
Mining Software Data - Uni Koblenz-Landau · • Tokenizing with NLTK import nltk import string...
69
© 2016 Hakan Aksu, Ralf Lämmel, Software Languages Team 1 Mining Software Data Hakan Aksu, Ralf Lämmel University of Koblenz-Landau Faculty of Computer Science Software Languages Team Creative Commons License: softlang logos by Wojciech Kwasnik, Archina Void, Ralf Lämmel, Software Languages Team, Faculty of Computer Science, University of Koblenz-Landau is licensed under a Creative Commons Attribution 4.0 International License SOFTLANG
Transcript of Mining Software Data - Uni Koblenz-Landau · • Tokenizing with NLTK import nltk import string...

© 2016 Hakan Aksu, Ralf Lämmel, Software Languages Team 1
Mining Software DataHakan Aksu, Ralf Lämmel
University of Koblenz-Landau Faculty of Computer Science
Software Languages Team
Creative Commons License: softlang logos by Wojciech Kwasnik, Archina Void, Ralf Lämmel, Software Languages Team, Faculty of Computer Science, University of Koblenz-Landau is licensed under a Creative Commons Attribution 4.0 International License
SOFTLANG
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
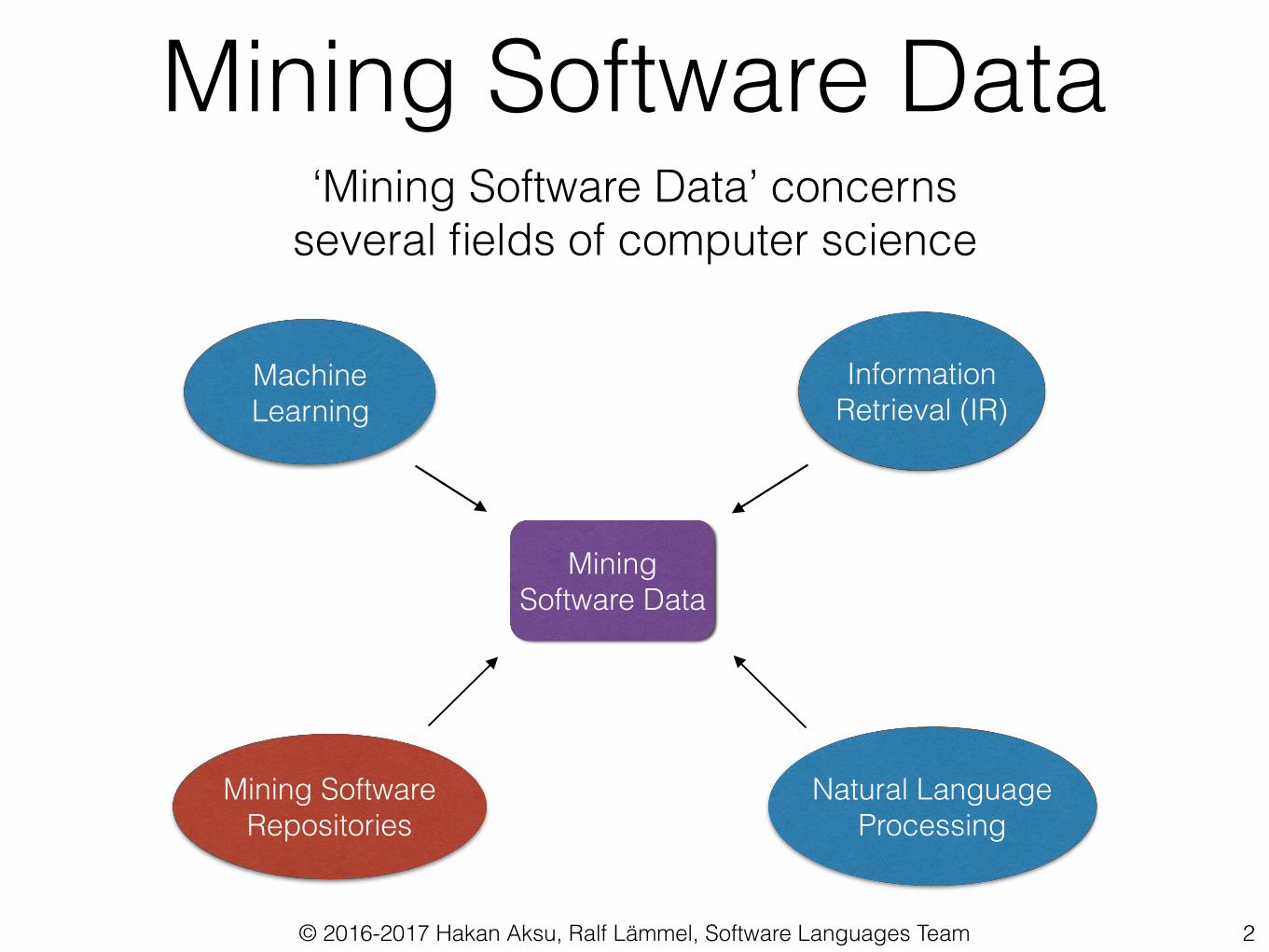
Mining Software Data
Mining Software Data
Information Retrieval (IR)
Machine Learning
Mining Software Repositories
Natural Language Processing
‘Mining Software Data’ concerns several fields of computer science
2

