
March12 natarajan
17
Introduction HMM Window Based MaxEnt CRF Summary References Machine Learning for Sequential Data: A Review MD2K Reading Group March 12, 2015 1 / 16
Transcript of March12 natarajan

Introduction HMM Window Based MaxEnt CRF Summary References
Machine Learning for SequentialData: A Review
MD2K Reading GroupMarch 12, 2015
1 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Classical Supervised Learning
� Given train set {(x1, y1), (x2, y2), ..., (xn, yn)}� x – features, independent variables, scalar/vector i.e. |x| ≥ 1; y ∈ Y –
labels/classes, dependent variables, scalar i.e. |y| = 1
� Learn a model h ∈ H such that y = h(x)
� Example: character classfication, x–image of hand written character,y ∈ {A,B, ...Z}
y1
x1
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
1 / 16
Introduction HMM Window Based MaxEnt CRF Summary References
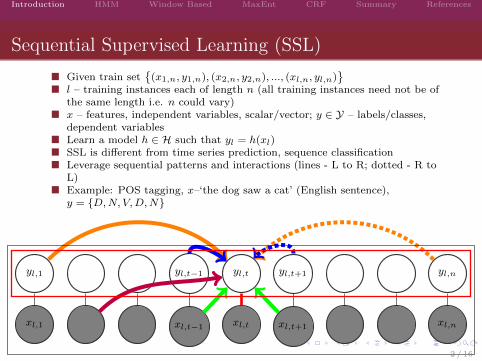
Sequential Supervised Learning (SSL)
� Given train set{
(x1,n, y1,n), (x2,n, y2,n), ..., (xl,n, yl,n)}
� l – training instances each of length n (all training instances need not be ofthe same length i.e. n could vary)
� x – features, independent variables, scalar/vector; y ∈ Y – labels/classes,dependent variables
� Learn a model h ∈ H such that yl = h(xl)� SSL is different from time series prediction, sequence classification� Leverage sequential patterns and interactions (lines - L to R; dotted - R to
L)� Example: POS tagging, x–‘the dog saw a cat’ (English sentence),
y = {D,N, V,D,N}
yl,1
xl,1
yl,t−1
xl,t−1
yl,t
xl,t
yl,t+1
xl,t+1
yl,n
xl,n
2 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
1 Hidden Markov Models
2 Window based Approaches
3 Maximum Entropy Models
4 Conditional Random Fields
3 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Hidden Markov Models (HMM)
p(y|x) =p(x|y)× p(y)
p(x)(Baye’s rule, single class)
= p(x|y)× p(y) (since p(x) is the same across all classes)
= p(x, y)
= p(x1|x2, ..., xn, y)× p(x2|x3, ..., xn, y)× ...× p(y)
= p(x1|y)× p(x2|y)× ...× p(y) (Naive Bayes assumption)
∝ p(y)n∏i=1
p(xi|y) (Naive Bayes model, single class)
p(y|x) =n∏i=1
p(yi)× p(xi|yi) (predict whole sequence; x, y are vectors)
=n∏i=1
p(yi|yi−1)× p(xi|yi) (first order Markov property; tack on y0)
P (x) =∑y∈Y
n∏i=1
p(yi|yi−1)× p(xi|yi)
(Y–all possible combinations of y sequences)
4 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
HMM (contd...)
