

Maximilian Michels – Google Cloud Dataflow on Top of Apache Flink
33
-
Upload
flink-forward -
Category
Technology
-
view
5.988 -
download
1
Transcript of Maximilian Michels – Google Cloud Dataflow on Top of Apache Flink

Contents § Google Cloud Dataflow and Flink § The Dataflow API § From Dataflow to Flink § Translating Dataflow Map/Reduce § Demo
2

Google Cloud Dataflow § Developed by Google § Based on the concepts of • FlumeJava (batch) • MillWheel (streaming)
§ Perfect integration into Google’s infrastructure and services • Google Compute Engine • Google Cloud Storage • Google BigQuery • Resource management • Monitoring • Optimization
3
Motivation § Execute on the Google Cloud Platform
• Very fast and dynamic infrastructure • Scale in and out as you wish • Make use of Google’s provided services
§ Execute using Apache Flink • Run your own infrastructure (avoid lock-in) • Control your data and software • Extend it using open source components
§ Wouldn’t it be great if you could choose? • Unified batch and streaming API • Similar concepts in batch and streaming • More options
4

The Dataflow API
5

The Dataflow API
PCollection A parallel collection of records which can be either bound (batch) or unbound (streaming)
PTransform A transformation that can be applied to a parallel collection
Pipeline A data structure for holding the dataflow graph
PipelineRunner A parallel execution engine, e.g. DirectPipeline, DataflowPipeline, or FlinkPipeline
6

WordCount in Dataflow #1
7
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create() .as(DataflowPipelineOptions.class); options.setRunner(DataflowPipelineRunner.class);
Pipeline p = Pipeline.create(options); p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(new CountWords())
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
p.run(); }

Word Count Dataflow #2
public static class CountWords extends
PTransform<PCollection<String>,PCollection<KV<String, Long>>> { @Override public PCollection<KV<String, Long>> apply(
PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.perElement()); return wordCounts; } }
8
Count Words

Word Count Dataflow #3
public static class ExtractWordsFn extends DoFn<String, String> {
@Override public void processElement(ProcessContext context) { String[] words = context.element().split("[^a-zA-Z']+"); for (String word : words) { if (!word.isEmpty()) { context.output(word); } } } }
9
Extract Words

Word Count Dataflow #4
public static class PerElement<T> extends PTransform<PCollection<T>, PCollection<KV<T, Long>>> {
@Override public PCollection<KV<T, Long>> apply(PCollection<T> input) { input.apply(ParDo.of(new DoFn<T, KV<T, Void>>() { @Override public void processElement(ProcessContext c) { c.output(KV.of(c.element(), (Void) null)); } }))
.apply(Count.perKey()); } } 10
Count

From Dataflow to Flink
11

From Dataflow to Flink public class MinimalWordCount { public static void main(String[] args) { DataflowPipelineOptions options = PipelineOptionsFactory.create() .as(DataflowPipelineOptions.class); options.setRunner(BlockingDataflowPipelineRunner.class); // Create the Pipeline object with the options we defined above. Pipeline p = Pipeline.create(options); // Apply the pipeline's transforms. p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*")) .apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() { private static final long serialVersionUID = 0; @Override public void processElement(ProcessContext c) { for (String word : c.element().split("[^a-zA-Z']+")) { if (!word.isEmpty()) { c.output(word); } } } })) .apply(Count.<String>perElement()) .apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>, String>() { private static final long serialVersionUID = 0; @Override public void processElement(ProcessContext c) { c.output(c.element().getKey() + ": " + c.element().getValue()); } .apply(TextIO.Write.to("gs://my-bucket/wordcounts")); // Run the pipeline. p.run(); } }
12
Dataflow Flink PCollec(on DataSet / DataStream PTransform Operator Pipeline Execu(onEnvironment
PipelineRunner Flink!
public class MinimalWordCount { public static void main(String[] args) { DataflowPipelineOptions options = PipelineOptionsFactory.create() .as(DataflowPipelineOptions.class); options.setRunner(BlockingDataflowPipelineRunner.class); // Create the Pipeline object with the options we defined above. Pipeline p = Pipeline.create(options); // Apply the pipeline's transforms. p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*")) .apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() { private static final long serialVersionUID = 0; @Override public void processElement(ProcessContext c) { for (String word : c.element().split("[^a-zA-Z']+")) { if (!word.isEmpty()) { c.output(word); } } } })) .apply(Count.<String>perElement()) .apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>, String>() { private static final long serialVersionUID = 0; @Override public void processElement(ProcessContext c) { c.output(c.element().getKey() + ": " + c.element().getValue()); } .apply(TextIO.Write.to("gs://my-bucket/wordcounts")); // Run the pipeline. p.run(); } }

