
MLlib and Machine Learning on Spark
32
Apache Spark MLlib and Machine Learning on Spark Petr Zapletal Cake Solutions
-
Upload
petr-zapletal -
Category
Software
-
view
688 -
download
8
Transcript of MLlib and Machine Learning on Spark

Apache Spark
MLlib and Machine Learning on Spark
Petr Zapletal Cake Solutions

Apache Spark and Big Data
1) History and market overview
2) Installation
3) MLlib and Machine Learning on Spark
4) Porting R code to Scala and Spark
5) Concepts - Core, SQL, GraphX, Streaming
6) Spark’s distributed programming model
7) Deployment

Table of contents
● Machine Learning Introduction
● Spark ML Support - MLlib
● Machine Learning Techniques
● Tips & Considerations
● ML Pipelines
● Q & A

Machine Learning
● Subfield of Artificial Intelligence (AI)
● Construction & Study of systems that can learn from
data
● Computers act without being explicitly programmed
● Can be seen as building blocks to make computers
behave more intelligently

Machine Learning

Terminology
● Features
o each item is described by number of features
● Samples
o sample is an item to process
o document, picture, row in db, graph, ...
● Feature vector
o n-dimensional vector of numerical features representing some sample
● Labelled data
o data with known classification results

Terminology

Categories
● Supervised learning
o labelled data are available
● Unsupervised learning
o No labelled data is available
● Semi-supervised learning
o mix of Supervised and Unsupervised learning
o usually small part of data is labelled
● Reinforcement learning
o model is continuously learn and relearn based on the actions and the
effects/rewards from that actions.
o reward feedback

Applications
● Speech recognition
● Effective web search
● Recommendation systems
● Computer vision
● Information retrieval
● Spam filtering
● Computational finance
● Fraud detection
● Medical diagnosis
● Stock market analysis
● Structural health monitoring
● ...
MLlib Introduction
● Spark’s scalable machine learning library
● Common learning algorithms and utilities

Benefits of MLlib
● Part of Spark
● Integrated workflow
● Scala, Java & Python API
● Broad coverage of applications & algorithms
● Rapid improvements in speed & robustness
● Ongoing development & Large community
● Easy to use, well documented
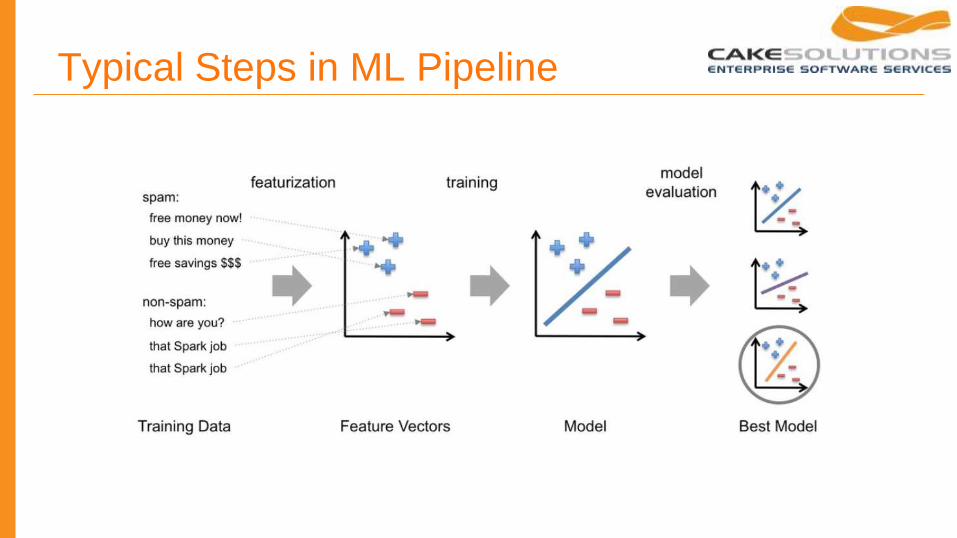
Typical Steps in ML Pipeline

Supported Algorithms

Data Types
● Vector
o both dense and sparse vectors
● LabeledPoint
o labelled data point for supervised learning
● Rating
o rating of a product by a user, used for recommendation
● Various Models
o result of a training algorithm
o used for predicting unknown data
● Matrices

