
Mehr und schneller ist nicht automatisch besser - data2day, 06.10.16
35
Mehr und schneller ist nicht automatisch besser Dr. Boris Adryan @BorisAdryan
-
Upload
boris-adryan -
Category
Data & Analytics
-
view
303 -
download
0
Transcript of Mehr und schneller ist nicht automatisch besser - data2day, 06.10.16

Mehr und schneller ist nicht automatisch besser
Dr. Boris Adryan @BorisAdryan

Dr. Boris Adryan• with Zühlke Engineering since September 2016
• longstanding IoT enthusiast • Founder of thingslearn Ltd. • Board Member & Strategic Advisor for Pycom
(microcontrollers), BioSelf (biosensors) and OpenSensors (IoT platform)
• before: research group leader for data analytics and machine learning at University of Cambridge, England
@BorisAdryan

Vision 2020
Planung, Umsetzung, Betrieb
Ihr Partner für Business Innovation
Vernetzte System, neue Geschäftsmodelle

39% of survey participants are worried about the cost of an industrial IoT solution.
“Why aren’t you doing IoT?”

IoT cost expectations
many sensors + complicated analytics + expensive infrastructure —————————————— IoT has little benefit
“…because my data scientist said the more the better ”
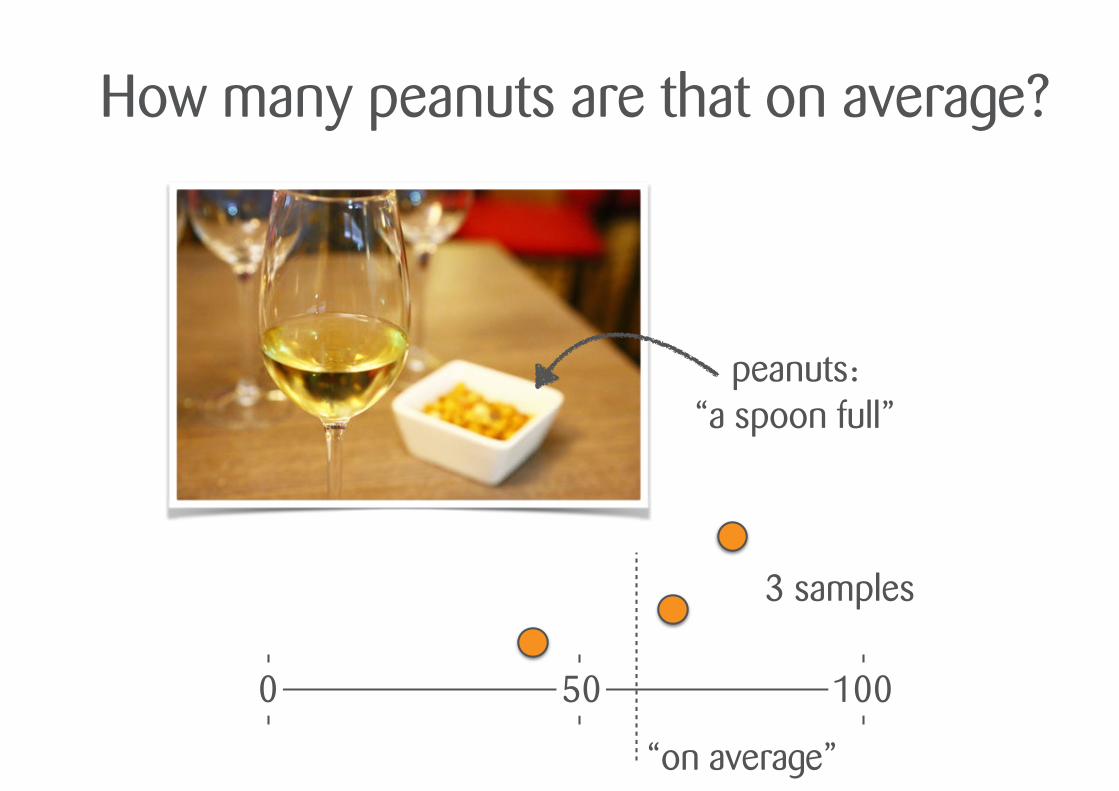
peanuts: “a spoon full”
How many peanuts are that on average?
0 50 100
“on average”
3 samples
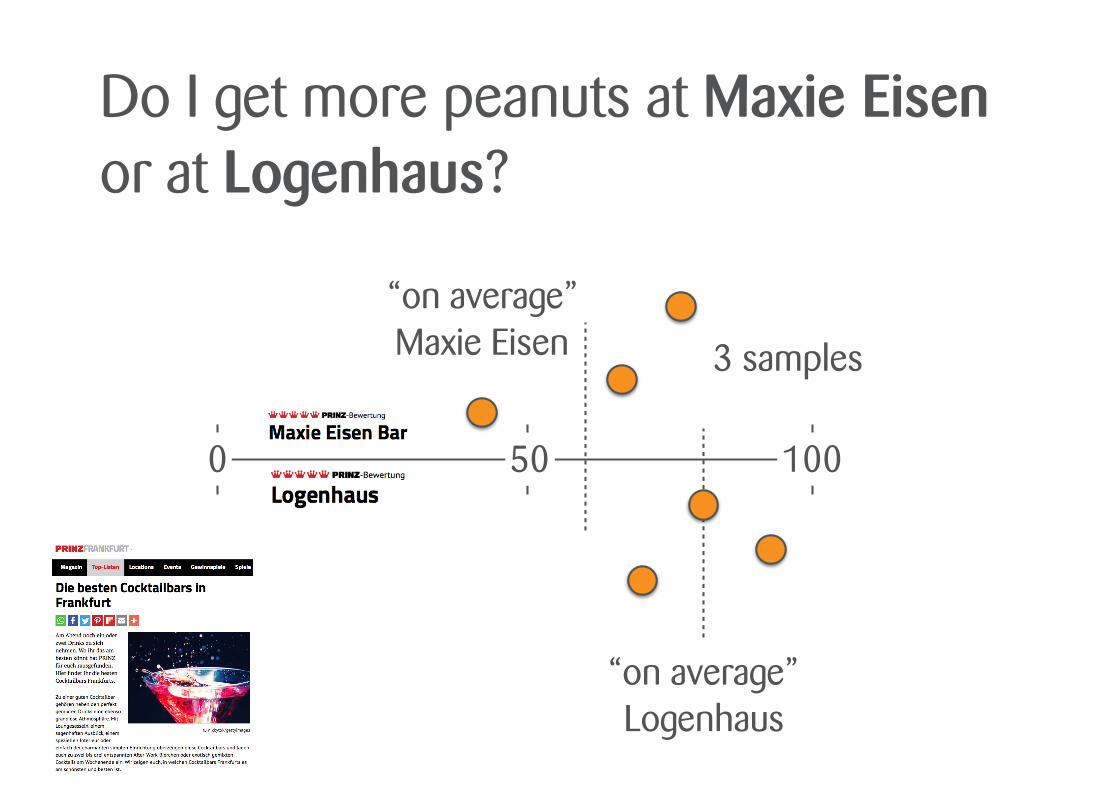
Do I get more peanuts at Maxie Eisen or at Logenhaus?
0 50 100
“on average” Maxie Eisen 3 samples
“on average” Logenhaus
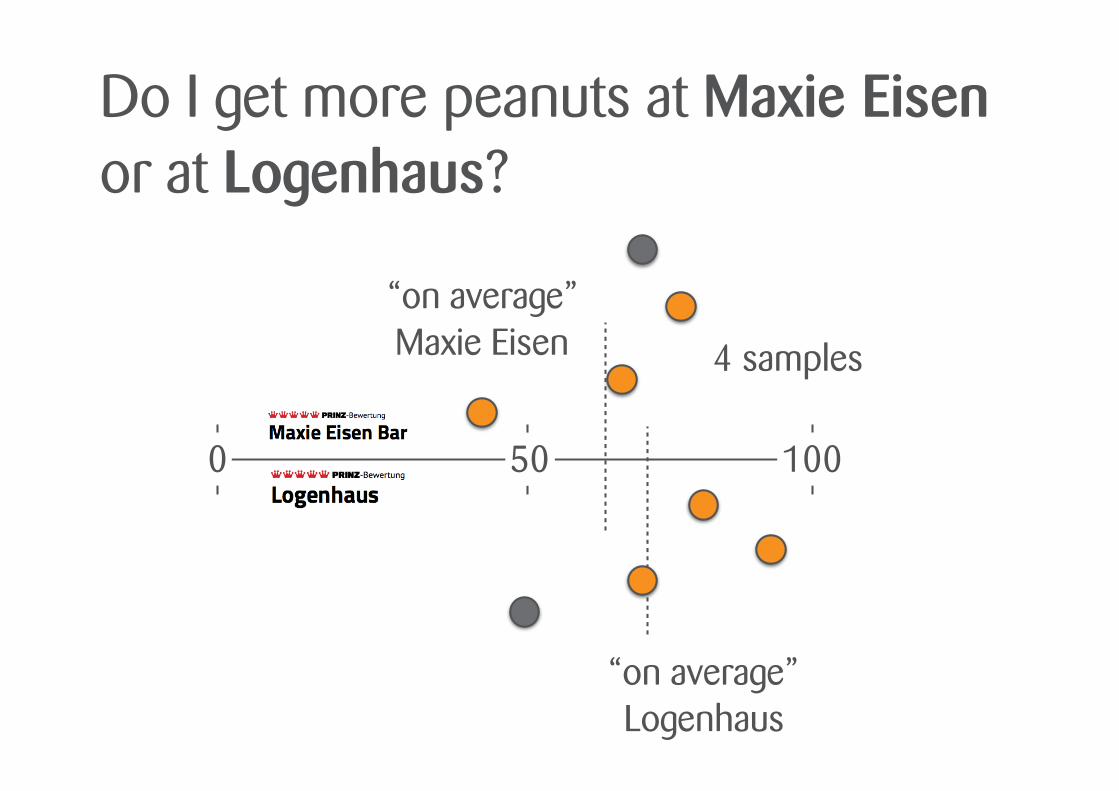
0 50 100
4 samples
Do I get more peanuts at Maxie Eisen or at Logenhaus?
“on average” Maxie Eisen
“on average” Logenhaus