The Dataflow SDK § Apache 2.0 licensed https://github.com/GoogleCloudPlatform/DataflowJavaSDK
§ Only Java (for now) § 1.0.0 released in June
§ Built with modularity in mind § Execution engine can be exchanged § Pipeline can be traversed by a visitor § Custom runners can change the translation
and execution process
13

A Dataflow is an AST Dataflow Program
Transform
Transform
Transform Transform
Transform
Transform 14

The WordCount AST RootTransform
TextIO.Read (ReadLines) CountWords
ParDo (ExtractWords) Count.PerElement
ParDo (Init)
Combine.PerKey (Sum.PerKey)
GroupByKey
GroupByKeyOnly
GroupedValues
ParDo
ParDo (Format Counts)
TextIO.Write (WriteCounts)
15

The WordCount Dataflow
TextIO.Read (ReadLines) ExtractWords GroupByKey Combine.PerKey
(Sum.PerKey) ParDo
(Format Counts) TextIO.Write
(WriteCounts)
16
§ AST converted to Execution DAG
RootTransform
TextIO.Read (ReadLines) CountWords
ParDo (ExtractWords) Count.PerElement
ParDo (Init)
Combine.PerKey (Sum.PerKey)
GroupByKey
GroupByKeyOnly
GroupedValues
ParDo
ParDo (Format Counts)
TextIO.Write (WriteCounts)

Dataflow Translation
17
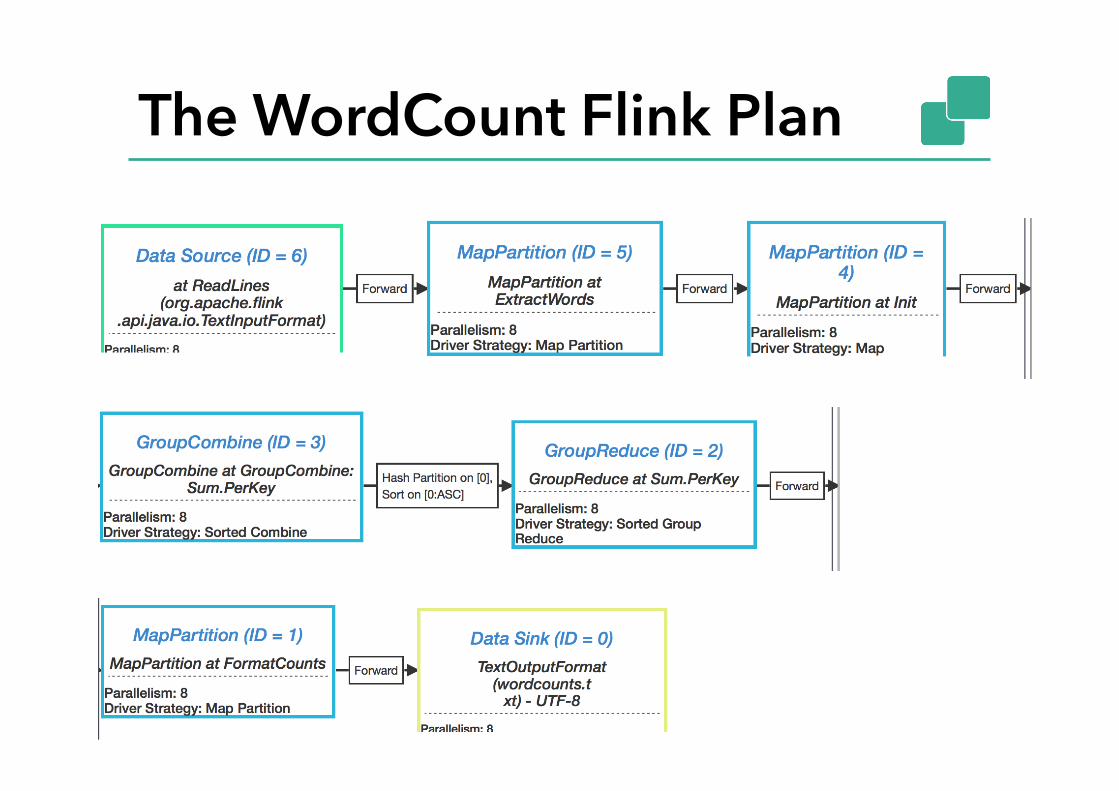
The WordCount Flink Plan
18

