
Linearized Nelson-Siegel and Svensson models for the...
48
Linearized Nelson-Siegel and Svensson models for the estimation of spot interest rates GeneviLve Gauthier, Jean-Guy Simonato HEC MontrØal January 18, 2009 Abstract Linearized versions of the Nelson-Siegel (1987) and Svensson (1994) models for es- timating zero-coupon yield curves from cross-section samples of coupon-bearing bonds are developed and analyzed. It is shown how these models can be made linear in the level, slope and curvature parameters and how prior information about these parame- ters can be conveniently incorporated in the estimation procedure. The parameters estimation of the original models involves optimization procedures that su/ers from the presence of many local optimums and is costly in computation time. This paper presents a much more e/ective estimation method in terms of precision and computa- tion time. More precisely, the performance of the linearized models relative to that of their original versions are assessed in a Monte Carlo setting and with a sample of U.S. government bonds. The results reveal that the linearized models compare favorably to the original models in terms of precision and computing e/ort. Probabilistic measures of the multiplicity of solution problem show that the linearized versions have fewer local optima and higher probabilities of obtaining a global optimum when compared to their original versions. Gauthier acknowledge the nancial support of the National Science and Engineering Research Council of Canada (NSERC) and HEC MontrØal. Simonato acknowledges the nancial support of HEC MontrØal. We thank Mathieu Boudreault for helpful comments. 1
Transcript of Linearized Nelson-Siegel and Svensson models for the...

Linearized Nelson-Siegel and Svensson models for theestimation of spot interest rates
Geneviève Gauthier, Jean-Guy Simonato�
HEC Montréal
January 18, 2009
Abstract
Linearized versions of the Nelson-Siegel (1987) and Svensson (1994) models for es-timating zero-coupon yield curves from cross-section samples of coupon-bearing bondsare developed and analyzed. It is shown how these models can be made linear in thelevel, slope and curvature parameters and how prior information about these parame-ters can be conveniently incorporated in the estimation procedure. The parametersestimation of the original models involves optimization procedures that su¤ers fromthe presence of many local optimums and is costly in computation time. This paperpresents a much more e¤ective estimation method in terms of precision and computa-tion time. More precisely, the performance of the linearized models relative to that oftheir original versions are assessed in a Monte Carlo setting and with a sample of U.S.government bonds. The results reveal that the linearized models compare favorably tothe original models in terms of precision and computing e¤ort. Probabilistic measuresof the multiplicity of solution problem show that the linearized versions have fewerlocal optima and higher probabilities of obtaining a global optimum when comparedto their original versions.
�Gauthier acknowledge the �nancial support of the National Science and Engineering Research Councilof Canada (NSERC) and HEC Montréal. Simonato acknowledges the �nancial support of HEC Montréal.We thank Mathieu Boudreault for helpful comments.
1

1 Introduction
The term structure of spot interest rates describes, at a given date, the yields of zero coupon
bonds according to their maturities. These are essential inputs used for many purposes such
as pricing derivatives, valuing investment projects or computing risk measures. It is therefore
important to have available accurate and e¢ cient approaches for computing these quantities.
Except for short maturities, spot interest rates are unobserved and must be estimated from
samples of coupon bond prices. Several approaches are available to perform this task. This
paper focuses on the Nelson and Siegel (1987) and Svensson (1994) approaches and develop
linearized versions of these models for estimating zero-coupon yield curves from samples of
coupon-bearing bonds. As shown in this study, these linearized versions obtain better yield
estimates, especially for the short end of the yield curve which is often estimated with low
precision with the original methods. These linearized versions also require less computing
e¤ort. For example, on a 10-year sample of U.S. government bonds, the linearized Nelson-
Siegel model is found to be, on average, 40 times faster than the original model. Finally,
measures of the multiplicity of local optimum problem shows that the linearized models have
higher probabilities of converging to a global optimum than their original counterparts.
In the literature, the approaches for zero-coupon yield curve estimation can be loosely
classi�ed in two categories. The �rst group contains approaches assuming speci�c dynamics
for the instantaneous spot interest rate and providing formulas for yield curves under di¤erent
assumptions about the risk premium. Important contributions to this class of models are
Vasicek (1977), Cox, Ingersoll, Ross (1985) and Du¢ e and Kan (1996). A second group
of methods �ts the interest rate curve at a point in time but does not impose a dynamic
2

structure to the spot rates. Well-known models from this group include McCulloch (1975)
cubic spline approach, Fama-Bliss (1987) forward rate extraction method and the Nelson-
Siegel (1987) �exible functional form. Because the Nelson-Siegel (1987) �exible functional
form can parsimoniously capture the di¤erent possible shapes of the interest rate curves, it
is a popular choice among academics and market participants. For example, as reported
by the Bank for International Settlements (2005), several central banks1 use this method
or a modi�ed version proposed in Svensson (1994) to estimate zero-coupon yield curves. In
the academic literature, Diebold and Li (2006), Mönch (2006), De Pooter et al. (2007) and
Fabozzi et al. (2005) have shown that a dynamic Nelson-Siegel factor based approach can
reproduce key features of U.S. interest rate curves with good forecasting performances.
Despite these good empirical performances, Nelson-Siegel type approaches are not free
of drawbacks. A �rst concern is theoretical. As show in Bjork and Christensen (1999), this
model is not theoretically arbitrage free. In a recent contribution, Christensen, Diebold and
Rudebusch (2007) reconcile the �exible functional form modeling setup with the absence
of arbitrage by developing a class of dynamic Nelson-Siegel type models that ful�ll the no-
arbitrage constraints. Coreneo et al. (2008) �nd that the classic Nelson-Siegel model is not
signi�cantly di¤erent from the three-factor no arbitrage model of Christensen et al. (2007)
model when it is applied to US zero-coupon yield-curve data. According to Coreneo et al.
(2008), such a result is obtained because the Nelson-Siegel model is su¢ ciently �exible and
applied to data generated in a competitive trading environment. Therefore, most of the yield
curves generated by the model ful�ll the no-arbitrage constraints in a statistical sense.
A second concern of the Nelson-Siegel (1987) type approaches is the di¢ culty with which
1Belgium, Finland, France, Germany, Italy, Norway, Spain and Switzerland
3

it can be �tted to a cross-section of coupon bond prices. As discussed in Bolder and Strélisky
(1999), De Pooter (2007) and Gimeno and Nave (2006), this problem is not trivial due to the
presence of multiple local optima. Because the parameters must be estimated with non-linear
optimization routines requiring important computational resources, this di¢ culty is further
magni�ed when several starting points are used to reduce the chances of being trapped in a
local optimum. Even when the model is used in a dynamic setting such as the one proposed
in Diebold and Li (2006), this di¢ culty remains a concern because a cross sectional �t at
each point in time is a required step. This study thus focuses on the cross-sectional �tting
problem of the Nelson-Siegel and Svensson models and proposes linearized versions of the
models that are easier to estimate while providing better empirical performances.
With bootstrapped samples of zero-coupon yields, Diebold and Li (2006) tackle the cross-
sectional �tting problem by �xing the parameter governing the position of the hump in the
�exible form. The Nelson-Siegel functional form then becomes linear in the other three
parameters, which can be estimated by linear regression. Searching over the di¤erent possible
values of the hump parameter then provides a convenient way to identify an optimum. This
approach is however possible only if one deals with a sample of zero-coupon bonds or yields.
Although zero-coupon bond prices can be bootstrapped for countries with liquid Treasury
�xed income markets, it is not always the case that such procedures are feasible for countries
with thinner markets or for other categories of �xed income instruments such as corporate
bonds. When dealing with a sample of coupon bonds, this simpli�cation is not possible.
The �rst contribution of this study is thus to show how this idea can be adapted to the
case of a sample of coupon bonds. To do this, a procedure relying on a �rst order Taylor
expansion is proposed to develop the linearized versions of the Nelson-Siegel and Svensson
4

models. These linearized versions reduce the dimension of the parameter space over which
a non-linear optimization is required. An e¢ cient random grid search can then be done to
explore the parameter space and raise the chances of getting a global optimum. As it will
be shown by our empirical results, the computation times of the linearized Nelson-Siegel are
around 40 times smaller than those of the original Nelson-Siegel model.
An interesting feature of the Nelson-Siegel-Svensson approach is the �nancial interpreta-
tion that can be attached to the parameters of the functional form. These parameters are
interpreted as the yield on a long-term zero-coupon bond, the slope, curvature and hump
position of the spot rate term structure. Because �nancial analysts often have strong pri-
ors about some of these values, introducing this information in the estimation procedure
should be bene�cial. Another contribution of our study thus addresses how prior informa-
tion can be introduced in our linearized Nelson-Siegel-Svensson framework with samples of
zero-coupon or coupon bonds. The prior information takes the form of expected parameter
values while con�dence levels about these expectations are characterized by standard devi-
ations. As it will be shown by the simulation results, incorporating this prior information
provides stability to parameters and yields estimates.
As a �nal contribution, we perform an empirical study measuring the multiplicity of
solution problem associated with the Nelson-Siegel-Svensson models and our linearized ver-
sions in a probabilistic setup. Building on the work of Robbins (1968), we compute monthly
estimates of the probability of not having found the global optimum with U.S. government
bonds data for years 1987 to 1996. Because the approach requires estimating repeatedly the
model with random starting points, the linearized models allow estimating this probability
in a fraction of the time required with the original model. Our results show that the lin-
5

earized versions usually have fewer local optima and higher probabilities of �nding the global
optimum than the original models.
The paper is organized as follows. In Section 2, we present the original models and
an assessment of the multiplicity of local optima problem with a U.S. government coupon
bond sample. Our linearized versions of these models are then described in Section 3. The
approach for introducing prior information is examined in Section 4. Section 5 shows the
results of simulation studies comparing the performance of the proposed algorithms. Finally,
Section 6 examines estimates of the probability of not having found the global optimum.
Section 7 concludes.
2 The Nelson-Siegel (1987) and Svensson (1994) mod-els
We describe here the Nelson-Siegel (1987) and Svensson (1994) models and de�ne the no-
tation and concepts that will be used to introduce our linearized algorithms in the next
sections. An assessment of the multiplicity of solution problem for these models is also
provided here with monthly samples of U.S. government bonds.
2.1 The �exible functional forms
Nelson-Siegel (1987) specify the spot interest rates as a �exible functional form given by2:
y (T ; �) = �+ ��1 (T ; �1) + �2 (T ; �) (1)
2The formulation found in Diebold and Li (2006) is used here. This formulation is equivalent to theoriginal Nelson and Siegel (1987) but is easier to interpret.
6

