
Making Cassandra Perform as a Time Series Database - Cassandra Summit 15
23
MM/DD/YY YOUR TITLE HERE PREPARED FOR: PLACE LOGO HERE Making Cassandra perform as a time series database Paul Ingram [email protected]
Transcript of Making Cassandra Perform as a Time Series Database - Cassandra Summit 15

M M / D D / Y Y
YOUR T ITLE HERE
P R E PA R E D F O R :
P L A C E L O G O
H E R E
Making Cassandra performas a time series database
Paul [email protected]

Introduction
• real time streaming analytics for monitoring and alerting
• ingest many billions of points of timeseries data per day
• ingest at 1 second resolution
• all of this data ends up in cassandra
#CassandraSummit

What we’re talking about
• a metric is an abstract quantity such as CPU load or heap size
• a source is some entity which measures and reports metrics
• a datapoint is a value for a metric from a source at some time
• a timeseries a sequence of those datapoints over time
#CassandraSummit
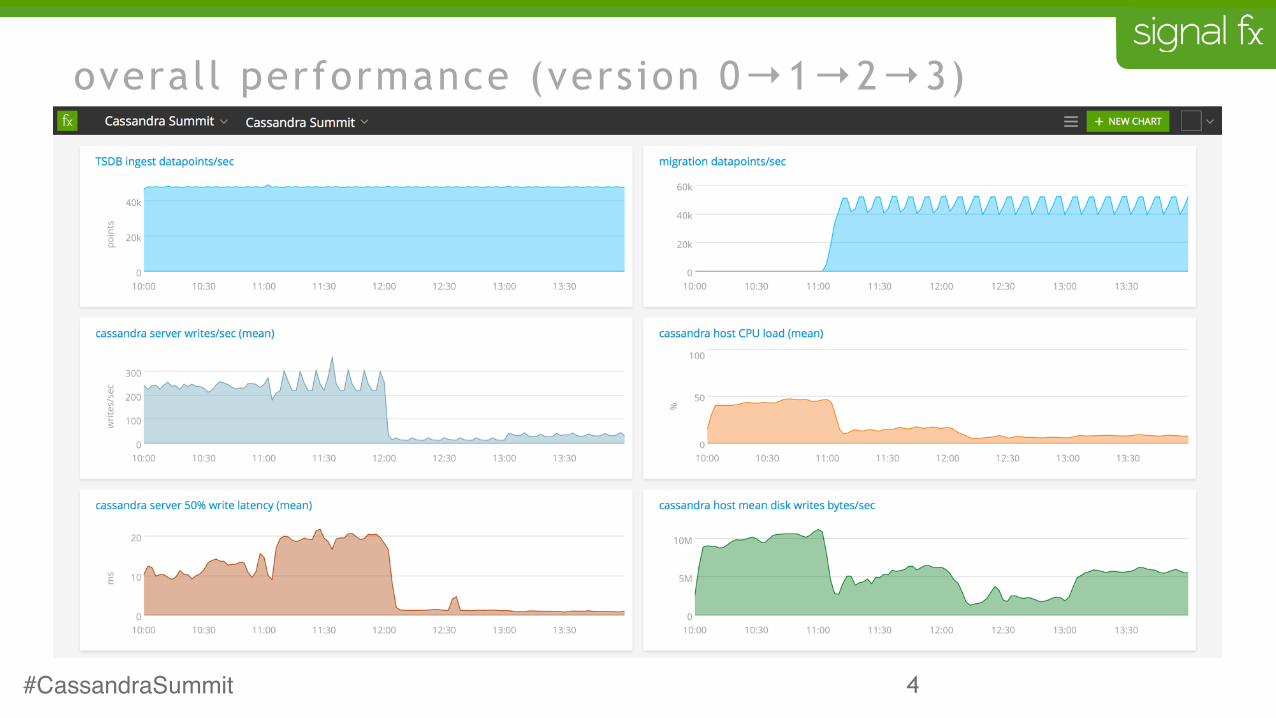
4#CassandraSummit