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Overview Information Retrieval (IR)
3

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Overview Information Retrieval (IR)
• Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers). (http://nlp.stanford.edu/IR-book/pdf/01bool.pdf)
• ‘Documents’ in 101project • wiki text (pages or sections) and • source-code units with
• program identifiers and • comments
4

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
IR scenario• Objective: find source-code units that implement a
specific feature, e.g., ‘Total’.
• Method: search source code for characteristic terms, e.g., ‘total’.
• Challenges:
• Distinguish feature implementation and testing.
• Dealing with variation in natural language usage.
5

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
• Precision is the fraction of the documents retrieved that are relevant to the user's information need.
• Recall is the fraction of the documents that are relevant to the query that are successfully retrieved.
Performance and correctness measures in IR
6

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Overview Machine Learning
7

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Types of Machine Learning
• Supervised learning
• Unsupervised learning
• Reinforcement learning
8

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Types of Machine Learning
Supervised learning (e.g., prediction models) is the machine learning task of inferring a function from labeled training data. The computer is presented with example inputs and their desired outputs. The goal is to learn a general rule that maps inputs to outputs.
Training Data Test Data
Learning Rules test rules determine, e.g., precision & recall
9

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Types of Machine LearningUnsupervised learning (e.g., cluster analysis): is the machine learning task of inferring a function to describe hidden structure from unlabeled data.No labels are given to the learning algorithm, leaving it on its own to find structure in its input.
One color stands for a cluster.
Possible structures:
10
Source: https://de.wikipedia.org/wiki/Clusteranalyse

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Types of Machine LearningReinforcement learning:
• Inspired by behaviorist psychology
• The algorithm learns by reward and punishment like a human
• Example: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as driving a vehicle), without a teacher explicitly telling it whether it has come close to its goal.
• Another example is learning to play a game by playing against an opponent.
11

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Overview Natural Language Processing
(NLP)
12

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Definition 1
Natural language processing is a branch of artificial intelligence that deals with analyzing, understanding and generating the languages that humans use naturally in order to interface with computers in both written and spoken contexts using natural human languages instead of computer languages. http://www.webopedia.com/TERM/N/NLP.html (April, 2016)
13

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Definition 2
Natural language processing is a method to translate between computer and human languages. It is a method of getting a computer to understandably read a line of text without the computer being fed some sort of clue or calculation. In other words, NLP automates the translation process between computers and humans. https://www.techopedia.com/definition/653/natural-language-processing-nlp (April, 2016)
14

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Definition 3
Computer understanding, analysis, manipulation, and/or generation of natural language. This can refer to anything from fairly simple string-manipulation tasks like stemming, or building concordances of natural language texts, to higher-level AI-like tasks like processing user queries in natural language. natural language processing. Dictionary.com. The Free On-line Dictionary of Computing. Denis Howe. http://www.dictionary.com/browse/natural-language-processing (accessed: April, 2016).
15

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Some tasks in NLP• Machine translation
• Translate text from one language to another • Morphological segmentation
• Separate words into individual morphemes and identify the class of the morphemes • Natural language generation
• Convert information from databases into readable human language • Part-of-speech tagging
• Given a sentence, determine the part of speech (e.g., noun, verb or adjective) for each word.
• Question answering • Given a human-language question, determine its answer
• Relationship extraction • Given a text, identify the relationships among named entities (e.g., who is father to whom)
• Word sense disambiguation • Many words have more than one meaning; Identify the meaning of words
• Text simplification • Text-to-speech • Natural language search • Text-proofing • …
16
Not much of this in this course!

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Overview Mining Software Repositories
(MSR)
17

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Mining Software Repositories
• The Mining Software Repositories (MSR) field analyzes the rich data available in software repositories.
• Analysis of • version control repositories • mailing list archives • bug tracking systems • issue tracking systems, etc.
• to uncover information about software systems, projects and software engineering.
https://en.wikipedia.org/wiki/Mining_Software_Repositories
18

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Current MSR research in the Software Languages Team
• Analysis of Software Repositories to identify developer experience in different scopes like experience in API usage or skills in specific frameworks (e.g., Django)
19

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Preparing programs for NLP and data mining
20

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
NL data in 101project• Program identifiers • Comments• Wiki text • Commit messages • Github issues • Github revisions
21

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Program identifierClass/Type/Interface names
method names variable/parameter names
22

