
MediaEval 2015 - The NNI Query-by-Example System for MediaEval 2015
13
NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany The NNI Query-by-Example System for MedialEval 2015 Jingyong Hou 1 , Van Tung Pham 2 , Cheung-Chi Leung 3 , Lei Wang 3 , Haihua Xu 2 , Hang Lv 1 , Lei Xie 1 , Zhonghua Fu 1 , Chongjia Ni 3 , Xiong Xiao 2 , Hongjie Chen 1 , Shaofei Zhang 1 , Sining Sun 1 , Yougen Yuan 1 , Pengcheng Li 1 , Tin Lay Nwe 3 , Sunil Sivadas 3 , Bin Ma 3 , Eng Siong Chng 2 , Haizhou Li 2,3 1 Northwestern Polytechnical University (NPWU), Xi’an, China 2 Nanyang Technological University (NTU), Singapore 3 Institute for Infocomm Research (I 2 R), A*STAR, Singapore Presented by CheungChi Leung Ins3tute for Infocomm Research (I 2 R), A*STAR, Singapore 1
-
Upload
multimediaeval -
Category
Education
-
view
116 -
download
1
Transcript of MediaEval 2015 - The NNI Query-by-Example System for MediaEval 2015

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
The NNI Query-by-Example System for MedialEval 2015
Jingyong Hou1, Van Tung Pham2, Cheung-Chi Leung3, Lei Wang3, Haihua Xu2, Hang Lv1, Lei Xie1, Zhonghua Fu1, Chongjia Ni3, Xiong Xiao2, Hongjie Chen1, Shaofei Zhang1, Sining Sun1, Yougen Yuan1,
Pengcheng Li1, Tin Lay Nwe3, Sunil Sivadas3, Bin Ma3, Eng Siong Chng2, Haizhou Li2,3
1Northwestern Polytechnical University (NPWU), Xi’an, China 2Nanyang Technological University (NTU), Singapore 3Institute for Infocomm Research (I2R), A*STAR, Singapore
Presented by Cheung-‐Chi Leung Ins3tute for Infocomm Research (I2R), A*STAR,
Singapore 1

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
System Diagram
2
• Score-level fusion of 66 systems from our 3 groups: – 15 DTW systems from NWPU – 39 DTW systems from I2R – 8 DTW systems and 4 SS systems
from NTU
• Our submitted system involves: – DTW mainly on bottleneck features/stacked bottleneck features – Symbolic search (SS) using phoneme tokenizers and weighted finite state transducer
(WFST)
Highlight of this year’s system: -‐ Noise robustness techniques to deal with noisy
data of this year
query audio search audio
tokenizer tokenizer tokenizer tokenizer ... ...
DTW DTW SS SS ... ...
intra-‐group and inter-‐group fusion
results

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Training Resources for Tokenizers • Tokenizers are used to convert the audio signal into
• bottleneck features (BNF)/stacked bottleneck features (SBNF)/posteriorgrams for DTW systems
• phone sequences/lattices for SS systems
3
Training corpora or phoneme recognizers NWPU I2R NTU Switchboard (English) √ √ √√
Development languages in OpenKWS
Cantonese √ √ √ Pashto √ √ √ Tagalog √ √ √ Tamil √ √ Turkish √ √ √ Vietnamese √ √
Fisher Spanish √ HKUST Mandarin √ CallHome EgypRan Arabic √ SEAME (mixed Mandarin-‐English) √ MASS (Malay) √ BUT phoneme recognizers (Czech, Hungarian and Russian) √ √ used in SS system(s)
√ used in DTW system(s)

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
DTW Systems
• Exact matching systems: conventional subsequence DTW; Good for type 1 queries
• Approximate matching systems to deal with type 2&3 queries • Use partial feature segment of query for matching • 1) Fixed-window based1: • Segments of 70-90 frames shifted by 5-10 frames
• 2) Phoneme-sequence based2: • Segments formed by consecutive 8 phonemes (phoneme
boundaries derived from phoneme recognizers)
1 P. Yang et al, “The NNI query-by-example system for MediaEval 2014” in Proc. MediaEval 2014 workshop, pp. 16-17. 2 J. Hou et al, “Spoken term detection technology based on DTW,” Journal of Tsinghua University (Sci and Tech), 2015 (to be published).
4

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Exact matching and approximate matching DTW Systems
• Fused results of 13 exact matching and 13 approximate matching (fixed-window based) DTW systems (from the 13 SBNF/BNF tokenizers)
5
minCnxe (maxTWV) on dev
Exact matching DTW
Approx. matching DTW
Exact+Approx. Matching DTW
Type 1 queries 0.700 (0.293) 0.711 (0.312) 0.685 (0.314)
Type 2 queries 0.893 (0.083) 0.853 (0.112) 0.852 (0.122)
Type 3 queries 0.874 (0.124) 0.867 (0.120) 0.856 (0.135)
All queries 0.844 (0.166) 0.828 (0.179) 0.817 (0.190)

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Adding Noise to Training Data for Tokenizers
• Precautions: – Signal-to-noise (SNR) distribution of the noise-added training data
should be similar to that of development data – Only portion (~50%) of training data is added with noise (as not all
utterances in this year are highly noisy)
6
QUESST dev data
training data of a tokenizer
tokenizer
noise segment
noise segment extracRon
model training