overall performance (version 0→1→2→3)
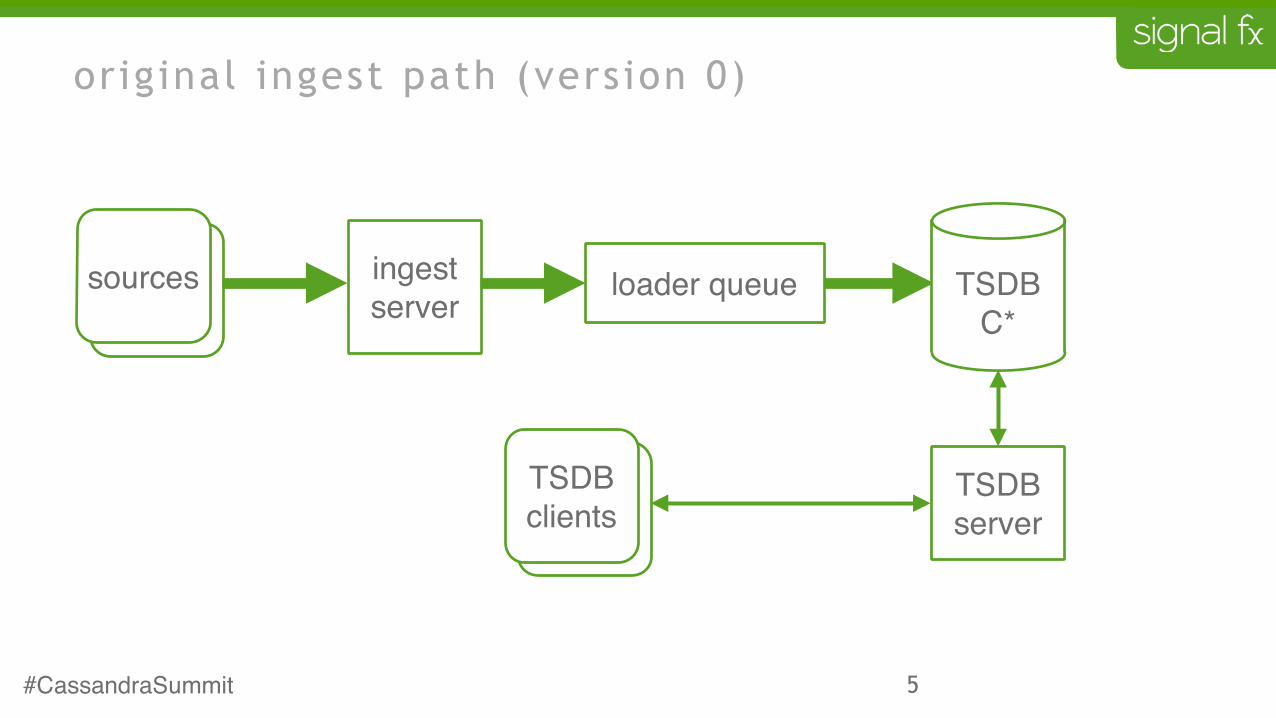
5
original ingest path (version 0)
ingestserver loader queue
TSDBserversources
TSDB clients
sourcessources TSDBC*
#CassandraSummit

6
TSDB schema (versions 0,1,2,3)
CREATE TABLE table_0 ( segment text time timestamp, value blob, PRIMARY KEY (segment, time) ) WITH COMPACT STORAGE;
#CassandraSummit

7
cassandra operation (version 0)
#CassandraSummit
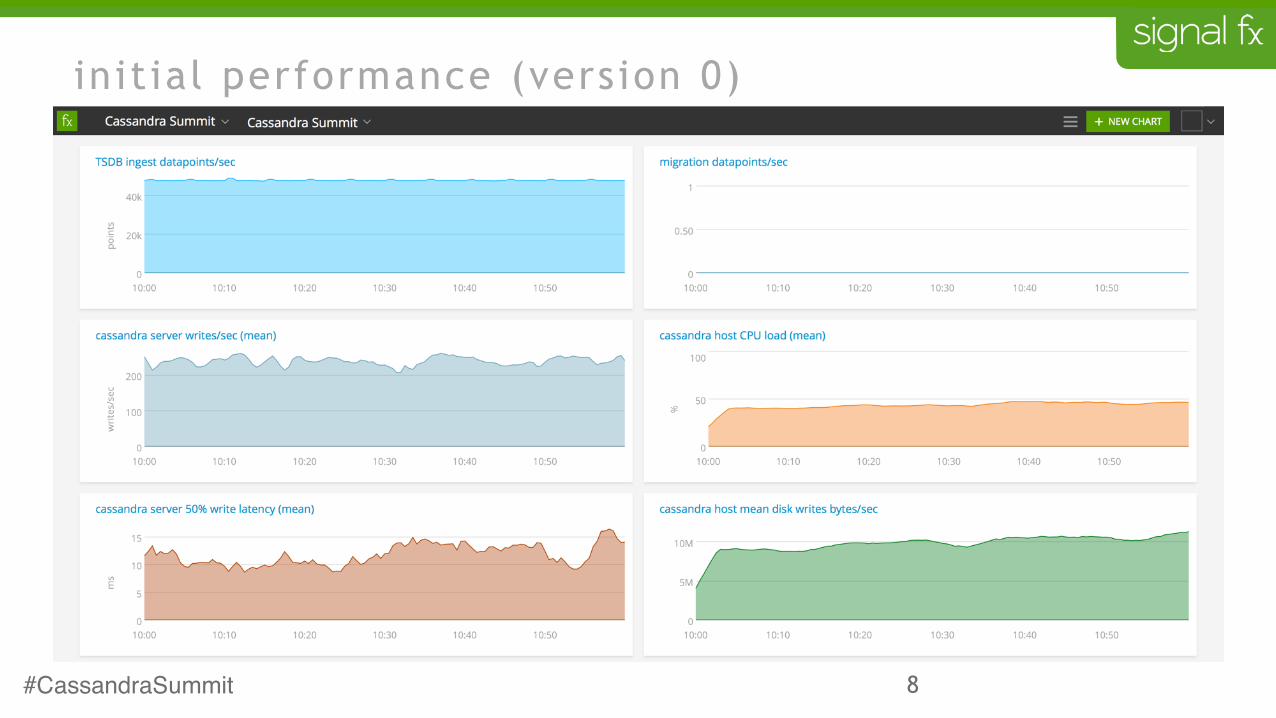
8#CassandraSummit
init ial performance (version 0)

