
making money in the financial services - University of Surrey
34
Transcript of making money in the financial services - University of Surrey


making money in the financial services industry?
Workshop at the International Conference on Terminology and Knowledge
Engineering, 30 August 2002, Nancy France.
Table of content
??Events and the Causes of Events - Khurshid Ahmad: University of Surrey
??Automatic Analysis of Corporate Financial Disclosures - Darina M. Slattery, Richard F.E. Sutcliffe, Eamonn J. Walsh: University of Limerick and University College Dublin
??A Financial News Summarisation System based on Lexical Cohesion - Paulo Cesar Fernandes de Oliveira, Khurshid Ahmad, Lee Gillam: University of Surrey
??Processing the language of predicting and forecasting in an Italian corpus of economic reports - Maria Teresa Musacchio: University of Trieste
??Economic News and Stock Market Correlation: A Study of the UK Market - Lee Gillam, Khurshid Ahmad, Saif Ahmad, Matthew Casey, David Cheng, Tugba Taskaya, Paulo C F de Oliveira and Pensiri Manomaisupat: University of Surrey
??Multi-lingual Knowledge Bases for Information Extraction - Roberta Catizone, Andrea Sezter, Nick Webb, Yorick Wilks: University of Sheffield
??Advertisement for GIDA Project

Events and the causes of events: the use of metaphor in financial texts
Khurshid Ahmad
Department of Computing, University of Surrey, Guildford, Surrey, UK [email protected]
Abstract A metaphor is defined by the OED as ‘The figure of speech in which a name or descriptive term is transferred to some object different from, but analogous to, that to which it is properly applicable’. The origins and the status of metaphors has exercised many philosophers, linguists and kindered spirits. It appears that metaphors and metaphorical expressions are used extensively in science, technology, and, in particular in finance and commerce. The rather qualitative, and sometimes culturally-rooted origins of metaphors, may exclude this linguistic expression from the quantitative and self-avowedly object nature of finance and commerce. Financial news, sometimes suffused with metaphors, is a case in point and the topic of this paper.
1. Introduction There is a considerable amount of interest in
developing a linguistic description of events in the study of language and in linguistic philosophy. The linguistic description has as its starting point a well-constructed string of letters which manifests structure at lexical, morphological, syntactic and possibly at the semantic level of organisation of language. Here the claim is that if we had a well-developed system through which we can process lexical semantic relations and a good grammatical description of how nouns behave, then we can describe “events as grammatical objects” (Tenny & Pustejovsky 2000); for Pustejovsky, one of the major themes in this area is that there is an assumption of “a logic of interpretation where events are associated with the tensed matrix verb of a sentence and sometimes with event-denoting nominals expressions, such as war and arrival” (Pustejovsky 2000: 445). Philosophers who are interested in the interrelationship between language and knowledge, language and ethics, language and aesthetics also discuss “events, causes, changes, states, actions and purposes” (Lakoff & Johnson 1999:170) focusing on how we use language to describe events and the causes of events – this description is informed by developments in generative semantics, in linguistic universals and the so-called frame theory as developed by Charles Fillmore (1976) and by Schank and Abelson (1977) [p590-591 philosophy in the flesh].
Events can be described very simply and very crudely as changes in the state of person, places, other concrete objects, and abstract objects. In some sense the objects are given permanence for a duration of time in which they could be described fully. The objects are subject to external and internal influences and they change, but the assumption is that they change perceptibly from one clearly defined status to another clearly defined status.
Here lies the conundrum: how can we have a description that deals equitably between the required permanence, a description of the status quo of the objects under observation, and the dynamics of the objects which make them interesting in the first place. Take, for example, the value associated with a currency of a national or supranational state in the so-called developed world. The US dollar ($), the EU euro (€), the Japanese yen (¥) and the British pound (£) all have their own aura
of permanence; the symbols associated with them are just one sign of this. However, these currencies are traded in the world markets and their values are continuously changing, sometimes reflecting the state of the national and supranational economies, at other times the changes reflect the activity in the rumour-mills, at yet other times the changes are imperceptible, and during times of great crises, like war or national tragedies, the value of these symbols lose all vestiges of permanence. Goal of the paper
2. Metaphors and the Real World The description of events that affect financial markets
in itself has now become as important as the causes that may change the status of the markets and the goods and services traded within the markets. The descriptions apparently have the power to ‘talk up’ and ‘talk down’ these objects of permanence. Indeed, a whole terminology has evolved around this description: Francis Knowles (1976) has argued that the reporting of financial markets uses a number of health metaphors – anaemic, ailing, debilitating, fatal, feverish , haemorrhaging – to describe a failing economy, or a falling currency, or a poorly performing bond or a crashing share. Knowles also tells us about metaphors used to describe a healthy state of affairs – immunity, revitalisation, appetite, strength and other metaphors.
It is almost inevitable that one will refer to George Lakoff in matters of metaphor; himself now a metaphorical reference to the study of metaphors. His famous Women, Fire and Dangerous Things (1987) tells us how metaphors are the surface form of deeply held cultural, religious or ideological beliefs. The title of the book refers to the value system of a group of the original people of Australia, who spoke the language Dyirbal, and use the word balan to describe the three objects of the title which are equally revered. The term balan is then used in the spoken description of the allegories used by the people to partially create a whole system of beliefs and values. Note also that there is an icon attached to the term, that of the snake for danger, and the same icon is treated differently in different circumstances of happiness and health, tragedy and death. Lakoff and Johnson subsequently catalogue Metaphors We Live By (1980): metaphors that are used in everyday speech but couched in

specific syntactic categories and have well defined semantic relationships with other words and terms.
In their latest work, Philosophy in the Flesh , Lakoff and Johnson deal with events and causes, the linguistic description of events and causes and discuss some fundamental philosophical problems like ‘does causation exist?’ (2000:232). They conclude that it is simple-minded to think that “our language is simply a reflection of the mind-independent world, and hence that such questions [of causation and realism] are simple and straightforward” (ibid.). Events and the causes of events, or how otherwise permanent objects change and resist change, are symbiotic notions in their own right. The authors look at causal models in social sciences and give examples of the two theories in international relations, which have an impact on financial markets, namely the Domino Effect and the Plate Tectonic Theory of International Relations. The former deals with the effects after the end of the Vietnam War and the latter deals with the break-up of the Soviet Union and subsequent realignment. For the authors, these are metaphorical causal models taken from a physical domain without much acknowledgement to the literary/metaphorical nature of the basis of these models.
Lakoff and Johnson deal at length with causation. For them, states are locations, whereby one can say things like the Japanese economy is out of depression and the US economy is in deep depression. Then there is a discussion of changes: “a change of state [is a] movement from one bounded region in space to another bounded region in space” (p183). The description of such bounded movement involves the verbs and prepositions of motion like go, come, enter, from, to, into and between. The changes could be continuous or graded; the continuous changes are essentially continuous motion through a set of proximate locations and the discrete ones involve movement through clearly delineated locations. So the financial metaphor would be the revitalisation of a company or an economy : from a state of poor health to a state of relative well-being. This so-called location event-structure metaphor involves forces that are responsible for causes and force movement which affects causation. For example, we have news that “the leadership of a dynamic CEO brought an organisation out of depression” or “the news about the rise in the Producer Price Index propelled the stock market to record heights”. These examples have been paraphrased from Lakoff and Johnson and suggest examples of “verbs of force movement being used to express abstract causation” (p184). Moreover, verbs of force movement that do not have conventional abstract causal sense, like hurl and drag, are used to indicate abstract causation: “a sudden drop in wheat subsidies
hurled the agribusiness into chaos” or “the US dollar dragged the British pound and the Japanese yen down”.
The works of Lakoff and Johnson, of Pustejovsky and the empirical observations of Knowles allow us to build a framework for analysing financial news stories, reports and learned articles. Metaphors will pose considerable challenges to the current systems for information extraction that deal with the news stories, reports and learned articles in finance. Furthermore, the work in the development of terminology systems that are focused on this dynamic discipline will also have to confront similar challenges.
3. Metaphors and the Financial World Financial markets and the constituent market makers
use a range of metaphors to describe the events and the causes of events. The subject of technical analysis, where graphical and mathematical models are used to predict and describe financial markets, uses these metaphors at length, so we have animal metaphors like bear trap, bear spread, and we also have bull, butterfly spread; there are spatial metaphors like vertical spread, slippage; there are metaphors related to the human body, for instance one has head and shoulders pattern , which describes an intensive period of trading in a stock or share called a rally where the stocks and shares advance extensively, the left shoulder is a drop in price because there are not many shares left to buy, then there is the head which shows there are plenty of shares to buy that exceed the price of the previous rally and then there is the right shoulder which comprises “of a rally up which fails to exceed the height of the head” (Reuters 1999).
There is a range of “slang” used within the financial markets which makes its appearance in financial news, in quality newspapers sometimes, but more often in the internet-based reports, magazines and newspapers dealing with the markets. These metaphors are wide ranging, dealing as they do with metaphors of aesthetics, religion, health and fairytales. The current state of the financial markets (July 2002) is being referred to as a dead cat bounce. This slang term is defined as: “a temporary recovery by a market after a prolonged decline or bear market. In most cases the recovery is temporary and the market will continue to fall”. The term is elaborated further as: “Ever heard the saying "even a dead cat will bounce if it is dropped from high enough!" (http://www.investopedia.com/terms/d/deadcatbounce.asp - visited 19 July 2002). The following list shows some additions since Knowles (1996) – they were selected for their colourful value:

Metaphor Source Meaning Elaboration Angel Investor Religion A financial backer providing venture
capital funds for small startups or entrepreneurs.
Similar to the ‘angels’ that invest in theatrical productions. In most cases this is a friend or family member.
Big Uglies Aesthetics A term used to describe the old industrial companies in unglamorous industries like mining, steel, and oil. They might not be as sexy as tech stocks but do provide solid long term earnings growth and dividends.
Big uglies are often overlooked by investors looking for fast profits with growth and tech stocks. Instead value investors seeking bargain-priced stocks with a low P/E ratio scoop them up. Investors often flock to big uglies when the markets tumble because of their bulletproof earnings.
Bo Derek Aesthetics Slang used to describe a perfect stock or investment. The name Bo Derek actually comes from the 1979 movie "10" in which she portrayed the "perfect woman".
Perhaps we should take this term into the new millennium and from now on refer to a perfect stock as a "Pamela Anderson" or "Kylie Minogue".
Cats and Dogs Animals A slang term referring to speculative stocks that have short or suspicious histories for sales, earnings, dividends, etc.
In a bull market analysts will often mention that everything is going up, even the cats and dogs.
Dead Cat Bounce
Animals A temporary recovery by a market after a prolonged decline or bear market. In most cases the recovery is temporary and the market will continue to fall.
Ever heard the saying "even a dead cat will bounce if it is dropped from high enough!".
Falling Knife Health A stock whose price is in the middle of a big nose-dive.
Don't try to catch a falling knife or you'll end up getting hurt!
Goldilocks Economy
Fairytales A term referring to the U.S. economy of the middle and late 1990s because it was: "not too hot, not too cold, but just right."
Meaning is self-explanatory
Market Cannibalisation
Health
The negative impact a new product has on the sales performance of a company's existing, related products.
In other words, you are eating your own market. For example, say Coca Cola puts out a new product called Coke2. Market cannibalisation is where customers buy Coke2 instead of regular Coke, although sales are up for the product they are not increasing for the company overall. Investors always dig deeper, the company will likely not outright admit this is occurring.
Phantom Stock Plan
Fairytales An employee benefit plan that gives selected employees (senior management) many of the benefits of stock ownership without actually giving them any company stock. Sometimes referred to as a shadow stock.
Rather than getting physical stock the phantom stock is "pretend" but it follows the actual price movement of the company stock. Then profits are paid out as cash or check.
Sweetheart Deal Fairytales Usually refers to a merger or sale between two or more companies where one gives the other very attractive terms and conditions for the deal.
In other words a transaction in which the other firm simply can not pass up, this is usually considered to be unethical. A broad term, but a merger may be a "sweetheart deal" for management of the takeover target because they get healthy buyout packages, but this may not necessarily be in the best interest of shareholders.
Tombstone Health A written adverstisement placed by investment bankers in a public offering of a security. It gives basic details about the issue and, in order of importance, the underwriting groups involved in the deal.
The tombstone is supposed to be a public announcement of an issue that will be offered for sale. In practice, the tombstone is made after the issue has been sold. In other words the deal is already dead.
Vulture Capitalist Animal 1) A slang word for a venture capitalist who deprives an inventor of control over their own innovations and most of the money they should have made from the invention. 2) A venture capitalist who invests in floundering firms hoping that they will turn around.
Like them or not, many vulture capitalists make more money than the venture capitalists do.