Implementing Map/Reduce
19

Implement a translation 1. Find out which transform to translate • ParDo.Bound • Combine.PerKey
2. Implement TransformTranslator • ParDoTranslator • CombineTranslator
3. Register TransformTranslator • Translators.add(ParDo, DoFnTranslator) • Translators.add(Combine, CombineTranslator)
20
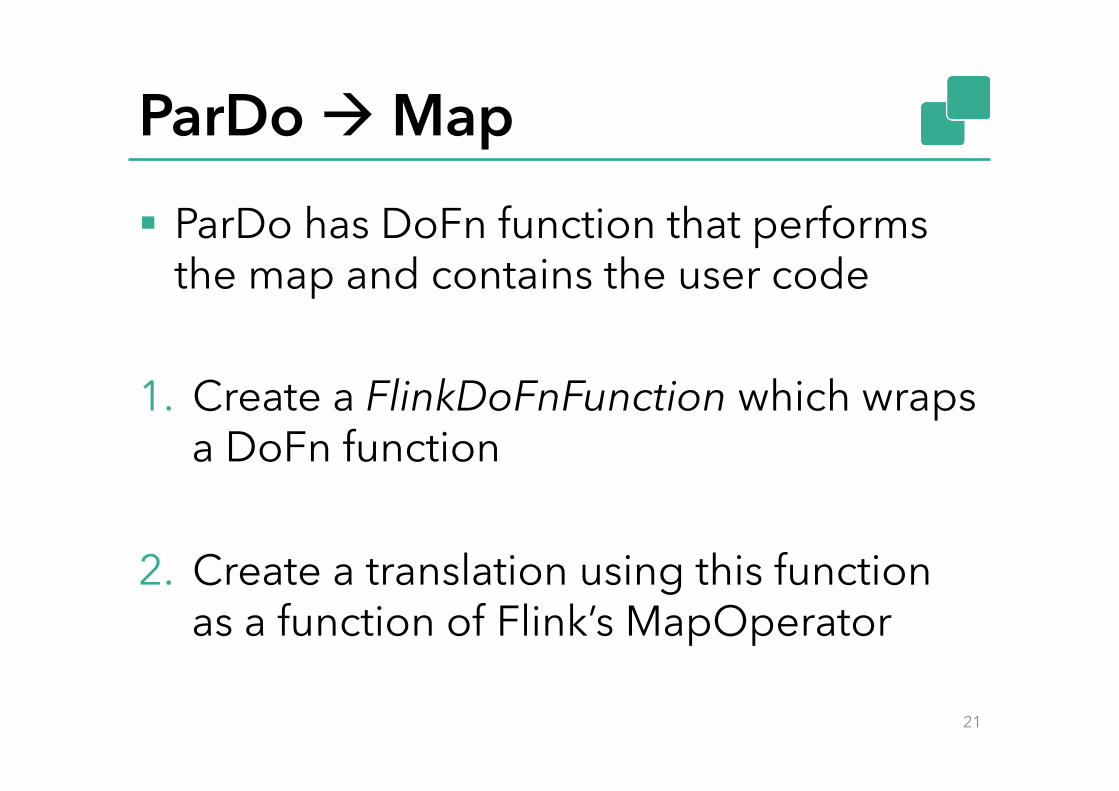
ParDo à Map § ParDo has DoFn function that performs
the map and contains the user code
1. Create a FlinkDoFnFunction which wraps a DoFn function
2. Create a translation using this function
as a function of Flink’s MapOperator
21