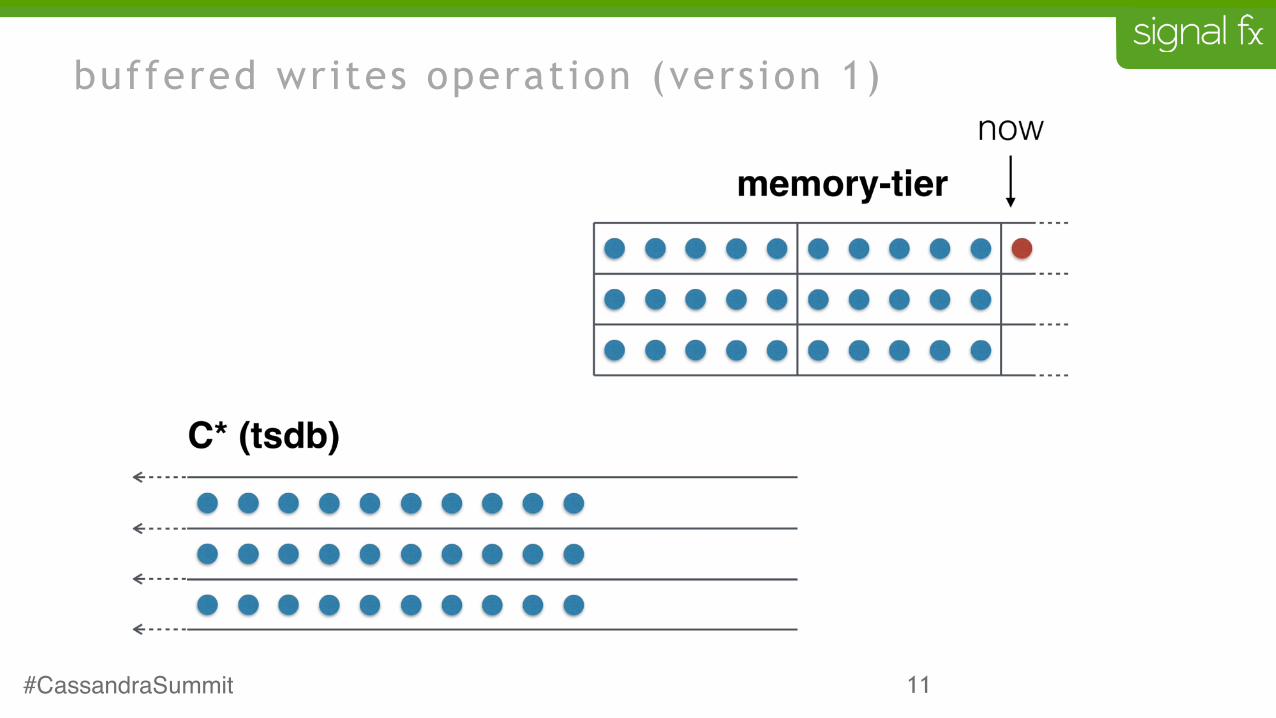
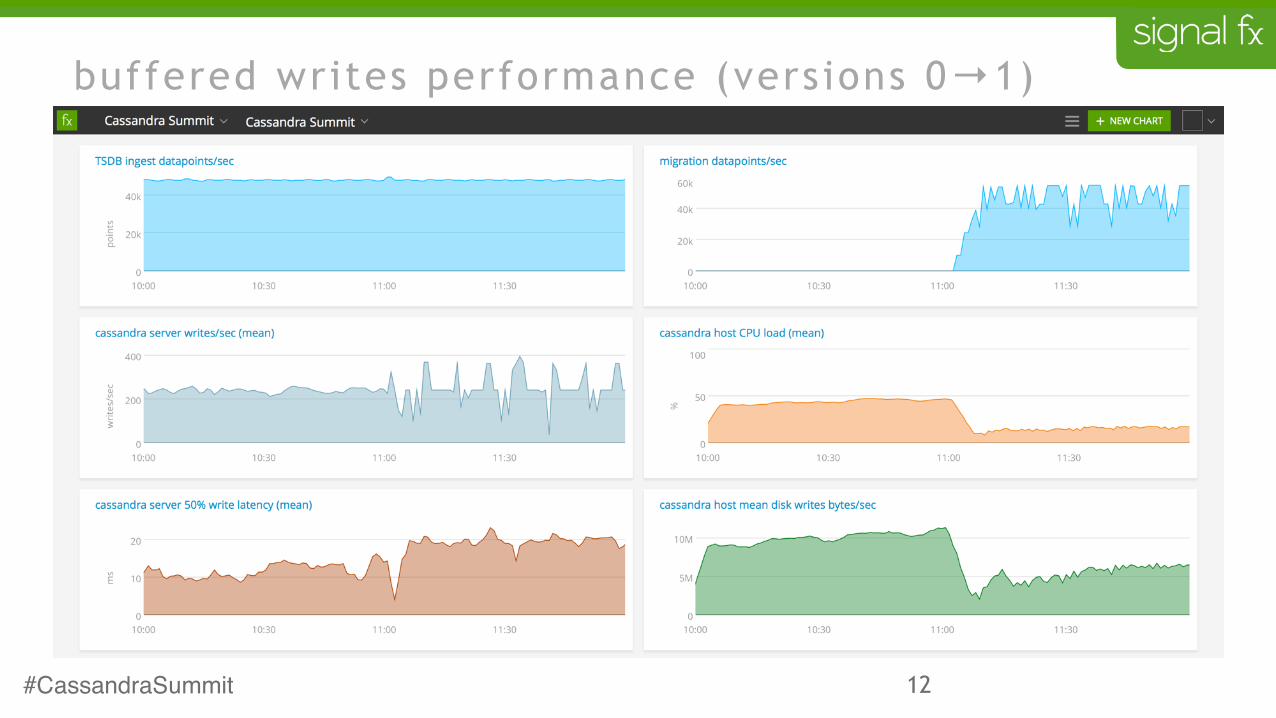
buffered writes rationale (version 1)
• writing every datapoint individually is very expensive
• buffer data in memory
• write many points in a batch statement
• buffers are dropped when they have been written to cassandra
9#CassandraSummit
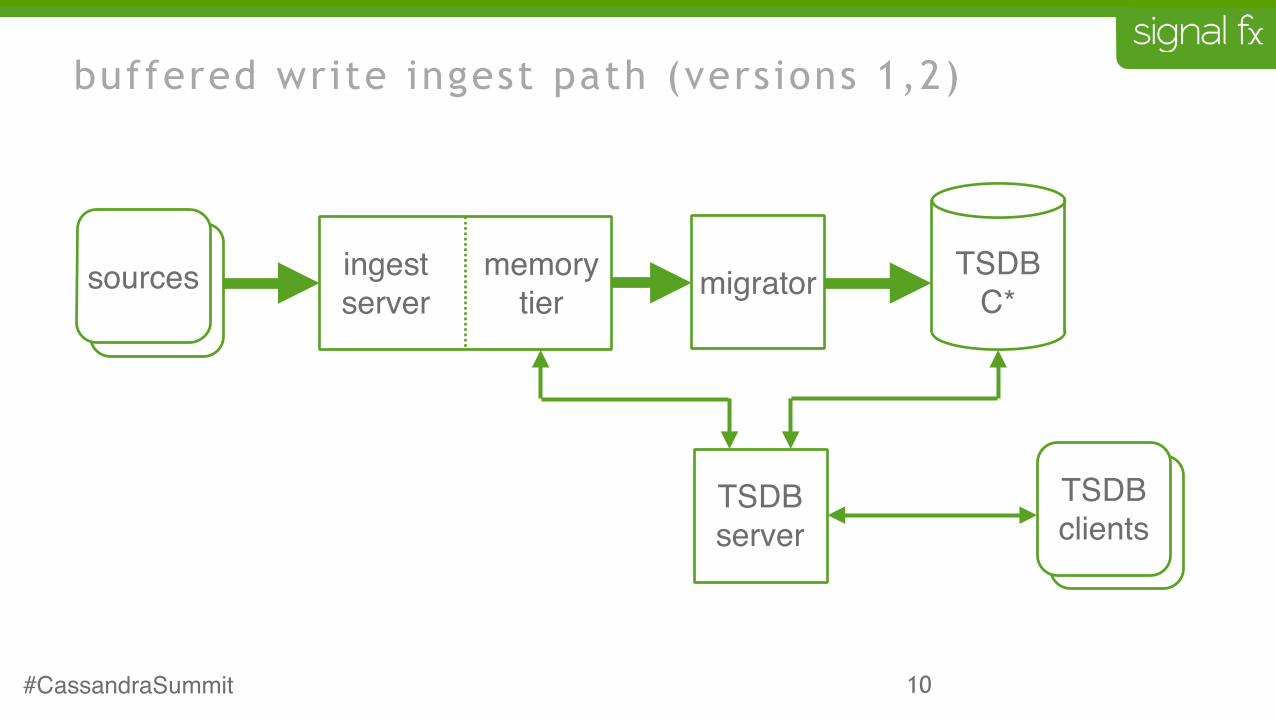
10
buffered write ingest path (versions 1,2)
TSDBserver sources
TSDB clients
sourcessources TSDBC*migratormemory
tieringestserver
#CassandraSummit