Feature Extraction & Basic Statistics
● Several classes for common operations
● Scaling, normalization, statistical summary, correlation, …
● Numeric RDD operations, sampling, …
● Random generators
● Words extractions (TF-IDF)
o generating feature vectors from text documents/web pages
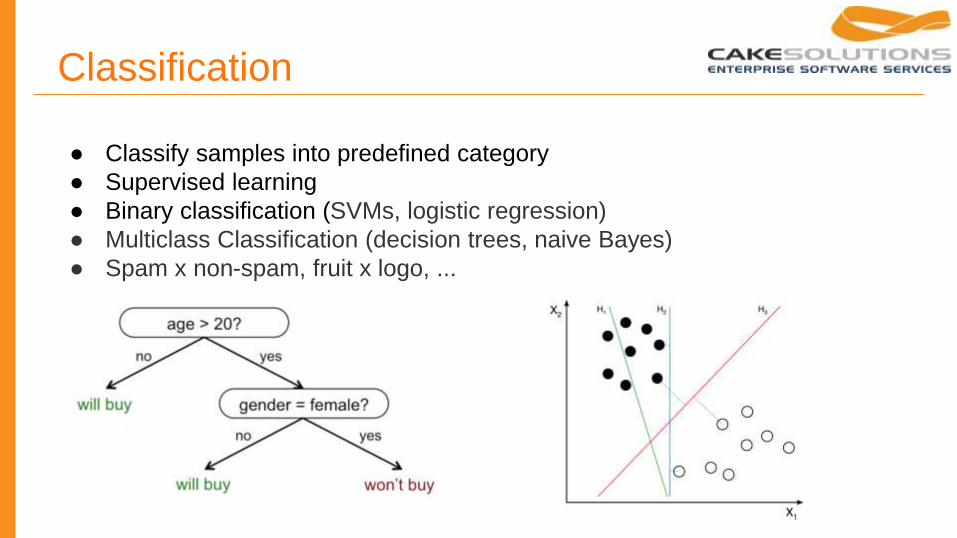
Classification
● Classify samples into predefined category
● Supervised learning
● Binary classification (SVMs, logistic regression)
● Multiclass Classification (decision trees, naive Bayes)
● Spam x non-spam, fruit x logo, ...
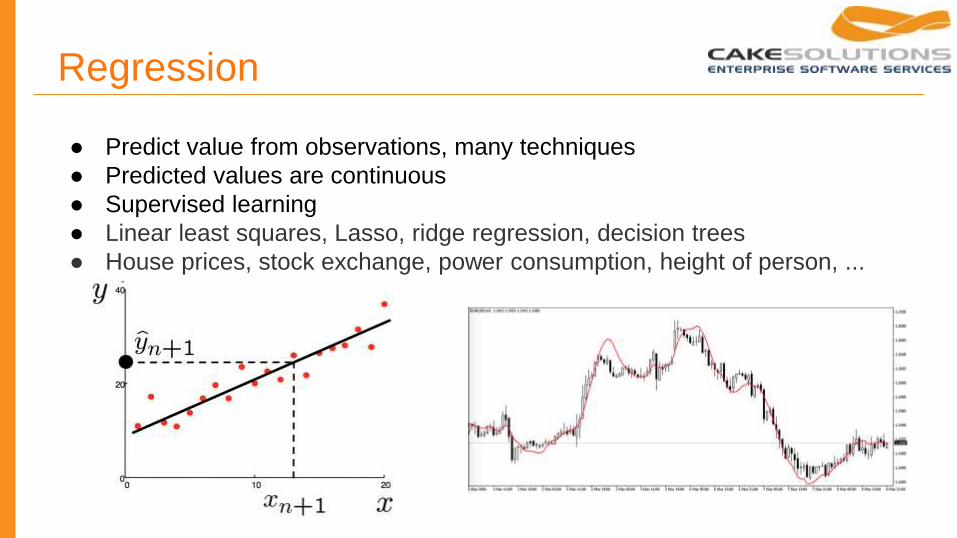
Regression
● Predict value from observations, many techniques
● Predicted values are continuous
● Supervised learning
● Linear least squares, Lasso, ridge regression, decision trees
● House prices, stock exchange, power consumption, height of person, ...

