
Modeling User Satisfaction and Student Learning in a Spoken Dialogue Tutoring System with Generic,...
35
Modeling User Satisfaction and Student Learning in a Spoken Dialogue Tutoring System with Generic, Tutoring, and User Affect Parameters Kate Forbes-Riley and Diane Litman University of Pittsburgh
-
Upload
shonda-george -
Category
Documents
-
view
214 -
download
0
Transcript of Modeling User Satisfaction and Student Learning in a Spoken Dialogue Tutoring System with Generic,...

Modeling User Satisfaction and Student Learning
in a Spoken Dialogue Tutoring System
with Generic, Tutoring, and User Affect Parameters
Kate Forbes-Riley and Diane LitmanUniversity of Pittsburgh

Outline
Overview PARADISE System and Corpora Interaction Parameters Prediction Models Conclusions and Future Work

Overview Goals:
PARADISE: Model performance in our spoken dialogue tutoring system in terms of interaction parameters
Focus design efforts on improving parameters - predict better performance for future
users
Use model to predict simulated user performance - as different system versions designed

Overview What is Performance in our spoken dialogue
tutoring system?
User Satisfaction: primary metric for many spoken dialogue systems, e.g. travel-planning (user surveys) Hypothesis: less useful
Student Learning: primary metric for tutoring systems (student pre/post tests) Hypothesis: more useful

Overview What Interaction Parameters for our spoken
dialogue tutoring system?
Spoken Dialogue System-Generic (e.g. time): shown useful in non-tutoring PARADISE applications modeling User Satisfaction
Tutoring-Specific (e.g. correctness) Hypothesis: task-specific parameters impact performance
User Affect (e.g. uncertainty) Hypothesis: affect impacts performance - generic too

Overview Are the resulting Performance Models useful?
Generic and Tutoring parameters yield useful Student Learning models
Affect parameters increase usefulness
Generic and Tutoring parameters yield less useful User Satisfaction models than prior non-tutoring applications
(Bonneau-Maynard et al., 2000), (Walker et al., 2002), (Möller, 2005): better models with generic only
Too little data to include Affect parameters

PARADISE Framework (Walker et al., 1997) Measure parameters (interaction costs and benefits) and
performance in system corpus
Train model via multiple linear regression (MLR) over parameters, predict performance (R2= variance predicted)
SPSS stepwise MLR: determine parameter inclusion (most correlated until no better R2/non-significant model)
System Performance = ∑ wi * pi
Test model usefulness (generalize) on new corpus (R2)
n
i=1

Speech front-end for text-based Why2-Atlas (VanLehn et al., 2002)
Qualitative Physics Tutor
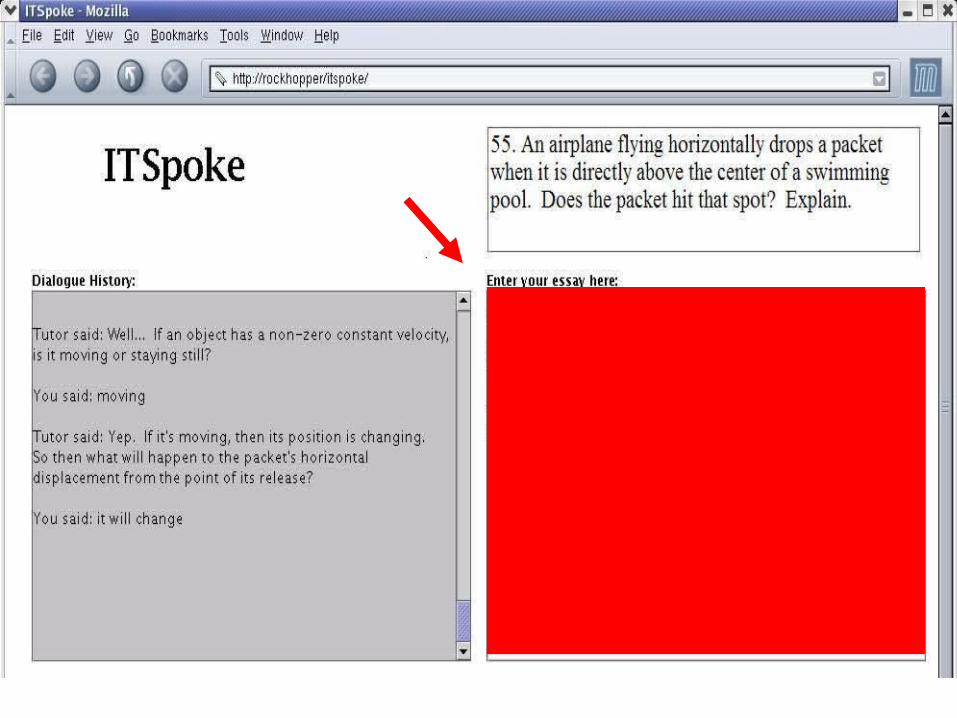