0 50 100
n samples
statistical power through large numbers of samples
deviation
Do I get more peanuts at Maxie Eisen or at Logenhaus?
“on average” Maxie Eisen
“on average” Logenhaus
Statisticians and data scientists LOVE larger sample sizes!
…but if sampling costs time and resources, we need a compromise.
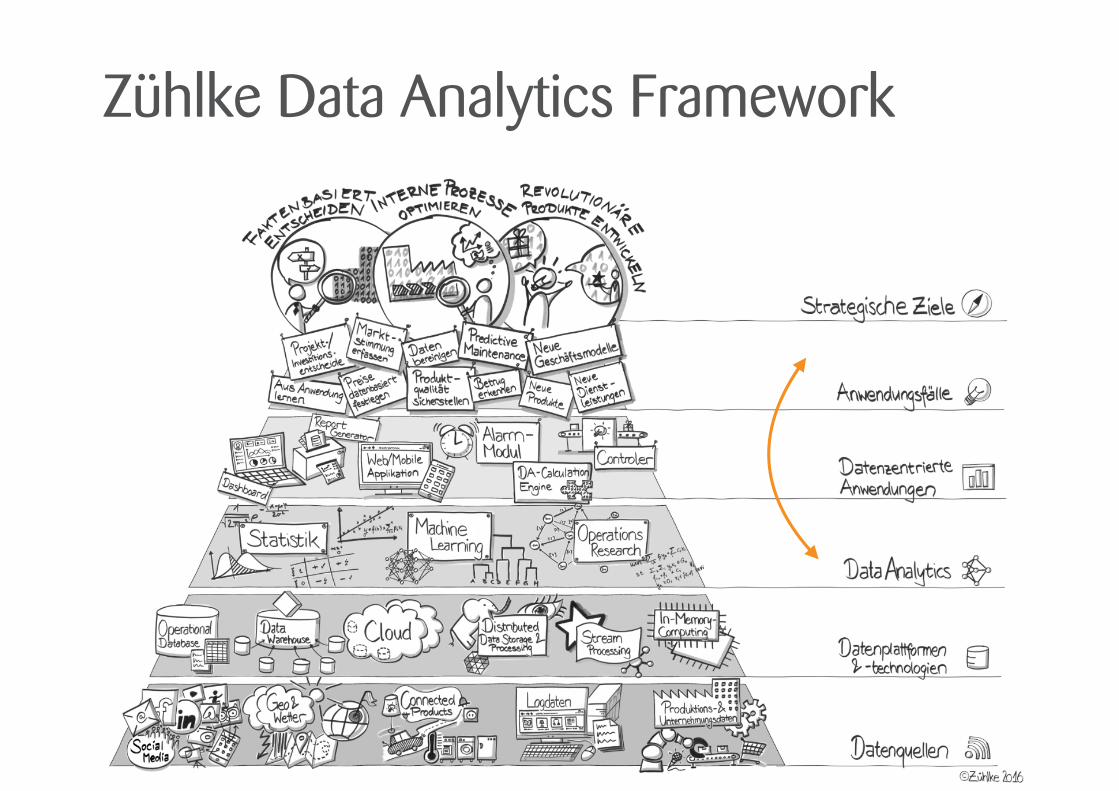
Zühlke Data Analytics Framework
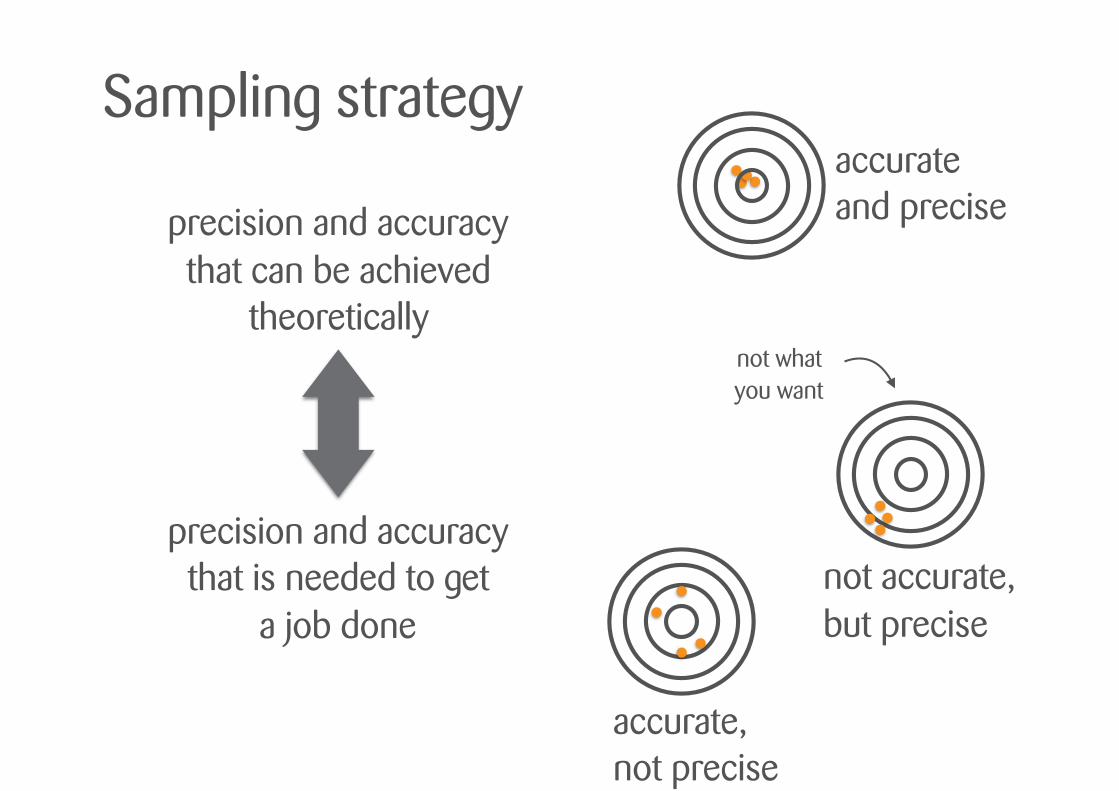
precision and accuracy that can be achieved
theoretically
Sampling strategy
precision and accuracy that is needed to get
a job done
accurate and precise
not accurate, but precise
accurate, not precise
not what you want

