
fyl

CHEE824 Winter 2004
J. McLellan 58
Log-likelihood function
• We can also work with the log-likelihood function, which extracts the important part of the expression from the exponential:
))(())((2
1)ln(
)),((2
1)ln()|,(
1
2
yy
xy
T
n
iii fynL

CHEE824 Winter 2004
J. McLellan 59
Maximum Likelihood Parameter Estimates
• Formal statement as optimization problem:
))(())((2
1exp
)2(
1max
)),((2
1exp
)2(
1max)|,(max
2/,
1
22/,,
yy
xy
Tnn
n
iiinn
fyl

CHEE824 Winter 2004
J. McLellan 60
Maximum Likelihood Estimation
• Examine the likelihood function:
• Regardless of the noise standard deviation, the likelihood function will be maximized by those parameter values minimizing the sum of squares between the observed data and the model predictions
» These are the parameter values that make the observed data the “most likely”
))(())((2
1exp
)2(
1
)),((2
1exp
)2(
1)|,(
2/
1
22/
yy
xy
Tnn
n
iiinn
fyl

CHEE824 Winter 2004
J. McLellan 61
Maximum Likelihood Estimation
• In terms of the residual sum of squares function, we have the likelihood function:
and the log-likelihood function:
)(
21
exp)2(
1)|,(
2/
Sl
nny
)(2
1)ln()|,(
SnL y

CHEE824 Winter 2004
J. McLellan 62
Maximum Likelihood Estimation
• We can obtain the optimal parameter estimates separately from the noise standard deviation, given the form of the likelihood function
» Minimize sum of squares of residuals – not a function of noise standard deviation
• For Normally distributed data, the maximum likelihood parameter estimates are the same as the least squares estimates for nonlinear regression
• The maximum likelihood estimate for the noise variance is the mean squared error (MSE),
» Obtain by taking derivative with respect to the variance, and then solving
nS
s)ˆ(2

CHEE824 Winter 2004
J. McLellan 63
Maximum Likelihood Estimation
Further comments:• We could develop the likelihood function starting with the
distribution of the random shocks, ε, producing the same expression
• If the random shocks were independent, but had a different distribution, then the observations would also have a different distribution
» Expectation function defines means of this distribution
where g is the individual density function
» Could then develop a likelihood function from this density fn.
n
iiinYY ygyyf
n1
1 ),;()|,(1
x

CHEE824 Winter 2004
J. McLellan 64
Inference Using Likelihood Functions
• Generate likelihood regions – contours of the likelihood function» Choice of contour value comes from examining distribution
• Unlike the least squares approximate inference regions, which were developed using linearizations, the likelihood regions need not be elliptical or ellipsoidal
» Can have banana shapes, or can be open contours
• Likelihood regions – first, examine the likelihood function:
– The dependence of the likelihood function on the parameters is through the sum of squares function S(θ)
)(
21
exp)2(
1)|,(
2/
Sl
nny

CHEE824 Winter 2004
J. McLellan 65
Likelihood regions
• Focusing on S(θ), we have
– Note that the denominator is the MSE – residual variance
• This is an asymptotic result in the nonlinear case, and an exact result for the linear regression case
• We can generate likelihood regions as values of θ such that
pnpF
pnSpSS
,~)ˆ(
)ˆ()(
]1)[ˆ()( , pnpFpnp
SS

CHEE824 Winter 2004
J. McLellan 66
Likelihood regions – further comments
• The likelihood regions are essentially sums of squares contours– Specifically for case where data are Normally distributed
• In the nonlinear regression case,
and so the likelihood contours are approximated by the linearization-based approximate joint confidence region from least squares theory
)ˆ(ˆˆ)ˆ()ˆ()( VVTTSS
,,2)ˆ(ˆˆ)ˆ( pnp
TT Fsp VV

CHEE824 Winter 2004
J. McLellan 67
Likelihood regions – further comments
• Using
is an approximate approach that approximates the exact likelihood region– Approximation is in the sampling distribution argument used to derive
the expression in terms of the F distribution
– This is asymptotically (as the number of data points becomes infinite) an exact likelihood region
• In general, an exact likelihood region would be given by
for some appropriately chosen constant “c”– Note that in the approximation,
]1)[ˆ()( , pnpFpnp
SS
)ˆ()( ScS
]1[ , pnpFpnp
c

CHEE824 Winter 2004
J. McLellan 68
Likelihood regions further comments
• In general, the difficulty in using
lies in finding a value of “c” that gives the correct coverage probability– The coverage probability is the probability that the region contains
the true parameter values
– The approximate result using the F-distribution is an attempt to get such a coverage probability
– The likelihood contour is reported to give better coverage probabilities for smaller data sets, and is less affected by nonlinearity
» Donaldson and Schnabel(1987)
)ˆ()( ScS