4. Information extraction, terminology management and metaphors
In the GIDA project, and its forerunner the ACE project, the intention is to analyse financial news at the lexical level. This involves using the diachronic distribution of a set of terms, to convert the distribution in a time series, and subsequently to correlate the lexical time series with the time series of financial instruments, including shares, currencies, bonds, etc. The challenge here is to ensure that one has a full coverage of the distribution not only of key lexical items but also of the linguistic variants of the lexical items. Variants that can be dealt with at the lexical level include morphological variants (inflection, derivation, compounding), orthographic variants (the literal names of currencies or the symbols used, or other abbreviations), but also pragmatic variants. Therefore, a study of metaphors used is very important in that a metaphor is a pragmatic variant of a lexical item: referring to the dead cat bounce metaphor, one can see that the metaphor reflects the behaviour of a financial instrument over a period of time and there are equivalent terms which are used in the financial literature which will convey the same meaning.
The challenge of the GIDA project, and cognate information extraction projects, is to compile a terminology collection of these metaphors and to manage this collection such that it remains up to date, is accessible, and above all, is useful. This will be the burden of my presentation. I will illustrate my talk with the analysis of contemporary financial texts to show the extent of the use of metaphors and its effect on the development of information extraction systems.
References Fillmore, Charles. 1976. Topics in Lexical Semantics.
In P. Cole (ed.) Current Issues in Linguistic Theory. Bloomington: Indiana Univ. Press. pp76-138.
Schank, R.C., & R. P. Abelson. 1977. Scripts, Plans, Goals and Understanding. Hillsdale, N.J.: Erlbaum.
Tenny, C., & J. Pustejovsky. (eds.) 2000. Events as Grammatical Objects. Stanford, CA: CSLI Publications.
Pustejovsky, J. 2000. Events and the Semantics of Opposition. In (eds.) C. Tenny & J. Pustejovsky. Events as Grammatical Objects.
Lakoff, G., & M. Johnson. 1999. Philosophy in the Flesh. New York: Basic Books.
Knowles, F. 1996. ‘Lexicographical Aspects of Health Metaphors in Financial Text’. In Proc. I-II of Euralex ’96 – 7th EURALEX International Congress on Lexicography. Göteborg, Sweden.
Lakoff, George. 1987. Women, Fire, and Dangerous Things. Chicago, IL: University of Chicago Press.
Lakoff, G., & M. Johnson. 1980. Metaphors We Live By. Chicago, IL: University of Chicago Press.
Reuters. 1999. An Introduction to Technical Analysis. Singapore: John Wiley & Sons (Asia) Pte Ltd.
http://www.investopedia.com/terms/d/deadcatbounce.asp – visited 19 July 2002

Automatic Analysis of Corporate Financial Disclosures
Darina M. Slattery*, Richard F.E. Sutcliffe*, Eamonn J. Walsh†
*Department of Computer Science and Information Systems, University of Limerick, Limerick, Ireland
{Darina.Slattery, Richard.Sutcliffe}@ul.ie †Department of Accountancy,
University College Dublin, Dublin, Ireland [email protected]
Abstract US Corporations are required by the Securities and Exchange Commission to file annual and interim disclosures on the Electronic Data Gathering, Analysis and Retrieval (EDGAR) system. Shareholders and investors attempt to analyse these disclosures in the hope of predicting the likely share price response. We are investigating the correlation between the release of disclosure information and the share price response and present three experiments in which a Decision Tree System and an Inverted Index System are trained against a collection of disclosures. The disclosures have been tokenised and contain only the most frequently occurring compounds. The Decision Tree System equalled or outperformed the Inverted Index System in two of the three experiments.
1. Introduction Investment analysts attempt to predict the share price
of a company by analysing information from a variety of sources. These sources include historical share price data, past performance records, current news announcements, Annual General Meetings, and market trends (Firth, 1976; Barker, 1997).
Heffernan (1996) maintains that share prices can be split into two parts: a random part and an ordered part. Share prices are ordered when everyone agrees on the likely share price response. Share prices are random when people disagree on the likely share price response. The information available to interested parties is vital when deciding how the share price is likely to respond.
The Efficient-Markets Model states that share prices always fully reflect all available knowledge of a company. It implies that all information about a company is publicly available and that this information is interpreted correctly in the share price. However, Firth (1976) argues that this is often not the case. He refers to the three types of Efficient-Markets Model. The Weak-Form Efficient Markets Model refers to a situation when historical share price data is of little benefit when trying to make excess profits above the market average. The Semi-Strong Form Efficient Markets Model is when all publicly available information is speedily and accurately incorporated into share prices and excess profit can only be made if one has insider information. The Strong-Form Efficient Markets Model is when the market is very well regulated and insider information is rare and when it does occur, it does not affect market efficiency.
Millard (1990) argues that by the time the information is made available to the general public, it will already have had an impact on the share price because some will have had insider information or will have made an educated guess as to the likely impact on the share price.
Quinn et al., (1997) studied 290 UK companies to investigate the share price response at the time of the release of the Interim Report, the Earnings Report, the Annual Report to Shareholders, and the Annual General Meeting. Their findings indicate that the Interim Report and the Earnings Report contain significant information
whereas the Annual Report to Shareholders and the Annual General Meeting produced little or no additional information. They also found that accounting disclosures vary in their effect according to industry.
Schadewitz et al., (1999) used the Determinants Forecasting Model to score a disclosure based on the information it contained. The aim of this study was to investigate if the degree of voluntary disclosure about interim earnings could affect the share price response. They assumed that the degree of voluntary disclosure was determined by the quality of the information being revealed. Their study suggested that when the market expected low levels of voluntary disclosure, companies with good news to report should increase their levels of disclosure. They offered a number of reasons for this. One such reason was that when the market received more information than was anticipated, and the information was positive, the market responded positively.
The study found that the market did not respond significantly to high levels of voluntary disclosure as it tended to be made by companies facing some form of difficulty. By the time the bad news event actually occurred, the market had already digested most of the information and so the market response was not very significant.
In our study, we are focusing on disclosures filed on EDGAR – the Electronic Data Gathering, Analysis and Retrieval system (EDGAR, 2002) maintained by the U.S. Securities and Exchange Commission (SEC, 2002). US corporations are legally obliged to file certain disclosures with the SEC and these are made available to the public on EDGAR. As law dictates the format of these disclosures, they often contain information that companies would not otherwise wish to disclose voluntarily. For this reason, we believe EDGAR disclosures may have a greater impact on share prices than voluntary disclosures.
Examples of disclosures filed with the SEC include the Company Prospectus, the Form 10-K (the annual report), and the Form 8-K (the recent material events report). Having studied the content requirements for all types of disclosures filed with the SEC, it became evident that Form 8-Ks contain information of material interest to shareholders. Form 8-Ks typically consist of a header,

event information, and appendices. Header information includes the date the filing was made with the SEC and the name and address of the company. The event information consists of one or more pre-defined Items ranging from Item 1 to Item 14. Examples of Items include ‘Item 1: Changes in Control of the Registrant’ (e.g. reporting mergers and acquisitions) and ‘Item 5: Other Events’ (e.g. reporting revenues). Appendices can include press releases and merger agreements.
2. Research Objective The objectives of the work presented are to investigate
the correlation between the release of disclosure information and share price responses, and to develop a system that will analyse such disclosure information and predict the likely share price response accordingly.
There are two principal stages of research. The first stage involves developing methods for identifying interesting sections within disclosures. The second entails using retrieval and learning techniques to predict the likely share price response, based on content identified in the first stage.
3. System Architectures
3.1. Decision Tree System The C4.5 Decision Tree System (DTS) derives a
decision tree by answering questions about non-categorial attributes and attempting to deduce accurately the value of the categorial attribute (Quinlan, 1993).
The system reads in a set of records and each record refers to a particular disclosure. Each record must contain the same number of non-categorial attributes and must be structured in the same way. Each non-categorial attribute has a binary value and refers to a particular phrase. If the phrase is present in the disclosure, the non-categorial attribute is set to true. Otherwise, the non-categorial attribute is set to false. The categorial attribute refers to the direction of the share price response around the time the disclosure was filed and is set to up, down, or nochange.
The system generates detailed and simplified decision trees and shows how these trees perform on the training disclosures. A misclassification error is estimated for unseen (test) disclosures, based on that found for the training disclosures. The system then shows how the trees perform on unseen disclosures and the estimated misclassification error can then be compared to the actual misclassification error.
3.2. Inverted Index System The Inverted Index System (IIS) is a conventional
Information Retrieval (IR) system which uses the Probabilistic Matching Function described in Robertson and Sparck Jones (1997). Typically, an IR system is indexed on a large collection of documents. When presented with a query, the system returns a list of the documents that best match the query.
In our experiments, the training disclosures are categorised into one of three groups (up, down, or nochange), depending on the direction of the share price response. Each group of training disclosures is treated as one document during the indexing process.
When the IIS is presented with a query (test) disclosure, the closest matching group is deemed to be the classification for that query disclosure. This is done for all query disclosures and the overall accuracy is returned as output. A default classification is chosen when the system cannot discern an answer. The default classification is set to up.
4. Training Data We obtained the filing date, URL and share price
response around the filing date for 567 8-K disclosures. The disclosures were all in the 7372 Standard Industry Classification (SIC) domain, which refers to companies engaged in “Services – Prepackaged Software”. Each of these disclosures was downloaded from EDGAR.
As regards direction of share price response, 41% of the 567 disclosures resulted in an increase (the ups), 46% resulted in a decrease (the downs), and 13% did not result in any change (the nochanges). For our experiments, we selected 219 of the 567 disclosures. The 219 consisted of an equal number of ups, downs, and nochanges.
5. Experiments
5.1. Method The ups, downs and nochanges were each randomly
divided into 80% training data and 20% test data. The same breakdown of training and test disclosures was used for both systems and for each of the three experiments.
A phrase list of five-word clusters was generated for all disclosures using Wordsmith Tools (Scott, 2002) and the phrase list was sorted by frequency in descending order. This phrase list was then converted to lowercase, tokenised, and read in to another program as a series of clauses. The training and test disclosures were converted to lowercase and tokenised. The clauses were used to create a single token for each multiple word phrase featured in the training and test disclosures. Examples of single token phrases are shown in Table 1.
a_material_adverse_effect_on
agreement_and_plan_of_merger
actual_results_to_differ_materially
Table 1: Examples of Single Token Phrases We conducted three experiments, using both systems
in each experiment. For our first experiment, a phrase list consisting of the 100 most frequently occurring phrases was used. For our second experiment, a phrase list consisting of the 1,000 most frequently occurring phrases was used. For our third experiment, a phrase list consisting of the 10,000 most frequently occurring phrases was used. Each multiple word phrase in the three phrase lists was represented by a single token, similar to those shown in Table 1.
The data was prepared for the Decision Tree System (DTS) using pattern-matching techniques. For each phrase in the phrase list that appeared in the training or test disclosure, the relevant non-categorial attribute was set to true. Otherwise, it was set to false. The relevant

categorial attribute (i.e. the share price response) was appended to the end of each record. We ran the DTS using each of the three phrase lists.
The data was prepared for the Inverted Index System (IIS) by concatenating all training ups. Concatenation was also performed on all training downs and on all training nochanges. These three documents were then indexed and compared to each of the query disclosures using the Probabilistic Matching Function. We ran the Inverted Index System using each of the three phrase lists.
N-Most
Frequent Phrases
DTS IIS (Default
up)
IIS (Default down)
IIS (Ignore Default)
100 38% 36% 38% 45%
1,000 44% 31% 38% 34%
10,000 42% 40% 42% 42%
Table 2: Classification Accuracy using the Decision Tree System and Inverted Index System
5.2. Results The results of the three experiments are shown in
Table 2. N-Most Frequent Phrases refers to the number of phrases used in each of the three experiments.
The classification accuracy of the DTS rose from 38% when 100 phrases were used to 44% when 1,000 phrases were used. However, the accuracy dropped slightly to 42% when 10,000 phrases were used. In his evaluation of a similar Decis ion Tree System to C4.5, Lewis (1994) argues that additional features (i.e. non-categorial attributes) are only useful if they appear in a sufficient number of training examples. This suggests we may need more training disclosures if we want to improve the performance when using such a large number of phrases.
As mentioned in section 3.2, the default classification for the Inverted Index System (IIS) is set to up. We also computed the classification accuracy of the IIS with the default set to down. However, as one would not want to invest money based on a default decision, we also computed the classification accuracy by ignoring the default classifications entirely.
Regardless of default used, the classification accuracy of the IIS either decreased or stayed the same when the number of phrases was increased from 100 to 1,000. However, the accuracy rose again when 10,000 phrases were used, which suggests that unlike the DTS, the performance of the IIS is not constrained by the number of training disclosures.
When ignoring the default classifications and using 100 phrases, the IIS achieved the highest overall performance, which was 45%. However, to achieve this result, we had to ignore 82% of the disclosures.
6. Conclusions and Next Steps The key findings of this study are that the Decision
Tree System (DTS) outperforms the Inverted Index System (IIS) when 1,000 phrases are used, regardless of the default. When 10,000 phrases are used, the DTS outperforms the IIS when the default is set to up but
equals the IIS when the default is set to down or when we ignored the default classifications entirely.
We need to establish which system has greater potential for improved performance, as the current performance levels are not satisfactory. Our findings suggest that we may be able to improve the performance of the DTS if we select the optimal number of non-categorial attributes (i.e. phrases) for a given number of disclosures. It is not yet evident what can be done to improve the performance of the IIS. As a result, our next step will be to determine the optimal number of non-categorial attributes for the DTS, using the 567 disclosures we currently have at our disposal.
At present, our systems are using a three-way classification, as the share price response can be up, down or nochange. As 87% of the 567 disclosures resulted in an increase or a decrease in share price, we will also investigate the performance of both systems using a two-way classification (up and down only), to determine if that will improve performance.
7. References Barker, R. G., 1997. The Role of Accounting Information
in Investment Decisions on the London Stock Exchange: a Study of Finance Directors, Analysts and Fund Managers. Ph.D. thesis, University of Cambridge.
EDGAR, 2002. Electronic Data Gathering, Analysis and Retrieval. System maintained by the U.S. Securities and Exchange Commission, Washington DC. Online: http://www.sec.gov/edgar.shtml
Firth, M., 1976. Share Prices and Mergers – A Study of Stock Market Efficiency. Saxon House.
Heffernan, S., 1996. Modern Banking in Theory and Practise. Wiley Publications.
Lewis, D. D., 1994. A Comparison of Two Learning Algorithms for Text Categorization. Proceedings of the Third Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, Nevada, April 11-13, 1994.
Millard, B. J., 1990. Stocks and Shares Simplified – A Guide for the Smaller Investor. Wiley Publications, 3rd Edition.
Quinlan, J. R., 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann, San Mateo, California.
Quinn, M. A., J. Fletcher, and I. A. M. Fraser, 1997. Market Reaction to Accounting Disclosures: Share Price Response, Firm Size and Industry Effect. Proceedings of the 20th Annual Congress of the European Accounting Association, Graz, Austria, April 23-27, 1997.
Robertson, S. E. & K. Sparck Jones, 1997. Simple, Proven Approaches to Text Retrieval. Technical Report TR356, Computer Laboratory, University of Cambridge.
Schadewitz, H. J., A. J. Kanto, H. A. Kahra, and D. R. Blevins, 1999. On the Effects of Various Degrees of Voluntary Disclosure on Share Returns. Online: http://www.westga.edu/~bquest/1999/disclose.html
Scott, M., 2002. Wordsmith Tools. Published by Oxford University Press. Online: http://www.lexically.net/wordsmith/version4/index.htm
SEC, 2002. U.S. Securities and Exchange Commission, Washington DC. Online: http://www.sec.gov

