
Logging, Storing, Processing, Correlating · Logging, Storing, Processing, Correlating A scalable...
31
Logging, Storing, Processing, Correlating A scalable logging infrastructure for the enterprise (with all the bells and whistles) Mario Schrön & Emre Bastuz
Transcript of Logging, Storing, Processing, Correlating · Logging, Storing, Processing, Correlating A scalable...

Logging, Storing, Processing, CorrelatingA scalable logging infrastructure for the enterprise
(with all the bells and whistles)
Mario Schrön & Emre Bastuz

Log data - treasure and burden

A treasure ... right!
• Log data is invaluable for
• Troubleshooting purposes
• Statistics and report creation
• Event detection (security events, outages, ... )

Definitely a pain
• In an enterprise environment the storage required for the logs is tremendous
• Processing the data is not easy due to the high volume
• Querying the data is even harder

Legacy approaches • „Let´s put it all in a relational database and access it with a
PHP webinterface“: been there, seen it, might or might not work
• „Let´s put it all in flat files and process them with a Perl script (overnight)“: scales far better, maintaining this programatic approach is hard
• „Vendor XYZ has implemented a logging server for his product“: they all do but the solutions are specific for a certain technology. Having to maintain logging systems for x vendors also does not scale

Wouldn´t it be cool if we had a logging infrastructure with ...
• ... scalable storage • ... scalable log processing capacity• ... an interface for querying the data • ... an interface for correlating the data
... and all of that usable with many device types and device vendors?

Open source to the rescue
• There are some kick-ass technologies out there
• Flume log collection
• Cassandra data storage
• Solr data indexing and searching
• OSSIM normalization and correlation

Open source to the rescue
• There are some kick-ass technologies out there
• Pig & PigLatin

What is „Flume“ anyway?
• Flume is an open source project, implementing a distributed logging system with no single point of failure
• For further details please see: https://www.cloudera.com/

What is „Cassandra“ anyway?
• Cassandra is an open source project, implementing the concept of a distributed NoSQL database
• It has been donated by Facebook to the public
• It´s extremely „cloudish“
• It´s a multi master, massively scalable implementation
• It´s pretty state of the art
• It´s cool
• For further details please see: http://cassandra.apache.org/

What is „Solr“ anyway?
• Solr is an open source project, implementing an enterprise class search engine
• It´s cool too
• For further details please see: http://lucene.apache.org/solr

What is „OSSIM“ anyway?
• OSSIM is an open source project, implementing a security information and event management system, including normalization and correlation
• Includes support for log normalization for a wide range of technologies
• For further details please see: http://www.alienvault.com/

What is „Pig“ anyway?
• Pig is an interface for executing queries against a cluster storage
• PigLatin is a minimalistic programming language for specifying queries
• For further details please see: http://pig.apache.org/