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Comments
comment blocks
single comments
23
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
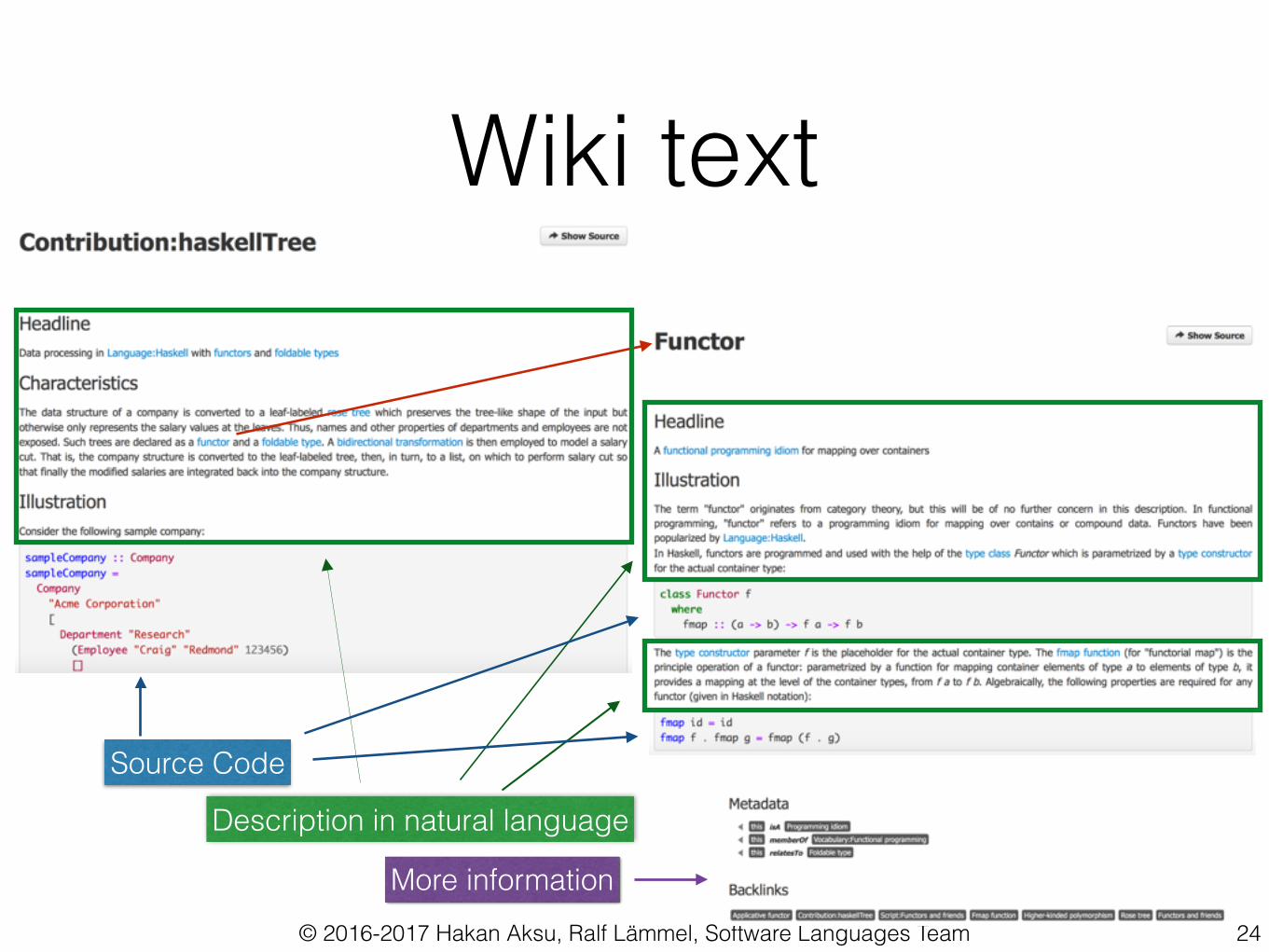
Wiki text
Description in natural language
Source Code
More information24

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
NL preprocessing
25

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
NL preprocessing tasks• After preparing programs for data mining (like scanning, fact extraction and/or program
identifier splitting) we need some NL preprocessing steps.
• Preprocessing is used to prepare the raw data for the analysis itself.
• There are many methods like • part-of-speech tagging • lemmatization • text simplification • word sense disambiguation • …
• We are interested in • Program identifier ‘Tokenizing’• ‘Tokenizing’• ‘Stemming’• Removing ‘Stop Words’
26

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Splitting
27
„getSalary“
splitting to
„get“ and „Salary“
Split program identifier to single words
Example

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Tokenizing• Separate a text (String) to its tokens
• Example — Input:• „Natural language processing makes fun.“
• Result:• „Natural“, „language“, „processing“, „makes“, „fun“, “.“
• Best practice is to work without punctuations and lowercased tokens (normalization of tokens).
• Normalized result:• „natural“, „language“, „processing“, „makes“, „fun“
28

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 29
Tokenizing in Python• Tokenizing with NLTK
import nltkimport stringremove_punctuation_map = dict((ord(char), None) for char in string.punctuation)
def tokenize(text):tokens = nltk.word_tokenize(text.translate(remove_punctuation_map))tokens = [w.lower() for w in tokens]return tokens
• Tokenizing with TextBlob
from textblob import TextBlobdef tokenize(text):
text = TextBlob(text)tokens = text.wordsreturn tokens
tokenize
with lowercase letters
without punctuation
only tokenizing
normalization also possible
Limited alternative text.translate(None,string.punctuation)

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Stemming• Stemming is the process of reducing a word into its stem.
• The stem or root form is not necessarily a word by itself, but it can be used to generate words by concatenating the right suffix.
• Example • fish, fishes and fishing stems into fish
It is a correct word • study, studies and studying stems into studi
It is not an English word.
• Most commonly, stemming algorithms (a.k.a. stemmers) are based on rules for suffix stripping.
30

