
Modeling Intention in Email : Speech Acts, Information Leaks and User Ranking Methods Vitor R....
60
Modeling Intention in Email: Speech Acts, Information Leaks and User Ranking Methods Vitor R. Carvalho Carnegie Mellon University
-
Upload
madison-simon -
Category
Documents
-
view
222 -
download
0
Transcript of Modeling Intention in Email : Speech Acts, Information Leaks and User Ranking Methods Vitor R....

Modeling Intention in Email: Speech Acts, Information Leaks and User Ranking Methods
Vitor R. CarvalhoCarnegie Mellon University

2
Other Research Interests
More details at http://www.cs.cmu.edu/~vitor
Info Extraction & Sequential Learning
IJCAI-05 (Stacked Sequential Learning)CEAS-04 (Extract Signatures and Reply Lines in Email)
Richard Stallman, founder of the Free Software Foundation, declared today…
Scalable Online & Stacked AlgorithmsKDD-06 (Single-pass online learning)NIPS-07 WEML (Online Stacked Graphical Learning)
Keywords for Advertising & Implicit QueriesWWW-06 (Finding Advertising Keywords in WebPages)CEAS-05 (Implicit Queries for Email)

3
Outline
1. Motivation
2. Email Speech Acts Modeling textual intention in email messages
3. Intelligent Email Addressing Preventing information leaks Ranking potential recipients
4. Fine-tuning Ranking Models Ranking in two optimization steps

4
Why Email
The most successful e-communication application. Great tool to collaborate, especially in different time zones. Very cheap, fast, convenient and robust. It just works.
Increasingly popular Clinton adm. left 32 million emails to the National Archives Bush adm….more than 100 million in 2009 (expected)
Visible impact Office workers in the U.S. spend at least 25% of the day on email –
not counting handheld use
[Shipley & Schwalbe, 2007]

5
Hard to manage
People get overwhelmed. Costly interruptions Serious impacts on work productivity Increasingly difficult to manage requests, negotiate
shared tasks and keep track of different commitments
People make horrible mistakes. “I accidentally sent that message to the wrong person” “Oops, I forgot to CC you his final offer” “Oops, Did I just hit reply-to-all?”
[Dabbish & Kraut, CSCW-2006].
[Belloti et al. HCI-2005]

6
Outline
1. Motivation √
2. Email Speech Acts Modeling textual intention in email messages
3. Intelligent Email Addressing Preventing information leaks Ranking potential recipients
4. Fine-tuning Ranking Models Ranking in two optimization steps

7
Example
From: Benjamin Han
To: Vitor Carvalho
Subject: LTI Student Research Symposium
Hey Vitor
When exactly is the LTI SRS submission deadline?
Also, don’t forget to ask Eric about the SRS webpage.
Thanks.
Ben
Request - Information
Reminder - Action/Task
Prioritize email by “intention” Help keep track of your tasks:
pending requests, commitments, reminders, answers, etc.
Better integration with to-do lists

8
Request
Time/date
Add Task: follow up on:
“request for screen shots”
by ___ days before -?
2
“next Wed” (12/5/07)
“end of the week” (11/30/07)
“Sunday” (12/2/07)
- other -

9
Classifying Email into Acts
[Cohen, Carvalho & Mitchell, EMNLP-04][Cohen, Carvalho & Mitchell, EMNLP-04]Verb
Commisive Directive
Deliver Commit Request Propose
Amend
Noun
Activity
OngoingEvent
MeetingOther
Delivery
Opinion Data
Verb
Commisive Directive
Deliver Commit Request Propose
Amend
Noun
Activity
OngoingEvent
MeetingOther
Delivery
Opinion Data
Nouns
Verbs An Act is described as a verb-
noun pair (e.g., propose meeting, request information) - Not all pairs make sense
One single email message may contain multiple acts
Try to describe commonly observed behaviors, rather than all possible speech acts in English
Also include non-linguistic usage of email (e.g. delivery of files)

10
Data & Features Data: Carnegie Mellon MBA students competition
Semester-long project for CMU MBA students. Total of 277 students, divided in 50 teams (4 to 6 students/team). Rich in task negotiation.
1700+ messages (from 5 teams) were manually labeled. One of the teams was double labeled, and the inter-annotator agreement ranges from 0.72 to 0.83 (Kappa) for the most frequent acts.
Features:– N-grams: 1-gram, 2-gram, 3-gram,4-gram and 5-gram– Pre-Processing
Remove Signature files, quoted lines (in-reply-to) [Jangada package] Entity normalization and substitution patterns:
“Sunday”…”Monday” →[day], [number]:[number] → [hour], “me, her, him ,us or them” → [me], “after, before, or during” →
[time], etc