Let´s build this!
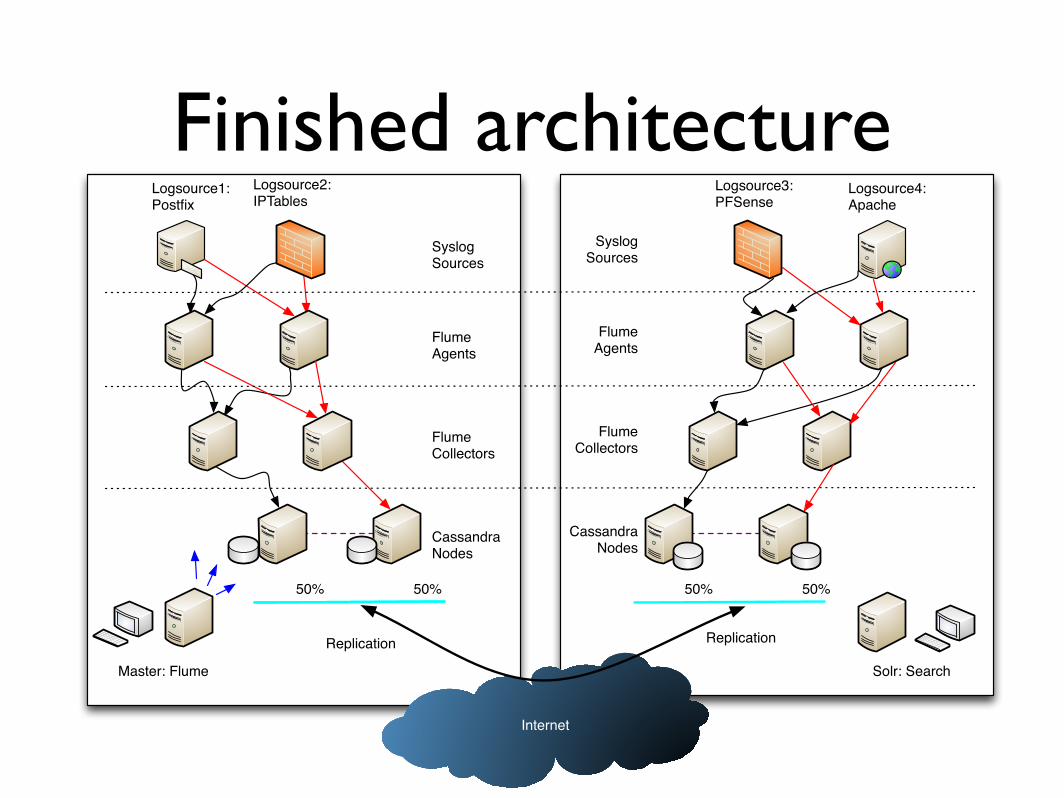
Finished architecture
Master: Flume
Logsource1: Postfix
Logsource2: IPTables
Logsource4: Apache
Logsource3: PFSense
Internet
50% 50% 50% 50%
Replication Replication
Flume Agents
Flume Agents
Flume Collectors
Flume Collectors
CassandraNodes
CassandraNodes
SyslogSources
SyslogSources
Solr: Search

Flume Architecture Overview

Flume Architecture Configuration

Cassandra Intro What it´s not

Cassandra Intro What it´s not
select Post.title, User.username from Post p, User u where p.AuthorID = u.ID and username = „hans“

Cassandra Intro Key-Value Datamodel
• A Column
{ // this is a column name: "emailAddress", value: "[email protected]", timestamp: 123456789}
• A SuperColumn
{ // this is a SuperColumn name: "homeAddress", // with an infinite list of Columns value: { // note the keys is the name of the Column street: {name: "street", value: "1234 x street", timestamp: 123456789}, city: {name: "city", value: "san francisco", timestamp: 123456789}, zip: {name: "zip", value: "94107", timestamp: 123456789}, }}

Cassandra Conclusion
• Relational databases are more complex but more flexible
• NoSQL is simpler and more scalable
• SQL vs. NoSQL = Flexibility vs. Scalability
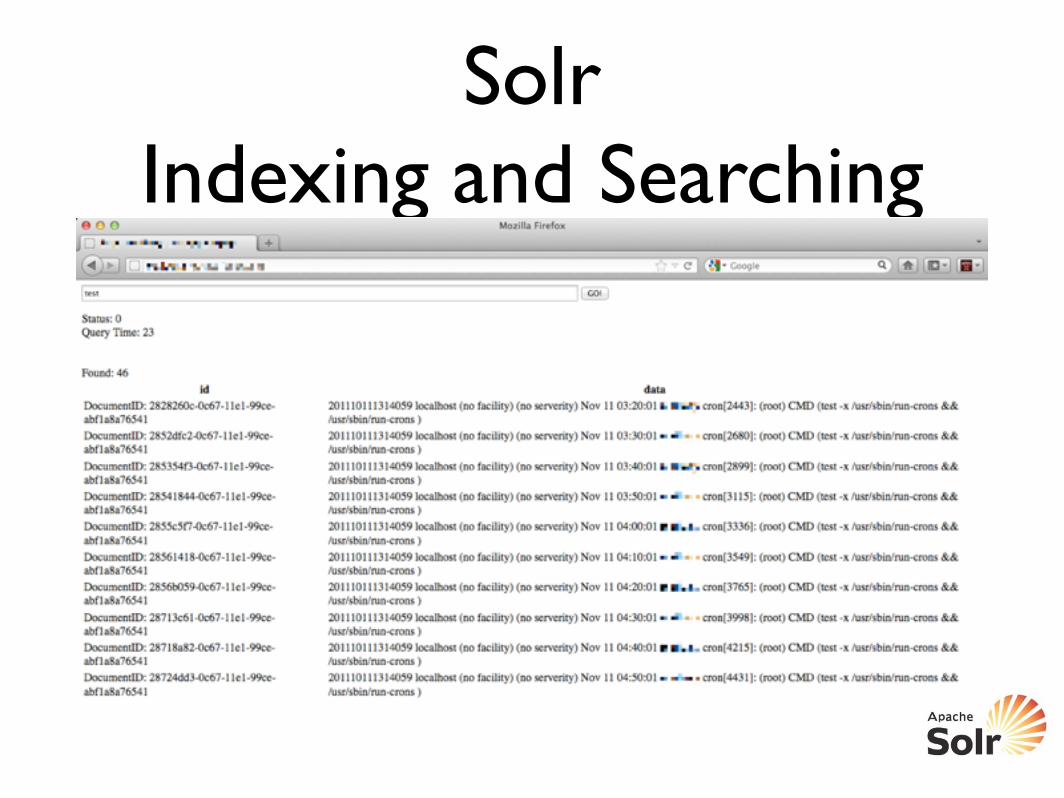
Solr Indexing and Searching

