
LUẬN VĂN THẠC SĨi.vietnamdoc.net/data/file/2015/Thang04/09/nghien-cuu-phuong-phap-xu... ·...
59
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ LÊ QUÝ TÀI NGHIÊN CỨU CÁC PHƯƠNG PHÁP XỬ LÝ TIẾNG VIỆT ỨNG DỤNG CHO TÓM TẮT VĂN BẢN LUẬN VĂN THẠC SĨ Hà Nội - 2011
Transcript of LUẬN VĂN THẠC SĨi.vietnamdoc.net/data/file/2015/Thang04/09/nghien-cuu-phuong-phap-xu... ·...

ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
LÊ QUÝ TÀI
NGHIÊN CỨU CÁC PHƯƠNG PHÁP XỬ LÝ TIẾNG VIỆT ỨNG DỤNG CHO TÓM TẮT VĂN BẢN
LUẬN VĂN THẠC SĨ
Hà Nội - 2011

ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
LÊ QUÝ TÀI
NGHIÊN CỨU CÁC PHƯƠNG PHÁP XỬ LÝ TIẾNG VIỆT ỨNG DỤNG CHO TÓM TẮT VĂN BẢN
Ngành: Công nghệ thông tin Chuyên ngành: Hệ thống thông tin Mã số: 60 48 05
LUẬN VĂN THẠC SĨ
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. PHẠM BẢO SƠN
Hà Nội - 2011

i
LỜI CAM ĐOAN
Tôi xin cam đoan kết quả đạt được trong luận văn là sản phẩm nghiên cứu, tìm hiểu của riêng cá nhân tôi. Trong toàn bộ nội dung của luận văn, những điều được trình bày hoặc là của cá nhân tôi hoặc là được tổng hợp từ nhiều nguồn tài liệu. Tất cả các tài liệu tham khảo đều có xuất xứ rõ ràng và được trích dẫn hợp pháp.
Tôi xin hoàn chịu trách nhiệm và chịu mọi hình thức kỷ luật theo quy định cho lời cam đoan của mình.
Hà Nội, tháng 6 năm 2011
TÁC GIẢ LUẬN VĂN
Lê Quý Tài

ii
LỜI CẢM ƠN
Trước hết tôi xin xin gửi lời cảm ơn đặc biệt tới TS. Phạm Bảo Sơn, người đã định hướng đề tài và tận tình hướng dẫn chỉ bảo tôi trong suốt quá trình thực hiện luận văn cao học này.
Tôi xin chân thành cảm ơn các thầy cô trường Đại học Công nghệ, Đại học Quốc Gia Hà Nội đã tận tình giảng dạy và truyền đạt những kiến thức, những kinh nghiệm quý báu trong suốt khóa học cao học.
Cuối cùng, tôi xin dành một tình cảm biết ơn tới gia đình và những người thân đã luôn ở bên cạnh, động viên, chia sẻ cùng tôi trong suốt thời gian học cao học cũng như quá trình thực hiện luận văn cao học.

iii
MỤC LỤC
LỜI CAM ĐOAN.....................................................................................................i
LỜI CẢM ƠN .........................................................................................................ii
MỤC LỤC .............................................................................................................iii
DANH MỤC CÁC KÝ HIỆU, CÁC CHỮ VIẾT TẮT........................................... v
DANH MỤC CÁC BẢNG .....................................................................................vi
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ ................................................................vii
MỞ ĐẦU ................................................................................................................1
Chương 1 TỔNG QUAN VỀ TÓM TẮT VĂN BẢN ..............................................3
1.1 Tổng quan......................................................................................................3
1.1.1 Khái niệm ..............................................................................................3
1.1.2 Lịch sử phát triển của tóm tắt văn bản.....................................................3
1.1.3 Phân loại các phương pháp tóm tắt văn bản.............................................4
1.2 Mô hình tóm tắt văn bản ................................................................................6
1.2.1 Các phương pháp áp dụng trong pha phân tích........................................7
1.2.2 Các phương pháp áp dụng trong pha biến đổi..........................................8
1.2.3 Các phương pháp trong pha tổng hợp kết quả..........................................9
1.3 Các phương pháp đánh giá .............................................................................9
1.3.1 Các phương pháp đánh giá trong..........................................................10
1.3.2 Các phương pháp đánh giá ngoài ..........................................................11
Chương 2 BÀI TOÁN TÓM TẮT VĂN BẢN TIẾNG VIỆT .............................. 12
2.1 Một số hướng tiếp cận bài toán tóm tắt văn bản ...........................................12
2.2 Đặc điểm tiếng Việt .....................................................................................13
2.2.1 Đặc điểm chung ....................................................................................13
2.2.2 Yếu tố ngoại lai trong từ tiếng Việt ......................................................14
2.2.3 Từ đồng nghĩa .......................................................................................14
2.2.4 Đặc điểm chính tả .................................................................................15
2.2.5 Bảng mã tiếng Việt trên máy tính..........................................................16
2.3 Phương pháp cho bài toán tóm tắt văn bản tiếng Việt...................................17

iv
Chương 3. ỨNG DỤNG PHƯƠNG PHÁP CẤU TRÚC ĐỂ TÓM TẮT VĂN BẢN TIẾNG VIỆT......................................................................................................... 20
3.1 Mô hình tóm tắt sử dụng phương pháp cấu trúc ...........................................20
3.2 Tiền xử lý văn bản .......................................................................................21
3.3 Xử lý từ .......................................................................................................22
3.4 Xây dựng đồ thị liên kết...............................................................................24
3.5 Sinh văn bản tóm tắt ....................................................................................28
Chương 4 THỰC NGHIỆM VÀ ĐÁNH GIÁ ........................................................ 33
4.1 Môi trường thử nghiệm................................................................................33
4.2 Dữ liệu thử nghiệm ......................................................................................33
4.3 Phương pháp đánh giá..................................................................................33
4.4 Kết quả thực nghiệm....................................................................................36
4.4.1 Thử nghiệm xác định ngưỡng................................................................36
4.4.2 Kết quả thử nghiệm đối với từng phiên bản...........................................37
KẾT LUẬN........................................................................................................... 42
TÀI LIỆU THAM KHẢO ..................................................................................... 44
PHỤ LỤC ............................................................................................................. 46

v
DANH MỤC CÁC KÝ HIỆU, CÁC CHỮ VIẾT TẮT
STT Ký hiệu, viết tắt Tên đầy đủ
1 IDF Inverse document frequency
Tần số tài liệu ngược
2 IR Information Retrieval
Tìm kiếm thông tin
3 TF Term frequency
Tần số từ

vi
DANH MỤC CÁC BẢNG
Bảng 1 Bậc của các nút sắp theo thứ tự giảm dần của văn bản Text(1).txt ............29
Bảng 2 Đánh giá sự liên quan của văn bản tóm tắt và văn bản GS ........................34
Bảng 3 Kết quả thử nghiệm với các ngưỡng khác nhau ........................................36
Bảng 4 Chất lượng của văn bản tóm tắt bởi Microsoft Word ................................37
Bảng 5 Kết quả thử nghiệm với phiên bản 1 .........................................................38
Bảng 6 Kết quả thử nghiệm với phiên bản 2 .........................................................38
Bảng 7 Kết quả thử nghiệm với phiên bản 3 .........................................................39
Bảng 8 So sánh kết quả các phiên bản và MS Word .............................................39
Bảng 9 So sánh các văn bản tóm tắt được thực hiện bởi 2 người...........................40

vii
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ
Hình 1 Kiến trúc của hệ thống tóm tắt văn bản tự động ..........................................6
Hình 2 Đồ thị liên kết các câu trong văn bản (gồm 11 câu, 30 liên kết trên 0,2)....19
Hình 3 Mô hình tóm tắt văn bản sử dụng phương pháp cấu trúc ...........................20
Hình 4 Đồ thị liên kết của văn bản Text(1).txt ......................................................27
Hình 5 Bản tóm tắt của Text(1).txt thực hiện bởi con người, tỉ lệ nén 10%...........35
Hình 6 Đồ thị kết quả tóm tắt với các ngưỡng.......................................................36
Hình 7 So sánh kết quả tóm tắt của các phiên bản và MS Word............................40

1
MỞ ĐẦU
Ngày nay, với sự phát triển như vũ bão của công nghệ thông tin, Internet cũng như các dịch vụ trực tuyến, ngày càng có nhiều thông tin được tạo ra. Ta có thể truy cập các thông tin đó qua sách, báo, Internet và các phương tiện truyền thông. Hơn nữa, nhu cầu đọc, tìm kiếm và lưu trữ thông tin của con người cũng ngày càng tăng lên. Tuy nhiên, với một lượng lớn thông tin như vậy thì người ta không thể nào có đủ thời gian và sức lực để đọc hết được chúng. Giải pháp là tóm tắt lại các văn bản đó, từ đó giúp tiết kiệm thời gian và công sức nhưng vẫn có thể đọc và xử lý được nhiều văn bản.
Tóm tắt văn bản tự động đã bắt đầu được nghiên cứu từ những năm 50 của thế kỉ trước. Đã có nhiều công trình nghiên cứu về lĩnh vực này và có được những kết quả đáng kể. Tóm tắt văn bản đã được sử dụng trong các phần mềm xử lý văn bản (Microsoft Office Word…), trong khai phá cơ sở dữ liệu văn bản (Oracle…), trong các ứng dụng tìm kiếm thông tin trực tuyến (hệ thống tìm kiếm Google, Yahoo…) và đều thu được những kết quả rất đáng khích lệ.
Tuy nhiên, đối với Tiếng Việt, do sự phức tạp của ngôn ngữ nên hiện chưa có nhiều công trình nghiên cứu về tóm tắt văn bản và kết quả của các công trình nghiên cứu về tóm tắt văn bản tiếng Việt còn hạn chế so với các ngôn ngữ khác mà đặc biệt là so với tiếng Anh.
Vì vậy, chúng tôi chọn đề tài: “Nghiên cứu các phương pháp xử lý tiếng Việt ứng dụng cho tóm tắt văn bản” nhằm nghiên cứu những vấn đề tổng quan về xử lý ngôn ngữ tự nhiên và một số phương pháp tóm tắt văn bản tiên tiến đã được ứng dụng và thu được kết quả khả quan đối với tiếng Anh; đồng thời nghiên cứu những đặc điểm của tiếng Việt nhằm cải tiến và ứng dụng những phương pháp đó để có thể xây dựng ứng dụng tóm tắt văn bản tiếng Việt.
Nội dung của luận văn được chia làm 4 chương:
Chương 1. Tổng quan về tóm tắt văn bản
Chương này trình bày những vấn đề tổng quan về bài toán tóm tắt văn bản, một số hướng tiếp cận hiện đại và các phương pháp đánh giá kết quả của văn bản tóm tắt.
Chương 2. Bài toán tóm tắt văn bản tiếng Việt
Chương này trình bày về bài toán tóm tắt văn bản tiếng Việt và một số khó khăn gặp phải do các đặc điểm của tiếng Việt (ngữ âm, ngữ pháp, chính tả…), và một số vấn đề về tiếng Việt trên máy tính (bảng mã, font chữ…), từ đó lựa chọn phương pháp phù hợp cho bài toán tóm tắt văn bản.

2
Chương 3. Ứng dụng phương pháp cấu trúc để tóm tắt văn bản tiếng Việt
Chương này trình bày về việc sử dụng phương pháp sử dụng cấu trúc văn bản kết hợp với từ điển từ dừng và từ điển đồng nghĩa để xây dựng chương trình tóm tắt văn bản tiếng Việt.
Chương 4. Thực nghiệm và đánh giá
Chương này trình bày về phương pháp được sử dụng để đánh giá hệ thống tóm tắt và các kết quả thực nghiệm.

3
Chương 1 TỔNG QUAN VỀ TÓM TẮT VĂN BẢN
1.1 Tổng quan
1.1.1 Khái niệm
Tóm tắt văn bản là một lĩnh vực của xử lý ngôn ngữ tự nhiên, đã được bắt đầu nghiên cứu từ những năm 50 của thế kỉ trước. Có nhiều định nghĩa về tóm tắt văn bản:
[19] định nghĩa tóm tắt văn bản là quá trình rút trích ra các thông tin quan trọng từ một hoặc nhiều văn bản để tạo ra văn bản ngắn gọn cho mỗi hoặc nhóm người dùng, cho từng tác vụ hay nhiều tác vụ khác nhau.
[21] định nghĩa hệ thống tóm tắt văn bản là hệ thống đưa ra dạng biểu diễn ngắn gọn của thông tin đầu vào căn cứ theo yêu cầu của người dùng.
Radev (2002) [22] định nghĩa văn bản tóm tắt là văn bản được tạo từ một hoặc nhiều văn bản khác mà truyền tải được những thông tin quan trọng trong văn bản gốc nhưng có độ dài không quá ½ văn bản gốc (thường ngắn hơn đáng kể).
Theo Partha Lal (2002) [16] thì tóm tắt văn bản là việc thể hiện nội dung văn bản dưới dạng giản lược một cách tự động nhằm đáp ứng yêu cầu nào đó từ phía người dùng.
Đỗ Phúc, Hoàng Kiếm (2006) [5] định nghĩa tóm tắt văn bản tự động là việc tìm các ý chính của văn bản.
Tựu chung lại, có ba đặc điểm quan trọng cần phải xem xét trong hệ thống tóm tắt văn bản:
1) Bản tóm tắt có thể được tạo ra từ một hoặc nhiều văn bản.
2) Bản tóm tắt cần truyền tải các thông tin quan trọng.
3) Bản tóm tắt cần phải ngắn.
1.1.2 Lịch sử phát triển của tóm tắt văn bản
Tóm tắt văn bản bắt đầu từ những năm cuối thập kỉ 1950 với nghiên cứu của Luhn (1958) [17] dựa trên tần số từ. Ý tưởng cơ bản của phương pháp tần số từ dựa trên kiến thức cho rằng tần số của từng từ trong văn bản là một độ đo hữu dụng để đánh giá tầm quan trọng của chúng.
Tiếp theo đó là phương pháp tóm tắt dựa trên vị trí của các câu trong văn bản của Baxendale (1958), và những nghiên cứu của Edmundson (1969) [14] về vị trí của các câu trong văn bản và các từ/cụm từ mang ý nghĩa tổng quát (từ/cụm từ dấu hiệu). Theo đó, những câu bắt đầu và kết thúc của đoạn văn/bài viết hay những câu

4
chứa những từ như “important” (đặc biệt), “result are” (kết quả là), “paper introduce” (bài báo giới thiệu về)… là những câu có ý nghĩa quan trọng.
Đầu những năm 1970, tiếp tục có những nghiên cứu với hướng tiếp cận ngoài (sử dụng các cụm từ dấu hiệu) và được ứng dụng trong các phần mềm thương mại (Pollock và Zamora).
Những năm 1980, phát triển nhiều nghiên cứu với nhiều hướng khác nhau, đặc biệt là hướng tiếp cận mức thực thể dựa trên trí tuệ nhân tạo như sử dụng script (Lehnert 1981), (DeJong 1982), các luật sản xuất và logic (Fum 1985), mạng ngữ nghĩa (Reimer và Hahn 1988), cũng như các hướng tiếp cận kết hợp (Rau 1989) hay (Aretoulaki 1994).
Willam B. Cavnar (1994): biểu diễn văn bản dựa trên n-gram thay cho cách biểu diễn truyền thống bằng từ khoá.
Chinatsu Anoe (1997) đã phát triển hệ DimSum để tóm tắt văn bản sử dụng xử lý ngôn ngữ tự nhiên và kĩ thuật thống kê dựa trên hệ thống tf-idf, sử dụng WordNet để xem xét ngữ nghĩa của từ và đề xuất một số kĩ thuật lượng giá.
Jaine Carbonell (1998) đã tóm tắt văn bản bằng cách xếp hạng các câu trội (câu chứa các ý chính của văn bản) và rút ra các câu trội.
Jade Goldstein (1999): phân loại tóm tắt dựa trên độ đo liên quan, phương pháp sử dụng kết hợp giữa ngữ học, thống kê. Mỗi câu được đặc trưng bằng các đặc tính ngữ học và độ đo thống kê.
J.Larocca Neto (2000) đã tạo tóm tắt văn bản dựa trên các dãy từ trong câu được chọn theo hệ số tf, sau đó dùng kỹ thuật gom cụm (clustering) để tạo tóm tắt.
Yoshio (2001) đã tạo tóm tắt văn bản tiếng Nhật. Có 2 phương pháp là rút câu dựa trên từ khoá và rút câu dựa trên kiến trúc ngữ nghĩa trong đó có xây dựng độ đo mối liên kết giữa hai từ.
Hiện nay, một số nghiên cứu về xử lý ngôn ngữ tự nhiên cũng bước đầu được áp dụng trong tóm tắt văn bản. Mặt khác, các nghiên cứu về tóm tắt đa văn bản, đa ngôn ngữ và tóm tắt đa phương tiện cũng bắt đầu phát triển.
1.1.3 Phân loại các phương pháp tóm tắt văn bản
Có nhiều tiêu chí để phân loại các phương pháp tóm tắt văn bản, sau đây là một số cách phân loại tiêu biểu [15]:
Căn cứ vào dạng tóm tắt, ta có thể chia thành:
- Trích xuất (extract): bản tóm tắt hoàn toàn chứa các “dãy từ” được sao chép nguyên dạng từ văn bản nguồn. “Dãy từ” ở đây có thể là cụm từ, câu hoặc đoạn văn. Tuy nhiên, với dạng trích xuất thì văn bản tóm tắt thiếu cấu kết cần thiết, các câu

