
Meetup oslo hortonworks HDP
65
© Hortonworks Inc. 2014 Page 1 Hortonworks Mats Johansson, Solutions Engineer
-
Upload
alexander-bakos-leirvag -
Category
Software
-
view
252 -
download
4
Transcript of Meetup oslo hortonworks HDP

© Hortonworks Inc. 2014 Page 1
Hortonworks Mats Johansson, Solutions Engineer

© Hortonworks Inc. 2014 Page 2
Agenda
• Introduction • Hadoop Drivers & Use Cases
• Reference Architectures • Ingest
• Transform • Consume

© Hortonworks Inc. 2014 Page 3
Hadoop for the Enterprise: Implement a Modern Data Architecture with HDP
Customer Momentum
• 230+ customers (as of Q3 2014)
Hortonworks Data Platform • Completely open multi-tenant platform for any app & any data. • A centralized architecture of consistent enterprise services for
resource management, security, operations, and governance.
Partner for Customer Success • Open source community leadership focus on enterprise needs • Unrivaled world class support
• Founded in 2011 • Original 24 architects, developers,
operators of Hadoop from Yahoo! • 600+ Employees • 800+ Ecosystem Partners
© Hortonworks Inc. 2014 Page 4
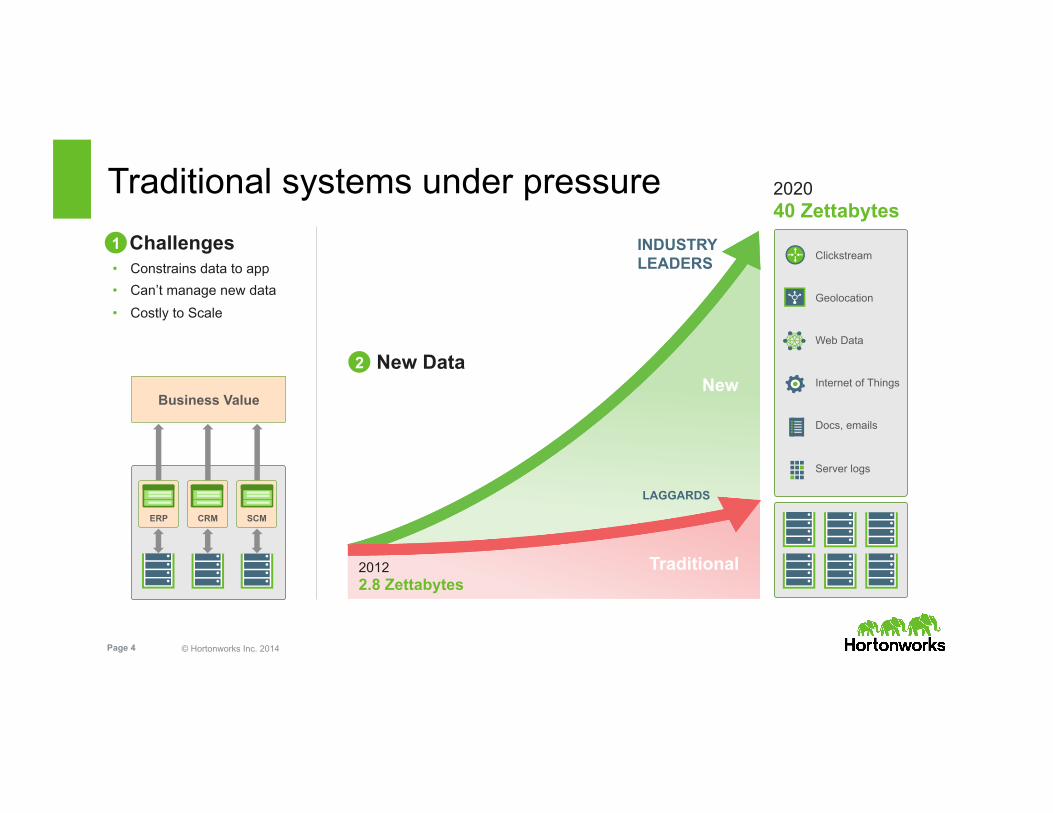
Traditional systems under pressure Challenges • Constrains data to app • Can’t manage new data • Costly to Scale
Business Value
Clickstream
Geolocation
Web Data
Internet of Things
Docs, emails
Server logs
2012 2.8 Zettabytes
2020 40 Zettabytes
LAGGARDS
INDUSTRY LEADERS
1
2 New Data
ERP CRM SCM
New
Traditional

© Hortonworks Inc. 2014 Page 5
Hadoop emerged as foundation of new data architecture
Apache Hadoop is an open source data platform for managing large volumes of high velocity and variety of data • Built by Yahoo! to be the heartbeat of its ad & search business
• Donated to Apache Software Foundation in 2005 with rapid adoption by large web properties & early adopter enterprises
• Incredibly disruptive to current platform economics
Traditional Hadoop Advantages ü Manages new data paradigm ü Handles data at scale ü Cost effective ü Open source
Traditional Hadoop Had Limitations Batch-only architecture Single purpose clusters, specific data sets Difficult to integrate with existing investments Not enterprise-grade
Application
Storage HDFS
Batch Processing MapReduce
© Hortonworks Inc. 2014 Page 6
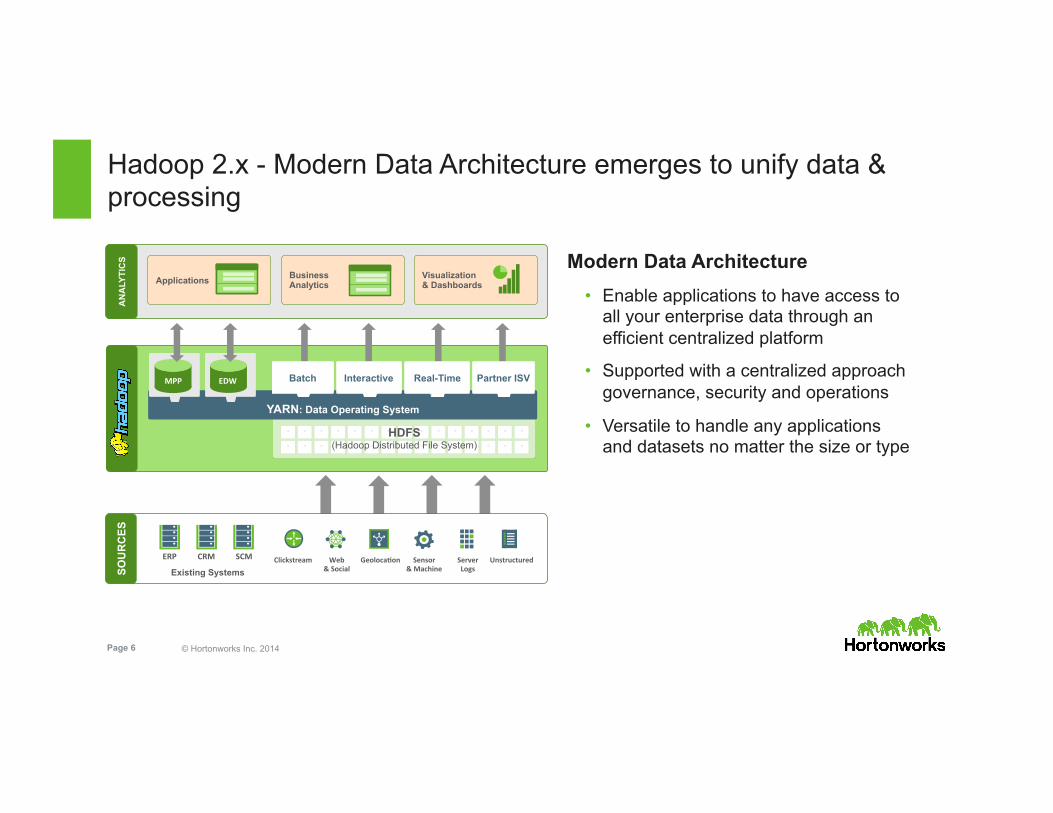
Hadoop 2.x - Modern Data Architecture emerges to unify data & processing
Modern Data Architecture • Enable applications to have access to
all your enterprise data through an efficient centralized platform
• Supported with a centralized approach governance, security and operations
• Versatile to handle any applications and datasets no matter the size or type
Clickstream Web & Social
Geoloca3on Sensor & Machine
Server Logs
Unstructured
SOU
RC
ES
Existing Systems
ERP CRM SCM
AN
ALY
TIC
S
Data Marts
Business Analytics
Visualization & Dashboards
AN
ALY
TIC
S
Applications Business Analytics
Visualization & Dashboards
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
HDFS (Hadoop Distributed File System)
YARN: Data Operating System
Interactive Real-Time Batch Partner ISV Batch Batch MPP EDW

