Missing Data Analysis with SPSS - EHE RMC @ OSU...Missing Data Analysis with SPSS Meng-Ting Lo...
92
Missing Data Analysis with SPSS Meng-Ting Lo ([email protected]) Department of Educational Studies Quantitative Research, Evaluation and Measurement Program (QREM) Research Methodology Center (RMC)
Transcript of Missing Data Analysis with SPSS - EHE RMC @ OSU...Missing Data Analysis with SPSS Meng-Ting Lo...

Missing Data Analysis with SPSS
Meng-Ting Lo ([email protected])
Department of Educational Studies Quantitative Research, Evaluation and Measurement Program (QREM)
Research Methodology Center (RMC)

2
Outline • Missing Data Patterns and Mechanisms • Traditional Techniques
• Listwise and pairwise deletion
• Mean substitution
• Regression and stochastic regression
• Hot deck imputation
• Averaging the available items
• Last observations carried forward
• Maximum Likelihood (ML) and Multiple Imputation (MI) • SPSS with Multiple Imputation (demonstration and practice) • Practical Issues/ Myths

3
• High school longitudinal study of 2009: public-use data NCES secondary longitudinal studies, more than 21,000 9th graders in
944 schools
Hsls09_MissingDataWorkshop_demo
Hsls09_MissingDataWorkshop_demo2_imputed5
Hsls09_MissingDataWorkshop_demo2_IterationHistory
Hsls09_MissingDataWorkshop_practice
• SPSS modules Missing Value Analysis
Multiple Imputation
Data and Material

4
The importance of dealing with missing data
• Rarely see a dataset that is complete and beautiful
• Traditional techniques rely on strict assumption about
missing data mechanisms (rarely be achieved in real world)
• The problem of missing data:
• Treat it inappropriately, obtain unreliable and biased estimates,
make incorrect conclusion of results
• Reduce the statistical power of your test to detect a significant effect
(e.g., listwise deletion)

5
Missing data patterns
“Where” is the missing data in your data set? Describing the location of missing data (shaded area). In old time: specific missing data handling methods were developed to deal with different missing data patterns. Now: MI and ML work well in any missing data patterns.
Figures from p.4 in Enders, C. K. (2010). Applied missing data analysis.
Guilford Press.
1
2
3
4
.
.
.
.

6
Missing data mechanisms (Donald Rubin, 1976) “Describe the relationships between measured variables and the probability of missing data and essentially function as assumptions for missing data analysis (Enders, 2010, p.2).”
• Missing complete at random (MCAR), Missing at random (MAR), and Missing not at random(MNAR)
• “Why data are missing?” Possible explanation for missing data and find evidence to justify our claim.
• Missing data mechanisms are much important than percentage of missing. • Percentage of missing is to know the scope of missing data problem.
• It governs the performance of different analytic techniques.

7
Introduced by Rubin (1976), missingness is a binary variable that has a probability distribution
Race: complete observed
DV: missing for some students
R: missing data indicator
Whether the probability of missing data on a variable (R) is related to other variables in the dataset?
missing
observed
Race
DV: Reading
Achievement R
Asian 0
Asian 0
Caucasian 0
Asian 0
Asian 0
Caucasian 66 1
Caucasian 88 1
Caucasian 95 1
Caucasian 100 1
Asian 86 1
Asian 56 1
Caucasian 78 1
Missing data mechanisms
The relationship between probability of missingness and other variables in the dataset is then used to determine the missing data mechanisms.

8
Missing not at random (MNAR)
“The probability of missing data on a variable Y is related to the values of Y itself, even after controlling for other variables (Enders, 2010, p.8).”
Example:
• There is no way to verify whether data is MNAR without knowing the actual values of Y. • In some situation, you may have some sense about the actual values
if you are in the field monitoring data collection process.
• Needs to use other techniques to handle missing data.

9
Missing at Random (MAR)
“The probability of missing data on a variable Y is related to some other measured variable(s), but not to the values of Y itself (Enders, 2010, p.6).”
Example:
• Because we do not know the actual value of Y… • Theoretical judgement about MAR by providing evidence.
• ML and MI assume MAR.