5
được trích ra có thể không phản ánh nội dung. Nói chung văn bản tóm tắt không được “trơn” do được “lắp ghép” từ các câu, đoạn văn được trích ra.
- Tóm tắt (abstracts): văn bản tóm tắt nói chung là không chứa các “dãy từ” trong văn bản nguồn mà là được “viết lại” một cách tự động. Với dạng này, người ta cần nhiều kĩ thuật xử lý ngôn ngữ. Hiện tại, đây vẫn là vấn đề khó, chưa thể giải quyết được một cách triệt để.
Căn cứ vào mức độ xử lý, có thể chia thành 2 dạng:
- Tiếp cận mức ngoài (surface-level): thông tin được miêu tả dưới dạng khái niệm về các đặc trưng nông (shallow feature). Các đặc trưng nông bao gồm các thuật ngữ (term) quan trọng qua thống kê (dựa vào tần số của các thuật ngữ trong văn bản), các thuật ngữ quan trọng dựa vào vị trí, các thuật ngữ trong các cụm từ dấu hiệu hay các thuật ngữ trong câu truy vấn của người dùng. Kết quả là một bản tóm tắt dạng trích xuất (extract).
- Tiếp cận mức sâu (deeper-level): ở mức này, bản tóm tắt có thể là dạng trích xuất hoặc dạng tóm tắt (abstract) và cần phải sử dụng đến sinh tổng hợp ngôn ngữ tự nhiên. Với dạng tiếp cận này, phải cần đến những phân tích về mặt ngữ nghĩa, chẳng hạn sử dụng hướng tiếp cận thực thể để xây dựng dạng biểu diễn của các thực thể văn bản (đơn vị văn bản) và mối quan hệ giữa các thực thể rồi từ đó tìm ra phần quan trọng. Mối quan hệ giữa các thực thể gồm quan hệ ngữ nghĩa như: đồng nghĩa, trái nghĩa, nghĩa hẹp, nghĩa rộng…, quan hệ cú pháp: dựa trên cây phân tích cú pháp và các mối quan hệ khác.
Căn cứ vào mục đích của bản tóm tắt, có thể chia làm 3 dạng:
- Trình bày sơ lược (indicative): Đưa ra những thông tin ngắn gọn về chủ đề chính của văn bản. Dạng tóm tắt này thường được sử dụng trong các hệ thống tìm kiếm thông tin. Thông thường, độ dài của văn bản tóm tắt loại này chỉ từ 5 đến 10% độ dài của toàn bộ văn bản.
- Tóm tắt cung cấp tin tức (Informative): Cung cấp các chủ đề con của toàn bộ văn bản, kiểu tóm tắt này có độ dài từ 20-30% văn bản gốc.
- Phê bình và đánh giá: Văn bản tóm tắt đưa ra những quan điểm của người tóm tắt về chủ đề được đưa ra. Tuy nhiên, kiểu tóm tắt này dường như vượt quá tầm của các hệ thống tóm tắt tự động hiện nay.
Việc phân loại tóm tắt dựa theo mục đích như trên không loại trừ lẫn nhau, có thể một bản tóm tắt vừa có chức năng cung cấp tin tức lại vừa là kiểu trình bày sơ lược.
Căn cứ vào người sử dụng, có thể chia thành các dạng:

6
- Tóm tắt chung: với kiểu tóm tắt này thì mọi chủ đề chính trong văn bản đều có tầm quan trọng như nhau, văn bản tóm tắt hướng đến một cộng đồng đông đảo người đọc.
- Tóm tắt dựa trên câu truy vấn: kết quả trả về dựa trên câu truy vấn của người dùng.
- Tóm tắt hướng đến người dùng hoặc chủ đề: văn bản tóm tắt đáp ứng nhu cầu của người dùng cụ thể hoặc chủ đề cụ thể nào đó.
Căn cứ vào số lượng văn bản tóm tắt: Tóm tắt đơn văn bản: thực hiện tóm tắt trên một văn bản hoặc tóm tắt đa văn bản: thực hiện tóm tắt trên nhiều văn bản khác nhau.
Căn cứ vào ngôn ngữ tóm tắt: Tóm tắt trên một ngôn ngữ hoặc tóm tắt trên nhiều ngôn ngữ khác nhau.
1.2 Mô hình tóm tắt văn bản
Hình 1 Kiến trúc của hệ thống tóm tắt văn bản tự động
Đầu vào của hệ thống có thể là một hoặc nhiều tài liệu, văn bản hay các thông tin đa phương tiện như ảnh, âm thanh, video. Hệ thống tóm tắt hiện nay thường tập trung vào việc xử lý đầu là văn bản (có thể mở rộng cho các thông tin dạng khác). Điều quan trọng trong việc tóm tắt văn bản là mức độ nén, tức là tỉ lệ giữa độ dài của văn bản tóm tắt so với văn bản gốc (đôi khi cũng được tính bằng phần bù của tỉ số này). Thông thường, tỉ lệ nén được tính dựa trên độ dài của văn bản, hoặc có thể tính bằng nội dung thông tin. Tỉ lệ nén dao động từ 1% đến 30%, nếu tỉ lệ nén giảm thì thông tin sẽ bị mất nhiều hơn. Văn bản tóm tắt có thể là văn bản liền mạch hoặc văn bản rời rạc. Quá trình tóm tắt có thể chia thành 3 pha: phân tích văn bản đầu vào, biến đổi, tổng hợp chỉnh sửa cho phù hợp với yêu cầu đầu ra.
Phân
tích
Tài liệu
Biế
n đổ
i
Tổng
hợp
kết
quả
Văn bản tóm tắt

7
1.2.1 Các phương pháp áp dụng trong pha phân tích
Trong pha này, văn bản nguồn được phân tích để xác định các đơn vị ngữ liệu và các đặc trưng của chúng, kết quả của pha này là đầu vào cho pha biến đổi. Các phương pháp áp dụng trong pha này bao gồm:
a)Phương pháp thống kê
Các phương pháp thuộc loại này sử dụng các số liệu thống kê về độ quan trọng của các từ, cụm từ, câu hoặc đoạn văn. Các phương pháp thống kê gồm:
- Dựa vào vị trí:
+ Chủ đề, tiêu đề: tiêu đề hay chủ đề của các đoạn văn thường chứa các từ và ngữ quan trọng.
+ Câu ở đầu hoặc cuối đoạn: xác suất câu đầu đoạn hay câu cuối đoạn chứa ý chính của cả đoạn là rất lớn, đặc biệt là câu đầu đoạn. Ngoài ra các đoạn đầu và cuối văn bản cũng quan trọng hơn các đoạn giữa.
+ Minh hoạ, chú thích: trong các câu chú thích, câu minh hoạ cho ảnh hay đồ thị thường chứa các thông tin quan trọng.
- Dựa vào cụm từ dấu hiệu: Các cụm từ dấu hiệu có đặc điểm thống kê rất tốt. Sau các cụm từ này thường là các từ hay câu quan trọng. Có hai loại cụm từ dấu hiệu : thứ nhất là các cụm từ mang ý nhấn mạnh, sau cụm từ này đoạn văn quan trọng; chẳng hạn “nói chung là”, “đặc biệt là”, “tóm lại”, “cuối cùng thì”, “trong bài viết này tôi muốn chỉ ra”, “bài viết nói về”, “nội dung gồm”... Thứ hai là các cụm từ không quan trọng, sau cụm từ này là các thành phần không có nhiều giá trị trong việc tóm tắt, chẳng hạn: “hiếm khi mà”, “bài này không nói đến”, “không thể nào…”
- Dựa vào thống kê tần suất từ: Độ quan trọng của từ phụ thuộc vào số lần xuất hiện của từ đó trong văn bản. Có thể dùng các kĩ thuật như tf-idf, tập thuật ngữ thường xuyên (frequent item set) để xác định tần suất từ.
b) Phương pháp cấu trúc
Các phương pháp này sử dụng các mối liên hệ cấu trúc - ngữ pháp - ngữ nghĩa để xác định các đơn vị ngữ liệu quan trọng. Tư tưởng chính của các phương pháp này là những đơn vị ngữ liệu nào có chứa các thành phần liên quan nhiều với các thành phần khác sẽ có mức độ quan trọng cao. Việc đánh giá các mối quan hệ sẽ dựa trên các mạng ngữ nghĩa hoặc các quan hệ cú pháp.
- Phương pháp sử dụng quan hệ giữa câu, đoạn
Phương pháp này xác định mối quan hệ giữa các đoạn trong văn bản hay các câu trong đoạn với nhau thông qua việc tính toán mức độ liên quan giữa chúng. Các

8
độ Cosine, Jaccard… được chọn để xác định độ tương đồng giữa các câu hay đoạn văn bản đó. Sau đó, ta chọn ra đoạn hay câu có độ liên quan lớn nhất.
+ Phương pháp chuỗi từ vựng (lexical chains)
Phương pháp liên kết từ vựng sử dụng các từ điển quan hệ từ vựng để xây dựng các chuỗi từ liên kết với nhau về mặt ngữ nghĩa. Sau khi xây dựng được chuỗi các từ vựng này, ta đánh giá độ mạnh của chúng và chọn ra những câu phù hợp. Morris và Hirst (1991) là những người đưa ra mô hình tính chuỗi từ vựng đầu tiên. Chuỗi từ vựng không những chỉ dùng trong tóm tắt văn bản mà còn được coi là lý thuyết tổng quát của vấn đề ngữ nghĩa trong xử lý ngôn ngữ tự nhiên
+ Phương pháp liên kết tham chiếu (word coreferences)
Phương pháp này gọi là phương pháp trích chọn trùng lặp (anaphora-based method). Theo phương pháp này, các cụm trùng lặp được chọn ra, phân rã xem đâu là từ (cụm từ) tham chiếu và từ (cụm từ) được tham chiếu. Sau khi phân tách các cụm trùng lặp, chúng ta tạo chuỗi các từ (cụm từ) tham chiếu đến cùng một từ được tham chiếu. Chuỗi dài nhất sẽ được coi là trọng tâm của đoạn, các câu chứa các từ trong chuỗi này có một độ ưu tiên nào đó thì sẽ được chọn.
Kết thúc pha phân tích sẽ là việc tổng hợp các chỉ số đánh giá độ quan trọng của các đơn vị ngữ liệu và thực hiện việc chọn các đơn vị ngữ liệu nào có độ quan trọng lớn làm đầu vào cho pha sau. Có thể nhận thấy các phương pháp thống kê dễ cài đặt hơn các phương pháp cấu trúc. Việc cài đặt các phương pháp thống kê đơn thuần chỉ là các công thức toán học, còn để cài đặt các phương pháp cấu trúc thì lại cần thực hiện rất nhiều kĩ thuật về cấu trúc dữ liệu và thậm chí là các kĩ thuật trong lĩnh vực trí tuệ nhân tạo.
1.2.2 Các phương pháp áp dụng trong pha biến đổi
Pha biến đổi có nhiệm vụ biến đổi đơn vị ngữ liệu được trích xuất trong pha phân tích như cụm từ, câu, đoạn văn. Thông thường pha biến đổi thực hiện rút gọn bản thân bên trong một câu, rồi có thể rút gọn đoạn mà không gây ảnh hưởng đến độ chính xác. Các phương pháp trong pha biến đổi gồm: [7].
a) Giản lược về cấu trúc câu
Lược bỏ các thành phần thừa, ít mang ý nghĩa trong câu, giúp cấu trúc câu được thu gọn lại. Công việc này thường dựa trên phân tích cú pháp và phân tích ngữ nghĩa các thành phần trong câu. Áp dụng phân tích cú pháp chúng ta được các cấu trúc của câu, qua đó ta có thể thay thế thành phần bằng những thành phần tương đương, ghép thành phần có nghĩa tương đương theo một luật nào đó. Phương pháp này có thể làm câu ngắn gọn hơn, tuy nhiên khó bảo toàn được văn phong.
b) Giản lược về mặt ngữ nghĩa

9
Thay thế hoặc loại bỏ các từ, cụm từ có ý nghĩa cụ thể bằng những từ, cụm từ ý nghĩa lúc này sẽ tổng quát, điển hình là:
- Trừu trượng hoá khái niệm: thay thế các khái niệm cụ thể bằng khái niệm chung.
- Thay thế ngữ tương đương: thay thế các ngữ đóng vai trò như nhau trong câu bằng một ngữ chung.
1.2.3 Các phương pháp trong pha tổng hợp kết quả
a) Phương pháp hiển thị phân đoạn
Các đơn vị ngữ liệu được trích xuất hay giản lược từ các pha trước được liên kết lại thành đoạn theo đúng thứ tự trong văn bản gốc, không thêm bớt từ nối và cũng không sắp xếp lại. Văn bản kết quả của phương pháp này có độ dễ đọc và dễ hiểu kém, thậm chí lủng củng vì các đơn vị ngữ liệu có thể bị mập mờ tham chiếu, không có từ nối hoặc thừa từ.
b) Phương pháp hiển thị liên kết
Với phương pháp này, ta sẽ đưa thêm các thông tin bổ sung vào văn bản tóm tắt. Hai phương pháp thường được áp dụng trong sử dụng mẫu (template) ngữ liệu huấn luyện (corpus).
1.3 Các phương pháp đánh giá Đánh giá một bản tóm tắt là một công việc khó bởi không tồn tại một bản tóm
tắt lý tưởng cho một (hoặc một tập) văn bản đưa ra [11]. Hơn nữa, việc đánh giá nội dung tóm tắt cũng rất khó khăn. Trường hợp kết quả là một câu trả lời cho một câu hỏi, ta có thể xác định được câu trả lời đó đúng hay sai, nhưng trong các trường hợp khác, thật khó trả lời liệu đầu ra là phải một kết quả đúng hay không? Thực tế luôn có khả năng một hệ thống sinh ra một bản tóm tắt tốt nhưng lại sai khác với bản tóm tắt do người thực hiện. Bên cạnh đó, khi việc đánh giá được thực hiện bởi con người thì chi phí đánh giá sẽ rất cao. Mặt khác, tóm tắt văn bản còn liên quan đến tỉ lệ nén văn bản, do đó, việc đánh giá bản tóm tắt cần phải quan tâm đến vấn đề này, khi đó độ phức tạp và chi phí đánh giá sẽ tăng cao [18]. Có nhiều kiểu đánh giá khác nhau tuỳ thuộc vào kiểu tóm tắt của hệ thống. Có thể là đánh giá trong (intrinsic) – tập trung vào chất lượng bản tóm tắt và đánh giá ngoài (extrinsic) – tập trung vào nhiệm vụ (McKeown 1998).
Các tiêu chí đánh giá:
- Độ mạch lạc (Coherence): đánh giá mức độ rõ ràng của văn bản tóm tắt, tính súc tích, khả năng có thể đọc và hiểu được của bài viết…

10
- Độ hàm chứa thông tin (Informationess): tỉ lệ thông tin của văn bản gốc trong văn bản tóm tắt.
- Độ liên quan (Relevance): xác định mức độ phù hợp của văn bản tóm tắt với chủ đề cho trước (chủ đề có thể là một câu truy vấn).
- Độ dễ đọc hiểu (Reading Comprehence): một người được giao việc đọc văn bản kết quả, sau đó trả lời các câu hỏi, hệ thống sẽ phải cho điểm và từ đó đưa ra phần trăm những câu trả lời đúng.
1.3.1 Các phương pháp đánh giá trong
a) So sánh với văn bản tóm tắt khác
Ý tưởng cơ bản của phương pháp này là đem văn bản do hệ thống tóm tắt so sánh với các bản tóm tắt khác (có thể do hệ thống tóm tắt khác thực hiện hoặc do con người thực hiện). Thông thường là đem so sánh với văn bản tóm tắt do con người thực hiện. Việc so sánh giữa các bản tóm tắt này có thể do con người thực hiện hoặc có thể thực hiện tự động. Khi so sánh, có thể sử dụng một số độ đo sau [18]:
- Độ chính xác (Precision) và độ bao phủ (Recall). Tuy nhiên, 2 độ đo này chưa đủ để phân biệt các bản tóm tắt, các bản tóm tắt khác nội dung nhưng vẫn có cùng độ đo.
- Độ đo hạng câu (Sentence Rank): thay thế cho độ bao phủ, khi đó, một bản tóm tắt được đặc trưng bởi hạng của các câu trong các bản tóm tắt thích hợp. Hạng của các câu trong bản tóm tắt do hệ thống thực hiện và trong các bản tóm tắt dùng để so sánh có thể tính bằng độ đo tương quan. Độ do này áp dụng đối với hệ thống tóm tắt dạng trích xuất.
- Độ đo dựa trên nội dung (Content-Based): dựa trên sự tương tự về mặt từ vựng, và có thể áp dụng đối với cả 2 dạng tóm tắt. Tuy nhiên, độ đo này hữu dụng với các bản tóm tắt trích xuất, hoặc với các bản tóm tắt dạng abstract nhưng có mức độ cắt-dán cao (tức là văn bản tóm tắt được tạo bởi nhiều từ, cụm từ, câu nguyên dạng trong văn bản nguồn).
b) So sánh với văn bản nguồn
Với phương pháp này, ta đem so sánh văn bản tóm tắt với văn bản nguồn để xác định mức độ hàm chứa thông tin của văn bản tóm tắt [18]. Các độ đo dựa trên nội dung như trên có thể sử dụng để đánh giá. Paice và Jones (1993) đã đưa ra phương pháp sử dụng thống kê để xác định mỗi thuật ngữ có phải là thuật ngữ trung tâm hay không phải thuật ngữ trung tâm. Tiếp đó, phân loại vào các nhóm Chính xác (Correct), không chính xác (Incorrect) và thiếu (Missing).