where T is the maturity expressed in years and � = (�; �; ; �; �)| is a vector of unknown
constant parameters. Moreover,
�1 (T ; �) =�
T
�1� e�
T�
�and �2 (T ; �) =
�
T
�1� e�
T�
�� e�
T� :
The �nancial interpretation of the parameters in � can be uncovered by looking at the
behavior of �1 (T ; �) and �2 (T ; �) as T varies. For a �xed positive value of � , �1 (�) tends
to one as T ! 0 and then gradually decreases to zero as T increases. �2 (�) starts at zero,
increases gradually and then decreases to zero again as T is increased furthermore. It is
thus clear that, as the maturity increases to in�nity, y (T ; �) tends to �:As such, � can
then be interpreted as the long term yield. Finally, as the maturity goes to zero, the yield
converges to � + �: This combination of parameters is thus interpreted as the short-term
rate. This allows � to be interpreted as the slope of the term structure which corresponds to
the di¤erence between the short-term and the long term rates. The parameter � determines
the position of the hump in the spot rate curve while controls the importance of this
hump. In a cross section study, Diebold and Li (2006) found a large correlation between
and what they called the curvature which they de�ned as the di¤erence between the slope
of the middle and long term rates and the slope of the short and middle rates.
Svensson (1994) proposed an extension of the Nelson-Siegel (1987) model by allowing
for an additional hump position in the spot rate curve with a parameter controlling for the
sensitivity to this hump:
y (T ; �) = �+ ��1 (T ; �) + �2 (T ; �) + ��3 (T ; �)
with
�3 (T ; �) =�
T
�1� e�
T�
�� e�
T�
7

and � = (�; �; ; �; �; �)| : This additional component makes it easier to �t term structure
shapes with more that one local maximum or minimum along the maturity dimension.
2.2 Parameter estimation: the zero-coupon bond case
When dealing with a sample of zero-coupon bond yields, because we do not expect a perfect
�t, we write the observed yields as:
yobs (Ti) = y (Ti; �) + "i;
for i 2 f1; 2; :::; ng where " = ("1; :::; "n)> is a random vector with expectation E ["] = 0n�1
and covariance matrix �" = E�"">
�= �2"In, where In is the n � n identity matrix and n
is the number of di¤erent maturities observed in the sample. Introducing an error term is
justi�ed since yields to maturity of zero-coupon bonds are usually estimated from a sample
of coupon paying bonds using bootstrapping techniques. This is usually done at the cost of
some approximation errors.
For the case of the Nelson-Siegel model, the unknown parameter vector � = (�; �; ; �)|
is then chosen to minimize the sum of squared errors de�ned as:
Q (�; �; ; �) =
nXi=1
(�+ ��1 (Ti; �) + �2 (Ti; �)� yobs (Ti))2 :
Because Q (�; �; ; �) might have several local optima, the design of a robust optimization
procedure is important. A naive algorithm allowing the exploration of the parameter space
can be designed as follows:
1. Construct a four-dimensional hyperbox�b�; b�
���b�; b�
���b ; b
���b� ; b�
�de�ning
the acceptable parameter space over which a search will be performed.
8

2. Generate W random starting points � = (A;B;�;�) according to a uniform distrib-
ution: if u1, u2, u3 and u4 are independent uniform random variables on the interval
[0; 1] then A = b� +�b� � b�
�u1, B = b� +
�b� � b�
�u2, � = b +
�b � b
�u3 and
� = b� +�b� � b�
�u4:
3. Evaluate the objective function Q (�; �; ; �) for each of theW random starting points.
4. Perform v numerical minimizations of Q initialized with the v best starting points for
which the objective function Q is found to be the smallest in step 3.
We will refer to this procedure as the naive algorithm. In this setting, W should be
relatively large to increase the chances of reaching the global optimum.
As suggested in Nelson-Siegel (1987) and Diebold and Li (2006), if � is �xed at some
speci�c value �0, equation (1) becomes a linear function of �1 (T ; �0) and �2 (T ; �0) and can
be rewritten as:
yobs = X�0��0 + "
where ��0 = (��0 ; ��0 ; �0)> with
X�0 =
0B@ 1 �1 (T1; �0) �2 (T1; �0)...
......
1 �1 (Tn; �0) �2 (Tn; �0)
1CA and yobs =
0B@ yobs (T1)...
yobs (Tn)
1CA :
Therefore, the objective function Q�0 (�� ; �� ; � ) = Q (�; �; ; �0), viewed as a function of
three parameters, may be minimized analytically using a least squares estimator
b��0 = �X>
�0��1" X�0
��1 �X
>
�0��1" yobs
�:
Consequently, the initial objective function Q (�; �; ; �), with four arguments, may be re-
duced to a single argument function:
q (�) = Q�b�� ; b�� ; b � ; �� :9

Adapting the naive algorithm to the above modi�cation reduces the problem to a one-
dimensional random grid search with an optimization algorithm searching over � only.
The above naive algorithm can be easily adapted to the Svensson (1994) model. The
algorithm then becomes a random search and optimization over six arguments. Again, as for
the Nelson-Siegel case, it is possible to reduce the dimension of the problem by re-expressing
the initial objective function. This would reduce the original problem to a two-dimensional
random grid search with an optimization algorithm searching over � and �:
2.3 Parameter estimation: the coupon bond case
Let B (m; c; T ) denote the value of a coupon bond with a face value of 100 dollars where
m is the number of remaining coupons, c is the annual coupon rate and T is the maturity
expressed in years. The Nelson-Siegel bond price can be de�ned as
B (mi; ci; Ti; �) =
miXj=1
c(j)i � P (T
(j)i ; �); (2)
where P (T ; �) = e�y(T ;�)�T is the discount factor. The dates T (1)i < ::: < T(mi)i = Ti are the
coupon dates and the cash �ow of the ith bond at time T (j)i (assuming that the coupons
are paid twice a year) is c(j)i = 100�ci21j<mi
+�1 + ci
2
�1j=mi
�. The indicator function 1A is
worth 1 if condition A is satis�ed and zero otherwise. Because we do not expect a perfect
�t between the Nelson-Siegel prices and the observed ones, we introduce an error term:
Bobs (mi; ci; Ti) = B (mi; ci; Ti; �) + "i (3)
where " = ("1; :::; "n)> is a random vector with expectation E ["] = 0 and a diagonal covari-
ance matrix �":
10

The parameter vector, � = (�; �; ; �)| for Nelson-Siegel and (�; �; ; �; �; �)| for Svens-
son, is usually estimated by minimizing the sum of squared errors
Q (�) =nXi=1
�(B (mi; ci; Ti; �)�Bobs (mi; ci; Ti))�
1
Di
�2(4)
where Di is the modi�ed duration of the ith coupon bond. The naive algorithm may be used
to obtain the parameter estimates.
As mentioned in Svensson (1994), Bolder and Stréliski (1999) and Gürkaynak et al.
(2007), because of the nonlinear relationship between bond prices and yields, minimizing the
unweighted square pricing errors will not produce the best �t in yields. Weighting the prices
by inverse durations approximately converts the pricing errors into yield �tting errors. As
veri�ed by Gürkaynak et al. (2007), �tting the above weighted price errors generates yield
curve parameters that are virtually identical to parameters obtained from �tting yield errors.
Alternatively, it would have been possible to directly �t the yield. However, this approach
increases the computing costs by a large amount because of the additional numerical work
required by the yield conversion.
2.4 The multiplicity of solution problem
Two problems can be obtained when carrying out the Nelson-Siegel or Svenson approaches.
First, di¤erent parameter values may lead to similar yield curves. Such a result is possible
because the model is estimated from coupon bonds with �nite maturities. Over the observed
maturities, di¤erent parameters can get almost identical yield curve estimates. These yield
curves would however be di¤erent if longer maturities were considered. This indetermination
problem will be addressed in Section 4 where the use of prior information will be looked at
to favor solutions with �nancially plausible parameter values.
11

The second problem comes from the optimization procedure. The function to optimize is
not guaranteed to be convex and empirical studies show many local optima. To illustrate this
problem, we look at the distinct solutions found with a monthly sample of U.S. government
coupon bonds from the Lehman Brothers Fixed Income Database distributed by Warga
(1998) (all bonds with optional features removed). The sample of monthly prices span
January 1987 to December 1996 period. For each of the 120 months, 100 random starting
points are used to estimate the Nelson-Siegel (1987) and Svensson (1994) models with a
non-linear least-squares procedure with the weighted bond pricing errors de�ned in (4). The
number of distinct solutions are recorded and summarized in Table 1. Because the ultimate
goal is about estimating yield curves, we use the estimated yields to discriminate between the
various solutions. Two solutions are considered identical if the computed zero-coupon yields,
for maturities of 0:1, 0:2, :::, Tmax years, all have absolute discrepancies smaller than some
given threshold varying from 5 to 20 basis points. Note that Tmax is the largest maturity
observed for a given month.
For the Nelson-Siegel case, with a 10 basis points threshold, an average of 3.1 solutions
was found with a maximum of 14 and a standard deviation of 2.1. For the Svensson case,
the problem is more severe with an average of 7.4 solutions. Looking at the percentiles
also shows that the problem is pervasive for both approaches and not due to a few months
with many solutions. Table 2 looks at the detailed result obtained for the speci�c case of
September 1990 for the Nelson-Siegel case. Each solution, in terms of parameter estimates
and function values, are clearly di¤erent. Figure 1 plots the estimated yield curves for the
solutions reported in the table. As expected, these curves show di¤erent shapes and values
for the short and long-term spot rates.
12

It is clear that such results raise the question about having observed or not the global
optimum. A possible approach to answer this question is to explore more thoroughly the
parameter space with other random starting points and optimizations. As discussed in
Section 6, an estimate of the probability of not having observed the global optimum can
be computed using such a random search strategy. This estimate provides guidance for
deciding if the search should be continued or stopped. But this approach, even with only
four parameters, is costly in computer resources. For example, for the Nelson-Siegel case,
the September 1990 sample requires on average 15 seconds of computer time to perform
an optimization using function lsqnonlin from Matlab. Because several repeated non-
linear optimizations may be required to get a reasonable estimate, such computer time
is prohibitive given that several hundreds of estimations may be needed for a reasonable
probability estimate. There is thus a clear need for lowering the computing time when
estimating this model. For this purpose, next section will propose linearized versions of the
Nelson-Siegel (1987) and Svensson (1994) models cutting down the number of parameters
over which a non-linear search must be performed.
3 Linearized algorithms
3.1 One-step linearized algorithms
It is possible to adapt the dimension-reduction approach described earlier to obtain an
approximation to the system described by equation (2). Our adaptation is based on a
linearization of the discount factor P (T ; �) = exp [�y (T ; �)� T ] with the approximation
exp (x) �= 1+x . Such an approximation is accurate only if x is in the neighborhood of zero,
which is not the case in the present context, especially for long maturities. Therefore, an
13

additional parameter, '; is introduced and the discount factor is rewritten as:
exp [�'T ] exp [('� y (T ; �))T ] :
The goal is to obtain inside the second exponential an expression as close to zero as possible
for all bonds in the sample so that the discount factor may be accurately linearized. Appendix
A shows, in the Nelson-Siegel framework, how this linearization introduced in the non-linear
set of equations (3) leads to the following approximative system:
Y'0 = X'0;�0�'0;�0 + e
where �'0;�0 = (�'0;�0 ; �'0;�0 ; '0;�0)> ; e = (e1; :::; en)
> is a vector of zero-mean random noises
with covariance matrix �e = E�ee>
�= �2eIn, and the expressions for Y'0 and X'0;�0 are
available in appendix. This approximation is appropriate if�y�T (j); �
�� '
�T (j) is close to
zero for any T (j). An intuitive candidate for ' can be, for example, the average yield-to-
maturity. With this approximate system, the parameters can be estimated by minimizing the
objective function O (�; �; ; �; ') =Pn
i=1 e2i : However, because this system is linear in �'0;�0 ;
the �ve dimensional objective function O (�; �; ; �; ') may be reduced to a two-dimensional
one. Given values for '0; �0; the least squares estimator for �'0;�0is:
b�'0;�0 = �X>
'0;�0��1e X'0;�0
��1 �X
>
'0;�0��1e Y'0
�(5)
which minimizesO�0;'0 (�; �; ) : Therefore, the �ve dimensional objective functionO (�; �; ; �; ')
is reduced to :
o (�; ') = O�b�';� ; b�';� ; b ';� ; �; '� : (6)
Adapting the naive algorithm to the above modi�cation is then straightforward and reduces
the problem to a two-dimensional random search with an optimization algorithm searching
over � and '. This will be referred to as the one-step linearized algorithm.
14

