
Methodologies and approaches for repository aggregation Pat Lockley University of Nottingham 19 th...
18
Methodologies and approaches for repository aggregation Pat Lockley University of Nottingham 19 th April 2010
-
Upload
allan-black -
Category
Documents
-
view
218 -
download
2
Transcript of Methodologies and approaches for repository aggregation Pat Lockley University of Nottingham 19 th...

Methodologies and approaches for repository aggregation
Pat LockleyUniversity of Nottingham19th April 2010

I’ve got a brand new combined harvester and I’ll give you the keyPat LockleyUniversity of Nottingham19th April 2010

The theory
Out in the world are lots of repositories using RSS feeds

The theory continued……….
So one site could bring all those feeds together, without the need to upload

The theory continues……….
At Nottingham we have Xerte Online Toolkits
This allows for content to be created online, and as one of it’s features allows for the simple automated creation of DCMI rich RSS feeds
Xerte Online Toolkits is free and open source
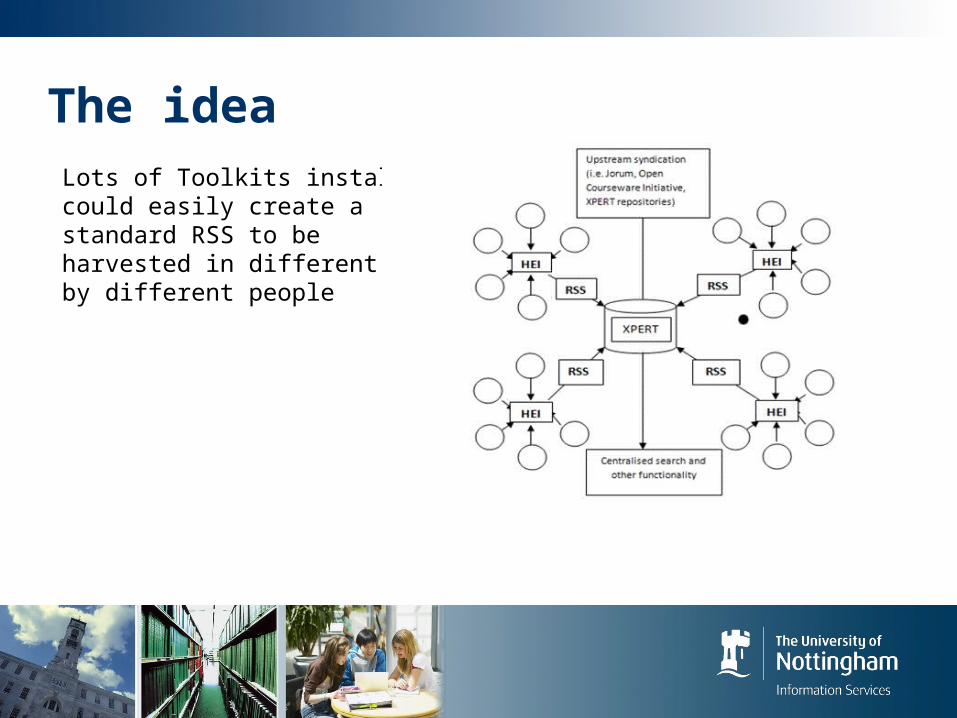
The ideaLots of Toolkits installs could easily create a standard RSS to be harvested in different ways by different people

The process… Robot #1So we built a harvester, a bit like a basic web robot
This would go off and get the RSS feeds, download them to a server, and look in the data for OER materials.
Given RSS feeds are a standard, this would be an easy task…..

The 2nd robot…Sadly, even between DCMI rich RSS and normal RSS there are differences
The link node, which contains the URL of the OER piece is sometimes empty
Sometimes other nodes are used
So gradually the robot got smarter…..

The 3rd robot…Now we had to tell which feed type was which….
Establishing a fingerprint
Knowing what your “fetching”
Getting as much metadata as possible
But…..

The 4th robot…Metadata comes in many forms, so the robot needs to be aware
Subject
Category
Author
Creator
Description
Related content

The 5th robot…Taking a preference
Dealing with conflict
Dealing with spam
Dealing with bad metadata

The 6th robot…Don’t forget we have users, all this metadata needs to be searchable
Does the user care?
Results driven approach?
How to search best?
Search evaluation?
Does it need an explanation?

The 7th robot…What to do when the RSS isn’t even RSS
80 RSS feeds
20 aren’t valid
5 aren’t XML

The 8th robot…RSS for humans or machines
All of the content?
Some of the content?
How do we want to talk?

The 9th robot…Is there more content in other forms?
OPML?
RSS?
OAI?
SRU?
Thinking beyond the field?

The 10th robot…Making it all make sense
Effort to make an aggregator
Harmonisation
Handling new challenges
Scope

The 11th robot…Making it smart
Harvests every day (approximately 25 new items a day)
Knows which items have been deleted
Knows which items have moved
Knows what people are looking for

Contacts
Pat Lockley - XpertJulian Tenney - XerteSteven Stapleton – Berlin OER


