11
Hệ thống tóm tắt TIPSTER SUMMAC đánh giá các bản tóm tắt dạng Q&A (Question and Answer – Hỏi và trả lời) (Mani, Firmin, House, Chrzanowski, Klein, Hirschman, Sundhem, Obrst (1998). Hệ thống này thay vì biểu diễn các khái niệm ở mức sâu thì chỉ xác định xem trong văn bản tóm tắt có hay không những khái niệm then chốt trong văn bản nguồn. Theo phương pháp tóm tắt này thì ta đưa vào một văn bản nguồn và một chủ đề, rồi thực hiện tóm tắt dựa trên chủ đề đó để trả lời cho câu hỏi. Khi đó, ta có thể xác định xem câu trả lời có Chính xác (chứa câu trả lời đúng), hoặc Đúng một phần (chứa một phần câu trả lời) hay Thiếu (không chứa câu trả lời).
1.3.2 Các phương pháp đánh giá ngoài
Ý tưởng cơ bản của các phương pháp đánh giá ngoài là đánh giá tác dụng của bản tóm tắt với các nhiệm vụ khác nhau [18].
- Đánh giá mức độ liên quan (relevance): ý tưởng của phương pháp này là đưa ra một văn bản và một chủ đề, đánh giá xem mức độ liên quan của văn bản với chủ đề đó.
- Đánh giá mức độ đọc hiểu: trước tiên, một người được đọc các văn bản tóm tắt từ một hoặc nhiều văn bản, sau đó trả lời các câu hỏi kiểm tra. Hệ thống tự động tính điểm các câu trả lời và đánh giá tỉ lệ trả lời đúng. Nếu bản tóm tắt cho phép trả lời các câu hỏi giống như khi đọc toàn bộ văn bản nguồn thì bản tóm tắt đó có khả năng cung cấp thông tin cao.
Hovey và Marcu (1998) thực hiện đo mức độ cung cấp thông tin dựa trên việc người ta có thể khôi phục lại các thông tin quan trọng trong văn bản khi đọc bản tóm tắt của văn bản đó. Bằng thực nghiệm, tác giả tiến hành dựng lại văn bản gốc dựa trên việc đọc văn bản tóm tắt kết hợp phỏng đoán.

12
Chương 2 BÀI TOÁN TÓM TẮT VĂN BẢN TIẾNG VIỆT
Chương này trình bày về một số hướng tiếp cận bài toán tóm tắt văn bản tiếng Việt. Đồng thời cũng đưa ra những đặc trưng quan trọng cần chú ý của tiếng Việt dưới góc độ của lĩnh vực xử lý ngôn ngữ tự nhiên, từ đó lựa chọn phương pháp cho bài toán tóm tắt văn bản tiếng Việt.
2.1 Một số hướng tiếp cận bài toán tóm tắt văn bản Tại Việt Nam hiện nay, lĩnh vực xử lý ngôn ngữ tự nhiên đã có được thành
tích trong các bài toán phân tách từ, phân lớp và phân nhóm văn bản. Tuy nhiên bài toán tóm tắt văn bản chưa có nhiều nghiên cứu và đa phần các công trình nghiên cứu đều sử dụng hoặc cải tiến các phương pháp dựa trên thống kê, cũng có một số nghiên cứu có dựa trên ngữ nghĩa để nâng cao độ chính xác.
Có thể kể đến một số công trình nghiên cứu như:
Đỗ Phúc, Hoàng Kiếm (2006) [5] đã sử dụng cây hậu tố để phát hiện các dãy từ phổ biến trong các câu của văn bản, dùng từ điển đồng nghĩa và WordNet tiếng Việt để giải quyết vấn đề nghĩa của từ, rồi dùng kĩ thuật gom cụm để gom các câu trong văn bản (vector đặc trưng cho câu) và hình thành các vector đặc trưng cụm, sau đó rút ra câu chứa nhiều thành phần của các vector đặc trưng cụm.
Vương Toàn (2007) [8] đã đề xuất quy trình tóm tắt văn bản khoa học. Theo đó, đầu tiên cho máy đọc lướt văn bản và tìm xem có sẵn những đoạn văn mang tính chất “tóm tắt” hay không; tiếp theo là định chủ đề, xác định 4-5 tiêu đề đề mục hoặc từ khoá để máy tự động chọn lưu tất cả những câu có các từ khoá đó.
Công trình nghiên cứu của Nguyễn Trọng Phúc, Lê Thanh Hương (2008) [6] lại sử dụng cấu trúc diễn ngôn để tóm tắt văn bản. Theo đó, xây dựng cây cấu trúc diễn ngôn biểu diễn mỗi quan hệ diễn ngôn giữa các đoạn văn bản (như các quan hệ nhân-quả, liệt kê, diễn giải,…), rồi từ cây cấu trúc diễn ngôn này đánh giá được độ quan trọng của các đoạn văn bản và tiến hành trích xuất tạo ra tóm tắt nội dung cho văn bản.
Với hướng tiếp cận tóm tắt đa văn bản dựa vào trích xuất câu, Trần Mai Vũ (2009) [9] đã xây dựng đồ thị quan hệ thực thể để tăng cường tính ngữ nghĩa cho độ tương đồng câu để áp dụng cho tóm tắt đa văn bản tiếng Việt.
Nguyễn Việt Cường (2007) [2] đã sử dụng phương pháp phân đoạn văn bản dựa trên chuỗi từ vựng kết hợp với phương pháp sinh tiêu đề dựa trên chủ đề của câu chủ đề nhằm thực hiện sinh tự động mục lục cho văn bản.

13
2.2 Đặc điểm tiếng Việt
2.2.1 Đặc điểm chung
Tiếng Việt là ngôn ngữ không biến hình từ và âm tiết tính tức là mỗi một tiếng (âm tiết) được phát âm tách rời nhau và được thể hiện bằng một chữ viết [1]. Hai đặc trưng này chi phối toàn bộ tổ chức bên trong của hệ thống ngôn ngữ Việt và cần được chú ý khi xử lý tiếng Việt trên máy tính.
Tiếng [1] là đơn vị cơ sở của cấu tạo ngữ pháp Việt Nam. Tiếng có thể có nghĩa, phai nghĩa và không có nghĩa; hơn nữa giữa 3 hiện tượng này có thể xuất hiện sự chuyển hoá lẫn nhau. Tiếng tham gia vào hệ thống ngôn ngữ với tư cách một thành tố trong các cơ chế cấu tạo từ (từ đơn, từ láy, từ ghép…). Theo Từ điển tiếng Việt – Hoàng Phê (1998) thì tiếng Việt hiện đại sử dụng 6718 âm tiết.
Hiện nay, có nhiều tranh luận khi định nghĩa từ trong tiếng Việt. Theo Ngữ pháp tiếng Việt [1] thì xét ở phương diện ngữ pháp có thể định nghĩa từ là đơn vị nhỏ nhất mà có nghĩa và có thể hoạt động tự do (trong câu), từ là đơn vị trung tâm của ngữ pháp Việt Nam, chi phối toàn bộ cú pháp tiếng Việt, đảm nhận và san sẻ các chức năng năng cú pháp trong câu và góp phần đưa câu vào các cấu tạo ngôn ngữ lớn hơn câu. Từ đây trở đi, khái niệm từ được dùng với nghĩa trên khi nói về tiếng Việt, còn đối với các ngôn ngữ châu Âu (ví dụ tiếng Anh), từ (word) vẫn được hiểu theo nghĩa là “cụm kí tự được ngăn cách bởi một hoặc nhiều dấu cách”.
Cụm từ là những kiến trúc gồm hai từ trở lên kết hợp “tự do” với nhau theo những quan hệ ngữ pháp hiển hiện nhất định và không chứa kết từ ở đầu. Cụm từ hoạt động trong câu mới mọi chức vụ ngữ pháp nhất định.
Câu là sự tổng hợp của các từ biểu thị một tư tưởng trọn vẹn.
Ví dụ:
Từ ‘học’ là một từ gồm một tiếng
Từ ‘đại học’ là một từ gồm hai tiếng
Cụm từ ‘khoa học máy tính’ gồm 2 từ hay 4 tiếng
Trong các hệ thống xử lý ngôn ngữ trên các tiếng châu Âu, để xác định các từ đặc trưng cho văn bản người ta có thể đơn giản lấy khoảng trắng làm ranh giới phân tách từ. Đối với tiếng Việt thì ta lại không thể làm tương tự bởi nếu ta chỉ dựa vào khoảng trắng để phân tách thì kết quả ta chỉ có được các “tiếng” vô nghĩa và do đó độ chính xác của hệ thống có thể sẽ rất thấp. Theo Ngữ pháp tiếng Việt - Nguyễn Hữu Quỳnh (2001) thì tiếng Việt có đến 80% là các từ 2 tiếng.
Từ tiếng Việt không có hiện tượng biến hình (ngôn ngữ đơn lập) bằng những phụ tố mang ý nghĩa ngữ pháp bên trong từ như các ngôn ngữ Ấn – Âu. Dĩ nhiên,

14
tiếng Việt cũng có một số hình thức biến hình như trường hợp thêm tiếng “sự trước một động từ để biến nó thành danh từ tương đương, ví dụ như động từ “lựa chọn” và danh từ “sự lựa chọn” hay thêm tiếng “hoá” sau một danh từ để biến nó thành động từ tương đương như danh từ “tin học” và động từ “tin học hoá”. Phụ tố cấu tạo từ tồn tại hiển nhiên hơn ở cơ chế láy với những quy tắc ngữ âm khái quát chứ không hẳn là những dạng thức cụ thể đồng loạt (ở những từ láy có phần gốc là yếu tố còn rõ nghĩa, phần láy là yếu tố không rõ nghĩa).
2.2.2 Yếu tố ngoại lai trong từ tiếng Việt
Tiếng Việt có các yếu tố ngoại lai thuộc gốc Hán, gốc Pháp, Anh trong đó yếu tố Hán vừa chiếm đa số vừa giữ vai trò khá quan trọng trong vốn từ và trong cấu tạo từ Việt.
Các yếu tố gốc Ấn – Âu đi vào tiếng Việt phải chịu áp lực rất mạnh của sự âm tiết hoá theo kiểu tiếng Việt. Sự Việt hoá về mặt âm tiết:
− Cắt từ nhiều âm tiết thành những âm tiết rời;
− Âm tiết hoá các tổ hợp phụ âm;
− Mỗi âm tiết nhận một thanh điệu thích hợp;
− Cấu tạo lại âm tiết theo các âm của tiếng Việt (như không chấp nhận l, h, s… ở cuối âm tiết).
Ngoài ra, khi Việt hoá các từ ngoại lai Ấn – Âu có sự đơn tố hoá từ nhiều hình vị (từ tố), tức là một số từ vốn là đa tố ở ngôn ngữ Ấn – Âu vào tiếng Việt được coi như từ đơn tố, ví dụ: sulơ, xuyết vôn tơ, mát xa…; và có sự giản hoá về phát âm như sứ (đại sứ quán), lốp (vỏ bánh xe) từ enveloppe…
2.2.3 Từ đồng nghĩa
Theo Cơ sở ngôn ngữ học và tiếng Việt - Mai Ngọc Chừ (1997) từ đồng nghĩa là những từ tương đồng với nhau về nghĩa, khác nhau về âm thanh và có phân biệt với nhau về một vài sắc thái ngữ nghĩa hoặc sắc thái phong cách,... nào đó, hoặc đồng thời cả hai. Những từ đồng nghĩa với nhau tập hợp thành một nhóm gọi là nhóm đồng nghĩa.
Ví dụ: dễ, dễ dàng, dễ dãi là những nhóm từ đồng nghĩa.
Thực ra, từ đồng nghĩa không phải là những từ trùng nhau hoàn toàn về nghĩa. Chúng nhất định có những dị biệt nào đó bên cạnh sự tương đồng (mặc dù phát hiện sự dị biệt đó không phải lúc nào cũng dễ dàng).
Những từ đồng nghĩa với nhau không nhất thiết phải tương đương với nhau về số lượng nghĩa, tức là các từ trong một nhóm đồng nghĩa không nhất thiết phải có dung lượng nghĩa bằng nhau: Từ này có thể có một hoặc hai nghĩa, nhưng từ kia có

15
thể có tới dăm bảy nghĩa. Thông thường, các từ chỉ đồng nghĩa ở một nghĩa nào đó. Chính vì thế nên một từ đa nghĩa có thể tham gia vào nhiều nhóm đồng nghĩa khác nhau: Ở nhóm này nó tham gia với nghĩa này, ở nhóm khác nó tham gia với nghĩa khác.
Ví dụ: Từ “coi” trong tiếng Việt là một từ đa nghĩa. Tuỳ theo từng nghĩa được nêu lên để tập hợp các từ, mà “coi” có thể tham gia vào các nhóm như:
+ coi – xem: coi hát – xem hát
+ coi – giữ: coi nhà – giữ nhà
Trong mỗi nhóm từ đồng nghĩa thường có một từ mang nghĩa chung, được dùng phổ biến và trung hoà về mặt phong cách, được lấy làm cơ sở để tập hợp và so sánh, phân tích các từ khác. Từ đó gọi là từ trung tâm của nhóm.
Ví dụ: Trong nhóm từ “yếu, yếu đuối, yếu ớt”, từ “yếu” được gọi là từ trung tâm.
Tuy nhiên, việc xác định từ trung tâm của nhóm không phải lúc nào cũng dễ và đối với nhóm nào cũng làm được. Nhiều khi ta không thể xác định một cách dứt khoát được theo những tiêu chí vừa nêu trên, mà phải dựa vào những tiêu chí phụ như: tần số xuất hiện cao (hay được sử dụng) hoặc khả năng kết hợp rộng.
Chẳng hạn, trong các nhóm từ đồng nghĩa tiếng Việt như: hồi, thuở, thời; hoặc chờ, đợi; hoặc chỗ, nơi, chốn,... rất khó xác định từ nào là trung tâm.
Với bài toán tóm tắt văn bản thì từ đồng nghĩa cũng có một ý nghĩa khá quan trọng bởi trong các câu, đoạn văn trong văn bản có các từ đồng nghĩa hoặc gần nghĩa nhau và việc sử dụng từ đồng nghĩa sẽ làm nâng cao tính chính xác khi so sánh về độ tương đồng ngữ nghĩa giữa các đơn vị văn bản.
2.2.4 Đặc điểm chính tả
Đặc điểm chính tả tiếng Việt có ý nghĩa quan trọng tiền xử lý dữ liệu văn bản. Một số đặc điểm chính tả tiếng Việt cần quan tâm như [7]:
− Các tiếng đồng âm: như kĩ/kỹ, lí, lý… thường bị sử dụng lẫn nhau như: lý luận, lí luận, kĩ thuật, kỹ thuật…
− Các từ địa phương: một số từ địa phương sử dụng thay cho các từ phổ thông, chẳng hạn: cây kiểng/cây cảnh, đờn/đàn, đậu phộng/lạc…
− Vị trí dấu thanh: theo quy định đánh dấu tiếng Việt, dấu được đặt trên nguyên âm có ưu tiên cao nhất. Tuy nhiên, khi viết văn bản nhiều bộ gõ văn bản không tuân thủ theo đúng nguyên tắc trên nên xảy ra hiện tượng dấu được đặt ở các vị trí khác nhau, chẳng hạn: toán, tóan, thuý, thúy…

16
− Cách viết hoa: theo quy định, chữ cái đầu câu và tên riêng phải viết hoa, tuy nhiên vẫn tồn tại một số cách viết tuỳ tiện.
− Phiên âm tiếng nước ngoài: hiện nay, vẫn còn nhiều tranh cãi giữa việc phiên âm tiếng nước ngoài thành tiếng Việt (Việt hoá), nên tồn tại nhiều cách viết (giữ nguyên gốc tiếng nước ngoài, phiên âm ra tiếng Việt), ví dụ: Singapore/Xin−ga−po.
− Từ gạch nối: do cách viết dấu gạch nối tuỳ tiện, không phân biệt được giữa nối tên riêng hay chú thích.
− Kí tự ngắt câu: các kí tự đặc biệt như “.”, “;”, “!”, “?”, “…” ngăn cách giữa các câu hoặc các vế câu trong câu ghép.
2.2.5 Bảng mã tiếng Việt trên máy tính
Hiện nay, việc đưa tiếng Việt vào máy tính không chỉ để soạn thảo văn bản mà còn để xây dựng các phần mềm có giao diện tiếng Việt và cũng để xử lý tiếng Việt. Tuy nhiên, hiện nay có nhiều cách mã hoá các kí tự tiếng Việt khác nhau, dẫn tới có nhiều bảng mã khác nhau được sử dụng. Theo thống kê, có tới trên 40 bảng mã tiếng Việt khác nhau được sử dụng, do đó, việc khai thác tài liệu cũng như xử lý dữ liệu rất phức tạp.
Có thể kể đến một số bảng mã dưới đây [4].
- Mã dựng sẵn
+ Mã dựng sẵn một bảng fonts: TCVN 5712-VN1, VISCII, BachKhoa 1, VietStar…: các bảng mã này mở rộng sang cả phần mã chuẩn, nên gây ảnh hưởng nghiêm trọng trong truyền thông.
+ Mã dựng sẵn hai bảng fonts: TCVN 5712-VN3 (ABC), VietSea, VNU…: sử dụng 2 bảng mã cho một kiểu chữ nên gây dư thừa và không hiện thực việc phân biệt chữ hoa chữ thường trong các chương trình xử lý số liệu.
- Mã tổ hợp
Các bảng mã VietWare-X, Vni for Windows, TCVN 5712-VN2, BachKhoa II, VS2, 3C25… và các trang mã 1258 (Microsoft), 1129 (IBM), ISO 10646 sử dụng phương pháp mã tổ hợp.
Tuy nhiên, hiện nay việc sử dụng tiếng Việt trên máy tính vẫn chưa có sự thống nhất cao về chuẩn mã tiếng Việt, gây khó khăn lớn cho việc thu thập, khai thác và xử lý tiếng Việt. Đòi hỏi các hệ thống xử lý văn bản tiếng Việt cần phải có bước tiền xử lý để nhận dạng và quy chuẩn các kí tự về một bảng mã chung.
Tóm tại, tiếng Việt là ngôn ngữ không biến hình từ và âm tiết tính, do đó, việc phân loại từ (danh từ, động từ, tính từ…) và ý nghĩa từ là vấn đề khó, cần có nhiều