The above procedure can be easily adapted to the Svensson (1994) model. For this case,
the original optimization problem is reduced to a three-dimensional random search with an
optimization algorithm searching over �; � and ':
3.2 Two-step linearized algorithms
It is possible to further reduce the dimension of the problem. As noticed above, the addi-
tional parameter ' should be close to the yield to maturity for the approximation to work
adequately. An obvious candidate for ' is therefore the average yield to maturity of the
zero-coupon bonds. Building on this intuition, it is possible to further reduce the dimension
of the problem and construct our algorithm to search mostly in the direction of hump lo-
cation parameters. It will also look at only two di¤erent values for the extra parameter ';
explaining the reduction in dimension. The algorithm goes as follows for the Nelson-Siegel
case:
1. Fix ' to an initial guess '0:
2. Apply the naive algorithm to the system o (�; '0) = O�b�';� ; b�';� ; b ';� ; �; '0� to �nd
an estimate e� :3. Construct e�0 = �b�'0;e� ; b�'0;e� ; b '0;e� ; e�� where
�b�'0;e� ; b�'0;e� ; b '0;e��> = �X>
'0;e���1e X'0;e���1 �
X>
'0;e���1e Y'0
�:
4. Construct the yield to maturity curve T ! y�T ; e�0�.
5. Compute the average yield ' = 1M
PMT=1 y
�T ; e�0� with M the largest maturity in the
sample. Set '0 = ':
15

6. Perform steps 2-5.
This will be referred to as the two-step linearized algorithm. Again, this procedure can
easily be adapted to the Svenson case with an optimization over � and � in each step.
As shown in numerical tests not reported in this study, the algorithm is not sensitive to
the starting values for ': This algorithm could also be generalized to perform iterations
on the value of ' until convergence is reached for this parameter. However, we usually
observe convergence in two or three iterations and the results are not improved by such
a modi�cation. Finally, modifying the algorithm to work with more than one value of '
could also be done. In this case, it would be required to split the maturity spectrum at
arbitrarily speci�ed time points to obtain the estimates. Again, our results did not show
much sensitivity to such a modi�cation.
The next section discusses how it is possible to take advantage of the �nancial interpre-
tation assigned to the parameters (or linear combinations of the parameters) of the �exible
functional form to introduce prior knowledge about these values.
4 Prior information
From the example looked at in Section 2, Figure 2 plots the zero-coupon yield curves associ-
ated with three solutions found using random starting points on a sample of U.S. government
bonds in July 1995. These curves have similar shapes. But, as shown in Table 3, the esti-
mated parameters are fairly di¤erent. This raises the question about how �nancially plausible
is each solution. Based on the information available to analysts on the date at which the
estimation is performed, one of these solutions might be rejected ex-post, that is, after the
estimation. Given that many di¤erent solutions may be obtained, this can quickly become
16

a tedious procedure. A better approach would be to include this prior information directly
in the estimation procedure. The occurrence of undesirable solutions, on an ex-ante basis,
might then be reduced.
A �rst approach for incorporating the prior information in the estimation process would
be to narrow the allowed parameter space during the non-linear optimization. However, it
is possible that the expectations about the values are incorrect. A second approach, which
is perhaps more interesting in our framework, is to introduce the prior information in a
way re�ecting this uncertainty. With linear systems, such an approach to include prior
information is provided by the Theil-Goldberger estimator. This estimator uses information
in the form of expected parameter values and the uncertainty about these expected values is
characterized by standard deviations. We describe here the procedure for the Nelson-Siegel
case, which can again be extended to the Svenson model.
As described in Goldberger (1964), a linear system such as the one described by equation
(5) incorporates prior information as follows:�Y'0
�prior
�=
�X'0;�0
R
��'0;�0+
�ed
�where �prior is an r � 1 vector containing the prior values about the parameters (or linear
combinations of the parameters), R is a r�3matrix describing the linear combinations of the
parameter values, d =(d1; d2; d3)> is a Gaussian random vector with E [d] = 0, E
�de>
�= 0
and diagonal covariance matrix of dimension r denoted by�d = E�dd>
�: In this framework,
the least squares estimator of �'0;�0 becomes
b�Bayes'0;�0=�eX>�1 eX��1 eX|�1 eY
17

with
eX =
�X'0;�0
R
�; eY =
�Y'0
�prior
�and
=
��2eIn 0n�303�n �d
�:
This estimator needs a value for �2e . An estimate of this quantity can be obtained with an
ordinary least squares regression of X'0;�0 on Y'0.
The form of matrix R will depend on the prior information imposed to the parameters.
For example, someone wishing to impose a prior value to the long term rate, the slope and
the curvature will have r = 3, R a 3� 3 identity matrix, �prior a 3� 1 vector of prior values
and �d a 3� 3 diagonal matrix with the prior variances associated to each prior parameter
value on the diagonal. Another possible case would be to impose prior values about the
short-term spot rate only. In the Nelson-Siegel framework, this quantity is equal to � + �.
In this case, r = 1; and
R =�1 1 0
�:
Matrices �prior and �d become scalar quantities, the former being the short rate prior value
and the latter being its associated variance re�ecting how con�dent we are about this prior.
The estimator with prior information can be used in conjunction with the one and two-
steps linearized algorithms: Next section examines the performance of these algorithms, with
and without prior information in simulated samples of coupon bonds.
18

5 A Monte Carlo study
5.1 Assumptions
In this section, we perform a Monte Carlo study assessing the e¢ ciency of the proposed
approaches. Four di¤erent cases are considered: large (N = 50) and small (N = 10) sample
sizes in combination with low and high noise variances. Each table will report the results
obtained from 500 replications.
For the Nelson-Siegel case, the parameters are set to the average of the estimated para-
meters presented in Diebold and Li (2006). These average values of � = 0:075; � = �0:02,
= �0:0015, and � = 15 arise from a monthly sample of zero-coupon yields between Janu-
ary 1987 to December 2000. For the Svensson case, the additional parameter �; � and � are
set to 0:05; 5 and 15.
For each replication, the coupon rates and the time to maturity are simulated using
uniform random variables on the intervals [1%; 10%] and [1; 30] years respectively. Bonds
with annual coupons and face values of 100$ are �rst simulated without error terms. The
yield to maturity of these bonds are then computed and i.i.d. zero mean normal error
terms are added to these yields, which are then transformed back into prices. The standard
deviations of these yield errors are set to 0:004 for the high noise case and to 0:00067 for the
low noise case. These variance levels come from Elton et al. (2001) who report the average
root mean squared errors (ARMSE) obtained by estimating the Nelson-Siegel model on
samples of government and corporate coupon bonds. The low variance case corresponds to
the ARMSE of government bonds while the high variance case is the ARMSE for BBB-rated
corporate coupon bonds3.
3The ARMSE reported in Elton and al. (2001) are bond pricing errors. The yield error standard deviation
19

The optimization steps are performed using the function lsqnonlin from Matlab with a
tolerance of 1:0� 10�6 for the di¤erences in the function and parameter values between two
successive iterations. The maximum number of function evaluations and maximum number
of iterations are set to 10,000. During the numerical optimization, the interval for �, the
long-term rate, is constrained to be in [0:01; 0:20]. The slope � which is the di¤erence
between the short and the long-term rates is assumed to be in [�0:5; 0:5]. The curvatures,
and �; are assigned to [�0:5; 0:5] while the position of the humps are assumed to be in
[0:1; 30].
For the Bayesian approaches, the prior means are set to the true values of �; �; and �:
A prior about the short rate is also speci�ed as the sum of � and �. For the prior standard
deviations, loose and tight priors are looked at. For the loose prior case, the standard
deviations of these parameters are set to the standard deviation of the estimated parameters
obtained in Diebold and Li (2006), which are around 0.015. The tight case sets the prior
standard deviations to 0.0015 for these three parameters.
5.2 Performance indicators
Tables 4 to 8 present summarized results for the parameters�estimation, computation time,
and the yield curve�s estimation. Three performance indicators measure the discrepancies
between the Nelson-Siegel and the simulated bond prices or yields. The indicator labelled
SSE1 corresponds to the objective function that has been optimized, evaluated at the optimal
parameter values. This function di¤ers for each algorithm. In the naive case, SSE1 is
calculated from Equation (4). In all other cases, it corresponds to Equation (6) which
corresponding to these bond pricing errors levels have been determined by simulation.
20

is based on a linearized approximation of the true Nelson-Siegel bond price. To measure
how these linearized methods perform as approximation to the original Nelson-Siegel model,
SSE2 presents the square root value of Equation (4) evaluated at the optimum. For the
plain Nelson-Siegel case, SSE1 and SSE2 are the same. Because SSE2 is not the optimized
function for the other approaches, it is expected to be larger than the plain Nelson-Siegel
case. To measure the quality of the estimation procedures on the estimated yield curves,
we report a root mean squared error measure based on the squared di¤erences between the
estimated zero-coupon yields and the true simulated yield curve for maturities of 1, 2, ...,
30.
5.3 Numerical results
Table 4 examines the Nelson-Siegel cases with a sample size of 50 bonds and a low variance
level for the random errors. For this case, all methods o¤er roughly similar performances
with respect to yield estimates. For the parameter estimation, the one-step, two-dimensional
linearized algorithm with loose priors produces parameter estimates that are o¤ from the
true parameters when compared to those obtained with the other methods. The average
convergence time of the Nelson-Siegel approach is roughly 14 to 20 times longer than the one
of the linearized methods. Among these linearized methods, the slowest technique is the one-
dimensional algorithm since it requires a two step one-dimensional non-linear optimization.
The average estimates of ' are similar for all methods. As expected, with correctly speci�ed
priors, tight prior methods perform better.
As the variance level of the error terms is increased and/or as the sample size is decreased,
clearer di¤erences are emerging. Because the remaining three cases are qualitatively similar
21