© Hortonworks Inc. 2014 Page 7
HDP delivers a comprehensive data management platform
Hortonworks Data Platform 2.2
YARN: Data Operating System (Cluster Resource Management)
1 ° ° ° ° ° ° °
° ° ° ° ° ° ° °
Script
Pig
SQL
Hive
Tez Tez
Java Scala
Cascading
Tez
° °
° °
° ° ° ° °
° ° ° ° °
Others
ISV Engines
HDFS (Hadoop Distributed File System)
Stream
Storm
Search
Solr
NoSQL
HBase Accumulo
Slider Slider
SECURITY GOVERNANCE OPERATIONS BATCH, INTERACTIVE & REAL-TIME DATA ACCESS
In-Memory
Spark
Provision, Manage & Monitor
Ambari
Zookeeper
Scheduling
Oozie
Data Workflow, Lifecycle & Governance
Falcon Sqoop Flume Kafka NFS
WebHDFS
Authentication Authorization Accounting
Data Protection
Storage: HDFS Resources: YARN Access: Hive, … Pipeline: Falcon
Cluster: Knox Cluster: Ranger
Deployment Choice Linux Windows On-Premises Cloud
YARN is the architectural center of HDP
Enables batch, interactive and real-time workloads
Provides comprehensive enterprise capabilities
The widest range of deployment options
Delivered Completely in the OPEN
© Hortonworks Inc. 2014 Page 8
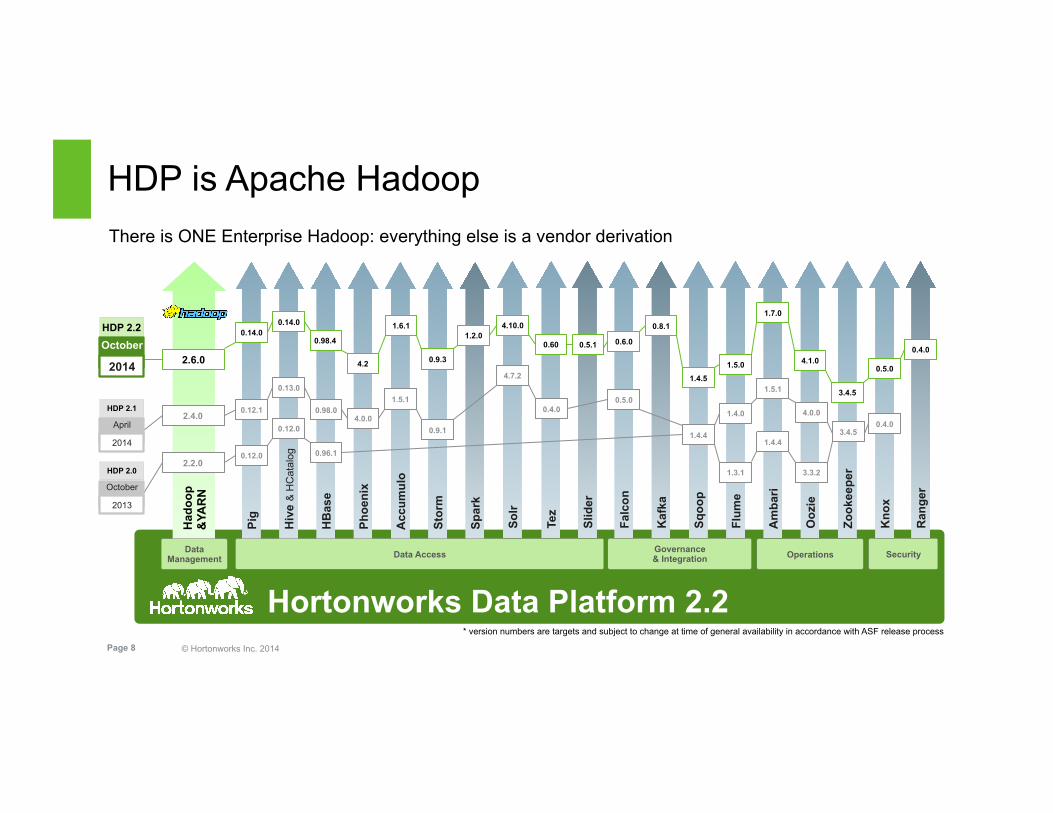
HDP is Apache Hadoop
There is ONE Enterprise Hadoop: everything else is a vendor derivation
Hortonworks Data Platform 2.2
Had
oop
&YA
RN
Pig
Hiv
e &
HC
atal
og
HB
ase
Sqo
op
Ooz
ie
Zoo
keep
er
Am
bari
Sto
rm
Flu
me
Kno
x
Pho
enix
Acc
umul
o
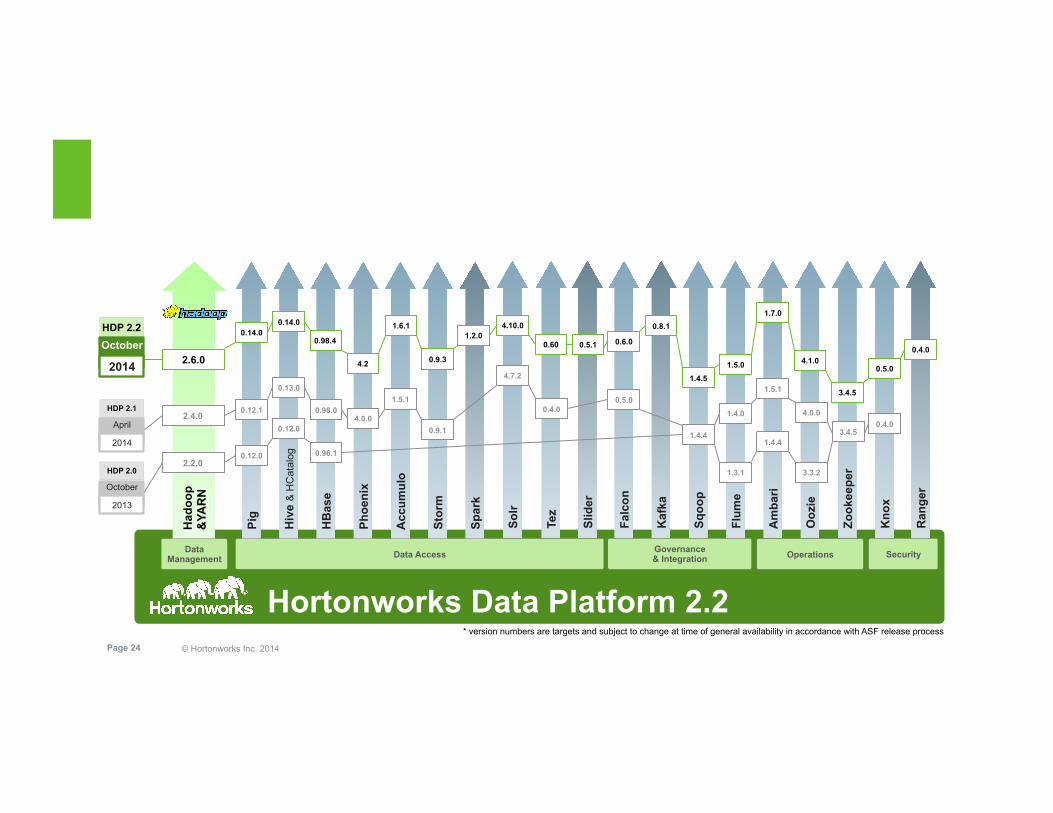
2.2.0 0.12.0
0.12.0 2.4.0
0.12.1
Data Management
0.13.0
0.96.1
0.98.0
0.9.1 1.4.4
1.3.1
1.4.0
1.4.4
1.5.1
3.3.2
4.0.0
3.4.5 0.4.0
4.0.0
1.5.1
Fal
con
0.5.0
Ran
ger
Spa
rk
Kaf
ka
0.14.0 0.14.0
0.98.4
1.6.1
4.2 0.9.3
1.2.0 0.6.0
0.8.1
1.4.5 1.5.0
1.7.0
4.1.0 0.5.0
0.4.0 2.6.0
* version numbers are targets and subject to change at time of general availability in accordance with ASF release process
3.4.5
Tez
0.4.0
Slid
er
0.60
HDP 2.0
October
2013
HDP 2.2 October
2014
HDP 2.1
April
2014
Sol
r
4.7.2
4.10.0
0.5.1
Data Access Governance & Integration Security Operations

© Hortonworks Inc. 2014 Page 9
HDP: Any Data, Any Application, Anywhere
Any Application • Deep integration with ecosystem
partners to extend existing investments and skills
• Broadest set of applications through the stable of YARN-Ready applications
Any Data Deploy applications fueled by clickstream, sensor, social, mobile, geo-location, server log, and other new paradigm datasets with existing legacy datasets.
Anywhere Implement HDP naturally across the complete range of deployment options
Clickstream Web & Social
Geoloca3on Internet of Things
Server Logs
Files, emails ERP CRM SCM
hybrid
commodity appliance cloud
Over 70 Hortonworks Certified YARN Apps

© Hortonworks Inc. 2014 Page 10
Technology Partnerships matter
Apache Project Hortonworks Relationship Named
Partner Certified Solution Resells Joint
Engr
Microsoft u u u u
HP u u u u
SAS u u u
SAP u u u u
IBM u u u
Pivotal u u u
Redhat u u u
Teradata u u u u
Informatica u u u
Oracle u u
It is not just about packaging and certifying software… Our joint engineering with our partners drives open source standards for Apache Hadoop HDP is Apache Hadoop

© Hortonworks Inc. 2014 Page 11
Customer Partnerships matter Driving our innovation through
Apache Software Foundation Projects
Apache Project Committers PMC Members
Hadoop 27 21
Pig 5 5
Hive 18 6
Tez 16 15
HBase 6 4
Phoenix 4 4
Accumulo 2 2
Storm 3 2
Slider 11 11
Falcon 5 3
Flume 1 1
Sqoop 1 1
Ambari 34 27
Oozie 3 2
Zookeeper 2 1
Knox 13 3
Ranger 10 n/a
TOTAL 161 108 Source: Apache Software Foundation. As of 11/7/2014.
Hortonworkers are the architects and engineers that lead development of open source Apache Hadoop at the ASF
• Expertise Uniquely capable to solve the most complex issues & ensure success with latest features
• Connection Provide customers & partners direct input into the community roadmap
• Partnership We partner with customers with subscription offering. Our success is predicated on yours.
27
Cloudera: 11
Facebook: 5
LinkedIn: 2
IBM: 2
Others: 23
Yahoo 10

© Hortonworks Inc. 2014 Page 12
Open Source IS the standard for platform technology Modern platform standards are defined by open communities
For Hadoop, the ASF provides guidelines and a governance framework and the open community defines the standards for Hadoop.
Roadmap matches user requirements not vendor monetization requirements
Hortonworks Open Source Development Model yields unmatched efficiency • Infinite number of developers under governance of ASF applied to problem
• End users motivated to contribute to Apache Hadoop as they are consumers • IT vendors motivated to align with Apache Hadoop to capture adjacent opportunities
Hortonworks Open Source Business Model de-risks investments • Buying behavior changed: enterprise wants support subscription license
• Vendor needs to earn your business, every year is an election year • Equitable balance of power between vendor and consumer
• IT vendors want platform technologies to be open source to avoid lock-in

© Hortonworks Inc. 2014 Page 14
Why do everyone go Hadoop? Drivers

© Hortonworks Inc. 2014 Page 15
Data has Changed
• 90% of the world’s data was created in the last two years
• 80% of enterprise data is unstructured
• Unstructured data growing 2x faster than structured
© Hortonworks Inc. 2014 Page 16
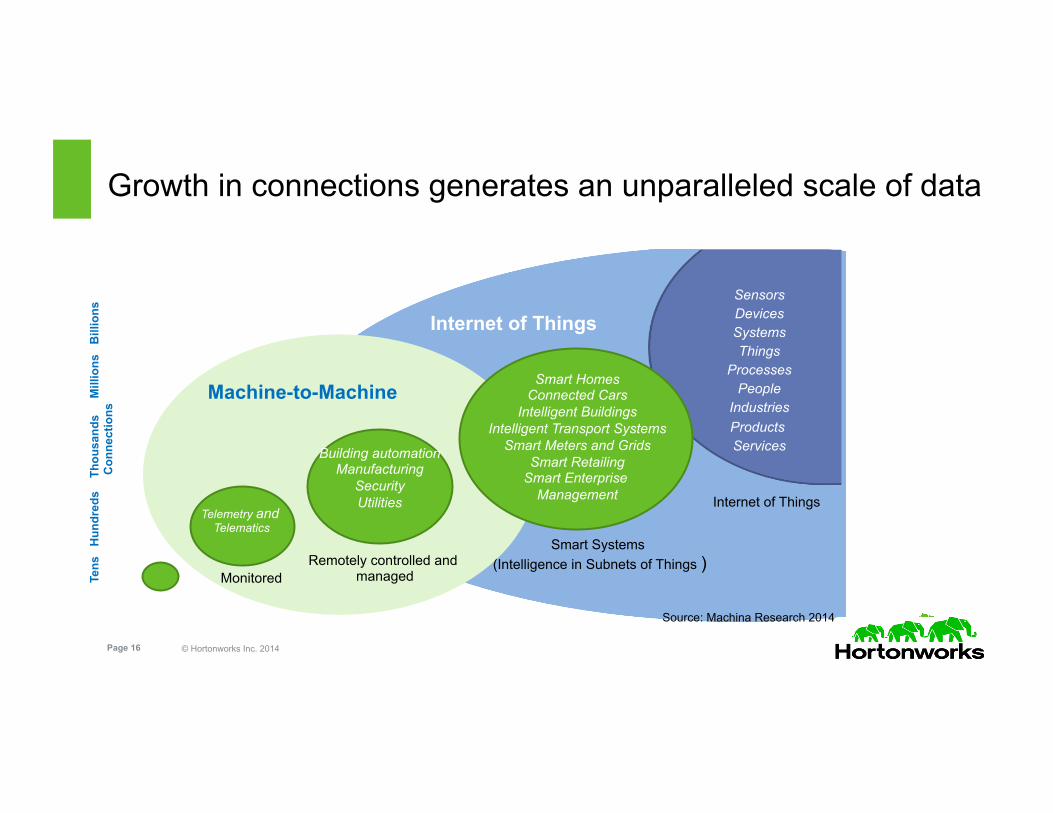
Growth in connections generates an unparalleled scale of data
Tens
H
undr
eds
Th
ousa
nds
M
illio
ns
Bill
ions
C
onne
ctio
ns
Internet of Things
Machine-to-Machine
Monitored
Smart Systems (Intelligence in Subnets of Things )
Telemetry and Telematics
Smart Homes Connected Cars
Intelligent Buildings Intelligent Transport Systems
Smart Meters and Grids Smart Retailing
Smart Enterprise Management
Remotely controlled and managed
Building automation Manufacturing
Security Utilities Internet of Things
Sensors Devices Systems Things
Processes People
Industries Products Services
Source: Machina Research 2014