Normalization and OSSIM
• OSSIM uses a relational database for log storage
• Log data is split into different columns and saved in the DB
• The fields are all the same for different kinds of technologies

OSSIM DB Schemamysql> use ossim; Database changed mysql> describe event; +-----------------+------------------+------+-----+-------------------+-----------------------------+ | Field | Type | Null | Key | Default | Extra | +-----------------+------------------+------+-----+-------------------+-----------------------------+ | id | bigint(20) | NO | PRI | NULL | | | timestamp | timestamp | NO | MUL | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | | tzone | float | NO | | 0 | | | sensor | text | NO | | NULL | | | interface | text | NO | | NULL | | | type | int(11) | NO | | NULL | | ... | protocol | int(11) | YES | | NULL | | | src_ip | int(10) unsigned | YES | | NULL | | | dst_ip | int(10) unsigned | YES | | NULL | | | src_port | int(11) | YES | | NULL | | | dst_port | int(11) | YES | | NULL | | | event_condition | int(11) | YES | | NULL | | | value | text | YES | | NULL | | ... | filename | text | YES | | NULL | | | username | text | YES | | NULL | | | password | text | YES | | NULL | | | userdata1 | text | YES | | NULL | | | userdata2 | text | YES | | NULL | | | userdata3 | text | YES | | NULL | | | userdata4 | text | YES | | NULL | | | userdata5 | text | YES | | NULL | | | userdata6 | text | YES | | NULL | | | userdata7 | text | YES | | NULL | | | userdata8 | text | YES | | NULL | | | userdata9 | text | YES | | NULL | | ... +-----------------+------------------+------+-----+-------------------+-----------------------------+ 40 rows in set (0.00 sec)

OSSIM Plugin Config
• OSSIM uses the concept of plugins
• Each plugin has a config file and datasource
• Many plugins with a data source „log“ are available: # cd /etc/ossim/agent/plugins # grep "source=log" * | wc -l 118

OSSIM & Logs Supported Technologies
# grep "source=log" * apache.cfg:source=log bluecoat.cfg:source=log cisco-asa.cfg:source=log cisco-ids.cfg:source=log cisco-ips-syslog.cfg:source=log cisco-nexus-nx-os.cfg:source=log cisco-pix.cfg:source=log cisco-router.cfg:source=log cisco-vpn.cfg:source=log f5.cfg:source=log juniper-srx.cfg:source=log juniper-vpn.cfg:source=log nagios.cfg:source=log netscreen-firewall.cfg:source=log netscreen-igs.cfg:source=log netscreen-manager.cfg:source=log netscreen-nsm.cfg:source=log pf.cfg:source=log postfix.cfg:source=log tarantella.cfg:source=log tippingpoint.cfg:source=log trendmicro.cfg:source=log
... and many many more

OSSIM Mapping of Log 2 DB Schema

Pig Example Std. Query
rows = LOAD 'cassandra://Keyspace1/FlumeData' USING CassandraStorage() AS (key, columns: bag {T: tuple(name, value)}); counted = foreach (group rows all) generate COUNT($1); dump counted;

Pig UDF based Query

Questions?

Thank you! :-)

