(large sample and high variance level, small sample with high and low variance levels), we
only present the results for the extreme case of 10 bonds with large noise in table 5. As
expected, the noise�s variance in�uences the standard deviations and sum of squared yield
errors when compared to their corresponding values in Table 4. For the spot rate estimates,
the tight prior cases are performing the best and the plain Nelson-Siegel and two-pass, one-
dimensional linearized without priors are the worst. Similar results are obtained for the
parameter estimates. The two-step, one-dimensional method without priors is highly biased
and ine¢ cient for � and : Loose priors are able to correct this situation. Indeed, the
estimates show errors in the same range of those from the plain Nelson-Siegel case but with
much smaller standard deviations. The two-step, one-dimensional algorithm, even if carried
out with loose priors, is thus dominating the original Nelson-Siegel approach in terms of
speed and precision.
Table 6 shows the results of a Monte Carlo experiment for which the parameters �; �;
and � are generated randomly for each simulated data set, rather than being �xed like in
the previous tables. Because the parameters are di¤erent for each of the 500 simulated
data sets, the table reports the di¤erence between the estimated and true parameters. The
random parameters are generated according to a uniform distribution. The minimum and
maximum values of the uniform distribution are taken from estimates of the one-dimensional
linearized algorithm on our monthly sample of U.S. government coupon bonds that will be
presented next section. The intervals for the uniform simulations are � 2 [0:0623; 0:1003],
� 2 [�0:0524; �0:0004], 2 [�0:0841; 0:0307] and � 2 [0:1532; 30]. 500 parameter sets
are simulated. Again, the prior means for �, � and are set to the true values while the
prior standard deviations are set to 0.015 for the loose case and 0.0015 for the tight case.
22

The conclusions about the reliability of the algorithm are similar qualitatively to those from
the previous tables. Our conclusions are thus not speci�c to parameter values chosen in
Tables 4 to 5.
Table 7 shows the results of a Monte Carlo experiment for which the prior means have
been set to values di¤erent from the true parameter values. Here the prior mean for the short
rate has been set to 0.065 while the true short rate i.e. �+ � is 0.055. The prior mean for �
is set to 0.085 while the true value is 0.075 and the prior means for � and are set to 0 while
the true values are -0.02 and -0.002. The results show that, in terms of yield estimates, the
two-step, one dimensional algorithms with no prior and loose prior have precisions similar
to the one obtained with the plain Nelson-Siegel algorithm. With tight priors, the precision
deteriorates, as expected from the wrong priors. However, the linearized algorithms are
about 20 times faster than the plain Nelson-Siegel case. The previous conclusions about the
two-step algorithm with loose priors are thus robust to the use of incorrect prior means.
Table 8 shows the results of a Monte Carlo experiment for the Svensson case with a large
sample and low variance. This table examines here only the two-step algorithms. Unlike
the Nelson-Siegel cases, the two-step algorithms are now two dimensional i.e. a non-linear
search is performed on the two hump location parameters � and �. The linearized method
with no prior does not perform adequately with large errors about yields and parameter
estimates. The addition of loose prior allows to obtain estimators with better precisions
than the plain Svensson approach and with lower standard deviations for the yield in the
short end of the curve. The average parameter values of the linearized algorithm with loose
prior are also closer to the true values. The reduction in computing time is not as large
as the one observed for the Nelson-Siegel case. There is still a substantial gain by a factor
23

around 2 for the approach with priors.
6 The probability of observing the global optimum
In this section, we examine an estimate of the probability that a search strategy using random
starting points has not observed all outcomes. This estimate focuses on the probability of
still having unobserved outcomes after k independent trials. If there is a low probability of
an unobserved outcome, there is a high probability that all maxima, including the global
maximum, have been found.
In addition, the parameter and yield estimates obtained with each methods will be com-
pared. These results will show the performance of the proposed methods in actual samples
of coupon bond prices.
6.1 Theoretical framework and assumptions
Denote by Uk the probability of still having unobserved outcomes after k independent trials.
Robbins (1968) has shown that the statistic
Vk =Skk;
where Sk is the number of singletons after k independent trials4, is a good estimate for
the probability of still having unobserved outcomes after k � 1 independent trials since
E (Vk � Uk�1) = 0: A variance bound can be found as:
E (Vk � Uk�1)2 <
1
k:
This bound can be used with the Chebyshev�s inequality to compute a con�dence interval
for Uk�1: This con�dence interval is however large and does not convey much information.4A singleton is a solution that has appeared only once in our k independent random trials.
24

In the statistical literature, Finch et al (1989) obtain an alternative con�dence interval.
Their approach is however not applicable here since it assumes equally probable domains of
convergence.
Using our monthly sample of U.S. government coupon bonds from January 1987 to De-
cember 1996, 100 random starting points are used to estimate monthly parameter values and
yield curves with the Nelson-Siegel and Svensson models with their corresponding linearized
versions. In practical applications, it is easy for analysts to obtain prior values for the short
rate from various sources. We therefore use, each month, a prior value for the short rate
(�+�) set according to the 3 month to maturity zero-coupon yield from the Federal Reserve
Bank of St-Louis. Since the information about the short rate is often of good quality, we set
the prior standard deviation for this linear combination of parameters to 0.0005, a reasonably
tight value. With such a standard deviation, an interval of two standard deviations around
the prior mean represents plus or minus ten basis points. The other prior used is a long run
mean (�) set equal to the average bond yield in the sample for the month, with a loose prior
standard deviation of 0.005. Finally, the slope and curvature are arbitrarily set to the aver-
age parameter values found in Diebold and Li (2006) with loose prior standard deviations of
0.01 for each. The optimization is performed with the same algorithm and settings described
in the earlier Monte Carlo studies. The solutions are classi�ed with threshold value of 10
basis point for the maximum absolute di¤erence between the estimated yields to maturity.
6.2 Numerical results
Table 9 reports the results about the V statistics for the Nelson-Siegel case. A �rst point
to notice is that on average, only 60% of the random starting points achieve convergence
25

for the plain Nelson-Siegel case. For the linearized algorithms, 100% of the cases achieve
convergence. The average of the V statistics computed each month is 0.03 for the Nelson-
Siegel case with a standard deviation of 0.04 and a maximum of 0.29. The percentiles show
that in at least 50 percent of the cases, the V statistic is 0.01 while it is smaller or equal to
0.04 in at least 75% of the samples. For most months, after 100 trials, there is thus a high
probability that all local optima are found. For the other methods, most cases show a V
statistic of zero. The mean number of distinct solutions is the highest for the Nelson-Siegel
case. The one-dimensional algorithms show averages around two for the number of distinct
solutions with, however, a small standard deviation. This suggests that the global optimum
is usually obtained when two or three distinct solutions are found.
Other interesting �ndings relate to the size of the group of solutions corresponding to the
lowest function value. Because uniform independent random numbers are used as starting
values, this number allows to compute the probability of hitting the global optimum in
a single trial, given that one hundred random starting points are used. For the Nelson-
Siegel case, the average probability is of 0.51 while it is over 0.90 for the two-step, one-
dimensional linearized algorithms and 0.80 for the one-step, two-dimensional algorithm. The
plain Nelson-Siegel also shows a greater standard deviation about this number than the
other methods. The other statistics about these estimated probabilities also indicate clearly
that the two-step, one-dimensional algorithms have a greater likelihood of hitting the global
optimum in a single trial. Overall, the numbers from these tables suggest that the multiplicity
of solution problem is much milder for the two-step one-dimensional linearized algorithms
than for the other approaches.
Table 10 reports the results about the V statistics for the Svensson case. A �rst di¤erence
26

is the larger proportion of cases achieving convergence for the plain algorithm. The linearized
algorithm, as in the Nelson-Siegel case, show 100% convergence. The V statistics are close to
those obtained for the Nelson-Siegel case. Another notable di¤erence is the lower estimates
of the probabilities of hitting the global optimum in a single trial. However, the two-step
algorithm with an average estimate of 0.76 dominates the plain Svensson with an estimate
of 0.61.
As a by-product of these probability estimates, we have made available the parameter and
yield estimates associated with each method. These estimates are interesting to compare to
show the similarities and di¤erences in results obtained with each algorithm. Table 11 reports
summary statistics about the monthly estimates from each method. The average estimates
for the short-term rate (� + �) are similar for the Nelson-Siegel case and the methods with
priors. These averages are close to the average risk-free yield of 0.0546 computed with the
risk-free short-term yield series from the St-Louis Federal Reserve, which is used as priors.
The standard deviation is however smaller for the linearized methods with priors, a result
consistent with those of the Monte Carlo simulation. The standard deviations for these
methods are close to the standard deviation computed from the risk-free yield time series
used in the methods with priors. This standard deviation is 0.01641. From this number,
we observe that the Nelson-Siegel method generates short-term rates showing too much
variability when compared with the observed short-term rates.
The estimates of � for the Nelson-Siegel and the two-step algorithm with priors are
roughly similar. The two-step without prior and one-step algorithm with priors stand out
with a low estimate of the average in�nite term rate and large standard deviations. The
average estimates of � are not statistically signi�cant. Again, the two-step, one-dimensional
27

linearized approach with priors has the lowest standard deviation. The average estimates
and standard deviations of and � are roughly equal for all methods. The more reliable
method (two-step, one-dimentional with priors) is 40 times faster than the plain approach.
The average sum of squared errors of the optimized functions are statistically di¤erent.
The average values of SSE2 are close to the Nelson-Siegel function value for the two-step,
one-dimensional methods, showing they produce reasonable approximation to the Nelson-
Siegel model. The results about the computing times show that the Nelson-Siegel approach
takes around 40 times the computing resources of the linearized algorithms.
Table 12 shows the yield estimates for di¤erent maturities. These results show that, for
the maturities of the sample, the averages of the Nelson-Siegel and all linearized algorithm are
close. For the shortest maturity, all estimators have an average close to the mean observed
short-term spot rate. The linearized estimators with priors have, however, lower standard
deviation for the shortest yield to maturity. For other maturities, the standard deviations of
yield estimates are close.
Finally, Tables 13 and 14 report the results for the Svensson case. The three methods
obtain di¤erent results for the average estimated parameter values. Unlike the Nelson-Siegel
case, the linearized method with no prior seem�s unreliable here (as it was the case with
the Monte Carlo study) with counterintuitive average parameters values of -0.22 and 0.23
for � and �. Again, the linearized method with prior get reasonable values for the � + �,
the short rate estimates, which are close in terms of mean and standard deviations to those
from the short yield series used as prior for the short rate, which is not the case for the plain
Svensson method. Again, the linearized method shows the smallest standard deviations for
the parameter estimates and the lowest computing time, improving the plain Svensson case
28

by an average factor of around 25. As for the yield estimates, the three methods provides
very close estimates, except for the very short end of the curve, which is estimated with the
greatest precision with the linearized approach with prior.
7 Conclusion
Linearized Nelson-Siegel and Svensson algorithms for estimating spot interest rate term
structures are developed and analyzed here. These algorithms retain the desirable features
of the original approaches, such as the �nancial interpretation of the parameters, but are
much faster to estimate. An advantage of these linearized algorithms is the possibility to
introduce prior information about some of the parameters of the model for which a �nancial
interpretation is available. As shown by Monte Carlo experiments and an empirical study on
samples of U.S. government bonds, introducing such prior information enhance the precision
with which the estimated spot rate curves can be obtained.
The probability of still having unobserved outcomes using a random starting point strat-
egy is assessed for the Nelson-Siegel and Svenson models and the proposed linearized versions.
Using monthly samples of U.S. coupon bond prices from 1987 to 1996, the results show that
multiplicity of solutions is a milder problem for the linearized algorithms. Our results suggest
that, among the algorithms studied here, the two-step, one-dimensional linearized algorithm
with prior information performs the best, even when used with very loose priors.
References
[1] Bank for International Settlements, 2005, Zero-coupon yield curves: technical documen-
tation, Bank for International Settlements, Basle, Switzerland.
29