CHEE824 Winter 2004
J. McLellan 69
Likelihood regions - Examples
• Puromycin – from Bates and Watts (untreated cases)– Red is 95% likelihood region
– Blue is 95% confidence region (linear approximation)
– Note some difference in shape,orientation and size, but not too pronounced
– Square indicates least squaresestimates
– Maple worksheet availableon course web

CHEE824 Winter 2004
J. McLellan 70
Likelihood Regions - Examples
• BOD – from Bates and Watts– Red is 95% likelihood region
– Blue is 95% confidenceregion (linear approximation)
– Note significant differencein shapes
– Note that confidence ellipseincludes the value of 0 for θ2
– Square indicates leastsquares estimates
– Maple worksheet availableon course web

CHEE824 Winter 2004
J. McLellan 71
Bayesian estimation
Premise –– The distribution of observations is characterized by parameters
which in turn have some distribution of their own
– Concept of prior knowledge of the values that the parameters might assume
• Model
• Noise characteristics
• Approach – use Bayes’ theorem
)(Y
),0(...~ 2 Ndii

CHEE824 Winter 2004
J. McLellan 72
Conditional Expectation
Recall conditional probability:
» probability of X given Y, where X and Y are events
For continuous random variables, we have a conditional probability density function expressed in terms of the joint and marginal distribution functions:
Note - Using this, we can also define the conditional expectation of X given Y:
)()(
)|(YPYXP
YXP
)(),(
)|(| yfyxf
yxfY
XYYX
dxyxfxYXE YX )|(}|{ |

CHEE824 Winter 2004
J. McLellan 73
Bayes’ Theorem
• useful for situations in which we have incomplete probability knowledge
• forms basis for statistical estimation• suppose we have two events, A and B• from conditional probability:
so
for P(B)>0
)()|()()()|()( APABPABPBPBAPBAP
)()()|(
)|(BP
APABPBAP

CHEE824 Winter 2004
J. McLellan 74
Bayesian Estimation
• Premise – parameters can have their own distribution – prior distribution
• The posterior distribution of the parameters can be related to the prior distribution of the parameters and the likelihood function:
),( f
),(),|(
)(
),(),|(
)(
),,()|,(
fyf
yf
fyf
yf
yfyf
)|,( yf Posterior Distribution- of parameters givendata

CHEE824 Winter 2004
J. McLellan 75
Bayesian Estimation
• The noise standard deviation σ is a nuisance parameter, and we can focus instead on the model parameters:
• How are the posterior distributions with/without σ related?
)()|()|( fyfyf
dyfyf )|,()|(

CHEE824 Winter 2004
J. McLellan 76
Bayesian estimation
• Bayes’ theorem• Posterior density function in terms of prior density function• Equivalence for normal with uniform prior – least squares /
maximum likelihood estimates• Inference – posterior density regions

CHEE824 Winter 2004
J. McLellan 77
Diagnostics for nonlinear regression
• Similar to linear case • Qualitative – residual plots
– Residuals vs. » Factors in model» Sequence (observation) number » Factors not in model (covariates)» Predicted responses
– Things to look for: » Trend remaining» Non-constant variance» Meandering in sequence number – serial correlation
• Qualitative – plot of observed and predicted responses– Predicted vs. observed – slope of 1– Predicted and observed – as function of independent variable(s)

CHEE824 Winter 2004
J. McLellan 78
Diagnostics for nonlinear regression
• Quantitative diagnostics– Ratio tests:
» MSR/MSE – as in the linear case – coarse measure of significant trend being modeled
» Lack of fit test – if replicates are present
• As in linear case – compute lack of fit sum of squares, error sum of squares, compare ratio
» R-squared
• coarse measure of significant trend
• squared correlation of observed and predicted values
• adjusted R-squared
• squared correlation of observed and predicted values

CHEE824 Winter 2004
J. McLellan 79
Diagnostics for nonlinear regression
• Quantitative diagnostics– Parameter confidence intervals:
» Examine marginal intervals for parameters• Based on linear approximations• Can also use hypothesis tests
» Consider dropping parameters that aren’t statistically significant» Issue in this case – parameters are more likely to be involved in
more complex expression involving factors, parameters• E.g., Arrhenius reaction rate expression
» If possible, examine joint confidence regions, likelihood regions, HPD regions
• Can also test to see if a set of parameter values lie in a particular region squared correlation of observed and predicted values

CHEE824 Winter 2004
J. McLellan 80
Diagnostics for nonlinear regression
• Quantitative diagnostics– Parameter estimate correlation matrix:
» Examine correlation matrix for parameter estimates• Based on linear approximation• Compute covariance matrix, then normalize using pairs of
standard deviations» Note significant correlations and keep these in mind when
retaining/deleting parameters using marginal significance tests» Significant correlation between some parameter estimates may
indicate over-parameterization relative to the data collected• Consider dropping some of the parameters whose estimates
are highly correlated
• Further discussion – Chapter 3 - Bates and Watts (1988), Chapter 5 - Seber and Wild (1988)

