
Link Resolvers and Knowledge Bases – Why are they so important? Sarah Pearson University of...
29
Link Resolvers and Knowledge Bases – Why are they so important? Sarah Pearson University of Birmingham Co-Chair KBART Working Group
-
Upload
austen-darren-short -
Category
Documents
-
view
217 -
download
0
Transcript of Link Resolvers and Knowledge Bases – Why are they so important? Sarah Pearson University of...

Link Resolvers and Knowledge Bases – Why are they so important?
Sarah Pearson
University of Birmingham
Co-Chair KBART Working Group

Agenda
What is OpenURL technology?
Why are knowledge bases important?
Problems with knowledge base metadata
How to make content more visible to users
The role of KBART
Feedback from you!
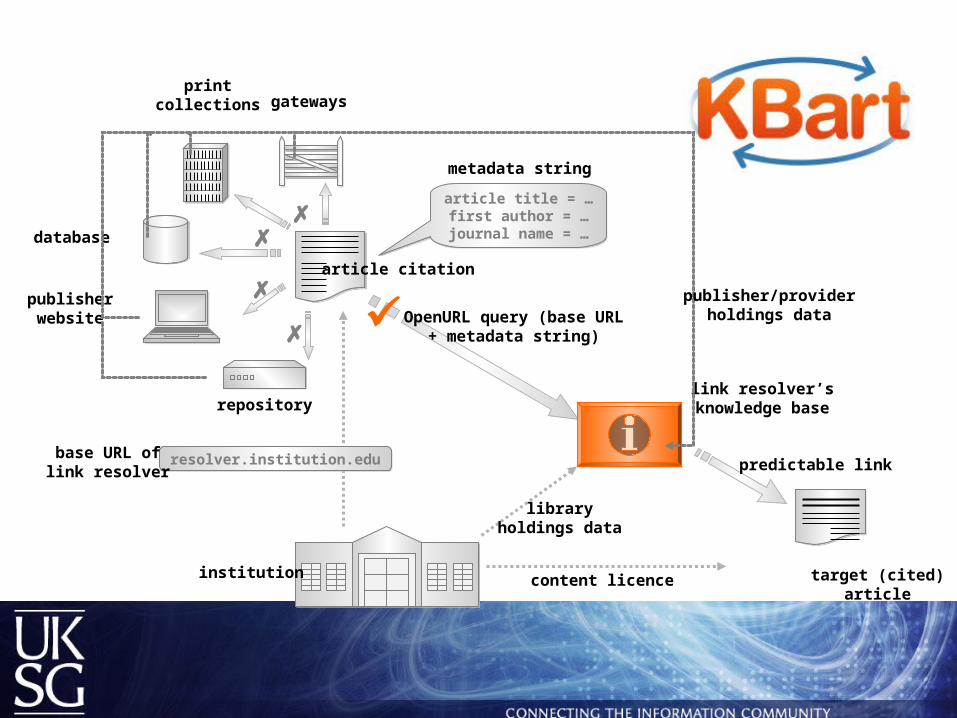
institution
repository
publisherwebsite
database
printcollections gateways
article citation
article title = …first author = …
journal name = …
article title = …first author = …
journal name = …
metadata string
OpenURL query (base URL+ metadata string)
resolver.institution.eduresolver.institution.edubase URL oflink resolver
link resolver’sknowledge base
publisher/providerholdings data
libraryholdings data
content licence
target (cited)article
predictable link

OpenURL query (base URL+ metadata string)
Make their content OpenURL compliant by:
– Creating outbound OpenURL links
Make their content “KB compliant” by:
– Telling the knowledge base what content they have and how to link to it
Which bits do publishers do?
publisher/providerholdings data
link resolver’sknowledge base
Together: “link-resolver compliance”

What does the link resolver do?
Takes an OpenURL and extracts the article metadata– http://baseurl.institution.edu/content?
genre=article&issn= 1234-5679&volume=53&issue=3&page=14
Compares article metadata to knowledge base – where is the article available?
– which version is preferred by the library?
Puts together a predictable link to this versiontarget (cited)
article
predictable link
– http://baseurl.institution.edu/content?genre=article&issn=
1234-5679&volume=53&issue=3&page=14

What bits do libraries do?
Have a link resolver! And register it with providers
Customise its knowledge base with their own holdings data
institution
resolver.institution.eduresolver.institution.edubase URL oflink resolver
libraryholdings data
link resolver’sknowledge base

Link resolver servicesLink Resolver Services
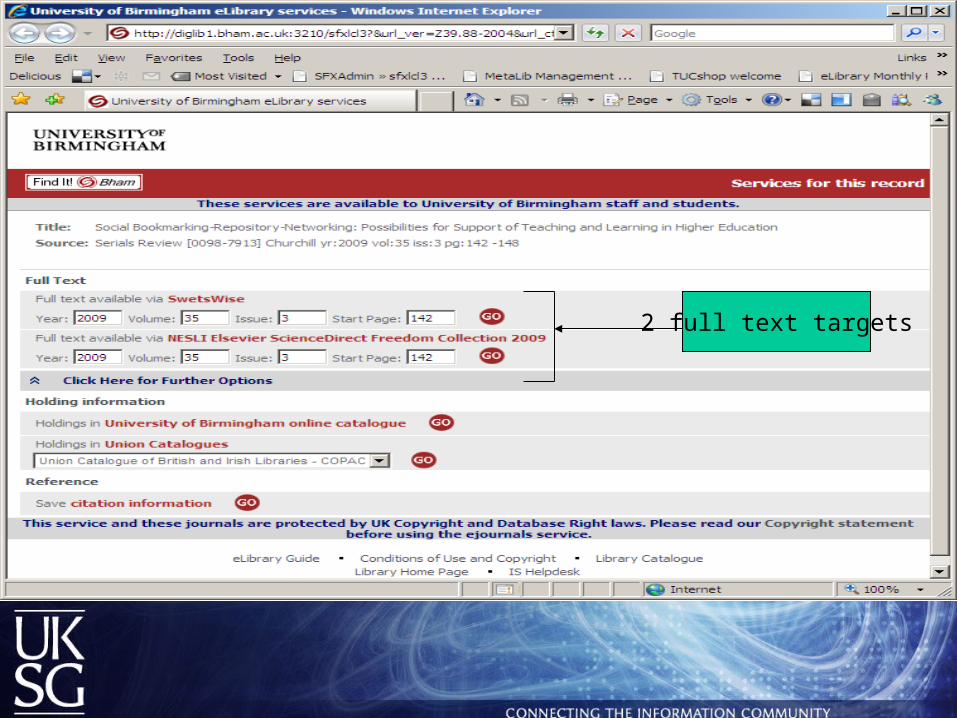
2 full text targets