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Adding Noise to Training Data for Tokenizers
• Results of an exact matching DTW system using SBNF (tokenizer trained using Switchboard corpus)
7
minCnxe (maxTWV) on dev
Baseline (orig. Switchboard data) baseline+noise1 baseline+noise2
Type 1 queries 0.762 (0.227) 0.733 (0.258) 0.735 (0.270)

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Speech Enhancement • Wiener filter is used to reduce noise in utterances1 • Initial results show this leads to better DTW search performance for some
tokenizers • Further investigation will be conducted
8
minCnxe (maxTWV) of exact matching DTW systems on type 1 dev queries
baseline w/ speech enhancement
Switchboard monophone SBNF 0.894 (0.097) 0.870 (0.110)
BUT-‐CZ posteriorgrams 0.931 (0.018) 0.872 (0.103)
BUT-‐HU posteriorgrams 0.909 (0.070) 0.857 (0.114)
1J. Chen, J. Benesty, Y. Huang, and T. Gaensle, "On single-‐channel noise reducRon in the Rme domain," in Proc ICASSP, 2011, pp.277-‐280.
NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
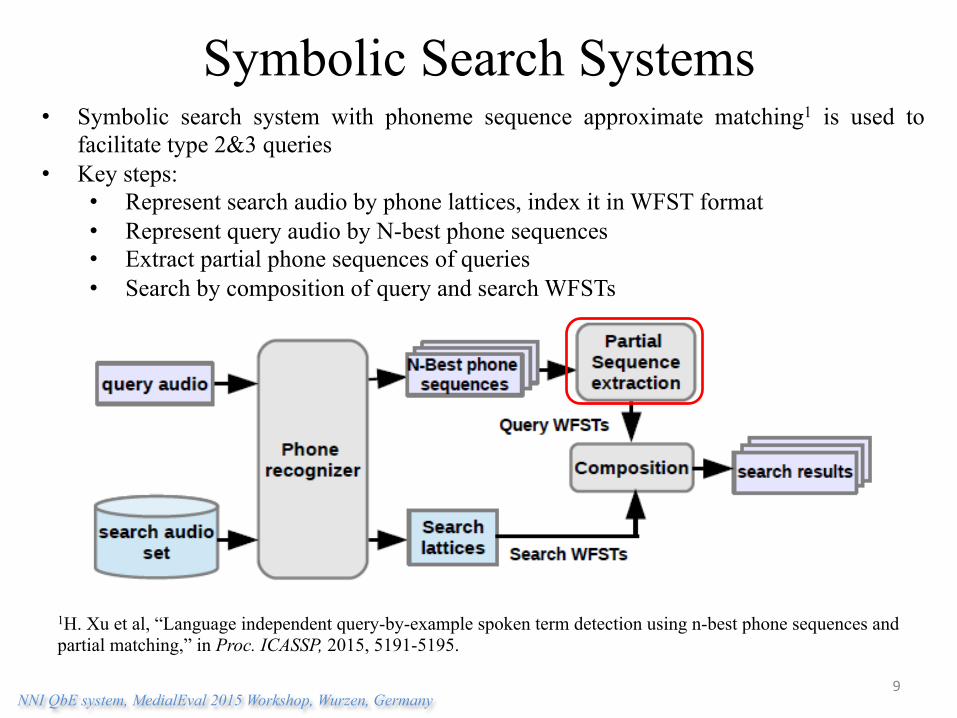
Symbolic Search Systems • Symbolic search system with phoneme sequence approximate matching1 is used to
facilitate type 2&3 queries • Key steps:
• Represent search audio by phone lattices, index it in WFST format • Represent query audio by N-best phone sequences • Extract partial phone sequences of queries • Search by composition of query and search WFSTs
9
1H. Xu et al, “Language independent query-by-example spoken term detection using n-best phone sequences and partial matching,” in Proc. ICASSP, 2015, 5191-5195.

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Symbolic Search Systems • Further improvement by fusing 4 SS systems and 8 DTW
system (4 exact matching and 4 fixed-window approximate matching) – Different types of systems use the same 4 tokenizers
10
minCnxe (maxTWV) on dev
DTW (including exact+approx.) SS DTW + SS relaRve
improvement
Type 1 queries 0.683 (0.321) 0.871 (0.150) 0.680 (0.331) 0.4% (3.1%)
Type 2 queries 0.878 (0.098) 0.902 (0.068) 0.831 (0.168) 5.4% (71.4%)
Type 3 queries 0.878 (0.113) 0.934 (0.072) 0.854 (0.174) 2.7% (54.0%)
All queries 0.836 (0.177) 0.910 (0.094) 0.809 (0.224) 3.2%(26.5%)

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Results
• Each group experienced performance gain by: – fusing exact-matching and approximate-matching systems – fusing systems with systems using different speech preprocessing
techniques (e.g. noise extraction, speech enhancement or VAD) – fusing systems with different tokenizers
• Further performance gain by inter-group fusion • Compared with our single best exact matching DTW systems,
system fusion brings around 13.5% relative improvement in minCnxe (115% in maxTWV) on all query types in dev
11

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Conclusion
12
• We have described the NNI system for the QUESST 2015 • Noise robustness techniques are used to deal with the noise
condition of data, and lead to better search performance • Same observations are obtained as last year: • Complementary DTW and SS systems • Complementary exact matching and approximate matching
systems • Further investigation will be conducted for speech
enhancement techniques, and the gain provided by BNF and SBNF

NNI QbE system, MedialEval 2015 Workshop, Wurzen, Germany
Thanks !
13


