A Financial News Summarisation System based on Lexical Cohesion
Paulo Cesar Fernandes de Oliveira, Khurshid Ahmad, Lee Gillam
Department of Computing School of Electronics, Computing and Mathematics
University of Surrey Guildford, Surrey, England, GU2 7XH
{p.fernandes-de-oliveir, k.ahmad, l.gillam}@surrey.ac.uk
Abstract Summarisation is important for the dissemination of information and forms an integral part of work in information extraction. A collection of keywords can be treated as a summary of a text , an abstract is essentially a summary of a (learned) text, and a headline can also be deemed as a summary. The automatic generation of summaries typically relies on the statistical distribution of terms in a given text or on the linguistic/pragmatic behaviour of key terms in the text. The latter is the subject of this paper: how can we use linguistic devices that are supposed to engender cohesion in a text for producing summary of the text. Michael Hoey (1991) proposed lexical cohesion as a basis for producing summaries of non-narrative texts. We have used lexical cohesion to produce summaries of narrative texts, namely financial news. SummariserPort is a system that produces summaries of financial texts and is currently being evaluated.
1. Introduction The rapid growth of information due to the World
Wide Web and on-line information services, have increased demands for effective and efficient methods of accessing and condensing texts. The growth in the volumes of financial news available has also grown in line with these other information sources. Company reports, analysts’ reports, on-line briefings and a host of discussions are readily available on financial websites and can be delivered to your email. According to America’s number-one money manager Peter Lynch (Lynch, p.20) “Stock market news has gone from hard to find (in the 1970s and early 1980s), then easy to find (in the late 1980s), then hard to get away from”. We can argue that for the 00s, it is hard to find the news in the constant commentary.
It is possible to retrieve vast quantities of materials using Information Retrieval (IR) as evidenced through a variety of search engines. One further consequence of this growth is the need for some form of text summarization such that the retrieved content can be reduced to a readable volume. In this respect, automatic text summarization has increasingly stimulated interest in both research and commercial sectors.
The main goal of automatic summarization is to take an information source, extract content from it, and show or present to the user the most important part in a condensed form according to the user’s needs, and in a sensitive manner (Mani, 2000). A summary generated by a computer program that can mimic the summarizing skills of a human being would have a big commercial and scientific value (e.g. financial market) (Benbrahim, 1996).
In short, a summary acts as a filter, indicating the major content of the original story. A good summary will provide the reader with an indication of whether the whole document is worth reading. A wide variety of texts can benefit from summarization, including newspapers,
journals, press releases, scientific reports, organisational memos, etc.
Automatic summarization has been investigated since the 1950’s in psychology, linguistics and information science (e.g. Kieras (1985); van Dijk (1980)). Current research tends to be carried out in AI where linguistic approaches are combined.
Our approach is based on a linguistic theory of text organisation called lexical cohesion (Hoey, 1991). This approach uses the more frequent words of the text, their variants and conceptual relationships to establish links between sentences in the text. Frequency information (repetition) is used to compute the strength of association between sentences to identify the sentences which best represent the message of the original text – an indicative summary. The sentences that associate most strongly are then selected for the summary. As this approach is based on frequency of recurrence, the process can be applied to various languages. Our system has summarized English documents and also Brazilian Portuguese texts.
2. Lexical Cohesion One important reference on cohesion is Halliday and
Hasan (1976). They define lexical cohesion as ‘selecting the same lexical item twice, or selecting two that are closely related’ (p.12). This observation suggests two interlinked conclusions. First, that cohesion focuses on repetition across sentences; and second, that it is possible to study lexical cohesion by studying repetition.
In their study, two important concepts were created: tie (p.3) which is ‘a single instance of cohesion’; and texture (p.2) which is defined as the property of ‘being a text’. In other words, for Halliday and Hasan, the organization of text (which is texture) is composed of relationships amongst items in the text; some are semantic, some are grammatical and they refer to these as cohesive ties. Table 1 below show the taxonomy.
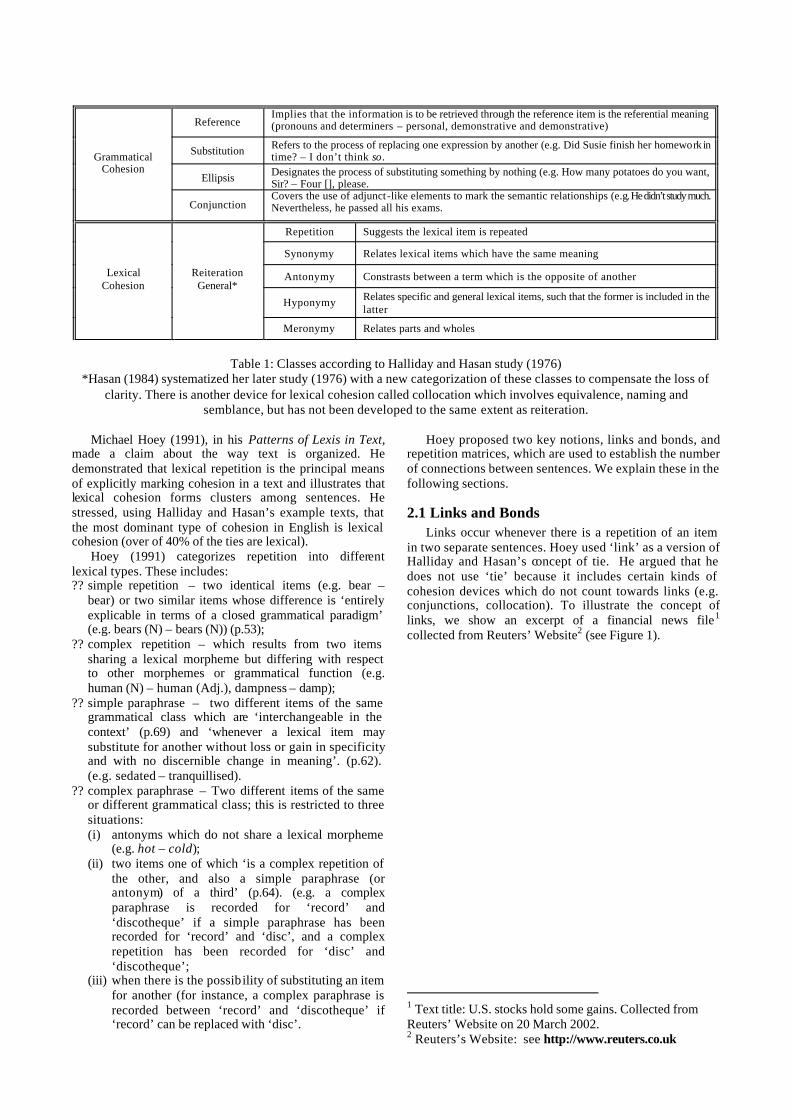
Table 1: Classes according to Halliday and Hasan study (1976) *Hasan (1984) systematized her later study (1976) with a new categorization of these classes to compensate the loss of
clarity. There is another device for lexical cohesion called collocation which involves equivalence, naming and semblance, but has not been developed to the same extent as reiteration.
Michael Hoey (1991), in his Patterns of Lexis in Text,
made a claim about the way text is organized. He demonstrated that lexical repetition is the principal means of explicitly marking cohesion in a text and illustrates that lexical cohesion forms clusters among sentences. He stressed, using Halliday and Hasan’s example texts, that the most dominant type of cohesion in English is lexical cohesion (over of 40% of the ties are lexical).
Hoey (1991) categorizes repetition into different lexical types. These includes: ?? simple repetition – two identical items (e.g. bear –
bear) or two similar items whose difference is ‘entirely explicable in terms of a closed grammatical paradigm’ (e.g. bears (N) – bears (N)) (p.53);
?? complex repetition – which results from two items sharing a lexical morpheme but differing with respect to other morphemes or grammatical function (e.g. human (N) – human (Adj.), dampness – damp);
?? simple paraphrase – two different items of the same grammatical class which are ‘interchangeable in the context’ (p.69) and ‘whenever a lexical item may substitute for another without loss or gain in specificity and with no discernible change in meaning’. (p.62). (e.g. sedated – tranquillised).
?? complex paraphrase – Two different items of the same or different grammatical class; this is restricted to three situations: (i) antonyms which do not share a lexical morpheme
(e.g. hot – cold); (ii) two items one of which ‘is a complex repetition of
the other, and also a simple paraphrase (or antonym) of a third’ (p.64). (e.g. a complex paraphrase is recorded for ‘record’ and ‘discotheque’ if a simple paraphrase has been recorded for ‘record’ and ‘disc’, and a complex repetition has been recorded for ‘disc’ and ‘discotheque’;
(iii) when there is the possibility of substituting an item for another (for instance, a complex paraphrase is recorded between ‘record’ and ‘discotheque’ if ‘record’ can be replaced with ‘disc’.
Hoey proposed two key notions, links and bonds, and repetition matrices, which are used to establish the number of connections between sentences. We explain these in the following sections.
2.1 Links and Bonds Links occur whenever there is a repetition of an item
in two separate sentences. Hoey used ‘link’ as a version of Halliday and Hasan’s concept of tie. He argued that he does not use ‘tie’ because it includes certain kinds of cohesion devices which do not count towards links (e.g. conjunctions, collocation). To illustrate the concept of links, we show an excerpt of a financial news file1 collected from Reuters’ Website2 (see Figure 1).
1 Text title: U.S. stocks hold some gains. Collected from Reuters’ Website on 20 March 2002. 2 Reuters’s Website: see http://www.reuters.co.uk
Reference Implies that the information is to be retrieved through the reference item is the referential meaning (pronouns and determiners – personal, demonstrative and demonstrative)
Substitution Refers to the process of replacing one expression by another (e.g. Did Susie finish her homework in time? – I don’t think so.
Ellipsis Designates the process of substituting something by nothing (e.g. How many potatoes do you want, Sir? – Four [], please.
Grammatical Cohesion
Conjunction Covers the use of adjunct-like elements to mark the semantic relationships (e.g. He didn’t study much. Nevertheless, he passed all his exams.
Repetition Suggests the lexical item is repeated
Synonymy Relates lexical items which have the same meaning
Antonymy Constrasts between a term which is the opposite of another
Hyponymy Relates specific and general lexical items, such that the former is included in the latter
Lexical Cohesion
Reiteration General*
Meronymy Relates parts and wholes

Figure 1: Links between 'stock' and 'markets' across sentences
Hoey also proposes ‘bonding’ to account for relations between sentences. A bond is established whenever there is an above-average degree of linkage between two sentences. It can be defined as ‘a connection between any two sentences by virtue of there being a sufficient number of links between them’ (p.91). Normally, three links constitute a bond. Hoey stresses that the number of links
which constitute a bond is relative to the type of text and to the average number of links in the text (p.91), but the least number of links is three ‘because of the greater likelihood of two repetitions occurring in a pair of sentences by chance’ (p.190). For example, the two sentences in the Figure 2 are bonded by four links.
17. In other news, Hewlett-Packard said preliminary estimates showed shareholders had approved its purchase of Compaq Computer -- a result unconfirmed by voting officials. 19. In a related vote, Compaq shareholders are expected on Wednesday to back the deal, catapulting HP into contention against International Business Machines for the title of No. 1 computer company.
Figure 2: Example of bonded sentences
2.2 Repetition Matrices Hoey suggested representation of the summary links
using a ‘repetition matrix’. The links between pairs of sentences due to repetition of a specific item can be represented in the form of a matrix, where the rows and columns represent the sentence numbers, and the elements (cells) show the number of links between the sentences. The rows represent links with subsequent sentences, the columns links with previous sentences. An extract of the link matrix for the news-wire text mentioned above is presented in Table1. It shows that, for instance, sentence 2 has 1 link with sentences 15, 17 and 20; and shares no links with sentences 3 to 14. In the other hand, sentence 18 has 5 links with sentence 19, 2 links with sentence 20, and so forth.
i j 1 2 3 4 5 6 7 8 9 10 111213 1415 161718 1920 …1 4 5 1 2 0 2 0 0 0 0 2 0 0 2 0 1 0 0 1 2 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 3 2 1 1 2 0 0 0 0 0 0 2 0 0 0 0 0 0 4 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 6 1 0 0 0 0 0 0 1 0 0 0 0 0 0 7 0 0 0 0 0 0 2 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 0 9 1 1 0 0 0 0 0 0 0 0 0
10 2 0 0 0 0 0 0 0 0 1 11 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 14 0 0 0 0 0 0 15 0 0 0 0 0 16 0 2 0 0 17 3 4 1 18 5 2 19 2 20 …
Table 1: An extract (one quarter) from a 43x43 link matrix of a text entitled ‘U.S. stocks hold some gains’ (20th March 2002). Only the upper part is represented because the matrix is symmetric
There is a variation in the number of links between
sentences. The majority of elements of this matrix demonstrate an absence of common terms between the sentences. There are, however, some sentences connected by an appreciable number of links and these are the ones we want to retain for an abridgement of the text.
When two sentences have an above-average number of links, they are said to form a bond. The cut-off point for bond information, the link threshold, depends on the length and type of text but should never be less than 3 to avoid accidental repetition. A link matrix can therefore
Sentence 23: J&J's stock added 83 cents to $65.49.
Sentence 26: Flagging stock markets kept merger activity and new stock offerings on the wane, the firm said.
Sentence 42: Lucent, the most active stock on the New York Stock Exchange, skidded 47 cents to $4.31, after falling to a low at $4.30.
Sentence15: "For the stock market t his move was so deeply discounted that I don't think it will have a major impact".