y1
x1
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
� HMM‘s are generative models i.e. model joint probability p(x, y)
� Predicts whole sequence
� Models only the first order Markov property not suitable for many realworld applications
� xt only influences yt. Cannot model dependencies like p(xt|yt−1, yt, yt+1)which implies xt influences {yt−1, yt, yt+1}
5 / 16
Introduction HMM Window Based MaxEnt CRF Summary References
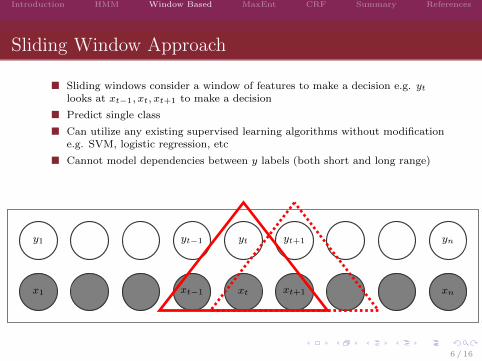
Sliding Window Approach
� Sliding windows consider a window of features to make a decision e.g. ytlooks at xt−1, xt, xt+1 to make a decision
� Predict single class
� Can utilize any existing supervised learning algorithms without modificatione.g. SVM, logistic regression, etc
� Cannot model dependencies between y labels (both short and long range)
y1
x1
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
6 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Recurrent Sliding Window Approach
� Similar to sliding window approach
� Models short range dependencies by using previous decision (yt−1) whenmaking current decision (yt)
� Problem: Need y values when training and testing
y1
x1
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
7 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Maximum Entropy Model (MaxEnt)
� Based on the Principle of Maximum Entropy (Jaynes, 1957)– if incomplete information about a probability distributionis available then the unbiased assumption that can be madeis a distribution which is as uniform as possible given theavailable information
� Uniform distribution - maximum entropy (primal problem)
� Model available information - expressed as constraints overtraining data (dual problem)
� Discriminative model i.e. models p(y|x)
� Predict a single class
8 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
MaxEnt (contd...)
I. Model the known (dual problem)
Train set = {(x1, y1), (x2, y2), ..., (xn, yn)} (given)
p(x, y) =1
N× No. of times (x, y) occurs in train set
(i.e. joint probability table)
fi(x, y) =
{1, if y = k AND x = xk0, otherwise
(e.g. y = physical activity AND x = HR ≥ 110bpm; 1 ≤ i ≤ m, m–number of features)
E(fi) =∑x,y
p(x, y)× fi(x, y) (expected value of fi from training data)
E(fi) =∑x,y
p(x, y)× fi(x, y)
(expected value of fi under model distribution)
=∑x,y
p(y|x)× p(x)× fi(x, y)
=∑x,y
p(y|x)× p(x)× fi(x, y) (replace p(x) with p(x))
we need to only learn the conditional probability as opposed to joint probability
9 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
MaxEnt (contd...)E(fi) = E(fi)∑
x,y
p(x, y)× fi(x, y) =∑x,y
p(y|x)× p(x)× fi(x, y)
(goal is to find best conditional probability p∗(y|x))
