
Les Indicateurs sociaux: problèmes de définition et de...
33
v) a, O S a, O v) .I u a, v) a Q U w 8 No 30 Les indicateurs sociaux : problèmes de définition et de sélection Unesco
Transcript of Les Indicateurs sociaux: problèmes de définition et de...

v) a, O S a, O v)
.I
u a, v)
a Q
U
w 8
No 30 Les indicateurs sociaux :
problèmes de définition et de sélection
Unesco

RAPPORTS ET DOCUMENTS DES SCIENCES SOCIALES
Les rapports et documents du Centre d’information de sciences sociales sont destinés à fournir un matériel documentaire à un public restreint de spécialistes, au fur et à mesure de l’exécution du programme de l’Unesco dans le domaine des sciences sociales. Il s’agit soit de rapports concernant le programme ordinaire de l’Unesco et ses programmes opérationels d’aide aux Etats membres soit de documents fournissant des renseignements sous forme de bibliographies, répertoires et annuaires.
Le contenu de ces rapports et documents engage la seule responsabilité de leurs auteurs dont les opinions ne reflètent pas nécessairement celles de l’Unesco.
sociales paraissent sans périodicité stricte. Les documents publiés par le Centre d’information de sciences
Sont actuellement disponibles : SS/CH 11 - SS/CH 15 - SS/CH 17 -
SS/CH 18 - SS/CH 19-
SS/CH 20 -
SS/CH 21 -
SS/CH 22 -
SS/CH 23 - SS/CH 24 -
SS/CH 25 - SS/CH 26 - SS/CH 27 - SS/CH 28 - SS/CH 29 - SS/CH 30 -
Répertoire international d’institutions qui s’occupent d’études de population (bilingue : français/anglais), 1959. Coopération internationale et programmes de développement économique et social (bilingue : français/anglais), 196 1. Répertoire international des instituts d‘enquête sociale par sondages (en dehors des Etats-Unis d’Amérique) (bilingue : français/anglais), 196 2. Activités en matière de sciences sociales de certaines académies de sciences d’Europe orientale, 1963. La modification des attitudes. Inventaire et bibliographie de certains travaux de recherche, 1964. Répertoire international des centres de recherche sociologique (en dehors des Etats-Unis d’Amérique) (bilingue : français/ anglais), 1964. Les organisations internationales de sciences sociales. Edition revisée avec une introduction de T.H. Marshall (bilingue : françaislanglais), 1965. Institutions effectuant des travaux dans le domaine de la planification économique et sociale en Afrique. (bilingue : français/anglais), 1966. Répertoire international des institutions spécialisées dans les recherches sur la paix et le désarmement, 1968. Guide pour l’établissement de centres nationaux de documen- tation en sciences sociales dans les pays en voie de développe- ment, 1969. Les données écologiques dans la recherche comparée, 1970. Archives de données de sciences sociales : Objectifs, fonctionnement et problèmes, 1973. DARE Système de dépistage automatique des données pour les sciences sociales et les sciences humaines de l’Unesco. 1973. Répertoire international des institutions de recherches sur la paix et les conflits. 1973. Le modèle de simulation de l’Unesco pour l’éducation (ESM) Les indicateurs sociaux : problèmes de définition et de sélection

Les indicateurs sociaux :
problèmes de définition et de sélection Division des méthodes et de l’analyse Département des sciences sociales
Unesco

Publié par Les Presses de l’Unesco 7, place de Fontenoy, 75700 Paris
ISBN 92-3-201 161-1 Edition anglaise ISBN 92-3-101161-8
Imprimé dans les ateliers de l’Unesco
Q Unesco 1975 [BI

Préface
Le présent document est à considérer dans le context du projet de l’Unesco relatif aux indicateurs des ressources humaines.
L‘Unesco a organisé à Varsovie, en 1967, une réunion spéciale d’experts chargés de discuter les approches envi- sageables pour l’élaboration d’un système d’indicateurs du développement des ressources humaines, et d’émettre un avis sur le choix des méthodes les mieux appropriées. Les participants à cette réunion ont examiné divers documents traitant du concept et de la théorie du développement, des procédures d’évaluation des données sur le personnel hautement qualifié et des méthodes à employer pour classer les pays suivant leur degré de développement.
Le projet a pris corps pendant les années suivantes, grâce au concours d’un groupe consultatif qui s’est réuni plusieurs fois. Des groupes de travail ont examiné les tra- vaux accomplis, qui consistaient principalement en un cer- tain nombre d’études’, et évalué les diverses méthodes con- çues ou mises au point pour aborder les problèmes particu- liers, dont le plus important était la détermination et la sélection des indicateurs. C’est cette dernière question qui fera essentiellement l’objet du présent document, où sera étudié également le problème de définition qui est au centre même du projet tout entier, qu’il s’agisse de la définition du développement qui le conditionne ou de celle des indica- teurs eux-mêmes dont il traite.
En 1969, année de sa première réunion, le groupe con- sultatif a commencé par passer en revue une première liste d’indicateurs des ressources humaines. Il devait égaie- ment régler certains points controversés et formuler des recommandations quant à l’orientation pratique de la suite des travaux de recherche. Les autres sujets examinés ont été la notion de ressources humaines, la pondération des différents indicateurs des ressources humaines et le rôle de ces ressources dans le développement. A sa deuxième réunion, tenue en 1970, le groupe a exa-
miné des documents et études réalisés sur la base des re- commandations formulées à la première. Mais il s’est moins attaché à la définition des concepts, aux aspects descriptifs des ressources humaines et aux problèmes mathématiques de choix et de pondération des indicateurs, pour faire une
plus large place aux interrelations des ressources humaines et du développement. Dans ce projet, les ressources hu- maines n’étaient pas considéréés sous le seul aspect de la main-d’œuvre ou du potentiel de main-d’œuvre. Le con- cept retenu était assez large pour couvrir, sous l’étiquette “indicateurs des ressources humaines”, des indicateurs qui, dans d’autres programmes de recherche, sont appelés indi- cateurs sociaux, indicateurs socio-économiques, indicateurs de modernisation, et sont censés concerner en même temps la productivité du travail et la qualité de la vie du travailleur. Le classement et le groupement des pays, sur la base d’un
certain nombre d’indicateurs des ressources humaines, ont été opérés suivant des méthodes mathématiques mises au point à cet effet. Les études des écarts et des disparités entre pays exé-
cutées par ces diverses méthodes ont été complétées par des études similaires portant sur des pays pris individuellement.
Le projet relatif aux indicateurs des ressources humaines est arrivé à son terme en décembre 1973 et a fait l’objet d’une dernière réunion en décembre 1973 à l’lnstitute of Development Studies de l’université du Sussex, au Royaume-Uni. Deux nouveaux projets, dont on a claire- ment défini les objectifs, ont été mis en route.
Le premier a trait à l’identification d’indicateurs clés du changement social et économique, destinés à l’évalua- tion du progrès socio-économique au regard des objectifs de la Deuxième décennie des Nations Unies pour le déve- loppement.
Le deuxième porte sur l’utilisation des indicateurs socio-économiques dans la planification du développement. Ces indicateurs répondront mieux aux besoins des plani- ficateurs dans le cas d’un pays particulier que ne le font les indicateurs trop agrégatifs qui sont le plus souvent utilisés aux fins de comparaisons internationales. Les indi- cateurs retenus pour ce projet s’établiront à un niveau d’agrégation moins élevé, tant sur le plan des données so- ciales que sur le plan géographique. Ils auront un rapport
1. Voir la liste de ces études en annexe page 31. (Ces documents ronéotypés seront communiqués SUI demande).
3

avec certaines des principales séries de déterminants de la distribution du développement et du bien-être, tels que: situation géographique et écologie, caractéristiques so- ciales et fonction économique.
Un troisième projet, qui démarrera en 1975, portera sur les indicateurs de la qualité de la vie et de l’environnement.
Ces nouveaux projets font tous intervenir la question des méthodes à employer dans la détermination et la sélection des indicateurs, question qui, avec celle de la définition des concepts, occupait une place privilégiée dans le projet ancien. Le présent mémoire donnera une idée de l’effort entrepris dans ce sens.
4

Table des matières
Première Partie . Problèmes de méthodologie et de sélection des indicateurs sociaux par’Serge Fanchette ............................................ 7
Deuxième Partie . Méthode de sélection d’un ensemble “compact” de variables par Zdzislaw Hellwig ............................................ 13
Troisième Partie . Comment établir une liste d’indicateurs de développement par Branislav Ivanovic .......................................... 23
Annexe ...................................................................... 31
5