10
Missing Complete at Random (MCAR) “The probability of missing data on a variable Y is unrelated to other measured variables and is unrelated to the values of Y itself (Enders, 2010, p.7).”
Example:
• Observed data are just a simple random sample of the hypothetically complete dataset.
• Find some evidence for MCAR. • For example, comparing cases with missing and without missing of a variable on
other measured variables, two groups should not have differences!

11
Finding evidence for MCAR or MAR: t-test Preforming a series of independent sample t-test to compare a group with missing and a group without missing on the mean of other variables in the dataset (categorical data, chi-square).
Self-
efficacy
DV: Reading
Achievement R
5 0
1 0
2 0
4 0
2 0
5 66 1
3 88 1
4 95 1
3 100 1
2 86 1
4 56 1
5 78 1
• Available in SPSS Missing Values
Analysis module
• No sig difference implies MCAR
• A sig difference implies MAR (good)
• A good way to identify variables that is
related to missingness, which can be
used in MI (provide information to
impute missing value)

12
Testing the MCAR: Little (1998)’s MCAR Test • Multivariate extension of the t-test approach: perform all t-tests
simultaneously.
• A global test of MCAR, available in SPSS Missing Values Analysis module under EM procedure.
• Testing the Null hypothesis: the data is MCAR. Significant MCAR test and/or significant t-tests = an indication of MAR.
• Issues: (1) Do not identify variables that violate MCAR.
(2) Low statistical power (type II error) when the number of variables that violate MCAR is small or weak relationship between missingness and data.

13
Traditional methods for handling missing data
• Listwise deletion
• Pairwise deletion
• Mean substitution
• Regression and Stochastic regression
• Hot deck imputation
• Averaging available items
• Last observation carried forward

14
Listwise Deletion (complete-case analysis)-include only cases with complete data • Easy, convenient, available in all statistical software
• Waste data and resources
• Reduce sample size and statistical power
• Assume MCAR (otherwise produce biased estimates)

15
Listwise Deletion (complete-case analysis)
Problems :
1. The remaining cases do not represent the entire sample well
2. Higher mean estimate
3. Reduce the variability of data
GPA Complete data Listwise deletion
Mean 3.19 3.51
Var 0.76 0.67
Assume MAR for this example data

16
Pairwise Deletion (available-case analysis)- analyses (e.g., correlation, regression) are conducted based on different subset of cases
• Assume MCAR
• Correlation r= 𝜎𝑋𝑌
𝜎𝑥2𝜎𝑦2
Estimation problem: r >1 or < -1
• Lack of consistent sample size: using different subsets of cases to estimate parameters, difficult to compute standard errors
1. Cases with complete
data for X&Y
2. Use cases having x or
y alone (separate
subsample)
50.01

17
Arithmetic Mean Imputation (mean substitution): using the mean of the available cases to fill in the missing value
• Y has some missing , replace the missing value for Y with the mean of Y calculated from cases without missing on Y. • Reduce variability of the data and correlations. • Severely bias the parameter estimate, even MCAR.
X Y
169 148
126
132
160 169
105
116
125
112
133
94
109
109
106
176 137
128
131
130
145 155
136
146 134
111
97
134
153 112
118
137
101
103
78
151 113
Schafer &Graham (2002)

18
Regression Imputation (conditional mean imputation): using the predicted scores from a regression equation of the complete cases to fill in the missing value
• Predicted score of Yi*=𝛽 0+𝛽 1X
• Reduce variability, overestimate correlations between variables and 𝑅2, even MCAR.
Schafer &Graham (2002)

19
• Predicted score of Yi*=𝛽 0+𝛽 1X+ Zi
• Adding residual terms to the predicted values: restore the variability to the imputed data and eliminate biases.
• Provide unbiased estimates under MAR just like ML and MI! But…attenuate the standard error, inflate type I error rate.
Stochastic Regression Imputation: using the predicted scores from a regression equation of the complete cases to fill in the missing value + normally distributed error term N~(0,𝝈𝟐)
Schafer &Graham (2002) Schafer &Graham (2002)