17
nghiên cứu thêm. Do vậy, tiền xử lý văn bản (tách từ, tách đoạn, tách câu…) trở nên rất phức tạp với việc xử lý các hư từ, phụ từ, từ láy…; hơn nữa, phương thức ngữ pháp chủ yếu là trật tự từ nên nếu áp dụng phương pháp tính xác suất xuất hiện của từ có thể không chính xác như mong đợi. Mặt khác, ranh giới xác định từ không phải là khoảng trắng, khiến cho việc tách từ trở nên khó khăn, dẫn đến khó khăn cho các giai đoạn tiếp theo như kiểm lỗi chính tả, gán nhãn từ loại, thống kê tần suất từ… Như thế, các phương pháp xử lý ngôn ngữ đang áp dụng cho tiếng Anh không thể áp dụng trực tiếp cho tiếng Việt mà cần có sự thay đổi cho phù hợp.
2.3 Phương pháp cho bài toán tóm tắt văn bản tiếng Việt Trong IR, mỗi văn bản được biểu diễn dưới dạng vector, chẳng hạn như
Di=(di1, di2, …, din) trong đó dik biểu diễn trọng số của từ Tk trong tài liệu Di. Tính toán độ tương tự giữa hai văn bản Di và Dj là Sim(Di, Dj) – theo các công thức tính độ tương tự. Nếu độ tương tự này đạt đến một ngưỡng đủ lớn thì ta nói rằng chúng có “liên quan về mặt ngữ nghĩa”, và ta có thể thiết lập một liên kết giữa hai văn bản này [23].
Áp dụng phương pháp này vào việc tóm tắt văn bản tự động, thay vì tìm liên kết giữa các văn bản, ta sẽ tìm liên kết trong nội bộ văn bản (liên kết giữa các câu trong văn bản). Sau khi xây dựng được đồ thị quan hệ, ta có được hình vẽ trực quan cấu trúc của văn bản. Từ cấu trúc này, ta có thể xây dựng văn bản tóm tắt bằng cách trích xuất ra các câu phù hợp [24].
Trong việc xác định ngưỡng để quyết định hai câu trong văn bản có quan hệ với nhau về mặt ngữ nghĩa hay không có một ý nghĩa quan trọng, bởi lẽ ngưỡng này có thể là tốt cho một dạng văn bản nào đó nhưng lại không tốt cho văn bản khác. Như vậy, trong quá trình xây dựng và đánh giá kết quả của chương trình tóm tắt văn bản, cần phải thực nghiệm với nhiều ngưỡng khác nhau để chọn ra một ngưỡng thích hợp.
Khi áp dụng phương pháp cấu trúc văn bản này đối với văn bản tiếng Việt do có những khác biệt đối với văn bản tiếng Anh nên cần phải có một số cải tiến để nâng cao độ chính xác.
Trước hết, đối với việc phân tách từ vựng tiếng Việt. Có thể sử dụng các phương pháp như:
+ Phương pháp so khớp cực đại hay còn gọi là phương pháp Left Right Maximum Matching (LRMM) [25]. Theo đó, ta thực hiện duyệt một ngữ hoặc một câu từ trái sang phải và chọn từ có nhiều âm tiết có mặt trong từ điển, rồi cứ thế tiếp tục cho đến khi hết câu.
+ Phương pháp sử dụng bộ chuyển trạng thái hữu hạn có trọng số WFST (Weighted Finite State Transducer) kết hợp với mạng Neural do Đinh Điền (2001)

18
[13] đưa ra. Với ý tưởng cơ bản là áp dụng WFST kết hợp với trọng số là xác suất xuất hiện của mỗi từ trong ngữ liệu. Dùng WFST để duyệt qua câu cần xét. Cách duyệt có trọng số lớn nhất sẽ là cách từ được chọn. Ngoài ra sử dụng mạng Neural để khử nhập nhằng nếu có.
Do việc xây dựng bộ tách từ khá phức tạp và nằm ngoài phạm vi của luận văn này nên chúng tôi sử dụng bộ tách từ đã được viết sẵn và cung cấp miễn phí để thực hiện bước tiền xử lý các văn bản.
Tiếp theo đó là cần loại bỏ các từ dừng. Từ dừng (stop-words) là các từ xuất hiện nhiều trong các văn bản mà thường thì không giúp ích trong việc phân biệt nội dung của các tài liệu. Do đó, khi xây dựng chương trình tóm tắt, cần tìm ra các từ dừng trong văn bản và loại bỏ chúng. Việc xác định các từ dừng trong văn bản được thông qua một từ điển từ dừng.
Khi đã loại bỏ các từ dừng, cần phải xác định tiếp các từ đồng nghĩa trong văn bản. Đối với tiếng Việt, do có một số lượng lớn các từ đồng nghĩa nên khi thực hiện đo độ tương tự giữa các câu trong văn bản, ta sử dụng thêm một từ điển đồng nghĩa để xác định các từ có ý nghĩa tương đồng giữa các câu, để có thể nâng cao phần nào độ chính xác. Trong chương tiếp theo, chúng tôi sẽ trình bày chi tiết việc xây dựng ứng dụng tóm tắt văn bản và kĩ thuật sử dụng từ điển đồng nghĩa này.
Ngoài ra, trong bước tiền xử lý, các vấn đề như bảng mã, chính tả, dấu câu… cũng cần được xử lý để đảm bảo tính khách quan và chính xác cho các bước tiếp theo.
Hình vẽ dưới đây mô tả một đồ thị quan hệ của các câu trong văn bản “Hỗ trợ 400 USD cho sinh viên mua laptop” (Tên file: Text(16).txt trong tập các văn bản thử nghiệm), bỏ qua các liên kết có độ tương tự dưới 0,2.
Sau khi đã có được đồ thị quan hệ giữa các câu trong văn bản, tiến hành duyệt đồ thị và chọn ra các câu quan trọng theo một số phương pháp sau:
Cách 1. Dựa vào bậc của các nút trên đồ thị
Bậc của một nút trên đồ thị là số lượng liên kết tới các nút khác. Khi một nút có bậc lớn thì câu tương ứng nút đó sẽ phủ một lượng lớn từ vựng và có thể chứa chủ đề của nhiều câu khác [24].
+ Chọn n nút có bậc cao nhất trong đồ thị (với n là số câu cần chọn trong văn bản tóm tắt).
+ Sắp xếp các câu được chọn ra theo thứ tự xuất hiện trong văn bản gốc.

19
Hình 2 Đồ thị liên kết các câu trong văn bản (gồm 11 câu, 30 liên kết trên 0,2)
Cách 2. Duyệt theo chiều sâu
+ Chọn một nút quan trọng (thường chọn nút đầu tiên hoặc nút có bậc cao).
+ Chọn nút tiếp theo tương tự nhất với nút trước đó, và cứ như thế.
Khi đã duyệt hết mà vẫn chưa đủ số câu mong muốn, ta sử dụng tiếp cách 1 với các câu còn lại.
Cách 3. Phân đoạn văn bản
+ Chia văn bản thành từng đoạn.
+ Áp dụng cách 1 cho mỗi đoạn, số đoạn của văn bản được chia phải đảm bảo để chọn được ít nhất một câu trong mỗi đoạn.
Trong chương này, chúng tôi đã trình bày về những hướng tiếp cận với bài toán tóm tắt văn bản tiếng Việt, đồng thời cũng nêu ra những đặc trưng cần chú ý của tiếng Việt và cuối cùng đưa ra cách tiếp cận của chúng tôi về việc sử dụng phương pháp cấu trúc để tóm tắt văn bản.
11 1
2
3
4
5
6 7
8
9
10
20
Chương 3. ỨNG DỤNG PHƯƠNG PHÁP CẤU TRÚC ĐỂ TÓM TẮT VĂN BẢN TIẾNG VIỆT
Trong chương này, chúng tôi trình bày chi tiết về việc sử dụng phương pháp cấu trúc đã trình bày trong chương 2 để xây dựng chương trình tóm tắt văn bản tiếng Việt.
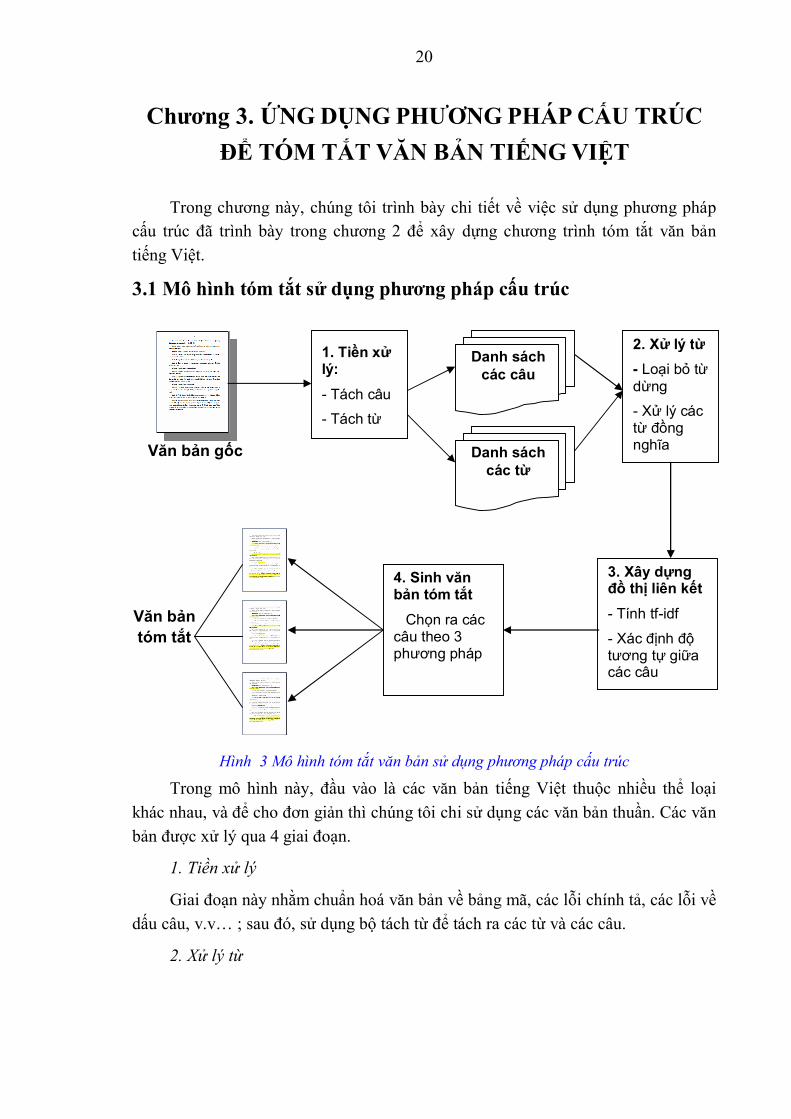
3.1 Mô hình tóm tắt sử dụng phương pháp cấu trúc
Hình 3 Mô hình tóm tắt văn bản sử dụng phương pháp cấu trúc
Trong mô hình này, đầu vào là các văn bản tiếng Việt thuộc nhiều thể loại khác nhau, và để cho đơn giản thì chúng tôi chi sử dụng các văn bản thuần. Các văn bản được xử lý qua 4 giai đoạn.
1. Tiền xử lý
Giai đoạn này nhằm chuẩn hoá văn bản về bảng mã, các lỗi chính tả, các lỗi về dấu câu, v.v… ; sau đó, sử dụng bộ tách từ để tách ra các từ và các câu.
2. Xử lý từ
1. Tiền xử lý: - Tách câu
- Tách từ
Danh sách các câu
Danh sách các từ
2. Xử lý từ - Loại bỏ từ dừng
- Xử lý các từ đồng nghĩa
3. Xây dựng đồ thị liên kết - Tính tf-idf
- Xác định độ tương tự giữa các câu
4. Sinh văn bản tóm tắt
Chọn ra các câu theo 3 phương pháp
Văn bản tóm tắt
Văn bản gốc

21
Pha này nhằm mục đích loại bỏ các từ dừng dựa trên một từ điển từ dừng có trước ; sau đó với mỗi từ trong câu, căn cứ vào từ điển đồng nghĩa để lập ra danh sách các từ đồng nghĩa.
3. Xây dựng đồ thị liên kết
Trong pha này, chúng tôi sử dụng kỹ thuật tf-idf để tính toán và vector hoá các câu của văn bản, sau đó tính toán độ tương đồng giữa các vector này. Nếu độ tương đồng giữa hai vector đạt đến một ngưỡng nào đó thì 2 câu sẽ được đưa vào đồ thị liên kết. Giá trị của ngưỡng này cũng sẽ được chúng tôi thử nghiệm và đánh giá hiệu lực.
4. Sinh văn bản tóm tắt
Trong pha này, chúng tôi sử dụng 3 kỹ thuật ở mục 2.3 để tạo ra văn bản tóm tắt. Như vậy, mỗi văn bản đầu vào sẽ có 3 văn bản tóm tắt tương ứng với từng kỹ thuật sau đây:
+ Dựa vào bậc của các nút trên đồ thị.
+ Duyệt theo chiều sâu.
+ Phân đoạn văn bản.
Để đánh giá hiệu quả của việc sử dụng bộ tách từ và từ điển đồng nghĩa, chúng tôi đã xây dựng 3 phiên bản cho ứng dụng này.
+ Phiên bản 1: Hoàn toàn không sử dụng bộ tách từ, các từ được tách ra căn cứ vào dấu trắng phân cách.
+ Phiên bản 2: Sử dụng bộ tách từ tiếng Việt để tách ra các từ.
+ Phiên bản 3: Sử dụng bộ tách từ tiếng Việt, kết hợp với từ điển từ dừng và từ điển đồng nghĩa.
Kết quả của từng phiên bản này sẽ được chúng tôi trình bày chi tiết trong chương kết quả thử nghiệm.
3.2 Tiền xử lý văn bản Chúng tôi sử dụng các tập tin văn bản được thu thập từ nhiều nguồn khác nhau
để thực hiện tóm tắt, phần lớn là các bài báo được lấy từ website vnexpress.net thuộc các lĩnh vực khoa học, giáo dục, xã hội và một số bài báo khoa học. Đối với các bài báo được lấy từ website, quá trình xử lý được thực hiện một cách bán tự động theo quy trình sau:
- Tải về các trang web chứa nội dung các bài báo (dạng html).
- Loại bỏ các thẻ HTML, lấy ra nội dung chính.