II. Make zero assumptions about the unknown (primal problem)
H(y|x) = −∑
(x,y)∈(X×Y)
p(x, y) log p(y|x) (conditional Entropy)
III. Objective function and Lagrange multipliers
Λ(p∗(y|x), λ) = H(y|x) +m∑i=1
λi
(E(fi)− E(fi)
)+ λm+1
∑y∈Y
p(y|x)− 1
(objective function)
p∗λ
(y|x) =1
Zλ(x)exp
(m∑i=1
λifi(x, y)
)(maximize conditional distribution subject to constraints)
p∗λ
(yt|yt−1, x) =1
Zλ(yt−1, x)exp
(m∑i=1
λifi(x, y)
)(inducing the Markov property results in Maximum Entropy Markov Model (MEMM))
10 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Conditional Random Fields (CRF)
� Discriminative model i.e. models p(y|x)
� Conditional probability, p(y|x), is modeled as a product offactors ψk(xk, yk)
� Factors have log-linear representation –ψk(Xk, yk) = exp(λk × φk(xk, yk))
� Predicts whole sequence
�
p(y|x) =1
Z(x)
∏C=C
ΨC(xC , yC) (CRF general form)
11 / 16
Introduction HMM Window Based MaxEnt CRF Summary References
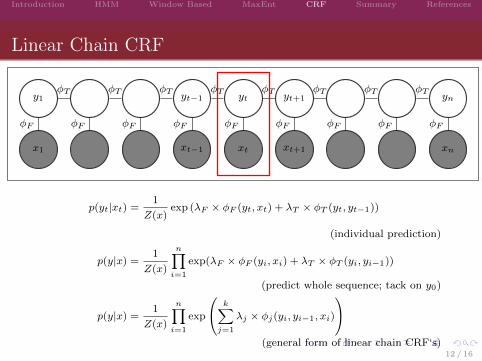
Linear Chain CRF
y1
x1
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
φF φF φF φF φF φF φF φF φF
φT φT φT φT φT φT φT φT
p(yt|xt) =1
Z(x)exp (λF × φF (yt, xt) + λT × φT (yt, yt−1))
(individual prediction)
p(y|x) =1
Z(x)
n∏i=1
exp(λF × φF (yi, xi) + λT × φT (yi, yi−1))
(predict whole sequence; tack on y0)
p(y|x) =1
Z(x)
n∏i=1
exp
k∑j=1
λj × φj(yi, yi−1, xi)
(general form of linear chain CRF‘s)
12 / 16
Introduction HMM Window Based MaxEnt CRF Summary References
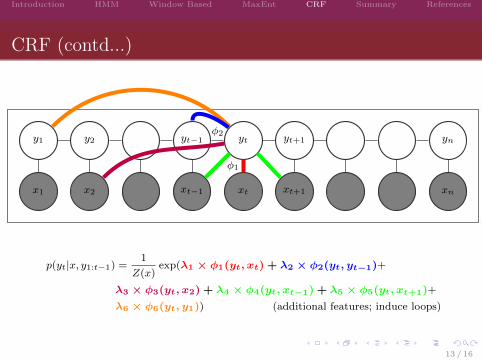
CRF (contd...)
y1
x1
y2
x2
yt−1
xt−1
yt
xt
yt+1
xt+1
yn
xn
φ1
φ2
p(yt|x, y1:t−1) =1
Z(x)exp(λ1 × φ1(yt, xt) + λ2 × φ2(yt, yt−1)+
λ3 × φ3(yt, x2) + λ4 × φ4(yt, xt−1) + λ5 × φ5(yt, xt+1)+
λ6 × φ6(yt, y1)) (additional features; induce loops)
13 / 16
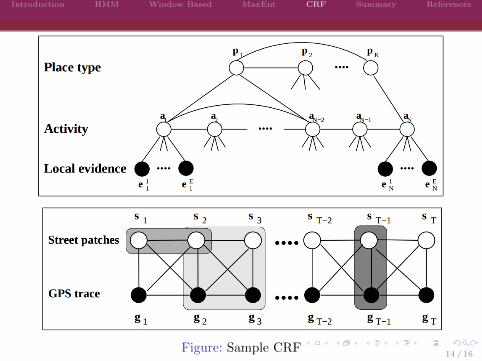
Introduction HMM Window Based MaxEnt CRF Summary References
Figure: Sample CRF
Further reading refer to [3, 4, 2, 1]
14 / 16
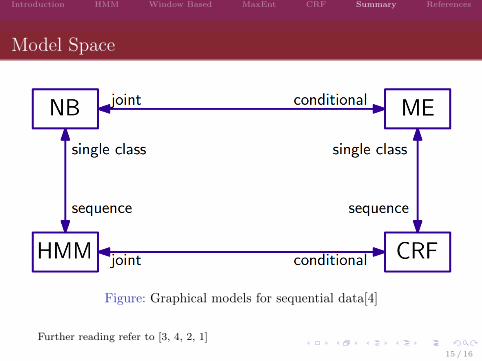
Introduction HMM Window Based MaxEnt CRF Summary References
Model Space
Figure: Graphical models for sequential data[4]
Further reading refer to [3, 4, 2, 1]
15 / 16

Introduction HMM Window Based MaxEnt CRF Summary References
Berger, A.A brief maxent tutorial.www.cs.cmu.edu/afs/cs/user/aberger/www/html/tutorial/tutorial.html.
Blake, A., Kohli, P., and Rother, C.Markov random fields for vision and image processing.Mit Press, 2011.
Dietterich, T. G.Machine learning for sequential data: A review.In Structural, syntactic, and statistical pattern recognition. Springer, 2002,pp. 15–30.
Klinger, R., and Tomanek, K.Classical probabilistic models and conditional random fields.TU, Algorithm Engineering, 2007.
16 / 16


