20
• Procedure: some respondents did not report their income, classified respondents into cells (groups) based on their demographic information such as age, gender, marital status; randomly draw an income value from similar respondents
Hot-Deck imputation: impute the missing values from
similar respondents
• Reduce variability to some extent, produce biases on correlation estimates and regression coefficients.
Schafer &Graham (2002)

21
• Researchers typically compute a scale score by summing or averaging the item responses that measure the same construct. • For example, 5 items measuring well-being, a respondent answered
3 items but not all of the items, her/his scale score would be the average of those 3 items.
• “Person mean substitution”
• Potential problem : Cronbach’s alpha is incorrect, may bias
the variance and correlation.
• Use with caution, especially with high rate of item nonresponses.
• ML and MI are better approaches.
Averaging the available items (multiple-item questionnaire)

22
• Replace the missing value with the observation that immediately before dropout.
• Assume the scores do not change from the previous measurement.
• Likely to produce biased estimate, even when data are MCAR.
Last observation carried forward: longitudinal designs
Observed data
ID W1 W2 W3 W4
1 50 51
2 46 48 50
3 24 55 56
Observed data
ID W1 W2 W3 W4
1 50 51
2 46 48 50
3 24 55 56
51 51
46
56

23
Recommended methods for handling missing data
• Maximum likelihood method (full information maximum likelihood, FIML)
• Multiple imputation

24
Why FIML or Multiple imputation (MI)?
• Traditional methods have its own limitation and some of them have strict assumption about missing data mechanisms.
• Provides you with better and more trustworthy parameter estimates.
• Make the conclusion about your statistical test more appropriately.
• Allow you to have rigor on your study.

25
Full information maximum likelihood (FIML)
• Assume MAR and multivariate normality data.
• Implemented in structural equation modeling program such as Mplus (default) when the outcome is continuous.
• When used in the missing data context, using all the information in the dataset to directly estimate the parameters and standard errors; handling missing data in one-step.
• Does not drop any cases with missing values.
• Does not produce imputed datasets.
• FIML reads in the raw data of one case at a time, and maximizes the ML function for one case at a time.

26
Full information maximum likelihood (FIML)
• “The computations for a case use the information only from the variables and the corresponding parameters for which the case has complete data (Enders, 2010, p.89)”. • Implies: depending on the missing data pattern for that case, the
computations differ slightly (the ML function is customized to different missing data pattern).
• Involving iterative processes, each time using different estimates of the parameters, until it finds a set of parameter values that maximize the likelihood function (Enders, 2010). • i.e., maximize the probability of observing the data, find a model that best
fit the data.
• ML converges: The parameter estimates no longer change across successive iterations.

27
Full information maximum likelihood (FIML)
0 100
An iterative process: putting the distribution in all possible locations until the program finds a place where the distribution with a set of parameters that best fit the data (have the highest probability /likelihood of observing the data).
Reading achievements

28
Multiple imputation (MI) • Assume MAR, also called multiple stochastic regression
imputation (iterative procedure). • Available in Mplus, SAS, Stata, Blimp, SPSS, R and other. • Involves three steps:
A dataset with
missing
data
Imputed dataset 1
Imputed dataset 2
Imputed dataset m
Results 1
Results 2
Results m
Pooled
(overall)
results
Imputation Phase Analysis Phase Pooling Phase

29
SPSS uses fully conditional specification (FCS) or chained equations imputation, multivariate imputation by chained equations (MICE) (a Markov Chain Monte Carlo algorithm) • Does not rely on the assumption of multivariate normality.
• Flexible in handling different types of variables.
Scale: linear regression
Categorical: logistic regression
• Specify the imputation model on a variable-by-variable basis.
“For each variable with missing data, a univariate (single dependent variable) imputation model is fitted using all other available variables in the model as predictors, then imputes missing values for the variable being fit “(IBM SPSS Missing Values 24).
Multiple imputation- imputation phase
ID Age Income Gender
1 35 0
2 5000 1
3 45 10000 0
4 20 1
5 18 4500