give rise to a bond matrix, a table of 1s and 0s, denoting either an existence or an absence of bonds between the sentences. Table 2 is the bond matrix correspondent to the link matrix of Table 1 for a link threshold of 3.
i j 1 2 3 4 5 6 7 8 9 10 111213 1415 161718 1920 …1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 0 11 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 14 0 0 0 0 0 0 15 0 0 0 0 0 16 0 0 0 0 17 1 1 0 18 1 0 19 0 20 …
Table 2: The bond matrix corresponding to the link matrix of Figure3 with link threshold = 3
2.3 Central, Marginal, Topic-opening and Topic-closing Sentences
Central sentences are those which have a high number of bonds, according to Hoey,‘the most bonded sentences’ in the text (p.265). Marginal sentences are ‘sentences that form no bonds or, for some texts, few bonds’ (p.267). A sentence is topic-opening if it bonds with more subsequent than preceding sentences, and it is topic-closing if it bonds more times with preceding sentences. The combination of topic-opening, topic-closing and ‘most bonded’ sentences can be used to automatically produce an indicative summary. The example provided above has a majority of marginal sentences and a few topic opening and topic closing sentences. These can be used to produce an indicative summary of this text.
3. SummariserPort – a Summariser System Based on the principles of lexical cohesion outlined above, we have developed a system for automatic text summarisation that we shall describe in this section.
3.1 Technical Description SummariserPort has been developed from a prototype
text -processing program called Tele-Pattan (Benbrahim, 1996). It was written in Java and represents a computer implementation of two of Hoey’s four categories of lexical repetition, Simple Repetition and Complex Repetition. The architecture of SummariserPort is shown in Figure 3.
Figure 3: The Architecture of SummariserPort
The description of this architechture is provided below: Parser: this module starts by reading the text file and segmenting it into sentences. We used a Java class designed specifically to parse natural language into words and sentences. It is called BreakIterator. Some features are (1) it has a built-in knowledge of punctuation rules; (2) it does not require any special mark-up. Morphological Rules: In this module the second category of Hoey’s (1991) approach is performed. The instances of complex repetition are looked up by means of a list of derivational suffixes encoded into the program. For the English language, it contains 75 morphology conditions that lead to approximately 2500 possible relations among words. Such repetition (complex) is counted as links. Patterns Extractor: performs analysis of simple repetition, counting lexical links between sentences. It uses an optional stop list containing closed class words and other non-lexical items, such as pronouns, prepositions, determiners, articles, conjunctions, some adverbs, etc., which are excluded from forming links. Output: produces the results. One result of this module is the summary itself. Other outputs include: link matrix; bond matrix; a histogram with number of occurrences of each link; total number of sentences, words and links; list of sentences grouped into categories of topic-opening, topic-closing and central and the word frequency list.
3.2 Summary Generation Our program was set to produce summaries consisting
of sentences from categories mentioned in the section 2.3, namely topic-opening, topic-closing and mo st-bonded. Within each category the sentences are ranked according to the number of bonds each sentence has with others sentences in the text. The indicative summary generated is approximately 30% of the size of the original text, which is produced by taking 10% of the number of sentences for each category.
4. Evaluation The program itself produces summaries in parts of a
second once it is initialised and hence is suitable for high-volume throughput such as that from a news-feed. The process of evaluating a summary remains the most
T e x t F i l e
T e x t A n a l y s i s
P a r s e r
P a t t e r n sE x t r a c t o r
M o r p h o l o g i c a lR u l e s
O u t p u t
S t a t i s t i c a lI n f o r m a t i o n
( B o n d s , L i n k s )
T e x tS u m m a r y

controversial part of such research. Authors witing about evaluation stress and state such problems (e.g. Karen Sparck Jones (1994), Edmunson (1969); Paice (1990) and Hand (1997)).
For us, the following aspects are relevant to the evaluation process for a summary: (a) the inclusion of the essential information; (b) the exclusion of non-essential information and (c) the readability of the summaries.
We considered that the inclusion of the relevant information’s criterion forms the basis of our evaluation procedure.
Our corpus contains 623 news-wire financial texts collected from Reuter’s Website on January 2002. For evaluation purposes, we chose randomly 5 different texts files. Each of these files were summarised by SummariserPort. In other words, a summary for each text was produced and its quality was evaluated against the summaries of the other texts.
A trial questionnaire was created for evaluating the quality of summary produced from these files that were evaluated by two test groups, PhD students from the University of Surrey and Financial Traders from JRC, Berlin.
Both the students and the traders were asked to rank the summary of each text. The results are tabulated in the tables below (Table 3 represents student results, Table 4 represents Trader results):
Rank the summaries from the worst to the best. (Obs: a rating scale from 1 = best to 5
= worst was used) S1 S2 S3 S4 S5 Student 1 1 3 2 4 5 Student 2 1 3 2 4 5 Student 3 3 1 2 4 5 Student 4 4 2 3 5 1 Student 5 1 3 2 4 5 Average 2 2.4 2.2 4.2 4.2
Table 3: Student Evaluation of summaries
Rank the summaries from the worst to the best (Obs: a rating scale from
1 = best to 5 = worst was used) S1 S2 S3 S4 S5 Trader 1 1 3 5 4 2 Trader 2 3 4 5 1 2 Trader 3 5 2 1 3 4 Trader 4 1 3 5 4 2 Average 2.5 3 4 3 2.5
Table 5:Trader evaluation of summaries The tables above show the subjectivity inherent in
such an evaluation. Individuals judge summaries differently depending on their expectations. However, in the majority of cases, Summary S1 was the most popular. A question arises here. Why S1 was considered the best among the others? We believe that the answer is because human evaluation is subjective and normally depends on the taste and motivation of the evaluator.
During the evaluation process, the Traders identified sentences they wanted to appear in the summary, but which were not included. This result is shown in Table 6.
S1 S2 S3 S4 S5
Trader 1 -7 Trader 2 -12, -17 -2 Trader 3 -2, -7, -10 Trader 4 -7 -17 -1, -2
Table 6: Missing Sentences (-)
We are currently investigating the reasons these sentences, while important to the traders, were missing from the summary.
The evaluation work is in progress and will be reported elsewhere3 (Oliveira and Ahmad, in prep.).
5. Conclusions According to the outcomes provided by the
experiments results, we can now draw some conclusions: ?? SummariserPort proved to be robust, fast, reliable and
is able to produce summaries of very high quality; ?? Our system empirically supports Hoey’s theory about
the organisation of the text, i.e. lexical cohesion; ?? The evaluation process does not stop here. We are
evaluating our system continuously. We are also trying another kinds of evaluations which are reported on the literature in order to obtain better results (e.g . task-based evaluation, target-based evaluation and automatic evaluation).
Acknowledgements The PhD student evaluators and JRC Berlin, in
conjunction with the authors, acknowledge the support of the EU-cofunded project Generic Information-based Decision Assistant (GIDA IST-2000-31123).
References Benbrahim, M., 1996. Automatic text summarisation
through lexical cohesion analysis. PhD thesis. Artificial Intelligence Group. Department of Computing. University of Surrey. Guilford.
Edmunson, H.P., 1969. New methods in automatic abstracting. Journal of ACM. 16(2):264-285.
Halliday, M.A.K. and Hasan, R., 1976. Cohesion in English . London and New York: Longman.
Hand, T.F., 1997. A proposal for task-based evaluation of text summarization systems. In ACL/EACL-97 summarization workshop. p.31-36.
Hasan, R., 1984. Coherence and cohesive harmony. In J. Flood (ed.), Understanding reading comprehension: Cognition, language and the structure of prose. Newark: International Reading Association. p.181-219.
Hoey, M., 1991. Patterns of Lexis in Text. Oxford: Oxford University Press.
Jones, K.S., 1994. Towards better NLP system evaluation. In Proceedings of the human language technology workshop. p.102-107. San Francisco: ARPA.
Kieras, D.E., 1985. Thematic processes in the comprehension of technical prose. In B.K. Britton and J.B.Black (eds.) Understanding expository text: A
3 The document will appear on our website: (http://www.computing.ac.uk/ai/gida)

theoretical and practical handbook for analysing explanatory text. Hillsdale, NJ: Lawrence Erlbaum, p.89-107.
Lynch, P. 2000 One up on Wall Street. Simon & Schuster, New York
Mani, I., 2000. Automatic Summarization. Amsterdam and Philadelphia: John Benjamins Publishing Company.
Oliveira, P.C.F. and Ahmad, K. (in prep.). Evaluating summaries: methods and techniques.
Paice, C.D., 1990. Constructing literature abstracts by computer: techniques and prospects. Information Processing and Management. 26(1):171-186.
van Dijk, T.A., 1980. Macrostructures: An interdisciplinary study of global structures in discourse, interaction and cognition. Hillsdale, NJ: Lawrence Erlbaum.

Processing the language of predicting and forecasting in an Italian corpus of economic reports
Maria Teresa Musacchio
SSLMIT, University of Trieste, Trieste, Italy [email protected]
Abstract Predicting and forecasting play a central role in economic theory and practice. Economic agents refer to them to base their policies and decisions on. This paper presents an attempt to extract predictions from an Italian corpus of economic reports using morphological rather than lexical information in KWIC concordance. The method – as applied to Italian – leads to identify grammatical and lexical information that can be used to integrate data in terminology collections. Lexical and grammatical data thus acquired can be fed back into the system to refine search for predictions and forecasts in a further stage of research.
1. Introduction Economists study the economy in much the same way
as other scientists approach their disciplines. They observe phenomena, formulate problems, develop theories or models to capture the essence of the phenomena, and they test their predictions against economic data in an attempt to verify or refute them. Although economists use theory and observation much like other scientists, their task becomes particularly challenging when it comes to testing because experiments are often difficult in economics. In many cases, economists cannot make experiments such as inducing inflation to generate useful data and put forward proposals or recommendations to control the economy. To compensate for the limitations in laboratory experiments, they study carefully the natural experiments offered by history (Mankiw, 1998: 18-19). Thus, prediction based on theories or models and forecasting based on data analysis acquire special relevance in economics compared to other areas of science and technology. Economic agents devise their policies and make their decisions partly referring to economic predictions and forecasts and this accounts for the attention given to reports containing this type of information and regularly published by authoritative economic and financial institutions such as the IMF and the OECD at international level and central banks, research institutes and institutes of statistics at national level.
The scientific method used by economists is also reflected in their daily practice and in their language as claims to knowledge can be made only by using language (Backhouse et al., 1993: 1). At the level of textual structure, this implies that in many economic texts a sequence of three parts – analysis, prediction or forecast, and proposal – can be identified (Sobrero, 1993: 255). Predicting and forecasting are thus central to economic discourse and in particular to argumentation. Here then lies the problem: if knowledge can only be expressed through language, how are predictions and forecasts formulated and can they be easily identified and tracked through linguistic analysis?
In economic discourse predicting and forecasting are forms of evaluation, that is assessments of the possible consequences of current events, descriptions of future developments. It is therefore to be expected that they will be expressed using verbs in tenses of future action such as future tenses and conditionals indicating the probability of
an event occurring in the future. Given the centrality of predictions and forecasts in economics, one can easily imagine that economists take great care to formulate them. They use devices to limit the validity of their claims, that is they use words to make meanings fuzzier or less fuzzy. In linguistics this process is called hedging (Lakoff, 1973: 195). Hedges qualify nouns, verbs, adjectives or whole predications and – as Brown and Levinson (1987) pointed out – also include epistemic modal expressions. In her research on speech acts in English economic discourse Merlini (1983: 8-16) identified four different types of predictions1 she classified as shown in Table 1 below. Two criteria are used to identify and classify predictions: epistemic and inferential gradients. The former indicates the degree of speaker/writer’s commitment to the truth value of the whole proposition (shields), the latter the truth conditions of propositions (approximators). Shields can be modals (epistemic will, would, could, should, may, might), modal expressions (to be [or seem/appear] + likely, possible, bound, due, destined) and modifiers such as adjectives or adverbs – either downtoners (likely, possible, probable, possibly, probably, presumably, perhaps) – or intensifiers like certainly and well. Further, the value of claims can be altered using modifiers such as obviously, surely, clearly, conceivably and equivalent paraphrases (this shows that, this indicates that, suggests that, one may reasonably expect, etc). Approximators are expressions like almost, nearly, at least, more or less, about, virtually, etc. (Bloor & Bloor, 1993: 153-154). Predictions often take an implicit form, that is, they are seldom introduced by verbs like to predict, to forecast, to expect and so on (Merlini, 1983: 23).
1 Merlini clearly states (1983: 8) that her analysis concerns what in English is generally referred to as ‘prediction’, that is a statement of the likely course of future economic events based on economic theory. It is my contention, however, that the third and fourth type of prediction indicated by Merlini are often based on data as well, so that the distinction between prediction and forecast is not clear-cut. Since this paper focuses on ‘applied’ and ‘instrumental’ predictions due to their greater interest to market operators, in what follows prediction will be used as an umbrella term to refer to both predictions and forecasts.