• Sphinx2 speech recognizer - Why2-Atlas performs NLP on transcript


3 ITSPOKE Corpora
Synthesized voice: Cepstral text-to-speech system
Pre-Recorded voice: paid voice talent
Corpus #Students #with Tests #with Survey #with Affect
SYN03 20 20 0 20
PR05 28 28 28 17
SYN05 29 29 29 0

Experimental Procedure
Subjects without college physics: Read a small background document Took a pretest Worked 5 problems (dialogues) with ITSPOKE Took a posttest
Corpus #Students #with Tests #with Survey #with Affect
SYN03 20 20 0 20
PR05 28 28 28 17
SYN05 29 29 29 0

User Satisfaction Survey after Posttest
Task Ease: It was easy to learn from the tutor.TTS Performance: It was easy to understand the tutor.User Expertise: I knew what I could say or do at each point in the
conversations with the tutor.Expected Behavior: The tutor worked the way I expected it to.Future Use: Based on my experience using the tutor to learn physics,
I would like to use such a tutor regularly.
ALMOST ALWAYS (5), OFTEN (4), SOMETIMES (3), RARELY (2), ALMOST NEVER (1)
Corpus #Students #with Tests #with Survey #with Affect
SYN03 20 20 0 20
PR05 28 28 28 17
SYN05 29 29 29 0

User Affect Annotation
Each student turn labeled with 1 Certainness State: certain, uncertain, mixed, neutral
Each student turn labeled with 1 Frustration State: frustrated, non-frustrated
Corpus #Students #with Tests #with Survey #with Affect
SYN03 20 20 0 20
PR05 28 28 28 17
SYN05 29 29 29 0

SYN03 Annotated Excerpt
T: What is the NET force acting on the truck equal to?
S: I don’t know (ASR: I don’t know ) [Uncertain, Frustrated, Incorrect]
T: Since net force is defined as the vector sum of all the forces exerted on an object, let's first find the forces
acting on the truck. Try to name them.
S: The impact force, the normal force, and gravity(ASR: the impact force but normal force and gravity) [Certain, Non-Frustrated, Correct]
T: Yep.

Interaction Parameters
Prior PARADISE applications Each dialogue between user and system represents a
single task (e.g., booking airline travel) Parameters calculated on a per-dialogue basis
Our tutoring application Entire tutoring session (5 dialogues) between student and
ITSPOKE represents a single task Parameters calculated on a per-student basis

13 Dialogue System-Generic Parameters Most from prior PARADISE applications (Möller, 2005),
(Walker et al. 2002), (Bonneau-Maynard, 2000) Time on Task Total ITSPOKE Turns, Total Student Turns Total ITSPOKE Words, Total Student Words Ave. ITSPOKE Words/Turn, Ave. Student Words/Turn Word Error Rate, Concept Accuracy Total Timeouts, Total Rejections
Ratio of Student Words to ITSPOKE Words Ratio of Student Turns to ITSPOKE Turns