11
Error Rate for Various Acts
5-fold cross-validation over 1716 emails, SVM with linear kernel
[Carvalho & Cohen, HLT-ACTS-06]
[Cohen, Carvalho & Mitchell, EMNLP-04]
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Recall
Pre
cis
ion
1g (1716 msgs) 1g+2g+3g+PreProcess

12
Best features
Ciranda:Java package for Email Speech Act Classification

13
Idea: Predicting Acts from Surrounding Acts
Deliver
Request
Commit
Propose
Request
Commit
Deliver
Commit
Deliver
Act has little or no correlation with other acts of same message
Strong correlation between previous and next message’s acts
Example of Email Thread Sequence
Both Context and Content have predictive value for email act classification
[Carvalho & Cohen, SIGIR-05]
Context: Collective classification problem

14
Collective Classification with Dependency Networks (DN)
• In DNs, the full joint probability distribution is approximated with a set of conditional distributions that can be learned independently. The conditional probabilities are calculated for each node given its Markov blanket.
))(|Pr()Pr( i
ii XBlanketXX Parent
MessageChild Message
Current
Message
Request
Commit
Deliver
… ……
[Heckerman et al., JMLR-00]
[Neville & Jensen, JMLR-07] Inference: Temperature-driven Gibbs sampling
[Carvalho & Cohen, SIGIR-05]

15
Act by Act Comparative Results
37.66
30.74
47.81
58.27
47.25
36.84
42.01
44.98
42.55
32.77
52.42
58.37
49.55
40.72
38.69
43.44
0 10 20 30 40 50 60 70
Commissive
Commit
Meeting
Directive
Request
Propose
Deliver
dData
Kappa Values (%)
Baseline Collective
Kappa values with and without collective classification, averaged over four team test sets in the leave-one-team out experiment.
Modest improvements over the baseline
Only on acts related to negotiation: Request, Commit, Propose, Meet, Commissive, etc.

16
Applications of Email Acts• Iterative Learning of Email Tasks and Email Acts
• Predicting Social Roles and Group Leadership
• Detecting Focus on Threaded Discussions
• Automatically Classifying Emails into Activities
[Kushmerick & Khousainov, IJCAI-05]
[Leusky,SIGIR-04][Carvalho,Wu & Cohen, CEAS-07]
[Feng et al., HLT/NAACL-06]
[Dredze, Lau & Kushmerick, IUI-06]

17
Outline
1. Motivation √
2. Email Speech Acts √ Modeling textual intention in email messages
3. Intelligent Email Addressing Preventing information leaks Ranking potential recipients
4. Fine-tuning User Ranking Models Ranking in two optimization steps

18

19

21
http://www.sophos.com/

22
Preventing Email Info Leaks
1. Similar first or last names, aliases, etc
2. Aggressive auto-completion of email addresses
3. Typos
4. Keyboard settings
Disastrous consequences: expensive law suits, brand reputation damage, negotiation setbacks, etc.
Email Leak: email accidentally sent to wrong person
[Carvalho & Cohen, SDM-07]

23
Preventing Email Info Leaks
1. Similar first or last names, aliases, etc
2. Aggressive auto-completion of email addresses
3. Typos
4. Keyboard settings
[Carvalho & Cohen, SDM-07]
• Method1. Create simulated/artificial email
recipients
2. Build model for (msg.recipients): train classifier on real data to detect synthetically created outliers (added to the true recipient list).
• Features: textual(subject, body), network features (frequencies, co-occurrences, etc).
3. Rank potential outliers - Detect outlier and warn user based on confidence.

24
Preventing Email Info Leaks
1. Similar first or last names, aliases, etc
2. Aggressive auto-completion of email addresses
3. Typos
4. Keyboard settings
[Carvalho & Cohen, SDM-07]
Rec6
Rec2
…
RecK
Rec5
Most likely outlier
Least likely outlier
P(rect)
P(rect) =Probability recipient t is an outlier given “message text and other recipients in the message”.