Type of prediction Examples Interpretive or hypothetical prediction = it creates a link between two phenomena: if phenomenon p is observed, then phenomenon q will occur
If consumers want more of any good, the price will rise, sending a signal to producers that more supply is needed. (Samuelson & Nordhaus, 2001 : 26)
Illustrative or speculative prediction = it creates a simplified model of reality for the sake of clarity. From this relationships are engendered and consequences are drawn.
Suppose you own a football club. Before the season begins you have to set the price of football tickets for the season. Your sole aim is to maximize your revenue from ticket sales so you can afford to buy some better players next season. (…) If the quantity demanded is insensitive to the price it will require a very low price to fill thge ground and total revenue will collapse. If, however, small reductions in ticket sales lead to large increases in the quantity sold, it makes more sense to charge a price that will fill the ground. (Begg et al., 1997 : 56)
Applied or realistic prediction = The past/current situation is analysed and economic models and tools are used to predict or forecast future events.
If the experiences of the 1994 bond-market decline are a guide to the future, even a substantial Wall Street correction (…) will have a relatively small effect on the pace of Main Street activity. (Tyson, 1997 : 58)
Instrumental prediction = it is used to prove the validity of : a) a warning or b) a proposal.
a) (…) the economy would be capable of a much better performance if only the Federal reserve and the bond market would relax the interest-rate brakes. (Tyson 1997: 58)
b) I hope that by the time this book comes out the European Central Bank will have moved aggressively to cut rates and stimulate growth; if it does not, the liquidity trap could be about to claim another victim. (Krugman, 1999: 162)
Table 1: A classification of predictions with examples
2. Predictions and forecasts in Italian This paper investigates the possibility of extracting
predictions – with special reference to trends in the business cycle affecting the markets – from an Italian corpus of economic reports. As the ups and downs in an economy can be expressed through language in many different ways, in this paper research on hedging and especially Merlini’s observations on predictions are applied to Italian. In this first stage of research, epistemic modality is used as a working hypothesis or ‘knowledge probe’ (Ahmad & Fulford, 1992) to identify predictions in Italian economic texts. Despite the noise one may find, an attempt is made to see if – in an untagged corpus – concordancing of prediction probes is a speedier way to identify the ups and downs in the economies than a search for all the terms expressing change or no change.
Data analysed in this paper come from a corpus of Italian economic texts jointly developed by the University of Surrey and the University of Trieste. It is approximately 190,000 tokens and includes the Annual Report, an issue of the Economic Bulletin of the Bank of Italy, a fragment on the Italian business cycle from The Annual Report of the Italian Institute of Statistics (ISTAT) and a number of speeches delivered by the Governor of the Bank of Italy. Corpus composition with data of publication of texts is illustrated in Table 2.
Texts Tokens Economic Bulletin of the Bank of Italy No. 32 – February 1999 36,188
Notes to the Economic Bulletin of the Bank of Italy (No. 32 – Feb. 1999) 5,500
Annual Report 1998 of ISTAT – fragment (Ch. 1) 33,354
Annual Report 1998 of the Bank of Italy 77,593
Considerazioni finali ( 31st May 1999) 11,172Dpef 1999-2001 (22nd April 1998) 8,794Speeches (December 1998-January 1999) 15,079
Total 187,680
Table 2: Composition of the Surrey-Trieste Corpus of Italian economic reports

Compared to English, Italian has a lower number of modals and relies on other devices to express varying degrees of confidence about future states and events. For instance, epistemic will indicating confident prediction has an Italian equivalent in the simple future indicative. A lower degree of confidence expressed in English through modals such as would, could, should, may and might is indicated in Italian by the simple conditional. The epistemic modals in Italian are potere indicating possibility and dovere expressing higher probability. Unlike their English counterparts potere and dovere can be conjugated in all tenses and modes (Serianni 1991: 396). As is known, Italian verbs are marked for simple tenses and for modes by suffixes attached to the verb root and inflected for person. The number of irregular verbs in Italian is relatively high. These features of Italian verbs would make retrieval of predictions based on simple future and conditional tenses highly complex. However, a number of restrictions can be applied that make retrieval much easier. First, in special languages a large use of impersonal forms and passives is made so that search for tenses inflected in the third person singular and plural – active or passive – can suffice. Second, problems of information retrieval due to morphological irregularities in tense formation can be avoided when it comes to simple future and conditional by querying the corpus for suffixes without their thematic vowels (‘e’, ‘i’ or nil) (Serianni, 1991: 433). For the simple future the search string will therefore be *rà/*ranno (3rd pers sing/pl): compare aumentare (to increase) ? aumenterà/ aumenteranno and diminuire (to decrease) ? diminuirà/diminuiranno – both regular verbs – and potere ? potrà/potranno or andare (to go) ? andrà/andranno. Similarly, the search string for the simple conditional will be *rebbe/*rebbero (cf. aumenterebbe/aumenterebbero but dovrebbe/dovrebbero). Besides limiting the number of searches, an advantage of the method used at this stage of research lies in the possibility to retrieve all predictions regardless of the verb or noun groups indicating them. For example, an upward trend may take the form ‘la domanda crescerà nel secondo trimestre’ (N + V + A ? ‘demand will grow in the second quarter’) – where information on the trend is carried by the verb – or a form where information is carried by the subject (the noun crescita or ‘growth/increase’ in the N+prep+N collocation crescita della domanda): ‘si verificherà una crescita della domanda nel secondo trimestre’ (V + N + prep + N + A ? lit. ‘An increase in demand will take place in the second quarter’). Information extracted in this way on the company a word keeps is both grammatical (colligation) and lexical (collocation) (Sinclair 1998). KWIC concordances are performed using SystemQuirk (Ahmad, 1998).
Occurrences of the simple future (3rd person sing/pl = 223) and the simple conditional (3rd person sing/pl = 307) in our corpus were manually checked to identify predictions vs other propositions. 98 predictions in the future or 43.95% of the total and 213 predictions in the conditional or 69.38% of the total were found. Predictions were then analysed to see if any structural patterns emerged. It soon became clear that predicted changes exhibit patterns where core information about ups and downs or no-change is carried either by the verb or by the noun – in this case usually in subject position. Table 3 shows examples of sentences in which prediction information is carried by verbal groups. Examples 1-5
concern increases, examples 6-7 stability, while examples 8-10 highlight decreases. Examples in the table also show typical approximators used in Italian in the context of predictions. Table 4 presents similar predictions, but their core information is carried by the noun group, while main verbs are general-purpose verbs, that is verbs that can collocate with a wide range of nouns and thus take on different meanings (provocare, comportare, segnare, indicare, contribuire). In Table 4 examples 1 to 7 designate upward trends, examples 8 and 9 indicate no change and examples 10 to 13 show downward trends. Further examples of approximators are found in these sentences and can be added to a list to be used in a second stage of work, when this simple method to extract predictions is refined by combining search of grammatical and lexical items.
Taken together, the two tables show the wide variety of verbs and phrases used to convey the idea of increase, decrease or no change of some economic indicators, though the list is by no means complete and indeed many more examples were found in our corpus. This may suggest that – in Italian and possibly other Romance languages – retrieval of predictions relying on morphology or syntax is a more productive method than the simple search for modals and modal expressions. Further indication of the relevance of retrieval based on verb tense inflection is provided in Table 5, which lists occurrences of all explicit predictions (si prevede [che]) and some shields – presumibilmente, probabilmente – to be found in our corpus.

LH co(n)text RH co(ntext) Text 1 soprattutto le aree
meridionali del Paeseaccrescerà la produttività del sistema speeches\dpef.txt
2 Consumatori mutano con il variare dell’età.
tenderà a crescere la domanda di alcuni beni speeches\interv~1.txt
3 questo processo; l’introduzione dell’euro
potrà accelerarlo Contribuendo alla diversificazione
reports\releco~1.txt
4 Lo sviluppo del commercio mondiale
salirebbe marginalmente, dal 3,3 al 4,4 per cento; reports\bollett~1.txt
5 dei Bot a 12 mesi. L’avanzo primario
dovrebbe innalzarsi dal 4,6 per cento del 1999 al 5,2
speeches\dpef.txt
6 nel medio termine l’avanzo primario
dovrà essere elevato e stabile.
L’andamento speeches\consfi~1.txt
7 l’indice di questo mese di gennaio
rimarrebbe sul livello di dodici mesi prima. Le aspettative
speeches\interv~1.txt
8 nei paesi industriali; in Europa, lo sviluppo
scenderà al 2 per cento. L’economia mondiale
speeches\consfi~1.txt
9 dal 1998 al 2002, l’incidenza delle spese sul
PILdovrebbe diminuire
di oltre tre punti percentuali (dal 4 reports\bollett~1.txt
10 Secondo le aspettative degli operatori,
l’inflazionesi ridurrebbe
a valori di poco superiori all’1 per cento, in reports\bollett~1.txt
Table 3: A concordance of economic predictions. Information is carried by the verb in column three. Hedging
lexicalised through inflection (conditionals), modals (potrà, dovrebbe) or modal expressions (tenderà a) is highlighted in bold, approximators are marked in italics.
LH co(n)text RH co(n)text Text 1 margine di interesse. Un
contributo positivopotrà derivare dalla crescita dei ricavi da
servizi reports\releco~1.txt
2 che il complesso dei provvedimenti esaminati
provocherà un aumento del reddito disponibile
reports\istat.txt
3 ad accentuarsi in Europa nei prossimi anni;
comporterà la tendenza alla concentrazione
speeches\interv~1.txt
4 delle prospettive della nostra economia
sarà possibile in autunno, con la definizione
speeches\dpef.txt
5 quelli dello scorso anno. La domanda interna
dovrebbe trovare sostegno nella dinamica dei consumi
reports\bollett~1.txt
6 (0,3 punti percentuali del PIL); l’avanzo primario
segnerebbe un aumento modesto. L’incidenza del
reports\bollett~1.txt
7 già all’opera lo scorso anno. La capacità di spesa
trarrebbe alimento dalla crescita del reddito disponibile
reports\bollett~1.txt
8 del 2000 (/fig. 28). La crescita dei prezzi in Italia
si manterrebbe pressoché costante attorno a questo livello
reports\bollett~1.txt
9 La crescita dei prezzi al consumo nel nostro paese
risulterebbe lievemente inferiore ai valori medi dell’area
reports\bollett~1.txt
10 del 1995 al 6,3 del 1998. La riduzione
dovrebbe proseguire con il venire a scadenza dei titoli
reports\releco~1.txt
11 dal 1965. L’assenza di pressioni inflazionistiche,
chepotrebbero determinare
un restringimento delle condizioni reports\istat.txt
12 per l’anno in corso. Al suo ridimensionamento
dovrebbero contribuire, oltre ai più favorevoli risultati previsti
speeches\dpef.txt
13 invariati nel terzo (tav. 4); i dati di fonte doganale
Indicherebbero una flessione nei mesi successivi. Il ristagno
reports\bollett~1.txt

Table 4: A concordance of economic predictions. Information is carried by the underlined noun (usu. the subject) in a N [+ prep. + N] + V + A construction. in column two or four. Hedging lexicalised through inflection (conditionals),
modals (potrà, dovrebbe) or modal expressions (sarà possibile) is highlighted in bold, approximators are marked in italics.
LH co(n)text RH co(n)text Text 1 dinamica dei salari
nominali, i qualisi prevede non aumenteranno più del
3% nel 1999 e nel 2000 reports\istat.txt
2 brasiliana, benché non ancora quantificabili,
si prevede Saranno evidenti soprattutto nei paesi dell’America latina
reports\istat.txt
3 L’avvio dell’euro determinerà
probabilmente un’integrazione del reports\releco~1.txt
4 di crescita. Le negoziazioni, che
partiranno presumibilmente
entro l’estate, riguarderanno reports\releco~1.txt
Table 5: Examples of explicit predictions and predictions containing shields in the Surrey-Trieste corpus.

3. Discussion and future work This paper presents the first stage of research in the
extraction of predictions from an untagged Italian corpus of economic reports. Drawing on linguistic research on modality and economic predictions in English, a simple method based on Italian morphology was used to identify predictions. Despite the noise – over 50% of occurrences are not predictions – this method can help identify a) verbs lexicalising predicted change or no change in economies and/or economic indicators and b) phrases (collocations) and patterns (colligations) pointing to predictions. The co-texts of sentences als o provide data on approximators and shields. Information acquired via morphology can then be used to refine the method for the extraction of predictions. The challenge is to compile lists of verbs and phrases which – combined with grammatical patterns – can integrate information provided in terminology collections as predictions and their language are central to economic discourse. To economists this can also prove a quick way to scan long Italian economic texts in search of predictions. In the second stage of research ways to reduce noise and thus improve the efficiency of extraction will be explored. In particular, attempts will be made to combine grammatical and lexical information to refine search.
In my presentation Italian examples will also be compared and contrasted with predictions drawn from an English corpus of economic reports developed at the University of Trieste. Reference will further be made to what little data on economic predictions can be gathered from the large written Italian corpora CORIS (general language) and CODIS (special languages) of the University of Bologna.
4. References Ahmad, K. and H. Fulford, 1992. “Knowledge Processing
4. Semantic relations and their use in elaborating terminology”, Computing Sciences Report CS-92-07. Guildford: University of Surrey.
Ahmad, K. 1998. Specialist texts and their Quirks. In TAMA ’98. Terminology in Advanced Microcomputer Applications. Proceedings of the 4th TermNet Symposium. Tools for Multilingual Communication. Vienna: TermNet, 141-157.
Backhouse, R., T. Dudley-Evans and W. Henderson, 1993. Exploring the language and rhetoric of economics. In W. Henderson, T. Dudley-Evans, and R. Backhouse (eds.), Economics and Language. London: Routledge, 1-20.
Begg, D., Fischer, S., Dornbusch, R., 1997. Economics. 5th ed.. Maidenhead: Mc-Graw-Hill.
Bloor, M., T. Bloor, (1993). How economists modify propositions. In W. Henderson, T. Dudley-Evans, and R. Backhouse (eds.), Economics and Language. London: Routledge, 153-169.
Brown, P., Levinson S.C., 1987. Politeness: Some Universals in Language Usage. Cambridge: Cambridge University Press.
Krugman, P., 2000. The Return of Depression Economics. London: Penguin.
Lakoff, G. 1973. Hedges: A study in meaning criteria and the logic of fuzzy concepts. Journal of Philosophical Logic, 2(4): 458-503.
Mankiw, G., 1998. Principles of Economics. Fort Worth (TX): The Dryden Press.
Merlini, L., 1983, Gli atti del discorso economico: la previsione. Status illocutorio e modelli linguistici nel testo inglese. Parma: Zara.
Samuelson, P.A., Nordhaus, W.D., 2001. Economics. New York: McGraw-Hill Irwin.
Serianni, L., 1991. Grammatica italiana. Italiano comune e lingua letteraria, 2a ed.. Torino: UTET.
Sinclair, J.M., 1998. The lexical item. In E. Weigand (ed.), Contrastive Lexical Semantics, Amsterdam/ Philadelphia: John Benjamins, 1-24.
Sobrero, A.A., 1993. Lingue speciali. In: A.A. Sobrerro A.A. (a cura di), Introduzione all’italiano contemporaneo. La variazione e gli usi. Roma-Bari: Laterza, vol. II:237-277.
Tyson, L., 1997. How bright is bright? In: The World in 1998. London: The Economist Publications, 58-59.

