
Michael Patrick Technical Account Manager at Percona · Michael Patrick Technical Account Manager...
46
Choosing a MySQL HA Solution Today Choosing the best solution among a myriad of options. Michael Patrick Technical Account Manager at Percona
Transcript of Michael Patrick Technical Account Manager at Percona · Michael Patrick Technical Account Manager...

Choosing a MySQL HA Solution TodayChoosing the best solution among a myriad of options.
Michael Patrick Technical Account Manager at Percona

The Evolution of HA in MySQLBlasts from the past…

Solutions used over the years
• MySQL databases on NFS shares and servers running Linux HA with Heartbeat - Bad idea but pre-replication!
• Simple Replication with manual failover.
• Scripts for failover, often written in Perl and many times home-grown. Often suffered from ping-pong effect.
• Veritas Clustering with Active/Passive failover with SAN mount/unmount of datadir.
• Master / Master with Load Balancer failover
• Corosync + Pacemaker with mount/unmount of NFS share.
• Corosync + Pacemaker + DRBD
• MMM, PRM, and Others - Added sophistication and intelligence
• And so on… So how do you decide which current solution is best for you?


Questions…Questions…Questions…How to zero in on the right solution?

You can’t hit a target if you don’t have one!
• Many in upper management don’t really know what they want and then just end up wanting it all.
• Your job is to document what is most important.
• No solution is a One-Size-Fits-All; rather, the best you can hope for is One-Size-Fits-Most.

What is the problem you are trying to solve?A very important question!

Redundancy vs. Scaling vs. High Availability
• These are not necessarily all the same!
• Redundancy ▪ Need multiple copies of data in event of
a disaster or bad queries run in Production
• Scaling ▪ Need to increase read and/or write
throughput
• High Availability ▪ Need to minimize outage duration and
get databases back online quickly
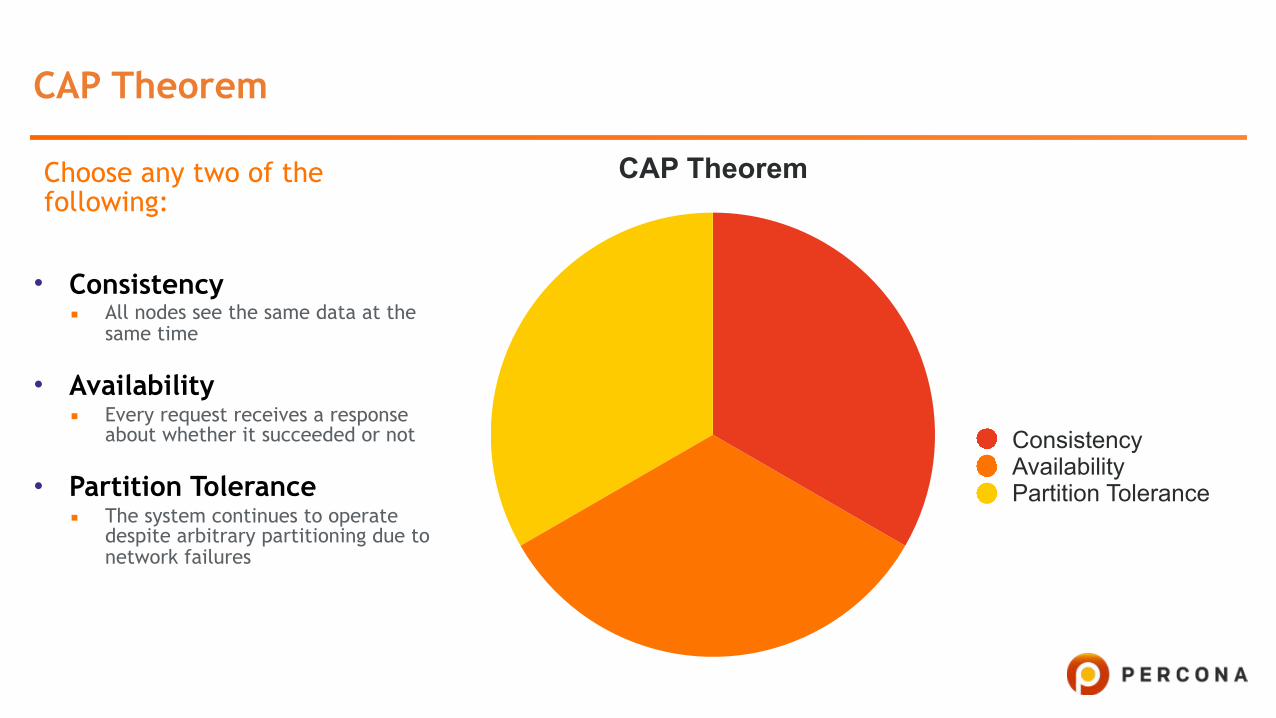
CAP Theorem
Choose any two of the following:
• Consistency ▪ All nodes see the same data at the
same time
• Availability ▪ Every request receives a response
about whether it succeeded or not
• Partition Tolerance ▪ The system continues to operate
despite arbitrary partitioning due to network failures
CAP Theorem
ConsistencyAvailabilityPartition Tolerance