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Stemming• The most famous algorithm is the Porter stemmer.
Introduced in1979.
• A more aggressive stemming algorithm is the Lancaster stemmer. Introduced in 1990.
• Python libraries • NLTK
doc http://www.nltk.org/api/nltk.stem.html demo http://www.nltk.org/book/ch03.html (Section 3.6)
• PyStemmer - https://github.com/snowballstem/pystemmer
31

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Stemming in Python• Stemming with NLTK
import nltkfrom nltk.stem.porter import PorterStemmerdef stem(tokens):
stem = []for item in tokens:
stems.append(PorterStemmer().stem(item))return stems
• Stemming with PyStemmer
import Stemmerdef stem(tokens):
stemmer = Stemmer.Stemmer('english')stems = stemmer.stemWords(tokens)return stems stemmer.stemWord(‘WordXYZ’)
stems single words
32

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Stop words• Stop words are usually extremely common words in a language
which are filtered out before processing of natural language data. There is no single universal list of stop words used by all NLP tools but here are some common english stop words: a, an, and, are, as, at, be, by, for, from, has, he, in, is it, its, of, on, that, the, to, was, were, will, with, …
• Some stop words lists (a.k.a. stop lists): • http://snowball.tartarus.org/algorithms/english/stop.txt • http://xpo6.com/list-of-english-stop-words/
• Python library: • NLTK - http://www.nltk.org/book/ch02.html (Section 4.1)
33

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Stop words in Python Remove stop words (with NLTK)
import nltkfrom nltk.corpus import stopwordsdef remove_stopwords(tokens):
stopwords = nltk.corpus.stopwords.words('english')content = [w for w in tokens if w not in stopwords]return content
you can use an alternative stop list -> you don’t need NLTK
if you use the stop list of NLTK install ‘stopwords‘ from the NLTK-Corpus with
nltk.download('stopwords')34
Source: http://www.nltk.org/book/ch02.html

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Mining Software Data
35

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Mining Software Data• We apply some techniques of NLP, data mining (IR, machine
learning), metaprogramming to scenarios with program identifiers, program comments, or documentation as data.
• Selection of techniques: • Java Parser• Regular Expression Matching• IDF• Cosine similarity• Clustering • Prediction model • Sentiment analysis • Correlation • “Plotting”
36

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Java Parser
37

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
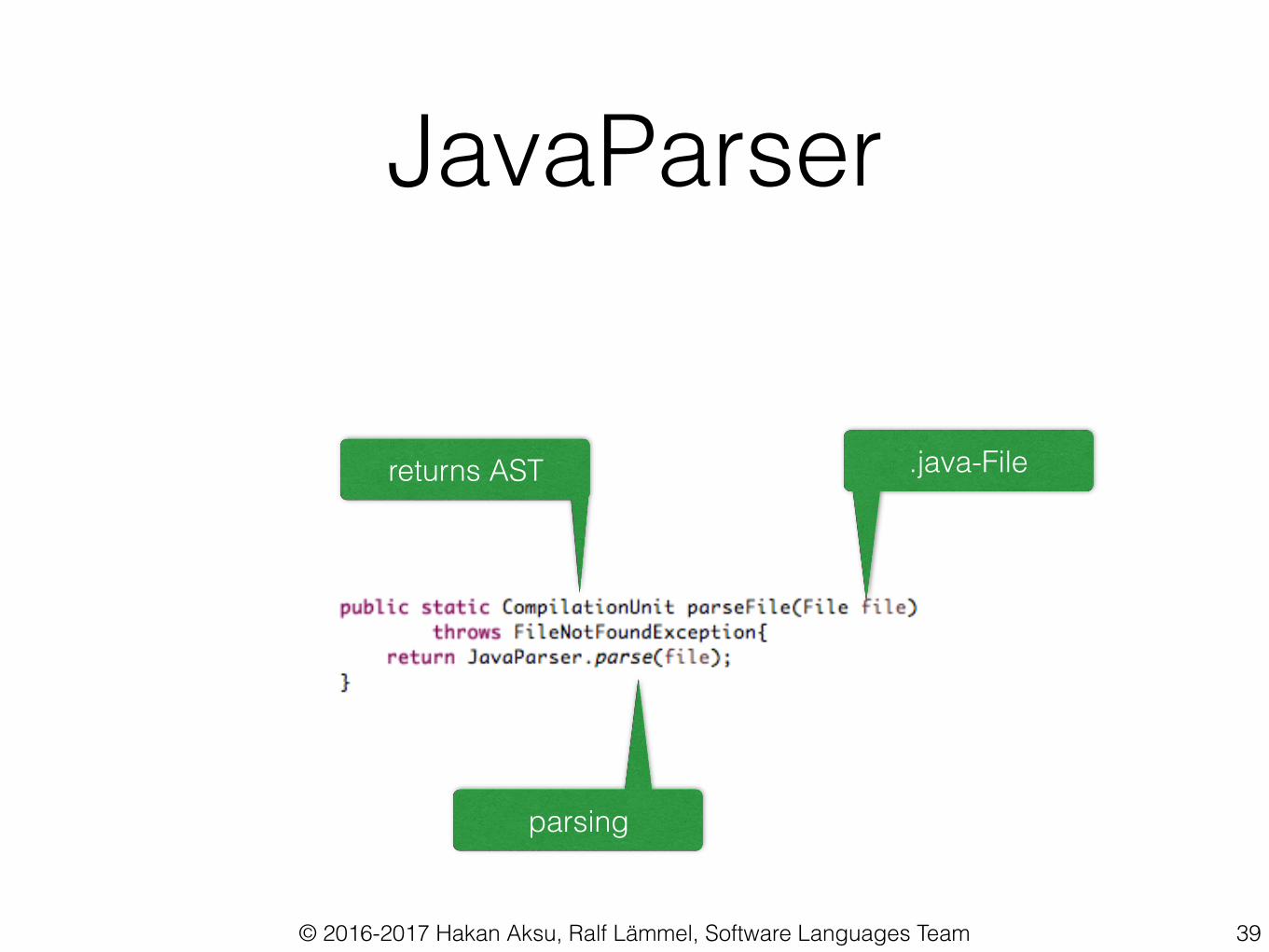
Java Parser
Given a source file JavaParser recognizes the different syntactic elements and produces an
Abstract Syntax Tree (AST).
38
https://github.com/javaparser/javaparser
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
JavaParser
39
returns AST .java-File
parsing