Economic News and Stock Market Correlation: A Study of the UK Market
Lee Gillam, Khurshid Ahmad, Saif Ahmad, Matthew Casey, David Cheng, Tugba
Taskaya, Paulo C F de Oliveira and Pensiri Manomaisupat
Department of Computing, University of Surrey, Guildford, Surrey, GU2 7XH, UK {l.gillam, k.ahmad, s.ahmad, m.casey, d.cheng, t.taskaya, p.oliveira, p.manomaisupat}@surrey.ac.uk
Abstract
In this paper, we examine the potential correlation between news and the stock market. Our goal is to match the movement of the market to events that cause the movements. The method employed attempts to produce a time-series of so-called ‘market sentiment’ from news stories that can be compared directly with time-series of stock markets and, in future, individual stocks. The results gained from a prototype based on this method indicate that news stories relate to movements in the financial market and so such a time-series is possible. We conclude that with systematic improvement of present techniques these results could be used in combination with existing financial prediction techniques, possibly improving the accuracy of such predictions.
Background News about financial markets has been treated in a variety of ways. Almeida, Goodhart and Payne [1] have studied the effects on the Dollar/Deutschmark exchange rate of macroeconomic announcements looking specifically at the 15 minutes following the announcement. Andersen and Bollerslev [2] and an earlier paper by Goodhart [7] have also studied these macroeconomic effects. Trading strategies based on taking strategic positions based on rumour and result have been treated by Brunnermeier [5]. Chang and Taylor [6] deal with news as ‘information arrivals’ which “are measured by the numbers of news items that appeared in the Reuters News Service”. Their approach is based on counting the number of news items in specific categories to find the most significant impacts on volatility. Chang and Taylor also provide a large literature review on the subject of information arrivals. Paradoxically, Roley and Selon [8] discuss the effects of market reactions when expected monetary policy actions do not occur – the news is that there is no news. According to the efficient market hypothesis, the effect of news is rapidly discounted in the market. Indeed, the movement of the market according to news is ascribed, according to Almeida, Goodhart and Payne [1] as “the unexpected part of an announcement”. If, for example, a company’s profits are in line with expectations, the share price will already to some extent contain the expectation. Higher or lower profit announcements will move the price up or down as this is the reaction to the unexpected part. Financial traders working on an intraday basis react to news events in certain ways and make an investment decision that eventually either appears consensual or contrarian. The value of the market at some future point indicates whether their approach was a success or not. Part of the challenge therefore is to determine what the ‘expected’ part of the news is and determine the
extent of the possibly unexpected part. This requires some understanding of what is termed ‘market sentiment’ – whether the market feels ‘good’ or ‘bad’ about certain things. The goal therefore is to quantify market sentiment that is expressed in financial news. Traders talk of ‘bull’ and ‘bear’ markets; markets that are rising and will continue to rise or falling and will continue to fall. Financial reports will to some extent reflect the feeling within and about a particular market, aspects of that market such as industry sectors or specific companies, or in relation to macroeconomic factors at a given time. We believe that if this feeling can be expressed numerically, the news itself can be treated as a time-series and compared with the time series of actual market values. The conversion of textual data to numeric data enables news to be manipulated using existing time-series mechanisms; one could consider the use of Bollinger Bands [4] representing positive and negative sentiment. Financial news may explain current economic performance or predict the state of the future economy. As such, there is a ‘past’ or ‘future’ element within such stories. The stories may contain a report of how the market performed, in which case the market affects the news or it may contain elements predicting the expected performance of a specific company in which case the market is affected by the news. Either way, there will be some correlation between news and the market. If we can determine such a correlation, further interesting research questions regarding the use of language will certainly be generated. In this paper, we investigate the possibility of extracting ‘market sentiment’ from financial news announcements and whether market sentiment can be seen to have an effect on market movement. We evaluate this approach in terms of exceptions and the need for inferencing over

news events to determine a fuller picture which provides the basis for future work. This work is the focus of an EU co-funded project called Ge neric Information Decision Assistant (GIDA – IST-2000-31123). Market Movements At time of writing, the financial markets have dropped about one-fifth (Dow Jones) to one-third (FTSE) of their value since peaks around December 1999. Certain drops can be seen around the time of catastrophic events such as those of September 11, which caused a lowest point around September 21 (see Figure 1) followed by a subsequent recovery to levels that were indicative of the slowly falling market.
Sep 11, 2001
Germany DAX(PERF) Nasdaq Composite Index
Japan NIKKEI AVERAGE INDEX(225) Dow Jones Industrial Average
Sep 11, 2001
Sep 11, 2001
Sep 11, 2001
Figure 1: Movement of major market indices from Feb 2001 to Jan 2002 showing major drop following
September 11
Movements of share prices for individual companies can be even more meteoric in nature. In September 1989, a Microsoft share was just under $1, at the peak of December 1999 it was $119.94 and trades currently around $51. A previous favourite of the UK market, Marconi, traded at £12.76 at its peak in August 2000 and yet in July 2002 it has traded as low as 3.1 pence per share, having lost over 99% of its value. Those with impressive hindsight would suggest that it was their strategy of focussing on telecommunications and the negative sentiment regarding telecommunications at the time. Potentially, this sentiment would be evident in news regarding slowing markets and the like. An historical study would be required to confirm this. Different ‘types’ of traders apply different strategies in selecting appropriate instruments to buy and sell. Intraday traders look for technical patterns on charts such as Head and Shoulders, Double Tops and a variety of Japanese Candlestick patterns. These traders are generally referred to as technicalists. On the other hand, fundamentalists look for the value of the company they are investing in by considering items such as the price / earnings ratio or the growth of the company.
Some traders may use various combinations of these two distinctions to evoke a trading strategy. For technicalists, the volume of arriving news makes its appropriate treatment difficult. For fundamentalists, missing an important news item is the major worry. By focussing on market sentiment, we hope to provide some indication of feeling regarding, initially, a particular market. Measuring Market Sentiment As reported in, we have previously modelled market sentiment using news announcements (financial / industrial / political) in the UK along with the daily closing value of the FTSE 100. For a specific experiment, the data set was taken from November 2001 and consists of a corpus of 30 news items per day published on the Reuters News site - www.reuters.co.uk between 9:00 AM and 5:30 PM and the corresponding closing value of the FTSE 100 for the day. The corpus contains time stamped business news from Britain, the United States and Europe. We have identified over 70 terms each for conveying ‘good’ and ‘bad’ news (see Ahmad et al [1] for further details). The news stories were analysed using System Quirk (http://www.computing.surrey.ac.uk/SystemQ) to find the frequency of occurrences of these terms and Table 1 shows a snapshot of the results for each week under consideration.
Week Good Word Frequency
Bad Word Frequency
1 58 40
2 71 75
3 77 66
4 73 59
5 72 28
Total 351 268
Table 1: Frequency of 'Good' and 'Bad' words in November 2001 news stories
For display purposes, the frequencies for ‘good’ and ‘bad’ words along with those of the FTSE 100 are then scaled according to Equation 1 below:
Equation 1: Scaling values within data sets
The scaled values can then be plotted alongside each other using, for example, Microsoft Excel as in Figure 2. This particular plot shows some interesting initial features, however the major result is that we have a method by which we can begin to experiment with texts as time-series. The method may initially appear naïve, however we believe there is value in continuing in this vein. Certainly this approach shows no initial reasons
maxffv i
i ?

why continuing its development would not be worthwhile.
Figure 2: 'Good' and 'bad' words plotted alongside FTSE 100 values (all scaled)
Figure 3 below shows the method used to combine these data. Applying this method to the data enables potential correlations to be made between the index and the good or bad news. Furthermore, well-developed time-series analysis (TSA) algorithms can be applied over these data and may potentially be used to make predictions regarding the market itself, although this is considered future work.
Figure 3: Method for processing news and financial time series
Prototype of a News Time Series System Having developed what appears on the surface to be a simplistic mechanism for converting text to a time-series of market sentiment, the next phase is the development of a prototype environment in which both the treatment of the news and the potential for combination with TSA algorithms are possible. From specific news feeds, Reuters news is published in NewsML, an application of XML. For web-based
news, HTML is common which can be converted to XHTML, another application of XML. Our prototype Sentiment and Time Series: Financial analysis system (SATISFI) therefore handles XML-based news and combines this handling with terminology extraction techniques to provide absolute frequencies for the sentiment.
SATISFI was validated using the same data set as for the previous experiment. A correlation routine has been implemented to provide an initial determination of whether the results of this analysis have some significance that is worth investigating further. Also, the capability to ‘shift’ a particular pattern (for example to determine whether the market is affected on a particular day by the news from the previous day) has been implemented. Figures 4 and 5 show screenshots of SATISFI plotting the ‘good’ and ‘bad’ sentiments alongside the FTSE 100. The system can display all three results on a single chart and can provide correlations between any two.
Figure 4: SATISFI Screenshot: ‘Good’ (Green – starts as upper line) Vs FTSE 100 (Blue – starts as lower line)
for November 2001.
Figure 5: SATISFI Screenshot: ‘Bad’ (Red – starts as upper line) Vs FTSE 100 (Blue – starts as lower line)
for November 2001.
Initial experiments with SATISFI appear to show that to some extent the FTSE 100 reacts to financial news.
News
Text Analysis
Generate Frequency
Scaling of Values
Display Time Series Data
Correlation
FTSE 100
Corpus of ‘good’ and ‘bad’ terms

Table 2 shows correlation results for shifted and un-shifted versions of FTSE 100 with upward and downward movement indicators for November 2001. It appears that bad sentiment on a particular day anti-correlates with the FTSE, that is, 2 days after bad sentiment, the FTSE rises. This is certainly an interesting result. ‘Good’ ‘Bad’ FTSE 0.15 -0.31 FTSE Shifted One Day Ahead -0.08 -0.34 FTSE Shifted Two Days Ahead -0.48 -0.58 Table 2: Results of correlations between FTSE 100 and
sentiments
Discussion and Future Work In this paper we examined the effects of news on the FTSE 100. To examine this further, a prototype has been developed that can produce some form of market sentiment. Although the approach appears naïve from a linguistic point of view, it does suggest initial promise for the treatment of news data as time series.
To evaluate this approach, 172 Reuters news stories for the week 4-8 February 2002 were analysed by 6 native English speakers to determine whether a particular news item was good or bad for the stock market. The same analysis was also carried out using SATISFI and the resulting correlations are shown in Table 3 below.
FTSE Vs ‘Good’ FTSE Vs ‘Bad’ Manual 0.21 -0.67 SATISFI -0.15 -0.25
Table 3: Comparative Correlation Results of News Analysed Manually and by SATISFI for February 4,
2002 to February 8, 2002.
We observed that the results from correlations produced by human analysis were better than those produced automatically. We have examined the reasons for this difference and propose to make a number of improvements in the treatment of sentiment. It is important to know the entity involved in the ‘good’ or ‘bad’ evaluation and how that may affect other entities – rising inflation is considered good using this method, however this is bad for stocks, and hence rules regarding the knock-on effects of certain events need to be considered. Information Extraction techniques may provide a valuable basis for the generation of such information. Negation and the consideration of reportage versus prediction are also issues – the phrase “not seen rising” is predictive and negates the rise. However, if this were about inflation, this would be ‘good’ for stocks. Double negation introduces a further complication – the phrase “wouldn’t be unhappy with” exists in our corpus. We also intend to determine the ‘goodness’ or ‘badness’ of particular words and phrases, for example surge or bankruptcy are more evocative than slight rise or declining. Finally, it will be beneficial to determine events that are considered
positive or negative – despite its connotations, restructuring seems to have some positive aspects to it, whereas accounting fraud represents an extremely negative sentiment.
These improvements are the focus of ongoing work of the authors within the GIDA project, in combination with other project partners.
References [1] Khurshid Ahmad, Paulo C F de Oliveira,
Pensiri Manomaisupat, Matthew Casey and Tugba Taskaya “Description of Events: An Analysis of Keywords and Indexical Names” in Proceedings of the LREC2002 workshop on Event Modelling for Multilingual Document Linking
[2] Alvaro Almeida, Charles Goodhart, and Richard Payne (1998) “The Effects of Macroeconomic News on High Frequency Exchange Rate Behaviour” in Journal of Financial and Quantitative Analysis, Vol. 33, No. 3, September 1998
[3] Torben G Anderson and Tim Bollerslev (1996) “DM-Dollar Volatility: Intraday Activity Patterns, Macroeconomic announcements and longer run dependencies” in Journal of Finance, Vol. 53: 219-265
[4] John Bollinger (2001) “Bollinger on Bollinger Bands” McGraw-Hill Education - Europe; ISBN: 0071373683
[5] Markus K. Brunnermeier (1998) “Buy on Rumours - Sell on News: A Manipulative Trading Strategy” in FMG Discussion Papers from Financial Markets Group and ESRC
[6] Yuanchen Chang and Stephen J. Taylor (2002) "Information Arrivals and Intraday Exchange Rate Volatility", Journal of International Financial Markets, Institutions and Money, forthcoming.
[7] Charles Goodhart (1990) “’News’ and the Foreign Exchange Market”. LSE Financial Markets Group Discussion Paper 071
[8] V.Vance Roley and Gordon H. Sellon Jr. (1998) “Market Reaction to Monetary Policy Nonannouncements.” Federal Reserve Bank of Kansas City.

