
Mihai Pintea. 2 Agenda Hadoop and MongoDB DataDirect driver What is Big Data.
20
Mihai Pintea Big Data Hadoop & MongoDB
-
Upload
lorin-anderson -
Category
Documents
-
view
222 -
download
1
Transcript of Mihai Pintea. 2 Agenda Hadoop and MongoDB DataDirect driver What is Big Data.

Mihai Pintea
Big Data Hadoop & MongoDB

2
Agenda
Hadoop and
MongoDB
DataDirect driver
What is Big Data

3
?

4
What is Big Data?
implications for everyone
transforming the way we do business
digital trace, which we can use and analyze
make use of the increasing volumes of data
Big data = data sets so large or complex that traditional data processing applications are
inadequate

5
How we generate Big Data?
Conversation Data Activity Data
Photo and Video Data Sensor Data
Internet of Things Data

6
What are the Big Data characteristics?
The 4 V’s of
Big Data
Volume
Velocity
Veracity
Variety
Quantity of data
Speed of generating data
Quality of data
Categories of data

7
How to turn Big Data into Value ?
VALUE
Volume
Velocity
Veracity
Variety
The ‘Datafication’of our World:• Activities• Conversations• Words• Voice• Social Media• Browser Logs• Photo• Video• Sensors• …
Analyzing Big Data:• Text Analytics• Sentiment
Analysis• Face
Recognition• Voice Analytics• Movement
Analytics• …

8
DataDirect Connectivity for Big Data
Apache Hadoop Hive Data SolutionsRapidly integrate Hadoop Hive with your cloud and on-premise applications, databases, files and social media sources.
Apache Cassandra Data SolutionsProvides improved business performance and scalability for integrating with Apache Cassandra managed systems
Amazon Redshift Data SolutionsData access to Amazon’s fast and powerful data warehouse service in the AWS cloud.
MongoDB Data SolutionsStreamlines access to the database and file-system data and makes it easier to get data in and out of other reporting and big data applications.
SAP HANA Data SolutionsConnectivity to SAP HANA to ease integration of in-memory operational data.

9
What is Hadoop?
Software technology designed for storing and processing large volumes of data
Open-source software framework written in Java for distributed storage and distributed processing of very large data sets on computer clusters
The core of Apache Hadoop consists of a storage part (Hadoop Distributed File System (HDFS)) and a processing part (MapReduce).
The base Apache Hadoop framework consists of the following modules: Hadoop Common, Hadoop Distributed File System (HDFS), Hadoop YARN, Hadoop MapReduce

10
Properties of a Hadoop System
● HDFS provides a write-once-read-many, append-only access model for data.
● HDFS is optimized for sequential reads of large files (64MB or 128MB blocks by default).
● HDFS maintains multiple copies of the data for fault tolerance.
● HDFS is designed for high-throughput, rather than low-latency.
● HDFS is not schema-based; data of any type can be stored.
● Hadoop jobs define a schema for reading the data within the scope of the job.
● Hadoop does not use indexes. Data is scanned for each query.
● Hadoop jobs tend to execute over several minutes or longer.

11
How Organizations Are Using Hadoop
Organizations typically use Hadoop for sophisticated, read-only analytics or high volume data storage applications such as:
Risk modeling
Predictive analytics
Machine learning
Customer segmentation
ETL pipelines
Active archives

12
DataDirect driver for Hadoop
● Access and analyze Hadoop data using familiar SQL-based reporting tools
● Progress DataDirect delivers the fastest performance for connecting to Apache Hive distributions
● Leveraging standard ODBC / JDBC relational data access methods

13
Benefits of DataDirect Hadoop Driver
A single driver supports all platforms and all Hadoop distributions out-of-the-box—for easier deployment and ongoing management
Meets the demands of low latency, real-time query and analysis with superior throughput, CPU efficiency and memory usage
Instantly works with popular BI and analytics tools such as Tableau, QlikView and SAP Crystal Reports
Provides highly secure access with user authentication, support for Hive Kerberos and SSL data encryption
Ensures reliability and stability with the most complete feature set and full standards compliance
Fully supports Hive2 with improved concurrency for better scalability