Première partie
Problèmes de méthodologie et de sélection des indicateurs sociaux
par Serge Fanchette Division des méthodes et de l’analyse Département des sciences sociales
Unesco
1. DEFINITION ET OBJET DES INDICATEURS SOCIAUX
La première question qui se pose est celle de la définition d’un indicateur social, qui entraîne, par voie de consé- quence, celle de son objet. La plupart des définitions pro- posées font état des buts des indicateurs sociaux, rendant ainsi artificielle la distinction définition/objet. Des défi- nitions très diverses apparaissent dans la documentation de plus en plus abondante consacrée aux indicateurs sociaux, allant de l’application de ce terme aux “bonnes statistiques sociales” présentées sous forme de séries temporelles à des séries spécifiquement adaptables à des modèles socio- logiques ou à des modèles de politique sociale ou de déve- loppement social. Dans cette gamme étendue s’insèrent des indicateurs qui, sous l’appellation générale d’indicateurs “sociaux”, sont définis comme normatifs, une distinction supplémentaire étant faite entre les variables d’entrée et les variables de sortie, c’est-à-dire entre les indicateurs des moyens et les indicateurs des résultats. Il existe aussi des variables “structurelles”, caractérisées par leurs relations mutuelles dans les limites d’une partie d’un système social général, par opposition à celles qui se prêtent à une certaine sommation en un indice composite. On trouve enfin les indicateurs qui ne s’inscrivent dans aucun système et qui constituent des indicateurs de performance de l’état social, etc.
Tous ces aspects sont associés dans la définition de Stuart Rice : “Les indicateurs sociaux sont nécessaires pour trouver un chemin dans le labyrinthe des interconnexions sociales. Ils permettent de caractériser les états sociaux, de définir les problèmes sociaux, et de dégager les tendances sociales, que l’ingénierie sociale pourra, on l’espère, orienter dans le sens des objectifs sociaux formulés par la planifica- tion sociale ”. Cette définition met en lumière trois éléments princi-
paux qui caractérisent les indicateurs sociaux et leur but : (i)
(ii)
leur fonction descriptive : description d’états sociaux et de tendances du changement social; leurs interconnexions, qui appellent une approche systémique ;
(iii) les instruments d’analyse qu’ils peuvent apporter au planificateur en lui permettant de suivre l’évolution sociale.
Le (i) paraît constituer la principale fonction générale des indicateurs. Le (ii) suppose qu’on construise un système d’indicateurs ou des modèles dans lesquels soient intégrés au moins certains des principaux constituants de la réalité sociale. Des difficultés conceptuelles liées aux nombreuses complexités résultant notamment de l’interaction des fac- teurs empiriques et théoriques font qu’on n’est pas allé très loin dans la construction de modèles sociaux. On a, dans ces essais, ou bien trop simplifié le réel pour appréhender certaines relations envisageables entre un très petit nombre de variables sociales, ou bien tenté d’introduire dans le modèle de si nombreux paramètres relatifs à une multitude de phénomènes sociaux qu’il devenait impossible de perce- voir les relations qui pourraient exister entre eux.
On a généralement négligé le (ii), pour passer directe- ment du (i) au (iii), c’est-à-dire du descriptif au prescriptif, par une approche intuitive ou heuristique, et plus souvent par la première que par la seconde.
La définition de Stuart Rice, notamment par le côté pragmatique de son approche, trouve un écho dans cette citation d’un ouvrage publié sous la direction de Sheldon et Moore et intitulé : Indicators of Social Change (New York, Russell Sage Foundation, 1968, p.4) : “La notion d”indi- cateurs sociaux’ séduit particulièrement ceux qui ont ac- cepté la tâche d’introduire des changements officiellement admis. Ils permettraient, en effet, de relever l’état actuel d’une partie de l’univers social et de dégager les tendances passées et futures, progressives ou régressives, d’après certains critères normatifs. La notion d’indicateurs sociaux mène immédiatement à l’idée d’une observation systéma- tique du changement social. Si l’on arrive à trouver un indi- cateur significatif d’un ensemble de changements en corré- lation, et si une intervention est possible (dans la variable première, indicative, ou l’un de ses constituants systé- miques), on aura peut-être apporté à l’administrateur de programme un moyen puissant d’analyse et d’action’’. Cette citation introduit l’hypothèse d’une série de
changements en corrélation dont pourrait rendre compte

un indicateur; les deuxième et troisième parties du présent document s’inspirent de la même idée lorsqu’il s’agit de choisir un nombre réduit d’indicateurs dans la gamme dont on dispose. Dans la partie qu’il a rédigée, Z. Hellwig opère un groupement d’indicateurs du développement à l’aide de graphes taxonomiques sur une échelle de distances cal- culées d’après des coefficients de corrélation. De son côté, B. Ivanovic propose, dans sa partie, un moyen d’établir une liste d’indicateurs du développement fondée sur la 1-distance.
Il semble que la définition de Stuart Rice et la citation de Sheldon et Moore fassent ressortir de manière directe et précise les caractères que doit avoir un indicateur social. Pourtant, tandis que le grand intérêt suscité par les indi- cateurs sociaux croissait au point de constituer ce que l’on a appelé le “Mouvement des indicateurs sociaux”, un cer- tain laxisme s’est manifesté dans l’emploi de ce terme, au point qu’on finit maintenant par l’appliquer à la plupart des statistiques rassemblées généralement à des fins admi- nistratives. On ne sait pas très bien où fixer une ligne de démarcation. A une consultation de secrétariats d’insti- tutions internationales sur les indicateurs sociaux convo- quée à Genève par la Conférence des statisticiens euro- péens, organe de la Commission économique des Nations Unies pour l’Europe, un expert éminent, soucieux de mettre un peu d’ordre dans la terminologie, a proposé de classer les séries statistiques en 6 catégories.’
GROUPE A:
(i) séries statistiques brutes; (ii) “séries clés”, c’est-à-dire, par exemple, celles que le
simple bon sens fait considérer comme les séries les plus intéressantes ou les plus importantes. Celles qu’on a retenues au Royaume-Uni et publiées dans Social Trends pourraient être considérées comme le fruit d’une sélection réfléchie, sinon rigoureuse;
(iii) le Système de statistiques sociales et démographiques des Nations Unies dont les éléments restent encore une matière première, mais sont présentés de façon complète et systématique.
GROUPE B:
(iv)
(v)
(vi)
indices composites obtenus en combinant d’une manière ou d’une autre des séries individuelles; séries “représentatives”, obtenues par des techniques multivariées, telles que l’analyse discriminante, etc; séries qui s’adaptent explicitement à des modèles sociaux.
Les Nations Unies essaient de mettre au point un “Système de statistiques démographiques et sociales’: Les nom- breux documents de travail établis pour les réunions aux- quelles ce projet a donné lieu ne proposent aucun critère de différenciation entre les indicateurs sociaux et les sta-
tistiques socio-démographiques. Par exemple, certains ta- bleaux de l’un de ces documents2 font apparaître, dans leurs colonnes 1 et 5, des statistiques portant la double étiquette “données statistiques” et “indicateurs sociaux”, sans justification apparente. Il est exact que la plupart des séries dont font état ces tableaux pourraient être classées dans une rubrique “information sociale” ou “comptabilité sociale”. Faute d’un modèle social auquel “ces indicateurs s’adaptent explicitement”, on peut encore employer cer- tains critères, fondés sur une connaissance spécialisée, pour choisir des indicateurs sociaux à une fin particulière. Une statistique sociale ne peut être considérée comme un indicateur social que dans un domaine social spécifique et pour un objectif spécifique. Au lieu de dresser une longue liste d’“indicateurs sociaux” à usage universel, il vaudrait mieux sans doute examiner de très près chaque indicateur envisageable dans le contexte de domaines particuliers d’intérêt social, en le soumettant à un traitement inter- disciplinaire rigoureux. Le Système de statistiques sociales et démographiques des Nations Unies pourrait être consi- déré comme une mise en ordre et une classification com- plètes et systématiques d’une matière première, d’où son inclusion dans le Groupe A (iii). Certaines des données sur lesquelles sera axée cette présentation permettront de construire divers indicateurs, ou pourront même servir directement d’indicateurs sans autre manipulation. L’approche inductive sur laquelle se fondent actuellement, en grande partie, la collecte et le choix des données devrait laisser la place à une approche déductive; l’identification des besoins, des aspirations et, de façon générale, des préoccupations sociales devrait influer sur la collecte et le regroupement des données pertinentes et, par conséquent, précéder ces opérations. Les travaux consacrés par l’Unesco aux indicateurs du
domaine des sciences sociales ont été axés, jusqu’à tout récemment, sur les indicateurs des ressources humaines. Ceux-ci ne sauraient être tous qualifiés d’indicateurs so- ciaux, et la plupart même ne pourraient l’être, assurément, si l’on appliquait sans nuances la définition de Rice. Beau- coup des éléments considérés comme des indicateurs des ressources humaines dans les travaux de l’Unesco satisfe- raient à la définition des indicateurs sociaux implicite dans certains tableaux des documents des Nations Unies. Mais de nombreuses autorités considéreraient que cette définition manque par trop de rigueur et que le terme est entendu dans un sens beaucoup trop lâche. La liste des indicateurs des
1. Ce participant a ajouté plus tard qu’“il ne voudrait pas qu’on accorde à ses propositions plus de poids qu’elles en méritent” et que “cette classification était imparfaite a bien des égards”. Il a dit ensuite qu’“un indicateur social devait essentiellement, par définition, être indicatif de quelque chose d’autre’’ et que, pour cette raison, il était tenté de limiter l’emploi du terme à la catégorie (vi). Mais il a estimé que c’était trop demander, “car on voudra presque certainement l’utiliser pour d’autres caté- gories. Au fond, ce qui importe c’est de penser en fonction d’une hiérarchie de types de séries”.
2. U n système de statistiques démographiques et sociales relié au système de la comptabilité nationale (E/CN3/432), Nations Unies, Genève.