• how to cut down on hardware costs
• how to cut down on software costs
Sweetening IoT for your customer
A few recommendations from the trenches:
many sensors + complicated analytics + expensive infrastructure —————————————— IoT has little benefit
less
reasonable

Westminster Parking Trial
https://www.westminster.gov.uk/new-trial-improve-conditions-disabled-drivers
IoT solution
Service company
~750 independent parking lots with a total of
>3,500 individual spaces
access to

Humans don’t scale that well…
labour: expensive
sensor: cheap
While the cost of the sensors is falling (and follows Moore’s Law), digging them in and out for deployment and maintenance is a significant cost factor.

Can we learn an optimal deployment and sampling pattern?
•sampling rate of 5-10 min •data over 2 weeks in May 2015 •overall 2.6 million data points
Can we make customers’ budget go further by • reducing the number of sensors in a geographic area? • lowering the sampling rate for better battery life?
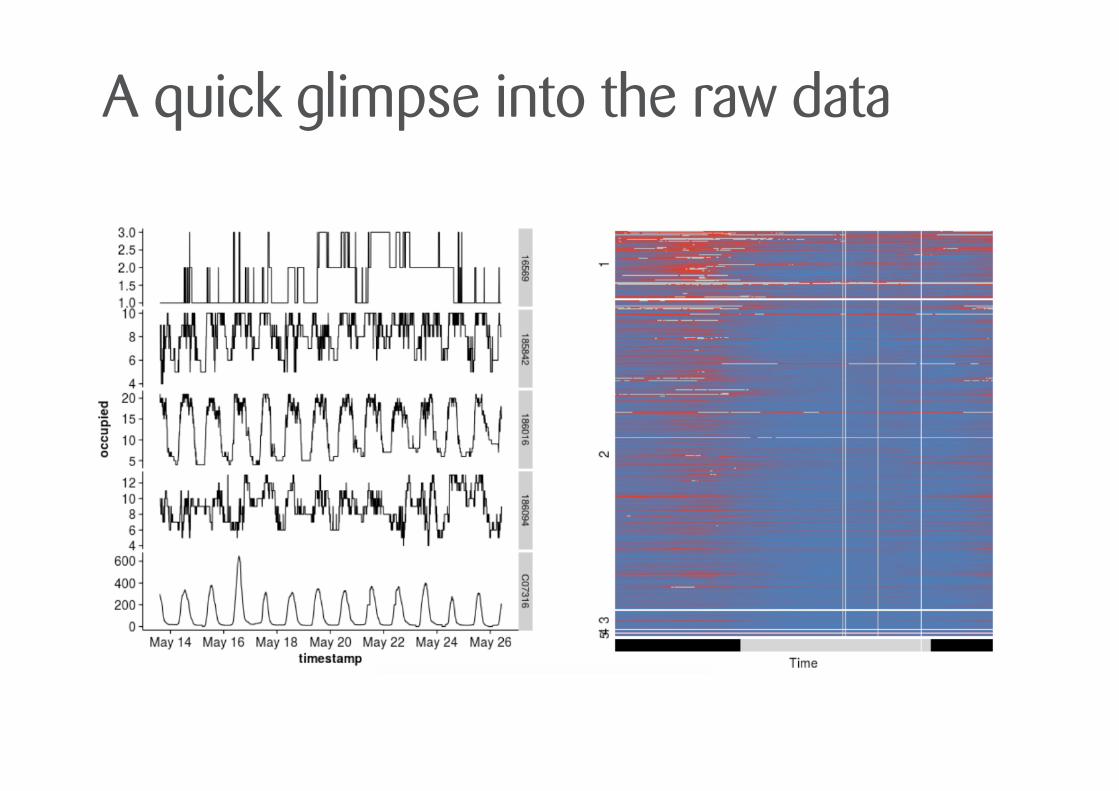
A quick glimpse into the raw data

Correlation and clustering
0
5
10
15
20
0 3 6 9 12
“correlated”
0
5
10
15
20
0 3 6 9 12
“anti-correlated”
0
5
10
15
20
0 3 6 9 12
“independent”
lorry
coach
car
bike
skateboard
hierarchical clustering on the basis of a feature matrix
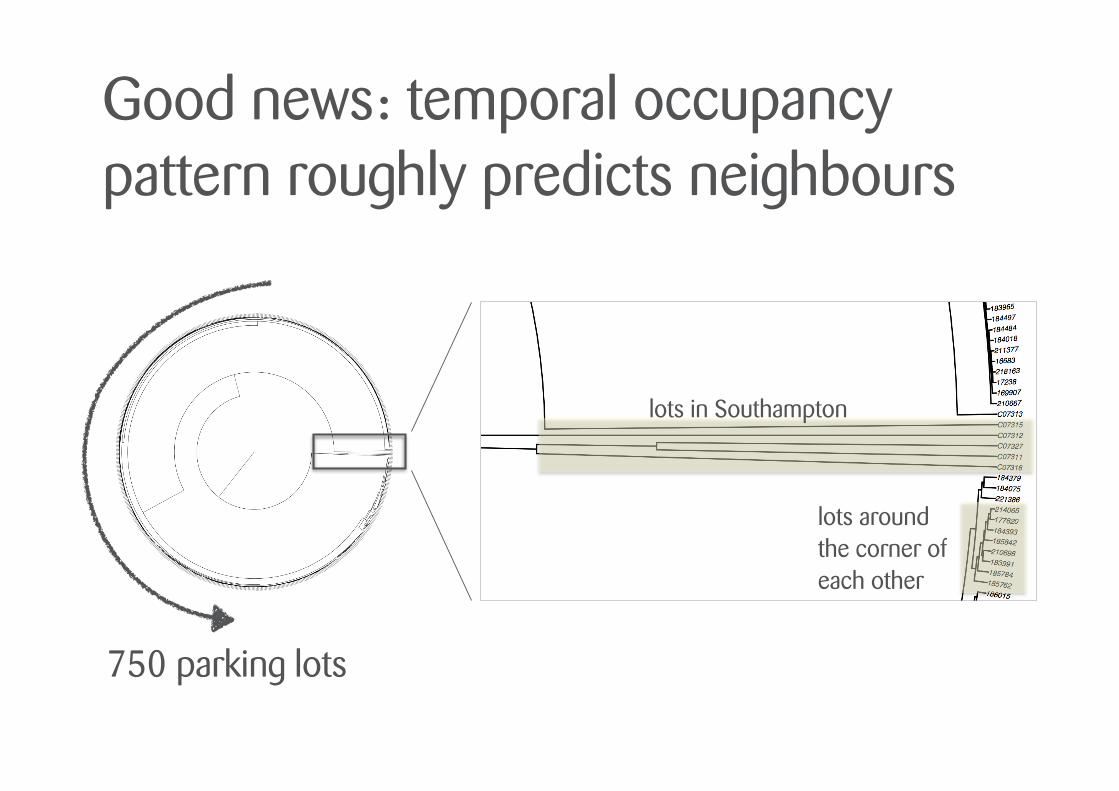
Good news: temporal occupancy pattern roughly predicts neighbours
lots in Southampton
lots around the corner of each other
750 parking lots