25
Simulating Email Leaks
Else: Randomly select an address book entry
3
2
1
Marina.wang @enron.comGenerate a random email address NOT in Address Book
• Several options:– Frequent typos, same/similar last names, identical/similar
first names, aggressive auto-completion of addresses, etc.
• We adopted the 3g-address criteria:– On each trial, one of the msg recipients is randomly chosen
and an outlier is generated according to:

26
Data and Baselines
• Enron email dataset, with a realistic setting– For each user, ~10% most
recent sent messages were used as test
– Some basic preprocessing
• Baseline methods:– Textual similarity– Common baselines in IR
• Rocchio/TFIDF Centroid [1971]Create a “TfIdf centroid” for each user in Address Book. For testing, rank according to cosine similarity between test msg and each centroid.
• Knn-30 [Yang & Chute, 1994]Given a test msg, get 30 most similar msgs in training set. Rank according to “sum of similarities” of a given user on the 30-msg set.

28
Leak Results 1
Average Accuracy in 10 trials:
On each trial, a different set of outliers is generated
0.35
0.4
0.45
0.5
0.55
0.6
Random Rocchio KNN-30
Acc
ura
cy
Rocc

29
Using Network Features
1. Frequency features– Number of received, sent and
sent+received messages (from this user)
2. Co-Occurrence Features– Number of times a user co-
occurred with all other recipients.
3. Auto features– For each recipient R, find Rm
(=address with max score from 3g-address list of R), then use score(R)-score(Rm) as feature.

30
Using Network Features
1. Frequency features– Number of received, sent and
sent+received messages (from this user)
2. Co-Occurrence Features– Number of times a user co-
occurred with all other recipients.
3. Auto features– For each recipient R, find Rm
(=address with max score from 3g-address list of R), then use score(R)-score(Rm) as feature.
Combine with text-only scores using perceptron-based reranking, trained on simulated leaks
Network Features
Text-based Feature

31
Email Leak Results[Carvalho & Cohen, SDM-07]
0.406
0.558 0.56
0.804
0.7480.718
0.814
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Leak Prediction
Ac
cu
rac
y .
Random
TfIdf
Knn30
Knn30+Frequency
Knn30+Cooccur1
Knn30+Cooccur_to
Knn30+All_Above

32
Finding Real Leaks in Enron
• How can we find it?– Grep for “mistake”, “sorry” or “accident”– Note: must be from one of the Enron users
• Found 2 good cases:1. Message germany-c/sent/930, message has 20 recipients, leak is
alex.perkins@2. kitchen-l/sent items/497, it has 44 recipients, leak is rita.wynne@
• Prediction results:– The proposed algorithm was able to find these two leaks
“Sorry. Sent this to you by mistake.”,“I accidentally sent you this reminder”

33
Not the only problem
when addressing emails…

34
Sometimes we just…forget an intended recipient
Particularly in large organizations, it is not uncommon to forget to CC an important collaborator: a manager, a colleague, a contractor, an intern, etc.
More frequent than expected (from Enron Collection)– at least 9.27% of the users have forgotten to add a desired email
recipient.– At least 20.52% of the users were not included as recipients
(even though they were intended recipients) in at least one received message.
Cost of errors in task management can be high: Communication delays, Deadlines can be missed Opportunities wasted, Costly misunderstandings, Task delays
[Carvalho & Cohen, ECIR-2008]

35
Data and Features Two Ranking problems:
Predicting TO+CC+BCC Predicting CC+BCC
Easy to obtain labeled data
Features Textual: Rocchio (TfIdf) and KNN Network (from Email Headers)
Frequency # messages received and/or sent (from/to this user)
Recency How often was a particular user addressed in the last 100 msgs
Co-Occurrence Number of times a user co-occurred with all other recipients. Co-occurr
means “two recipients were addressed in the same message in the training set”

36
Email Recipient Recommendation
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
TOCCBCC CCBCC
MA
P
Frequency
Recency
TFIDF
KNN
Perceptron
36 Enron users
[Carvalho & Cohen, ECIR-08]44000+ queries
Avg: ~1267 q/user

37
Intelligent Email Auto-completionTOCCBCC
CCBCC
[Carvalho & Cohen, ECIR-08]

38
Leak warnings: hit x to remove recipient
Timer: msg is sent after 10sec by default
Suggestions:hit + to add
Mozilla Thunderbird plug-in (Cut Once)

39
Outline
1. Motivation √
2. Email Speech Acts √ Modeling textual intention in email messages
3. Intelligent Email Addressing √ Preventing information leaks Ranking potential recipients
4. Fine-tuning User Ranking Models Ranking in two optimization steps