CHEE824 Winter 2004
J. McLellan 81
Practical Considerations
• Convergence – – “tuning” of estimation algorithm – e.g., step size factors
– Knowledge of the sum of squares (or likelihood or posterior density) surface – are there local minima?
» Consider plotting surface
– Reparameterization
• Ensuring physically realistic parameter estimates– Common problem – parameters should be positive
– Solutions
» Constrained optimization approach to enforce non-negativity of parameters
» Reparameterization – for example
e1
1
10
)exp( positive
positive
Bounded between 0 and 1

CHEE824 Winter 2004
J. McLellan 82
Practical considerations
• Correlation between parameter estimates– Reduce by reparameterization
– Exponential example –
)exp( 21 x
))(exp(
))(exp()exp(
))(exp(
021
02021
0021
xx
xxx
xxx

CHEE824 Winter 2004
J. McLellan 83
Practical considerations
• Particular example – Arrhenius rate expression
– Effectively reaction rate relative to reference temperature
– Reduces correlation between parameter estimates and improves conditioning of estimation problem
)11
(exp
)11
(expexp
)111
(expexp
0
00
refref
refref
refref
TTRE
k
TTR
E
RT
Ek
TTTRE
kRTE
k

CHEE824 Winter 2004
J. McLellan 84
Practical considerations
• Scaling – of parameters and responses• Choices
– Scale by nominal values
» Nominal values – design centre point, typical value over range, average value
– Scale by standard errors
» Parameters – estimate of standard devn of parameter estimate
» Responses – by standard devn of observations – noise standard deviation
– Combinations – by nominal value / standard error
• Scaling can improve conditioning of the estimation problem (e.g., scale sensitivity matrix V), and can facilitate comparison of terms on similar (dimensionless) bases

CHEE824 Winter 2004
J. McLellan 85
Practical considerations
• Initial guesses– From prior knowledge
– From prior results
– By simplifying model equations
– By exploiting conditionally linear parameters – fix these, estimate remaining parameters

CHEE824 Winter 2004
J. McLellan 86
Dealing with heteroscedasticity
• Problem it poses – precision of parameter estimates• Weighted least squares estimation• Variance stabilizing transformations – e.g., Box-Cox
transformations

CHEE824 Winter 2004
J. McLellan 87
Estimating parameters in differential equation models
• Model is now described by a differential equation:
• Referred to as “compartment models” in the biosciences.
• Issues – – Estimation – what is the effective expectation function here?
» Integral curve or flow (solution to differential equation)– Initial conditions – known?, unknown and estimated?, fixed (conditional
estimation)?– Performing Gauss-Newton iteration
» Or other numerical approach– Solving differential equation
00)();;,,( ytytyfdtdy u

CHEE824 Winter 2004
J. McLellan 88
Estimating parameters in differential equation models
What is the effective expectation function here?– Differential equation model:
– y – response, u – independent variables (factors), t – becomes a factor as well
– Expectation function is the solution to the differential equation, which is evaluated at different times at which observations are taken
– Note implicit dependence on initial conditions, which may be assumed or estimated
– Often this is a conceptual model and not an analytical solution – the solution is often the numerical solution at specific times - subroutine
00)();;,,( ytytyfdt
dy u
),;,()( 0yty iii u

CHEE824 Winter 2004
J. McLellan 89
Estimating parameters in differential equation models
• Expectation mapping
• Random noise – is assumed to be additive on the observations
),;,(
),;,(
),;,(
)(
)(
)(
)(
0
022
011
2
1
yty
yty
yty
nnn
u
u
u
nnnY
Y
Y
2
1
2
1
2
1
)(
)(
)(
)(Y

CHEE824 Winter 2004
J. McLellan 90
Estimating parameters in differential equation models
Estimation approaches– Least squares (Gauss-Newton/Newton-Raphson iteration), maximum
likelihood, Bayesian
– Will require sensitivity information – sensitivity matrix V
How can we get sensitivity information without having an explicit solution to the differential equation model?
),;,(
),;,(
),;,(
)(
0
022
011
yty
yty
yty
nn u
u
u
V

CHEE824 Winter 2004
J. McLellan 91
Estimating parameters in differential equation models
Sensitivity equations– We can interchange the order of differentiation in order to obtain the
sensitivity differential equations – referred to as sensitivity equations
– Note that the initial condition for the response may also be a function of the parameters – e.g., if we assume that the process is initially at steady-state parametric dependence through steady-state form of model
– These differential equations are solved to obtain the parameter sensitivities at the necessary time points: t1, …tn
00 )(
);,,();,,(
yty
tyfy
y
tyfy
dt
d
dt
dy uu