A caveat: Is a high-degree of correlation a function of parking lot size?
finding two lots of 20 spaces that correlate
finding two lots of 3 spaces that correlate
0:00 12:00 23:59
0:00 12:00 23:59
“more likely”
“less likely”

Bootstrapping in DBSCAN clusters
Simulation: Swap the occupancy vectors between parking lots of similar size and test per grid cell if these lots still correlate

What makes a good spatial cluster?

Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
https://en.wikipedia.org/wiki/DBSCAN#/media/File:DBSCAN-Illustration.svg
2 parameters:
epsilon (distance) minPoints (in cluster)
A - core points B, C - corner points N - noise point

Stratification strategy
3 lots with cc > 0.5
2 spaces 4 spaces 4 spaces
Test:
1. Take occupancy profile of ONE random 2-space parking lot and TWO random 4-space parking lots.
2. Determine cc.
3. Repeat n times and get a cc distribution for that parking lot combination.

Combining stats with street knowledge

Verdict: In some grid cells the level of the occupancy of one parking lot predicts the occupancy of most parking spaces.
x
x
x
x
x
x
x
xx x x
xxxx
x
Better for navigation
We suggested that about 60% of the sensors may be sufficient.
Better predictive power

Suggested technology for trials
A temporary survey would have allowed us to make the same recommendation, including the insight that the provided 5’ resolution is probably not required.

• how to cut down on hardware costs
• how to cut down on software costs
Sweetening IoT for your customer
A few recommendations from the trenches:
many sensors + complicated analytics + expensive infrastructure —————————————— IoT has little benefit
less
reasonable