[2] Bjork, T., and B. Christensen, 1999, Interest rate dynamics and consistent forward rate
curves, Mathematical Finance 9, 323�348.
[3] Bolder, D. and D., Stréliski, 1999, Yield curve modelling at the Bank of Canada, Tech-
nical report no. 84, Bank of Canada.
[4] Christensen, J, Diebold, F. and G. Rudebusch, 2007, The a¢ ne arbitrage-free class of
Nelson-Siegel term structure models, Federal Reserve Bank of San Francisco Working
Paper No. 2007-20.
[5] Coroneo, L., Nyholm, K. and R. Vidova-Koleva, 2008, How arbitrage-free is the Nelson-
siegel model?, European Central Bank working paper No. 874.
[6] Cox, J., Ingersoll, J. and S. Ross, 1985, A theory of the term structure of interest rates,
Econometrica 53, 385-407.
[7] De Pooter, M., 2007, Examining the Nelson-Siegel class of term structure models: in-
sample �t versus out-of-sample forecasting performance, Working paper Econometric
Institute, Erasmus University Rotterdam.
[8] De Pooter, M., Ravazzolo, F. and D. van Dijk, 2007, Predicting the term structure
of interest rates: incorporating parameter uncertainty, model uncertainty and macro-
economic information, Tinbergen Institute Discussion paper. No. 2007-028/4 .
[9] Diebold, F. and C., Li, 2006, Forecasting the term structure of government bond yields,
Journal of Econometrics 130, 337-364.
30

[10] Du¢ e, D. and R. Kan, 1996, A yield-factor model of interest rates, Mathematical Fi-
nance 6, 379-406.
[11] Elton E. J., Gruber, M.J., Agrawal, D. and C. Mann, 2001. Explaining the rate spread
on corporate bonds, The Journal of Finance 56, 247-277.
[12] Fabozzi, F., Martellini, L. and P. Priaulet, 2005, Predictability in the shape of the term
structure of interest rates, Journal of Fixed Income, 40�53 (June).
[13] Fama, E. and R. Bliss, 1987, The information in long-maturity forward rates, American
Economic Review 77, 680�692.
[14] Finch, S., Mendell, N. and H. Thode, 1989, Probabilistic measures of adequacy of a
numerical search for a global maximum, Journal of the American Statistical Association
84, 1020-1023.
[15] Gimeno, R. and J. Nave, 2006, Genetic algorithm estimation of interest rate term struc-
ture, Bank of Spain Working Paper No. 0636.
[16] Goldberger, A., 1964, Econometric Theory, Wiley, New York.
[17] Gürkaynak, R., Sack, B. and J. Wright, 2007, The U.S. Treasury yield curve: 1961 to
the present, Journal of Monetary Economics 54, 2291-2304.
[18] McCulloch, J., 1975, The tax adjusted yield curve, Journal of Finance, 30, 811�830.
[19] Mönch, E., 2006, Term structure surprises: the predictive content of curvature, level,
and slope, Working paper, Humboldt University Berlin.
31

[20] Nelson, R. and F. Siegel, 1987, Parsimonious modeling of yield curves, Journal of Busi-
ness 60, 473-489.
[21] Robbins, H., 1968, Estimating the total probability of the unobserved outcomes of an
experiment, The Annals of Mathematical Statistics 39, 256-257.
[22] Svensson, L., 1994, Estimating and interpreting forward interest rates: Sweden 1992-
1994, Centre for Economic Policy Research, Discussion Paper 1051.
[23] Vasicek, O., 1977, An equilibrium characterization of the term structure, Journal of
Financial Economics 5, 177-188.
[24] Warga, A., 1998. Fixed income database. University of Houston, Houston, Texas.
A Linearized Nelson-Siegel model for coupon bonds
For the Nelson-Siegel case, starting from Equation (2), we introduce an additional parameter
' to get
B (m; c; T ; �) =mXj=1
c(j) exp��y�T (j); �
�T (j)
�;
=mXj=1
c(j) exp��'T (j)
�exp
��'� y
�T (j); �
��T (j)
�which is then linearized in the second exponential to obtain:
B (m; c; T ; �) �=mXj=1
c(j) exp��'T (j)
� �1 + 'T (j) � y
�T (j); �
�T (j)
�;
=
mXj=1
c(j) 0�T (j); '
�� �
mXj=1
c(j) 1�T (j); '; �
�� �
mXj=1
c(j) 2�T (j); '; �
��
mXj=1
c(j) 3�T (j); '; �
�
32

with
0(T; '; �) = exp [�'T ] (1 + 'T ) ;
1(T; '; �) = exp [�'T ]T;
2(T; '; �) = exp [�'T ]T�1 (T ; �) ;
3(T; ') = exp [�'T ]T�2 (T ; �) :
Using these, it is possible to approximate the bond price equation (2) with
Bobs (mi; ci; Ti) =mXj=1
c(j) 0
�T(j)i ; '
�� �
mXj=1
c(j) 1
�T(j)i ; '; �
�� �
mXj=1
c(j) 2
�T(j)i ; '; �
��
mXj=1
c(j) 3
�T(j)i ; '; �
�+ ei:
Assuming that n bond prices are observed, the weigthed bond prices may be rewritten as a
linear system:
Y'0 = X'0;�0�'0;�0 + e
where
X'0;�0 = (X1 X2 X3)
with the n� 1 vectors
Xi =
0BBB@1D1
Pm1
j=1 c(j) i
�T(j)1 ; '0; �0
�...
1Dn
Pmn
j=1 c(j) i
�T(j)n ; '0; �0
�1CCCA
for i = 1 to 3; and
Y'0 =
0BBB@1D1
hPm1
j=1 c(j) 0
�T(j)1 ; '0
��Bobs (m1; c1; T1)
i...
1Dn
hPmn
j=1 c(j) 0
�T(j)n ; '0
��Bobs (mn; cn; Tn)
i1CCCA
where each elements of the original system of equation (4) are now weighted with the inverse
of the modi�ed bond duration.
33

Table 1: Summary statistics about the number of optimum found each month with monthlysamples of U.S. government bonds - January 1987 to December 1996
Threshold 0.0005 0.0010 0.0015 0.0020
Nelson-SiegelMean 3.7 3.1 2.8 2.6Std. 2.5 2.1 1.9 1.7Max 15.0 14.0 13.0 11.0Min 1.0 1.0 1.0 1.025-th percentile 2.0 2.0 2.0 2.050-th percentile 3.0 2.5 2.0 2.075-th percentile 5.0 4.0 3.0 3.0
SvenssonMean 9.6 7.4 6.2 5.6Std. 2.7 2.4 2.2 2.1Max 18.0 15.0 13.0 13.0Min 4.0 2.0 1.0 1.025-th percentile 7.5 6.0 4.0 4.050-th percentile 10.0 7.0 6.0 5.075-th percentile 11.5 9.0 8.0 7.0
This table reports the summary statistics about the number of local optima found when estimating theNelson-Siegel and Svensson models with a non-linear least squares algorithm initialized with 100 di¤erentrandom starting points. Two solutions are considered identical if the computed zero-coupon yields, formaturities of (0.1, 0.2, ..., Tmax) years, all have absolute discrepancies smaller than a threshold value indicatedin the table. Tmax is the largest maturity observed for a given month. The optimizations are performedusing the function lsqnonlin of Matlab with a tolerance of 1:0� 10�6 for the di¤erences in the function andparameter values between two successive iterations. The random starting parameter values are generatedaccording to a uniform distribution on the following intervals : � 2 [0:01 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5],� 2 [�0:5 0:5] , �1 2 [0:01 30], and � 2 [0:01 30] .
34

Table 2: Distinct solutions for Nelson-Siegel model with a sample of government couponbonds in September 1990
� � � fvSolution 1 0.0349 0.0403 0.1132 15.9768 0.5881Solution 2 0.0922 -0.0118 -0.0253 1.1262 0.7304Solution 3 0.0880 -0.2698 0.1286 0.1000 4.8375
This table reports the parameters and objective function values associated with the distinct solutions obtainedby the repeated estimation of the Nelson-Siegel model on a cross-section of US government bonds prices inSeptember 1990. Two solutions are considered identical if the computed zero-coupon yields, for maturitiesof (0.1, 0.2, ..., Tmax) years, all have absolute discrepancies smaller than 10 basis points. Tmax is the largestmaturity observed for a given month. The optimizations are performed using the function lsqnonlin of Matlabwith a tolerance of 1:0�10�6 for the di¤erences in the function and parameter values between two successiveiterations. The random starting parameter values are generated according to a uniform distribution on thefollowing intervals: � 2 [0:01 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5] and � 2 [0:01 30] .
Table 3: Local optima for for the Nelson-Siegel model and a sample of government couponbonds in July 1995
� � � fvSolution 1 0.0508 0.0046 0.0605 19.5513 0.1981Solution 2 0.0761 -0.0208 -0.0060 4.9431 0.2099Solution 3 0.0715 -0.0161 0.0215 12.5585 0.2046
This table reports the parameters and objective function values associated with three local optima obtainedby the repeated estimation of the Nelson-Siegel on a cross-section of US government bonds prices in July1995. The random starting parameter values are generated according to a uniform distribution on thefollowing intervals: � 2 [0:01 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5] and � 2 [0:01 30] .
35