12 Tutoring-Specific Parameters 9 Parameters related to Correctness of Student Turn
ITSPOKE labels: Correct, Incorrect, Partially Correct Total and Percent for each label Ratio of each label to every other label
Total number of essays per student
Student pretest and posttest score (for US)
Similar parameters available in most tutoring systems

25 User Affect Parameters
For each of our 4 Certainness labels: Total, Percent, and Ratio to each other label Total for each sequence of identical labels
(e.g. Certain:Certain)
For each of our 2 Frustration labels Total, Percent, and Ratio to each other label Total for each sequence of identical labels

User Satisfaction Prediction Models Predicted Variable: Total Survey Score
Range: 9 - 24 out of 5 - 25; no corpora differences (p = .46)
Input Parameters: Generic and Tutoring
Do models generalize across corpora (system versions)? Train on PR05 Test on SYN05 Train on SYN05 Test on PR05
Do models generalize better within corpora? Train on half PR05 Test on half PR05 (for each half) Train on half SYN05 Test on half SYN05 (for each
half)

User Satisfaction Prediction Models Best Results (on Test Data)
Inter-corpus models are weak and don’t generalize well Intra-corpus models generalize better, but are still weak
predictors of User Satisfaction Generic and Tutoring parameters selected
Train R2 Ranked Predictors Test R2
SYN05 .068 ITSPOKE Words/Turn PR05 .018
SYN05half #2
.685 ITSPOKE Words/Turn, Student Words/Turn, #Correct
SYN05 half #1
.227

User Satisfaction Prediction Models Comparison to Prior Work
Some of same parameters also selected as predictors, e.g. in (Walker et al., 2002) (User Words/Turn)
Higher best test results (R2 = .3 - .5) in (Möller, 2005), (Walker et al., 2002) and (Bonneau-Maynard et al., 2000)

Student Learning Prediction Models First Experiments:
Data and Input Parameters: same as for User Satisfaction experiments
Predicted Variable: Posttest controlled for Pretest (learning gains); significant learning independently of corpus (p < .001)
Train R2 Ranked Predictors Test R2
PR05 .556 Pretest, %Correct SYN05 .636
SYN05 half #1
.580 Pretest, Student Words/Turn
SYN05 half #2
.556

Student Learning Prediction Models First Experiments: (Best Results on Test Data in table)
All models account for ~ 50% of Posttest variance in train and test data
Intra-corpus models don’t show higher generalizability
Generic and Tutoring parameters selected
Train R2 Ranked Predictors Test R2
PR05 .556 Pretest, %Correct SYN05 .636
SYN05 half #1
.580 Pretest, Student Words/Turn
SYN05 half #2
.556

Student Learning Prediction Models
Further experiments:
Including third corpus (SYN03) with Generic and Tutoring parameters yields similar results
Best Result (on Test Data):
Train R2 Ranked Predictors
Test R2
PR05+SYN03 .413 Pretest, Time SYN05 .586

Student Learning Prediction Models Further experiments: including User Affect
Parameters can improve results:
Train R2 Ranked Predictors Test R2
SYN03
.644 Time, Pretest, #Neutrals
PR05-17
.411
Posttest = .86 * Time + .65 * Pretest - .54 * #Neutrals
Train R2 Ranked Predictors Test R2
SYN03
.478 Pretest, Time PR05-17
.340
Same experiment without User Affect Parameters:

Summary: Student Learning Models
This method of developing a Student Learning model:
useful for our tutoring application
User Affect parameters can increase usefulness of Student Learning Models

Summary: User Satisfaction Models
This method of developing a User Satisfaction model:
less useful for our tutoring application as compared to prior non-tutoring applications
Why are our User Satisfaction models less useful?
Per-student measure of User Satisfaction not fine-grained enough
Tutoring systems not designed to maximize User Satisfaction; goal is to maximize Student Learning

Conclusions
For the tutoring community: PARADISE provides an effective method of extending
single Student Learning correlations
For the spoken dialogue community: When using PARADISE:
other performance metrics may be more useful for applications not optimized for User Satisfaction
task-specific and user affect parameters may be useful