40
Email Recipient Recommendation
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
TOCCBCC CCBCC
MA
P
Frequency
Recency
TFIDF
KNN
Perceptron
36 Enron users

41
Learning to Rank
• Can we do better ranking?– Learning to Rank: machine learning to improve ranking
– Many recently proposed methods:• RankSVM• ListNet• RankBoost• Perceptron Variations
– Online, scalable.
– Learning to rank using 2 optimization steps• Pairwise-based ranking framework
[Elsas, Carvalho & Carbonell, WSDM-08]
[Joachims, KDD-02]
[Cao et al. , ICML-07]
[Freund et al, 2003]

42
Pairwise-based Ranking
)()( jiji dfdfdd
mimiiii xwxwxwddf ...,w)( 2211
Rank q
d1
d2
d3
d4
d5
d6
...
dT
We assume a linear function f
0, jiji ddwdd
Goal: induce a ranking function f(d) s.t.
Constraints:),...,,( 62616 mxxx

43
Ranking with Perceptrons
• Nice convergence and mistake bounds– bound on the number of misranks
• Online, fast and scalable
• Many variants – Voting, averaging, committee, pocket, etc.– General update rule:
– Here: Averaged version of perceptron
][1NRR
tt ddWW
[Elsas, Carvalho & Carbonell, 2008]
[Collins, 2002; Gao et al, 2005]

44
Rank SVM
• Minimizing number of misranks (hinge loss approx.)• Equivalent to maximizing AUC• Lowerbound on MAP, precision@K, MRR, etc.
,2
1min
2
RPi
iranksvmw
CwL
RP
NRRranksvmw
ddwwL ],1[min2
[Joachims, KDD-02],
[Herbrich et al, 2000]
)},{(,1,,0 subject to i NRRiNRR ddRPddw
.2C
1 where,
Equivalent to:
[Elsas, Carvalho & Carbonell, WSDM-08]

45
Loss Function
NRR ddwx ,
-0.5
0
0.5
1
1.5
2
-3 -2 -1 0 1 2 3
Lo
ss
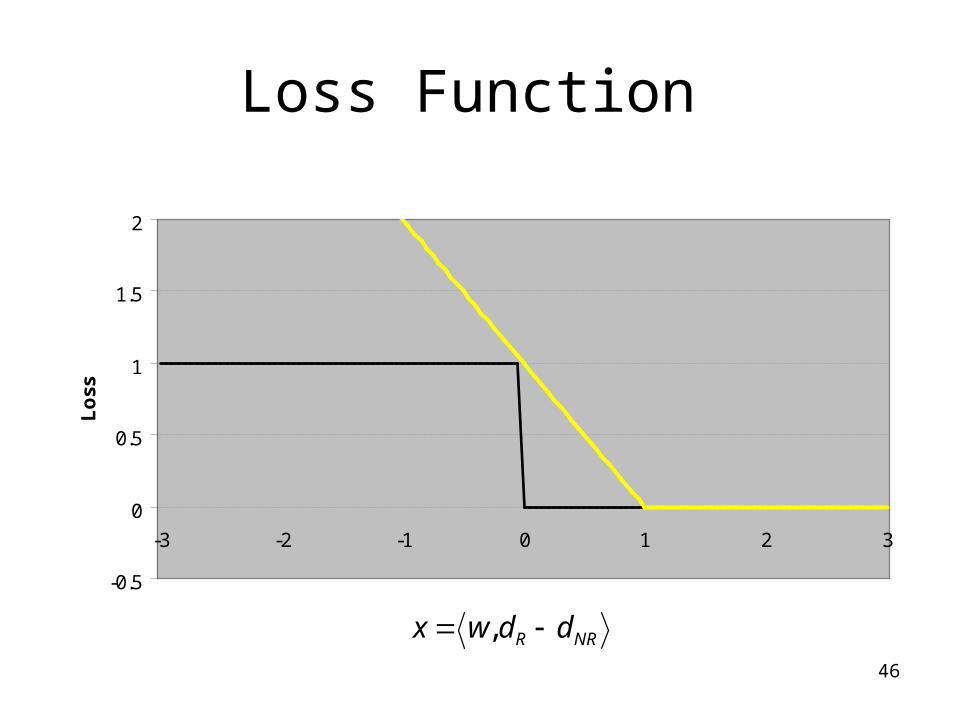
46
Loss Function
NRR ddwx ,
-0.5
0
0.5
1
1.5
2
-3 -2 -1 0 1 2 3
Lo
ss