30
• The imputation process goes through all variables with missing value iteratively, every time with new/updated imputed values.
• When the maximum number of iterations is reached (specified by researchers or by default), the imputed values at the maximum iteration are saved (one imputed dataset is created).
Request 5 imputations with 200 maximum iterations = SPSS runs the MCMC algorithm 5 times and save the imputed values at 200th iteration each time.
Generally, 5-10 iterations is sufficient, but recommended to be conservative.
You may need to increase the number of iterations if the model hasn't converged (save iteration history data in SPSS and plot it to assess convergence).
Multiple imputation- imputation phase
Age Income Gender
This process is repeated for several times

31
Multiple imputation – imputation phase What variables should be included in the imputation model? • (1) “At least” the variables that you are going to use in the
subsequent analysis should be included. • For example, run a regression model and use gender, SES to predict
freshman’s GPA. Gender, SES, and GPA should be included in the imputation model.
• (2) Include auxiliary variables: “variables are either correlates of
missingness or correlates of an incomplete variable” (Enders, 2010, p.17); these variables may not the study interest, but help improving the imputation quality and increasing the “plausibility of MAR”.
• For example, there are other variables such as parents’ education level, ACT, SAT, and other variables in the datasets which are correlated with variables of interest or their missingness.

32
Multiple imputation – imputation phase How many imputed datasets are needed? • There are strong associations between statistical power and
number of imputations.
• Convention wisdom: 3-5 imputed datasets; however, study showed that with only 3 or 5 imputed datasets, the power is below its optimal level (Graham et al., 2007).
• According to Enders (2011), “generating a minimum of 20 imputed datasets seems to be a good rule of thumb for many situations“.
• If the proportion of missing data is > 50% , increasing the # of imputations > 40 and be thoughtful about the variables included in the imputation model.

33
Multiple imputation – analysis phase
• The imputation phase generate m set of imputed datasets.
• The analysis phase: analyze the imputed datasets using the normal analysis procedure. • For example, a researcher generates 20 datasets and now would
like to use multiple regression to analyze the data. She/he will repeat multiple regression analysis 20 times, one analysis for each of the datasets.
Dataset1 Dataset2
Paramter β SE Paramter β SE
Intercept 2.62 3.41 Intercept 2.18 3.2
SES 1.81 1.6 SES 1 1.9

34
Multiple imputation – pooling phase
• Pooling point estimate: 𝜽 =
1
𝑚 𝜃 𝑡
𝑚
1
m= # of imputed datasets
𝜃 𝑡= parameter estimate for t dataset • Take an average of the parameter
estimates across m datasets
• Pooling standard errors:
𝑽𝑻 = 𝑉𝑊 + 𝑉𝐵 +
𝑉𝐵
𝑚 ; SE= 𝑽𝑻
𝑉𝑇= total sampling variance
𝑉𝑊=within-imputation variance
(the mean of the squared SE across m datasets)
𝑉𝐵= between-imputation variance
(variability of parameter estimate across m
datasets; additional variance that is due to
missing)
𝑉𝐵
𝑚 = correction factor for a finite number
of imputation
The statistical significance of the 𝜽 can be calculated in the usual way by
calculating the ratio 𝜽 / 𝑉𝑇

35
Using SPSS to
Deal with Missing Data

36
• High school longitudinal study of 2009: public-use data NCES secondary longitudinal studies, more than 21,000 9th graders in
944 schools
• Selected sample: subsample of 500 students who took math and science course in 2009
• Selected measures: 9th grade sex (0=male), race/ethnicity (0=white), socioeconomic
status
9th and 11th grade math IRT scores
9th grade math interest (3 items; 4 point Likert scale)
9th grade math self-efficacy (4 items; 4 point Likert scale)
The example data
Demonstration dataset: Hsls09_MissingDataWorkshop_demo