Guaranteeing Consistency
• The problem is that although MySQL replication is great, it alone does not guarantee consistency across all nodes.
• There is always the possibility that data on nodes is out of sync since transactions can be lost during failover.
• Galera-based clusters, such as PXC, are certification-based to prevent this!

Can I afford to lose data?
• Depends on the Application ▪ Apps should check status codes on transactions to
be sure they were committed. Many do not! ▪ Some apps can afford to lose data periodically. Is
it really the worst thing if a comment is lost off a blog, for example?
• Lost transactions ▪ During failover, simple asynchronous replication
schemes have the possibility of losing data.
• Inconsistent nodes ▪ Without conflict detection and resolution, it is
unavoidable ▪ Run pt-table-sync often to check for inconsistent
data across replication nodes ▪ Use a Galera-based Distributed Cluster, such as PXC
with certification processes

Can I afford lost transactions?
• It depends on your application. Some are more tolerant than others! It is always a factor of durability versus performance.
• Many MySQL DBAs worry about setting innodb_flush_log_at_trx_commit to 1 for ACID compliance, setting sync_binlog, and so on, but then use replication with no consistency checks!
• If you are using traditional MySQL replication, are you consistently running pt-table-checksum?Then use pt-table-sync to fix any inconsistencies.
• PXC maintains consistency through certification.

Avoiding Single Point of Failure
• What is watching your system? Or is anything standing ready to intervene in a failure?
• With replication, take a look at MHA and MySQL Orchestrator. Both are great tools to perform failover of a Replica (Slave).
• With PXC, failover is typically much faster, but it is not the perfect solution in every case.
• MHA can lose its monitor and still function. The databases will still be available, but failover will not be possible until the monitor daemon is restarted.

MHA
• Automated master monitoring and failover.
• During a failover, MHA will look for the Slave with the latest relay log events and applies them to all slaves.
• Can be configured to power off old Master to avoid split brain.
• Can choose to failover manually.
• Can execute scripts to do IP failover and such.
• Can manually migrate to a new host for scheduled maintenance and other tasks.
• Available here: https://code.google.com/p/mysql-master-ha/

Conflict Detection & Resolution
• Galera’s Certification Process
▪ Transaction continues on a node as normal until it reaches COMMIT stage.
▪ Changes are collected into a writeset.
▪ Writeset is set to all nodes for certification.
▪ PKs are used to determine if the writeset can be applied.
▪ If certification fails, the writeset is dropped and the transaction is rolled back.
▪ If it succeeds, the transaction commits and the writesets are applied to all of the nodes.
▪ All nodes will reach the same decision on every transaction and is thus deterministic.

Do I want Failover or a Distributed System?
• Failover Pitfalls
▪ Failover systems have a monitor which detects failed nodes and moves services elsewhere if available.
▪ Failover takes time!
• Distributed Systems to the Rescue
▪ Distributed Systems minimize failover time.

Automatic or Manual Failover?
• Advantage of Manual Failover
▪ The primary advantage to failing over manually is that a human usually can make a better decision as to whether failover is necessary.
▪ Avoid ping-ping between nodes!
▪ Systems rarely get it perfect, but they can be close!
• Advantage of Automatic Failover
▪ More 9’s due to minimized outages.
▪ No need to wait on a DBA to perform.