Multi-lingual Knowledge Bases for Information Extraction
R. Catizone, A. Setzer, N. Webb, Y. Wilks
Department of Computer ScienceUniversity of Sheffield
Regent Court211 Portobello StreetSheffield S1 4DP, UK
fR.Catizone, A.Setzer, N.Webb, [email protected]
AbstractInformation Extraction (IE) is a technology which, although performing at workable levels of accuracy, still faces majorchallenges in order to be deployable for a range of tasks. Traditionally, IE has been seen as a small scale, very focussedapplication. This paper reports on work done in the 5th Framework EU project, NAMIC, the aim of which was to performknowledge-based content analysis of news text for automatic authoring. An information extraction engine was used toidentify significant initial information in the form of domain specific events and their related objects. We present here theextensions to IE technology which make IE suitable for processing large, multi-domain, multi-lingual collections.
1. Introduction and Motivation
The two key components of an IE system are 1)the events (things that happen) and 2) their associatedobjects (typically people, places, and organisations).Although IE has been a successful technology (MUC,1995) (MUC, 1998), most current IE systems focus oneither a single task (such as resumes, or managementsuccession) or a single domain. One of the require-ments of the NAMIC project was handling multilin-gual texts in a broad range of news domains. As suchwe set out to improve the coverage of our IE system byapplying a stochastic, corpus-based approach to Infor-mation Extraction while incorporating a multilinguallexical resource. We have extended IE technology be-yond manually created domain templates by system-atically capturing as much significant data as possiblefrom the domain corpora and merging it with a broad-based knowledge base.
In the following sections, we will explain howthe requirements of the 5th Framework EU projectNAMIC led us to produce an IE system that wasknowledge-based, multilingual and very large-scale.We will further discuss other applications that maybenefit from using our method.
2. What is Information Extraction?
Information Extraction is the process of identify-ing specific types of information within a collectionof documents. Generally, the information that is spec-ified refers to events and their corresponding relations.The information is normally requested from a set of
documents in one domain such as finance or enter-tainment. The process of extracting specific kindsof information involves a variety of different subpro-cesses. Of these, the most significant are Named En-tity recognition, and coreference resolution. NamedEntity recognition is the process of identifying propernouns that are related to a particular relevant event insome domain. Generally named entity types are per-son, location, organisationetc. Coreference resolu-tion is the process of linking together all references tothe same term in a document even though the wordsused to indicate the term may be different - Mr. JohnSmith, he, John etc.
Information Extraction has a good track record(MUC, 1998), but usually only covers documentswithin a very limited set of domains. In this paper, wewill explain how we created a large-scale IE systemthat could be easily applied to process texts in multi-ple domains and multiple languages.
2.1. Knowledge-based vs. Shallow IE
IE as a technology has a variety of methods, ofwhich two are particularly dominant.
Knowledge based methods use some representa-tion of a world model as a basis for building a rep-resentation of a text during processing, and groundinginstances of people, places and events during process-ing. The LaSIE system (Humphreys et al., 1998), isan example of such a system.
Within LaSIE, the world model is an ontologicalrepresentation of events and objects for a particular

domain or set of domains, and as such is made up ofa set of event and object types, with attributes. Theevent types characterise a set of events in a particulardomain and are usually represented in a text by verbs.Object types on the other hand, are best thought ofas characterising sets of people, places or things andare usually represented in a text by nouns (both properand common). When used as part of an InformationExtraction system, instances of each type are instan-tiated in the world model. Those instances that referto the same thing are linked together, or co-referred.This is a major sub-task within IE, and knowledge-based methods have proved very effective at coref-erence resolution. The LaSIE system from the Uni-versity of Sheffield did very well in the MUC-7 task(MUC, 1998).
The Discourse Processor module inside LaSIEtranslates the semantic representation produced by theparser into a representation of instances, their onto-logical classes and their attributes, in the XI knowl-edge representation language (see (Gaizauskas andHumphreys, 1996)).
XI allows a straightforward definition of cross-classification hierarchies, the association of arbitraryattributes with classes or instances, and a simplemechanism to inherit attributes from classes or in-stances higher in the hierarchy.
The semantic representation produced by theparser for a single sentence is processed by addingits instances, together with their attributes, to the dis-course model which has been constructed for a text.
Following the addition of the instances mentionedin the current sentence, together with any presuppo-sitions that they inherit, the coreference algorithm isapplied to attempt to resolve, or in fact merge, each ofthe newly added instances with instances currently inthe discourse model.
The merging of instances involves the removal ofthe least specific instance (i.e. the highest in the ontol-ogy) and the addition of all its attributes to the otherinstance. This results in a single instance with morethan one realisation attribute, which corresponds to asingle entity mentioned more than once in the text, i.e.a coreference.
The mechanism described here is an extremelypowerful tool for accomplishing the IE task, however,in common with all knowledge-based approaches, andas highlighted in the introduction to this paper, the sig-nificant overhead in terms of development and deploy-ment is in the creation of the world model representa-tion.
The overhead of any knowledge-based approach isin the quantity of information required prior to pro-
cessing (the size of the world model the IE systempossesses), and how this information is acquired. Tra-ditionally, this kind of IE system has worked well ina very tightly defined domain, where hand-crafting ofa World Model is possible, and which ensures highquality results.
On the other hand, shallow models use large quan-tities of data to derive mappings from surface formsto templates (Riloff, 1993; Sonderland et al., 1995).Automatic techniques are used to acquire extractionrules automatically from large domain specific cor-pora, often partially annotated by human users, anduploaded into the IE engine. The benefits are largelyin the length of time it takes to have an initial work-ing system, and the breadth of coverage such a systemcan achieve. Initially, a system created in this way cansuffer from a loss of precision, but larger corpora, andthe ability to do some limited generalisation throughelectronic thesauri, have meant that these systems nowperform at a very high level of accuracy. However,they are unable to support higher levels of inferenceor generalisation.
The best approach would be a knowledge-basedextraction system which could make use of rapid pro-totyping techniques and large corpora to acquire data.
3. Making IE very large-scale
In a knowledge-based IE system, the method of ac-quiring and importing knowledge into the system isvery important. In a large number of IE systems, thedomain knowledge that is required of the system isinput manually - a very time-consuming and tediousprocess. The essential knowledge that makes up a KBIE system pertains to events and their related objects.In the following sections, we propose a means for ac-quiring this knowledge automatically. We chose torepresent and structure our knowledge hierarchicallyto allow for generalisation.
3.1. Extending the Event Hierarchy
The traditional limitations of a knowledge-basedinformation extraction system have been the need tohand-code information for the world model - specifi-cally relating to the event structure of the domain. Thisis also valid for NAMIC. To aid the development of theworld model, a semi-automatic boot-strapping processhas been developed, which creates the event type com-ponent of the world model. To us, event descriptionscan be categorised as a set of regularly occurring verbswithin our domain, complete with their subcategorisa-tion information.
The domain verbs can be extracted using a sta-tistical technique over domain corpora. Our tech-

lorry(X) motorcycle(X) car(X)( ) & (commercial(X) private(X))
(rover(X) toyota(X) renault(X)) & (twodoor(X) fourdoor(X))
top(X)
event(X)object(X)
vehicle(X)
e1
country(X)
e2 e3 made_in
property(X)
colour_of
multi_valued_prop(X) single_valued_prop(X)
Figure 1: An example of a XI hierarchy
nique involved finding the most frequently occuringverbs in a domain corpus. In the domain of finance,we used a corpus of Financial Times news articleswhich contained about 13,000,000 words. We firsttagged the corpus with part of speech tags using theBrill Tagger and then used a morphology program tomerge like verb forms together. We then did a fre-quency count over the verbs and removed, by hand,the most common verbs such as have, be, etc Wealso carried out the same analysis on Web documentsusing IPTC (International Press and Telecommunica-tions Council) categories as our domain topics. Once alist of verbs has been extracted, subcategorisation pat-terns can be generated automatically using a combi-nation of weakly supervised example-driven machinelearning algorithms. There are mainly three inductionsteps. First, syntactic properties are derived for eachverb, expressing the major subcategorisation informa-tion underlying those verbal senses which are moreimportant in the domain. Then, in a second phase,verb usage examples are used to induce the seman-tic properties of nouns in argumental positions. Thisinformation relates to selectional constraints, indepen-dently assigned to each verb subcategorisation pattern.Thus, different verb senses are derived, able to de-scribe the main properties of the domain events (e.g.Companies acquire companies). In a third and finalphase event types are derived by grouping verbs ac-cording to their syntactic-semantic similarities. Here,shared properties are used to generalise from the lex-ical level, and generate verbal groups expressing spe-cific semantic (and thus conceptual) aspects. Thesetypes are then fed into the event hierarchy as requiredfor their straightforward application within the targetIE scenario.
3.1.1. Acquisition of Subcategorisation PatternsEach verb v is separately processed. First, each
local context (extracted from sentences in the sourcecorpus) is mapped into a feature vector describing:
� the verb v of each vector (i.e. the lexical head ofthe source clause),
� the different grammatical relationships (e.g.Subj and Obj for grammatical subject and ob-jects respectively) as observed in the clause, and
� the lexical items, usually nouns, occurring inspecific grammatical positions, e.g. the subjectNamed Entity, in the clause.
Then, vectors are clustered according to the set ofshared grammatical (not lexical) properties: Only theclauses showing the same relationships (e.g. all theSubj-verb-Obj triples) enter in the same subset Vi.Each cluster thus expresses a specific grammatical be-haviour shared by several contexts (i.e. clauses) in thecorpus. The shared properties in Vi characterise thecluster, as they are necessary and sufficient member-ship conditions for the grouped contexts.
As one context can enter in more than one clus-ter (as it can share all (or part) of its relations withthe others), the inclusion property establishes a natu-ral partial order among clusters. A cluster Vi is in-cluded in another cluster Vj if its set of properties islarger (i.e. Pi � Pj) but is shown only by a subsetof the contexts of the latter Vj . The larger the set ofmembership constraints, the smaller the resulting clus-ter is. In this way, clusters are naturally organised intoa lattice (called a Galois lattice). Complete proper-ties express for each cluster candidate subcategorisa-tion pattern for the target verb v.

Finally, the lattice is traversed top-down and thesearch stops at the more important clusters (i.e. thoseshowing a large set of members and characterisedby linguistically appealing properties): they are re-tained and a lexicon of subcategorisation structures(i.e. grammatical patterns describing different usagesof the same verb) is compiled for the target verb v.For example, (buy, [Subj:X, Obj:Y]) can beused to describe the transitive usage of the verb buy.More details can be found in (Basili et al., 1997).
3.1.2. Corpus-driven Induction of VerbSelectional Restrictions
The lattice can be further refined to express seman-tic constraints over the syntactic patterns specified atthe previous stage. A technique proposed in (Basili etal., 2000) is adopted by deriving semantic constraintsvia synsets (i.e. synonymy sets) in the WordNet 1.6base concepts (part of EuroWordNet). When a givenlattice node expresses a set of syntactic properties,then this suggests:
� a set of grammatical relations necessary to ex-press a given verb meaning, R1; :::; Rk; and
� references to source corpus contexts C where thegrammatical relations are realised in texts.
This information is used to generalise verb argu-ments. For each node/pattern, the nouns appearing inthe same argumental position i (in at least one of thereferred examples in the corpus) are grouped togetherto form a noun set Ni: a learning algorithm basedon EuroWordNet derives the most informative Eu-roWordNet synset(s) for each argument, activated bythe Ni members. Most informative synsets are thosecapable of (1) generalising as many nouns as possiblein Ni, while (2) preserving their specific semanticproperties. A metric based on conceptual density (E.and G., 1995) is here employed to detect the promis-ing, most specific generalisations sem(Ni) of Ni.Then the derived sets for each argument R1; :::; Rk areused to generate the minimal set of semantic patternss1; :::; sk capable of ”covering” all the examples in C ,with si 2 sem(Ni) 8i. The sequences express themost promising generalisations of examples C for thesubcategorisation R1; :::; Rk . As an example, (buy,[Agent:Company,Object:Company]) ex-presses the knowledge required for matchingsentences like ”Intel buys Vortex”. Full details on theabove process can be found in (Basili et al., 2000).Company is a base concept in EuroWordNet andit is sharedamong the three languages. It can thusbe activated via the Inter-Lingual-Index from lexicalitems of any language. If included in the world model
(as a concept in the object hierarchy), these baseconcepts play the role of a multilingual abstractionfor the event constraints.
3.1.3. Induction of Domain Event Types viaConceptual Clustering of Verb semanticPatterns
The final phase in the development of a large scaleworld model aims to link the event matching rulesvalid for one verb to the suitable event hierarchynodes. The following semi-automatic process can beapplied:
� First, a limited set of high level event types canbe defined by studying the corpus and via knowl-edge engineering techniques (e.g. interactionswith experts of the domain);
� then, semantic descriptions of verbs can begrouped automatically, according to the similar-ity among their corresponding patterns;
� finally, the obtained verb groups can be mappedto the high-level types, thus resulting in a flat hi-erarchy.
An example of the target event hierarchy is given infigure 2.
Currently, a set of event types (8 main groupingsin a financial domain ranging from ”Company Acqui-sitions” and ”Company Assets” to ”Regulation”) havebeen defined. Within the eight event groupings, we ac-quired more than 3000 lexicalisations of events. Theclustering step has been approached with a techniquesimilar to the Galois lattices, where feature vectorsrepresent syntactic-semantic properties of the differ-ent verbs (i.e. pattern si; :::; sk derived in the previ-ous phase). All verbs are considered1 and the obtainedclusters represent semantic abstractions valid for morethan one verb. The following is an example of thegrouping of the verbs acquireto win.
cluster(141,[acquire,buy, catch,contribute,earn,gain,hire,issue,obtain,offer,order,pay,reach,receive,refer,secure,sell,
serve,trade,win]).patt(141, [
arg(’Obj’,(’measure quantity amountquantum ’,0),’abstraction ’),
arg(’Subj’,(’social_group’,0),
1Initial partitions according to the Levin classification(Levin, 1993) are adopted. A partition of the verbs is builtfor each of the Levin classes and conceptual clustering isapplied internally to each group.