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 40
Iterate over AST with JavaParser

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Iterate over AST• via Recursive-Method
• process on actual Node (instanceof queries and casts for specific Nodes)
• call method with child Nodes
• via Visitor • call accept method with specific Visitor • process on visit methods for specific Nodes
41

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Java Parser scenario
How can we print all method names
of a .java-File?
42

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
VIA Recursive Method
43
ACTUAL NODE- At beginning the AST-root (CompilationUnit) -
instanceof-query and cast for MethodDeclaration-Nodes
recursive call for child Nodes
prints Method names
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
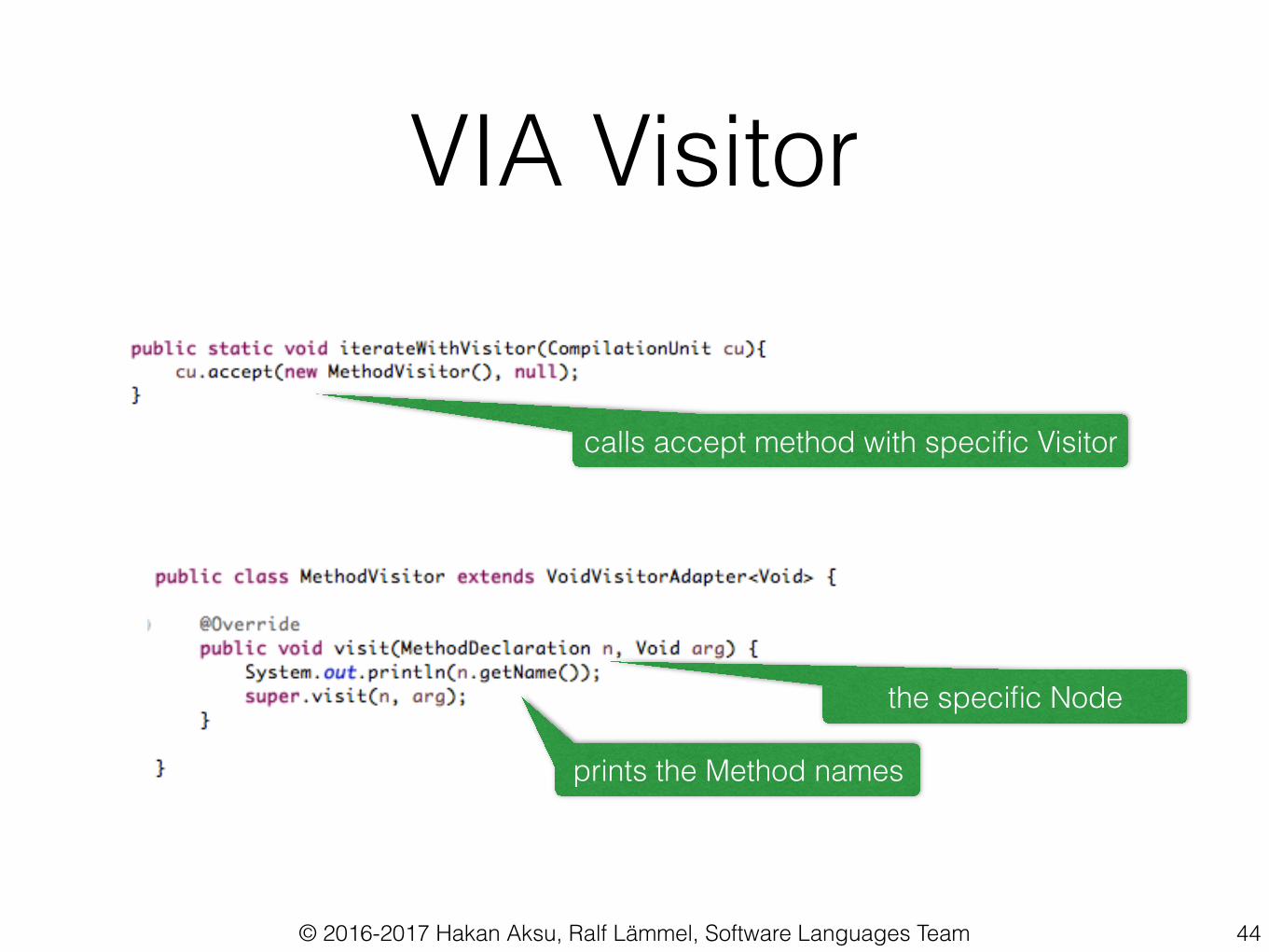
VIA Visitor
44
calls accept method with specific Visitor
prints the Method names
the specific Node