11
buffered writes operation (version 1)
#CassandraSummit
12
buffered writes performance (versions 0→1)
#CassandraSummit

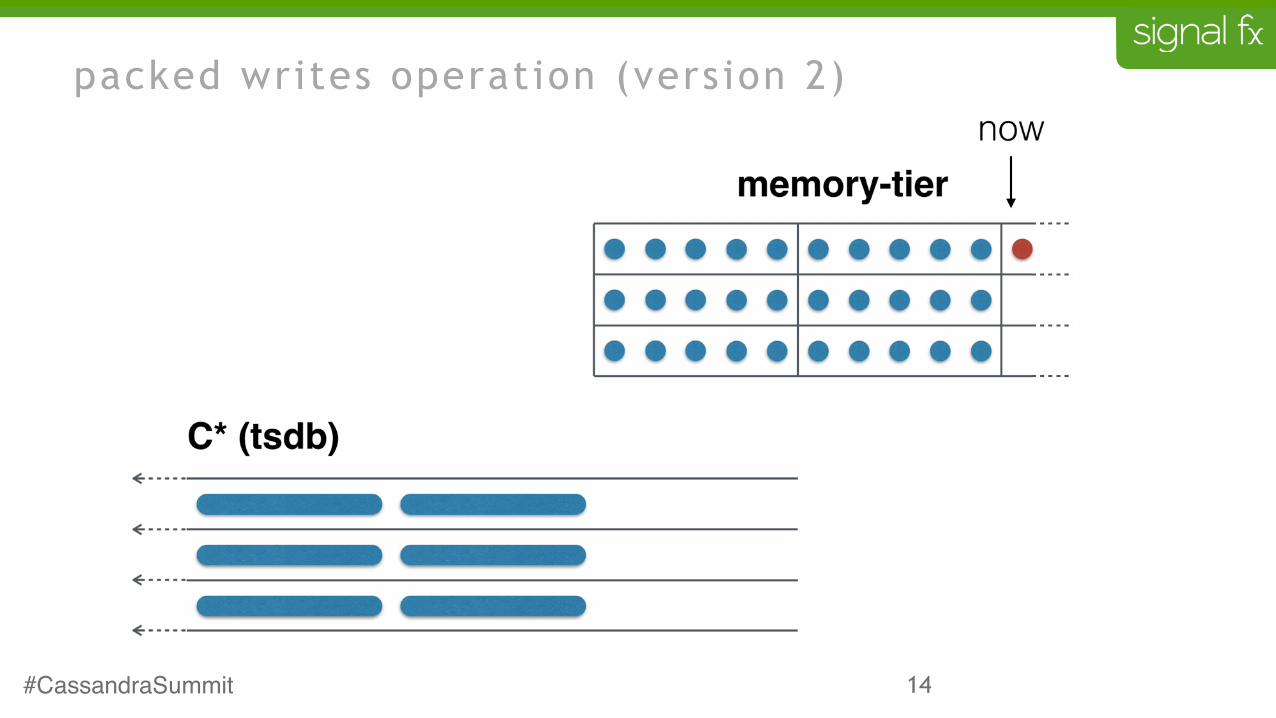
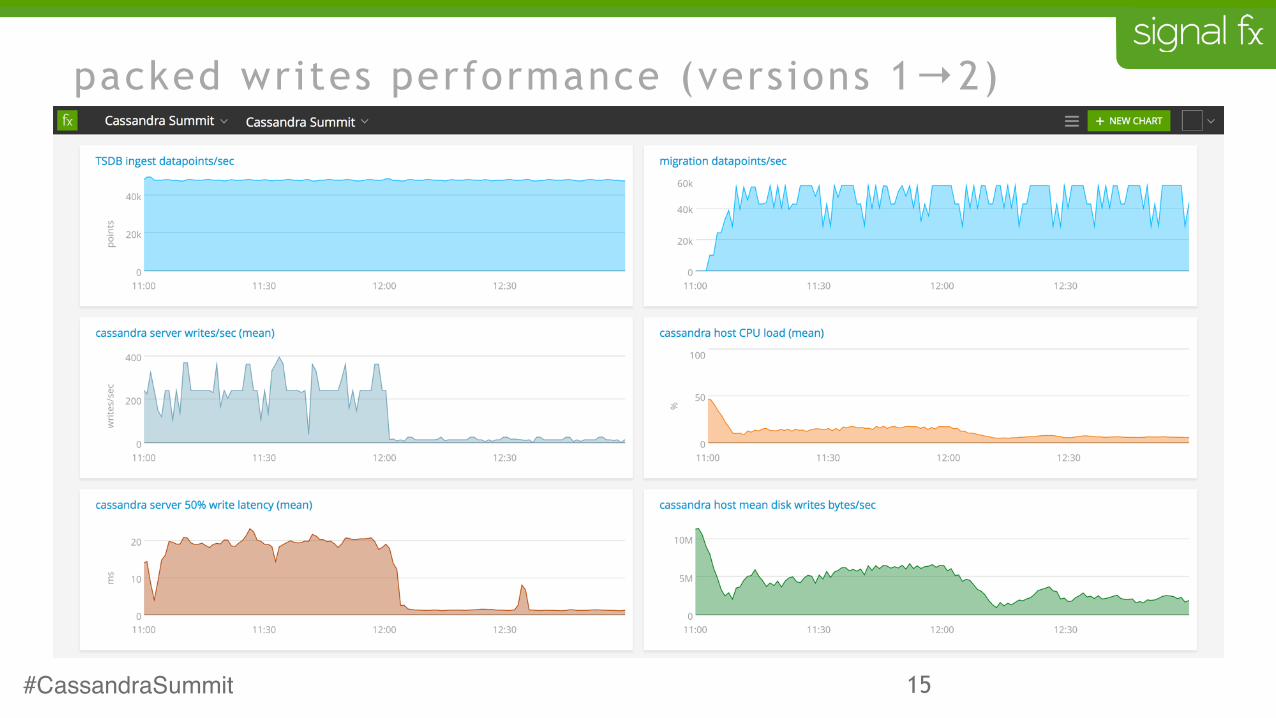
packed writes rationale (version 2)
• writing data point-by-point means a column for each datapoint
• pack a buffer of datapoints into a block and write the block
• this will reduce the number of columns and write operations
• will have more impact on storage than on performance
• schema and overall flow remain the same