37
• Delete cases with no data on any of the variables.
• All missing values need to be displayed as system missing (a blank cell) or user-defined missing (a value assigned by researcher, such as 999 or -8888).
Using SPSS to deal with missing data

38
• Change all missing values (either system missing or user-defined missing value) to a common value -999.
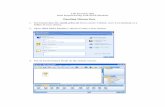
• Transform-> click Recode into Same Variables -> Select all of the variables into the selection box-> click Old and New Values->
Using SPSS to deal with missing data
-999
1
2
3
4

39
• Assign missing values for all the variables: In Variable View -> Click on one cell in the Missing column to assign -999 as a discrete missing value -> Click OK.
• Right click Copy -> Select all cells with numeric variables --- Click Paste.
Using SPSS to deal with missing data

40
• Define variables : In Variable View -> Under Measure column -> assign the scale for each of the variables.
Using SPSS to deal with missing data

41
• Analyze the pattern of missing data: Go to Analyze -> Multiple Imputation - > Analyze Patterns Select the variables excluding the ID to Analyze Across Variables For Minimum percentage missing for variable to be displayed, change to 0 -> Click OK (would like to see everything that is missing)
Using SPSS to deal with missing data

42
Using SPSS to deal with missing data
Variables: the number of variables which contained missing values= 9 out of 12 (green) Cases: 409 cases have complete data (81.8%) (blue) ; 91 cases have at least one missing value on a variable Values: the number of individual values (out of 6000=12*500) that are missing = 110 (1.83%) (green)
Only 1.83% of the individual values are missing.

43
Using SPSS to deal with missing data
The number and percent missing for each variable.
Examine the percentage of missing for each variable, make sure that each percent missing makes sense based on your knowledge about this dataset!
Notice, the variables are ordered by the amount of values they are missing (i.e. the percentage missing).

44
Using SPSS to deal with missing data
• Each pattern (row) reflects a group of cases with the same pattern of missing values (15 patterns of missing and nonmissing data)
• The variables along the bottom (x-axis) are ordered by the amount of missing values each contains.
• The percent missing for the 10 most common patterns
• Pattern 1 = no missing (81%) is the most prevalent pattern.
• Pattern 10= missing on MATH11 (10%)
The pattern here is arbitrary.
least highest

45
• Request Little’s MCAR test and independent sample t-tests for MAR Go to Analyze --- Missing Value Analysis-->
Using SPSS to deal with missing data
Descriptive: Report Student t-
test for each pair of continuous
variables to examine MAR

46
• Request Little’s MCAR test and Separate Variance t tests Go to Analyze --- Missing Value Analysis
Using SPSS to deal with missing data
A note: If you get a warning message in the SPSS output that the EM algorithm failed to converge in 25 iterations, you can increase the maximum iterations by clicking on the EM button.

47
• Request Little’s MCAR test and Separate Variance t-tests
Using SPSS to deal with missing data
Scroll down in the SPSS Output window to the EM Means table: Under this table, you can find the result from Little’s MCAR test. Non- significant results at p = .054 indicate the data are missing completely at random (MCAR).

48
Examine independent sample t-tests
A significant t-test indicates the probability of missing is a function of the values on another variables. It’s an indication of MAR! We have variables that can be used in the imputation model.

49
• Research Question: Can students’ SES and math self-efficacy predict their 11th grade math score ?
• Dependent Variable: MATH11
• Independent Variables: SES and EFF_total (sum of 4 items)
• Auxiliary variables (for imputation): SEX, RACE, MATH09, Math interest items • Correlation analysis: these variables are correlated with variables of
interest to some extent
• Independent sample t-test: some of them are correlated with missingness for variables of interest
Analysis model

50
Before imputation, set a random seed Transform-> Random Number Generators -
> select Set Active Generator-> click
Mersenne Twister -> select Set Starting
Point and Fixed Value -> click OK.