© Hortonworks Inc. 2014 Page 17
IoT Predictions by 2020
7,1tn IoT Solutions Revenue | IDC
1,9tn IoT Economic Value Add | Gartner
309bn IoT Supplier Revenue | Gartner
50bn Connected Devices | Cisco
14bn Connected Devices | Bosch SI Peter Middleton, Gartner: “By 2020, component costs will have come down to the point that connectivity will become a standard feature, even for processors costing less than
$1
http://postscapes.com/internet-of-things-market-size
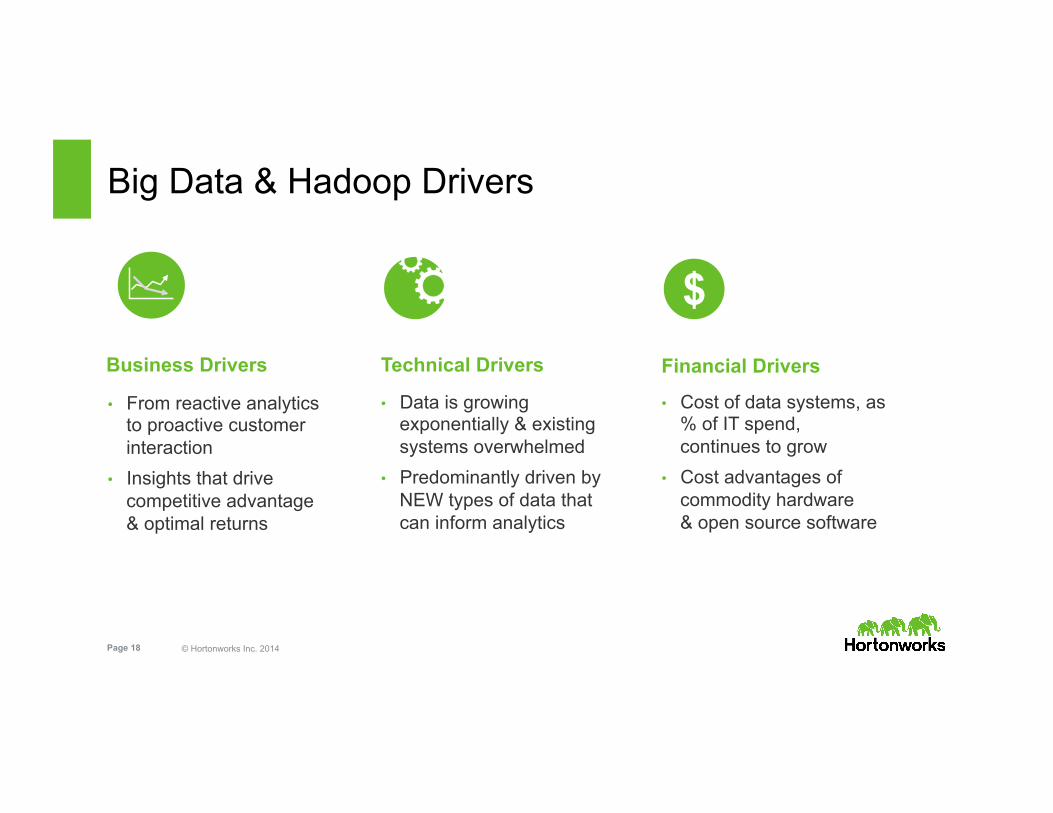
© Hortonworks Inc. 2014 Page 18
Big Data & Hadoop Drivers
Business Drivers
• From reactive analytics to proactive customer interaction
• Insights that drive competitive advantage & optimal returns
Financial Drivers
• Cost of data systems, as % of IT spend, continues to grow
• Cost advantages of commodity hardware & open source software
$
Technical Drivers
• Data is growing exponentially & existing systems overwhelmed
• Predominantly driven by NEW types of data that can inform analytics
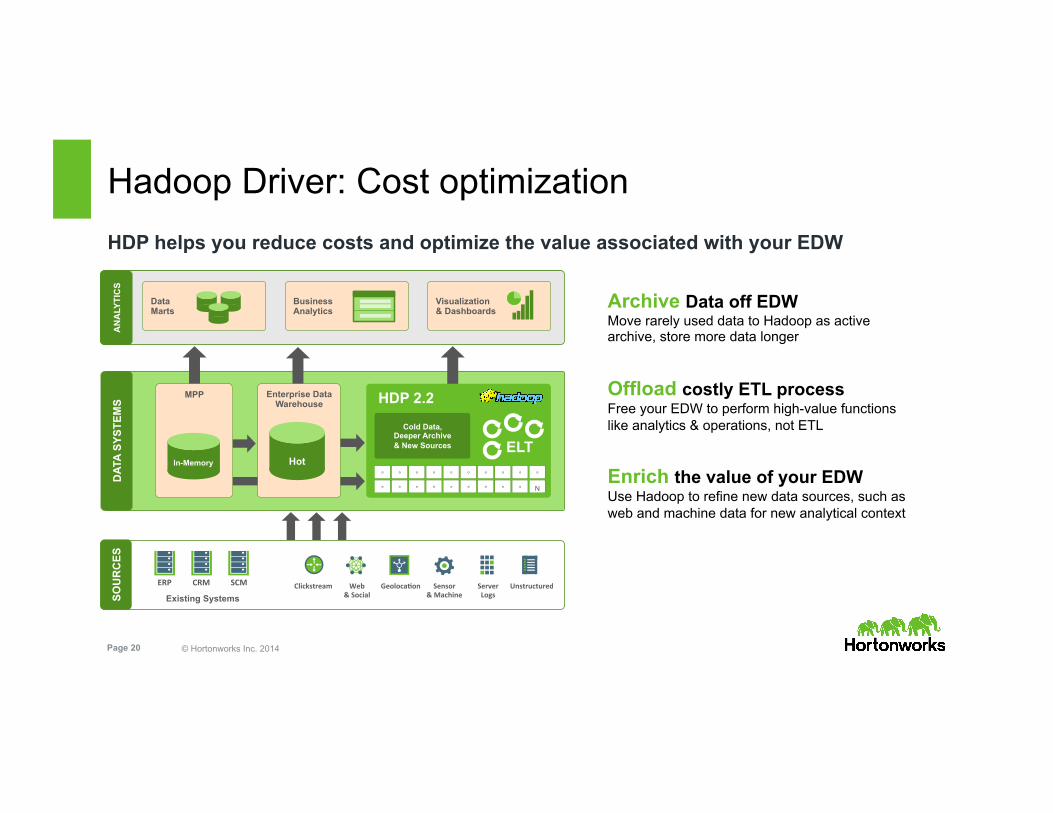
© Hortonworks Inc. 2014 Page 20
Hadoop Driver: Cost optimization
Archive Data off EDW Move rarely used data to Hadoop as active archive, store more data longer
Offload costly ETL process Free your EDW to perform high-value functions like analytics & operations, not ETL
Enrich the value of your EDW Use Hadoop to refine new data sources, such as web and machine data for new analytical context
AN
ALY
TIC
S
Data Marts
Business Analytics
Visualization & Dashboards
HDP helps you reduce costs and optimize the value associated with your EDW
AN
ALY
TIC
S D
ATA
SYST
EMS
Data Marts
Business Analytics
Visualization & Dashboards
HDP 2.2
ELT °
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
N
Cold Data, Deeper Archive & New Sources
Enterprise Data Warehouse
Hot
MPP
In-Memory
Clickstream Web & Social
Geoloca3on Sensor & Machine
Server Logs
Unstructured
Existing Systems
ERP CRM SCM
SOU
RC
ES

© Hortonworks Inc. 2014 Page 21
Single View Improve acquisition and retention
Predictive Analytics Identify your next best action
Data Discovery Uncover new findings
Financial Services
New Account Risk Screens Trading Risk Insurance Underwriting
Improved Customer Service Insurance Underwriting Aggregate Banking Data as a Service
Cross-sell & Upsell of Financial Products Risk Analysis for Usage-Based Car Insurance Identify Claims Errors for Reimbursement
Telecom Unified Household View of the Customer Searchable Data for NPTB Recommendations Protect Customer Data from Employee Misuse
Analyze Call Center Contacts Records Network Infrastructure Capacity Planning Call Detail Records (CDR) Analysis
Inferred Demographics for Improved Targeting Proactive Maintenance on Transmission Equipment Tiered Service for High-Value Customers
Retail 360° View of the Customer Supply Chain Optimization Website Optimization for Path to Purchase
Localized, Personalized Promotions A/B Testing for Online Advertisements Data-Driven Pricing, improved loyalty programs
Customer Segmentation Personalized, Real-time Offers In-Store Shopper Behavior
Manufacturing Supply Chain and Logistics Optimize Warehouse Inventory Levels Product Insight from Electronic Usage Data
Assembly Line Quality Assurance Proactive Equipment Maintenance Crowdsource Quality Assurance
Single View of a Product Throughout Lifecycle Connected Car Data for Ongoing Innovation Improve Manufacturing Yields
Healthcare Electronic Medical Records Monitor Patient Vitals in Real-Time Use Genomic Data in Medical Trials
Improving Lifelong Care for Epilepsy Rapid Stroke Detection and Intervention Monitor Medical Supply Chain to Reduce Waste
Reduce Patient Re-Admittance Rates Video Analysis for Surgical Decision Support Healthcare Analytics as a Service
Oil & Gas Unify Exploration & Production Data Monitor Rig Safety in Real-Time Geographic exploration
DCA to Slow Well Declines Curves Proactive Maintenance for Oil Field Equipment Define Operational Set Points for Wells
Government Single View of Entity CBM & Autonomic Logistic Analysis Sentiment Analysis on Program Effectiveness
Prevent Fraud, Waste and Abuse Proactive Maintenance for Public Infrastructure Meet Deadlines for Government Reporting
Hadoop Driver: Advanced analytic applications
© Hortonworks Inc. 2014 Page 22
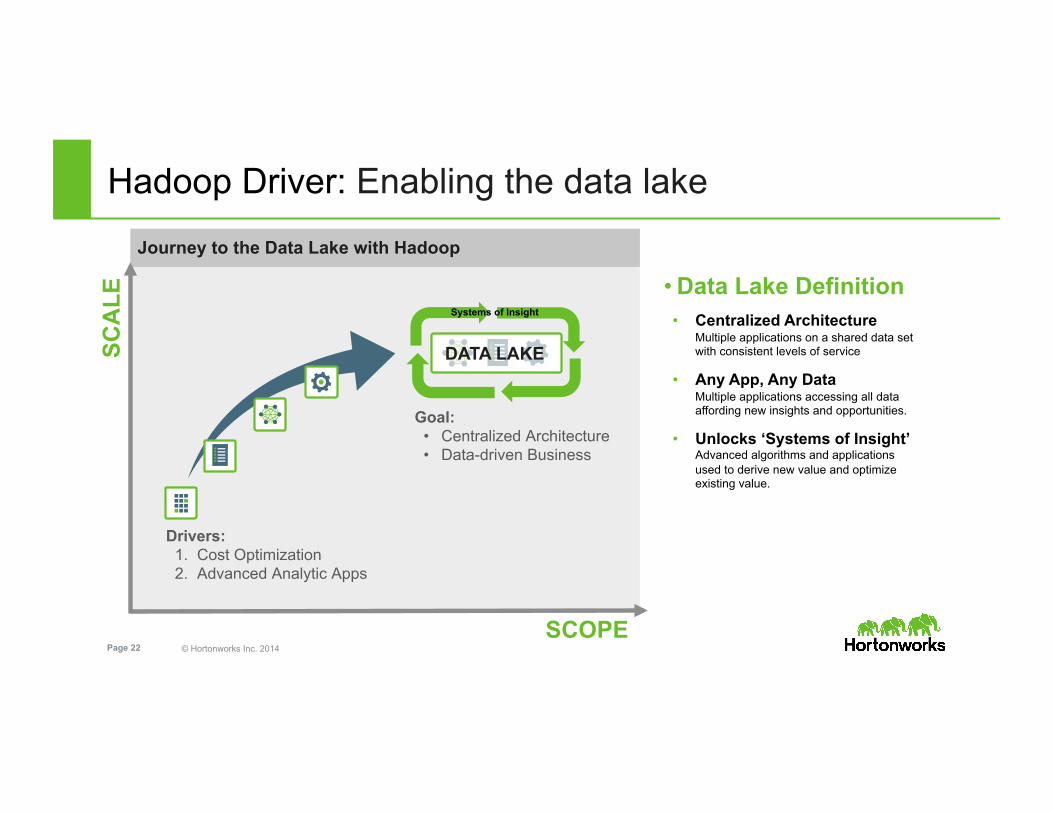
Hadoop Driver: Enabling the data lake
SCA
LE
SCOPE
• Data Lake Definition • Centralized Architecture
Multiple applications on a shared data set with consistent levels of service
• Any App, Any Data Multiple applications accessing all data affording new insights and opportunities.
• Unlocks ‘Systems of Insight’ Advanced algorithms and applications used to derive new value and optimize existing value.
Drivers: 1. Cost Optimization 2. Advanced Analytic Apps
Goal: • Centralized Architecture • Data-driven Business
DATA LAKE
Journey to the Data Lake with Hadoop
Systems of Insight