Full text article

What is a knowledge base?
A database
Contains information about web resources – e.g. what journal holdings are available in JSTOR
– and how you link to articles in them
Contains information about the resources a library has licensed/owns– May contain electronic and print holdings (in addition
to a number of other services)

So why is it so important?
It knows where all the content is
It knows which versions the library is able to access
So – it’s the only place that can get a user to an “appropriate copy”

And that means?......
More content visible to end users
Content linking is more accurate for end users
Increase in content usage
Maximum reach for authors and editors
Better return on investment for library
Favourable renewal decision
Protection of revenue for content providers

Knowledge Bases – Measure of Success Better access for users
– Fewer false positives: saying it’s available when its not
– Fewer false negatives: saying it’s not available when it is
Best-case scenario: – IF a user is seeking an item, and the library offers access
to it through exactly 3 online resources,
– THEN the OpenURL resolver returns exactly 3 accurate links to the full text
– AND the ‘best’ resources appear first

Problems in the supply chain
Wrong data
– Content provider gives wrong metadata for title to knowledge base
– Link resolver uses bad metadata to make link
– Link does not resolve to correct target
– Dead end

Outdated data
– Provider tells knowledge base it has a particular issue
– Link resolver links to an article from it
– Issue has been removed
– Dead end
– Or, provider doesn’t notify that issue is now live
– So no traffic from link resolvers to that issue!
Problems in the supply chain
That’s not
good!

Problems in the supply chain
Lack of knowledge of its importance means:
some content providers aren’t using it
many others aren’t investing in more accurate & timely metadata transfer

And when the supply chain breaks …
Researchers will go to …

Knowledge Bases And Related Tools
UKSG and NISO collaborative project
UKSG 2007 research report,“Link Resolvers and the Serials Supply Chain”
To improve navigation of the e-resource supply chain by
Ensuring timely transfer of accurate data to knowledge bases, ERMs etc.
Right. So. What is KBart?

Guidelines
Education
Information hub
What is KBart’s mission?

Definition of the problems
1. Lack of uptake of OpenURL technology
2. Poor metadata held in knowledge bases
3. Inaccurate implementation of OpenURL syntax by OpenURL sources
4. Poor inbound URL syntax management by OpenURL targets

Areas which KBART is addressing Identifier inconsistencies
Title inconsistencies
Incorrect date coverage
Inconsistent date formatting
Inconsistencies in content coverage description
Embargo inconsistencies
Data format and exchange
Outdated holdings data
Lack of customisation

Recommendations
Phase I – encompasses the more fundamental recommendations from original research:
– File format
– Mandatory and optional fields
– Common approaches for presenting data within fields
– Handling of packages
– Frequency of data update
– Collection mechanism

Mandatory and optional fields Publication title Print-format identifier (ie, ISSN, ISBN, etc.) Online-format identifier (ie, eISSN, eISBN, etc.) Date of first issue available online Number of first volume available online Number of first issue available online Date of last issue available online (or blank, if coverage is to present) Number of last volume available online (or blank, if coverage is to present) Number of last issue available online (or blank, if coverage is to present) Title-level URL First author (for monographs) Title ID Embargo Coverage type (abstracts/fulltext) Coverage notes Publisher name (if not given in the file’s title)

Going public
Final Phase I KBart report now released!
www.uksg.org/kbart
http://www.niso.org/workrooms/kbart
Feedback and suggestions welcomed!
Phase II started in March

Phase II / Next Steps Change of leadership and team members
Endorsement / Compliance / Engagement
Definitions for global vs local updates
Consortia-specific metadata transfer
Institution-specific metadata transfer
Review of metadata transfer for e-books
Open access material

Phase II Working Group
Jason Price Claremont Colleges / California Digital Library Elizabeth Stevenson Edinburgh University Chad Hutchens University of Wyoming Sarah Pearson University of Birmingham Paul Moss OCLC Sheri Meares EBSCO Christine Stohn Ex Libris Sherrard Ewing Serials Solutions Matthew Llewellin Royal Society Andreas Biedenbach Springer Marieke Heins Swets Ruth Wells Taylor & Francis Rose Robinson Publishing Technology

Let’s look at those benefits again…… More content visible to end users
Content linking is more accurate for end users
Increase in content usage
Maximum reach for authors and editors
Better return on investment for library
Favourable renewal decision
Protection of revenue for content providers

Learn more
www.uksg.org/kbart http://www.niso.org/workrooms/kbart
Sarah Pearson – KBart co-chair
KBart interest group
http://www.niso.org/lists/kbart_interest/

Your Turn!
Comments on knowledge base engagement
Feedback on KBART recommendations to date
Suggestions for future work
Endorsement / take-up
Supply chain involvement


