51
• Conducting multiple imputation: Analyze-> Multiple Imputation-> Impute Missing Data Values-> Move the variables of interest to the Variables in Model box.
Using SPSS to deal with missing data

52
Variables-> • 5 imputations will
be implemented for demonstration purpose
• Missing value will be imputed 5 times and stored
• Name the dataset
below the Create a new dataset button

53
• PMM: still uses regression, but the imputed values are adjusted to match the nearest actual value in the dataset (from observations with the same predicted value with no missing on that variable).
• If the original variable is bounded by 0 and 40, the imputed values will also be bounded by 0 and 40.
• According to Paul Allison, there are some drawbacks of PMM in SPSS. https://statisticalhorizons.com/predictive-mean-matching
Method-> • Since the missing
data pattern is arbitrary, selecting FCS
• Specify the number of maximum iterations = 200
Default =10; Increase the number of iterations if the Markov Chain Monte Carlo algorithm hasn't converged.

54
Constraints-> • Click on Scan Data: examine
the variable summary
• You can specify the role of a variable during the imputation and constraint the range of imputed values (min, max, rounding) so that they are plausible
• Obtain integer values = specify 1 as the rounding denomination (6.648->7); obtain values rounded to the nearest cent, specify 0.01 (6.648->6.65)
This column allows you
to specify the smallest
denomination to accept.
1
2 3

55
Constraints-> • If specify the Min and Max:
Maximum draw procedure will be activated: it attempts to draw values for a case until it finds a set of values that are within the specified ranges
• Errors: if a set of values within the ranges is not obtained • Increase the maximum
draws
• Demonstration: no constraints on the range of variables

56
• Imputation model: univariate model type, model effects, and # of values imputed
• Descriptive statistics: basic information before and after imputation
• Iteration history: information on the convergence performance

57
Outputs
Hsls09_MissingDataWorkshop_demo2_imputed5

58
• Datasets with imputed values are numbered 1 through M, where M is the number of imputations.
• Select the
imputation from the drop-down list in the edit bar in Data view.

59
You can distinguish imputed values from observed values by cell background color.

60
• Compute the
scale score (composite score) for self-efficacy in the stacked dataset
• This would apply
to all the imputed datasets
Create composite score: Transform-> Compute Variable

61
• Split the file by
imputation number
• This invokes the
analysis and pooling phase for multiple imputed datasets
Before the analysis: Data-> Split file

62
• SPSS provides pooled estimate for some analyses but not all…
• Analyses with this icon, indicating that SPSS provides corresponding procedure to accommodate multiple imputed datasets
• Let’s perform a multiple regression
Analyze data as usual

63
SPSS outputs for multiple regression-descriptive statistics

64
SPSS outputs for multiple regression- correlation matrix

65
Coefficientsa
Imputation Number Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig.
Fraction
Missing Info.
Relative
Increase
Variance
Relative
Efficiency B Std. Error Beta
Original data 1 (Constant) 45.446 3.777 12.031 .000
X1 Socio-economic
status composite
8.626 1.072 .356 8.046 .000
EFF_total 1.879 .315 .264 5.967 .000
Pooled 1 (Constant) 44.126 3.734 11.818 .000 .158 .174 .969
X1 Socio-economic
status composite
9.242 1.019
9.073 .000 .087 .091 .983
EFF_total 1.901 .309 6.146 .000 .130 .141 .975
a. Dependent Variable: X2 Mathematics IRT-estimated number right score
SPSS outputs for multiple regression- coefficient estimates
• Results differ slightly across imputed datasets • SPSS provides pooled estimate for unstandardized regression coefficients!

66
Imputation Diagnostics

67
SPSS outputs for multiple regression- coefficient estimates
• Fraction missing info: The proportion of total sampling variance that is
due to missing data (𝑉𝐵 +𝑉𝐵
𝑚 )/ 𝑉𝑇 for a parameter estimate, related to
percentage missing for that variable. • 0.087 for SES: 8.7% of the sampling variance is due to missing data • A measure of the impact of missing data on parameter estimates

68
SPSS outputs for multiple regression- coefficient estimates
• Relative Increase Variance: how much the sampling variance would be
increased (inflated) because of missingness (𝑉𝐵 +𝑉𝐵
𝑚 )/ 𝑉𝑤.
• 0.141 for EFF_total: compared to the sampling variance for EFF_total assumed it has complete data, the estimated sampling variance for EFF_total (with missing) is 14.1% larger.
• Variables with larger percentage missingness tend to have larger relative increase variance.