ressources humaines qui a été dressée à mesure que se déroulait l’exécution du projet ne les qualifie pas d’indi- cateurs sociaux. On fait état, pour les différents domaines retenus, d’indicateurs de l’éducation, d’indicateurs de la santé, d’indicateurs de l’emploi, etc. Ils seraient à consi- dérer tout d’abord comme les indicateurs “définition- nels”, c’est-à-dire se référant à des phénomènes identiques en tout ou en partie à “l’indicateur”. Les autres seraient à considérer comme “inférentiels”, c’est-à-dire comme reflétant indirectement le phénomène non observable ou non observé directement. Les indicateurs de l’éducation sont ainsi dénommés parce qu’ils sont relatifs à l’éducation et, par conséquent, “définitionnels”. Mais ils pourraient aussi être des indicateurs “inférentiels” des ressources hu- maines, en ce sens qu’ils expriment le “flux” que représente la mise en valeur des ressources humaines. Ils mériteraient mieux alors le nom d’indicateurs, au deuxième sens du terme, car beaucoup pensent qu’un indicateur doit, par dé- finition, être indicatif de “quelque chose d’autre’’ (voir la note 1 de la page 8). Les séries classées comme indicateurs des ressources hu-
maines dans le projet de l’Unesco appartiendraient au type (ii) du groupe A (voir page 8).
2. INDICES COMPOSITES
Quelle que soit l’appellation qui leur convienne, de nom- breuses séries de la liste de l’Unesco ont parfois été grou- pées en des indices composites en vue de servir de mesure du développement plus appropriée que le PIB, pour per- mettre des comparaisons internationales et pour montrer l’évolution dans le temps au niveau national et internatio- nal. De nombreuses méthodes très élaborées (telles que la taxonomie de Wroclaw, méthode de la 1-distance) ont été utilisées pour calculer de tels indices. 11 y a quelques années, le souci de disposer d’une “mesure” du développement “social” correspondant à celle que constitue le PIB pour le développement économique a conduit d’autres organi- sations à construire diverses indices, dont les plus intéres- sants ont été les différents indices du “niveau de vie” élaborés sous l’égide des Nations Unies, qui ont fait l’objet d’importants travaux d’ordre conceptuel et métho- dologique à l’Institut de Recherche des Nations Unies pour le développement social, à Genève. Ce désir de calculer, d’une façon ou d’une autre, le “bonheur national brut” procédait de la conviction que le PIB n’est pas tout et n’exprime pas, de lui-même, l’état de bien-être de la popu- lation. Mais le rapprochement de ces deux notions a mal- heureusement tourné à l’obsession et le PIB, malgré ses nombreuses insuffisances, est omniprésent, à tel point que le système de comptabilité sociale envisagé tend à être par trop calqué sur celui de la comptabilité économique. L‘opération qui consiste à additionner les constituants de la production, sur la base d’une commune mesure com- mode telle que leur prix, ne pose pas les nombreux pro- blèmes conceptuels liés à la sommation des constituants du bien-être et, a fortiori, du “bonheur”. Dans un bref ar- ticle de son numéro du 25 décembre intitulé “Where the
grass is greener”, l’Economist, à propos de la construction d’un “thermomètre social qui ferait le pendant du calcul du produit national brut”, écrivait : “Il est incontestable que les statistiques sociales se perfectionnent et se déve- loppent; les statisticiens se lancent dans des tentatives de plus en plus ambitieuses pour comparer des choses qui n’ont guère de commune mesure et pour dresser, sur la base d’un calcul des priorités dans les services sociaux, des bilans statistiques ingénieusement présentés. Mais le choix des composantes d’un indice global de la qualité de la vie et la détermination des pondérations à leur appliquer est une tâche auprès de laquelle le calcul du PNB semble un jeu d’enfant ...” A propos des différentes définitions d’un indicateur
social, le Professeur Claus Moser, Directeur de l’Office de statistiques de Londres, écrivait récemment : ... “certains auteurs estiment que les indicateurs sociaux doivent néces- sairement être des combinaisons de séries, c’est-à-dire des nombres indices, au sens classique du terme. Mais c’est là en restreindre fâcheusement le sens. Même abstraction faite de toute autre considération, le calcul de tels indices se heurte à de sérieux obstacles d’ordre technique - surtout en ce qui concerne le problème de la pondération. Les in- suffisances dans les concepts, la mesure et l’interprétation ont des effets cumulatifs et, dans notre méthode d’approche, il n’est envisagé de travailler sur des combinaisons de nombres indices qu’à des étapes ultérieures ...”
Il semble donc que la construction d’indices composites, malgré les grosses difficultés indiquées plus haut et l’échec par lequel se sont soldées les nombreuses tentatives de mise au point ou d’exploitation de ces indices, reste inscrite au programme de travail sur les indicateurs de bon nombre d’organisations et instituts. 11 faut bien dire que, de façon générale, la construction de tels indices a perdu beaucoup de son attrait, en raison des nombreuses insuffisances si- gnalées par le professeur Moser. Mais il n’en reste pas moins que ces activités vont se poursuivre encore assez longtemps. Le travail d’agrégation qu’elles impliquent est essentielle- ment conditionné par des problèmes de choix et de pondération.
La répartition entre les différents domaines, dans la liste Unesco des indicateurs des ressources humaines, n’était pas seulement une affaire de classification. On entendait en effet, dans chaque domaine, regrouper les indices en un indice composite pour ce domaine particulier. Les études sur le problème de la pondération avaient pour objectif, parmi d’autres, de résoudre ce problème d’agrégation.
posite unique a autant d’adversaires que de partisans. Les premiers estiment qu’un indice composite en dit moins que ces-composantes prises séparément et a donc moins d’utilité. Pour ceux qui considèrent que le développement constitue un processus distinctif dont les diverses composantes progressent de façon assez uniforme et continue, un profil constitué par les différents éléments pris séparément est plus révélateur. Il donne un tableau de la mesure de dispersion des facteurs de développement que représentent les ressources humaines, mettant ainsi en lumière les déséquilibres et les disparités du système. D’autre part, si les trajectoires du développement
Le regroupement de plusieurs indices en un indice com-
9

ne sont pas parallèles et s’il existe une certaine possibilité de substitution entre indicateurs d’un même domaine, l’agrégation de plusieurs indicateurs dans le domaine en question pourrait fournir une unité de mesure d’une grande utilité dans les comparaisons internationales.
3. CONSTRUCTION DE MODELES SOCIAUX
D’après la hiérarchie des catégories indiquées à la page 8, établie dans l’ordre selon lequel elles se rapprochent pro- gressivement du concept d’indicateur social, la catégorie (VI) - la dernière - comprend les séries s’adaptant explicitement à des modèles sociaux. Beaucoup pensent qu’elles méritent plus que les autres l’appellation d’indicateurs sociaux. Cer- tains participants à la controverse sur la définition d’un indi- cateur social voudraient réserver ce terme à une série qui “trouve expréssement sa place dans un modèle sociologique ou un modèle de politique sociale”. Les indicateurs écono- miques s’adaptent à des modèles économiques construits sur la base de théories économiques. De même, un indicateur social doit ne pouvoir être interprété que dans le contexte d’une théorie. Cette analogie avec l’indicateur économique doit être poussée jusqu’à une conclusion logique, que beau- coup de spécialistes des sciences sociales considèrent comme la phase ultime d’élaboration des indicateurs sociaux avant qu’ils puissent devenir des auxiliaires utiles de la planifica- tion, et qui est leur intégration, en tant que paramètres, à des modèles sociaux ou des modèles du changement social fondés sur une théorie et une politique sociales. Mais avant qu’on puisse aborder cette phase, les spécialistes des sciences sociales devront procéder à l’analyse, que néces- site le travail préliminaire restant à accomplir, de tous les éléments de comptabilité sociale actuellement collectés, c’est-à-dire des indicateurs, pour en dégager la signification dans l’absolu et dans le contexte où ils s’inscrivent. Leur intérêt varie sans cesse, et certains deviennent vite désuets ou sont reconnus non pertinents ou inutiles. D’autres prennent la vedette, en raison de préoccupations vraiment fondées ou simplement parce qu’ils ont la vogue. Voilà maintenant plus de dix ans que la “qualité de la vie” est devenue un souci majeur sans que soient apparus des indicateurs censés la mesurer, même très approximative- ment - des indicateurs qui, espère-t-on, feraient perdre leur primauté, dans l’esprit du public, au PNB ou au taux de croissance économique. Ces indicateurs économiques sont toujours considérés comme bons, encore que des indica- teurs auxiliaires comme le taux d’inflation, la dégradation du pouvoir d’achat, le chômage ou l’inégalité de distribu- tion du revenu, qui auraient plus de pertinence, reçoivent rarement des spécialistes du développement toute l’atten- tion dont ils devraient faire l’objet dans la planification. Les indicateurs censés caractériser la “qualité de la vie” n’ont donc pas été mis au point. Mais on finira par en construire pour décrire les aspects physiques, sociaux et culturels de l’environnement et leur interaction. Il reste encore beaucoup à faire pour construire ou même définir des indicateurs re- présentatifs des préoccupations de notre temps. Si l’on songe que ces proccupations se sont fait jour il y a des
années, ce travail aurait dû progresser beaucoup plus vite. On ne peut plus maintenant prétendre que l’apparition de ces “nouvelles” préoccupations est affaire de mode, ou que cer- taines disparaîtront sans doute avec le passage du temps. L’en- vironnement et la qualité de la vie, sujets d’intérêt relativement nouveaux, sont appelés à prendre plus d’importance dans l’éco- nomie de pénurie où vont sans doute vivre désormais les pas- sagers du vaisseau spatial “Terre”. Ceux qui ont la charge de guetter l’apparition des signaux d’alarme sur des tableaux de bord devenus indispensables devront entreprendre un effort à deux niveaux : au niveau supérieur, ils construiront les indi- cateurs qui serviront de signaux d’alarme en cas de menace pour l’environnement et la qualité de la vie; à un niveau plus modeste, ils étudieront, contrôleront et analyseront la masse de données assemblées périodiquement à grand frais dans des domaines très divers, et en élimineront celles auxquelles on n’a jamais trouvé d’utilisation sans pour autant s’interroger sur l’opportunité de les réunir. L’étude des interrelations des facteurs socio-économiques
- tels que les expriment les indicateurs les plus usuels -et de la croissance économique a beaucoup retenu l’attention. Le choix des indicateurs est beaucoup plus facile dans ce cas. Malheureusement, de nombreux indicateurs intéressant le bien-être d’un pays, la “qualité de sa vie”, ne sont pas tou- jours en corrélation positive avec la croissance économique. De ce fait, les modèles socio-économiques, en dépit de leur nom, n’en font que rarement état et mettent le plus souvent l’accent sur les aspects purement économiques. Ces modèles, malgré leur complexité, ne découragent pas les mo- délistes les plus entreprenants; la facilité relative de concep- tion des indicateurs qui entrent dans leur construction, le fait qu’on peut en disposer et les mesurer aisément et les possibilités immenses de dégager des relations offertes par certains ordinateurs de la troisième génération ont conduit à multiplier les modèles à partir desquels on a souvent bâti des théories après coup. Il est permis de penser que l’élaboration des indicateurs sociétaux, moins ma- térialistes, qui interviendront dans des modèles exprimant le véritable progrès social, l’amélioration de la qualité de la vie et d’autres notions de ce genre, obligera leurs auteurs, en raison de sa difficulté, à des efforts au regard desquels la tâche de l’économètre paraîtra bien aisée. Il faudrait en effet tenir compte de toutes les variables qui s’opposent, se renforcent et s’inhibent les unes les autres en changeant d’orientation avec le passage du temps, entreprise auprès de laquelle l’élaboration des modèles macro-économiques, pour reprendre l’expression de l’article de l’Economist, semble un jeu d’enfant. Ces difficultés sont telles que les spécialistes sont de plus en plus nombreux à les juger insurmontables et à considérer que les modèles sociétaux sont du pur domaine du rêve.
des séries de la page 8, il reste à accomplir une tâche importante : faire un choix, par une méthode inductive, entre les séries normalement collectées qui sont suf- fisamment fiables. Ce choix peut se fonder sur le bon sens, l’intuition ou une approche interdisciplinaire et variera selon les fins particulières auxqueiles les séries sont censées servir. Lorsqu’il s’agit de mesurer le degré de
Avant de construire ces modèles, si l’on respecte l’ordre
10