© Hortonworks Inc. 2014 Page 23
How do everyone do Hadoop? Reference architecture
© Hortonworks Inc. 2014 Page 24
Hortonworks Data Platform 2.2
Had
oop
&YA
RN
Pig
Hiv
e &
HC
atal
og
HB
ase
Sqo
op
Ooz
ie
Zoo
keep
er
Am
bari
Sto
rm
Flu
me
Kno
x
Pho
enix
Acc
umul
o
2.2.0 0.12.0
0.12.0 2.4.0
0.12.1
Data Management
0.13.0
0.96.1
0.98.0
0.9.1 1.4.4
1.3.1
1.4.0
1.4.4
1.5.1
3.3.2
4.0.0
3.4.5 0.4.0
4.0.0
1.5.1
Fal
con
0.5.0
Ran
ger
Spa
rk
Kaf
ka
0.14.0 0.14.0
0.98.4
1.6.1
4.2 0.9.3
1.2.0 0.6.0
0.8.1
1.4.5 1.5.0
1.7.0
4.1.0 0.5.0
0.4.0 2.6.0
* version numbers are targets and subject to change at time of general availability in accordance with ASF release process
3.4.5
Tez
0.4.0
Slid
er
0.60
HDP 2.0
October
2013
HDP 2.2 October
2014
HDP 2.1
April
2014
Sol
r
4.7.2
4.10.0
0.5.1
Data Access Governance & Integration Security Operations
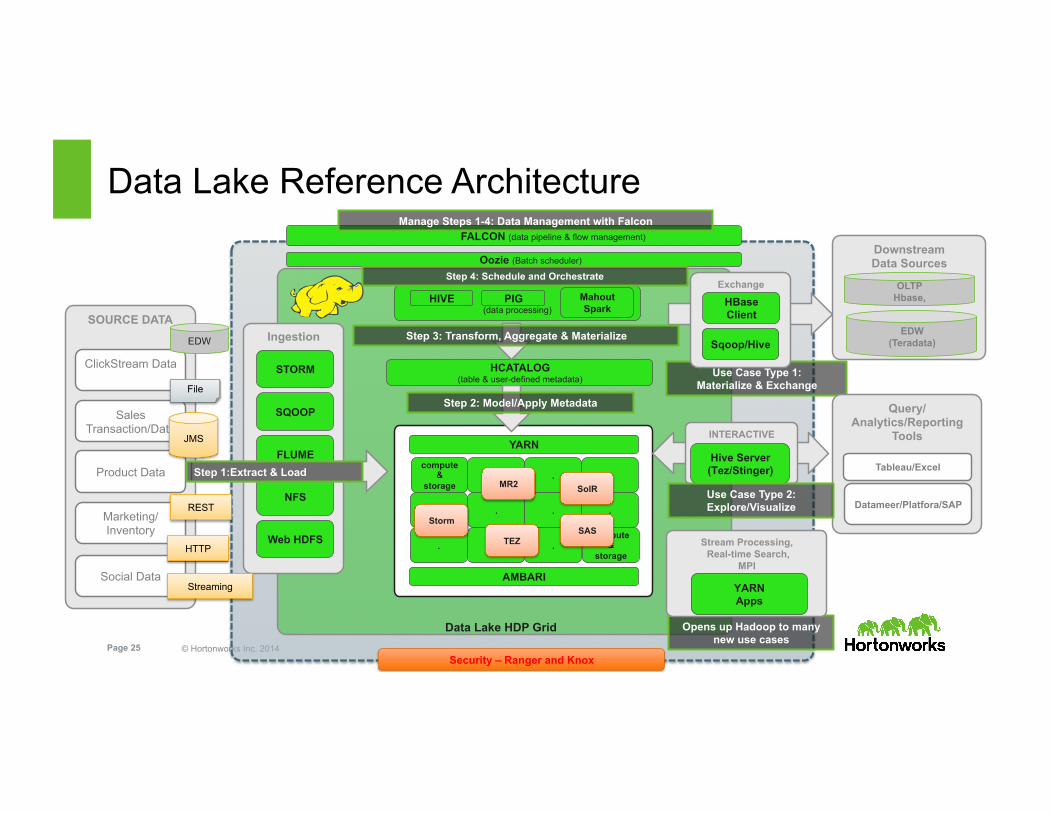
© Hortonworks Inc. 2014 Page 25 Security – Ranger and Knox
compute &
storage . . .
. . .
. . compute
& storage
.
.
YARN
Data Lake HDP Grid
AMBARI
Data Lake Reference Architecture
HCATALOG (table & user-defined metadata)
Step 2: Model/Apply Metadata
Use Case Type 1: Materialize & Exchange
Opens up Hadoop to many new use cases
Stream Processing, Real-time Search,
MPI
YARN Apps
INTERACTIVE
Hive Server (Tez/Stinger)
Query/ Analytics/Reporting
Tools
Tableau/Excel
Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize
FALCON (data pipeline & flow management)
Manage Steps 1-4: Data Management with Falcon
Oozie (Batch scheduler)
(data processing)
HIVE PIG Mahout Spark
Exchange
HBase Client
Sqoop/Hive
Downstream Data Sources
OLTP Hbase,
EDW (Teradata)
Storm SAS
SolR
TEZ
Step 3: Transform, Aggregate & Materialize
MR2
Step 4: Schedule and Orchestrate
Ingestion
SQOOP
FLUME
Web HDFS
NFS
SOURCE DATA
ClickStream Data
Sales Transaction/Data
Product Data
Marketing/Inventory
Social Data
EDW
File
JMS
REST
HTTP
Streaming
STORM
Step 1:Extract & Load
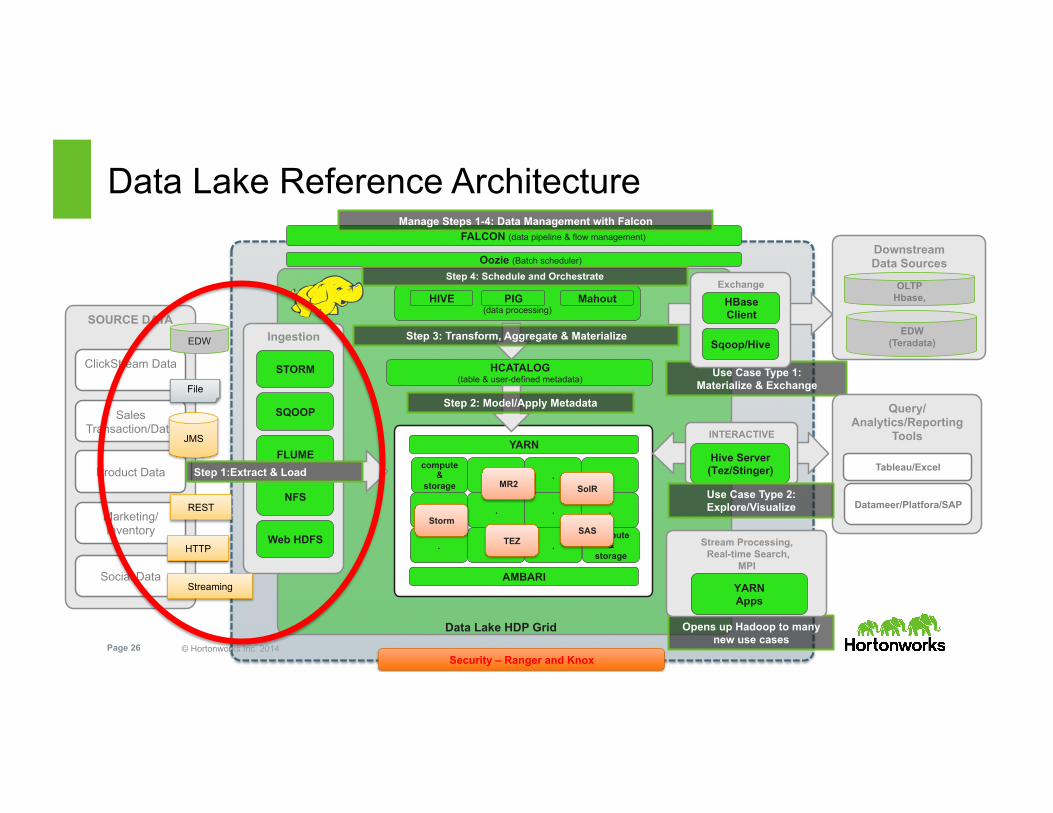
© Hortonworks Inc. 2014 Page 26 Security – Ranger and Knox
compute &
storage . . .
. . .
. . compute
& storage
.
.
YARN
Data Lake HDP Grid
AMBARI
Data Lake Reference Architecture
HCATALOG (table & user-defined metadata)
Step 2: Model/Apply Metadata
Use Case Type 1: Materialize & Exchange
Opens up Hadoop to many new use cases
Stream Processing, Real-time Search,
MPI
YARN Apps
INTERACTIVE
Hive Server (Tez/Stinger)
Query/ Analytics/Reporting
Tools
Tableau/Excel
Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize
FALCON (data pipeline & flow management)
Manage Steps 1-4: Data Management with Falcon
Oozie (Batch scheduler)
(data processing)
HIVE PIG Mahout Exchange
HBase Client
Sqoop/Hive
Downstream Data Sources
OLTP Hbase,
EDW (Teradata)
Storm SAS
SolR
TEZ
Step 3: Transform, Aggregate & Materialize
MR2
Step 4: Schedule and Orchestrate
Ingestion
SQOOP
FLUME
Web HDFS
NFS
SOURCE DATA
ClickStream Data
Sales Transaction/Data
Product Data
Marketing/Inventory
Social Data
EDW
File
JMS
REST
HTTP
Streaming
STORM
Step 1:Extract & Load

© Hortonworks Inc. 2014 Page 27
FILES NFS Gateway

© Hortonworks Inc. 2014 Page 28
The HDFS NFS Gateway
§ HDFS access is usually done using the HDFS API or the web API
§ The HDFS NFS Gateway (NFS) allows HDFS to be mounted as part of a client local file system
§ The NFS Gateway is a stateless daemon, that translates NFS protocol to HDFS access protocols
Client NFS
Gateway
DataTransferProtocol
DataTransferProtocol
ClientProtocol
NFSv3 NameNode
DataNode
DataNode
HD
FSC
lient

© Hortonworks Inc. 2014 Page 29
NFS Access
Page 29
• What can you do now
– Users can browse the HDFS file system through their local file system on NFSv3 complaint operating systems
– Users can download the files from HDFS to local file system
– Users can upload files from local file system to HDFS file system
• What is coming
– NFSV4 and other protocols to access to HDFS
– Highly Available NFS Gateway
– Kerberos Integration