69
SPSS outputs for multiple regression- coefficient estimates
• Relative efficiency: it is an efficiency estimate from m imputations relative to performing an infinite number of imputations 1/(1+F/M), where F= Fraction missing info, M= # of imputation. • Close to 1 = more efficient, produce proper
SE (won’t produce too large SE) • Large percentage of missing needs more
imputations to achieve sufficient efficiency for parameter estimates
SAS documentation for multiple imputation
(Horton & Lipsitz, 2001, p. 246)
(fraction of missing info)
The SE got from infinite # of imputations is
98.3% of SE got from 5 imputations

70
Iteration history: Provides mean and standard deviation by iteration and imputation for continuous imputed variables
• Build the plot to examine the convergence of model

71
Assessing the performance of imputations Graphs > Chart Builder> select line chart

72
Assessing the performance of imputations
1
2
3

73
Assessing the performance of imputations
In the Element Properties, select Value as
the statistic to display.
1 2
3
4

74
Assessing the performance of imputations
1
2

75
Mean and standard deviation of the imputed values of SES
at each iteration (200) for each of the 5 requested imputations
(can be requested for each continuous imputed variable).
The purpose of this plot is to look for trends or patterns.
Model converge: the parameter values bounce around in a random
fashion with no trend ( it reaches this phase immediately) and the
different lines of imputations should be mixed with each other.

76
Assessing the performance of imputations using trace plots (using Ender’s Macro http://www.appliedmissingdata.com/macro-programs.html):
• The plot for mean and SD for imputed continuous variables can be requested using Ender’s SPSS macro.
• An indication of the performance of the imputations. • For using this macro: 1000 iterations with 2 imputed datasets.
• Provides additional convergence performance criterion: • Potential scale reduction (PSR) for every 100 iteration: the MCMC is regarded
as converge when the PSR < 1.05.

77
Problematic or pathological case of non-convergence:
Figure from Buuren, S. V., & Groothuis-Oudshoorn, K. (2010). mice: Multivariate imputation by chained equations in R. Journal of statistical software, 1-68.

78
Healthy case of convergence:
Figure from Buuren, S. V., & Groothuis-Oudshoorn, K. (2010). mice: Multivariate imputation by chained equations in R. Journal of statistical software, 1-68.

79
Practice time!

80
• High school longitudinal study of 2009: public-use data
• Selected sample: subsample of 490 participants who took math and science course in 2009
• Selected measures: 9th grade sex (0=male), race/ethnicity (0=white), SES
9th and 11th grade math and science GPA
9th grade science utility (3 items; 4 point Likert scale)
9th grade science self-efficacy (4 items; 4 point Likert scale)
• Nominal Var: SEX, RACE
• Scale Var: SES, MGPA12, SGPA12
• Ordinal Var: Science utility and self-efficacy items
The practice data

81
• Research Question: Can students’ race, SES and science self-efficacy predict their 12th grade science GPA score ?
• Dependent Variable: SGPA12
• Independent Variables: Race, SES and SEFF_total (sum of 4 items)
• Auxiliary variables for imputation model: Sex, MGPA12, science utility items • Examine the correlation analysis and univariate t-tests
Analysis model

82
• Change all missing values (either system missing or user-defined missing value) to a common value , e.g., 999
• Assign missing values for all the variables in variable view
• Define variables : In Variable View -> Under Measure column -> assign the scale for each of the variables
• Analyze the pattern of missing data and examine the percentage of missing (how many percentage of missing?)
• Request Little’s MCAR test (EM) and Separate Variance t-test
• Conducting multiple imputation: 10 datasets, 100 iterations
• Remember to set the maximum and minimum value of science and math GPA to 0 and 4
• Create a composite score for science self-efficacy
• Run a regression model to answer the research question
• Examine the convergence of model by using iteration history
TASKS : YOU CAN DO IT!