Linear Regression Example
● Method run trains model
● Parameters are set with setters setNumInterations and setIntercept
● Stochastic Gradient Descent (SGD) algorithm is used for minimizing function
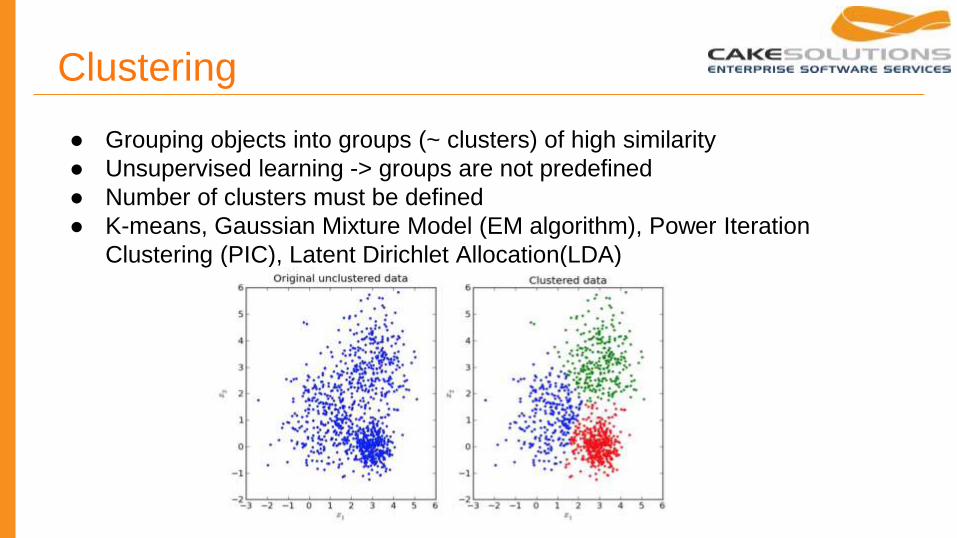
Clustering
● Grouping objects into groups (~ clusters) of high similarity
● Unsupervised learning -> groups are not predefined
● Number of clusters must be defined
● K-means, Gaussian Mixture Model (EM algorithm), Power Iteration
Clustering (PIC), Latent Dirichlet Allocation(LDA)

Collaborative Filtering
● Used for recommender systems
● Creates and analyses matrix of ratings, predicts missing entries
● Explicit (given rating) vs implicit (views, clicks, likes, shares, ...) feedback
● Alternating least squares (ALS)

Dimensionality Reduction
● Process of reducing number of variables under consideration
● Performance needs, removing non-informative dimensions, plotting, ....
● Principal Component Analysis (PCA) - ignoring non-informative dims
● Singular Value Decomposition (SVD)
o factorizes matrix into 3 descriptive matrices
o storage save, noise reduction

Tips
● Preparing features
o each algorithm is only as good as input features
o probably the most important step in ML
o correct scaling, labeling for each algorithm
● Algorithm configuration
o performance greatly varies according to params
● Caching RDD for reuse
o most of the algorithms are iterative
o input dataset should be cached (cache() method) before passing into
MLlib algorithm
● Recognizing sparsity
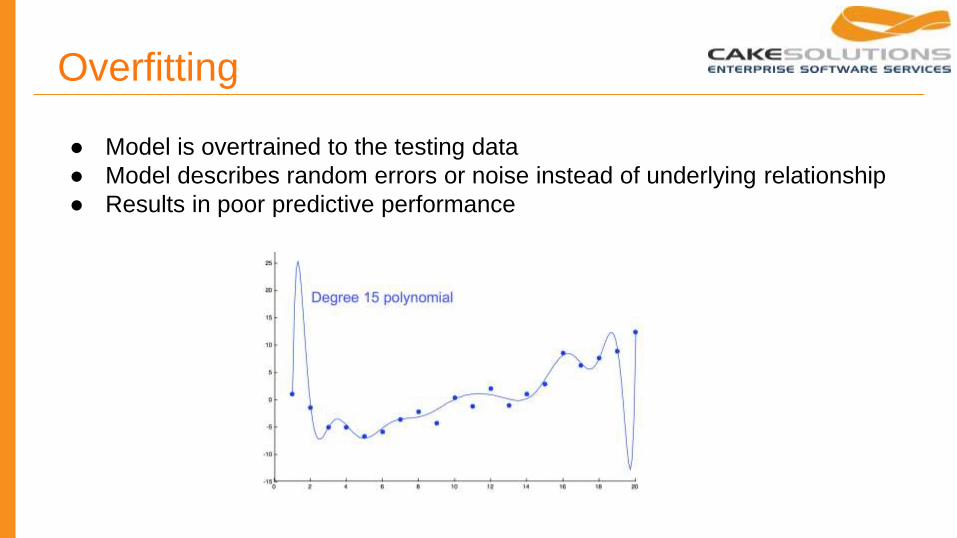
Overfitting
● Model is overtrained to the testing data
● Model describes random errors or noise instead of underlying relationship
● Results in poor predictive performance