14
What is MongoDB?
Open-source document database written in C++ that provides high performance, high availability, and automatic scaling
Document Database: A record in MongoDB is a document, which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects.
High Performance: MongoDB provides high performance data persistence
High Availability: To provide high availability, MongoDB’s replication facility, called replica sets, provide – automatic failover and data redundancy

15
Data Model Design of MongoDB
Embedded Data Model
Normalized Data Model

16
DataDirect MongoDB Driver
● Available as ODBC and JDBC interfaces● Support of common RDBMS functionality such as joins● Deep Normalization to any level of nested JSON● SQL-92 compliant with industry-leading breadth of SQL
coverage

17
How MongoDB Driver Works?
Progress DataDirect maps complex MongoDB JSON structures, including nested documents and nested
arrays into their most natural relational counterpart–child tables that relate to a primary parent table.

18
MongoDB with Hadoop in Organizations
MONGODB HADOOP
eBayUser data and metadata
management for product catalogUser analysis for personalized search & recommendations
Orbitz Management of hotel data and pricing
Hotel segmentation to support building search facets
Pearson Student identity and access control. Content management of course
materials
Student analytics to create adaptive learning programs
Foursquare User data, check-ins, reviews, venue content management
User analysis, segmentation and personalization
Tier 1 Investment
Bank
Tick data, quants analysis, reference data distribution
Risk modeling, security and fraud detection
19
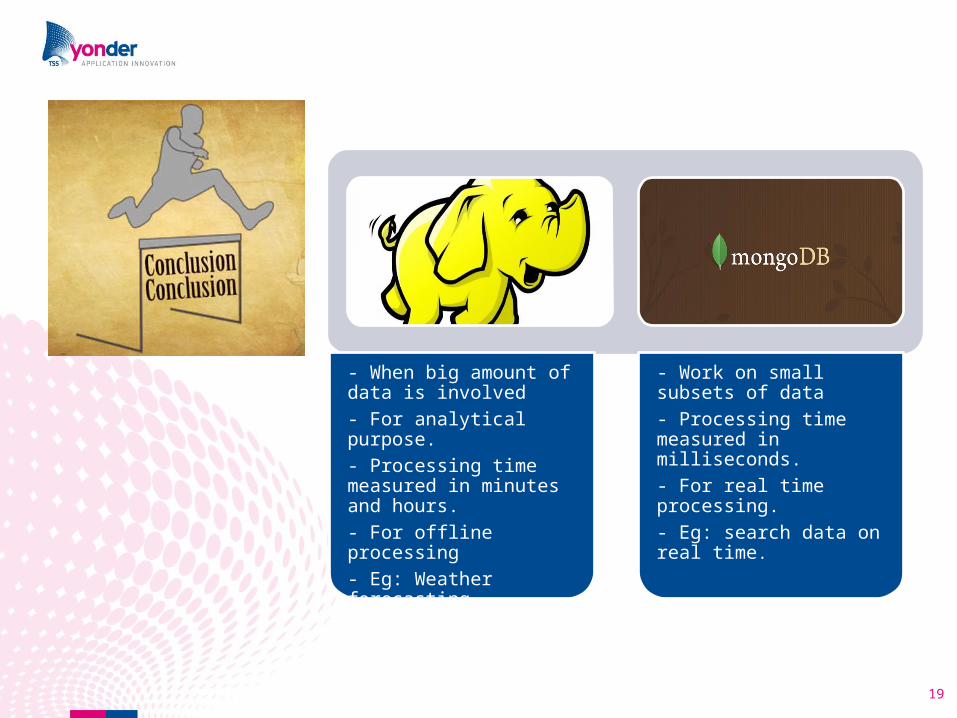
- When big amount of data is involved - For analytical purpose.- Processing time measured in minutes and hours.- For offline processing- Eg: Weather forecasting
- Work on small subsets of data- Processing time measured in milliseconds.- For real time processing.- Eg: search data on real time.

20
Q&A


