22
- Loại bỏ các câu không liên quan đến nội dung của bài viết (như các liên kết tới các trang khác…).
- Chuẩn hoá về mặt chính tả (các từ, dấu câu,…).
Đối với các bài báo khoa học (chủ yếu là dạng pdf) thì nội dung của các bài báo được sao chép một cách thủ công để đảm bảo tính chuẩn mực về chính tả.
Nội dung của mỗi văn bản được lưu trữ trong một file text và được mã hoá bằng mã Unicode UTF-8.
Tiếp đó, công cụ WordSegForTV [12] được sử dụng để phân tách ra các từ và các câu. Kết quả ta sẽ thu được 2 file: một file chứa các từ được phân tách (dấu “|” được sử dụng để ngăn cách giữa các từ), và một file chứa các câu, ở đầu mỗi câu có số thứ tự của câu được đặt trong cặp dấu “[ ]”.
Ví dụ: Đoạn văn bản sau:
“Du lịch Việt Nam suy thoái theo kinh tế thế giới.
Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao. Lượng khách quốc tế của nhiều công ty giảm tới 50%.”
Khi tách từ xong ta sẽ được kết quả:
Du| lịch| Việt Nam| suy thoái| theo| kinh tế| thế giới|.|
Tuần| trước| một| đoàn| khách| Australia| đã| hủy| hợp đồng| với| Trung tâm| Du lịch| Vietsky Travel| vì| tỷ giá| ngoại tệ| thay đổi| làm giá| tour| tăng| cao|.| Lượng| khách| quốc tế| của| nhiều| công ty| giảm| tới| 50%|
Và danh sách các câu:
[1]Du lịch Việt Nam suy thoái theo kinh tế thế giới
[2]Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao
[3]Lượng khách quốc tế của nhiều công ty giảm tới 50%
Kết quả của bước tiền xử lý này sẽ là đầu vào cho bước xử lý từ tiếp theo. Riêng đối với chương trình phiên bản 1, bộ tách từ sẽ không được sử dụng mà việc phân tách các từ sẽ căn cứ vào dấu trắng giữa các âm tiết (tức là coi mỗi âm tiết như là một từ đơn). Danh sách các câu sẽ được người thực hiện các bản tóm tắt đối sánh sử dụng để chọn ra các câu.
3.3 Xử lý từ Pha này có đầu vào là tập tin văn bản đã được thêm dấu phân tách từ ở bước
trên và có nhiệm vụ xác định các câu. Ranh giới để phân định các câu là các dấu kết

23
thúc câu bao gồm: dấu chấm câu (.), dấu hỏi chấm (?), dấu chấm than (!) và dấu ba chấm (...). Đồng thời, chương trình có nhiệm vụ xác định các từ, ranh giới để xác định là dấu “|”. Thuật toán dưới đây thể hiện việc chọn ra các từ, các câu, các từ đồng nghĩa và loại bỏ các từ dừng. Chúng tôi dùng từ điển các từ dừng do website xulyngongu.com cung cấp để loại bỏ bớt các từ không có giá trị trong việc so sánh nội dung giữa 2 câu. Từ điển đồng nghĩa được sử dụng là của [3].
Thuật toán 1
Input: Tập tin văn bản đã tách từ.
Output: Tập các từ T, Tập các câu Sent.
1. Mở tập tin văn bản
ST=Nội dung file
2. {Tách ra các câu}
n=0; {đếm số lượng câu}
k=1;
while k<len(st) begin
if ST(k)=Dấu kết thúc câu then begin
n=n+1;
sent(i)=Câu kết thúc tại vị trí k;
end;
Tăng k;
end;
3. {Tách ra các từ}
k=1;
while k<len(st) begin
if ST(k)= “|” then begin
word=Chọn ra từ kết thúc tại k;
Chuẩn hoá word; {Loại bỏ dấu cách, các kí hiệu vô ích, chuyển về chữ thường}
if word có trong từ điển từ dừng then word=””
else if word có trong từ điển đồng nghĩa then
Đưa word và các từ đồng nghĩa vào Tập từ Term;

24
Else Đưa word vào Tập từ T;
Tăng k;
end;
4. return T, Sent;
Thuật toán này được sử dụng cho phiên bản 3, trong phiên bản 2 thuật toán cũng được sử dụng, tuy nhiên không có phần loại bỏ từ dừng và tìm kiếm từ trong từ điển đồng nghĩa. Với phiên bản 1, việc xác định các câu cũng tương tự như trên, tuy nhiên ranh giới các từ được xác định bằng khoảng trắng.
3.4 Xây dựng đồ thị liên kết Pha này có nhiệm vụ xây dựng đồ thị liên kết giữa các câu trong văn bản với
đầu vào là danh sách các câu và các từ đã được xử lý ở pha trước đó. Ta thực hiện vector hoá các câu trong văn bản và thực hiện tính toán độ tương đồng giữa 2 câu bất kì trong văn bản. Trong mô hình không gian vector, ta coi mỗi văn bản như một vector (hay một điểm) trong không gian Euclide nhiều chiều, trong đó mỗi chiều là từ. Có 3 cách để biểu diễn vector [20] tuỳ thuộc vào kiểu của các thành phần trong vector: nhị phân, tần số từ tf, và tần số từ−tần số tài liệu ngược tf-idf.
Giả sử văn bản cần tóm tắt có n câu được đánh số là nsentsentsent ,...,, 21 và m từ mttt ,...,, 21 gọi ijn là số lần xuất hiện của từ it trong câu jsent . Trong phương pháp
này, chúng tôi sử dụng cách biểu diễn tf-idf để biểu diễn các vector văn bản.
Mỗi thành phần thứ i của vector văn bản jsent được tính bằng:
)(),( ijiij tIDFsenttTFsent (1)
Trong đó:
- mi ,1 , nj ,1
- Giá trị ),( ji senttTF được tính bằng nhiều cách:
+ Tính bằng tổng số lần xuất hiện của các từ trong tài liệu:
0n if
0n if 0
),( ij
1
ij
m
kkj
ijji
n
nsenttTF (2)
+ Tính bằng số lần xuất hiện lớn nhất của các từ:

25
0n if
max
0n if 0),(
ij
ij
kjk
ijji
nnsenttTF (3)
+ Tính bằng ln số lần xuất hiện số từ (sử dụng trong hệ thống Cornell SMART):
0n if )nln ln(1 1
0n if 0),(
ijij
ijji senttTF (4)
Trong cài đặt thử nghiệm, công thức (4) được sử dụng để tính giá trị ),( ji senttTF .
- Với mỗi từ it giá trị )( itIDF được tính bằng tỉ lệ thức của các câu mà xuất
hiện từ it với tổng số câu có được.
Gọi S là tập hợp các câu và it
S là tập các câu có chứa từ it .
n
jsentS1
(5a)
0| ijjt nsentSi
(5b)
Giá trị )( itIDF có thể tính theo một số cách:
+ Tính bằng thương số của S và itS :
iti S
StIDF )( (6)
+ Tính bằng hàm logarit:
iti S
StIDF
1log)( (7)
Trong cả 3 phiên bản thì công thức (7) được sử dụng để tính toán giá trị )( itIDF .
Sau khi vector hoá các câu trong văn bản, ta tính độ tương quan giữa từng cặp câu với nhau theo công thức tính độ tương đồng Cosine đã nêu ở trên. Khi đó, độ tương đồng giữa 2 câu isent và jsent bất kì được tính bằng:

26
m
l
lj
m
k
ki
m
lk
lj
ki
ji
sentsent
sentsentsentsentsim
1
1,),( (8)
Tiếp đó, ta xây dựng đồ thị liên kết giữa các câu trong văn bản. Đồ thị được biểu diễn bằng một ma trận D như sau:
thresholdsentsentsimfsentsentsim
thresholdsentsentsimifsentsentD
jiji
jiji ),( i ),(
),( 0),( (9)
Trong đó: threshold là một ngưỡng được cho trước và được tính toán bằng thực nghiệm đối với các loại văn bản. Trong thử nghiệm này của chúng tôi, ngưỡng threshold = 0,2.
Thuật toán 2.
Xây dựng đồ thị liên kết
Input: Tập từ T, số lượng từ m, tập các câu Sent, số lượng câu n, ngưỡng threshold.
Output: Đồ thị liên kết các câu njmijiDis ..1,..1),,(
1. {Sắp xếp tập từ T}
HeapSort(T,m);
2. {Tính tf-idf}
for i = 1 to m
for j = 1 to n
if T(i)=T(j) then N(i,j) = N(i,j) + 1;
{Tính tf}
for i = 1 to m
for j = 1 to n begin
tf(i,j) = 0;
if N(i,j) > 0 then tf(i,j) = 1 + ln(1+ln(N(i,j)))
end;
{Tính idf}
for i = 1 to m begin
count = 0;
27
for j = 1 to n
if N(i,j) > 0 then count = count + 1;
idf(i) = ln((1+n)/count)
end;
3. {Tính toán độ tương đồng}
for i = 1 to m
for j = 1 to n begin
sim = cos(senti, sentj)
if sim > threshold then Dis(i,j) = sim;
4. return Dis(i,j)
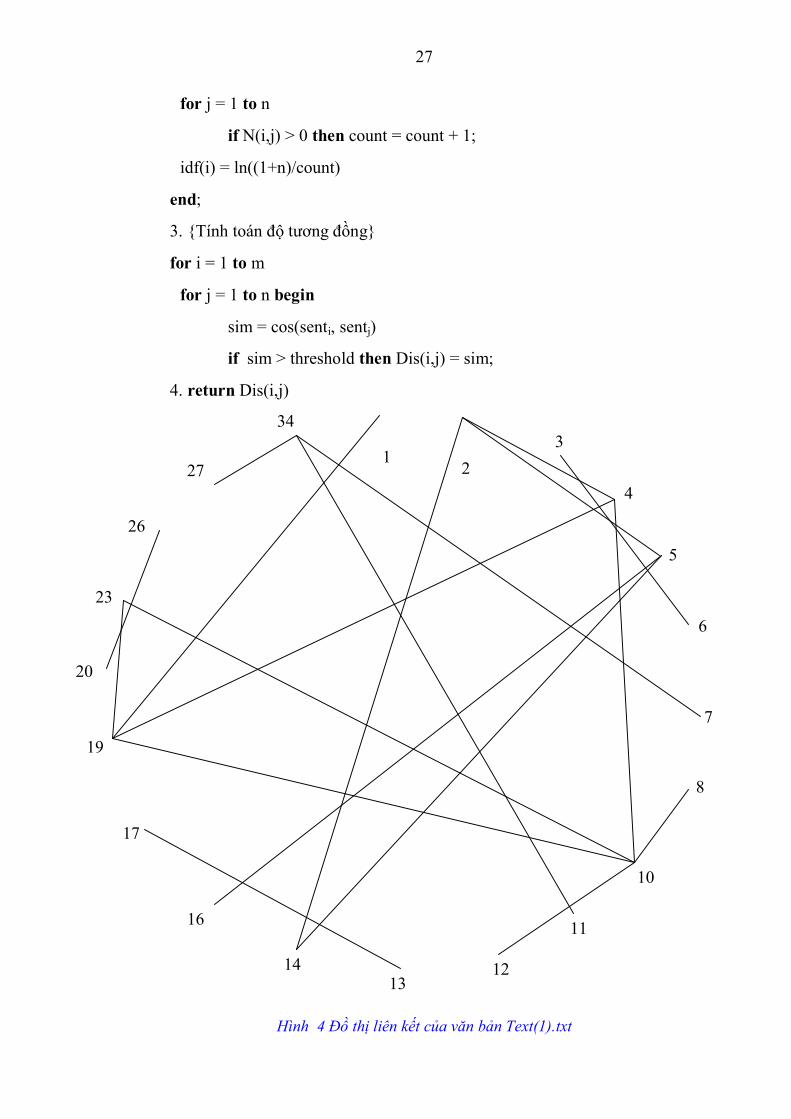
Hình 4 Đồ thị liên kết của văn bản Text(1).txt
1 2
3
4
5
6
7
8
10
11
12 13
14
16
17
19
20
23
26
27
34

28
3.5 Sinh văn bản tóm tắt Giả sử văn bản cần tóm tắt có độ dài là p% độ dài của văn bản gốc.
Chúng tôi xây dựng thủ tục duyệt đồ thị để chọn ra những câu quan trọng theo 3 phương pháp:
a) Phương pháp 1. Dựa vào bậc của các nút trên đồ thị
Bước 1: Tính bậc của mỗi nút trong đồ thị (bậc được tính bằng số liên kết của nút với các nút khác).
Bước 2: Sắp xếp các nút theo thứ tự bậc giảm dần.
Bước 3: Chọn ra các nút có bậc cao nhất, ngừng chọn khi số câu đủ yêu cầu.
Thuật toán 3
Input: Đồ thị liên kết Dis(i,j), tỉ lệ nén p%, số câu n.
Output: Tập các câu được chọn Selection.
1. {Tính số câu cần chọn}
NumberOfSent = Round(n * p);
2. {Tính bậc của các nút}
for i = 1 to n begin
Degree(i) = 0;
for j = 1 to n
if Dis(i,j) <> 0 then Degree(i) = Degree(i) + 1;
end;
3. Sắp xếp Degree(i), i = 1..n theo chiều giảm dần
4. {Chọn ra các câu}
for i = 1 to NumberOfSent
selection(i) = Số thứ tự của câu tương ứng;
5. Sắp xếp selection theo chiều tăng dần;
6. return selection;
Ví dụ:
Với văn bản Text(1).txt, tỉ lệ nén được chọn là 10%, số câu cần chọn ra là 4. Theo thuật toán 3, thứ tự của các nút được sắp xếp theo bậc giảm dần là (bỏ qua các nút có bậc bằng 0:
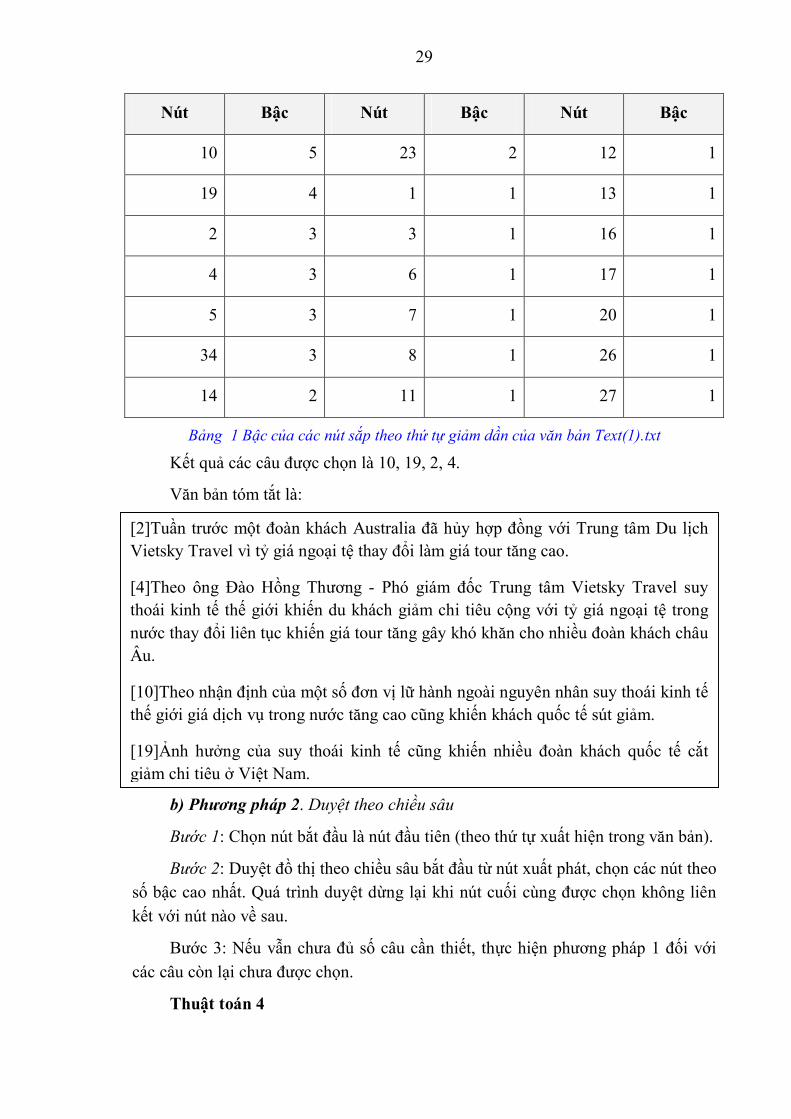
29
Nút Bậc Nút Bậc Nút Bậc
10 5 23 2 12 1
19 4 1 1 13 1
2 3 3 1 16 1
4 3 6 1 17 1
5 3 7 1 20 1
34 3 8 1 26 1
14 2 11 1 27 1
Bảng 1 Bậc của các nút sắp theo thứ tự giảm dần của văn bản Text(1).txt
Kết quả các câu được chọn là 10, 19, 2, 4.
Văn bản tóm tắt là:
b) Phương pháp 2. Duyệt theo chiều sâu
Bước 1: Chọn nút bắt đầu là nút đầu tiên (theo thứ tự xuất hiện trong văn bản).
Bước 2: Duyệt đồ thị theo chiều sâu bắt đầu từ nút xuất phát, chọn các nút theo số bậc cao nhất. Quá trình duyệt dừng lại khi nút cuối cùng được chọn không liên kết với nút nào về sau.
Bước 3: Nếu vẫn chưa đủ số câu cần thiết, thực hiện phương pháp 1 đối với các câu còn lại chưa được chọn.
Thuật toán 4
[2]Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao.
[4]Theo ông Đào Hồng Thương - Phó giám đốc Trung tâm Vietsky Travel suy thoái kinh tế thế giới khiến du khách giảm chi tiêu cộng với tỷ giá ngoại tệ trong nước thay đổi liên tục khiến giá tour tăng gây khó khăn cho nhiều đoàn khách châu Âu.
[10]Theo nhận định của một số đơn vị lữ hành ngoài nguyên nhân suy thoái kinh tế thế giới giá dịch vụ trong nước tăng cao cũng khiến khách quốc tế sút giảm.
[19]Ảnh hưởng của suy thoái kinh tế cũng khiến nhiều đoàn khách quốc tế cắt giảm chi tiêu ở Việt Nam.

30
Input: Đồ thị liên kết Dis(i,j), tỉ lệ nén p%, số câu n.
Output: Tập các câu được chọn Selection.
1. Tính số câu cần chọn;
2. Tính bậc của các nút;
3. {Chọn nút đầu tiên}
Count = 1; selected = 1;
Selection(count) = selected;
4. {Tạo danh sách kề với nút được chọn}
for i = 1 to n
if (Dis(selected,i) > 0 then Đưa i vào danh sách kề;
5. {Chọn nút có bậc cao nhất trong danh sách kề}
Selected = nút có bậc cao nhất trong danh sách kề;
Count = Count + 1;
Quay lại bước 4.
6. {Nếu chưa đủ số câu}
If count < NumberOfSent then begin
for i = 1 to n
if sent(i) chưa được chọn then Đưa i vào Danh sách còn lại;
Chọn (NumberOfSent – count) câu trong Danh sách còn lại;
7. Sắp xếp selection theo chiều tăng dần;
8. return selection;
Với ví dụ trên, các câu được chọn lần lượt là: 10, 19, 4, 2.
[2]Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao.
[4]Theo ông Đào Hồng Thương - Phó giám đốc Trung tâm Vietsky Travel suy thoái kinh tế thế giới khiến du khách giảm chi tiêu cộng với tỷ giá ngoại tệ trong nước thay đổi liên tục khiến giá tour tăng gây khó khăn cho nhiều đoàn khách châu Âu.
[10]Theo nhận định của một số đơn vị lữ hành ngoài nguyên nhân suy thoái kinh tế thế giới giá dịch vụ trong nước tăng cao cũng khiến khách quốc tế sút giảm.
[19]Ảnh hưởng của suy thoái kinh tế cũng khiến nhiều đoàn khách quốc tế cắt giảm chi tiêu ở Việt Nam.