13#CassandraSummit
14
packed writes operation (version 2)
#CassandraSummit
15
packed writes performance (versions 1→2)
#CassandraSummit

redo-log rationale (version 3)
• if the ingest server dies, we lose the buffered data
• fix this with more cassandra
• write a persistent log of data as it’s written to the memory-tier
• when an ingest server restarts it will reload its memory-tier from this log
16#CassandraSummit
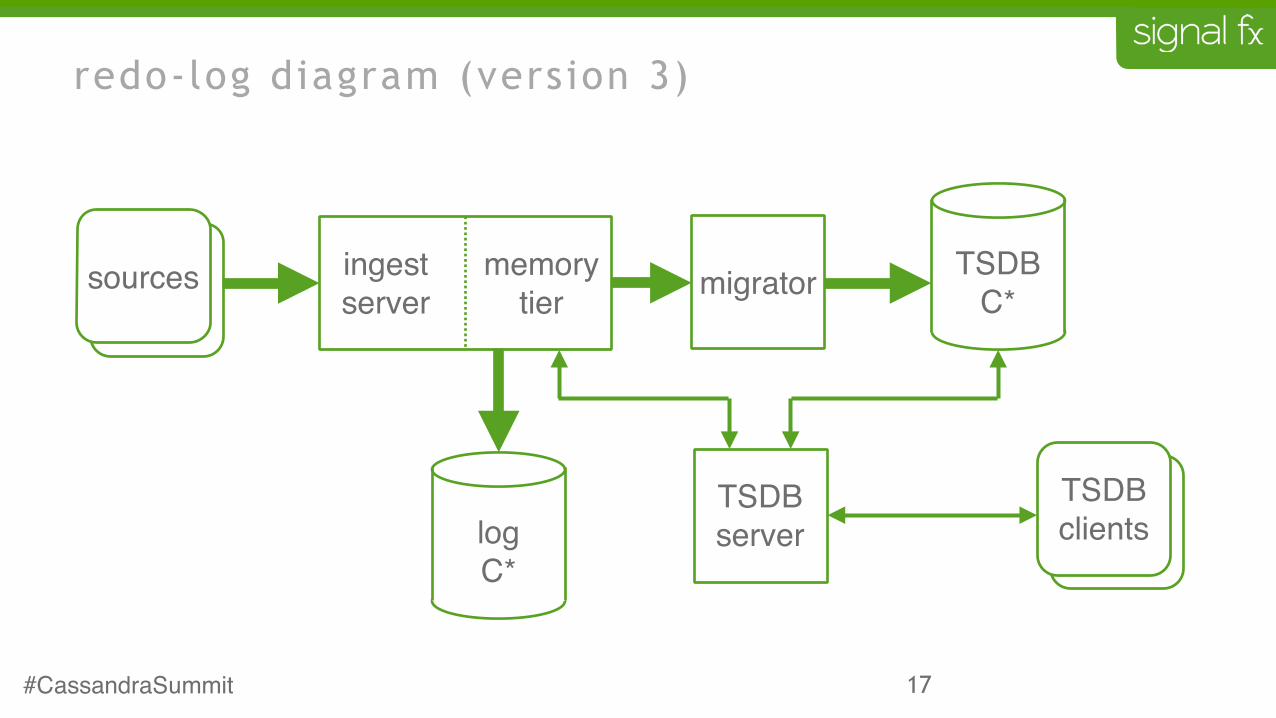
17
redo-log diagram (version 3)