Step 1: ParDo à Map
22
public class FlinkDoFnFunction<IN, OUT> extends RichMapPartitionFunction<IN, OUT> { private final DoFn<IN, OUT> doFn; public FlinkDoFnFunction(DoFn<IN, OUT> doFn) { this.doFn = doFn; } @Override public void mapPartition(Iterable<IN> values, Collector<OUT> out) { for (IN value : values) { doFn.processElement(value); } } }

Step 2: ParDo à Map
23
private static class ParDoBoundTranslator<IN, OUT> implements FlinkPipelineTranslator.TransformTranslator<ParDo.Bound<IN, OUT>> { @Override public void translateNode(ParDo.Bound<IN, OUT> transform, TranslationContext context) { DataSet<IN> inputDataSet = context.getInputDataSet(transform.getInput()); final DoFn<IN, OUT> doFn = transform.getFn(); TypeInformation<OUT> typeInformation = context.getTypeInfo(transform.getOutput()); FlinkDoFnFunction<IN, OUT> fnWrapper = new FlinkDoFnFunction<>(doFn, context.getPipelineOptions()); MapPartitionOperator<IN, OUT> outputDataSet = new MapPartitionOperator<>(inputDataSet, typeInformation, fnWrapper); context.setOutputDataSet(transform.getOutput(), outputDataSet); } }

Combine à Reduce § Groups by key (locally) § Combines the values using a combine fn § Groups by key (shuffle) § Reduces the combined values using combine fn 1. Create a FlinkCombineFunction to wrap
combine fn 2. Create a FlinkReduceFunction to wrap combine
fn 3. Create a translation using these functions in
Flink Operators 24

The Flink Dataflow Runner
25

FlinkPipelineRunner § Available on GitHub § https://github.com/dataArtisans/flink-dataflow
§ Only batch support at the moment § Execution based on Flink 0.9.1 Roadmap § Streaming (after Flink 0.10 is out) § More transformations § Coder optimization
26

Supported Transforms (WIP)
27
Dataflow Transform Flink Operator
Create.Values FromElements
View.CreatePCollec(onView BroadCastSet
FlaDen.FlaDenPCollec(onList Union
GroupByKey.GroupByKeyOnly GroupBy
ParDo.Bound Map
ParDo.BoundMul( MapWithMul(pleOutput
Combine.PerKey.class Reduce
CoGroupByKey CoGroup
TextIO.Read.Bound ReadFromTextFile
TextIO.Write.Bound WriteToTextFile
ConsoleIO.Write.Bound Print
AvroIO.Read.Bound AvroRead
AvroIO.Write.Bound AvroWrite

Types & Coders § Flink has a very efficient type serialization
system § Serialization is needed for sending data
over to the wire or between processes § Flink may even work on serialized data § The TypeExtractor extracts the return
types of operators § Following operators make use of this
information
28

Types & Coders continued § Coders are Dataflow serializers § Should we use Flink’s type serialization
system or Dataflow’s? § Decision: use Dataflow coders • Full API support (e.g. custom Coders) • Comparing may require serialization or
deserialization of entire Object (instead of just the key)
29

Challenges & Lessons Learned
§ Dataflow’s API model is suited well for translation into Flink
§ Efficient translations can be tricky § For example: WordCount from 6 hours to
1 hour using a combiner and better coder type serialization
§ Implement a dedicated Combine-only operator in Flink
30

How To User the Runner § Instructions also on the GitHub page https://github.com/dataArtisans/flink-dataflow
1. Build and install flink-dataflow using Maven
2. Include flink-dataflow as a dependency in your Maven project
3. Set FlinkDataflowRunner as a runner 4. Build a fat jar including flink-dataflow 5. Submit to the cluster using ./bin/flink
31

Demo
32

That’s all Folks!
§ Check out the Flink Dataflow runner! § Write your programs once and execute
on two engines § Provide feedback and report issues on
GitHub § Experience the unified batch and
streaming platform through Dataflow and Flink
33






![StreamBox-HBM: Stream Analytics on High Bandwidth Hybrid ...pekhimenko/Papers/StreamBox-ASPLOS_19.pdf · as Flink [12], Spark Streaming [71], and Google Cloud Dataflow [5]. These](https://static.fdocuments.net/doc/165x107/5fc263a4d5e0fe745b3b5c92/streambox-hbm-stream-analytics-on-high-bandwidth-hybrid-pekhimenkopapersstreambox-asplos19pdf.jpg)