My current pet hate: Deep Learning
Deep learning has delivered impressive results mimicking human reasoning, strategic thinking and creativity.
At the same time, big players have released libraries such that even ‘script kiddies’ can apply deep learning.
It’s already leading to unreflected use of deep learning when other methods would be more appropriate.
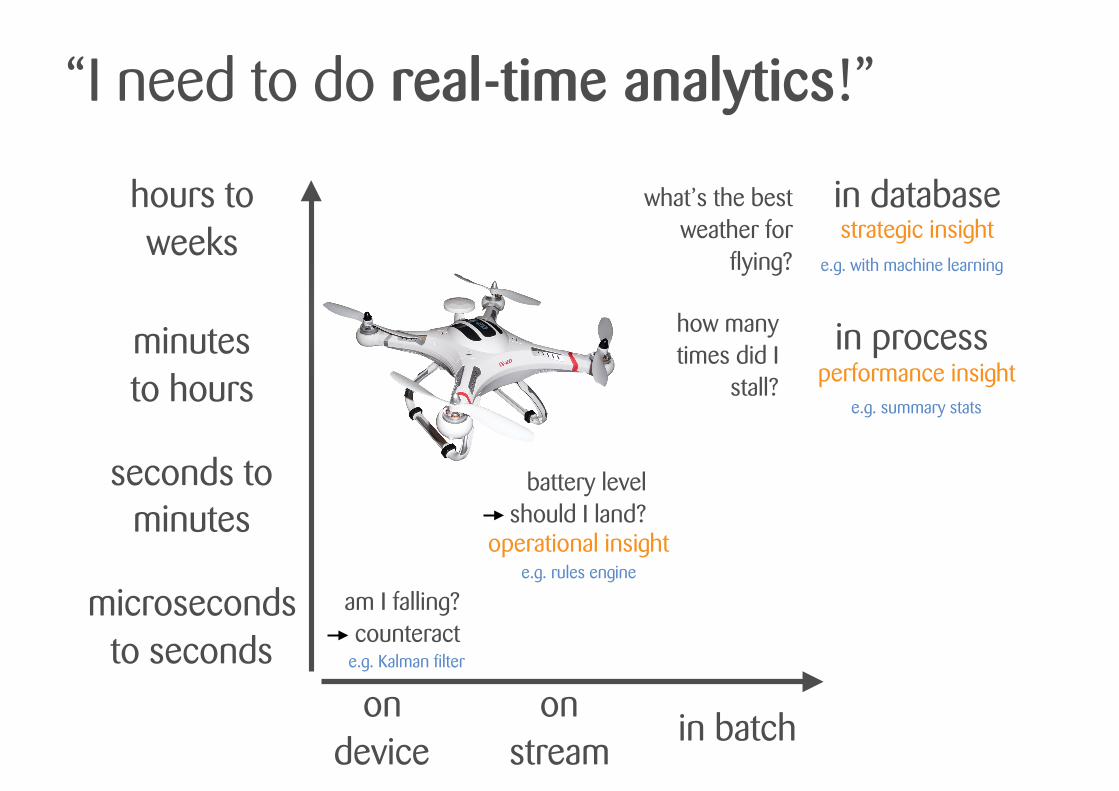
“I need to do real-time analytics!”
microseconds to seconds
seconds to minutes
minutes to hours
hours to weeks
on device
on stream
in batch
am I falling? counteract
battery level should I land?
how many times did I
stall?
what’s the best weather for
flying?
in process
in database
operational insight
performance insight
strategic insight
e.g. Kalman filter
e.g. with machine learning
e.g. rules engine
e.g. summary stats
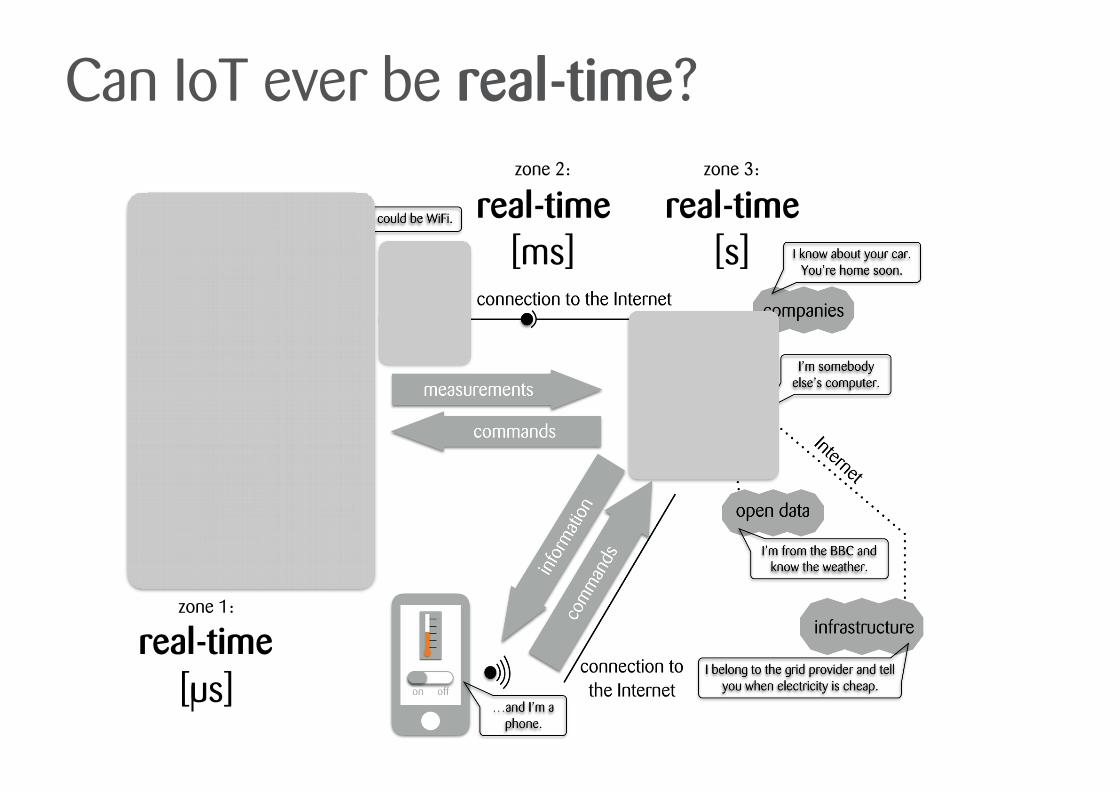
Can IoT ever be real-time?
zone 1:
real-time [us]
zone 2:
real-time [ms]
zone 3:
real-time [s]