31
c) Phương pháp 3. Phân đoạn văn bản
Bước 1: Tách văn bản thành những phân đoạn, căn cứ vào độ dài của văn bản và tỉ lệ nén p.
Bước 2: Áp dụng phương pháp 1 đối với từng phân đoạn, ở mỗi phân đoạn chọn ít nhất một câu. Các câu còn lại được chọn là các nút có bậc cao trong các phân đoạn. Quá trình chọn sẽ dừng lại khi đạt đủ số câu cần thiết.
Thuật toán 5
Input: Đồ thị liên kết Dis(i,j), tỉ lệ nén p%, số câu n.
Output: Tập các câu được chọn Selection.
1. Tính số câu cần chọn;
2. Tính bậc của các nút;
3. {Tính toán số đoạn, số câu chọn mỗi đoạn}
SentPerSeg = 1;
NumberOfSent = n/SentPerSeg;
while NumberOfSeg > NumberOfSent begin
SentPerSeg = SentPerSeg + 1
NumberOfSeg = n/SentPerSeg
end;
SelectSentPerSeg = NumberOfSent / NumberOfSeg
4. {Chọn ra các câu trong từng đoạn}
First = 1; Last = SentPerSeg;
while last < n begin
Sắp xếp bậc của các nút trong đoạn [First, Last];
for i = 1 to SelectSentPerSeg chọn câu có bậc lớn nhất;
First = Last + 1;
Last = Last + SentPerSeg;
end;
5. Sắp xếp selection theo chiều tăng dần;
6. return selection;
Cùng với ví dụ văn bản Text(1), văn bản được chia thành 4 phần, mỗi phần 8 câu, phương pháp 3 sẽ chọn ra các câu: 2, 10, 19, 34

32
Văn bản kết quả là:
Như vậy, với 3 phương pháp lựa chọn các câu để sinh văn bản tóm tắt như trên thì mỗi văn bản đầu vào sẽ có 3 văn bản tóm tắt. Các văn bản tóm tắt được đánh giá nhằm kiểm tra năng lực của từng phương pháp, để từ đó chọn lựa ra phương pháp thích hợp.
Trong chương này, chúng tôi đã giới thiệu mô hình tóm tắt văn bản sử dụng phương pháp cấu trúc và trình bày chi tiết về việc xây dựng chương trình tóm tắt văn bản. Nhằm mục đích kiểm nghiệm tác dụng của bộ tách từ tiếng Việt, từ điển đồng nghĩa, chúng tôi đã cài đặt 3 phiên bản cho ứng dụng này. Trong chương tiếp theo, chúng tôi sẽ trình bày những kết quả thực nghiệm thu được trên các phiên bản này.
[2]Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao.
[10]Theo nhận định của một số đơn vị lữ hành ngoài nguyên nhân suy thoái kinh tế thế giới giá dịch vụ trong nước tăng cao cũng khiến khách quốc tế sút giảm.
[19]Ảnh hưởng của suy thoái kinh tế cũng khiến nhiều đoàn khách quốc tế cắt giảm chi tiêu ở Việt Nam.
[34] Năm nay nước này dự kiến tăng khoảng 20% nhưng 9 tháng đầu năm chỉ tăng 6% Singapore năm ngoái đón 10 triệu lượt khách tăng 6,7% thì 9 tháng đầu năm nay chỉ tăng 0,1%.

33
Chương 4 THỰC NGHIỆM VÀ ĐÁNH GIÁ
Chương này trình bày về những kết quả thu được sau quá trình thử ngiệm chương trình đồng thời đưa ra những đánh giá, nhận xét để từ đó có thể nâng cao được độ chính xác của hệ thống.
4.1 Môi trường thử nghiệm Chương trình được xây dựng và thử nghiệm trên máy tính cá nhân có cấu hình
và các phần mềm cần thiết như sau:
- Vi xử lý: Intel Dual Core T2390 1.86GHz
- Bộ nhớ: 2GB
- Hệ điều hành: Windows 7.
- Phần mềm phát triển: Microsoft Visual Basic 2008.
- Phần mềm WordSegForTV [12] nhằm thực hiện tách từ trong văn bản.
4.2 Dữ liệu thử nghiệm a) Tập văn bản thử nghiệm
Gồm 50 văn bản có nội dung với nhiều lĩnh vực khác nhau, phần lớn được lấy từ website vnexpress và một số bài báo khoa học khác. Trong đó, có 19 bài viết thuộc lĩnh vực Giáo dục, 16 bài về Xã hội, 6 bài viết về Khoa học thường thức, 4 bài Tâm sự và 4 bài báo khoa học. Mỗi văn bản được lưu trong một tập tin được đặt tên theo thứ tự từ Text(1).txt đến Text(50).txt. Văn bản có kích thước lớn nhất là 27KB với 179 câu, văn bản có kích thước nhỏ nhất là 1,45KB với 9 câu.
b) Từ điển
- Từ điển từ dừng [10]: gồm 807 từ do website xulyngonngu.com cung cấp.
- Từ điển đồng nghĩa [3]: gồm 603 mục từ với tổng cộng 2867 từ đồng nghĩa.
4.3 Phương pháp đánh giá Như trên đã trình bày, có nhiều phương pháp khác nhau để đánh giá kết quả
của một hệ thống tóm tắt. Trong đó, phương pháp so sánh văn bản của hệ thống tóm tắt với văn bản do con người thực hiện được sử dụng nhiều. Trong thử nghiệm của chúng tôi, phương pháp này cũng được sử dụng để đánh giá độ chính xác của hệ thống tóm tắt.
Gọi hệ thống tóm tắt cần đánh giá là S, hệ thống tóm tắt đối sánh là GS thì ta có bảng đánh giá mức độ liên quan của S và GS như sau:

34
Hệ thống S Hệ thống GS Số câu S chọn Số câu S không chọn
Số câu GS chọn A B
Số câu GS không chọn C D
Bảng 2 Đánh giá sự liên quan của văn bản tóm tắt và văn bản GS
Trong đó:
A là tổng số câu được cả 2 hệ thống tóm tắt chọn;
B là tổng số câu S không chọn nhưng GS chọn;
C là tổng số câu S chọn nhưng GS không chọn;
D là tổng số câu mà cả 2 hệ thống đều không chọn.
Khi đó, độ chính xác Precision (P) được tính bằng:
CAAP
(10)
Độ chính xác P cho biết tỉ lệ giữa các câu S chọn ra chính xác so với tổng số những câu có trong văn bản tóm tắt do S thực hiện.
Độ bao phủ Recall (R) được tính bằng:
BAAR
(11)
Độ bao phủ R cho biết tỉ lệ giữa các S chọn ra chính xác so với tổng số câu trong văn bản do GS thực hiện.
Độ đo F: là tiêu chí đánh giá chung cho kết quả tóm tắt của hệ thống, độ đo này là hàm điều hoà của độ chính xác và độ hồi quy và được tính bằng:
RPPRF
2 (12)
Như trên đã trình bày, tỉ lệ nén của văn bản tóm tắt là tỉ lệ giữa tổng số câu do hệ thống tóm tắt lựa chọn so với tổng số câu của văn bản ban đầu. Chúng tôi thử nghiệm hệ thống tóm tắt với 3 mức độ nén: 10%, 20% và 30%.
Tập văn bản thử nghiệm trên được tóm tắt bởi con người, mỗi văn bản được tóm tắt thành 3 văn bản với mức độ nén lần lượt là 10%, 20% và 30%. Các văn bản được chuyển cho hai người tóm tắt để chọn ra các câu có ý nghĩa quan trọng. Việc lựa chọn các câu sẽ là chọn ra số thứ tự của câu đó trong văn bản gốc. Mỗi câu được chọn sẽ được ghi trên một dòng.

35
Chẳng hạn, với văn bản Text(1).txt trong tập văn bản thử nghiệm, văn bản này có 35 câu. Giả sử, với tỉ lệ nén là 10% thì người tóm tắt sẽ thực hiện chọn ra 4 câu, các câu được chọn được ghi trong một tập tin văn bản viết theo dạng:
Hình 5 Bản tóm tắt của Text(1).txt thực hiện bởi con người, tỉ lệ nén 10%
Văn bản tóm tắt của Text(1).txt
Đồng thời, để so sánh kết quả tóm tắt của hệ thống với các hệ thống khác, chúng tôi lựa chọn Microsoft Office Word 2003 làm hệ tóm tắt đối sánh. Khi có được các câu do chức năng AutoSummarize lựa chọn, căn cứ vào danh sách các câu có được ở bước tiền xử lý, danh sách các câu được chọn sẽ được lưu vào trong một file có định dạng giống như trên. Các tập tin này được lưu trong cùng thư mục theo từng tỉ lệ nén, các tập tin tóm tắt theo cùng mức độ nén thì được lưu trong cùng một thư mục.
[4]Theo ông Đào Hồng Thương - Phó giám đốc Trung tâm Vietsky Travel suy thoái kinh tế thế giới khiến du khách giảm chi tiêu cộng với tỷ giá ngoại tệ trong nước thay đổi liên tục khiến giá tour tăng gây khó khăn cho nhiều đoàn khách châu Âu.
[10]Theo nhận định của một số đơn vị lữ hành ngoài nguyên nhân suy thoái kinh tế thế giới giá dịch vụ trong nước tăng cao cũng khiến khách quốc tế sút giảm.
[19]Ảnh hưởng của suy thoái kinh tế cũng khiến nhiều đoàn khách quốc tế cắt giảm chi tiêu ở Việt Nam.
[35] Trong thời điểm khó khăn này chiến lược của ngành du lịch là thu hút khách ở thị trường gần như Hong Kong, Đài Loan, Nhật Bản, Hàn Quốc, Thái Lan và những tỉnh ven biển Trung Quốc như Quảng Đông, Quảng Tây, Vân Nam - người đứng đầu ngành du lịch Việt Nam nói.
36
4.4 Kết quả thực nghiệm
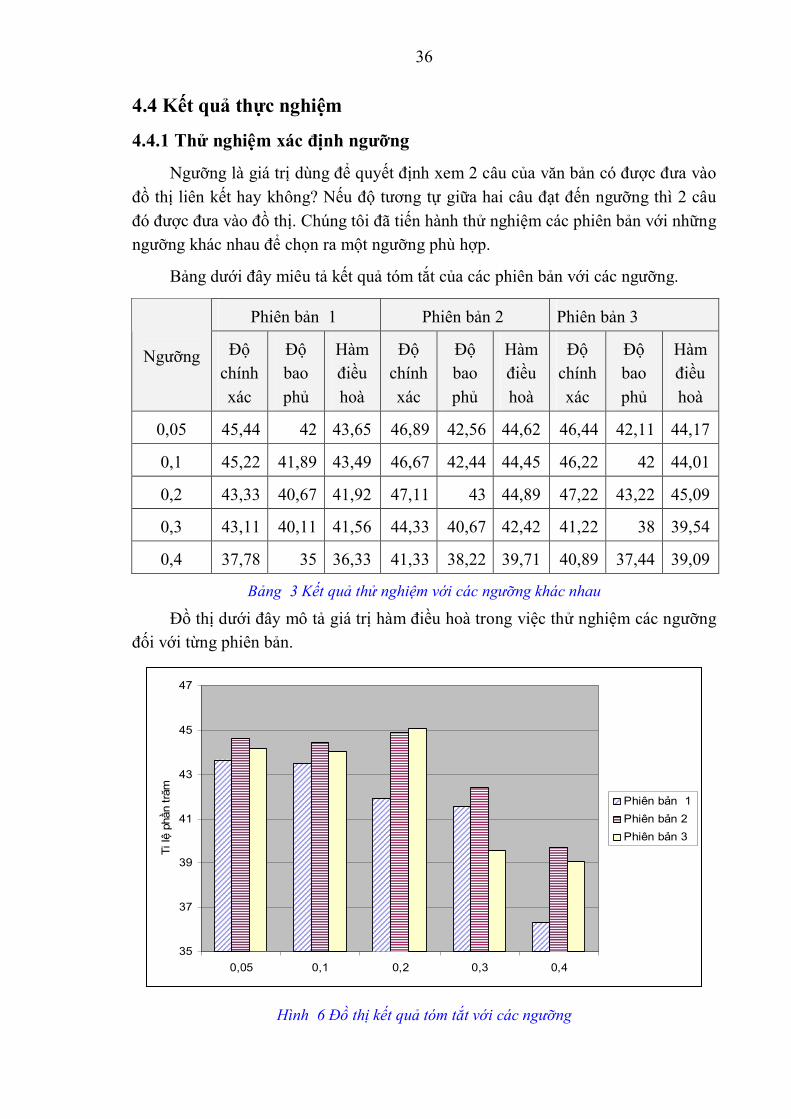
4.4.1 Thử nghiệm xác định ngưỡng
Ngưỡng là giá trị dùng để quyết định xem 2 câu của văn bản có được đưa vào đồ thị liên kết hay không? Nếu độ tương tự giữa hai câu đạt đến ngưỡng thì 2 câu đó được đưa vào đồ thị. Chúng tôi đã tiến hành thử nghiệm các phiên bản với những ngưỡng khác nhau để chọn ra một ngưỡng phù hợp.
Bảng dưới đây miêu tả kết quả tóm tắt của các phiên bản với các ngưỡng.
Phiên bản 1 Phiên bản 2 Phiên bản 3
Ngưỡng Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
0,05 45,44 42 43,65 46,89 42,56 44,62 46,44 42,11 44,17
0,1 45,22 41,89 43,49 46,67 42,44 44,45 46,22 42 44,01
0,2 43,33 40,67 41,92 47,11 43 44,89 47,22 43,22 45,09
0,3 43,11 40,11 41,56 44,33 40,67 42,42 41,22 38 39,54
0,4 37,78 35 36,33 41,33 38,22 39,71 40,89 37,44 39,09
Bảng 3 Kết quả thử nghiệm với các ngưỡng khác nhau
Đồ thị dưới đây mô tả giá trị hàm điều hoà trong việc thử nghiệm các ngưỡng đối với từng phiên bản.
35
37
39
41
43
45
47
0,05 0,1 0,2 0,3 0,4
Ti lệ
phầ
n tră
m
Phiên bản 1 Phiên bản 2 Phiên bản 3
Hình 6 Đồ thị kết quả tóm tắt với các ngưỡng