développement, tant au niveau national qu’au niveau inter- national, il devient nécessaire de simplifier la série d’indica- teurs dont on dispose habituellement. Les Parties II et III proposent des méthodes de sélection d’indicateurs clés du développement socio-économique. Les exemples d’ap- plication des méthodes qu’on y trouvera ont essentielle- ment valeur d’illustration. On a dû, en l’occurrence, se fonder sur les séries habituellement disponibles pour un nombre suffisant de pays. Il ne faut donc pas attacher
trop d’importance à leur choix, dicté plutôt par des consi- dérations de disponibilité que par leur valeur conceptuelle. Les méthodes décrites sont évidemment applicables à des séries méritant davantage le nom d’indicateurs sociaux. Cela étant, elles constitueraient un instrument utile pour l’étude et la sélection d’indicateurs qui, comme l’ont dit Sheldon et Moore, “soient l’expression d’une série de changements reliés par des corrélations’:
1 1

Deuxième partie
Méthode de sélection d‘un ensemble ((compact)) de variables
par Zdzi SI a w Hel I wi g de l‘Institut de hautes études économiques de Wroclaw,
Pologne
1. MODELES EMPIRIQUES DU DEVELOPPEMENT SOCIO-ECONOMIQUE
Nul n’ignore que le problème de la croissance économique constitue l’aspect le plus complexe, le plus ardu et, par conséquent, le plus controversé des sciences économiques théoriques et appliquées. Il a retenu l’attention et l’intérêt de nombreux spécialistes et a été abordé à de nombreux points de vue par beaucoup d’économistes et de mathé- maticiens éminents, selon des perspectives allant d’un exposé historique ou descriptif à la considération de rela- tions causales abstraites et très élaborées.
matiques purement descriptifs ou même plus élaborés, fondés généralement sur une extrapolation des tendances, montrera que s’ils ont leur utilité du point de vue pédago- gique, ils n’aident nullement à résoudre certains problèmes fondamentaux du développement économique qui confron- tent les planificateurs dans leurs tâches quotidiennes. C‘est pourquoi plusieurs spécialistes ont recherché d’autres mé- thodes d’approche des importants problèmes du développe- ment et de la croissance économique. L’une d’elles a été exposée dans la série d’études publiées sous forme de docu- ments de travail au titre du projet de l’Unesco relatif aux indicateurs des ressources humaines. Cette approche fait intervenir un concept que nous
allons brièvement exposer:
Une analyse du parti pratique à tirer de modèles mathé-
(i) L’objet de toute étude scientifique doit être défini avec précision. Les vecteurs sont le moyen de repré- sentation le plus concis et le plus commode pour l’étude des structures politiques, administratives, géographiques ou sociales. L‘objet de l’étude, un pays par exemple, ou l’une quelconque de ses subdi- visions administratives, est généralement un objet géo-politique et socio-économique très complexe. L’emploi de vecteurs permet la précision et la conci- sion qui sont toutes deux très importantes en pareil cas.
(ii) Lorsqu’on veut présenter et décrire une unité socio- économique à l’aide de vecteurs, la partie la plus importante de l’opération est évidemment le choix de composantes vectorielles appropriées.
(iii) Ii faut choisir, entre la liste de toutes les variables envisageables (dont le nombre n’est limité que par la disponibilité des données) et les nombreux sous- ensembles différents de variables choisis, le chemi- nement qui éclairera le mieux les nombreux aspects de l’objet étudié. Une fois choisis des ensembles variables optimaux, il devient possible de représenter les pays par des vecteurs. Cela permet de répartir ces pays en un certain nombre de sous-groupes plus homogènes que l’univers qu’ils constituent. Ce processus de groupage est d’une réelle importance, car il fait apparaître les différences et les similitudes princi- pales entre les pays.
plus en profondeur la nature interne des phéno- mènes en question (par exemple par l’analyse de variance ou des techniques connexes). Il est plus facile de comparer des pays lorsqu’ils sont représentés par des vecteurs. On peut le faire en définissant la “distance” d’un pays par rapport à un autre. Cette distance peut simultanément jouer le rôle de mesure du développement socio- économique (on détermine alors le retard d’un pays par rapport au pays “idéal”) et être considérée comme un indice composite de la performance géné- rale de ce pays dans un domaine particulier de son activité. Des études récentes ont montré que l’emploi de certaines métriques ouvrait les possibilités d’agré- gation ascendante, c’est-à-dire de construire des in- dices composites plus généraux, résolvant ainsi un problème très important d’agrégation des mesures, ou au contraire d’agrégation descendante, c’est-à- dire de ventiler une structure composite en plusieurs parties plus simples et plus élémentaires (voir, par exemple, l’étude dans laquelle S. Fanchette, proposait une méthode d’agrégation et de désagrégation de
(iv)
On peut alors, grâce à l’analyse statistique, étudier
(v)
13

données socio-économiques calculées selon la métrique euclidienne)’. A cet égard, la possibilité d’une analyse et d’une synthèse a été démontrée. Il n’est plus question, à notre époque, de parler du développement d’un pays en le dissociant de son contexte géographique ou de la famille de pays à laquelle il se rattache par des liens géo-politiques. On pourrait même aller plus loin et dire qu’on ne saurait étudier son développement sans tenir compte du reste du monde. Puisque nous ne pouvons pas construire un modèle qui décrive et explique, à l’échelle mondiale, tous les mouvements qui se pro- duisent sur la carte du développement, nous pourrons nous contenter de l’hypothèse fondamentale suivante: le seul moyen de les juger et les mesurer est de pro- céder par comparaison. Les deux principales dimen- sions dans la comparaison sont le temps et l’espace, ce dernier étant compris dans un sens très large. Nous pourrons, en comparant les pays, découvrir le schéma d’une “stratégie du développement bien équilibrée” et aussi retenir, dans un groupe relativement homo- gène de pays, celui qui pourrait avoir, vis-à-vis des autres, le rôle d’un modèle de développement empi- riquement vérifié. On pourrait étudier avec la plus grande attention les cheminements de développe- ment adoptés délibérément ou instinctivement par le pays de référence. Cela veut dire, au fond, qu’au lieu d’essayer de construire plusieurs modèles de développement plus ou moins primitifs (ou plus ou moins élaborés, si l’on préfère cette formule), il serait plus facile, moins coûteux, plus prudent et plus satis- faisant de disposer d’un modèle réel et vivant. Il ne s’agit plus maintenant que de trouver le moyen de découvrir ce modèle dans chaque famille de pays homogènes.
Ayant ainsi esquissé et commenté ce concept, examinons maintenant les aspects méthodologiques et pratiques de la construction de ces modèles empiriques. Le choix des variables aura ici un rôle d’importance capitale.
Dans certains domaines modernes d’expérimentation, par exemple en biologie, en médecine, en agriculture, etc., nous ne sommes pas en mesure d’établir des bases très solides et absolument sûres permettant de décrire et d’ex- pliquer les interrelations de tous les phénomènes en cause. Il y a deux raisons principales à cela :
mettre au point une procédure statistique qui débouche sur la construction de modèles plus ou moins élaborés permettant de simuler, avec un certain degré d’exactitude, le “schéma de comportement” et la performance de l’objet à l’étude.
Cette procédure se déroule généralement en plusieurs étapes :
1. 2.
3.
4. 5. 6. 7. 8. 9.
10.
11. 12.
13.
14. 15.
Reconnaissance préliminaire du domaine d’intérêt. Elaboration des définitions de quelques faits, phé- nomènes, variables et catégories de base. Développement d‘une approche intuitive du pro- blème, formulation d‘hypothèses de travail appor- tant une explication plausible de la structure interne de l’ensemble du système de phénomènes en corré- lation. Conception d’expériences statistiques. Collecte des données. Vérification des données. Analyse préliminaire des données statistiques. Etablissement de tableaux de corrélation. Groupement des unités statistiques (conçues, formel- lement, comme des vecteurs dans un espace à N dimensions). Groupement des variables statistiques, également interprétées comme des vecteurs dans un espace à n dimensions (N > n) Choix des variables les plus représentatives. Agrégation et construction de certains indices composites. Analyse statistique finale et construction de mo- dèles empiriques. Estimation des paramètres. Vérification finale de la correspondance entre la description théorique des phénomènes en cause et leur description réelle.
Comme les étapes 1-9 et 12 ont été étudiées de façon plus ou moins approfondie à l’occasion du projet de recherche sur les indicateurs des ressources humaines exécuté par le Département des sciences sociales de l’Unesco, on se con- centrera ici sur les étapes 10 et il.
2. QUELQUES CRITERES DE SELECTION
On pourrait utiliser bien des méthodes pour choisir cet ensemble de variables. Elles peuvent se ranger en deux groupes selon la nature du critère retenu pour opérer le choix. Si nous décidons, intuitivement ou en nous fondant sur les idées généralement admises, que l’une des variables appartenant à l’ensemble complet de variables envisageables devra servir de critère, nous adoptons alors un critère “endogène”. C’est le cas, par exemple, si nous choisissons
La série de phénomènes est illimitée, du moins en théorie; Il faut compter avec l’incidence considérable de cer- tains facteurs aléatoires, qui introduit des distorsions dans la relation fonctionnelle “pure” entre les va- riables identifiables et mesurables dont on connaît l’intervention.
Face à ce problème épineux de méthodologie, on s’est donné beaucoup de mal depuis quelque temps, dans certains domaines des sciences appliquées (la sociologie et la science économiques sont, à cet égard, de bons exemples), pour
1. Etude XX: Distancebased anaiysis, Numerical Taxonomy and Classification of Countries according to selecteü areas of socio- economic development, par Serge Fanchette (SHC/WS/237, mai 1972), document ronéotypé, Unesco.
14