47
Loss Function
NRR ddwx ,
-0.5
0
0.5
1
1.5
2
-3 -2 -1 0 1 2 3
Lo
ss
)(11
11
1
xsigmoidee
exx
x
Robust to outliers

48
Fine-tuning Ranking Models
Base Ranker
Sigmoid Rank
Non-convex:
Final model
Base ranking model
e.g., RankSVM, Perceptron, ListNet,
etc.
Minimize (a very close approximation for) the empirical error: number of misranks
Robust to outliers (label noise)

49
Learning
• SigmoidRank Loss
• Learning with Gradient Descent
RP
NRRkSigmoidRanw
ddwsigmoidwL )],(1[min2
xexsigmoid
1
1)(
)( )()(
)()()1(
kdrankSigmoi
k
kk
kk
wLw
www
)],(1)[,( 2)( )(NRRNRR
RP
kdrankSigmoi ddwsigmoidddwsigmoidwwL

50
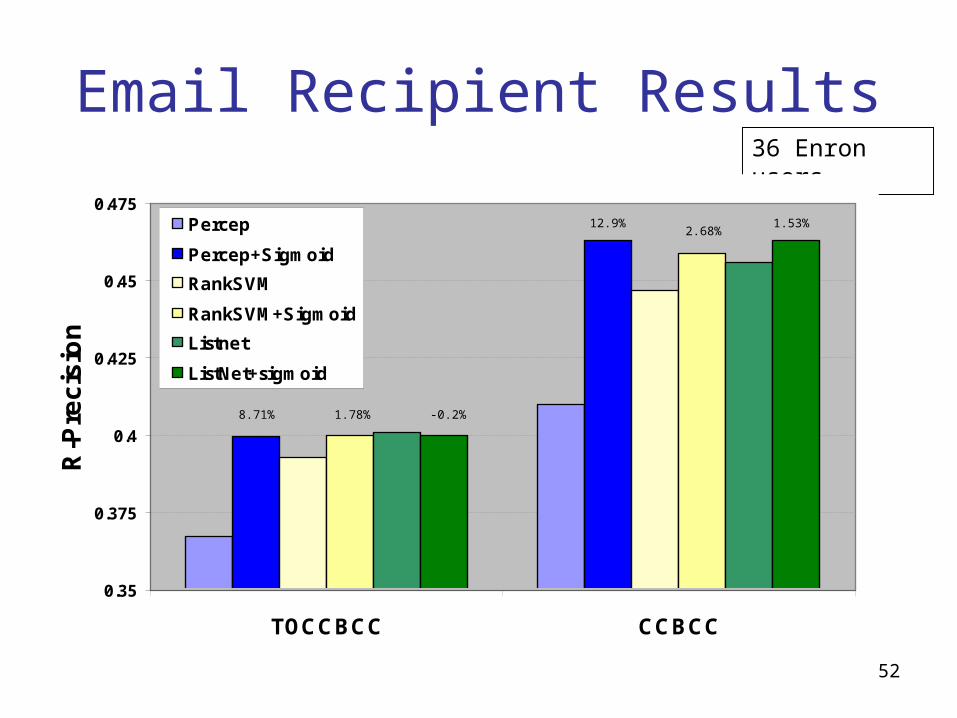
Email Recipient Results
0.3
0.35
0.4
0.45
0.5
0.55
TOCCBCC CCBCC
MA
P
Frequency
Recency
TFIDF
KNN
Percep
Percep+Sigmoid
RankSVM
RankSVM+Sigmoid
Listnet
ListNet+sigmoid
36 Enron users
12.7% 1.69% -0.09%
13.2% 0.96% 2.07%
44000+ queries
Avg: ~1267 q/user
p=0.74p<0.01
p<0.01
p<0.01
p=0.06 p<0.01

51
Email Recipient Results36 Enron users
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
TOCCBCC CCBCC
AU
C
Percep
Percep+Sigmoid
RankSVM
RankSVM+Sigmoid
Listnet
ListNet+sigmoid
26.7% 1.22% 0.67% 15.9% 0.77% 4.51%
p<0.01 p<0.01 p=0.55 p<0.01 p<0.01 p<0.01
52
Email Recipient Results36 Enron users
0.35
0.375
0.4
0.425
0.45
0.475
TOCCBCC CCBCC
R-P
rec
isio
n
Percep
Percep+Sigmoid
RankSVM
RankSVM+Sigmoid
Listnet
ListNet+sigmoid
8.71% 1.78% -0.2%
12.9% 2.68%
1.53%