© Hortonworks Inc. 2014 Page 31
FILES WebHDFS
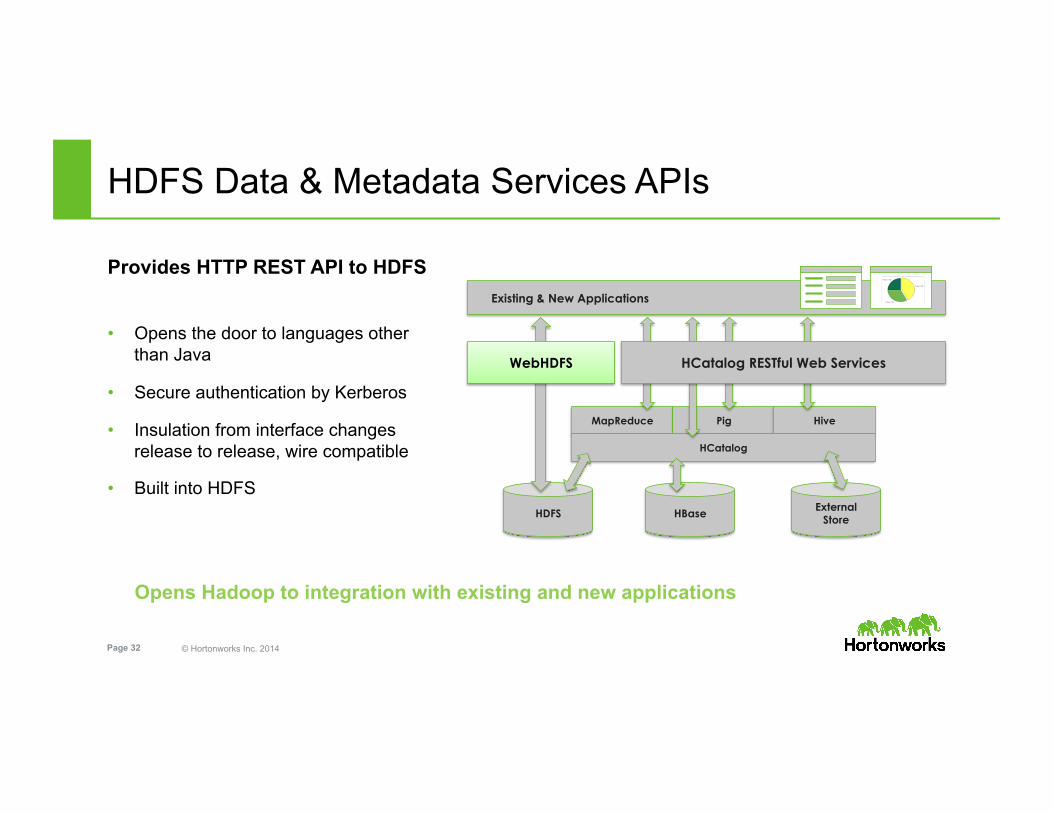
© Hortonworks Inc. 2014 Page 32
HDFS HBase External Store
Existing & New Applications
MapReduce Pig Hive
HCatalog
HCatalog RESTful Web Services
Provides HTTP REST API to HDFS
• Opens the door to languages other than Java
• Secure authentication by Kerberos
• Insulation from interface changes release to release, wire compatible
• Built into HDFS
Opens Hadoop to integration with existing and new applications
WebHDFS
HDFS Data & Metadata Services APIs

© Hortonworks Inc. 2014 Page 34
WebHDFS - example
• To read a file named input/mydata:
$ curl -i –L "http://host:50070/webhdfs/v1/input/mydata?op=OPEN” • To list the contents of a directory named “tdata”: $ curl –i "http://host:50070/webhdfs/v1/tdata?op=LISTSTATUS”
• To make a directory named “myoutput”: $ curl -i -X PUT "http://host:50070/webhdfs/v1/myoutput? op=MKDIRS&permission=744"

© Hortonworks Inc. 2014 Page 35
RELATIONAL SQOOP

© Hortonworks Inc. 2014 Page 36
Sqoop Overview
Page
• Enables RDBMS data exchange • JDBC based data exchange in and out of Hadoop • Native connectors for Major vendors like Teradata, Netezza, Oracle, etc.
• Import • Tables, entire databases
• Export • HDFS files, HCatalog/Hive tables
• Partner accelerators • DB and ETL partners focus here for accelerated connecters to their platforms • For example, Teradata Sqoop accelerator for HDP uses FastLoad to drastically reduce data transfer time
• Configurable • Custom queries can be used • Incremental data import
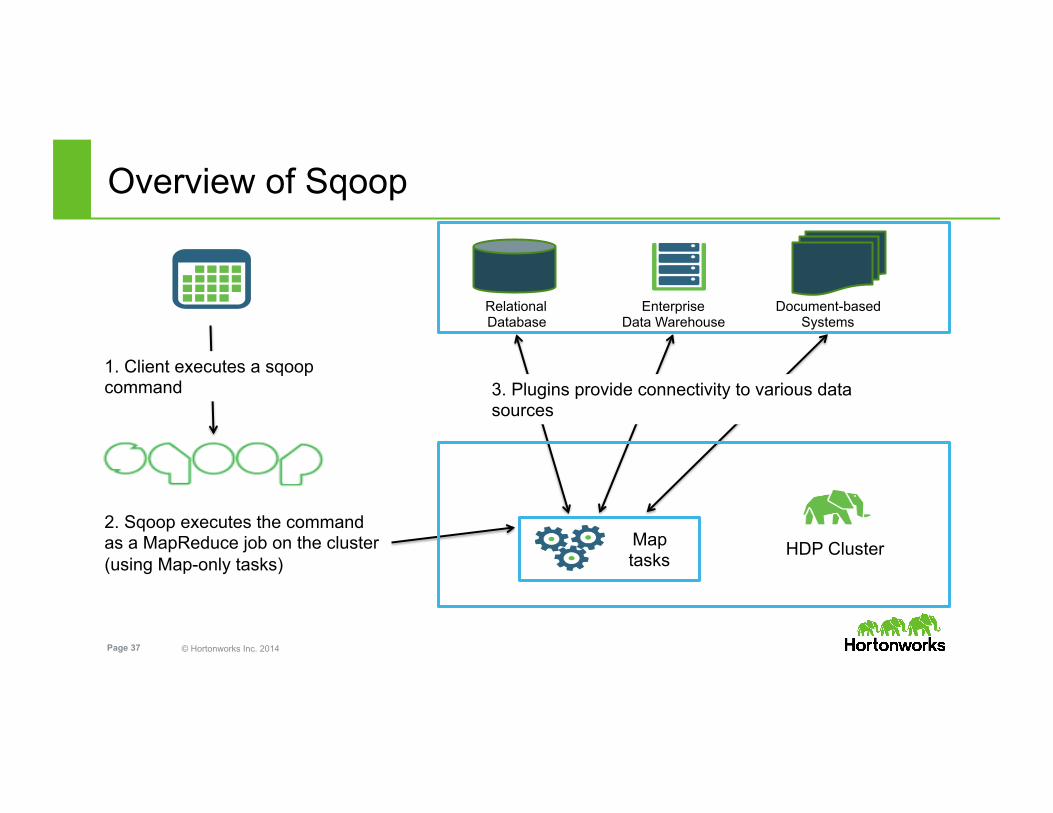
© Hortonworks Inc. 2014 Page 37
Overview of Sqoop
Relational Database
Enterprise Data Warehouse
Document-based Systems
1. Client executes a sqoop command
2. Sqoop executes the command as a MapReduce job on the cluster (using Map-only tasks)
3. Plugins provide connectivity to various data sources
HDP Cluster Map tasks

© Hortonworks Inc. 2014 Page 40
Sqoop Jobs & Workflow
- Sqoop can save regular jobs for regular execution of repeated tasks - Often used with incremental updates from tables, the same job is
executed repeatedly to check for new data - Sqoop use its own internal metastore to maintain jobs
- To manage multi-tenancy and security, most production implementations use Oozie and Falcon to save and execute Sqoop jobs
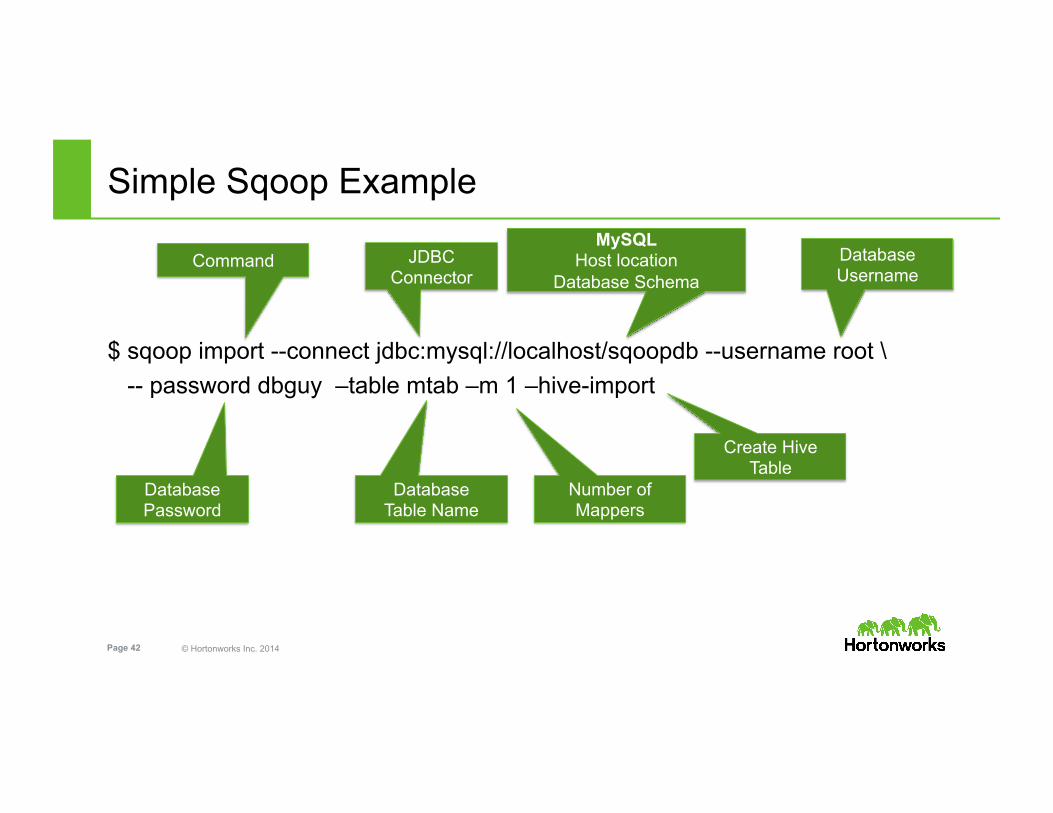
© Hortonworks Inc. 2014 Page 42
Simple Sqoop Example
$ sqoop import --connect jdbc:mysql://localhost/sqoopdb --username root \ -- password dbguy –table mtab –m 1 –hive-import
Command JDBC Connector
MySQL Host location
Database Schema Database Username
Number of Mappers
Database Password
Database Table Name
Create Hive Table

© Hortonworks Inc. 2014 Page 43
LOGS FLUME

© Hortonworks Inc. 2014 Page 44
Flume Introduction
A Flume is an artificial channel or stream created which uses water to transport objects down a channel. Apache Flume, a data ingestion tool, collects, aggregates and directs data streams into Hadoop using the same concepts. Flume works with different data sources to process and send data to defined destinations.
Flume Agent
Channel Source Sink

© Hortonworks Inc. 2014 Page 46
Flume Events
Flume sources listen for and respond to events. Events are:
§ Units of data transferred over a channel from a source to a sink. § A byte payload with optional string headers that represent the unit of data that Flume can
transport. § A singular unit of data that can be transported by Flume. § Individual records in a larger dataset. § Can be batched. § Made up of headers and a body.
§ Performance: < 100 K events/sec total <10 K event/sec single-flow

© Hortonworks Inc. 2014 Page 47
Flume Sources
• Accept data from an application or server – Example: A web server
• Sources can be a polled or event driven. – Polled sources are repeatedly polled by Flume source runners
– Example: Sequence generator which simply generates events whose body is a monotonically increasing integer
– Event driven sources provide the Flume Source with events – Examples:
– Avro source which accepts Avro RPC calls and converts the RPC payload into a Flume event – Netcat source which mimics the nc command line tool running in server mode. Sources are a user
accessible API extension point.
• Sources sends events it receives to one or more channels
Source

© Hortonworks Inc. 2014 Page 48
Flume Channels
• A channel is a connection point for transferring events from a source to a sink. – Connecting sources and sinks run asynchronously. – Events are stored until a sink removes it for further transport.
• Different levels of curability and performance: – In memory: The channel is fast but has a risk for data loss if the agent fails. – Persistent: Ensures durable and reliable event storage with recovery capabilities in case
an agent fails.
Channel