Table4:MonteCarloresultsfortheNelson-Siegelcase:50bondsandlownoisevariance
��
�
'time
SSE1
SSE2
rmse
dy1
dy5
dy10
dy30
Nelson-Siegel(500validcases)
Mean
0.072
-0.017
-0.001
13.960
18.669
0.061
0.061
2.5
-1.3
0.6
-0.1
1.7
Std
0.007
0.007
0.015
8.586
6.942
0.009
0.009
1.2
5.1
1.9
1.8
5.1
Two-step,one-dimensionallinearizedNelson-Siegelwithoutpriors(500validcases)
Mean
0.070
-0.015
-0.003
11.365
0.062
0.977
0.061
0.061
2.5
-1.3
0.6
-0.2
1.1
Std
0.008
0.008
0.017
8.170
0.000
0.191
0.009
0.009
1.2
5.5
1.9
1.8
5.2
Two-step,one-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.072
-0.016
-0.007
9.340
0.062
1.383
0.061
0.061
2.4
-1.1
0.6
-0.3
1.1
Std
0.003
0.003
0.006
5.934
0.000
0.226
0.009
0.009
1.1
4.7
1.9
1.8
4.9
Two-step,one-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.074
-0.019
-0.002
13.842
0.062
1.352
0.062
0.062
1.7
0.9
0.0
-0.1
-1.6
Std
0.002
0.001
0.001
2.914
0.000
0.209
0.009
0.009
0.8
3.2
1.4
1.3
2.4
One-step,two-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.060
-0.005
-0.004
4.149
0.066
0.983
0.060
0.385
2.9
0.1
0.1
-0.4
-1.0
Std
0.013
0.013
0.013
3.563
0.022
0.176
0.008
0.406
1.3
7.9
2.4
1.9
6.2
One-step,two-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.075
-0.020
-0.002
17.268
0.067
0.933
0.062
0.102
2.0
0.7
-0.2
-0.1
-1.4
Std
0.002
0.001
0.000
5.019
0.008
0.289
0.009
0.071
1.0
3.9
1.6
1.5
4.3
Trueparameters:�=0.075,�=-0.020, =-0.002,�=15.Forthenon-linearoptimization,lowerboundsandupperboundsfor�,� and
�havebeensetto0.010,-0.500,-0.500,0.100and0.200,0.500,0.500,30.000.�SSE1�isthesumofsquarederrorsobtainedfortheoptimized
function;�SSE2�isthesumofsquarederrorsobtainedfortheNelsonandSiegelmodelwiththeestimatedparameters;�rmse�istheroot
meansquarederroroftheestimatedyields;�dy1�,�dy5�,�dy10�and�dy30�arethedi¤erencesinbasispointsbetweentheestimatedand
trueyieldformaturitiesof1,5,10and30years.1000random
startingpointshavebeenevaluatedwithanoptimizationperformedwiththe
10bestpointsandthelowestoptimum
valuekeptastheestimate.�validcases�isthenumberofcasesforwhichconvergencewasachieved.
TheTwo-step,one-dimensionallinearizedalgorithmhasbeeninitializedwith'equaltothepriormeanfor�plushalfthepriormeanof�.
36

Table5:MonteCarloresultsfortheNelson-Siegelcase:10bondsandhighvariance
��
�
'time
SSE1
SSE2
rmse
dy1
dy5
dy10
dy30
Nelson-Siegel(488validcases)
Mean
0.087
-0.024
-0.050
9.358
6.911
0.289
0.289
100.2
-37.4
0.5
2.1
-3.6
Std
0.053
0.173
0.223
9.703
4.416
0.099
0.099
129.1
739.2
80.1
39.4
55.5
Two-step,one-dimensionallinearizedNelson-Siegelwithoutpriors(500validcases)
Mean
0.100
-440.691
440.625
9.988
0.063
0.499
0.790
4.850
510.1
983.6
-44.6
-9.3
14.7
Std
0.640
4737.405
4737.589
12.377
0.030
0.134
3.397
40.232
968.3
5710.6
315.2
174.8
199.3
Two-step,one-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.071
-0.019
-0.005
9.583
0.061
0.920
0.319
0.319
19.8
13.6
-2.3
-3.8
7.7
Std
0.006
0.006
0.008
9.369
0.001
0.133
0.104
0.104
8.9
36.0
20.9
15.8
27.0
Two-step,one-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.075
-0.020
-0.002
17.028
0.062
0.822
0.343
0.343
13.1
-0.1
-0.2
0.5
0.7
Std
0.001
0.000
0.000
6.452
0.001
0.026
0.102
0.103
8.4
7.5
8.7
13.0
19.8
One-step,two-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.063
-0.011
-0.003
7.887
0.054
0.920
0.308
0.582
27.3
14.2
0.9
2.4
-27.7
Std
0.010
0.011
0.011
10.305
0.022
0.627
0.103
0.445
15.9
41.2
24.1
20.4
67.0
One-step,two-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.075
-0.020
-0.002
22.760
0.059
0.684
0.334
0.381
18.0
0.9
2.8
3.9
-19.3
Std
0.001
0.000
0.000
7.528
0.013
0.315
0.101
0.120
11.4
8.2
9.9
13.0
41.6
Trueparameters:�=0.075,�=-0.020, =-0.002,�=15.Forthenon-linearoptimization,lowerboundsandupperboundsfor�,� and
�havebeensetto0.010,-0.500,-0.500,0.100and0.200,0.500,0.500,30.000.�SSE1�isthesumofsquarederrorsobtainedfortheoptimized
function;�SSE2�isthesumofsquarederrorsobtainedfortheNelsonandSiegelmodelwiththeestimatedparameters;�rmse�istheroot
meansquarederroroftheestimatedyields;�dy1�,�dy5�,�dy10�and�dy30�arethedi¤erencesinbasispointsbetweentheestimatedand
trueyieldformaturitiesof1,5,10and30years.1000random
startingpointshavebeenevaluatedwithanoptimizationperformedwiththe
10bestpointsandthelowestoptimum
valuekeptastheestimate.�validcases�isthenumberofcasesforwhichconvergencewasachieved.
TheTwo-step,one-dimensionallinearizedalgorithmhasbeeninitializedwith'equaltothepriormeanfor�plushalfthepriormeanof�.
37

Table6:MonteCarloresultsfortheNelson-Siegelcase:random
parametervalues,50bondsandlowvariance
���
���
�
���
'time
SSE1
SSE2
rmse
dy1
dy5
dy10
dy30
Nelson-Siegel(384validcases)
Mean
-0.002
0.002
0.003
-2.855
12.828
0.063
0.063
2.6
-0.3
0.2
-0.1
1.2
Std
0.019
0.020
0.034
8.716
7.712
0.014
0.014
1.4
7.2
2.2
1.9
5.5
Two-step,one-dimensionallinearizedNelson-Siegelwithoutpriors(385validcases)
Mean
-0.005
-0.040
0.050
-3.636
0.062
0.789
0.063
0.065
3.3
1.3
0.1
-0.2
-0.3
Std
0.024
0.770
0.767
10.099
0.018
0.091
0.014
0.015
9.1
50.9
2.4
1.9
6.1
Two-step,one-dimensionallinearizedNelson-Siegelwithloosepriors(385validcases)
Mean
-0.005
0.005
-0.000
-5.092
0.062
1.232
0.063
0.065
2.5
-0.4
0.2
-0.2
-0.5
Std
0.009
0.010
0.023
8.162
0.018
0.116
0.015
0.015
1.2
5.8
2.2
1.9
5.3
Two-step,one-dimensionallinearizedNelson-Siegelwithtightpriors(385validcases)
Mean
-0.001
0.000
-0.000
-0.171
0.062
1.220
0.064
0.065
2.4
0.8
-0.3
0.1
-3.6
Std
0.001
0.001
0.001
2.052
0.018
0.091
0.015
0.015
1.3
3.5
1.8
1.6
5.4
One-step,two-dimensionallinearizedNelson-Siegelwithloosepriors(385validcases)
Mean
-0.019
0.018
0.009
-7.970
0.062
0.900
0.062
0.536
3.0
0.2
0.1
-0.2
-2.0
Std
0.022
0.022
0.032
9.676
0.030
0.180
0.014
0.745
1.4
7.1
2.4
2.0
6.7
One-step,two-dimensionallinearizedNelson-Siegelwithtightpriors(385validcases)
Mean
-0.000
0.000
-0.000
0.726
0.065
0.854
0.064
0.100
2.3
1.3
-0.3
-0.2
-2.1
Std
0.001
0.001
0.001
2.957
0.020
0.160
0.014
0.093
1.1
3.4
1.9
1.7
5.0
Trueparameters:random
parametervaluesaregeneratedaccordingtoauniformdistributiononthefollowingintervals:�2[0:06230:1004],
�2[�0:05370:0015], 2[�0:0847
0:0286]and�2[0:154130].Thepriormeansfor�,�and aresettothetrueparametervalue.Prior
standarddeviationsfor�,�and :0.015,0.015,0.015.Forthenon-linearoptimization,lowerboundsandupperboundsfor�,� and�
havebeensetto0.010,-0.500,-0.500,0.100and0.200,0.500,0.500,40.000.�Mean�and�Std�arethemeanandstandarddeviationofthe
di¤erencebetweentheestimatedandtrueparametervalues.�SSE1�isthesumofsquarederrorsobtainedfortheoptimizedfunction;�SSE2�
isthesumofsquarederrorsobtainedfortheNelsonandSiegelmodelwiththeestimatedparameters;�rmse�istherootmeansquarederrorof
theestimatedyield;�dy1�,�dy5�,�dy10�and�dy30�arethedi¤erencesinbasispointsbetweentheestimatedandtrueyieldformaturities
of1,5,10and30years;500datasetshavebeensimulatedandforeachdataset,1000random
startingpointshavebeenevaluatedwithan
optimizationperformedwiththe10bestpointsandthelowestoptimum
valuekeptastheestimate.�validcases�isthenumberofcasesfor
whichconvergencewasachieved.TheTwo-step,one-dimensionallinearizedalgorithmhasbeeninitializedwith'equaltothepriormeanfor
�plushalfthepriormeanof�.
38

Table7:MonteCarloresultsfortheNelson-Siegelcase:wrongpriors,50bondsandlowvariance
��
�
'time
SSE1
SSE2
rmse
dy1
dy5
dy10
dy30
Nelson-Siegel(500validcases)
Mean
0.072
-0.017
-0.001
13.960
19.320
0.061
0.061
2.5
-1.3
0.6
-0.1
1.7
Std
0.007
0.007
0.015
8.586
7.848
0.009
0.009
1.2
5.1
1.9
1.8
5.1
Two-step,one-dimensionallinearizedNelson-Siegelwithoutpriors(500validcases)
Mean
0.070
-0.015
-0.003
11.365
0.062
0.887
0.061
0.061
2.5
-1.3
0.6
-0.2
1.1
Std
0.008
0.008
0.017
8.170
0.000
0.231
0.009
0.009
1.2
5.5
1.9
1.8
5.2
Two-step,one-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.072
-0.016
-0.006
9.998
0.062
1.323
0.061
0.061
2.4
-1.2
0.5
-0.3
1.3
Std
0.003
0.003
0.008
6.880
0.000
0.305
0.009
0.009
1.1
4.9
1.9
1.7
4.8
Two-step,one-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.070
-0.014
-0.004
8.015
0.062
1.502
0.067
0.068
4.3
-4.0
-4.0
-2.6
8.0
Std
0.001
0.001
0.002
1.888
0.000
0.355
0.010
0.010
1.2
2.8
1.7
1.3
2.6
One-step,two-dimensionallinearizedNelson-Siegelwithloosepriors(500validcases)
Mean
0.060
-0.004
-0.004
4.098
0.066
0.941
0.060
0.397
2.9
-1.1
0.1
-0.4
-1.0
Std
0.013
0.013
0.013
3.785
0.022
0.246
0.008
0.407
1.3
7.9
2.3
1.9
6.2
One-step,two-dimensionallinearizedNelson-Siegelwithtightpriors(500validcases)
Mean
0.064
-0.008
-0.006
12.092
0.077
0.892
0.063
0.345
2.6
-3.5
-1.5
-1.4
-1.3
Std
0.003
0.004
0.002
11.329
0.016
0.228
0.009
0.093
1.2
3.6
1.8
1.6
5.1
Trueparameters:�=0.075,�=-0.020, =-0.002,�=15.Forthenon-linearoptimization,lowerboundsandupperboundsfor�,� and
�havebeensetto0.010,-0.500,-0.500,0.100and0.200,0.500,0.500,30.000.�SSE1�isthesumofsquarederrorsobtainedfortheoptimized
function;�SSE2�isthesumofsquarederrorsobtainedfortheNelsonandSiegelmodelwiththeestimatedparameters;�rmse�istheroot
meansquarederroroftheestimatedyields;�dy1�,�dy5�,�dy10�and�dy30�arethedi¤erencesinbasispointsbetweentheestimatedand
trueyieldformaturitiesof1,5,10and30years.1000random
startingpointshavebeenevaluatedwithanoptimizationperformedwiththe
10bestpointsandthelowestoptimum
valuekeptastheestimate.�validcases�isthenumberofcasesforwhichconvergencewasachieved.
TheTwo-step,one-dimensionallinearizedalgorithmhasbeeninitializedwith'equaltothepriormeanfor�plushalfthepriormeanof�.
39