How Fast Does Failover Have to Occur?
• Replication / MHA / MMM
▪ Depends upon how long it takes for pending Replica transactions to complete before failover can occur
▪ Typically around 30 seconds
• DRBD
▪ Typically around 30 seconds
• PXC / MySQL Cluster
▪ VERY fast failover. Typically less than 1 second depending upon Load Balancer

DRBD Advantages
• Organizations wanting some of the functionality of a SAN but at a cheaper price point
• Those not very familiar with MySQL Replication
• When you absolutely cannot lose a single transaction, although there are other HA options which can provide the same safety.
• Ensured data consistency. Asynchronous solutions such as MySQL’s replication can lead to data inconsistency and require periodic consistency checks.

DRBD Challenges
• Second node is a hot standby to the active node
▪ If using InnoDB, the startup on the second node can be considerable in the event of a crash where InnoDB has to replay its transaction logs.
▪ Often the standby is cold if using O_DIRECT with InnoDB to avoid double caching with the Operating System’s file cache. If you do not use O_DIRECT, you can waste RAM and CPU by doing double buffering. This can still be a problem since write traffic often is not going to same tables as read traffic.

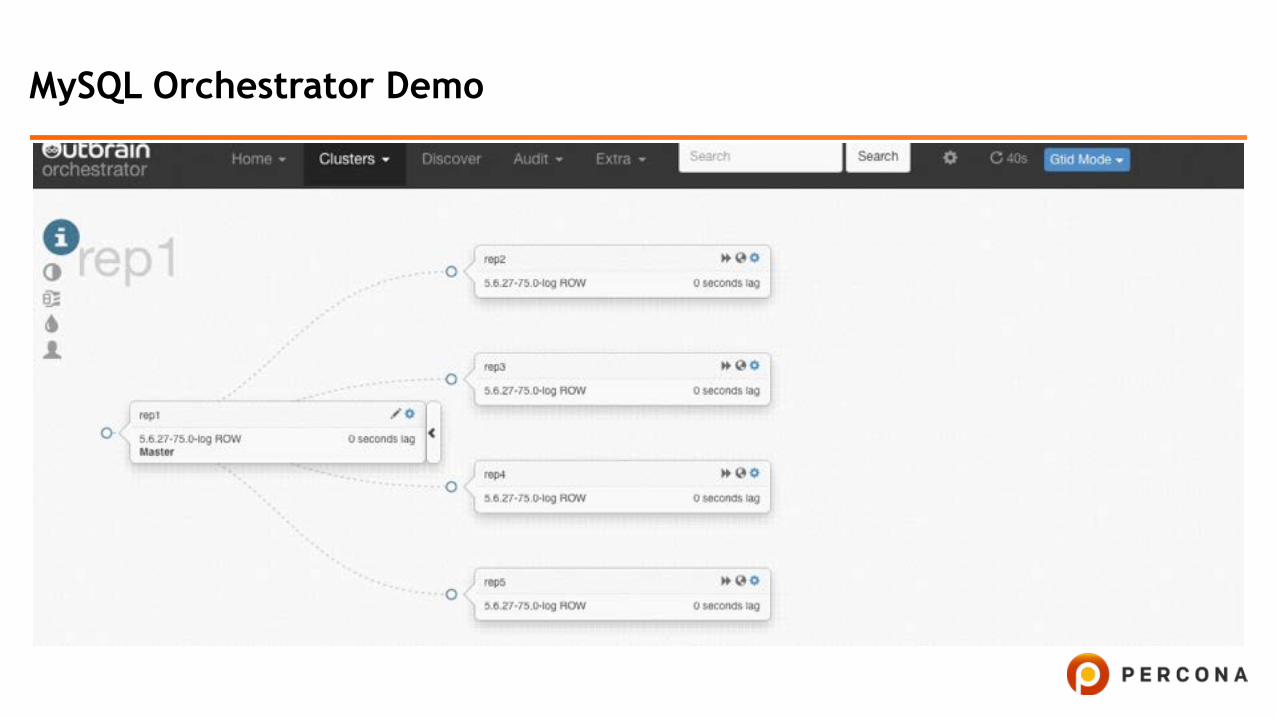
MySQL Orchestrator
• The topology and status of the replication tree is automatically detected and monitored
• Either a GUI, CLI or API can be used to check the status and perform operations
• Supports automatic failover of the master, and the replication tree can be fixed when servers in the tree fail – either manually or automatically
• It is not dependent on any specific version or flavor of MySQL (MySQL, Percona Server, MariaDB or even MaxScale binlog servers)
• Orchestrator supports many different types of topologies, from a single master -> slave to complex multi-layered replication trees consisting of hundreds of servers
• Orchestrator can make topology changes and will do so based on the state at that moment; it does not require a configuration to be defined with what corresponds to the database topology
• The GUI is not only there to report the status – one of the cooler things you can do is change replication just by doing a drag and drop in the web interface (of course you can do this and much more through the CLI and API as well)
• More information: https://www.percona.com/blog/2016/03/08/orchestrator-mysql-replication-topology-manager/
MySQL Orchestrator Demo

