



Mining public datasets using opensource tools: Zeppelin, Spark and Juju
38
Mining Public Datasets Using Open Source Tools At scale & on a budget by Alexander
-
Upload
seoulengineer -
Category
Data & Analytics
-
view
996 -
download
0
Transcript of Mining public datasets using opensource tools: Zeppelin, Spark and Juju

Mining Public Datasets Using Open Source Tools
At scale & on a budget by Alexander

Software Engineer at NFLabs, Seoul, South Korea
Co-organizer of SeoulTech Society
Committer and PPMC member of Apache Zeppelin (Incubating)
@seoul_engineer
github.com/bzz
Alexander

IS DATA IMPORTANT?
Content Streaming Services
Taxi
Housing
Web Search
Kuaidi
OpenHouse
IoT

CONTEXT
Size of even Public Data is huge and growing
There could be more research, applications and data products build using that data
Quality and number of free tools available to public to crunch that data is constantly improving
Cloud brings affordable computations @ scale

PUBLIC DATA = OPPORTUNITY

AGENDA
Datasets
Tools
Scale and Budget

Datasets
Tools
Scale and Budget

• Internet archives• Web applications logs (wikipedia activity, github activity)• Genome• AdClicks• Webserver access logs • Network traffic• Scientific datasets• Images, Songs (Million Song Dataset)• Reviews, • Social media• Flight timetables• Taxis• n-gram language model
DATASETS

DATASETS
• 300Gb compressed• Collaboration google and github engineers• Events on PR, repo, issues, comments in JSON
http://githubarchive.org

http://www.commitlogsfromlastnight.com/

http://sideeffect.kr/popularconvention/

https://www.gitlive.net/

Common Crawl
https://commoncrawl.org
Nonprofit, by Factual
On AWS S3 in WARC, WAT, formatssince 2013, monthly: ~150Tb compressed, 2+bln ulrs

URL Index by Ilya Kreymer of @webrecorder_io http://index.commoncrawl.org/


Datasets
Tools
Scale and Budget

TOOLS OVERVIEW
Generic: Grep, Python, Ruby, JVM - all good, but hard to scale beyond single machine or data format
Hight-performance: MPI, Hadoop, HPC - awesome but complex, not easy, problem specific, not very accessible
New, scalable: Spark, Flink, Zeppelin - easy (not simple) and robust

Apache Software Foundation
http://www.apache.org/foundation/

Apache Software Foundation
1999 - 21 founders of 1 project
2016 - 9 Board of Directors 600 Foundation members2000+ committers of 171 projects (+55 incubating)
Keywords: meritocracy, community over code, consensus
Provide: infrastructure, legal support, way of building software
http://www.apache.org/foundation/

Apache Spark Scala, Python, R
Apache Zeppelin Modern Web GUI, plays nicely with Spark, Flink, Elasticsearch, etc. Easy to set up.
Warcbase Spark library for saved crawl data (WARC)
Juju Scales, integration with Spark, Zeppelin, AWS, Ganglia
NEW, SCALABLE TOOLS

APACHE SPARK
From Berkeley AMP Labs, since 2010
Founded Databricks since 2013, joined Apache since 2014
1000+ contributors
REPL + Java, Scala, Python, R APIs
http://spark.apache.org

APACHE SPARK
Has much more: GraphX, MLlib, SQLhttps://spark.apache.org/examples.html
http://spark.apache.org
Parallel collections API (similar to FlumeJava, Crunch, Cascading)