TSDBserver sources
TSDB clients
sourcessources TSDBC*migratormemory
tieringestserver
logC*
#CassandraSummit

18
log schema (version 3)
CREATE TABLE table_0 ( stamp text, sequence bigint, value blob, PRIMARY KEY (stamp, sequence) ) WITH COMPACT STORAGE;
#CassandraSummit
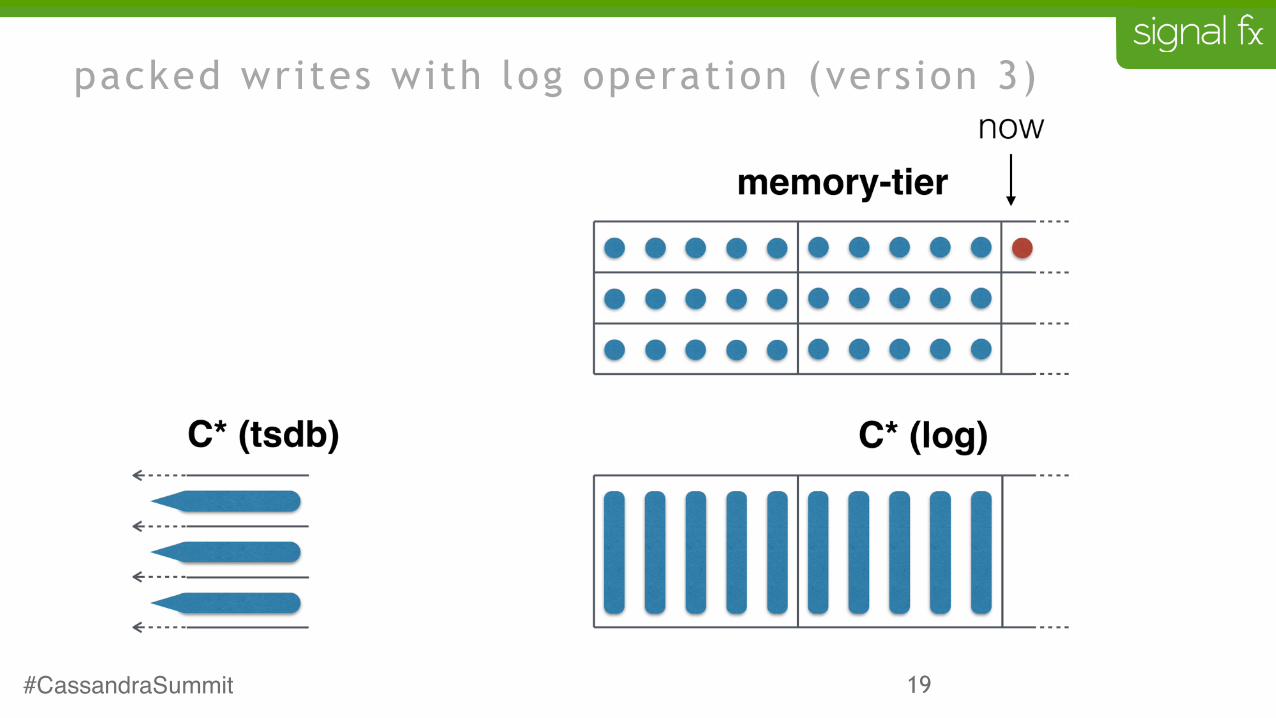
19
packed writes with log operation (version 3)
#CassandraSummit
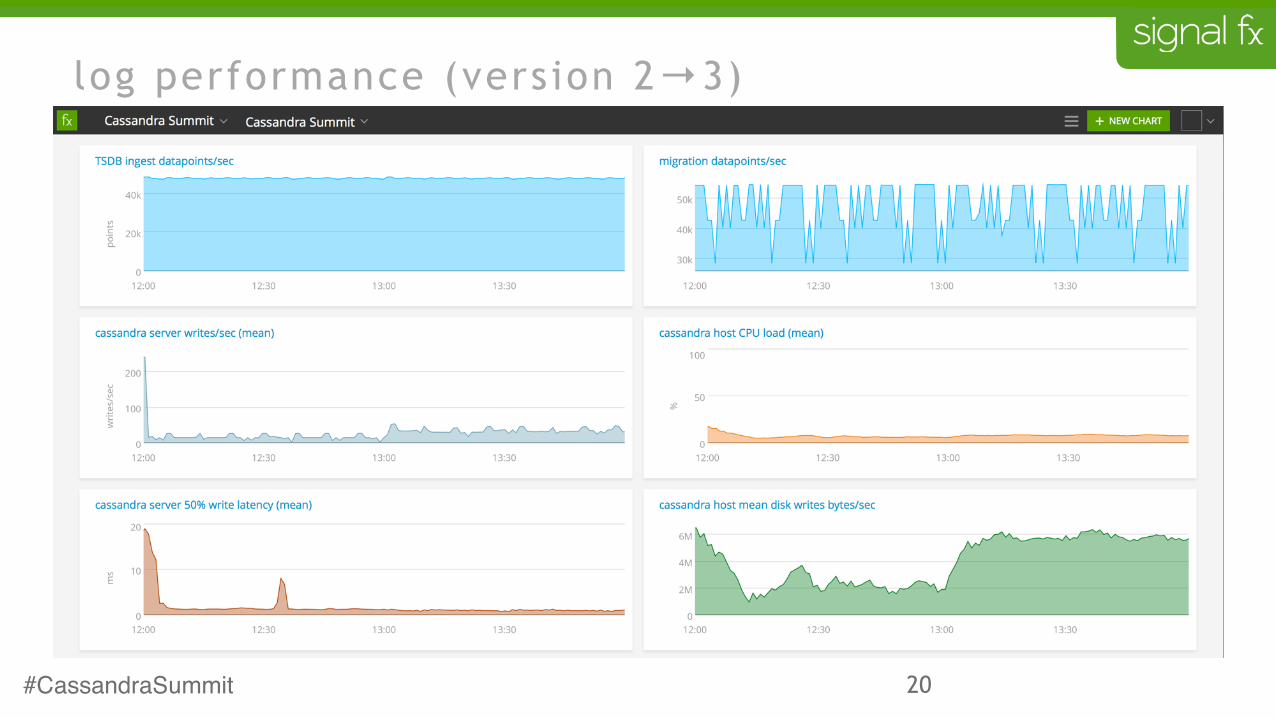
20
log performance (version 2→3)
#CassandraSummit

what we found
• matching the workload to the database is very important