le PNB par tête comme l’indicateur de performance éco- nomique le plus valable et si nous nous en servons pour mesurer la pertinence du choix des composantes d’un système, dont il fait partie, qui couvre à la fois le domaine économique et le domaine social, et dont la performance économique, mesurée d’après la valeur des biens et services produits, est l’une des caractéristiques.
Après avoir décidé des composantes d’un système repré- sentées par le nombre de variables choisies, on pourra par- fois recourir à une variable “externe” pour mesurer la per- tinence de chacune des variables envisageables que nous avons définies comme pouvant sans doute constituer des éléments de l’ensemble à retenir pour caractériser le sys- tème. 11 s’agit alors d’un critère “exogène” qui peut être, par exemple, un indice composite du développement socio- économique correspondant à la distance par rapport au “pays idéal” dans la taxonomie de Wroclaw! Cette notion introduit une certaine tautologie, car la distance taxono- mique est composée de distances intéressant les dimensions représentées par toutes les variables envisageables. Un meil- leur exemple peut être emprunté à l’analyse en composantes principales, où le critère de choix de la variable la plus re- présentative est le degré de variance totale expliquée.
une méthode mise au point dans quelques études déjà exé- cutées au titre du projet de l’Unesco et qui ont trait à la notion de “capacité maximale d’information” d’une variable explicative! On peut aussi appliquer une méthode mieux connue, qui consiste à examiner la signification statistique des paramètres d’une fonction de régression dans un cas multidimensionnel. Lorsqu’on applique cette méthode, qui fait partie d’un ensemble de méthodes très voisines d’ana- lyse par régression multiple, il est fortement conseillé d’uti- liser la procédure très pratique et efficace de régression et de contrôle de proche en proche. Tous les centres d’infor- matique convenablement équipés disposent, pour ces opé- rations, de programmes tout préparés. On songera toutefois que, si l’on choisit cette méthode, il faudra procéder, au préalable, à la vérification de certaines hypothèses qu’elle fait intervenir en ce qui concerne la distribution aléatoire multidimensionnelle des variables, opération généralement assez fastidieuse.
Si l’on opte pour un critère endogène, on peut appliquer
3. CARACTERE (OU TYPOLOGIE) DES VARIABLES
Il est deux autres points à retenir lorsqu’on étudie les diffé- rentes méthodes de choix, dans l’ensemble des variables envisageables, de la meilleure combinaison possible. Le premier est surtout de caractère théorique et concerne la nature des variables en question. Tous les indicateurs so- ciaux peuvent être considérés comme des variables conti- nues. Cette proposition a des conséquences méthodolo- giques de grande portée. Elle signifie, entre autres choses, que nous sommes en droit d’appliquer des paramètres sta- tistiques fondamentaux tels que la valeur moyenne, l’écart- type ou le cœfficient de corrélation. Elle signifie également que, si nous ne faisons pas intervenir de variables discrètes ou catégorielles, nous pouvons grouper les pays et les va-
riables en utilisant soit la méthode taxonomique de Wroclaw, soit la méthode des composantes principales, pour ne citer que ces deux-là. L’emploi de la majorité des variables socio- économiques retenues pour analyser les aspects statistiques du développement socio-économique postule leur continuité. La gamme de variables pouvant normalement servir à carac- tériser des pays peut en comprendre que nous pourrions qualifier de discrètes ou de catégorielles. On peut citer, parmi celles-ci, le nombre de groupes ethniques vivant dans un pays à société plurale ou le nombre de langues ou de dialectes qui y sont parlés. Ce sont là des exemples de va- riable discrète. Les variables peuvent aussi être catégorielles, par exemple lorsqu’elles revêtent la forme d’une question telle que “le pays est-il membre des Nations Unies? ’; illus- tration d’une variable catégorielle qui ne peut prendre que l’une ou l’autre de deux valeurs diamétralement opposées : l’affirmation ou la négation. Le PIB, l’espérance de vie, les taux de natalité ou de mortalité, qui comptent parmi les variables le plus souvent choisies pour caractériser le déve- loppement socio-économique, sont les variables continues les plus étroitement associées aux variables catégorielles, que le pays puisse être considéré comme peu développé ou relativement développé. Il est bien difficile de traiter simultanément de manière satisfaisante un assortiment disparate de variables continues, discrètes et catégorielles. La distinction entre ces catégories est le plus souvent bien tranchée, mais il arrive qu’elle ne le soit pas, de même que le cours d’un fleuve peut présenter une succession de cascades. Nous citerons comme exemple le flux des véhi- cules dans la rue d’une grande ville et ses interruptions par les feux de circulation, qui transforment un continuum en une suite de quanta. Il est heureux que ce problème de clas- sification ne soit pas à tel point épineux qu’on puisse l’assi- miler à celui de la théorie ondulatoire et de la théorie cor- pusculaire de la lumière qui, de nos jours, pourraient être invoquées pour en expliquer la continuité ou la disconti- nuité. 11 paraît également oiseux de pousser plus loin l’ana- logie avec l’électron, à la fois corpuscule et mouvement ondulatoire.
Quand la liste fait état de tous les types, il faut ou bien transformer, à l’aide d’une échelle appropriée, les variables contenues en variables discrètes, ou faire l’opération contraire.
Dans le premier cas, il ne sera plus question de variables et de leurs valeurs numériques. II faudra les convertir en probabilités satisfaisantes. Cela veut dire, par exemple, que la valeur attendue E (X) devra être remplacée par np, l’écart-type S (X) par [np (1-p)] % et le cœfficient de cor- rélation r (X,Y) par le cœfficient de dépendance stochas- tique; on aura donc
1. Le concept de “pays idéal” est exposé dans 1’Etude III, de Z. Heiiwig.
2. Etudes VI et XVi: On the optimal choice of predictors: Approximative methods of selection of an optimal set of predictors, by Z. Heiiwig.
15