83
Practical Issues/
Myths

84
Practical issues/Myths Is imputation making up the data?
Note really! The goal of imputation is not to produce the individual values and treat them as real data, but to estimate the population parameter and “preserve important characteristics of the data set as a whole (Graham, 2008).”
Account for uncertainty associated with missing data. Thus, unbiased estimates can be obtained.

85
Practical issues/Myths Should both independent variables and dependent
variables be included in the imputation model (MI)? At least, all the variables that you will use in your analysis should be included. Why?
When the DV is not included, the correlations between it and IVs are assumed to be 0. Excluding it will reduce its relationships with other variables.
Taking a liberal approach for variables selection in the imputation phase. Programs did not distinguish whether a variable is IV or DV!

86
Practical issues Why including auxiliary variables?
Inclusive Analysis Strategy: ML and MI require MAR and since there is no test for MAR, we need to find ways to increase the likelihood to satisfy MAR. Shafer and Graham (2002, p, 173): collecting data on the potential causes of missingness “may effectively convert an MNAR situation to MAR ”. Incorporates a number of “auxiliary variables” : help increasing statistical power or reduce biases in parameter estimates.
Use as many as you can, most useful are those with correlations .40.

87
Practical issues
Working with multiple items questionnaire, whether to impute the individual items or scale scores? If doable, imputing individual items, since it maximizes the information for creating the imputations and have more
statistical power than imputing scale scores (Enders, 2010, p.269-270).

88
Practical issues What if my missing data is MNAR?
Using Selection Modeling and Pattern Mixture Modeling (Chapter 10 in Ender’s Applied Missing Data Analysis) These two models deal with the NMAR situation by statistically modeling the missing data mechanism. Enders, C. K. (2011). Missing not at random models for latent growth curve analyses. Psychological methods, 16(1), 1.

89
What should I report when I write it up?
• Missing data mechanisms
• Percentage of missing for each variable & overall percentage of missing
• Software for missing data imputation
• Imputation method & algorithm
• Number of imputed datasets
• The variables used in the imputation model

90
Reference • Enders, C. K. (2010). Applied missing data analysis. Guilford Press.
• Graham, J. W. (2012). Missing data : analysis and design. Springer.
• Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual review of psychology, 60, 549-576.
• Pigott, T. D. (2001). A review of methods for missing data. Educational research and evaluation, 7(4), 353-383.
• Schafer, J. L., & Graham, J. W. (2002). Missing data: our view of the state of the art. Psychological methods, 7(2), 147.
• Azur, M. J., Stuart, E. A., Frangakis, C., & Leaf, P. J. (2011). Multiple imputation by chained equations: what is it and how does it work?. International journal of methods in psychiatric research, 20(1), 40-49.
• Puma, M. J., Olsen, R. B., Bell, S. H., & Price, C. (2009). What to Do when Data Are Missing in Group Randomized Controlled Trials. NCEE 2009-0049. National Center for Education Evaluation and Regional Assistance.
• IBM SPSS Missing Values 21 & 24 (user manual).
• Buuren, S. V., & Groothuis-Oudshoorn, K. (2010). mice: Multivariate imputation by chained equations in R. Journal of statistical software, 1-68.

91
• UCLA: idre
• SAS : https://stats.idre.ucla.edu/sas/seminars/multiple-imputation-in-sas/mi_new_1/
• Stata : https://stats.idre.ucla.edu/stata/seminars/mi_in_stata_pt1_new/
• Craig Enders website:
• Mplus: http://www.appliedmissingdata.com/additional-examples.html
• Blimp: http://www.appliedmissingdata.com/multilevel-imputation.html
Recommended websites

92
Thank you
Don’t be afraid of missing data!