• load is much more dependent on rate of writes than on volume of data written
• for our very write-heavy workload we saw 4x performance improvement by doing fewer, larger writes
• it turns out to be cheaper to write data twice efficiently than once naively
21#CassandraSummit
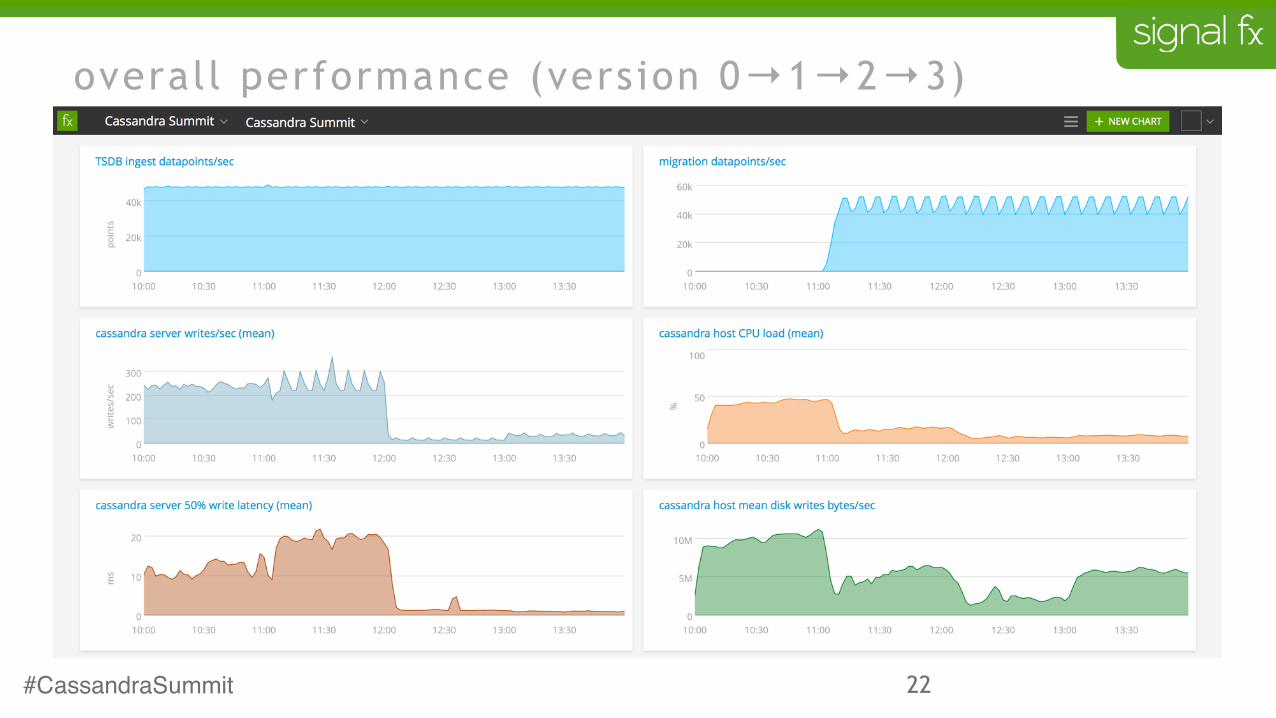
22
overall performance (version 0→1→2→3)
#CassandraSummit

23
Thanks
Paul [email protected]
#CassandraSummit
WE’RE [email protected]://signalfx.com/careers.html


