où p.. = probabilités correspondant à (5, Y.); p.,p. - 1J 1 1 1
distributions de probabilité marginale, et s, t =le nombre de lignes et de colonnes dans le tableau des contingences de probabilité. Cela veut dire aussi qu’au lieu d’appliquer une méthode taxonomique facile à comprendre et dont les résultats sont aisément chiffrables, ou la méthode moins facile et plus classique des composantes principales, on devra, pour grouper et choisir les variables les mieux appropriées, trouver des méthodes spéciales pour traiter des valeurs et des catégories discrètes, dont l’une est celle de “l’analyse des correspondances” qu’on peut considérer comme une adaptation de la méthode classique des “com- posantes principales”, destinée à pourvoir au cas où il s’agit de valeurs discrètes. Si, au lieu de convertir des variables continues en va-
riables discrètes, on procédait en sens inverse, cette façon de faire aurait sans doute au moins deux avantages : (a) Comme le nombre de variables discrètes et de caté-
gories de la liste des indicateurs socio-économiques serait très inférieur à celui des variables continues, les calculs nécessaires pour convertir les premières en variables continues seraient beaucoup plus simples que si l’on procédait en sens inverse; Le calcul des variables continues est bien moins compliqué sur le plan conceptuel, parce qu’on les connaît beaucoup mieux. Nous disposons alors non seulement de bien meilleurs instruments d’analyse statistique, mais aussi de nombreux programmes tout préparés si nous décidons d’utiliser l’ordinateur.
(b)
Il existe plusieurs moyens de convertir des variables dis- crètes ou catégorieiles en variables continues. Pour les va- riables discrètes, l’une des techniques les plus courantes est celle de l’interpolation linéaire. On en applique une autre avec succès depuis quelque temps: la procédure dite d’application aléatoire de la linéarisation. Si l’on veut convertir des variables catégorielles en variables continues, l’une des méthodes les plus connues et généralement re- commandées est celle des variables dites “accessoires’:
4. LE PROBLEME DES PONDERATIONS
La technique moderne de représentation de certains objets d’étude scientifique par des vecteurs dans un espace à n dimensions conduit immédiatement à s’interroger sur l’im- portance relative des composantes vectorielles. L‘expérience ou l’intuition, même si l’on connaît mal le domaine dont il s’agit, conduit à penser que les variables, qu’elles soient des- criptives ou explicatives, ne sauraient avoir toutes la même importance relative qu’obscurcit du reste, de prime abord, une présentation des données sous forme brute. Il est
d’usage de normaliser ces variables avant d’en étudier l’im- portance relative par les moyens d’analyse statistique habi- tuels. Les méthodes de normalisation sont tout à fait clas- siques et ne posent pas de réels problèmes. Mais elles s’ap- pliquent à une gamme de pratiques étendue. La méthode classique consistant à remplacer xi par (xi - X) /s (où s représente l’écart-type) introduit aussi l’élément de pondé- ration. Tout en faisant disparaître le problème des unités, elle affecte la variable d’un écart-type moins marqué. Indé- pendamment de ce premier biais, on se heurte au problème plus délicat des pondérations à affecter aux variables, qui ne peut être résolu de manière satisfaisante si l’on n’a pas défini le critère le plus approprié pour évaluer l’importance relative de certaines des variables. On en vient alors à étu- dier les divers critères à envisager pour différencier et hiérar- chiser les variables. Toutefois, comme nous devrons utiliser les mêmes critères pour choisir les variables les plus signifi- catives et en retenir les plus importantes, nous pouvons conclure que le problème que pose le choix des variables et celui de l’importance à leur attribuer en fonction d’un système donné de pondération sont à peu près les mêmes, considérés de deux points de vue différents d’une même idée, en ce sens qu’avant de commencer à parler de pondé- rer des variables, il faut déterminer les critères qui permettent le mieux de les comparer et de les choisir. On retiendra aussi une considération importante en ce
qui concerne les pondérations. Celles-ci s’expriment par des nombres de valeur non négative (p1, p2...pn) tels que
j=l subdivise en de nombreux sous-intervalles, dont la longueur moyenne doit tendre vers zéro. Si donc nous acceptons comme valeur seuil un nombre po tel que O < po < 1 , en retenant toutes les variables 5 correspondant aux pon- dérations p. ordonnées en ordre décroissant et satisfaisant
p. = 1. Si g représente un nombre élevé, l’unité se J
J x p j >/ 1- à la formule
et si, d’autre part, nous considérons que po est une valeur arbitraire susceptible de varier entre deux extrêmes assez écartés et, par ailleurs, qu’on ne pourra jamais calculer assez exactement l’importance relative des variables, il faut admettre, à toutes fins pratiques, que toutes les va- riables retenues ont la même importance relative, qui est considérable, et doivent être affectées du même cœfficient de pondération (p), alors que toutes les variables écartées, étant d’importance mineure, se voient attribuer des cœf- ficients de pondérations q égaux entre eux, mais inférieurs aux pondérations attribuées aux variables retenues (voir la fig. 1). Le problème du choix des variables les plus ap- propriées se ramène donc à un problème de pondération, ‘qui lui-même consiste à trouver une formule (no= f Cpo) ou no p > 1 - po dans laquelle no p + (n-no) q = 1
1 1 Pj puisque p= ”0 pj et q = - 1 n- no
3 \<*O 0 no
16

Nous nous sommes efforcés de montrer que le problème que pose la mesure de l’importance relative des variables (ou des composantes vectorielles à l’aide desquelles nous définissons l’objet de notre étude) est, au fond, un pro- blème de pondération, qui peut toujours se ramener à celui que pose la réduction de la liste initiale des variables envisageables à une liste beaucoup plus courte. Cet ensemble réduit ne devrait faire état que des va-
riables les plus importantes ou les plus représentatives de la série initialement considérée. L’établissement de cet ensemble “compact” conditionne les possibilités d’ana- lyse socio-économique et constitue un aspect essentiel de la théorie des comparaisons internationales dans ce domaine.
p3
Fig. 1 b, - - 9 ~
pj pno ~
C’est là, évidemment, une conclusion dont il ne faut pas sous-estimer l’importance. Au fond, les méthodes sta- tistiques modernes les plus élaborées, telles que le test de Fisher de signification globale des paramètres de régression, la méthode de régression de proche en proche, l’analyse en composantes principales, l’analyse factorielle, la mé- thode de capacité maximale d’information, la méthode d’analyse des correspondances, traitent toutes du même genre de questions : comment déterminer un ensemble compact de variables, comment diviser l’ensemble de va- riables en quelques groupes plus homogènes et comment trouver les meilleurs représentants de groupes particuliers.
Nous exposerons, dans le paragraphe qui suit, une mé- thode très simple et très commode qui pourrait apporter certaines réponses à ces questions. Elle fait appel à des graphes et ne nécessite donc pas le recours aux calculs com- pliqués qui sont inévitables quand on emploie d’autres méthodes, celle de l’analyse en composantes principales par exemple.
5. GROUPEMENT DES VARIABLES PAR LA METHODE TAXONOMIQUE
Pour rendre cette méthode plus aisément compréhensible, nous l’illustrerons, en la présentant, d’ exemples numériques.
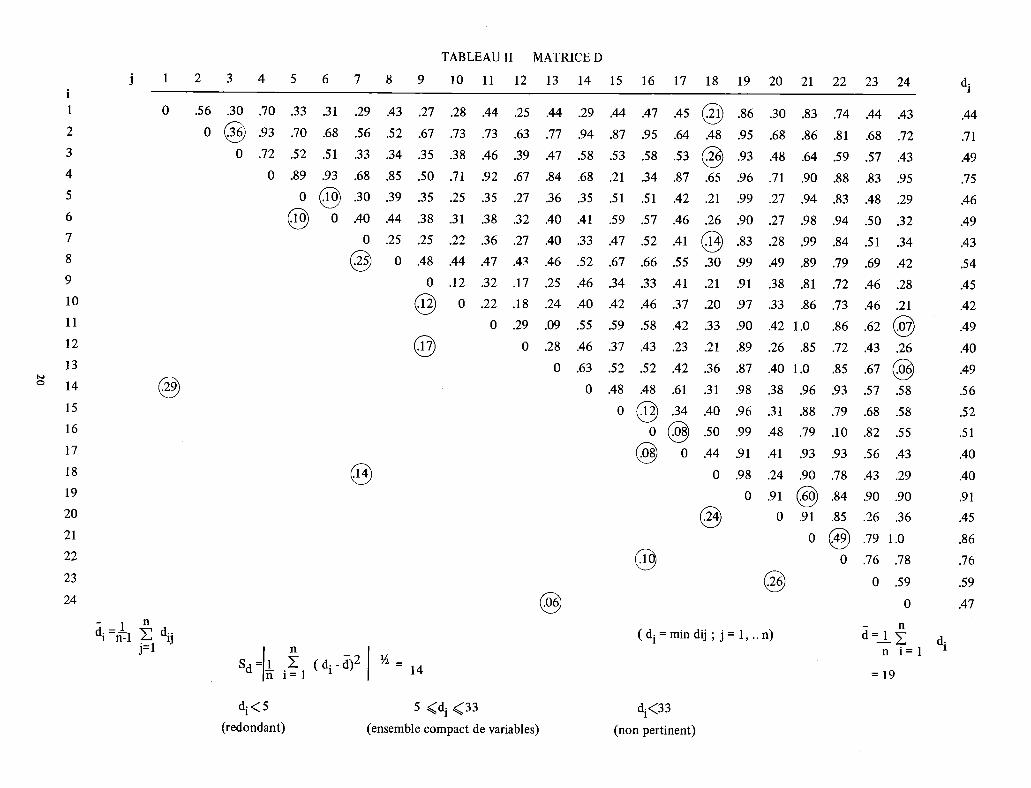
L‘algorithme commence par une matrice de corréla- tion R (n x n) où n représente le nombre de variables (voir le tableau 13). Dans une deuxième étape, nous opérons la transfor- mation suivante d.. = 1 - r au moyen de laquelle la matrice R est transformée en une nouvelle matrice D (voir le tableau 2). Cette matrice est aussi de type (n x n), symétrique, et comporte des éléments d.. où i, j = 1,2 ... et dij > O)
1J Nous devons maintenant découvrir le plus petit élé- ment dans chaque ligne de la matrice D. En désignant ces éléments par di, on a alors di = m 1 n d..
1J
Après avoir découvert di dans la i eme ligne, on trouve le numéro de la colonne dont le croisement avec la ligne en question donne une cellule contenant la valeur di. On obtient ainsi n paires d’indices :
Définissons maintenant quelques termes. Ils seront très simples. Chacune de nos paires d’indices s’appel- lera une arête et i et j 1, dans (i, ji), seront des som- mets.
1~ I ij I
. J
(1 , jl), (2, j2), ........... (n, jn)
Etudes VI, ViI, IX (Documents de travail ronéotypés de ïUnesco). Le Rapport n”70.10 de l’Institut de Recherche des Nations Unies pour le développement social intitulé “Conrenrs and meas- urements of socic-economic development: An empirical enquiry” offre un bon exemple du choix d’indicateurs-clés à partir d‘une gamme étendue d’indicateurs (Genève, 1970). N.V. Sovani. A. M. Subramanian. An index of Socio-economic Development of Nations UNRSIP 1969.
17

