
Lightly Supervised and Unsupervised Acoustic Model Training Lori Lamel, Jean-Luc Gauvain and Gilles...
34
Lightly Supervised and Unsupervised Acoustic Model Training Lori Lamel, Jean-Luc Gauvain and Gilles Adda Spoken Language Processing Group, LIMSI, France CSL 2002 Reporter: Shih-Hung Liu 2007/03/05
-
Upload
baldwin-franklin -
Category
Documents
-
view
221 -
download
1
Transcript of Lightly Supervised and Unsupervised Acoustic Model Training Lori Lamel, Jean-Luc Gauvain and Gilles...

Lightly Supervised and Unsupervised Acoustic Model Training
Lori Lamel, Jean-Luc Gauvain and Gilles Adda
Spoken Language Processing Group, LIMSI, France
CSL 2002
Reporter: Shih-Hung Liu 2007/03/05

2
Outline
• Abstract
• Introduction
• Lightly supervised acoustic model training
• System description
• Impact of the amount of acoustic training data
• Impact of the language model training material
• Unsupervised acoustic model training
• Conclusions

3
Abstract
• This paper describes some recent experiments using lightly supervised and unsupervised techniques for acoustic model training in order to reduce the system development cost
• The approach uses a speech recognizer to transcribe unannotated broadcast news
• The hypothesized transcription is optionally aligned with closed-captions to create labels for the training data

4
Introduction
• Despite the rapid progress made in LVCSR, there remain many outstanding challenges
• One of the main challenges is to reduce the development costs required to adapt a recognition system to a new task
• With today’s technology, the adaptation of a recognition system to a new task required large amounts of transcribed acoustic training data
• One of the most often cited costs in development is that of obtaining this necessary transcribed acoustic training data, which is expensive process in terms of both manpower and time

5
Introduction
• There are certain audio sources such as radio and television news broadcasts, that can provide an essentially unlimited supply of acoustic training data
• However, for the vast majority of audio data sources there are no corresponding accurate word transcriptions
• Some of these sources also broadcast manually derived closed-captions
• There may also exist other sources of information with different levels of completeness such as approximation transcriptions, summaries or keywords, which can be used to provide some supervision

6
Introduction
• The basic idea is to use a speech recognizer to automatically transcribe raw audio data, thus generating approximate transcriptions for the training data
• Training on all of the automatically annotated data is compared with using the closed-captions to filter the hypothesized transcriptions, thus removing words that are potentially incorrect and training only on the words which agree

7
Lightly supervised acoustic model training
• The following training procedure is used in this work which can be used with all of the different levels of supervision:
1. Normalize the available text materials (e.g. newspaper and newswire, commercially produced transcripts, closed-captions, detailed transcripts of acoustic training data) and train an n-gram language model
2. Partition each show into homogeneous segments, labelling the acoustic attributes (speaker, gender, bandwidth) 3. Train acoustic models on a small amount of manually annotated data (1 h or less) 4. Automatically transcribe a large amount of raw training data 5. Optionally align the closed-captions with the automatic transcriptions (using a
dynamic programming algorithm) removing speech segments where the two transcripts disagree.
6. Run the standard acoustic model training procedure on the speech segments using the automatic transcripts
7. Reiterate from step 4.

8
Lightly supervised acoustic model training

9
System description
• The LIMSI broadcast news transcription system has two components– an audio partitioner
• to divide the continuous stream of acoustic data into homogeneous segments, associating appropriate labels with the segments
– a word recognition• initial hypothesis generation – used for MLLR
• word graph generation - trigram
• final hypothesis generation – fourgram

10
Impact of the amount of acoustic training data
As expected, when more training data is used, the word error rate decreases