© Hortonworks Inc. 2014 Page 49
Flume Sinks
Sinks receive Events from Channels which are then written to the HDFS or forwarded to another data source. Supported destinations are shown below:
HDFS
Avro
Sink
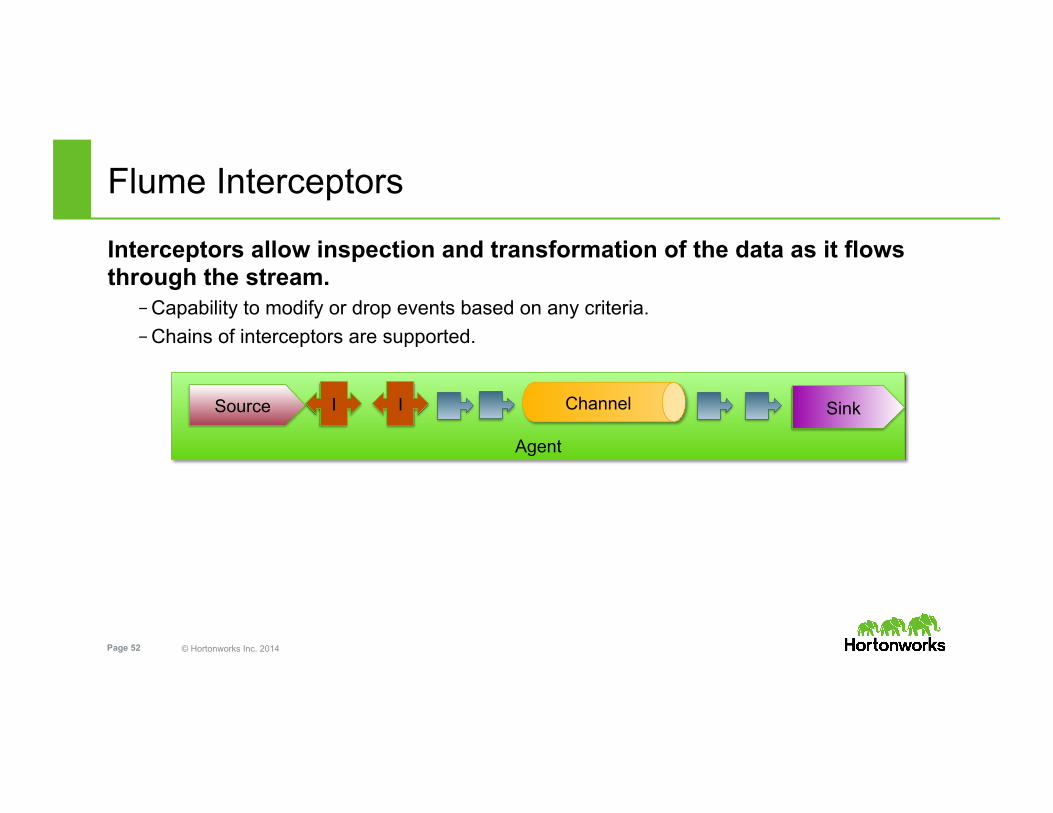
© Hortonworks Inc. 2014 Page 52
Flume Interceptors
Interceptors allow inspection and transformation of the data as it flows through the stream.
– Capability to modify or drop events based on any criteria. – Chains of interceptors are supported.
Agent
Channel Source I I Sink

© Hortonworks Inc. 2014 Page 53
Flume config - example
Agent
MemoryChannel pstream hdfssink
HDFS
• tail –f /etc/passwd

© Hortonworks Inc. 2014 Page 54
Flume config - example # A single-node Flume configuration # Configure source agent.sources = pstream agent.sources.pstream.type = exec agent.sources.pstream.command = tail -f /etc/passwd # Configure channel agent.channels = memoryChannel agent.channels = memoryChannel agent.channels.memoryChannel.type = memory # Configure sink agent.sinks = hdfssink agent.sinks.hdfsSink.type = hdfs agent.sinks.hdfsSink.hdfs.path = hdfs://hdp/user/root/flumetest agent.sinks.hdfsSink.hdfs.fileType = SequenceFile agent.sinks.hdfsSink.hdfs.writeFormat = Text # Bind source and sink to channel agent.sources.pstream.channels = memoryChannel agent.sinks.hdfsSink.channel = memoryChannel

© Hortonworks Inc. 2014 Page 58
REAL-TIME STORM
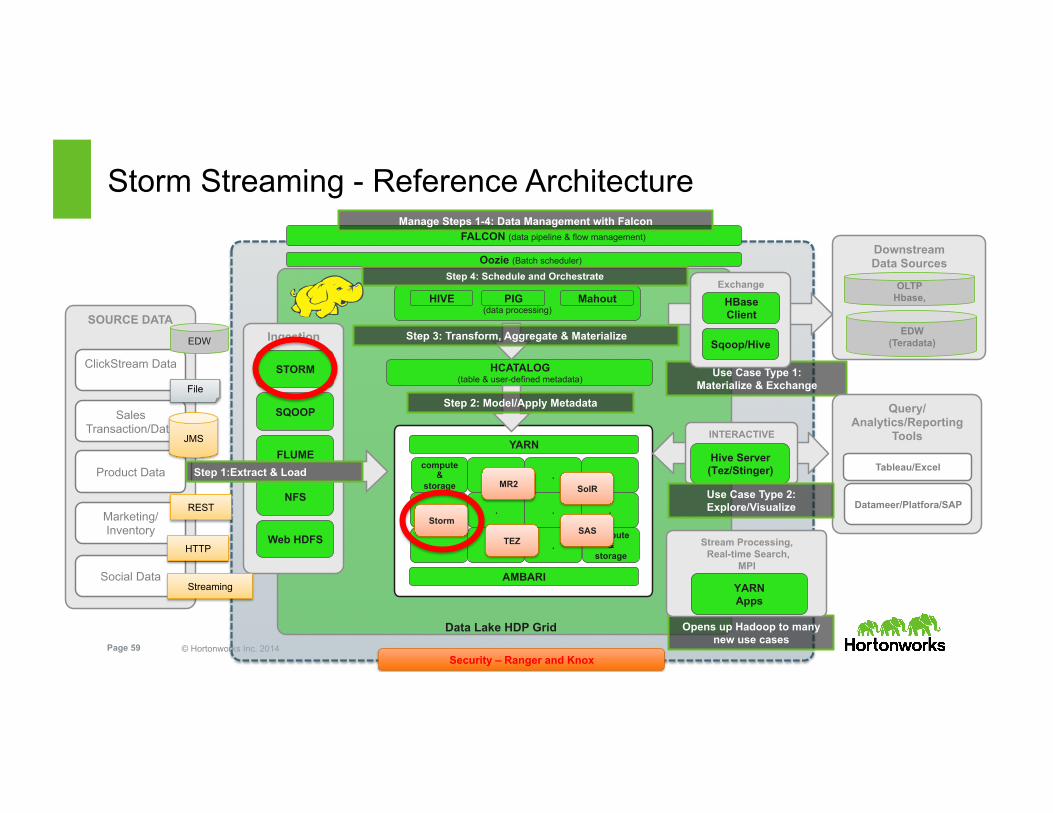
© Hortonworks Inc. 2014 Page 59 Security – Ranger and Knox
compute &
storage . . .
. . .
. . compute
& storage
.
.
YARN
Data Lake HDP Grid
AMBARI
Storm Streaming - Reference Architecture
HCATALOG (table & user-defined metadata)
Step 2: Model/Apply Metadata
Use Case Type 1: Materialize & Exchange
Opens up Hadoop to many new use cases
Stream Processing, Real-time Search,
MPI
YARN Apps
INTERACTIVE
Hive Server (Tez/Stinger)
Query/ Analytics/Reporting
Tools
Tableau/Excel
Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize
FALCON (data pipeline & flow management)
Manage Steps 1-4: Data Management with Falcon
Oozie (Batch scheduler)
(data processing)
HIVE PIG Mahout Exchange
HBase Client
Sqoop/Hive
Downstream Data Sources
OLTP Hbase,
EDW (Teradata)
Storm SAS
SolR
TEZ
Step 3: Transform, Aggregate & Materialize
MR2
Step 4: Schedule and Orchestrate
Ingestion
SQOOP
FLUME
Web HDFS
NFS
SOURCE DATA
ClickStream Data
Sales Transaction/Data
Product Data
Marketing/Inventory
Social Data
EDW
File
JMS
REST
HTTP
Streaming
STORM
Step 1:Extract & Load
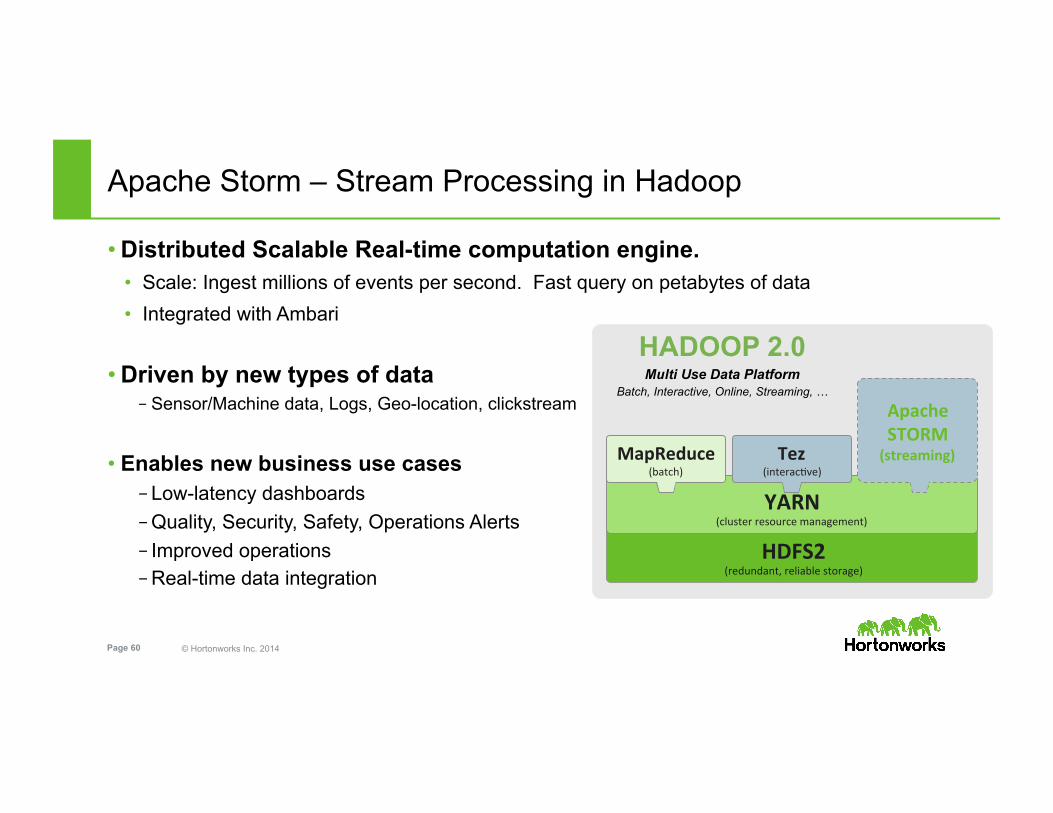
© Hortonworks Inc. 2014 Page 60
Apache Storm – Stream Processing in Hadoop
• Distributed Scalable Real-time computation engine. • Scale: Ingest millions of events per second. Fast query on petabytes of data • Integrated with Ambari
• Driven by new types of data – Sensor/Machine data, Logs, Geo-location, clickstream
• Enables new business use cases – Low-latency dashboards – Quality, Security, Safety, Operations Alerts – Improved operations – Real-time data integration
HDFS2 (redundant, reliable storage)
YARN (cluster resource management)
MapReduce (batch)
Apache STORM (streaming)
HADOOP 2.0
Tez (interac5ve)
Multi Use Data Platform Batch, Interactive, Online, Streaming, …