Table8:MonteCarloresultsfortheSvenssoncase:50bondsandlowvariance
��
�
��
'time
SSE1
SSE2
rmse
dy1
dy5
dy10
dy30
Svensson(500validcases)
Mean
0.086
-0.019
0.002
0.001
8.493
11.126
4.454
0.052
0.052
4.814
-0.9
-0.0
-0.1
-1.7
Std
0.039
0.093
0.170
0.159
7.986
9.233
2.136
0.007
0.007
7.060
41.6
2.6
2.3
8.1
Two-step,two-dimensionallinearizedSvenssonwithoutpriors(500validcases)
Mean
0.076
2.531
-0.339
-2.219
7.821
10.638
0.079
7.573
0.051
0.061
9.588
-7.2
0.1
-0.1
-0.7
Std
0.187
33.700
53.959
42.012
9.283
10.829
0.000
0.708
0.007
0.001
28.400
156.6
3.4
2.7
10.6
Two-step,two-dimensionallinearizedSvenssonwithloosepriors(500validcases)
Mean
0.077
-0.025
-0.007
0.049
4.090
9.360
0.079
2.054
0.052
0.061
3.542
0.4
-0.4
-0.2
-2.3
Std
0.012
0.015
0.025
0.027
3.909
6.931
0.000
0.255
0.007
0.000
2.164
12.0
2.6
2.1
7.2
Two-step,two-dimensionallinearizedSvenssonwithtightpriors(500validcases)
Mean
0.075
-0.021
-0.001
0.050
5.595
13.885
0.079
1.909
0.053
0.061
2.748
1.4
-1.3
0.6
-2.6
Std
0.001
0.001
0.000
0.001
1.225
2.016
0.000
0.232
0.007
0.000
1.362
4.0
1.7
1.8
5.7
Trueparameters:�=0.075,�=-0.020, =-0.002,�=0.050,�=5,�=15.Forthenon-linearoptimization,lowerboundsandupper
boundsfor�,�, ,�,� 1and� 2havebeensetto0.010,-0.500,-0.500,-0.500,0.100,0.100and0.200,0.500,0.500,0.500,30.000,30.000.
�SSE1�isthesumofsquarederrorsobtainedfortheoptimizedfunction;�SSE2�isthesumofsquarederrorsobtainedfortheSvensson
modelwiththeestimatedparameters;�rmse�istherootmeansquarederroroftheestimatedyields;�dy1�,�dy5�,�dy10�and�dy30�are
thedi¤erencesinbasispointsbetweentheestimatedandtrueyieldformaturitiesof1,5,10and30years.1000random
startingpointshave
beenevaluatedwithanoptimizationperformedwiththe10bestpointsandthelowestoptimum
valuekeptastheestimate.�validcases�is
thenumberofcasesforwhichconvergencewasachieved.Theone-dimensionallinearizedalgorithmhasbeeninitializedwith'equaltothe
priormeanfor�plushalfthepriormeanof�.
40

Table 9: Summary statistics about the random search for optima for the Nelson-Siegel casewith U.S. government bonds - January 1987 to December 1996
Method 2 steps 2 steps 1 step1 dim. 1 dim. 2 dim.
Plain no Bayes Bayes Bayes
Mean nb. of valid cases 59.76 100.00 100.00 100.00Std. nb. of valid cases 33.45 0.00 0.00 0.00Mean nb. of singleton 1.17 0.05 0.01 0.21Std. nb. of singleton 1.70 0.22 0.09 0.41Mean nb. of distinct solutions 3.10 1.63 1.51 2.73Std. nb. of distinct solutions 2.07 0.54 0.52 0.80Mean global optimum group size 50.86 93.96 95.15 84.38Std. global optimum group size 31.27 8.24 7.81 10.18
Mean V statistic 0.03 0.00 0.00 0.00Std. V statistic 0.04 0.00 0.00 0.00Min. V statistic 0.00 0.00 0.00 0.00Max. V statistic 0.29 0.01 0.01 0.01
25-th Percentile 0.00 0.00 0.00 0.0050-th Percentile 0.01 0.00 0.00 0.0075-th Percentile 0.04 0.00 0.00 0.00
Mean of global optimum prob. 0.51 0.94 0.95 0.84Std. of global optimum prob. 0.31 0.08 0.08 0.10Min. of global optimum prob. 0.07 0.59 0.59 0.48Max. of global optimum prob. 0.99 1.00 1.00 1.00
25-th Percentile of global optimum prob. 0.17 0.91 0.93 0.7950-th Percentile of global optimum prob. 0.55 0.96 1.00 0.8675-th Percentile of global optimum prob. 0.80 1.00 1.00 0.91
This table reports statistics about the estimation results got with U.S. government bond prices for theNelson-Siegel model and the linearized algorithms. All models are estimated with a non-linear least squaresalgorithm initialized with 100 di¤erent random starting points each month from January 1987 to December1996. Two solutions are considered identical if the computed zero-coupon yields, for maturities of (0.1, 0.2,..., Tmax) years, all have absolute discrepancies smaller than a threshold value of 10 basis points. Tmax is thelargest maturity observed for a given month. The optimization are performed using the function lsqnonlinof Matlab with a tolerance of 1:0 � 10�6 for the di¤erences in the function and parameter values betweentwo successive iterations. The random starting parameter values are generated according to a uniformdistribution on the following intervals : � 2 [0:05 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5] and � 2 [0:01 30] .
41

Table 10: Summary statistics about the random search for optima for the Svensson casewith U.S. government bonds - January 1987 to December 1996
2 steps 2 steps2 dim. 2 dim.
Method Plain no Bayes Bayes
Mean nb. of valid cases 91.23 100.00 100.00Std. nb. of valid cases 9.14 0.00 0.00Mean nb. of singleton 3.13 0.89 0.32Std. nb. of singleton 2.13 0.92 0.56Mean nb. of distinct solutions 7.56 5.36 3.29Std. nb. of distinct solutions 2.37 1.38 1.10Mean global optimum group size 60.90 63.90 76.30Std. global optimum group size 17.68 19.56 16.53
Mean V statistic 0.03 0.01 0.00Std. V statistic 0.02 0.01 0.01Min. V statistic 0.00 0.00 0.00Max. V statistic 0.10 0.04 0.03
25-th Percentile 0.01 0.00 0.0050-th Percentile 0.03 0.01 0.0075-th Percentile 0.05 0.01 0.01
Mean of global optimum prob. 0.61 0.64 0.76Std. of global optimum prob. 0.18 0.20 0.17Min. of global optimum prob. 0.23 0.31 0.37Max. of global optimum prob. 0.96 1.00 1.00
25-th Percentile of global optimum prob. 0.48 0.45 0.6250-th Percentile of global optimum prob. 0.60 0.63 0.8275-th Percentile of global optimum prob. 0.78 0.82 0.89
This table reports statistics about the estimation results got with U.S. government bond prices for theSvensson model and the linearized algorithms. All models are estimated with a non-linear least squaresalgorithm initialized with 100 di¤erent random starting points each month from January 1987 to December1996. Two solutions are considered identical if the computed zero-coupon yields, for maturities of (0.1, 0.2,..., Tmax) years, all have absolute discrepancies smaller than a threshold value of 10 basis points. Tmax is thelargest maturity observed for a given month. The optimization are performed using the function lsqnonlinof Matlab with a tolerance of 1:0 � 10�6 for the di¤erences in the function and parameter values betweentwo successive iterations. The random parameter starting values are generated according to a uniformdistribution on the following intervals : � 2 [0:01 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5], � 2 [�0:5 0:5] ,� 2 [0:01 30], and � 2 [0:01 30] .
42

Table 11: Summary statistics on parameter estimates from U.S. government bonds for theNelson-Siegel case - January 1987 to December 1996
� � � ' �+ � SSE1 SSE2 time
Nelson-SiegelMean 0.0691 -0.0157 0.0325 7.2485 � 0.0533 0.58 0.58 17.16Std 0.0204 0.0407 0.0569 7.2459 � 0.0305 0.41 0.41 17.95Min 0.0100 -0.2175 -0.0507 0.1888 � -0.1295 0.15 0.15 0.42Max 0.1013 0.0651 0.2449 29.2960 � 0.0976 2.07 2.07 65.19
Two-steps, one-dimensional linearized without priorsMean 0.0542 0.0002 0.0499 8.7580 0.0757 0.0544 0.57 0.66 0.47Std 0.0523 0.0710 0.0965 9.9094 0.0096 0.0419 0.41 0.40 0.31Min -0.1526 -0.4333 -0.0643 0.1615 0.0578 -0.3514 0.14 0.15 0.11Max 0.1013 0.2130 0.4535 30.0000 0.0958 0.0975 2.04 2.09 1.73
Two-steps, one-dimensional linearized with priorsMean 0.0749 -0.0182 0.0207 6.4088 0.0757 0.0567 0.63 0.72 0.42Std 0.0094 0.0204 0.0366 5.8194 0.0096 0.0178 0.47 0.46 0.25Min 0.0507 -0.0571 -0.0579 0.1288 0.0578 0.0276 0.15 0.16 0.16Max 0.0992 0.0142 0.0984 30.0000 0.0949 0.0938 2.24 2.41 1.84
One-step, two-dimensional linearized with priorsMean 0.0517 0.0047 0.0285 8.0864 0.0721 0.0564 0.59 75.62 0.63Std 0.0347 0.0429 0.0524 8.3743 0.0322 0.0181 0.48 135.39 1.06Min -0.0568 -0.0566 -0.0621 0.1048 0.0100 0.0285 0.08 0.31 0.16Max 0.0968 0.1087 0.1551 30.0000 0.1196 0.0974 2.29 680.72 10.70
This table reports statistics about the estimates got with U.S. government bond prices for the Nelson-Siegelmodel and the linearized algorithms. All models are estimated with a non-linear least squares algorithminitialized with 100 di¤erent random starting points each months from January 1987 to December 1996.The optimization are performed using the function lsqnonlin of Matlab with a tolerance of 1:0 � 10�6 forthe di¤erences in the function and parameter values between two successive iterations. �SSE1� is the sumof squared errors obtained for the optimized function; �SSE2� is the sum of squared errors obtained forthe Nelson and Siegel model with the estimated parameters. The random starting parameter values aregenerated according to a uniform distribution on the following intervals : � 2 [0:05 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5] and � 2 [0:01 30] .
43