11
Impact of the language model training material

12
Impact of the language model training material
• LMa (baseline Hub4 LM): newspaper and newswire (News), commercially produced transcripts (Com) pre-dating June 1998, and acoustic transcripts
• News.Com.Cap: newspaper and newswire, commercially produced transcripts, and closed-captions (Cap) during May 1998
• News.Com: newspaper and newswire, and commercially produced transcripts during May 1998
• News.Cap: newspaper and newswire and closed-captions during May 1998
• News: newspaper and newswire during May 1998
• News.Com97: newspaper and newswire during May 1998, commercially produced transcripts during December 1997
• News.Com97.Cap: newspaper and newswire and closed-captions during May 1998, commercially produced transcripts during December 1997
• News97: newspaper and newswire during December 1997
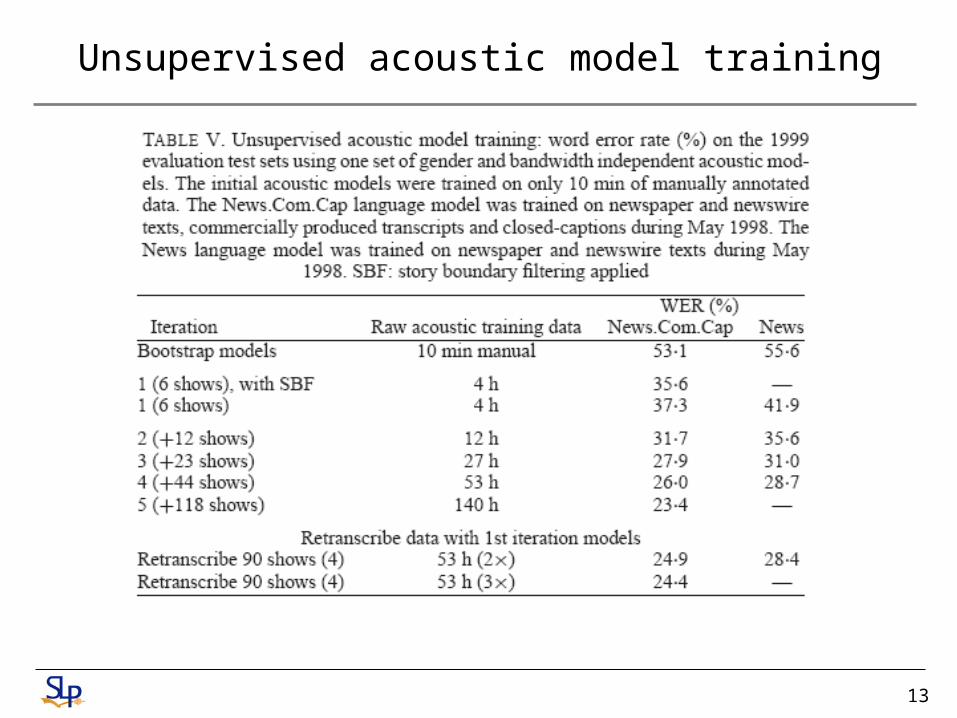
13
Unsupervised acoustic model training

14
Unsupervised acoustic model training

15
Conclusions
• In this work, we have investigated the use of low cost data to train acoustic models for broadcast news transcriptions
• This method required substantial computation time, but little manual effort
• A question that remains unanswered is:– Can better performance be obtained using large amounts of
automatically annotated data than with a large, but lesser amount of manually annotated data?and if so, how much data is needed?

Unsupervised Training of Acoustic Models for Large Vocabulary Continuous Speech Recognition
Frank Wessel and Hermann Ney
RWTH Aachen, Germany
IEEE SAP January 2005
Reporter: Shih-Hung Liu 2007/03/05

17
Outline
• Abstract
• Introduction
• Description of the training procedure
• Bootstrapping with an optimized system
• Bootstrapping with a low-cost system
• Iterative application of the unsupervised training
• Unsupervised training of an across-word system
• Conclusions and outlook

18
Abstract
• For LVCSR systems, the amount of acoustic training data is of crucial importance
• Since untranscribed speech is available in various forms nowadays, the unsupervised training is studied in this paper
• A low-cost recognizer is used to recognize large amount of untranscribed acoustic data
• These transcriptions are then used in combination with a confidence measure which is used to detect possible recognition errors
• Finally, the unsupervised training is applied iteratively

19
Introduction
• The building of a recognizer for a new language, a new domain, or different acoustic conditions usually requires the recording and transcription of large amounts of speech data
• In contrast to the early days of speech recognition, large collections of speech data are available these days
• Unfortunately, most of the acoustic material comes without a detailed transcription and has to be transcribed manually
• One possible way to reduced manual effort is to use an already existing speech recognizer to transcribe new data automatically

20
Description of the training procedure

21
Description of the training procedure

22
Description of the training procedure

23
Appendix – confidence measure example

24
Bootstrapping with an optimized system

25
Bootstrapping with an optimized system
• These results can be attributed to two opposed effects: – If the recognizer used to transcribe the data is trained on large
amounts of material as in the experiments above, most of the incorrectly recognized words in the transcription will be acoustically very similar to the words originally spoken
• The negative impact of these errors is thus only small since the acoustic models are defined on a phonetic level
– Confidence measure cannot improve the performance since they do not only exclude words from the training which might be erroneous but since they also reduce the amount of training material for the acoustic models
• The trade-off between these two effects is an obvious explanation for the above results

26
Bootstrapping with an optimized system
As the experiment clearly shows, the automatically transcribed training corpus can be used successfully to argument an already existing training corpus and to reduce the WERs on the testing corpus
w1 sil w2
sil w2

27
Bootstrapping with a low-cost system
• The scenario for the following experiments is as follows:– It is assumed that 72h of the Broadcast New97 training corpus
are not transcribed, but chopped into suitable audio segments– It is also assumed no initial acoustic models, no initial phonetic
CART, and no initial LDA matrix are available
• In such a scenario, it appears to be straightforward to transcribed a small amount of the training corpus manually, to train a recognizer and to generate transcriptions of the rest of the training data