How Many 9’s Do You Really Need?
• Every manager always says “As many as I can get.”
• That sounds great, but the reality is that tradeoffs are required!
• Most applications can tolerate a few minutes of downtime with minimal impact.


Do I need to scale reads and/or writes?
• Scaling Reads
▪ Most solutions offer ability to read from multiple nodes or replicas.
▪ MySQL Replication, MHA, PXC, MySQL Cluster, and others are well suited for this.
• Scaling Writes
▪ Many people wrongly try to scale writes by writing to multiple nodes in PXC, leading to conflicts.
▪ Sharding is often an option to move some traffic off the main servers.
▪ Others try it with Master-Master Replication which is also problematic.
▪ Read/write Splitting via a tool such as MaxScale or ProxySQL.
▪ MySQL Cluster scales well.

Galera Issues When Writing to Multiple Nodes
• Will see increased number of wsrep_local_cert_failures.This will occur when a local certification is performed and a writeset is compared against pending writesets in the local receive queue of the node. If a conflict occurs, the transaction is rolled back and never committed. Then this counter will be incremented. Local transactions always lose!
• You can also see wsrep_local_bf_aborts. Happens when a writeset is being applied on another node and a currently open writeset conflicts. The local transaction is discarded again, since the first committed transaction wins.

ProxySQL
• Read/Write Splitting
• Query Caching
• Query Filtering and Rewriting
• Logging
• Transparent Reconnections
• Connection Pooling
• Built-in Key/Value Storage
• Integration with Clustering Solution Like MHA for Planned and/or Automatic Failover
• Support for Master-Slave Setups (MySQL Replication) or Multi-masters (NDB or Galera)

What about provisioning new nodes?
• Replication
▪ Largely, this is a manual process ▪ MySQL Utilities makes this easier than ever
• Distributed Clusters
▪ PXC and MySQL Cluster make this much easier
▪ PXC uses state transfer (either SST or IST) to automate the process for cluster nodesCan be logical or physical backup methods: mysqldump, rsync, xtrabackup, etc.SST: State Snapshot Transfer - Full data copy between donor node and joiner nodeIST: Incremental State Transfer - Identifies only missing transactions on the joiner node and receives them from the donorSST is forced if a requested seqno is not available in the writeset-cache or gcache

The Rule of Threes
• With PXC, try to have three of everything
▪ If you span a data center, have 3 data centers
▪ If your nodes are on a switch, try to have 3 switches
▪ PXC really needs at least three nodes in the cluster. An odd number is preferred for voting reasons.
▪ Forget about trying to keep a cluster alive during failure with only two data centers. You are better off making one a DR site and performing failover manually. Bootstrapping will be required to make a node primary. BEWARE, however, if the original data center comes back online as you can end up with divergent clusters.
▪ Forget about custom weighting to try to get by on two data centers. The 51% rule will get you anyway!

How many data centers do I have?
• What if I only have 1 data center?
▪ You can gain protection against a single failed node, or more, depending on the cluster size
• What if I have 2 data centers?
▪ You should probably be considering the second data center as a DR solution with a manual failover with PXC
• What about 3 or more?
▪ Most robust solution for Galera-based clusters such as PXC, offering capability of losing a data center or node

How do I plan for Disaster Recovery?
• Make sure the DR node(s) can handle the traffic, if even at minimized performance level
▪ Many times these nodes are under-powered
• Replicating from a PXC Cluster to a DR site
▪ Asynchronous Replication from PXC to a single node
▪ Asynchronous Replication from PXC to a replication topology
▪ Asynchronous Replication from PXC to another PXC cluster