Table 12: Summary statistics on yield estimates from U.S. government bonds for the Nelson-Siegel case - January 1987 to December 1996
dy0.1 dy1 dy5 dy10 dy20 dy30
Nelson-SiegelMean 0.0556 0.0614 0.0710 0.0761 0.0791 0.0793std 0.0222 0.0167 0.0121 0.0103 0.0086 0.0073max 0.0975 0.0965 0.0931 0.0964 0.0989 0.0997min -0.0453 0.0316 0.0479 0.0568 0.0609 0.0626
Two-steps, one-dimensional linearized without priorMean 0.0565 0.0614 0.0710 0.0761 0.0791 0.0792std 0.0263 0.0167 0.0121 0.0103 0.0086 0.0072max 0.0974 0.0964 0.0932 0.0964 0.0989 0.0999min -0.1446 0.0318 0.0479 0.0566 0.0609 0.0627
Two-steps, one-dimensional linearized with priorMean 0.0573 0.0612 0.0710 0.0761 0.0792 0.0797std 0.0178 0.0166 0.0121 0.0103 0.0086 0.0074max 0.0938 0.0952 0.0929 0.0959 0.0977 0.0983min 0.0284 0.0318 0.0479 0.0566 0.0609 0.0627
One-step, two-dimensional linearized with priorMean 0.0570 0.0612 0.0709 0.0759 0.0794 0.0794std 0.0180 0.0166 0.0120 0.0103 0.0086 0.0079max 0.0973 0.0963 0.0928 0.0956 0.0993 0.1030min 0.0286 0.0319 0.0479 0.0563 0.0614 0.0601
This table reports statistics about yields estimates got with U.S. government bond prices for the Nelson-Siegelmodel and the linearized algorithms. All models are estimated with a non-linear least squares algorithminitialized with 100 di¤erent random starting points each months from January 1987 to December 1996.Maturities are in years and Tmax is the largest maturity observed for a given month. The optimization areperformed using the function lsqnonlin of Matlab with a tolerance of 1:0 � 10�6 for the di¤erences in thefunction and parameter values between two successive iterations. The random starting parameter values aregenerated according to a uniform distribution on the following intervals : � 2 [0:05 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5] and � 2 [0:01 30] .
44

Table13:Summarystatisticsonparameterestimatesfrom
U.S.governmentbondsfortheSvenssoncase-January1987
toDecember1996
��
�
� 1� 2
'�+�
SSE1
SSE2
time
Svensson
Mean
0.0444
-0.0041
0.0649
0.0659
5.9959
8.8000
�0.0403
0.47
0.47
25.21
Std
0.0260
0.0877
0.1053
0.0870
6.6172
6.8762
�0.0764
0.40
0.40
18.28
Min
0.0100
-0.4470
-0.3125
-0.2054
0.1601
0.1315
�-0.3754
0.07
0.07
1.95
Max
0.0942
0.2801
0.4921
0.2264
23.1858
30.0000
�0.3519
1.66
1.66
72.38
Two-step,two-dimensionallinearizedwithoutpriors
Mean
-0.2180
0.2352
0.3247
0.5567
8.1585
12.8628
0.0755
0.0172
0.45
0.54
1.12
Std
0.4312
0.4724
0.9339
1.4494
10.0708
9.7363
0.0095
0.1351
0.40
0.40
0.78
Min
-1.8061
-0.9148
-0.6890
-8.8903
0.1695
0.1000
0.0579
-0.8359
0.06
0.06
0.38
Max
0.0862
1.8306
9.6024
4.8171
30.0000
30.0000
0.0950
0.0888
1.68
1.70
5.63
Two-step,two-dimensionallinearizedwithpriors
Mean
0.0633
-0.0084
0.0210
0.0412
4.2955
7.9131
0.0756
0.0549
0.51
0.60
0.92
Std
0.0167
0.0167
0.0412
0.0335
5.3911
6.2491
0.0096
0.0163
0.43
0.42
0.36
Min
0.0106
-0.0529
-0.0452
-0.0365
0.1000
0.1972
0.0578
0.0289
0.08
0.08
0.36
Max
0.0891
0.0297
0.1547
0.1025
30.0000
30.0000
0.0952
0.0883
1.77
1.79
2.19
ThistablereportsstatisticsabouttheestimatesgotwithU.S.governmentbondpricesfortheSvenssonmodelandthelinearizedalgorithms.
Allmodelsareestimatedwithanon-linearleastsquaresalgorithminitializedwith100di¤erentrandom
startingpointseachmonthsfrom
January1987toDecember1996.TheoptimizationareperformedusingthefunctionlsqnonlinofMatlabwithatoleranceof1:0�10�6for
thedi¤erencesinthefunctionandparametervaluesbetweentwosuccessiveiterations.�SSE1�isthesumofsquarederrorsobtainedfor
theoptimizedfunction;�SSE2�isthesumofsquarederrorsobtainedfortheNelsonandSiegelmodelwiththeestimatedparameters.The
random
startingparametervaluesaregeneratedaccordingtoauniformdistributiononthefollowingintervals:�2[0:010:2],�2[�0:50:5],
2[�0:50:5],�2[�0:50:5],�2[0:0130],and�2[0:0130].
45

Table 14: Summary statistics on yield estimates from U.S. government bonds for the Svens-son case - January 1987 to December 1996
dy0.1 dy1 dy5 dy10 dy20 dy30
SvenssonMean 0.0473 0.0612 0.0709 0.0761 0.0794 0.0781std 0.0422 0.0166 0.0121 0.0104 0.0084 0.0073max 0.2155 0.0961 0.0933 0.0970 0.0988 0.0942min -0.1793 0.0319 0.0479 0.0566 0.0613 0.0608
Two-step, two-dimensional linearized without priorMean 0.0348 0.0612 0.0709 0.0760 0.0798 0.0771std 0.0736 0.0166 0.0121 0.0104 0.0084 0.0079max 0.0889 0.0964 0.0934 0.0969 0.0989 0.0940min -0.4482 0.0320 0.0480 0.0563 0.0616 0.0597
Two-step, two-dimensional linearized with priorMean 0.0557 0.0611 0.0709 0.0761 0.0793 0.0790std 0.0167 0.0167 0.0121 0.0103 0.0085 0.0077max 0.0895 0.0962 0.0932 0.0967 0.0987 0.0972min 0.0288 0.0317 0.0480 0.0566 0.0610 0.0615
This table reports statistics about yields estimates got with U.S. government bond prices for the Svenssonmodel and the linearized algorithms. All models are estimated with a non-linear least squares algorithminitialized with 100 di¤erent random starting points each months from January 1987 to December 1996.Maturities are in years and Tmax is the largest maturity observed for a given month. The optimization areperformed using the function lsqnonlin of Matlab with a tolerance of 1:0 � 10�6 for the di¤erences in thefunction and parameter values between two successive iterations. The random starting parameter values aregenerated according to a uniform distribution on the following intervals : � 2 [0:01 0:2], � 2 [�0:5 0:5], 2 [�0:5 0:5], � 2 [�0:5 0:5] , � 2 [0:01 30], and � 2 [0:01 30] .
46
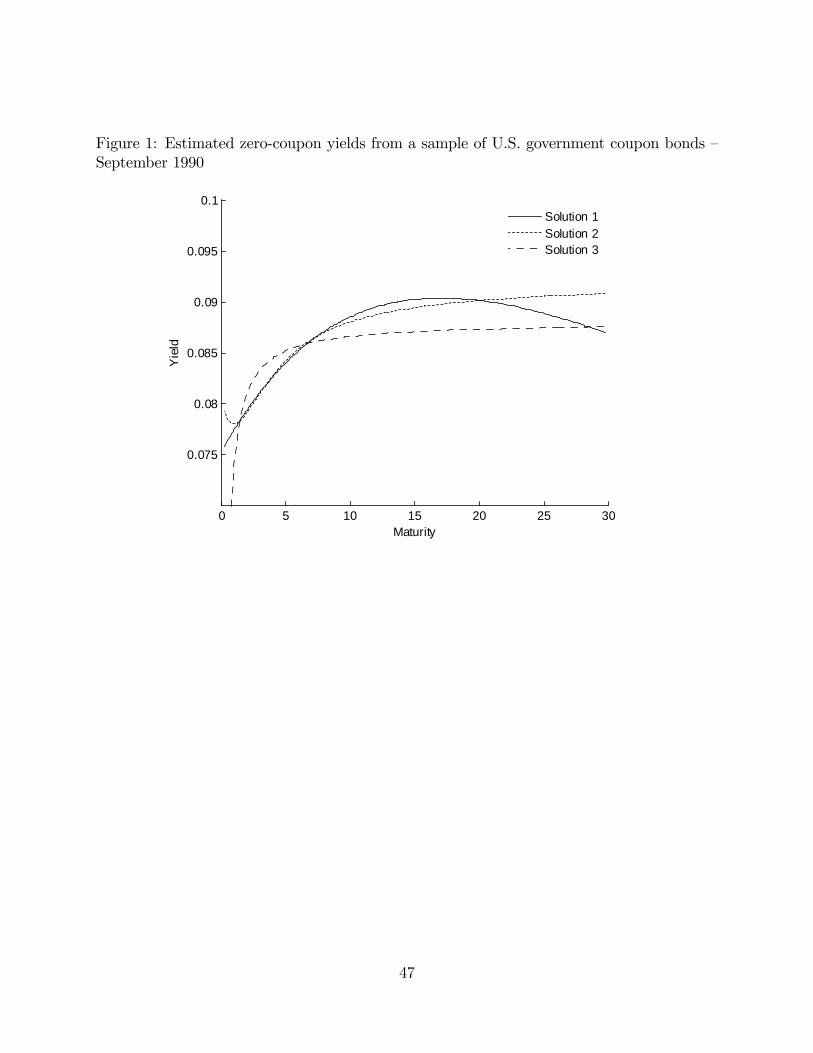
Figure 1: Estimated zero-coupon yields from a sample of U.S. government coupon bonds �September 1990
0 5 10 15 20 25 30
0.075
0.08
0.085
0.09
0.095
0.1
Maturity
Yie
ld
Solution 1Solution 2Solution 3
47

Figure 2: Estimated zero-coupon yields from a sample of U.S. government coupon bonds �July 1995
0 5 10 15 20 25 300.05
0.055
0.06
0.065
0.07
0.075
0.08
Maturity
Yie
ld
Solution 1Solution 2Solution 3
48


