28
Bootstrapping with a low-cost system

29
Bootstrapping with a low-cost system

30
Iterative application of the unsupervised training
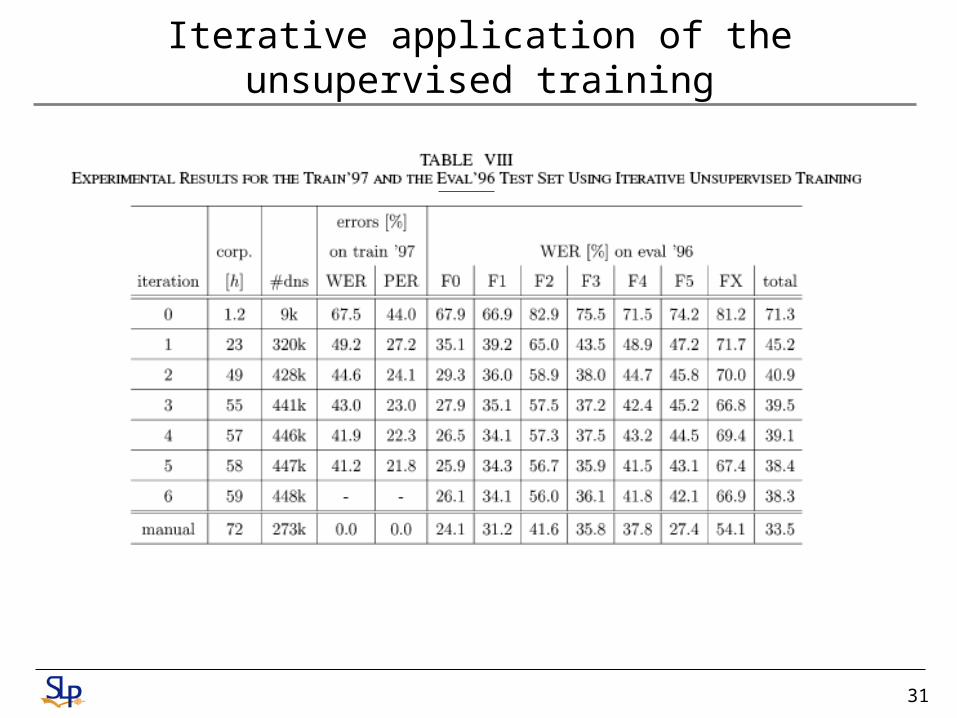
31
Iterative application of the unsupervised training
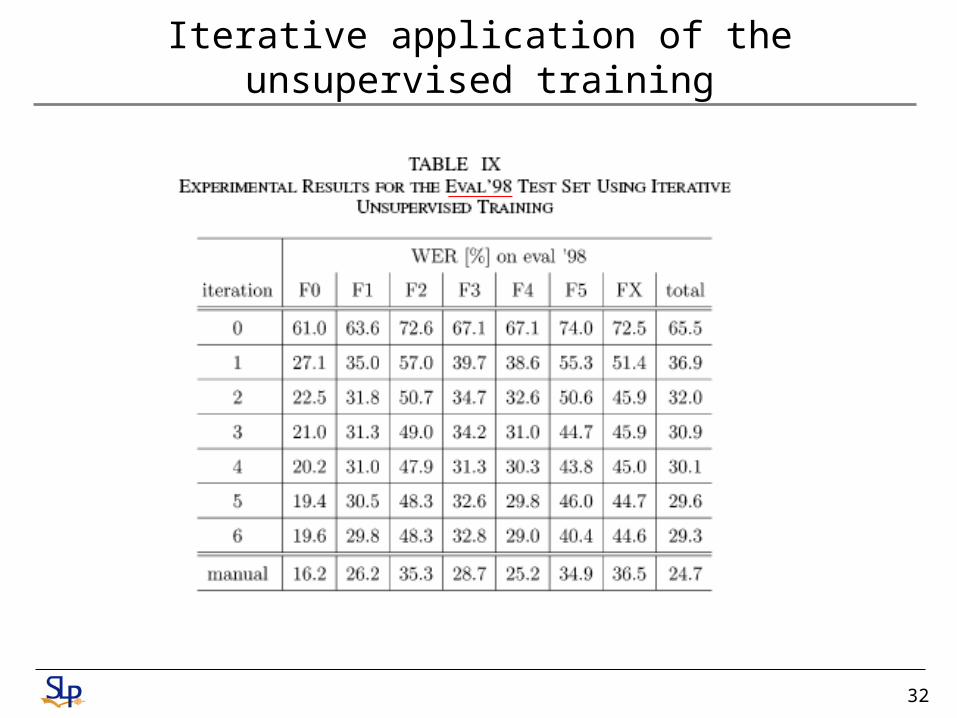
32
Iterative application of the unsupervised training

33
Unsupervised training of an across-word system

34
Conclusions and outlook
• The experiments show that confidence measures can be used successfully to restrict the unsupervised training to those portions of the transcriptions where the words are most probably correct
• With the unsupervised training procedure, the manual expenditure of transcribing speech data can be reduced drastically for new application scenario









![PUBLICATIONS - LIMSI · Publications List [27]S. Matsoukas, J.L. Gauvain, G. Adda, T. Colthurst, C.L. Kao, O. Kimball, L. Lamel, F. Lefevre, J. Ma, J. Makhoul, L. Nguyen, R. Prasad,](https://static.fdocuments.net/doc/165x107/5f418e12c898741fd96e5b9a/publications-limsi-publications-list-27s-matsoukas-jl-gauvain-g-adda.jpg)