Le premier sommet est le début de l’arête, qui se termine au second sommet. Les arêtes peuvent donc être qualifiées d’orientées. Quand nous trace- rons un graphe, tous les sommets seront représentés par des points et toutes les arêtes par des flèches. Le nombre de flèches dirigées vers un sommet caractéri- sera sa puissance. Nous trouvons ensuite le sommet qui a la puissance la plus élevée. S’il en existe plus d’un, nous choisirons celui auquel correspond la valeur la plus faible de
(v)
(vi) Nous devrons relier tous les sommets qui sont le point de départ d’arêtes dirigées vers le sommet de puis- sance la plus élevée à celui-ci. Tous les sommets reliés au sommet de puissance la plus élevée peuvent main- tenant être considérés comme les extrémités d’autres sommets qui sont à relier à toutes ces extrémités. En continuant ainsi à relier les uns aux autres tous les sommets reliés à celui dont la puissance est la plus élevée, on obtient une certaine famille de sommets qui peuvent être appelée la “première concentration” de sommets, ou le premier groupe de points.
(vii) Nous découvrons ensuite tous les groupes correspon- dant aux sommets de puissance inférieure à la puis- sance la plus élevée, par ordre de grandeur décrois- sante.
(viii) Le sommet de puissance la plus élevée d’un groupe en est appelé le centre. Si un groupe contient plus d’un sommet de puissance la plus élevée, nous choi- sirons celui auquel correspond la plus haute valeur de d.. Le centre d’un groupe peut être considéré comme représentatif des variables de ce groupe. L‘ensemble des éléments représentatifs de la totalité des groupes sera dénommé un ensemble de variables clés. La gamme de variation des paramètres di doit main- tenant être divisée en trois parties :
1
(ix)
Tous les sommets d’où partent des arêtes dont la longueur d. J appartient au premier intervalle peuvent être retirés du graphe, et les variables correspondantes peuvent être dénom- mées redondantes. Les sommets qui constituent le point de départ d’autres d’arêtes dont la longueur di entre dans le troisième intervalle peuvent aussi être retirés et les variables correspondantes être considérées comme non pertinentes. Les variables restantes constituent l’ensemble “compact’: Toutes les étapes conduisant à obtenir des groupes parti- culiers, les variables clés et l’ensemble “compact” de va- riables sont récapitulées et illustrées dans les diagrammes qui suivent. La méthode exposée est simple et facile à interpréter.
Elle est également applicable aux variables continues, dis- crètes et catégorielles. Si sa grande simplicité étonne ou éveille des réticences, il en existe d’autres plus élaborées, comme celle de l’analyse en composantes principales, par exemple, qui apporteront de bonnes solutions au problème tel qu’il a été posé ci-dessus, mais à bien plus grands frais.
6. CONCLUSION
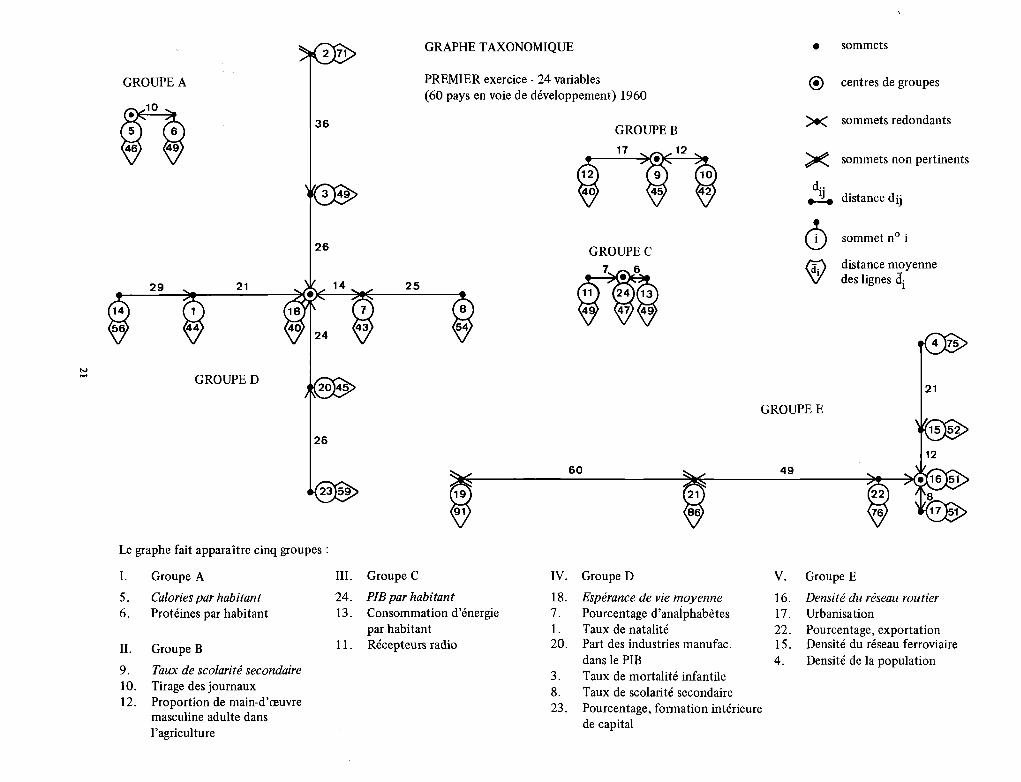
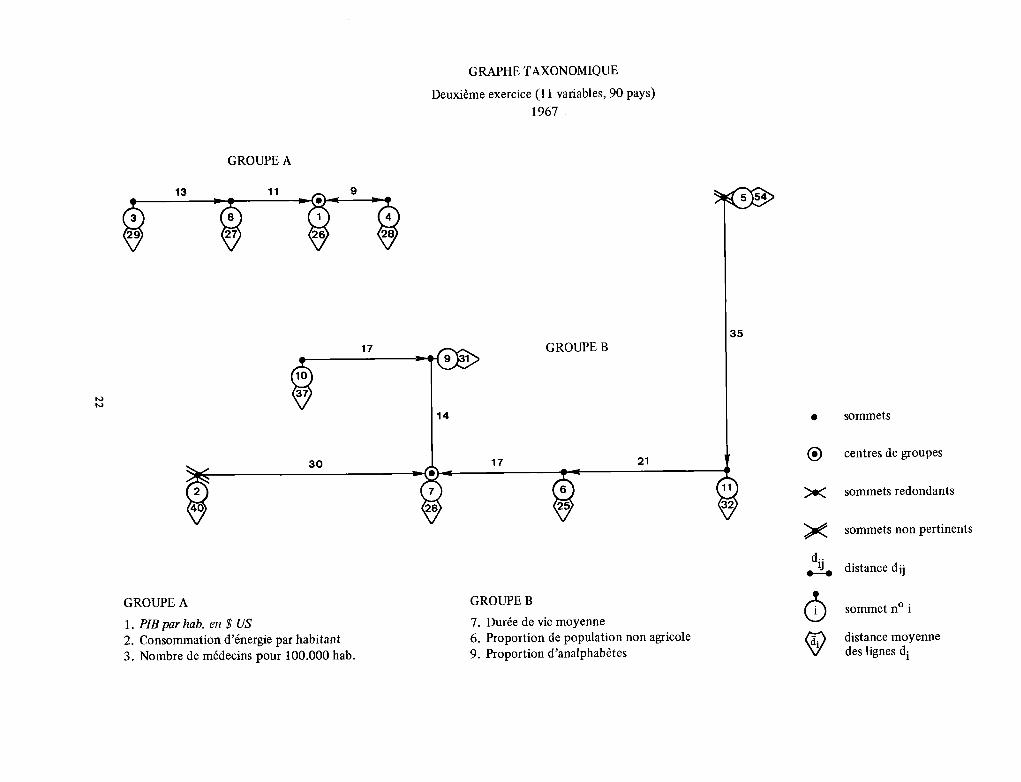
La méthode de sélection ainsi proposée, tout en étant une variation du thème de l’intercorrélation, a le mérite de la simplicité et fournit un tableau clair, grâce au graphe taxo- nomique, des relations et des distances entre les variables. De plus, son élaboration a mis en lumière une idée nouvelle, celle que les problèmes de sélection et de pondération sont étroitement liés et appellent une solution unique. La technique de groupement proposée ici a permis de
déterminer des groupes de variables et des centres de groupes. Chaque centre peut être rendu représentatif de l’ensemble du groupe. L‘accroissement du nombre des variables plus représentatives se traduirait par un mouvement, en cercles concentriques, du centre vers la périphérie, de façon à inclure le nombre de variables à retenir pour une fin parti- culière. Les deux opérations exécutées ont abouti à des graphes taxonomiques reproduits dans les pages qui suivent. Il se peut que, dans chaque cas, le nombre originel de va- riables ait été un peu trop limité pour qu’il soit possible de tirer du groupement beaucoup de conclusions utiles, mais il paraît s’accorder en grande partie avec ce que nous sa- vons déjà - ou ce que nous pressentons - du mouvement relatif des variables dans le processus de développement.
18