CHEE824 Winter 2004
J. McLellan 92
Estimating parameters in differential equation models
Sensitivity equations– The sensitivity equations are coupled with the original model
differential equations – for the single differential equation (and response) case, we will have p+1 simultaneous differential equations, where p is the number of parameters
ppp
tyfy
y
tyfy
dt
d
tyfy
y
tyfy
dt
d
tyfy
y
tyfy
dt
d
tyfdt
dy
);,,();,,(
);,,();,,(
);,,();,,(
);,,(
222
111
uu
uu
uu
u

CHEE824 Winter 2004
J. McLellan 93
Estimating parameters in differential equation models
Variations on single response differential equation models– Single response differential equation models need not be restricted
to single differential equations
– We really have a single measured output variable, and multiple factors
» Control terminology – multi-input single-output (MISO) system
);,,(
)();;,,( 00
thy
ttf
ux
xxuxx
);,,();,,(
,,1,)(
;);,,();,,( 00
ththy
pittftf
dt
d
iiiii
uxx
x
ux
xxuxx
x
uxx Sensitivityequations
Differential equation model

CHEE824 Winter 2004
J. McLellan 94
Estimating parameters in differential equation models
Options for solving the sensitivity equations – – Solve model differential equations and sensitivity equations
simultaneously
» Potentially large number of simultaneous differential equations
• ns(1+p) differential equations
» Numerical conditioning
» “Direct”
– Solve model differential equations, sensitivity equations, sequentially
» Integrate model equations forward to next time step
» Integrate sensitivity equations forward, using updated values of states
» “Decoupled Direct”

CHEE824 Winter 2004
J. McLellan 95
Interpreting sensitivity responses
Example – first-order linear differential equation with step input
uyy 2
1
2
1
Step response Sensitivities

CHEE824 Winter 2004
J. McLellan 96
Estimating parameters in differential equation models
• When there are multiple responses being measured (e.g., temperature, concentrations of different species), the resulting estimation problem is a multi-response estimation problem
• Other issues– Identifiability of parameters– How “time” is treated – as independent variable (in my earlier
presentation), or treating responses at different times as different responses
– Obtaining initial parameter estimates » See for example discussion in Bates and Watts, Seber and Wild
– Serial correlation in random noise» Particularly if the random shocks enter in the differential equation,
rather than being additive to the measured responses

CHEE824 Winter 2004
J. McLellan 97
Multi-response estimation
Multi-response estimation refers to the case in which observations are taken on more than one response variable
Examples – Measuring several different variables – concentration, temperature, yield– Measuring a functional quantity at a number of different index values –
examples » molecular weight distribution – measuring differential weight fraction
at a number of different chain lengths» particle size distribution – measuring differential weight fraction at a
number of different particle size bins» Time response – treating response at different times as individual
responses» Spatial temperature distribution – treating temperature at different
spatial locations as individual responses

CHEE824 Winter 2004
J. McLellan 98
Multi-response estimation
Problem formulation– Responses
» n runs
» m responses
– Model equations
» m model equations – one for each response – evaluated at n run conditions
» Model for jth response evaluated at ith run conditions
nmnn
m
m
m
yyy
yyy
yyy
21
22221
11211
21 YYYY
),( ijij fh xH

CHEE824 Winter 2004
J. McLellan 99
Multi-response estimation
• Random noise– We have a random noise for each observation of each response –
denote random noise in jth response observed at ith run conditions as Zij
– Have matrix of random noise elements
– Issue – what is the correlation structure of the random noise?
nmnn
m
m
ij
ZZZ
ZZZ
ZZZ
Z
21
22221
11211
Z
Within run correlation?
Between run correlation?

CHEE824 Winter 2004
J. McLellan 100
Multi-response estimation
Covariance structure of the random noise – possible structures– No covariance between the random noise components – all random
noise components are independent, identically distributed?
» Can use least squares solution in this instance
– Within run covariance – between responses – that is the same for each run condition
» Responses have a certain inherent covariance structure
» Covariance matrix
» Determinant criterion for estimation
» Alternative – generalized least squares – stack observations
– Between run covariance
– Complete covariance – between runs, across responses
















![Flujo de Potencia [Modo de compatibilidad] - u-cursos.cl · Método de Gauss Método de Gauss ----SeidelSeidel La “Receta” para Gauss La “Receta” para Gauss ––Seidel Seidel](https://static.fdocuments.net/doc/165x107/5d3f527d88c993860c8d17eb/flujo-de-potencia-modo-de-compatibilidad-u-metodo-de-gauss-metodo-de.jpg)