What storage engine(s) do I need?
• MHA ▪ Not storage engine dependent. Works
with all storage engines
• PXC ▪ Requires InnoDB. ▪ Support for MyISAM is experimental and
should not be used in Production
• DRBD ▪ InnoDB is highly suggested for its
journaling capability
• MySQL Cluster ▪ Requires NDB Storage Engine
Build Fix
Optimize Manage

Load Balancer Options
• HAProxy ▪ Open-source software solution ▪ Cannot split reads and writes. If that is a requirement, the app
will need to do it!
• F5 BigIP ▪ Typical hardware solution
• MaxScale ▪ Can do read/write splitting
• ProxySQL ▪ Can also read/write splitting
• Elastic Load Balancer (ELB) ▪ Amazon solution

What happens if the cluster reboots?
• A power outage in a single data center could lead to issues
▪ PXC can be configured to auto bootstrap. ▪ See the pc.recovery option. ▪ Useful for automatic recovery from full cluster crashes, such as a
power outage in the data center. ▪ Graceful full cluster restarts without the need to explicitly bootstrap
a new Primary component.
• Surviving a Reboot
▪ Helpful if nodes are shutdown by a System Administrator for a reboot or other such process
▪ Normal shutdown sets the seqno in the grastate.dat file properly

Do I need to be able to read after writing?
• Asynchronous Replication does not guarantee consistent views of data across nodes
• PXC offers Causal Reads
▪ Replica will wait for the event to be applied before processing additional queries, guaranteeing a consistent read state across nodes.
▪ Older versions wsrep_causal_reads option.
▪ Newer versions use wsrep_sync_wait. ▪ When enabled, the node will block new
queries until it catches up on all pending updates until the time of the check.
▪ Will almost certainly increase latency. ▪ Depending upon value, you can choose
the type of check performed.

PXC Causality Check Settings
0 : Disabled
1 : Checks on READS (SELECT/SHOW/BEGIN/START TRANSACTION)
2 : Checks on UPDATE/DELETE statements
3 : Basically options 1 & 2 above
4 : Checks made on INSERT & REPLACE statements

What if I do a lot of data loading?
• In the recent past, it was conventional wisdom to use replication in such scenarios over PXC.
• MTS does help if data is distributed over multiple schemas but is not a fit for all situations, especially if loading to a single database!
• PXC is now a viable option since we discovered a bug in Galera which did not properly split large transactions. The wsrep_load_data_splitting option was not working properly.Previously had to split transactions manually at approximately every 10,000 records.This was fixed as of PXC version 5.6.30.

Have I taken precautions against split brain?
• Split Brain occurs when a cluster has its nodes divided from one another, most often due to network blip, and nodes form two or more new and independent (and thus divergent) clusters
• PXC is configured to go into a non-primary state and refuse to take traffic
• A newer setting with PXC will allow for dirty reads for non-primary nodes
• Solutions such as Corosync/Pacemaker also have this issue and usually use STONITH to deal with this.

Does my app require high concurrency?
• Newer approaches to replication allow for parallel threads (PXC has had this from the beginning.), such as Multi-Thread Slaves (MTS)
• MTS
▪ Allows a replica to have multiple SQL threads all with their own relay logs
▪ Traditionally replication to the Slave is a single thread which is why it is a challenge for Slaves to keep up with Masters who are taking multiple threads/connections
▪ Enable GTID to make backups via Percona XTRABackup safer due to not being able to trust SHOW SLAVE STATUS to get relay log position

Am I limited on RAM?
• Some Distributed solutions such as MySQL Cluster require a lot of RAM, even with file-based tables. Be sure to plan appropriately.
• PXC works much more like a stand-alone node and RAM is only assigned in the traditional MySQL manner to the buffers, caches, etc.
How stable is my network?
• No matter what Network Engineers tell you, networks are not 100% reliable.
• Some “Network Problems” are due to outside factors such as system resource contention (especially on virtual machines)
• Network problems cause inappropriate failover issues.
• Use LAN segments with PXC to minimize network traffic across WAN

Making the right choice depends upon...
• Knowing what you really need!
• Knowing your options.
• Knowing your constraints!
• Understanding the pros/cons of each solution
• Setting expectations properly!


Stay in Contact
Email: [email protected]
Skype: percona.mpatrick
Blog: https://www.percona.com/blog/author/michael-patrick/

Q & ATime to take your questions!

DATABASE PERFORMANCE MATTERS

