© Hortonworks Inc. 2014 Page 62
Key Capabilities of Storm
Page 62
• Extremely high ingest rates >1 million tuples/second Data Ingest
• Ability to easily plug different processing frameworks • Guaranteed processing – at-least once processing semantics Processing
• Ability to persist data to multiple relational and non relational data stores Persistence
• Security, HA, fault tolerance & management support Operations
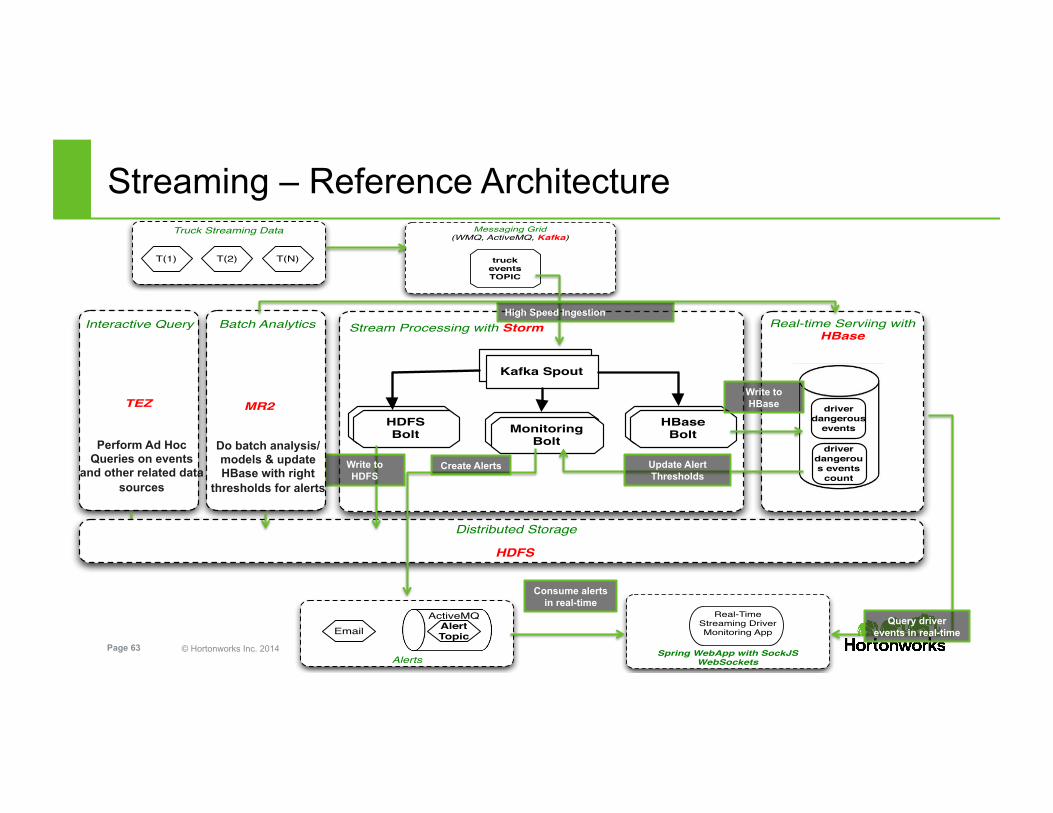
© Hortonworks Inc. 2014 Page 63
Streaming – Reference Architecture Truck Streaming Data
T(N)T(2)T(1)
Interactive Query
TEZ
Perform Ad Hoc Queries on events
and other related data sources
Messaging Grid(WMQ, ActiveMQ, Kafka)
truckeventsTOPIC
Stream Processing with Storm
Kafka Spout
HBase BoltMonitoring
Bolt
HDFS Bolt
High Speed Ingestion
Distributed Storage
HDFS
Write to HDFS
Alerts
ActiveMQAlert Topic
Create Alerts
Real-time Serviing with HBase
driver dangerous
events
driver dangerous events
count
Write to HBase
Update Alert Thresholds
Spring WebApp with SockJS WebSockets
Real-Time Streaming Driver Monitoring App
Query driver events in real-time
Consume alerts in real-time
Batch Analytics
MR2
Do batch analysis/models & update HBase with right
thresholds for alerts

© Hortonworks Inc. 2014 Page 66
TRANSFORM AND CONSUME PIG / HIVE / OTHERS
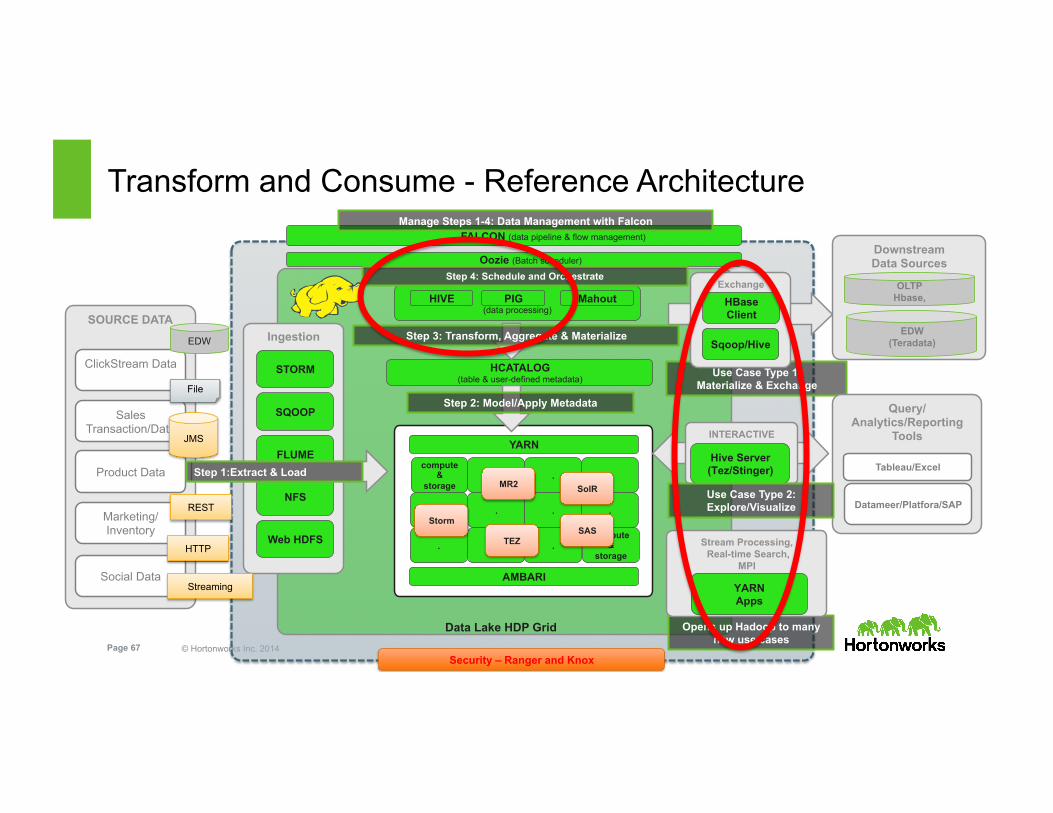
© Hortonworks Inc. 2014 Page 67 Security – Ranger and Knox
compute &
storage . . .
. . .
. . compute
& storage
.
.
YARN
Data Lake HDP Grid
AMBARI
Transform and Consume - Reference Architecture
HCATALOG (table & user-defined metadata)
Step 2: Model/Apply Metadata
Use Case Type 1: Materialize & Exchange
Opens up Hadoop to many new use cases
Stream Processing, Real-time Search,
MPI
YARN Apps
INTERACTIVE
Hive Server (Tez/Stinger)
Query/ Analytics/Reporting
Tools
Tableau/Excel
Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize
FALCON (data pipeline & flow management)
Manage Steps 1-4: Data Management with Falcon
Oozie (Batch scheduler)
(data processing)
HIVE PIG Mahout Exchange
HBase Client
Sqoop/Hive
Downstream Data Sources
OLTP Hbase,
EDW (Teradata)
Storm SAS
SolR
TEZ
Step 3: Transform, Aggregate & Materialize
MR2
Step 4: Schedule and Orchestrate
Ingestion
SQOOP
FLUME
Web HDFS
NFS
SOURCE DATA
ClickStream Data
Sales Transaction/Data
Product Data
Marketing/Inventory
Social Data
EDW
File
JMS
REST
HTTP
Streaming
STORM
Step 1:Extract & Load

© Hortonworks Inc. 2014 Page 68
Transform and Consume
• Tez and MapReduce – For Programmers – When control matters
• Pig – Pig for declarative data crunching and preprocessing (the T in ELT) – User Defined Functions (UDF) for extensibility and portability. Ex: Custom UDF for calling industry-
specific data format parsers (SWIFT, X12, NACHA, HL7, HIPPA, etc.)
• Hive – HiveQL (SQL-like) to ad-hoc query and explore data
© Hortonworks Inc. 2014 Page 70
Pig
§ High level procedural language for analyzing massive amount of data
§ Intended to sit between MapReduce and Hive
– Provides standard relational transforms (join, sort, etc.) – Schemas are optional, used when available, can be defined at runtime – User Defined Functions are first class citizens
© Hortonworks Inc. 2014 Page 71
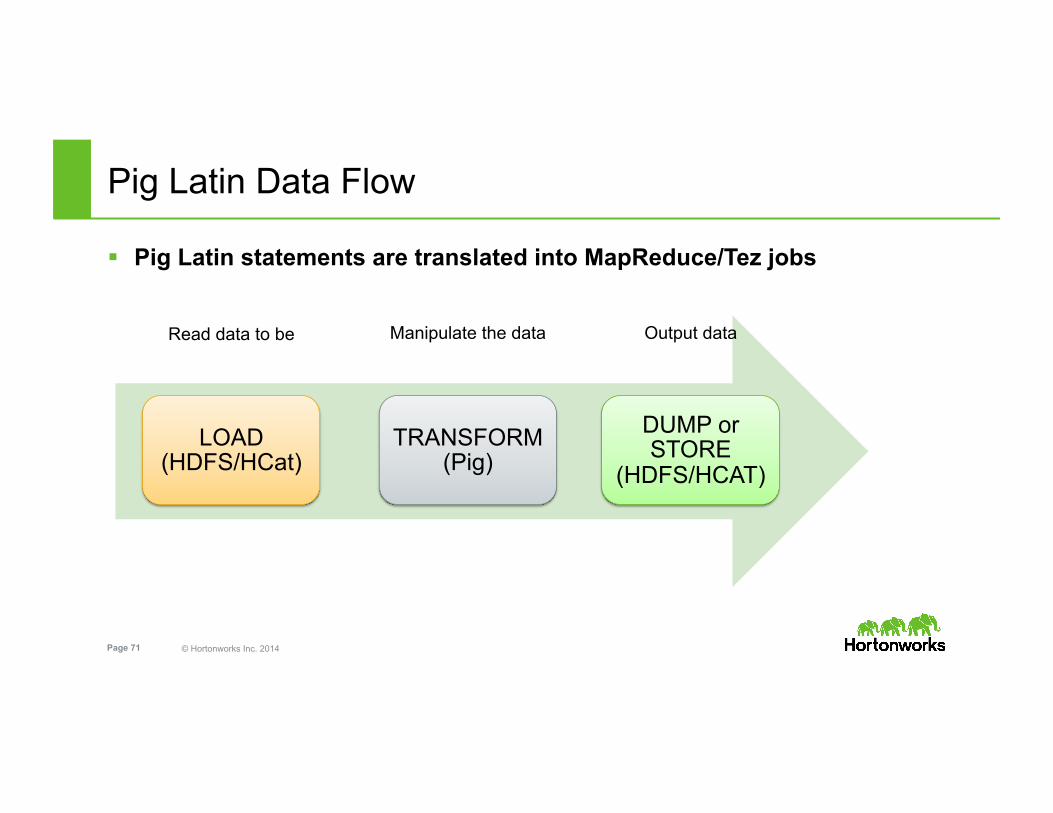
Pig Latin Data Flow
§ Pig Latin statements are translated into MapReduce/Tez jobs
Read data to be Manipulate the data Output data
LOAD (HDFS/HCat)
TRANSFORM (Pig)
DUMP or STORE
(HDFS/HCAT)

© Hortonworks Inc. 2014 Page 72
Pig Examples
§ logevents = LOAD 'input/my.log' AS (date:chararray, level:chararray, code:int, message:chararray);
§ severe = FILTER logevents BY (level == 'severe’ • AND code >= 500); § grouped = GROUP severe BY code; § STORE grouped INTO 'output/severeevents’;
§ e1 = LOAD 'pig/input/File1' USING PigStorage(',') AS (name:chararray,age:int, zip:int,salary:double); § f = FOREACH e1 GENERATE age, salary; § g = order f by age; § DUMP g;

© Hortonworks Inc. 2014 Page 74
Hive & Pig
Hive & Pig work well together and many customers use both.
Hive is a good choice: • if you are familiar with SQL • when you want to query the data • when you need an answer to specific questions
Pig is a good choice: • for ETL (Extract -> Transform -> Load) • for preparing data for easier analysis • when you have a long series of steps to perform