37
Qua kết quả này, ta có thể nhận thấy, với ngưỡng 0,05; 0,1 và 0,2 thì chương trình tóm tắt cho kết quả khả quan nhất. Khi ngưỡng tăng dần thì giá trị hàm điều hoà lại giảm rất nhanh do khi độ tương tự giữa hai câu không đạt đến ngưỡng đó thì hai câu đó không thể được đưa vào đồ thị liên kết, từ đó hai câu này sẽ không được chọn vào văn bản tóm tắt (mà rất có thể hai câu này chứa nội dung chính và sẽ được chọn). Việc xác định ngưỡng có một vị trí quan trọng trong chương trình tóm tắt. Bởi lẽ ngưỡng còn phụ thuộc vào từng loại văn bản, một ngưỡng này có thể là tốt với loại văn bản nhưng có thể lại không tốt với loại văn bản khác. Trong thử nghiệm kết quả tóm tắt đối với từng văn bản dưới đây chúng tôi sử dụng ngưỡng 0,2 để đánh giá.
4.4.2 Kết quả thử nghiệm đối với từng phiên bản
a) Đánh giá chất lượng tóm tắt của Microsoft Word
Bảng dưới đây là kết quả đối sánh của các bản tóm tắt do Microsoft Word thực hiện.
Tỉ lệ nén Độ chính xác Độ bao phủ Hàm điều hoà
10% 34 28 30,71
20% 36 30 32,73
30% 44 41 42,45
Trung bình 38 33 35,32
Bảng 4 Chất lượng của văn bản tóm tắt bởi Microsoft Word
b) Phiên bản 1
Trong phiên bản này, chúng tôi không sử dụng bộ tách từ mà chỉ sử dụng dấu trắng làm dấu hiệu phân tách từ.
Ngưỡng threshold được chọn đối với cả 3 phiên bản để đưa 2 câu vào đồ thị liên kết được chọn là 0,2.
Dưới đây là kết quả đánh giá độ chính xác và độ bao phủ trung bình của phương pháp được sử dụng trong phiên bản này theo từng mức độ nén khi so sánh với văn bản tóm tắt “lý tưởng” do con người thực hiện. Chúng tôi cũng đưa ra độ chính xác trung bình chung cho cả 3 mức độ nén.
38
Đơn vị: %
Phương pháp 1 Phương pháp 2 Phương pháp 3
Tỉ lệ nén Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
10% 51 42 46,06 46 44 44,98 32 28 29,87
20% 46 44 44,98 47 45 45,98 41 38 39,44
30% 40 40 40 41 40 40,49 46 45 45,49
Trung bình 45,67 42 43,76 44,67 43 43,82 39,67 37 38,29
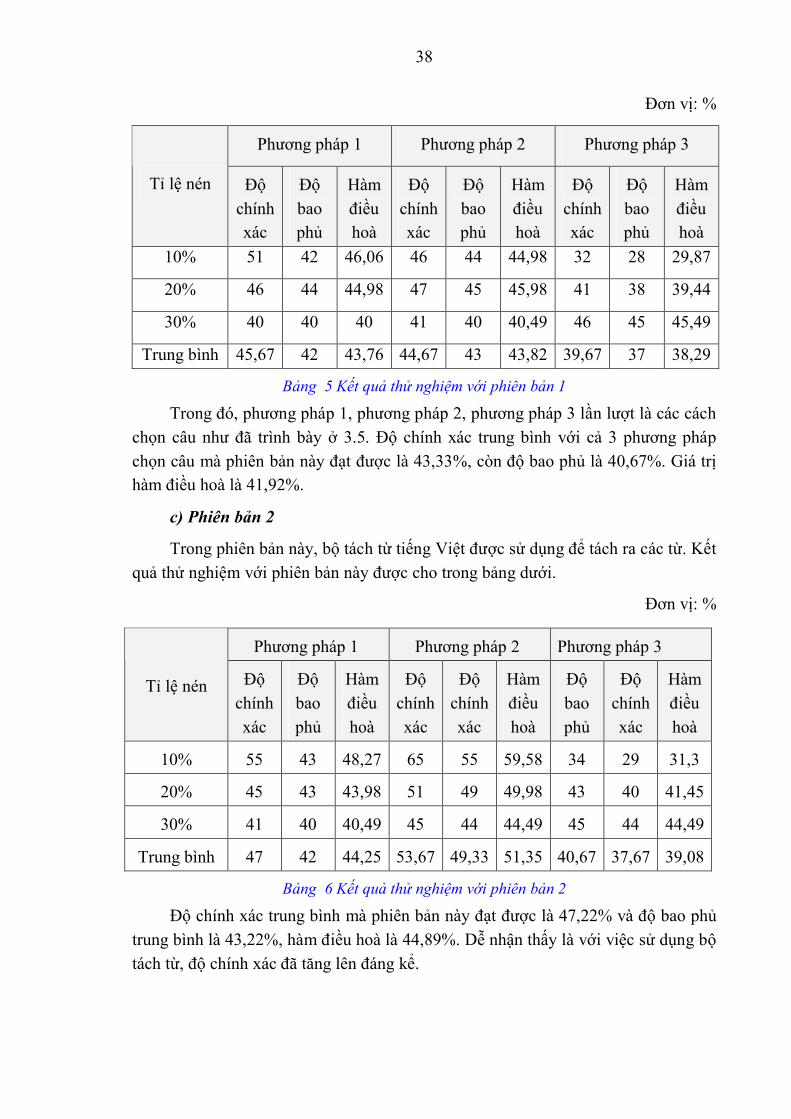
Bảng 5 Kết quả thử nghiệm với phiên bản 1
Trong đó, phương pháp 1, phương pháp 2, phương pháp 3 lần lượt là các cách chọn câu như đã trình bày ở 3.5. Độ chính xác trung bình với cả 3 phương pháp chọn câu mà phiên bản này đạt được là 43,33%, còn độ bao phủ là 40,67%. Giá trị hàm điều hoà là 41,92%.
c) Phiên bản 2
Trong phiên bản này, bộ tách từ tiếng Việt được sử dụng để tách ra các từ. Kết quả thử nghiệm với phiên bản này được cho trong bảng dưới.
Đơn vị: %
Phương pháp 1 Phương pháp 2 Phương pháp 3
Tỉ lệ nén Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ chính xác
Hàm điều hoà
Độ bao phủ
Độ chính xác
Hàm điều hoà
10% 55 43 48,27 65 55 59,58 34 29 31,3
20% 45 43 43,98 51 49 49,98 43 40 41,45
30% 41 40 40,49 45 44 44,49 45 44 44,49
Trung bình 47 42 44,25 53,67 49,33 51,35 40,67 37,67 39,08
Bảng 6 Kết quả thử nghiệm với phiên bản 2
Độ chính xác trung bình mà phiên bản này đạt được là 47,22% và độ bao phủ trung bình là 43,22%, hàm điều hoà là 44,89%. Dễ nhận thấy là với việc sử dụng bộ tách từ, độ chính xác đã tăng lên đáng kể.
39
d) Phiên bản 3
Phiên bản này sử dụng đồng thời cả bộ tách từ tiếng Việt và các từ điển từ dừng, từ đồng nghĩa. Kết quả trung bình của phiên bản này như dưới đây.
Đơn vị: %
Phương pháp 1 Phương pháp 2 Phương pháp 3
Tỉ lệ nén Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ chính xác
Hàm điều hoà
Độ bao phủ
Độ chính xác
Hàm điều hoà
10% 53 43 47,48 65 56 60,17 36 31 33,31
20% 44 41 42,45 52 49 50,46 42 39 40,44
30% 42 41 41,49 47 46 46,49 44 43 43,49
Trung bình 46,33 41,67 43,88 54,67 50,33 52,41 40,67 37,67 39,11
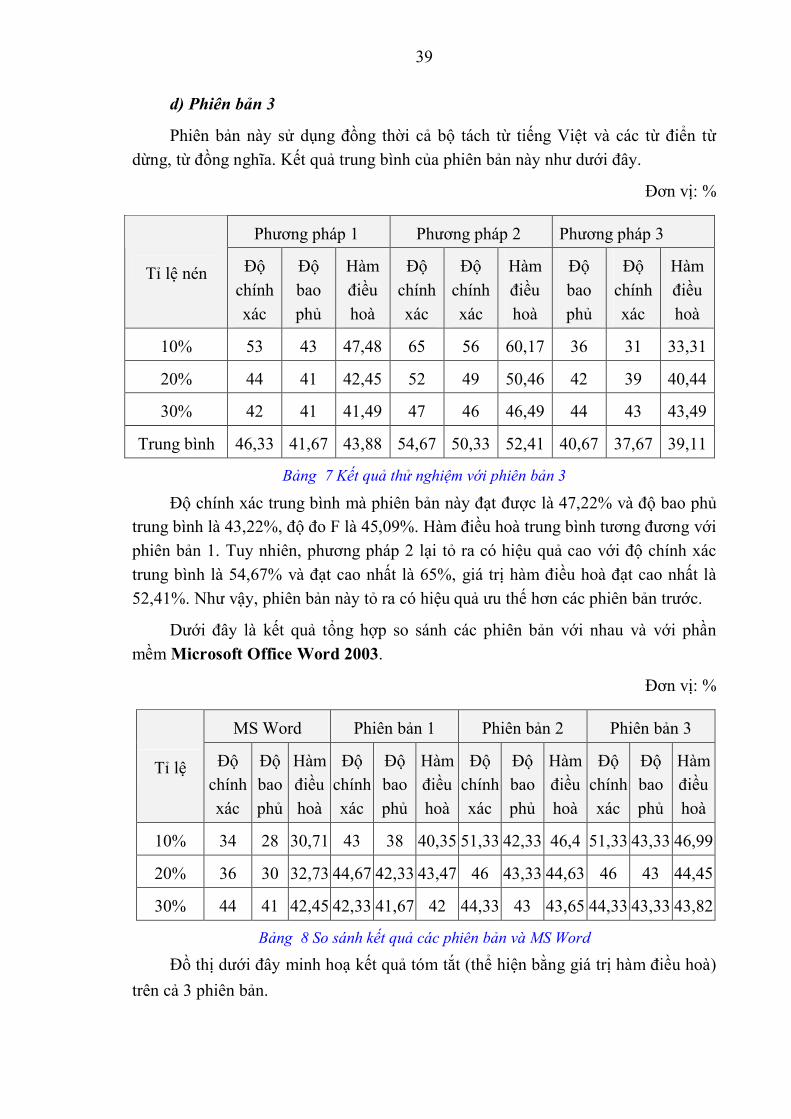
Bảng 7 Kết quả thử nghiệm với phiên bản 3
Độ chính xác trung bình mà phiên bản này đạt được là 47,22% và độ bao phủ trung bình là 43,22%, độ đo F là 45,09%. Hàm điều hoà trung bình tương đương với phiên bản 1. Tuy nhiên, phương pháp 2 lại tỏ ra có hiệu quả cao với độ chính xác trung bình là 54,67% và đạt cao nhất là 65%, giá trị hàm điều hoà đạt cao nhất là 52,41%. Như vậy, phiên bản này tỏ ra có hiệu quả ưu thế hơn các phiên bản trước.
Dưới đây là kết quả tổng hợp so sánh các phiên bản với nhau và với phần mềm Microsoft Office Word 2003.
Đơn vị: %
MS Word Phiên bản 1 Phiên bản 2 Phiên bản 3
Tỉ lệ Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
Độ chính xác
Độ bao phủ
Hàm điều hoà
10% 34 28 30,71 43 38 40,35 51,33 42,33 46,4 51,33 43,33 46,99
20% 36 30 32,73 44,67 42,33 43,47 46 43,33 44,63 46 43 44,45
30% 44 41 42,45 42,33 41,67 42 44,33 43 43,65 44,33 43,33 43,82
Bảng 8 So sánh kết quả các phiên bản và MS Word
Đồ thị dưới đây minh hoạ kết quả tóm tắt (thể hiện bằng giá trị hàm điều hoà) trên cả 3 phiên bản.
40
30
32
34
36
38
40
42
44
46
48
MS Word Phiên bản 1 Phiên bản 2 Phiên bản 3
Tỉ lệ
phầ
n tră
m
10%20%30%
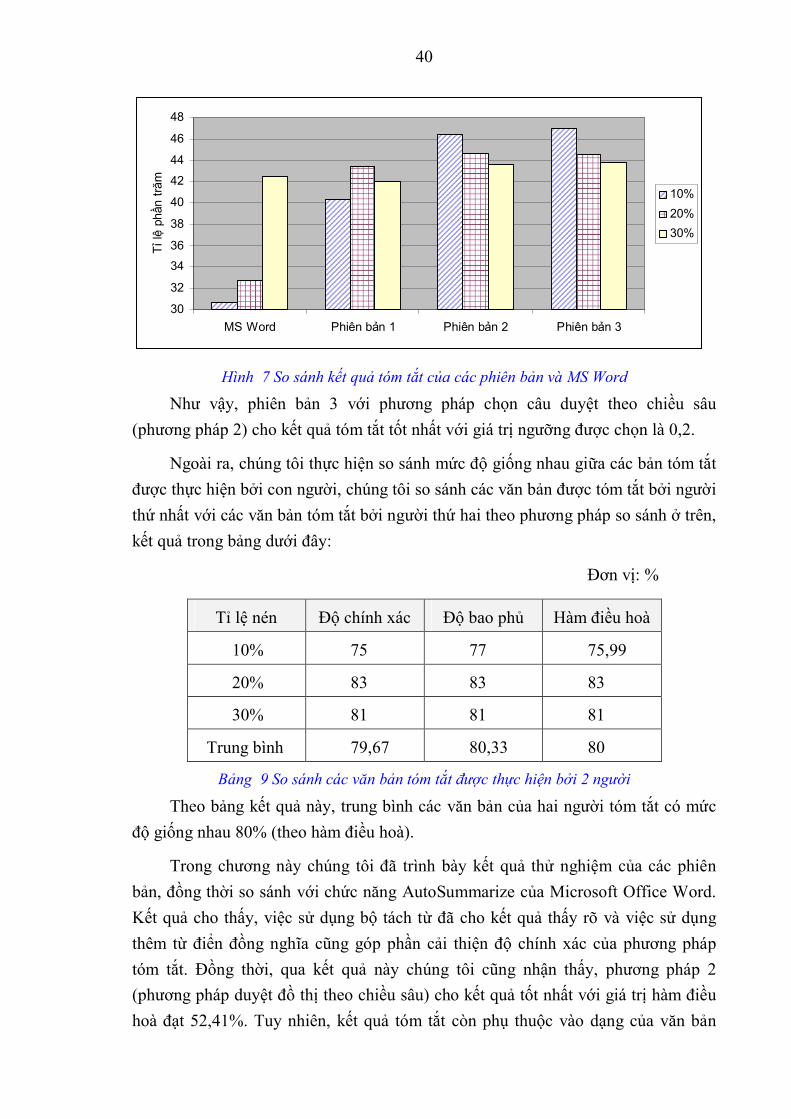
Hình 7 So sánh kết quả tóm tắt của các phiên bản và MS Word
Như vậy, phiên bản 3 với phương pháp chọn câu duyệt theo chiều sâu (phương pháp 2) cho kết quả tóm tắt tốt nhất với giá trị ngưỡng được chọn là 0,2.
Ngoài ra, chúng tôi thực hiện so sánh mức độ giống nhau giữa các bản tóm tắt được thực hiện bởi con người, chúng tôi so sánh các văn bản được tóm tắt bởi người thứ nhất với các văn bản tóm tắt bởi người thứ hai theo phương pháp so sánh ở trên, kết quả trong bảng dưới đây:
Đơn vị: %
Tỉ lệ nén Độ chính xác Độ bao phủ Hàm điều hoà
10% 75 77 75,99
20% 83 83 83
30% 81 81 81
Trung bình 79,67 80,33 80
Bảng 9 So sánh các văn bản tóm tắt được thực hiện bởi 2 người
Theo bảng kết quả này, trung bình các văn bản của hai người tóm tắt có mức độ giống nhau 80% (theo hàm điều hoà).
Trong chương này chúng tôi đã trình bày kết quả thử nghiệm của các phiên bản, đồng thời so sánh với chức năng AutoSummarize của Microsoft Office Word. Kết quả cho thấy, việc sử dụng bộ tách từ đã cho kết quả thấy rõ và việc sử dụng thêm từ điển đồng nghĩa cũng góp phần cải thiện độ chính xác của phương pháp tóm tắt. Đồng thời, qua kết quả này chúng tôi cũng nhận thấy, phương pháp 2 (phương pháp duyệt đồ thị theo chiều sâu) cho kết quả tốt nhất với giá trị hàm điều hoà đạt 52,41%. Tuy nhiên, kết quả tóm tắt còn phụ thuộc vào dạng của văn bản

41
tóm tắt, phương pháp này có thể là tốt với dạng văn bản này nhưng cũng có thể không tốt với dạng văn bản khác. Bảng phụ lục bên dưới cho thấy kết quả tóm tắt với từng văn bản trong tập văn bản thử nghiệm: Có văn bản được tóm tắt với độ đo F rất cao (76,63%) nhưng có văn bản thì độ đo F chỉ đạt xấp xỉ 22%. Do vậy cũng cần có những nghiên cứu tiếp theo để cải tiến và đưa ra được phương pháp cho kết quả tốt hơn với nhiều dạng văn bản.

42
KẾT LUẬN
Tóm tắt văn bản là một lĩnh vực khó của xử lý ngôn ngữ tự nhiên. Sản phẩm của quá trình tóm tắt có thể ứng dụng vào nhiều lĩnh vực: từ hỗ trợ việc đọc và khai thác thông tin cho đến hỗ trợ các hệ thống tìm kiếm. Có nhiều hướng tiếp cận để tóm tắt văn bản: từ các phương pháp thống kê, học máy đến ứng dụng các kĩ thuật xử lý ngôn ngữ phức tạp. Tóm tắt văn bản có thể có nhiều dạng, tuỳ theo từng tiêu chí phân loại và mục đích, yêu cầu của người sử dụng.
Luận văn đã trình bày những vấn đề tổng quan về tóm tắt văn bản, giới thiệu các hướng tiếp cận chính với các phương pháp tóm tắt văn bản tiêu biểu đã và đang được sử dụng trong các hệ thống tóm tắt văn bản tiếng Anh và đều đã thu được những kết quả rất khả quan. Chúng tôi đã trình bày về việc áp dụng, cải tiến phương pháp sử dụng cấu trúc văn bản để tóm tắt văn bản. Trong phương pháp này, chúng tôi đã sử dụng một số kĩ thuật để xử lý áp dụng cho tiếng Việt (bộ tách từ, từ điển từ dừng, từ điển đồng nghĩa…). Chúng tôi đã tiến hành cài đặt thử nghiệm và đánh giá các bản tóm tắt của hệ thống với các bản tóm tắt do con người thực hiện. Kết quả thử nghiệm cho thấy, hệ thống có khả năng nhận diện ra những câu quan trọng, tuy nhiên, tính mạch lạc và độ chính xác còn chưa cao.
Do hạn chế về mặt thời gian, kĩ thuật và đặc biệt chưa có dữ liệu về tiếng Việt đầy đủ: như từ điển từ đồng nghĩa, trái nghĩa, từ dừng… nên cần có nhiều thời gian và công sức để xây dựng và cải tiến phương pháp tóm tắt văn bản tiếng Việt để có được hệ thống tóm tắt văn bản hiệu quả. Phương pháp chúng tôi sử dụng thực nghiệm trong đề tài này mới chỉ thuộc dạng trích chọn các câu trong văn bản. Tương lai, chúng tôi sẽ tiếp tục nghiên cứu để cải tiến phương pháp này và các phương pháp khác để có thể xây dựng được chương trình tóm tắt với khả năng sinh tự động văn bản tóm tắt theo một số hướng:
- Thử nghiệm với nhiều dạng văn bản khác nhau: bài báo khoa học, báo điện tử… để có thể đưa ra được các tham số cho phù hợp (như ngưỡng khi đánh giá độ tương tự, độ dài của phân đoạn văn bản…) kết hợp với phương pháp tìm các cụm từ dấu hiệu để xác định những câu quan trọng.
- Sử dụng phương pháp phân tích cú pháp, biến đổi từ và một số kĩ thuật xử lý khác để tăng tính mạch lạc cho văn bản tóm tắt.
- Nghiên cứu các phương pháp sinh tóm tắt văn bản (tóm tắt dạng abstract) để xây dựng chương trình tóm tắt với khả năng “viết” ra bản tóm tắt chứ không đơn thuần là trích chọn các câu trong văn bản.

43
Vì thời gian và trình độ còn hạn chế nên chắc chắn đề tài không thể tránh khỏi những thiếu sót, rất mong nhận được ý kiến đóng góp của các thầy cô và các bạn để đề tài được hoàn thiện hơn.
Xin chân thành cảm ơn!