53
Email Recipient Results
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Perceptron
Pe
rce
ptr
on
+S
igm
oid
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
RankSVM
Ran
kSV
M+
Sig
mo
id
36 Enron users
MAP values
CCBCC task
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.2 0.4 0.6 0.8
ListNet
Lis
tNet
+S
igm
oid

54
Set Expansion (SEAL) Results
0.8
0.82
0.84
0.86
0.88
0.9
0.92
0.94
SEAL-1 SEAL-2 SEAL-3
MA
P
Percep
Percep+Sigmoid
RankSVM
RankSVM+Sigmoid
ListNet
ListNet+Sigmoid
[Wang & Cohen, ICDM-2007]
[18 features, ~120/60 train/test splits, ~half relevant]
1.76% 0.46% 3.22%
2.68% 0.11% 3.20%
1.94% 0.44% 1.81%

55
Letor Results[Liu et al, SIGIR-LR4IR 2007]
[#queries/#features: (106/25) (50/44) (75/44)]
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Ohsumed Trec3 Trec4
MA
P
Percep
Percep+Sigmoid
RankSVM
RankSVM+Sigmoid
ListNet
ListNet+Sigmoid
41.8% 0.38% -0.2%
261% 7.86% 19.5%
21.5% 2.51% 2.02%

56TOCCBCC Enron: user lokay-m
0.82
0.84
0.86
0.88
0.90
0.92
0 5 10 15 20 25 30 35
Epoch (gradient descent iteration)
AU
C (
tra
in)
perceptron+sigmoid
rankSVM+sigmoid
ListNet+sigmoid
Random+sigmoid
Learning Curve
A few steps to convergence- good starting point

57
Sigma Parameter
xexsigmoid
1
1)(
-15
-10
-5
0
5
10
15
0.1 1 2 3 4 5 6 7
sigma parameter ()
M
AP
(%)
Trec3
Trec4
Ohsumed ( x10 )

58
Conclusions
• Email acts• Managing/tracking commits, requests... (semi) automatically
• Preventing User’s Mistakes• Email Leaks (accidentally adding non-intended recipients)• Recipient prediction (forgetting intended recipients)• Mozilla Thunderbird extension
• Ranking in two-optimization steps• Closer approximation minimizing number of misranks
(empirical risk minimization framework)• Robust to outliers (when compared to convex losses)• Fine-tune any base learner in few steps - good starting point

59
Related Work 1• Email acts:
– Speech Act Theory [Austin, 1962;Searle,1969]
– Email classification: spam, folder, etc.– Dialog Acts for Speech Recognition, Machine
Translation, and other dialog-based systems. [Stolcke et al., 2000] [Levin et al., 03]
• Typically, 1 act per utterance (or sentence) and more fine-grained taxonomies, with larger number of acts.
• Email is new domain
– Winograd’s Coordinator (1987) • users manually annotated email with intent.
– Related applications: • Focus message in threads/discussions [Feng et al, 2006], Action-items
discovery [Bennett & Carbonell, 2005], Activity classification [Dredze et al., 2006], Task-focused email summary [Corsten-Oliver et al, 2004], Predicting Social Roles [Leusky, 2004], etc.

60
Related Work 2• Email Leak
– [Boufaden et al., 2005]• proposed a privacy enforcement system to monitor specific
privacy breaches (student names, student grades, IDs).
• Recipient Recommendation– [Pal & McCallum, 2006], [Dredze et al., 2008]
• CC Prediction problem, Recipient prediction based on summary keywords
– Expert Search in Email• [Dom et al.,2003], [Campbell et al,2003], [Balog & de Rijke,
2006], [Balog et al, 2006],[Soboroff, Craswell, de Vries (TREC-Enterprise 2005-06-07…)]

61
Related Work 3• Ranking in two-optimization steps
– [Perez-Cruz et al, 2003] • similar idea for the SVM-classification context (Empirical Risk
Minimization)
– [Xu, Crammer & Schuurman, 2006][Krause & Singer, 2004][Zhan & Shen, 2005], etc.
• SVM robust to outliers and label noise
– [Collobert et al, 2006], [Liu et al, 2005]• convexity tradeoff

62
Thank you.


