© Hortonworks Inc. 2014 Page 75
Hive Overview
§ Data warehouse infrastructure built on top of Hadoop § Provides SQL for summarization, analysis and querying of data § Converts SQL to Tez or MapReduce jobs
§ ANSI SQL:92 compliant and SQL:2003 analytics compliance § ACID Transactions
§ Supports JDBC/ODBC
Used extensively for Analytics and Business Intelligence

© Hortonworks Inc. 2014 Page 77
Hive Objects
• Hive has TABLES defined within DATABASES
• A DATABASE is basically a directory in hdfs:/
• A TABLE consists of: – Data: typically a file or group of files in HDFS – Schema: in the form of metadata stored in a relational database
• Schema and data are separate – A schema can be defined for existing data – Data can be added or removed independently – Hive can be "pointed" at existing data
• We have to define a schema if you have existing data in HDFS that you want to use in Hive

© Hortonworks Inc. 2014 Page 78
Create Table Example
CREATE TABLE customer ( customerID INT, firstName STRING, lastName STRING, birthday TIMESTAMP) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; CREATE EXTERNAL TABLE salaries ( gender string, age int, salary double, zip int ) STORED BY ‘org.apache.hive.hbase.HBaseStorageHandler’ LOCATION ‘/user/train/salaries’

© Hortonworks Inc. 2014 Page 79
Query Examples
• SELECT * FROM customers;
• SELECT COUNT(1) FROM customers;
• SELECT CustomerId, COUNT(OrderId) FROM customersOrders GROUP BY customerId;
• SELECT customers.*, orders.* FROM customers INNER JOIN orders ON customers.customerID = orders.customerID ORDER BY orders.qty;
• SELECT customers.*, orders.* FROM customers LEFT JOIN orders ON customers.customerID = orders.customerID;
• WITH cte as (SELECT CustomerID, OrderID FROM customerOrders) SELECT * FROM cte;

© Hortonworks Inc. 2014 Page 80
SQL Support
SQL Datatypes SQL Seman3cs INT/TINYINT/SMALLINT/BIGINT SELECT, INSERT
FLOAT/DOUBLE GROUP BY, ORDER BY, HAVING
BOOLEAN Inner, outer, cross and semi joins
ARRAY, MAP, STRUCT, UNION Sub-‐queries in the FROM clause
STRING ROLLUP and CUBE
BINARY UNION
TIMESTAMP Standard aggrega5ons (sum, avg, etc.)
DECIMAL Custom Java UDFs
DATE Windowing func5ons (OVER, RANK, etc.)
VARCHAR Advanced UDFs (ngram, XPath, URL)
CHAR Sub-‐queries for IN/NOT IN, HAVING
Interval Types JOINs in WHERE Clause
Common Table Expressions (WITH Clause)
INSERT / UPDATE / DELETE
Non-‐equi joins
Set func5ons -‐ Union, Except, Intersect
All sub-‐queries Minor syntax differences resolved – rollup, case
Legend Available Now
S5nger.next

© Hortonworks Inc. 2014 Page 81
Introducing Stinger.next
Stinger.next Initiative Enterprise SQL at Hadoop Scale
Speed Improve Hive query performance to deliver sub-second query times
Scale The only SQL interface to Hadoop designed for queries that scale from GB to TB and PB
SQL Enable transactions and SQL:2011 analytics for Hive
Delivered over a familiar three phases
Delivered a single SQL engine for all workloads, simplify clusters
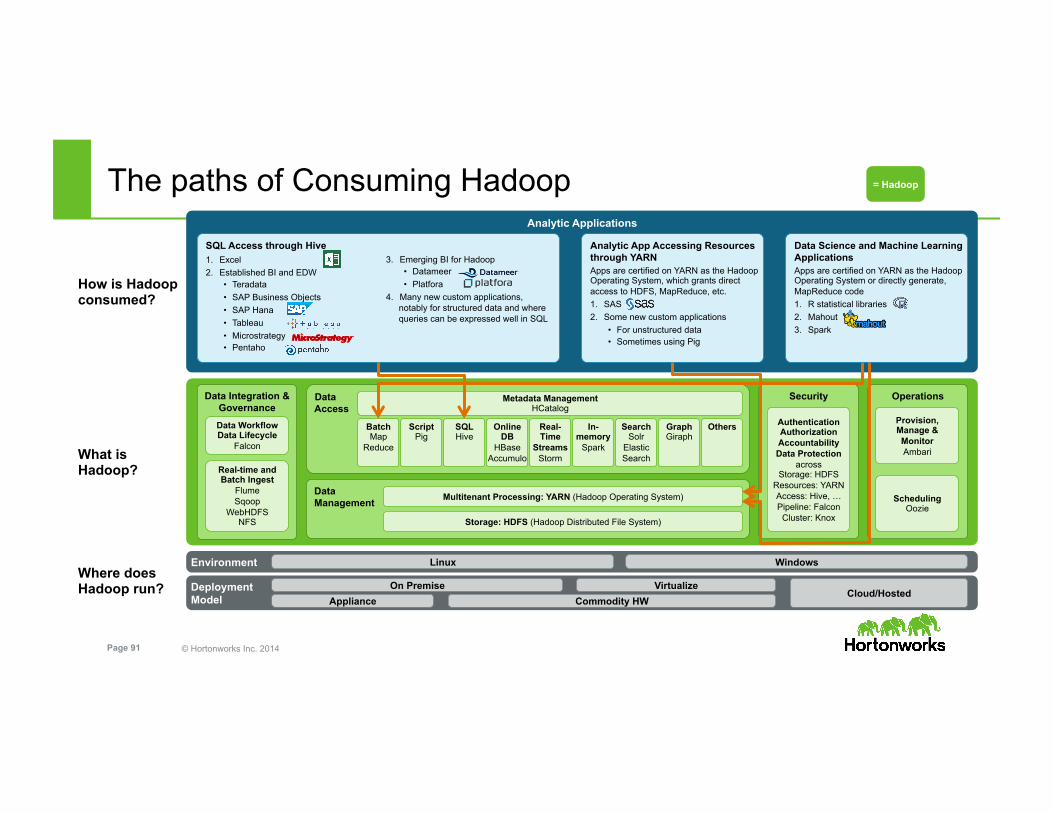
© Hortonworks Inc. 2014 Page 91
Analytic Applications
Deployment Model
Environment
The paths of Consuming Hadoop
Commodity HW
Linux Windows
Appliance On Premise Virtualize
Cloud/Hosted
= Hadoop
Where does Hadoop run?
What is Hadoop?
Data Access
Data Management
Storage: HDFS (Hadoop Distributed File System)
Multitenant Processing: YARN (Hadoop Operating System)
Security
Authentication Authorization Accountability Data Protection
across Storage: HDFS
Resources: YARN Access: Hive, … Pipeline: Falcon
Cluster: Knox
Operations
Provision, Manage & Monitor Ambari
Scheduling Oozie
Data Integration & Governance Data Workflow Data Lifecycle
Falcon
Real-time and Batch Ingest
Flume Sqoop
WebHDFS NFS
Batch Map
Reduce
Online DB
HBase Accumulo
Real-Time
Streams Storm
Others Script Pig
SQL Hive
In-memory
Spark
Search Solr
Elastic Search
Graph Giraph
Metadata Management HCatalog
SQL Access through Hive 1. Excel 2. Established BI and EDW
• Teradata • SAP Business Objects • SAP Hana • Tableau • Microstrategy • Pentaho
How is Hadoop consumed?
3. Emerging BI for Hadoop • Datameer • Platfora
4. Many new custom applications, notably for structured data and where queries can be expressed well in SQL
Data Science and Machine Learning Applications Apps are certified on YARN as the Hadoop Operating System or directly generate, MapReduce code 1. R statistical libraries 2. Mahout 3. Spark
Analytic App Accessing Resources through YARN Apps are certified on YARN as the Hadoop Operating System, which grants direct access to HDFS, MapReduce, etc. 1. SAS 2. Some new custom applications
• For unstructured data • Sometimes using Pig

© Hortonworks Inc. 2014 Page 94
Learn Hadoop on Sandbox
http://hortonworks.com/products/hortonworks-sandbox
HDP Sandbox - A complete Hadoop platform in a virtual machine Sandbox comes with a dozen hands-on tutorials that will guide you through the basics of Hadoop
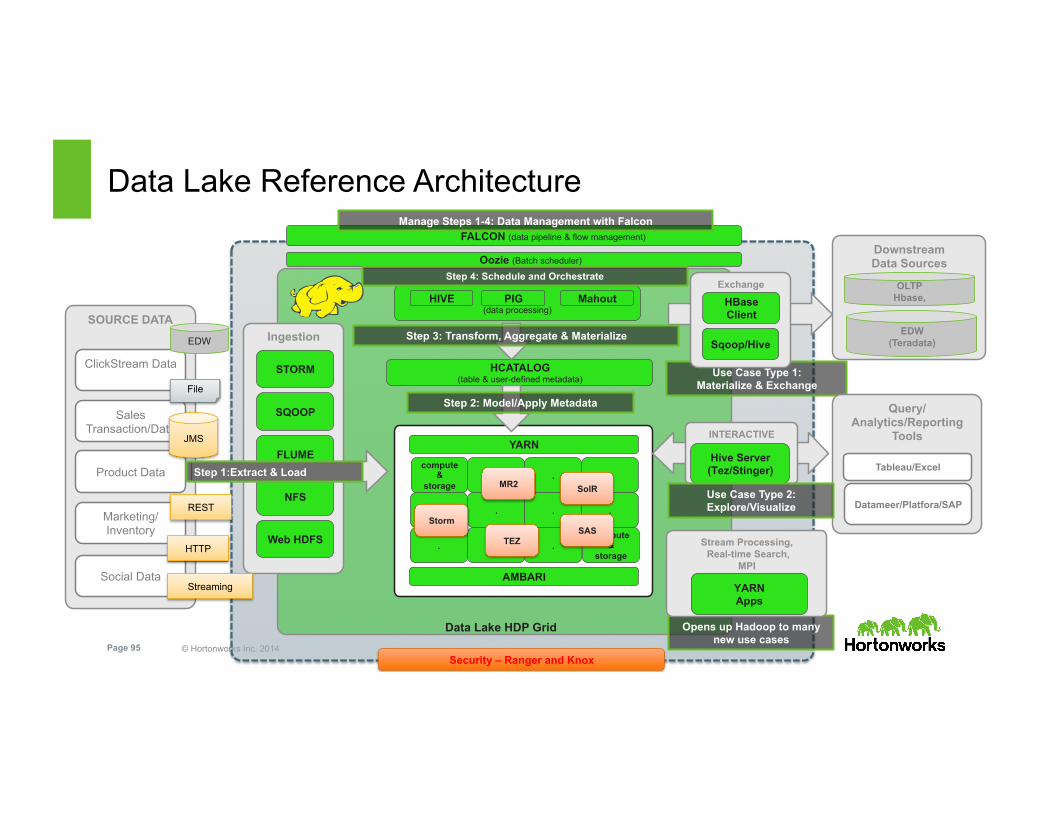
© Hortonworks Inc. 2014 Page 95 Security – Ranger and Knox
compute &
storage . . .
. . .
. . compute
& storage
.
.
YARN
Data Lake HDP Grid
AMBARI
Data Lake Reference Architecture
HCATALOG (table & user-defined metadata)
Step 2: Model/Apply Metadata
Use Case Type 1: Materialize & Exchange
Opens up Hadoop to many new use cases
Stream Processing, Real-time Search,
MPI
YARN Apps
INTERACTIVE
Hive Server (Tez/Stinger)
Query/ Analytics/Reporting
Tools
Tableau/Excel
Datameer/Platfora/SAP Use Case Type 2: Explore/Visualize
FALCON (data pipeline & flow management)
Manage Steps 1-4: Data Management with Falcon
Oozie (Batch scheduler)
(data processing)
HIVE PIG Mahout Exchange
HBase Client
Sqoop/Hive
Downstream Data Sources
OLTP Hbase,
EDW (Teradata)
Storm SAS
SolR
TEZ
Step 3: Transform, Aggregate & Materialize
MR2
Step 4: Schedule and Orchestrate
Ingestion
SQOOP
FLUME
Web HDFS
NFS
SOURCE DATA
ClickStream Data
Sales Transaction/Data
Product Data
Marketing/Inventory
Social Data
EDW
File
JMS
REST
HTTP
Streaming
STORM
Step 1:Extract & Load


