44
TÀI LIỆU THAM KHẢO Tiếng Việt
[1] Diệp Quang Ban (2008), Ngữ pháp tiếng Việt - tập 1, 2, NXB Giáo dục, Hà Nội.
[2] Nguyễn Việt Cường (2007), “Xây dựng mục lục cho văn bản”, Luận văn thạc sĩ, Đại học Công nghệ - Đại học Quốc gia Hà Nội, Hà Nội.
[3] Trần Trọng Dương, Nguyễn Quốc Khánh, Bùi Hồng Quế, Nguyễn Đình Phúc, Nguyễn Minh Châu (2008), Từ điển đồng nghĩa và trái nghĩa tiếng Việt dành cho học sinh, Nhà xuất bản từ điển bách khoa, Hà Nội, tr. 9-323.
[4] Vũ Xuân Lương (2002), “Tiếng Việt giàu nhưng có còn đẹp trên mạng thông tin toàn cầu”, Tạp chí ngôn ngữ & đời sống, Hà Nội.
[5] Đỗ Phúc, Hoàng Kiếm (2006), “Rút ý chính từ văn bản tiếng Việt hỗ trợ tạo tóm tắt nội dung”, Tạp chí công nghệ thông tin và truyền thông, Hà Nội.
[6] Nguyễn Trọng Phúc, Lê Thanh Hương (2008), “Tóm tắt văn bản sử dụng cấu trúc diễn ngôn”, Đại học Bách Khoa Hà Nội, Hà Nội.
[7] Nguyễn Hồng Thái (2008), “Tóm tắt văn bản tiếng Việt theo chủ đề”, Đồ án tốt nghiệp cao học, Đại học Bách khoa Hà Nội.
[8] Vương Toàn (2007), “Thử đề xuất quy trình tự động tóm tắt văn bản khoa học”, Bản tin thư viện – Công nghệ thông tin, tr.14-17.
[9] Trần Mai Vũ (2009), Tóm tắt đa văn bản dựa vào trích xuất câu, Luận văn thạc sĩ, Đại học Công nghệ - Đại học Quốc gia Hà Nội.
[10] Website xulyngonngu.com
Tiếng Anh
[11] Dipanjan Das, Andre F.T. Martins (2007), “A Survey on Automatic Text Summarization”, Language Technologies Institute, Carnegie Mellon Univerisity.
[12] Dang Duc Pham, Giang Chan Binh, Son Bao Pham (2009), “ ”, International Conference on Knowledge and Systems Engineering, pp.154-161.
[13]Dinh Dien, Hoang Kiem, Nguyen Van Toan (2001), “Vietnamese Word Segmentation”, National University of HCM City
[14] Edmundson (1969), “New methods in automatic extracting”, Journal of the ACM, 16(2), pp.264-285.

45
[15] Jezek, K. and Steinberger, J. (2008) "Automatic Text Summarization (The state of the art 2007 and new challenges)", Znalosti, FIIT STU Bratislava, Slovakia, pp.1-12.
[16] Partha Lal (2002), Text Summarization, Doctor thesis, University of Sheffield.
[17] H.P. Luhn (1958), “The Automatic Creation of Literature Abstracts”, IBM Journal of Research and Development, volume 2, pp. 159-165.
[18] Inderjeet Mani (2001), “Summarization Evaluation: An Overview”, In: Proceedings of the North American chapter of the Association for Computational Linguistics (NAACL), Workshop on Automatic Summarization, USA.
[19] Inderjeet Mani and Mark T. Maybury, (1999), Advances in Automatic Text Summarization, The MIT Press Cambridge, Massachusetts London, England, pp. ix-x.
[20] Zdravko Markov and Daniel T.Larose (2007), Data mining the web – Uncovering patterns in Web content, structure, and usage, John Wiley & Sons Inc. Publication, New Jersey, USA.
[21] Joel Larocca Neto, Alex A. Freitas, Celso A.A. Kaestner (2002), “Automatic Text Summarization using a Machine Learning Approach”, Springer Verlag Berlin Heidelberg , pp. 205-215
[22] Dragomir R. Radev, Kathleen McKeown (2002), “Introduction to the Special Issue on Summarization”, Computational Linguistics, Volume 28 (4), pp. 399-408.
[23] Gerard Salton, Chris Buckley and Jame Allan (1992), “Automatic structuring of text files”, Electronic Publishing, Vol. 5(1), pp. 1-17.
[24] Gerard Salton, Am1t Singha, Mandar Mitra And Chris Buckley (1997), “Automatic Text Structuring and Summarization”, Advances in Automatic Text Summarization, The MIT Press Cambridge, Massachusetts London, England, pp. 341-355.
[25] Chih-Hao Tsai (2000), “A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm”, Web publication at http://technology.chtsai.org/mmseg/

46
PHỤ LỤC Văn bản Text(1) đã được tách thành các câu:
[1]Du lịch Việt Nam suy thoái theo kinh tế thế giới
[2]Tuần trước một đoàn khách Australia đã hủy hợp đồng với Trung tâm Du lịch Vietsky Travel vì tỷ giá ngoại tệ thay đổi làm giá tour tăng cao
[3] Lượng khách quốc tế của nhiều công ty giảm tới 50%
[4]Theo ông Đào Hồng Thương - Phó giám đốc Trung tâm Vietsky Travel suy thoái kinh tế thế giới khiến du khách giảm chi tiêu cộng với tỷ giá ngoại tệ trong nước thay đổi liên tục khiến giá tour tăng gây khó khăn cho nhiều đoàn khách châu Âu
[5] Một đoàn khách Czech khác cũng cho biết sẽ hủy hợp đồng vì không muốn mua vé máy bay giá cao không chấp nhận giá tour tăng
[6]Ông Phùng Quang Thắng - Giám đốc Công ty Du lịch Hanoitourist cũng cho hay khách nước ngoài vào du lịch tại VN qua đơn vị này đã giảm tới 50% so với năm trước đặc biệt là Thái Lan
[7] Mỗi năm công ty đón khoảng 7.000 du khách Thái thì nay chỉ được một nửa
[8]Nhiều đơn vị lữ hành tên tuổi khác cũng đều bị sút giảm khách quốc tế như Vietran tour giảm 30% Vietravel giảm 10%
[9] Theo đại diện của Vietran tour khách du lịch Malaysia, Trung Quốc mọi năm vào Việt Nam khá ồ ạt song nay thì cầm chừng
[10]Theo nhận định của một số đơn vị lữ hành ngoài nguyên nhân suy thoái kinh tế thế giới giá dịch vụ trong nước tăng cao cũng khiến khách quốc tế sút giảm
[11] Năm nay giá tour tăng 20% cao nhất trong nhiều năm
[12] Nguyên nhân là giá dịch vụ đầu vào tăng như hàng không khách sạn ăn uống
[13]Theo ông Đào Hồng Thương thông thường các hợp đồng đón khách đã được ký từ năm trước nên doanh nghiệp du lịch khá điêu đứng khi giá dịch vụ trong nước tăng ào ạt
[14] Một đoàn khách Pháp mới hủy hợp đồng vì đơn vị báo lại giá tour tăng thêm 100 USD một khách
[15]Chúng tôi phải cố gắng đàm phán với đối tác để chia sẻ rủi ro

47
[16] Có nơi thông cảm chấp nhận ký lại hợp đồng song họ đều không thoải mái một số khác thì không chấp nhận nên rất khó cộng tác tiếp với họ - ông Thương phàn nàn
[17]Hiện giá tour trong nước vẫn chưa có dấu hiệu giảm nên các hợp đồng ký cho năm tới khá nhỏ giọt
[18] Tuy nhiên ông Phùng Quang Thắng - Giám đốc Hanoitourist tin tưởng năm sau giá tour có thể giảm do giá xăng dầu giảm giá vé máy bay cũng sẽ xuống thấp hơn
[19]Ảnh hưởng của suy thoái kinh tế cũng khiến nhiều đoàn khách quốc tế cắt giảm chi tiêu ở Việt Nam
[20] Nhiều khách sạn 5 sao trở nên vắng vẻ hơn thay vào đó khách sạn 3 sao lại lên ngôi
[21] Theo chị Đào Việt Nga đại diện khách sạn Melia thời điểm này các năm trước công suất phòng tại khách sạn Melia thường đạt tới 90% song nay chỉ gần 80%
[22] Một số khách hàng truyền thống cho biết họ chuyển sang đặt phòng khách sạn ít sao hơn để giảm chi phí
[23]Suy thoái kinh tế thế giới khiến khách quốc tế cắt giảm chi tiêu tình hình khó khăn có thể kéo dài hết năm 2009, chị Nga nhận định
[24]Theo nghiên cứu của Công ty TNHH CB Richard Ellis Việt Nam các khách sạn 5 sao trong quý 3 có hiệu suất sử dụng chỉ đạt 59% giảm 19% so với thời gian cùng kỳ năm ngoái và giá thuê trung bình 148,5 USD một đêm
[25] Nhiều khách sạn cao cấp đã phải giảm giá để thích ứng với điều kiện của thị trường
[26] Trong khi đó khách sạn 3 sao lại tăng công suất lên đến 80%
[27]Theo thống kê của Tổng cục Du lịch khách du lịch quốc tế 9 tháng là 3,3 triệu khách chỉ tăng 5,9 % so với cùng kỳ năm trước
[28] Các thị trường giảm mạnh nhất là Nhật Bản, Hàn Quốc, châu Âu
[29]Trao đổi với VnExpress
[30] Ông Hoàng Tuấn Anh - Bộ trưởng Văn hóa Thể thao và Du lịch nhận xét tình hình kinh tế thế giới khủng hoảng đã ảnh hưởng lớn đến du lịch
[31] Một thời gian dài giá xăng dầu tăng giá vé máy bay đến Việt Nam tăng gấp đôi
[32] Mục tiêu đón 4,8 - 5 triệu khách quốc tế sẽ khó thành hiện thực

48
[33]Theo ông Tuấn Anh năm ngoái Malaysia thu hút 21 triệu khách tăng 16%
[34] Năm nay nước này dự kiến tăng khoảng 20% nhưng 9 tháng đầu năm chỉ tăng 6% Singapore năm ngoái đón 10 triệu lượt khách tăng 6,7% thì 9 tháng đầu năm nay chỉ tăng 0,1%
[35] Trong thời điểm khó khăn này chiến lược của ngành du lịch là thu hút khách ở thị trường gần như Hong Kong, Đài Loan, Nhật Bản, Hàn Quốc, Thái Lan và những tỉnh ven biển Trung Quốc như Quảng Đông, Quảng Tây, Vân Nam - người đứng đầu ngành du lịch Việt Nam nói
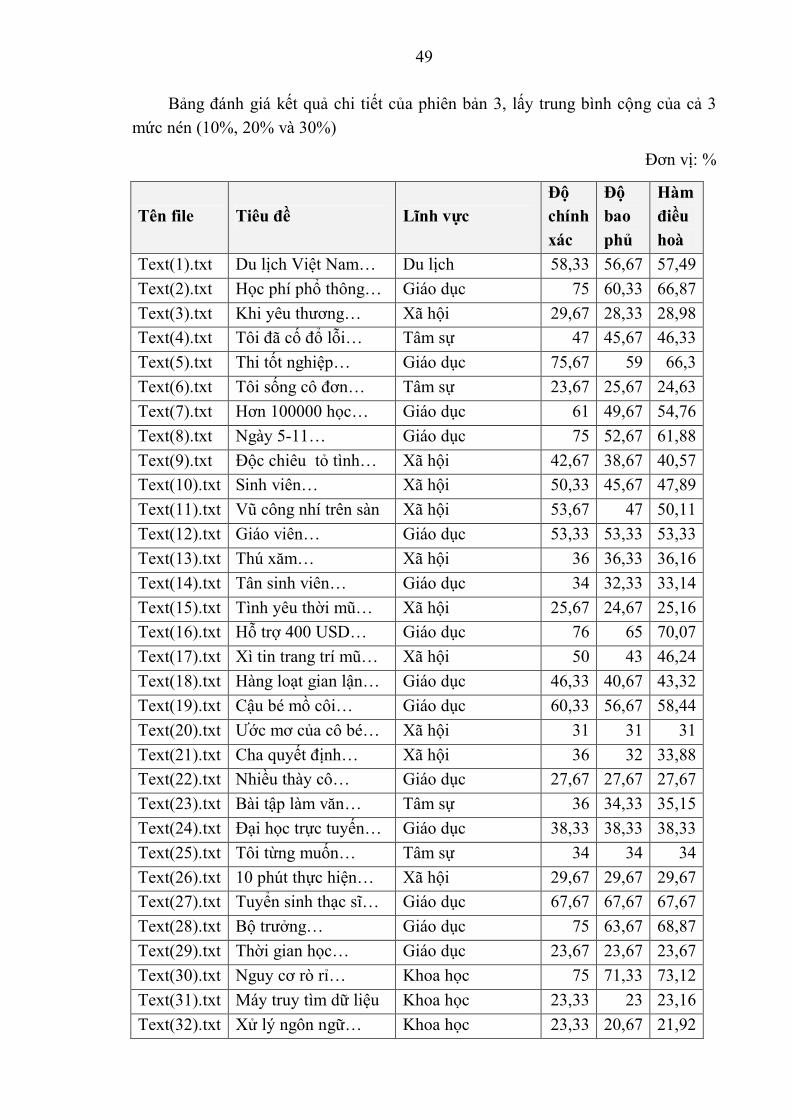
49
Bảng đánh giá kết quả chi tiết của phiên bản 3, lấy trung bình cộng của cả 3 mức nén (10%, 20% và 30%)
Đơn vị: %
Tên file Tiêu đề Lĩnh vực Độ chính xác
Độ bao phủ
Hàm điều hoà
Text(1).txt Du lịch Việt Nam… Du lịch 58,33 56,67 57,49 Text(2).txt Học phí phổ thông… Giáo dục 75 60,33 66,87 Text(3).txt Khi yêu thương… Xã hội 29,67 28,33 28,98 Text(4).txt Tôi đã cố đổ lỗi… Tâm sự 47 45,67 46,33 Text(5).txt Thi tốt nghiệp… Giáo dục 75,67 59 66,3 Text(6).txt Tôi sống cô đơn… Tâm sự 23,67 25,67 24,63 Text(7).txt Hơn 100000 học… Giáo dục 61 49,67 54,76 Text(8).txt Ngày 5-11… Giáo dục 75 52,67 61,88 Text(9).txt Độc chiêu tỏ tình… Xã hội 42,67 38,67 40,57 Text(10).txt Sinh viên… Xã hội 50,33 45,67 47,89 Text(11).txt Vũ công nhí trên sàn Xã hội 53,67 47 50,11 Text(12).txt Giáo viên… Giáo dục 53,33 53,33 53,33 Text(13).txt Thú xăm… Xã hội 36 36,33 36,16 Text(14).txt Tân sinh viên… Giáo dục 34 32,33 33,14 Text(15).txt Tình yêu thời mũ… Xã hội 25,67 24,67 25,16 Text(16).txt Hỗ trợ 400 USD… Giáo dục 76 65 70,07 Text(17).txt Xì tin trang trí mũ… Xã hội 50 43 46,24 Text(18).txt Hàng loạt gian lận… Giáo dục 46,33 40,67 43,32 Text(19).txt Cậu bé mồ côi… Giáo dục 60,33 56,67 58,44 Text(20).txt Ước mơ của cô bé… Xã hội 31 31 31 Text(21).txt Cha quyết định… Xã hội 36 32 33,88 Text(22).txt Nhiều thày cô… Giáo dục 27,67 27,67 27,67 Text(23).txt Bài tập làm văn… Tâm sự 36 34,33 35,15 Text(24).txt Đại học trực tuyến… Giáo dục 38,33 38,33 38,33 Text(25).txt Tôi từng muốn… Tâm sự 34 34 34 Text(26).txt 10 phút thực hiện… Xã hội 29,67 29,67 29,67 Text(27).txt Tuyển sinh thạc sĩ… Giáo dục 67,67 67,67 67,67 Text(28).txt Bộ trưởng… Giáo dục 75 63,67 68,87 Text(29).txt Thời gian học… Giáo dục 23,67 23,67 23,67 Text(30).txt Nguy cơ rò rỉ… Khoa học 75 71,33 73,12 Text(31).txt Máy truy tìm dữ liệu Khoa học 23,33 23 23,16 Text(32).txt Xử lý ngôn ngữ… Khoa học 23,33 20,67 21,92
50
Text(33).txt Phát hiện phóng xạ… Khoa học 71,33 71,33 71,33 Text(34).txt Nhận dạng ký tự… Khoa học 28,67 28,67 28,67 Text(35).txt Ứng dụng xử lý... Bài báo khoa học 23,33 23,33 23,33 Text(36).txt Tại sao Apple… Khoa học 33 30,67 31,79 Text(37).txt Vua thổ cẩm… Xã hội 40 36,33 38,08 Text(38).txt Người mê thằn lằn Xã hội 49,67 47,67 48,65 Text(39).txt Cụ già sở hữu… Xã hội 31,67 30 30,81 Text(40).txt Xử lý ngôn ngữ Bài báo khoa học 33,67 32,67 33,16 Text(41).txt Tiếng Việt 'giàu'… Bài báo khoa học 24,33 25 24,66 Text(42).txt Lưu trữ thông tin… Khoa học 57,33 49,67 53,23 Text(43).txt Những người trẻ… Xã hội 38 38 38 Text(44).txt Mỗi ngày một triệu… Giáo dục 60,33 47,67 53,26 Text(45).txt Lắp camera… Giáo dục 75 64 69,06 Text(46).txt Thầy giáo… Xã hội 78,33 75 76,63 Text(47).txt Trường mầm non… Giáo dục 61 61 61 Text(48).txt Phụ huynh thu tiền… Giáo dục 56,33 56,33 56,33 Text(49).txt Giới trẻ mê nhảy… Xã hội 54,67 43,67 48,55 Text(50).txt Tâm sự thầy cô… Giáo dục 43 39,67 41,27


