GovernmentalActivities
CompanyAcquisitions
Event
Group 1 Group N
acquire buy send receive decide institute allow
...
...
... ... ...
Figure 2: Top levels in the event hierarchy vs. verb clusters
’entity something ’)]).
The above cluster expresses a conceptual propertyable to suggest a specific event subtype. Thus, manualmapping to the correct high-level concept (”Companyacquisition” event type) is made possible and moreintuitive. As semantic constraints in event typesare given by base concepts, translations into Italianand Spanish rules (for example: (acquistare,[Agent:Company,Object:Company])) arepossible. They inherit the same topological positionin the event ontology. Accordingly, the worldmodel has a structure (i.e. the main object andevent hierarchies) which is essentially languageindependent. Only the lowest levels are representativeof each language. Here, a language specific lexicali-sation is required. The advantage is that most of thegroups derived for English can be retained for otherlanguages, and a simple translation suffices for mostof the patterns. Lexicalisations are thus associatedwith the language independent abstractions (i.e.matching rules over parsed texts) which control thebehaviour of instances of these events in the discourseprocessing.
The integrated adoption of EuroWordNet and theautomatic acquisition/translation of verb rules is thusthe key idea leading to a successful and quick devel-opment of the large scale IE component required forautomatic authoring.
3.2. Object Hierarchy
In typical Information Extraction processing envi-ronments, the range of objects in the text is expected tobe as limited and constrained as the event types. Forexample, when processing ’management succession’events (MUC, 1995), the object types are the obviousperson, location, organisation, timeand date. Intu-itively however, if the need was to process the entire
output of a news agency, it seems clear that we mustbe able to capture a much wider range of possible ob-jects which interact with central events. Rather thanattempt to acquire all of this object information fromthe corpus data, we instead chose to use an existingmultilingual lexical resource, EuroWordNet.
3.2.1. EuroWordNetEuroWordNet (Vossen, 1998) is a multilingual lex-
ical knowledge (KB) base comprised of hierarchicalrepresentations of lexical items for several Europeanlanguages (Dutch, Italian, Spanish, German, French,Czech and Estonian). The wordnets are structured inthe same way as the English WordNet developed atPrinceton (Miller, 1990) in terms of synsets (sets ofsynonymous words) with basic semantic relations be-tween them.
In addition, the wordnets are linked to an Inter-Lingual-Index (ILI), based on the Princeton Word-Net 1.5. (WordNet 1.6 is also connected to the ILIas another English WordNet (Daude et al., 2000)).Via this index, the languages are interconnected sothat it is possible to go from concepts in one lan-guage to concepts in any other language having sim-ilar meaning. Such an index also gives access to ashared top-ontology and a subset of 1024 Base Con-cepts (BC). The Base Concepts provide a commonsemantic framework for all the languages, while lan-guage specific properties are maintained in the indi-vidual wordnets. The KB can be used, among oth-ers, for monolingual and cross-lingual information re-trieval, which was demonstrated by (Gonzalo et al.,1998).
3.2.2. EuroWordNet as the Object OntologyThe example rules shown in the previous section
relate to Agents which conveniently belong to a classof Named Entities as would be easily recognised underthe MUC competition rules (person, companyand lo-

cation for example). However, a majority of the rulesextracted automatically from the corpus data involvedother kinds of semantic classes of information whichplay key roles in the subcategorisation patterns of theverbs.
In order to be able to work with these patterns,it was necessary to extend the number of semanticclasses beyond the usual number of predefined classes,across a variety of languages.
Representing the entirety of EWN in our object hi-erarchy would be time consuming, and lead to inef-ficient processing times. Instead we took advantageof the Base Concepts (Rodriquez et al., 1998) withinEWN, a set of approximately 1000 nodes, with hierar-chical structure, that can be used to generalise the restof the EWN hierarchy.
These Base Concepts represent a core set of com-mon concepts to be covered for every language thathas been defined in EWN. A concept is determinedas important (and is therefore a base concept) if it iswidely used, either directly or as a reference for otherwidely used concepts. Importance is reflected in theability of a concept to function as an anchor to attachother concepts.
The hierarchical representation of the base con-cepts is added to the object hierarchy of the NAMICworld model. Additionally, a concept lookup functionis added to the namematcher module of the NAMICarchitecture. This lookup takes all common nounsin the input, and translates them into their respectiveEWN Base Concept codes.
This process was reversed in the event rule acqui-sition stage, so that each occurrence of a object in arule was translated into a Base Concept code. This hastwo effects. Firstly, the rules become more generic,creating a more compact rule base. Secondly, giventhe nature of the inter-lingual index which connectsEWN lexicons, the rules became language indepen-dent at the object level. Links between the lexicali-sations of events are still required, and at present arehand-coded, but future development of the verb repre-sentations of WN might eliminate this.
In summary, this new, expanded WM covers boththe domain specific events and a wide range of agents,and can be acquired largely automatically from cor-pus data, and used to process large amounts of text ona spectrum of domains by leveraging existing multi-lingual lexical resources.
3.3. The NAMIC Task
Automatic Authoring Automatic Authoring is thetask of automatically deriving a hypertextual struc-ture from a set of available news articles - in our case
this is applied to the three project languages respec-tively (English, Italian, and Spanish). Monolingualauthoring establishes links between paragraphof arti-cles in the same language , whereas Multilingual Au-thoring establishes links between articles in all threelanguages. The underlying principle, however, is sim-ilar in both cases and the complexity of the overallframework requires a suitable decomposition, like thefollowing:
� Text processing requires at least the detection ofmorphosyntactic information characterising thesource texts: recognition, normalisation, and as-signment of roles is required for the main partic-ipants for the different events/facts described
� Proper Noun Matching is the activity of findingproper nouns in the incoming texts. This pro-cess uses lists of different proper nouns - Per-son names, locations names etc. as well as a setof rules for identifying proper nouns in a text.There may also be significant common nouns inthe incoming texts, but these are found throughassociation to their respective events in the EventMatching process.
� Event Matching is then the activity of selectingthe relevant facts of a news article, in terms oftheir general type (e.g. selling or buying compa-nies, winning a football match), their participantsand their related roles (e.g. the company sold orthe winning football team)
� Authoring is thus the activity of generating linksbetween news articles according to relationshipsestablished among facts detected in the previousphase.
For instance, a company acquisition can be re-ferred to in one (or more) news items as:
– Intel, the world’s largest chipmaker, boughta unit of Danish cable maker NKT that de-signs high-speed computer chips used inproducts that direct traffic across the inter-net and corporate networks.
– The giant chip maker Intel said it acquiredthe closely held ICP Vortex Computersys-teme, a German maker of systems for stor-ing data on computer networks, to enhanceits array of data-storage products.
– Intel ha acquistato Xircom inc. per 748 mil-ioni di dollari.

– Le dichiarazioni della Microsoft, infatti,sono state precedute da un certo fermento,dovuto all’interesse verso Linux di grandiditte quali Corel, Compaq e non ultima Intel(che ha acquistato quote della Red Hat) ...
All the above news deal with facts in the samearea of interest (to a potential user class) and theyshould be linked by the authoring software.
Experience with content extraction systems hasshown that the big issue for their future is theirportability and adaptability to new domains. Ma-chine Learning is the standard answer to this problem(Ciravegna, 2001) but we have tried to indicate thatother forms of the reuse and adaptation of well-listedNLP modules can also be shown to be productive. Inthis paper we have demonstrated a positive outcomefrom the customisation of the LaSIE recognition andontology systems to a very large domain of multilin-gual newspaper texts.
4. Future ApplicationsThe technology developed in the NAMIC
project, in fulfilling the requirements of large-scale, knowledge-based information extraction, isapplicable to a wide-range of situations. Given thelarge amounts of textual data now available, on theInternet and in company or instituition intranets, theuse of tools to leverage the content of these documentswould be very beneficial.
As Information Retrieval looks to tackle the prob-lems of Question-Answering, the task of supplyingspecific answers to user questions, as opposed to thedocument retrieval familiar to all search engine users,Information Extraction is seen as a key technology.
Unfortunately, one of the barriers on the uptakeof IE has been the large amount of human effort re-quired to bootstrap such a system - and in the case ofknowledge-based approaches, the lack of breadth of adomain which could be covered, due to the necessityof hand-coding a world model corresponding to thetarget task.
Shallow, statistical approaches to IE have alwaysboasted that, given domain information, stochastictechniques can be used to prototype the domain in arapid and low cost manner. The technologies devel-oped in the NAMIC project use some of these tech-niques to construct a complex world model, encom-passing deeper, linguistically motivated relationshipsbetween concepts in text.
In general, the use of technologies which can per-form some kind of multilingual knowledge-based doc-ument analysis are perfect for assisting in Knowledge
Management activities, such as the six UK Universityproject, AKT (Advanced Knowledge Technologies2)
AKT is concerned with Knowledge Managementin the sense of using technologies to share, store andretrieve collective expertise of people in an organisa-tion. One of the major tasks within this field is knowl-edge acquisition, which due to being a largely manualprocess has a high cost and is a performance bottle-neck.
The text and documents which form the reposito-ries of information are stored for the most part in un-structured textual format. The unacceptability of theknowledge contained within these texts prevents it’suse by automatic systems, and even inhibits coherentmanagement by humans.
Clearly, large-scale information extraction tech-nologies can be useful here, and specificallythe knowledge-based content extraction technologywhich forms the basis of the NAMIC project, and wewould hope that we can apply our technologies to suchproblems in the immediate future.
5. Acknowledgements
This research is funded by the European Union,grant number IST-1999-12392. We would also liketo thank all the partners in the NAMIC consortium.
6. References
R. Basili, M.T. Pazienza, and M. Vindigni. 1997.Corpus-driven unsupervised learning of verb sub-categorization frames. In M. Lenzerini, editor,AI*IA 97: Advances in Artificial Intelligence,Lecture Notes in Artificial Intelligence n., 1321.Springer Verlag, Berlin.
R. Basili, M.T. Pazienza, and M. Vindigni. 2000.Corpus-driven learning of event recognition rules.In Proc. of Machine Learning for Information Ex-traction workshop, held jointly with the ECAI2000,Berlin, Germany.
F. Ciravegna. 2001. Adaptive information extractionfrom text by rule induction and generalisation. InProceedings of 17th International Joint Conferenceon Artificial Intelligence (IJCAI 2001), Seattle, WA.
J. Daude, L. Padro, and G. Rigau. 2000. MappingWordNets using Structural Information. In Pro-ceedings of the 38th Annual Meeting of the Associ-ation for Computational Linguistics ACL’00, HongKong, China.
Agirre E. and Rigau G. 1995. A proposal for wordsense disambiguation using conceptual distance.In International Conference ”Recent Advances in
2see http://www.aktors.org

Natural Language Processing” RANLP’95, TzigovChark, Bulgaria.
R. Gaizauskas and K. Humphreys. 1996. Xi: A sim-ple prolog-based language for cross-classificationand inheritance. In Proceedings of the 6th In-ternational Conference on Artificial Intelligence:Methodologies, Systems, Applications (AIMSA96),pages 86–95.
J. Gonzalo, F. Verdejo, I. Chugur, and J. Cigarran.1998. Indexing with WordNet Synsets can im-prove Text Retrieval. In Proceedings of the COL-ING/ACL’98 Workshop on Usage of WordNet forNLP, Montreal, Canada.
K. Humphreys, R. Gaizauskas, S. Azzam, C. Huyck,B. Mitchell, H. Cunningham, and Y. Wilks. 1998.University of Sheffield: Description of the LaSIE-II system as used for MUC-7. In Proceedingsof the Seventh Message Understanding Confer-ences (MUC-7). Morgan Kaufman. Available athttp://www.saic.com.
B. Levin. 1993. English Verb Classes and Alterna-tions. Chicago, IL.
G. Miller. 1990. Five Papers on WordNet. Interna-tional Journal of Lexicography, 4(3).
1995. Proceedings of the Sixth Message Understand-ing Conference (MUC-6). Morgan Kaufman. Avail-able at http://www.saic.com.
1998. Proceedings of the Seventh Message Under-standing Conference (MUC-7). Morgan Kaufman.Available at http://www.saic.com.
E. Riloff. 1993. Automatically constructing a dictio-nary for information extraction tasks. In Proceed-ings of the 11th National Conference on ArtificialIntelligence, pages 811–816. AAAI/MIT Press.
H. Rodriquez, S. Climent, P. Vossen, L. Bloksma,A. Roventini, F. Bertagna, A. Alonge, and W. Pe-ters. 1998. The Top-Down Strategy for BuildingEuroWordNet: Vocabulary Coverage, Base Con-cepts and Top Ontology . Special Issue on Eu-roWordNet. Computers and the Humanities, 32(2-3):117–152.
S. Sonderland, D. Fisher, J. Aseltine, and W. Lehnert.1995. Crystal:inducing a conceptual dictionary. InProceedings of the 14th International Joint Confer-ence on Artificial Intelligence.
P. Vossen. 1998. EuroWordNet: A MultilingualDatabase with Lexical Semantic Networks. KluwerAcademic Publishers, Dordrecht.



