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Regular Expression Matching
45

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
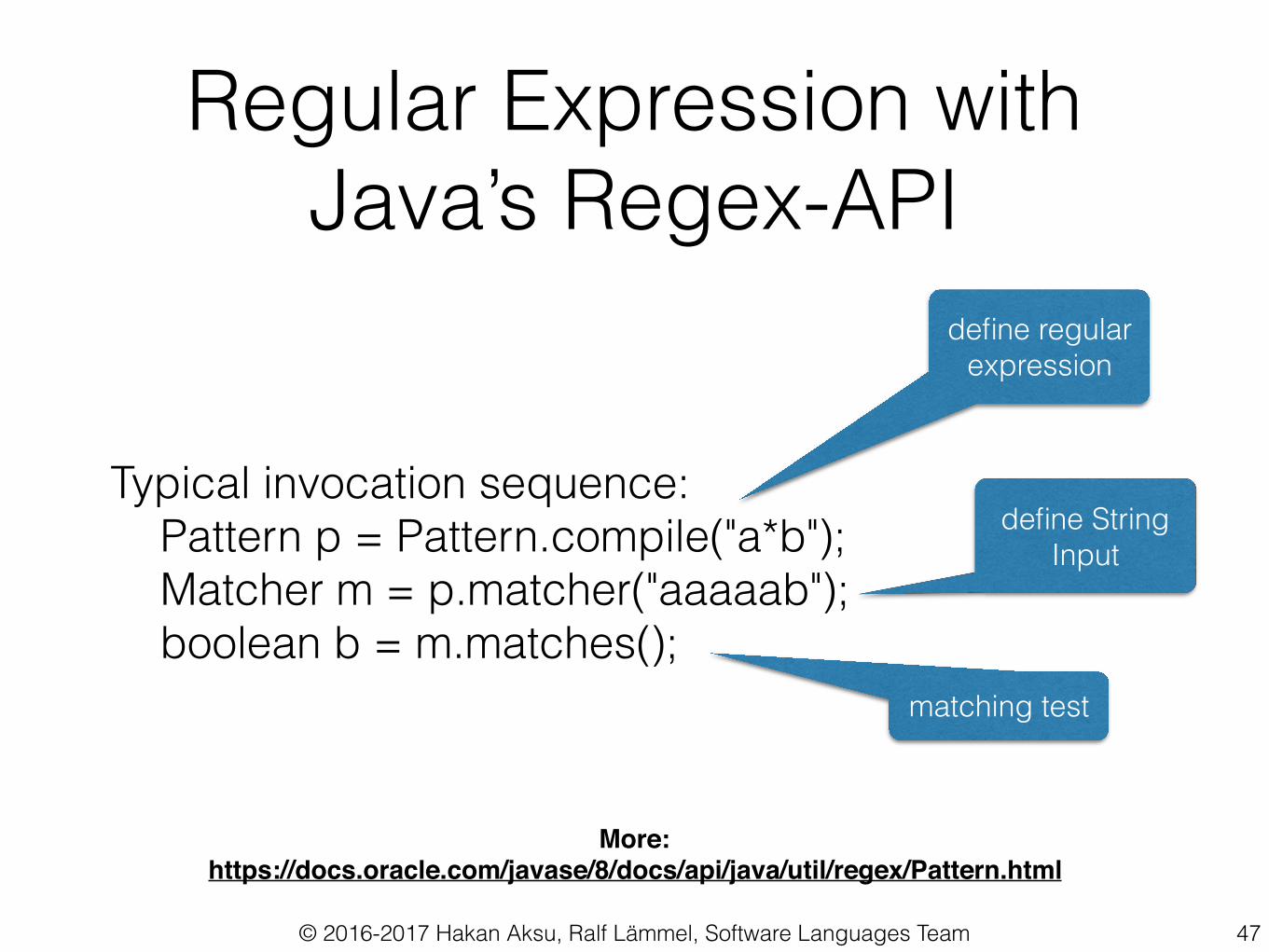
Regular Expression with Java’s Regex-API
46
Charactersx The character x \\ The backslash character \t The tab character ('\u0009') \n The newline (line feed) character ('\u000A') \r The carriage-return character ('\u000D') \f The form-feed character ('\u000C') \a The alert (bell) character ('\u0007') \e The escape character ('\u001B') \cx The control character corresponding to x
More:https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html
Character classes[abc] a, b, or c (simple class) [^abc] Any character except a, b, or c (negation) [a-zA-Z] a through z or A through Z, inclusive (range) [a-d[m-p]] a through d, or m through p: [a-dm-p] (union) [a-z&&[def]] d, e, or f (intersection) [a-z&&[^bc]] a through z, except for b and c: [ad-z] (subtraction) [a-z&&[^m-p]] a through z, and not m through p: [a-lq-z](subtraction)
Greedy quantifiersX? X, once or not at all X* X, zero or more times X+ X, one or more times X{n} X, exactly n times X{n,} X, at least n times X{n,m} X, at least n but not more than m times
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Typical invocation sequence: Pattern p = Pattern.compile("a*b"); Matcher m = p.matcher("aaaaab"); boolean b = m.matches();
47
More:https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html
Regular Expression with Java’s Regex-API
define regular expression
define String Input
matching test