Future Work Investigate usefulness of additional input parameters
for predicting Student Learning and User Satisfaction
User Affect annotations (once complete)
Tutoring Dialogue Acts (e.g. Möller, 2005; Litman and Forbes-Riley, 2006)
Discourse Structure annotations (Rotaru and Litman, 2006)

Thank You!
Questions?
Further information:http://www.cs.pitt.edu/~litman/itspoke.html
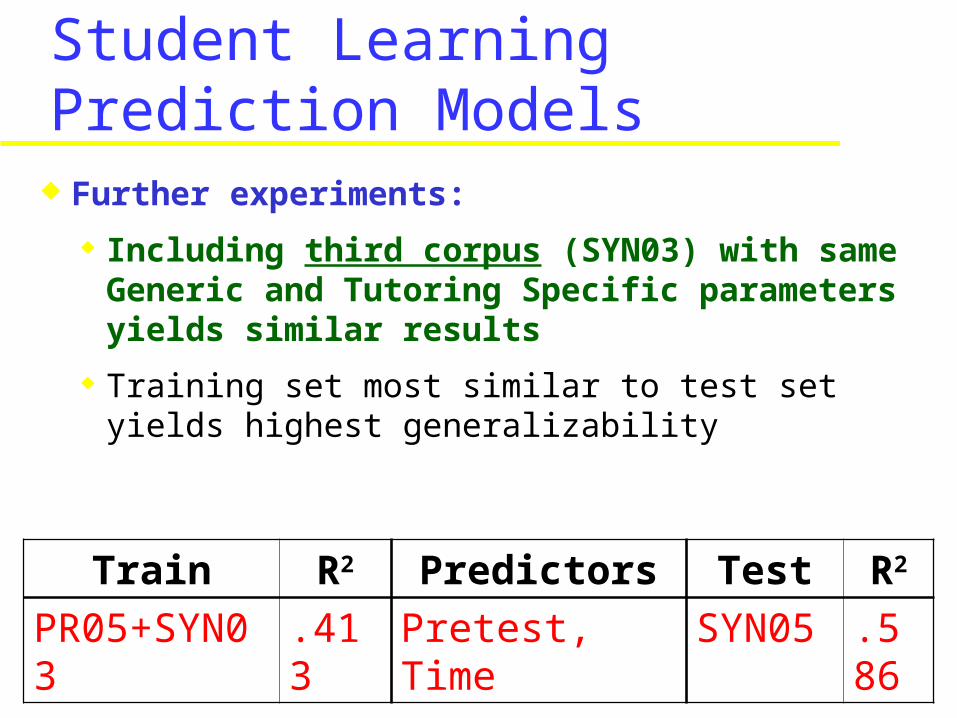
Student Learning Prediction Models Further experiments:
Including third corpus (SYN03) with same Generic and Tutoring Specific parameters yields similar results
Training set most similar to test set yields highest generalizability
Train R2 Predictors Test R2
PR05+SYN03 .413 Pretest, Time SYN05 .586

User Satisfaction Prediction Models Comparison to Prior Work
Some of same parameters also selected as predictors, e.g. in (Walker et al., 2002) (User Words/Turn)
Higher best test results (R2 = .3 - .5) in (Möller, 2005), (Walker et al., 2002) and (Bonneau-Maynard et al., 2000)
Similar sensitivity to changes in training data in (Möller, 2005) and (Walker et al., 2000)

Student Learning Prediction Models First Experiments: (Best Results on Test Data in table)
All models account for ~ 50% of Posttest variance in train and test data; less sensitive to training data changes
Intra-corpus models don’t have higher generalizability
Generic and Tutoring parameters selected
Train R2 Predictors Test R2
PR05 .556 Pretest, %Correct SYN05 .636
SYN05 half #1
.580 Pretest Student Words/Turn
SYN05 half #2
.556


