Data Partitioning
● Supervised learning
● Partitioning labelled data
● Labelled data
o Training set
set of samples used for learning
experiments with algorithm parameters
o Test set
testing fitted model
must not tune model any further
● Common separation - 70/30

Performance
● 10-100x faster than Hadoop & Mahout
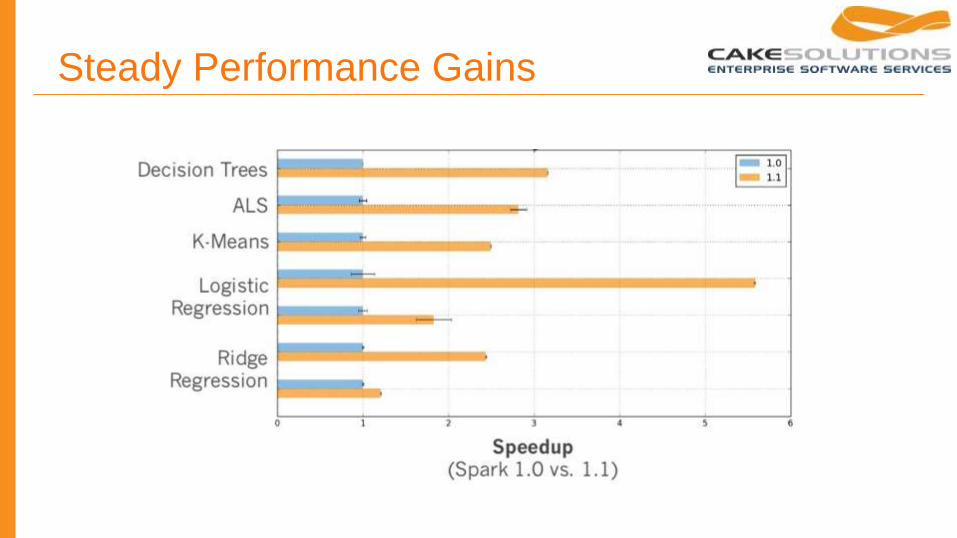
Steady Performance Gains
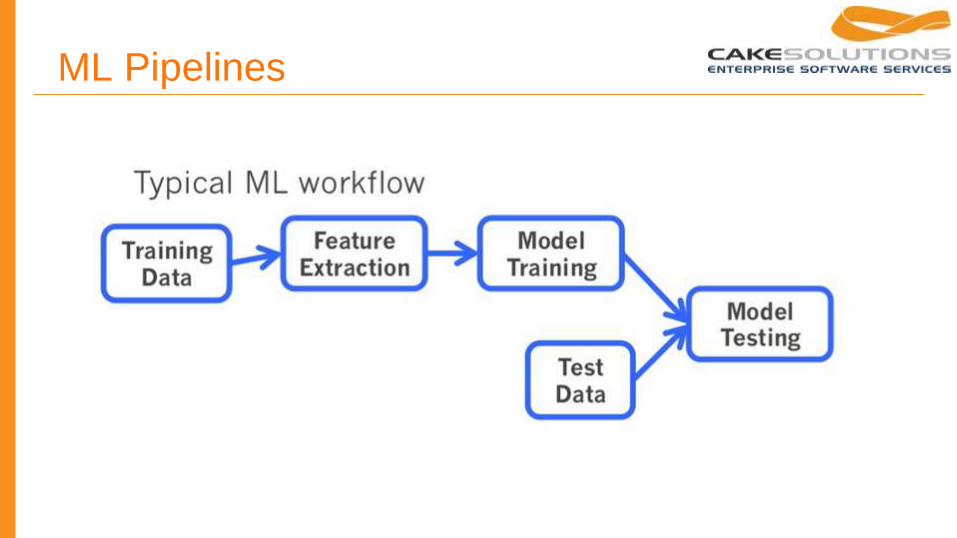
ML Pipelines
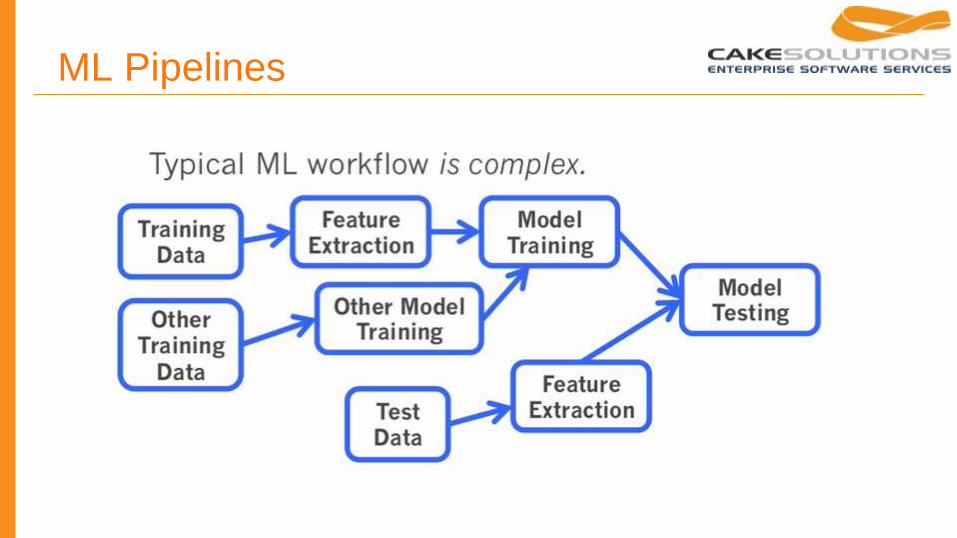
ML Pipelines
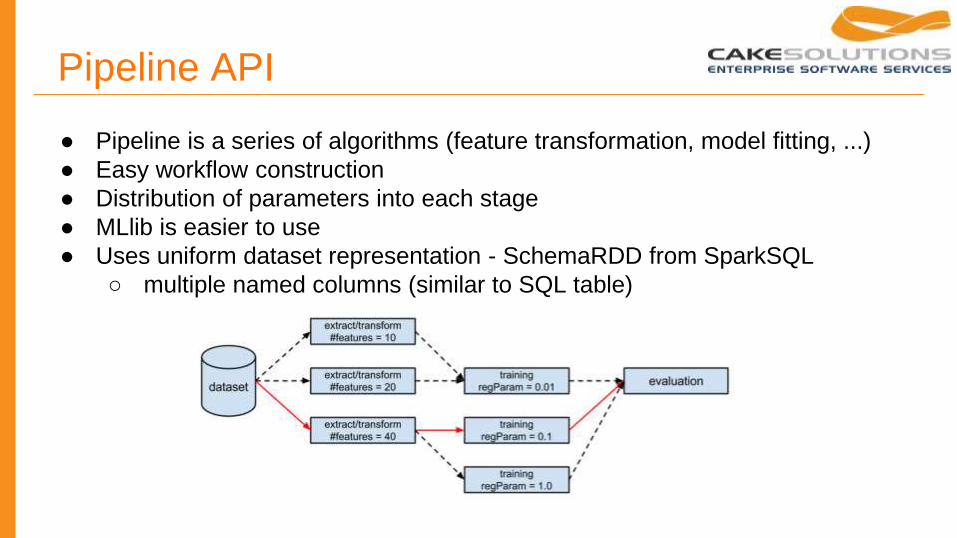
Pipeline API
● Pipeline is a series of algorithms (feature transformation, model fitting, ...)
● Easy workflow construction
● Distribution of parameters into each stage
● MLlib is easier to use
● Uses uniform dataset representation - SchemaRDD from SparkSQL
○ multiple named columns (similar to SQL table)

Demo

Conclusion
● What is Machine Learning
● Machine Learning Use Cases & Techniques
● Spark’s Machine Learning library - MLlib
● Tips for using MLlib and Spark

Questions









![Automated Machine Learning Using Spark Mllib to Improve Customer Experience-(Sourabh Chaki, [24]7](https://static.fdocuments.net/doc/165x107/55cc97bcbb61eb003d8b47ba/automated-machine-learning-using-spark-mllib-to-improve-customer-experience-sourabh.jpg)