Edge, fog and cloud computing
Edge Pro: - immediate compression from raw
data to actionable information - cuts down traffic - fast response
Con: - loses potentially valuable raw data - developing analytics on embedded
systems requires specialists - compute costs valuable battery life
Cloud Pro: - compute power - scalability - familiarity for developers - integration centre across
all data sources - cheapest ‘real-time’
option
Con: - traffic
Fog Pro: - same as Edge - closer to ‘normal’ development work - gateways often mains-powered
Con: - loses potentially valuable raw data

Some of our examples for real-time analytics
Choosing the appropriate method and toolset on every level.
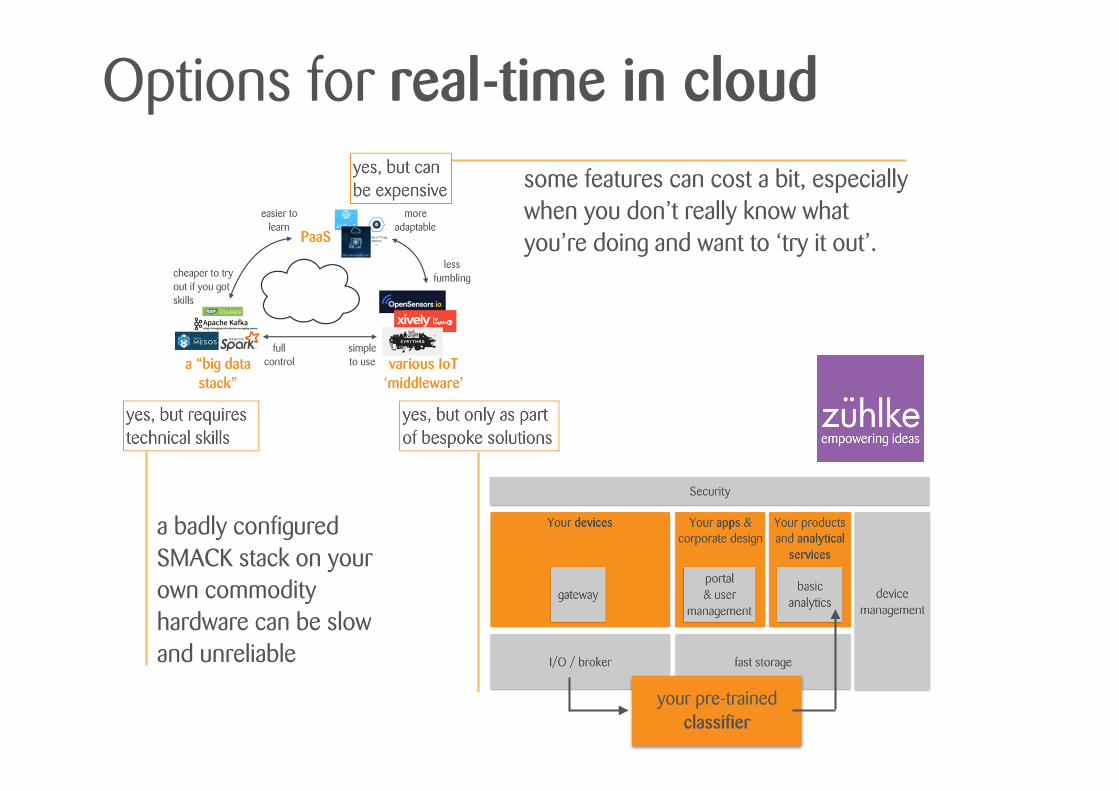
Options for real-time in cloudsome features can cost a bit, especially when you don’t really know what you’re doing and want to ‘try it out’.
a badly configured SMACK stack on your own commodity hardware can be slow and unreliable
your pre-trained classifier

Dr. Boris Adryan @BorisAdryan
‣ Preliminary surveys and data analysis can help to minimise the number of sensors and develop an optimal deployment strategy and sampling schedule.
‣ Super-fast analytics and state-of-the-art methods are not automatically the most useful solution.
‣ A good understanding on the type of insight that is required by the business model is essential.
Zühlke can advise on options around IoT and data analytics, and provide complete solutions where needed.
Summary
