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Design Pattern Detection with
JavaParser and
Regular Expression Matching
48

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 49
https://boa.unimib.it/retrieve/handle/10281/31515/43100/phd_unimib_055259.pdf
Tools for Design Pattern Detection

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Design Pattern Detection
We focus on simple design pattern detection with • Java Parser and • Regular Expression Matching
50

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Example
How can we detect the Singleton Pattern?
51

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Constraints for Singleton Pattern
We identify a Singleton class with following criteria: 1. has class constructors regardless of accessibility 2. has a static reference, regardless of accessibility,
to the Singleton class, and 3. has a public-static method that returns the
Singleton class type
52
http://dblp.uni-trier.de/rec/html/conf/kbse/ShiO06

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Singleton Pattern Detection with
Java Parser
53
© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
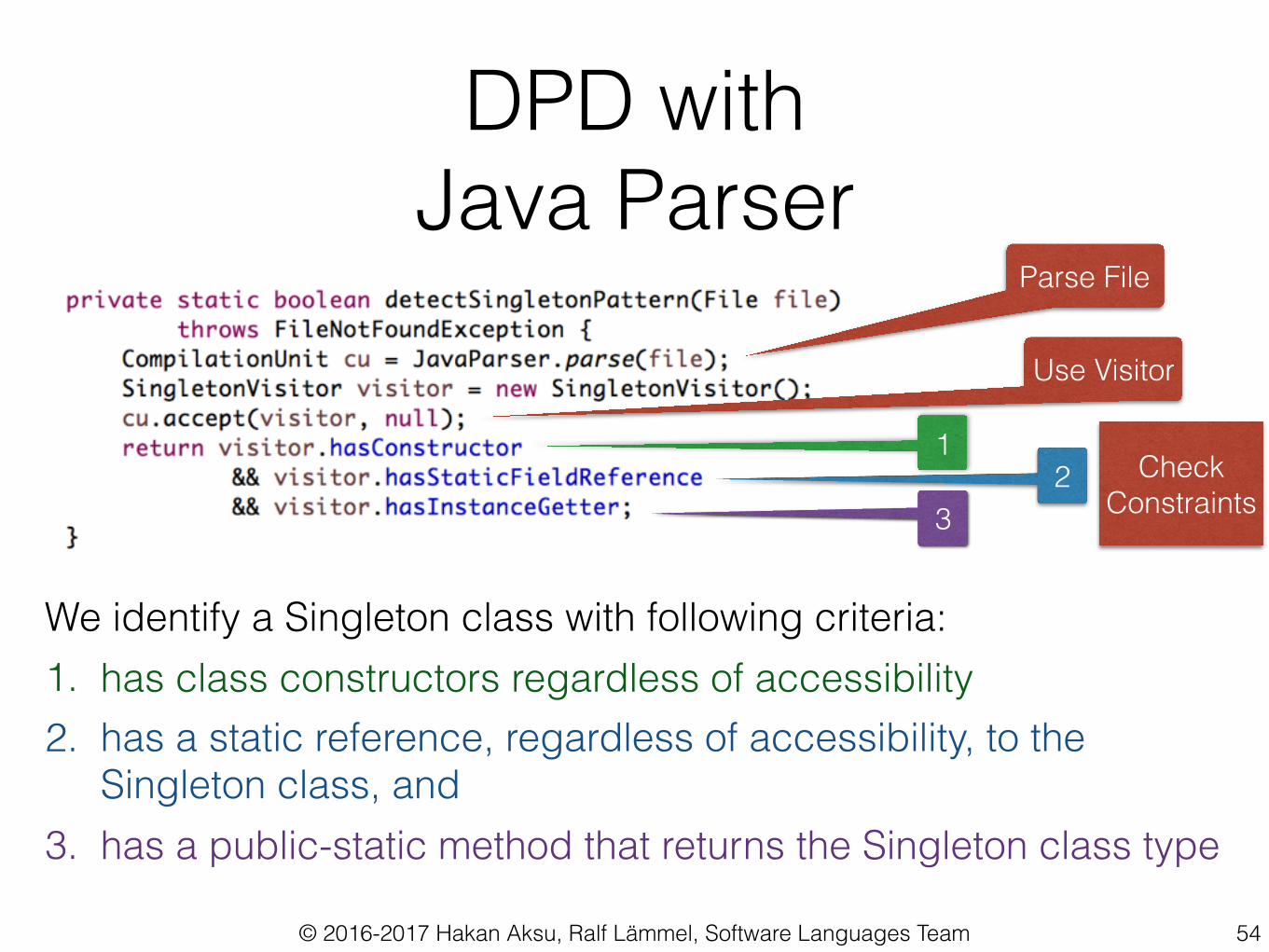
DPD with Java Parser
54
We identify a Singleton class with following criteria: 1. has class constructors regardless of accessibility 2. has a static reference, regardless of accessibility, to the
Singleton class, and 3. has a public-static method that returns the Singleton class type
12
3
Parse File
Use Visitor
Check Constraints