• Notebook style GUI on top of backend processing system
• Plays nicely with all the eco-system Spark, Flink, SQL, Elasticsearch, etc.
• Easy to set up
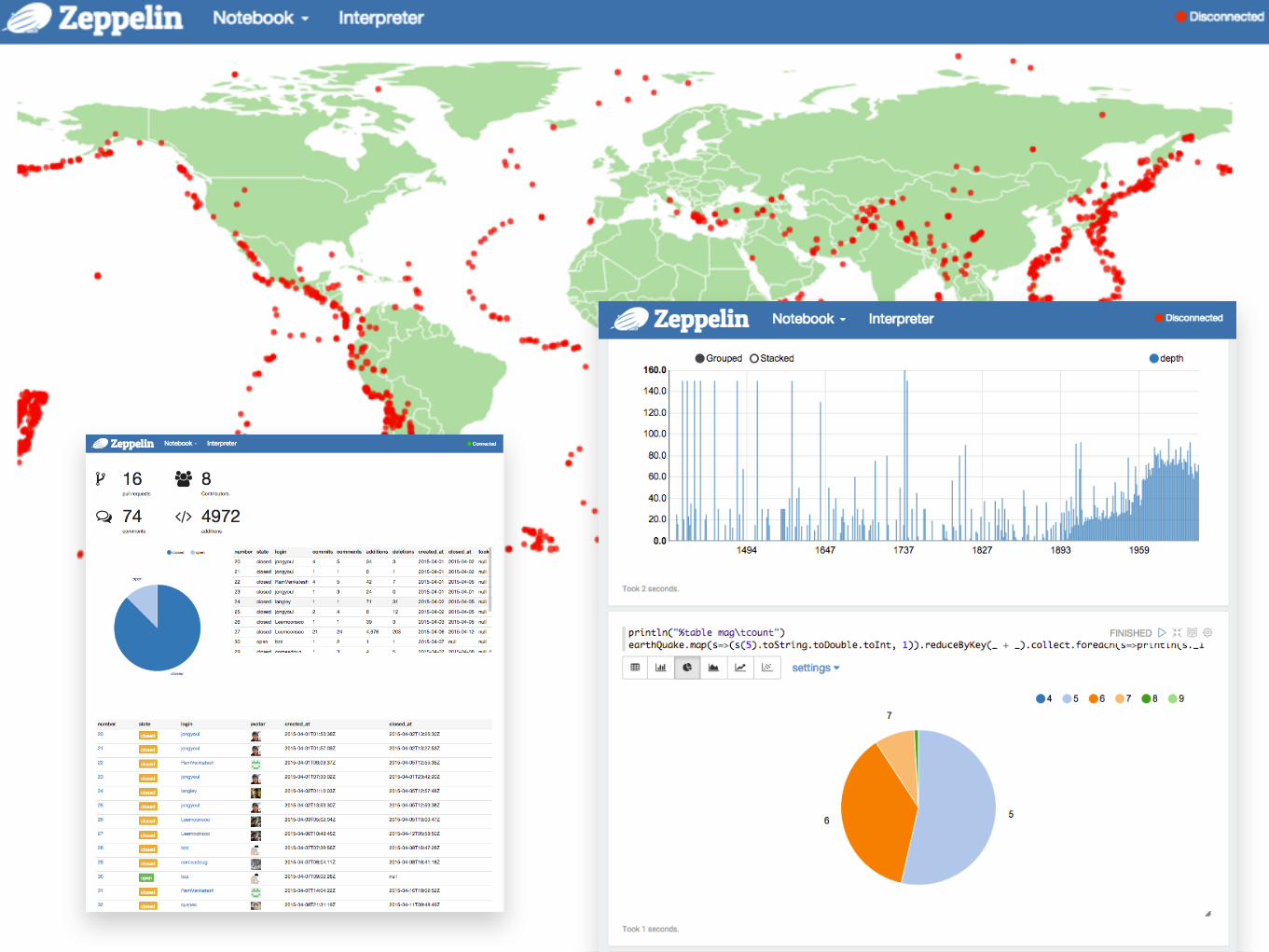
APACHE ZEPPELIN (INCUBATING)
http://zeppelin.incubator.apache.org

Enters ASF Incubation12.201408.2013 NFLabs Internal project Hive/Shark
12.2012 Commercial App using AMP Lab Shark 0.510.2013 Prototype Hive/Shark
APACHE ZEPPELIN PROJECT TIMELINE
01.2016 3 major releases
http://zeppelin.incubator.apache.org

Interactive Visualization
APACHE ZEPPELIN

Pluggable Interpreters
APACHE ZEPPELIN

Spark library for WARC (Web ARChive) data processing * text analysis * site link structure
WARCBASE
https://github.com/lintool/warcbase
http://lintool.github.io/warcbase-docs

Service modeling at scale
Deployment\configuration automation + Integration with Spark, Zeppelin, Ganglia, etc + AWS, GCE, Azure, LXC, etc
JUJU
https://jujucharms.com/

$ apt-get install juju-core juju-quickstart # or $ brew install juju juju-quickstart $ juju generate-config #LXC, AWS, GCE, Azure, VMWare, OpenStack
$ juju bootstrap $ juju quickstart apache-hadoop-spark-zeppelin $ juju expose spark zeppelin $ juju add-unit -n4 slave
JUJU
http://bigdata.juju.solutions/getstarted

JUJU
http://bigdata.juju.solutions/getstarted
7 node cluster designed to scale out

Datasets
Tools
Scale and Budget

1 core
10s PC
1000 instances
APPROACH: SCALE AND BUDGET
Prototype
Estimate the cost
Scale out
Your laptop
AWS spot instances
Deployment automation

TAKEAWAY
There are plenty of free tools out there
To crunch the data for fun and profit
They are easy (not simple) to learn and generic enough

Thank you


