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
DPD with Java Parser
55
Specific Visitor for
Singleton Pattern Detection

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 56
save classname
1. constraint
3. constraint
2. constraint

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Singleton Pattern Detection with
regular expression matching
57

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
DPD with regular expression matching
58
regular expr 1. constraint
regular expr 2. constraint
regular expr 3. constraint
Match reg expr in File for
1.-3. constraint
API: java.util.regex.*

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Inverse Document Frequency (IDF)
59

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
TF-IDF scenario• Extract vocabulary from Wiki text (including stemming and
stop list application) • Compute TF-IDF from wiki pages („documents“).
• We get ranked lists for every document. • Do the first ranked terms ‘characterize’ the document? • Are the first ranked terms important for all documents?
word TF-IDFword1 5,4word2 2,9
… …
word TF-IDFword5 8,2word1 5,2
… …
word TF-IDFword4 1,4word3 1,3
… …
document 1 document 2 document 3
60

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Inverse Document Frequency (IDF)
N = total number of documentsdft = number of documents that contain a term tidft = Inverse document frequency of a term t
idft = log
N
dft
If a word appears in many documents, then it is not a unique identifier; this word has a low IDF score.
61

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
• TF-IDF stands for "Term Frequency, Inverse Document Frequency". It is a way to score the importance of words (or "terms") in a document based on how frequently they appear across multiple documents.
• Intuitively...• If a word appears frequently in a document, it's important. Give the
word a high score.• If a word appears in many documents, it's not a unique identifier.
Give the word a low score.
tfd,t = number of occurrence of term t in a document d
TF-IDF
tfidfd,t = tfd,t logN
dft
N = total number of documentsdft = number of documents that contain a term t
tfidfd,t = term freq. - IDF of a term t in document d
62

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
TF-IDF in PythonDifferent ways to calculate the ‘term frequency’:
def term_frequency(term, tokenized_document): return tokenized_document.count(term)
def sublinear_term_frequency(term, tokenized_document): return 1 + math.log(tokenized_document.count(term))
def augmented_term_frequency(term, tokenized_document): max_count = max([term_frequency(t, tokenized_document) for t in tokenized_document]) return (0.5 + ((0.5 * term_frequency(term, tokenized_document))/max_count))
63
Source: http://billchambers.me/tutorials/2014/12/21/tf-idf-explained-in-python.html

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
TF-IDF in PythonCalculating IDF
def inverse_document_frequencies(tokenized_documents): idf_values = {} all_tokens_set = set([item for sublist in tokenized_documents for item in sublist]) for tkn in all_tokens_set: contains_token = map(lambda doc: tkn in doc, tokenized_documents) idf_values[tkn] = 1 + math.log(len(tokenized_documents)/(sum(contains_token))) return idf_values
64
Source: http://billchambers.me/tutorials/2014/12/21/tf-idf-explained-in-python.html
tokenized documents
sublist
item
item
item
sublist
item
item
item
sublist
item
item
item

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
TF-IDF in PythonCalculating TF-IDF for every term in all documents
def tfidf(documents): tokenized_documents = [tokenize(d) for d in documents] idf = inverse_document_frequencies(tokenized_documents) tfidf_documents = [] for document in tokenized_documents: doc_tfidf = [] for term in idf.keys(): tf = sublinear_term_frequency(term, document) doc_tfidf.append(tf * idf[term]) tfidf_documents.append(doc_tfidf) return tfidf_documents
65
Source: http://billchambers.me/tutorials/2014/12/21/tf-idf-explained-in-python.html

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
TF-IDF in PythonCalculating TF-IDF with scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
sklearn_tfidf = TfidfVectorizer(tokenizer=process, stop_words = ‘english’)
sklearn_representation = sklearn_tfidf.fit_transform(all_documents)
66
Source: http://billchambers.me/tutorials/2014/12/21/tf-idf-explained-in-python.html
reference to tokenizing and stemming method define stop words

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team
Cosine similarity
67

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 68
Cosine scenarioFind for each method or class scope of each contribution the most similar scope in another contribution where the vector is based on the term frequency (after preprocessing) of the program identifiers (or comments) in the scope. The terms to be included into the vector could be selected in different ways.
We could consider the top-n terms from an (TF-)IDF analysis.

© 2016-2017 Hakan Aksu, Ralf Lämmel, Software Languages Team 69
Cosine similarity in Pythonimport nltk, stringfrom sklearn.feature_extraction.text import TfidfVectorizer
stemmer = nltk.stem.porter.PorterStemmer()remove_punctuation_map = dict((ord(char), None) for char in string.punctuation)
def stem_tokens(tokens): return [stemmer.stem(item) for item in tokens]
def normalize(text): return stem_tokens(nltk.word_tokenize(text.lower().translate(remove_punctuation_map)))
vectorizer = TfidfVectorizer(tokenizer=normalize, stop_words='english')
def cosine_sim(text1, text2): tfidf = vectorizer.fit_transform([text1, text2]) return ((tfidf * tfidf.T).A)[0,1]
print cosine_sim('a little bird', 'a little bird')print cosine_sim('a little bird', 'a little bird chirps')print cosine_sim('a little bird', 'a big dog barks')
calculate cosine similarity
calculate tfidf-Vector


