d N
m
m
m
c.l
3
N
O
m
2 O0 3
2 \O 3
IA 3
2
m 3
3 3 3
O, m
00
II
\O
IA
d
m
N
3
II 3
\O IA
\O
';? II 3
O
t'.
d
'i!
7
3
m
IA
m
\O
3
7
T! 3
\O
IA P.
\O IA 1' m 7 7
3
m
II
3
r: m
'f! Y 3
II
O
O
t':
t
d
3
*al .z 3 2 2 al -0
X
b
-
O0
';? 3 'i!
'i!
3 4! 3
3 7 m
m
d
N
IA
N
\O
IA
m 1' \O
3
7
7
Cr)
II m.
II 9
';? 3
p. II
m
O0
d T
N 3 I. s O
II
d
u!
3
'al mi x 't: 3
2 al a
X
b 2 hi
IA 9
II 1
m :
% m
c!
9
m d
IA
m 3
\O u!
r: m cl m 3 3 m O0 9
c!
Y
m
O
IA 3.
c.l 3 II 9
3
3.
3
E
O
cd
a
O a
mi a, a
.a, x .e
Y
"1 3
$ n 4
3
P.
N
'". II 3
\O 9
t'.
9
P.
m
3
m
O0 Y
m q
T
u!
u!
m
m
IA
d
7
IA u!
r: u!
u!
IA
IA
3
O 7
O
a!
3
3 ci 8 5 m
al .3
iI
VI
00 9
'". 9
9
u!
O
\O
m
m
O 1
d
t'.
d Y
*. t
W.
O
u!
9
u!
9
u!
-. O
m
3
m
O0
m m
N
\O
Y 3
f 6. m 8 .3 'al Y
e E \O'
a
O0 Y
4
m.
c! 3
3
:
3
Y
3
7
O P.
T
m.
IA
d
m
". t
d Y
W
II IA 1' 0
'". \O m.
m m.
3
al
m
t'.
d Y
O0 m.
% c.l u!
9
t':
m
m
m Y
u!
u!
d Y
II
\O
IA t':
m Y O0 u!
09 O0
i
E .3
mi a
c
m ?
d m.
c! II
d 1
II 9
9
*. u!
d Y
cri
O
m
O0 m.
u!
t'.
O
\O
m g! W
t'.
3
X 2
m
a!
O0
3
d 1
O 9
W. W
O 1
II u!
W Y
N t
T
T
a!
3
IA
3
3
7
3
O 3 E
hl Y
"! N
3
N 3
m u!
8 O
u!
u!
09
\O
O0
3
1
a
IA 3
mm\O
Y Y P.
N
q3
3
3
"3
3
19
O
II -6- W
v1 Y
al
E E P
Y)
al a
3
fi al W y1
2 Y c al O
v1 Y
5 2 E E O,
a c O
W Y)
Y
al
v1 Y
al .3
Y
h
al
c c a
d 8 E v1 *
E P
:p
W al O 9 Y v1 a
w 3 W O
X E O 2 # e?l c3
.3
O C Y
al
E E s
n r
5 (Y
O
d
c3
O)
21
h
5 a
P
4
p?; O ;i"
m 5 O d O YC l-
I- V-
(1
22

Troisième partie
Comment établir une liste d‘indicateurs de développement
par B ra nislav I va novic Ancien directeur de l’Office des statistiques
Conférence des Nations Unies sur le commerce et le développement
1. INTRODUCTION
Le choix des indicateurs du développement socio-écono- mique est certainement un des plus importants problèmes dans l’exécution du projet d’évaluation et de prévision du développement durant la Deuxième décennie des Nations Unies. La qualité des résultats sera d’autant meilleure que l’information sur le niveau du développement des pays, contenue dans les indicateurs choisis, est plus complète.
Il existe aujourd’hui un certain nombre d’indicateurs qui sont bien enracinés dans notre esprit comme étant ceux qui renseignent le plus sûrement sur le développement socio-économique d’un pays et qui sont utilisés le plus souvent dans l’évaluation de son niveau de développement. Par exemple, des indicateurs comme le PIB par habitant, la proportion d’analphabètes, le pourcentage de la popu- lation non agricole ou la part des produits industriels dans le PIB représentent quelques-uns de ces indicateurs classiques.
Cependant, les listes d’indicateurs du développement utilisées dans les différentes institutions de recherche, na- tionales ou internationales, ne sont pas toujours identiques et les controverses ne manquent pas dans la discussion sur l’utilité et l’importance de l’un ou de l’autre de ces indica- teurs classiques. En réalité, on peut se demander, d’une part, s’il existe des raisons objectives de considérer tous ces indices comme des indicateurs du développe- ment socio-économique et, d’autre part, si d’autres in- dices, ignorés ou négligés jusqu’ici, ne seraient pas plus appropriés que ne le sont certains de ceux que l’on envisage traditionnellement. En recherchant ainsi de nouveaux indicateurs de déve-
loppement, nous avons défini et étudié l’indicateur de la “Concentration des naissances d’après l’âge de la mère:’’ C’est un indicateur qui donne l’information sur la qualité familiale d’un pays. Mais il n’est pas difficile de constater qu’il s’agit aussi d’un important indicateur du développe- ment. Remarquons, tout d’abord, que la haute concentra- tion des naissances dans un pays, calculée d’après l’âge de la mère, signifie que le nombre des enfants par famille est
limité, ce qui assure un niveau de vie plus élevé dans ce pays. Ensuite, que le domaine de concentration se trouve entre 20 et 30 ans d’âge de la mère, ce qui veut dire que l’âge des parents permet aux enfants d’avoir une bonne éducation familiale, une protection économique prolongée, un développement physique favorable et une éducation scolaire plus complète. Enfin, si la concentration est grande, on rencontre rarement des cas défavorables comme ceux, par exemple, de mères trop jeunes ou trop âgées, d’enfants nés d’un second mariage, etc. En bref, la vie d’une famille est d’autant plus ordonnée et son activité sur le plan socio- économique d’autant plus efficace que la concentration des naissances, d’après l’âge de la mère, est plus forte. Les analyses quantitatives montrent que cet indicateur
donne plus d’information sur le niveau de développement d’un pays que certains indicateurs classiques comme, par exemple, les exportations d’articles manufacturés par habi- tant, la durée de vie moyenne, la proportion d’alphabètes, la part des industries manufacturières dans le PIB, le taux d’inscriptions scolaires, etc.
tive des indicateurs de développement, il faudrait ajouter aux indicateurs de toutes les listes utilisées jusqu’à présent ceux qui ont été négligés ou ignorés dans le passé.
On formerait ainsi une très longue liste qu’on appellerait la liste maximale des indicateurs du développement socio- économique. Les statistiques de ces indicateurs donneraient des informations très complètes sur tous les aspects du dé- veloppement des pays observés.
Cependant, en examinant toutes les publications statis- tiques du Bureau de statistique des Nations Unies, des com- missions économiques régionales, des diverses institutions spécialisées des Nations Unies ainsi que les publications
On pourrait conclure que, pour arriver à une liste exhaus-
1. Pour le pays j, la mesure de cet indicateur est donnée par
oÙ n représente le nombre de groupes d’âge, x ?J .. le nombre de naissances où i’âge de la mère appartient au i-eme groupe et Xj le nombre total de naissances dans le pays j au cours de l’année observée.
23

nationales et d’autres documents publiés soit officiellement, soit officieusement, nous pouvons constater que le choix des indicateurs de développement est très limité du fait de l’absence de données statistiques relatives à de nombreux pays en voie de développement.
L‘absence ou la mauvaise qualité des données statistiques empêche l’introduction d’un grand nombre d’indicateurs de développement comme, par exemple, ceux qui renseignent sur la productivité du travail dans l’industrie ou dans l’agri- culture, sur le niveau de vie de la population, l’infrastructure, les cadres dans l’industrie et l’enseignement, etc.
L‘introduction d’un seul indicateur dans le système sta- tistique d’un pays exige souvent l’organisation d’un nouveau service doté de cadres compétents et d’un équipement adéquat qui serait apte à compiler, traiter et publier les données, Ces données devraient être d‘une bonne qualité et comparables à celles des autres pays.
dans notre liste d’indicateurs de développement exige du temps, de nouvelles institutions et de grands sacrifices financiers. Il va sans dire que ce problème est encore plus grave dans les pays en voie de développement.
Pour suivre le développement des pays au cours de la Deuxième décennie avec une précision qui serait suffisante pour atteindre nos objectifs, quelques nouveaux indicateurs devraient incontestablement être introduits dans la liste d’in- dicateurs de développement. Mais lesquels faut-il choisir parmi tant d’indicateurs déjà proposés? Le premier problème à résoudre dans l’exécution du pro-
jet d’évaluation et de prévision du développement au cours de la Deuxième décennie sera donc l’établissement scienti- fique d’une liste optimale d’un nombre réduit d’indicateurs de développement.
Par conséquent, l’introduction de nouveaux indicateurs
2. CRITERE DU CHOIX DES INDICATEURS DU DEVELOPPEMENT SOCIO-ECONOMIQUE
Divers indicateurs statistiques peuvent être utilisés pour esti- mer et suivre le développement socio-économique d’un pays. Chacun de ces indicateurs apporte une information partielle sur le niveau du développement et, en général, ces informations par- tielles ne sont pas identiques. Ainsi, par exemple, l’indicateur “Pourcentage de la population non agricole” nous apporte une information sur le niveau de développement d’un pays qui n’est pas identique à celle apportée par l’indicateur “Consommation d’énergie par habitant”. Il faut donc choisir et former tout un ensemble d’indicateurs pour avoir une idée plus complète sur le niveau du développement des pays observés.
dicateurs, on augmente l’information globale sur le niveau de développement des pays observés. Les différents indicateurs de développement ne con-
tiennent pas le même volume d’information sur le niveau de développement d’un pays. Cela veut dire qu’ils n’ont pas la même importance par rapport au développement. Ainsi, le “PIB par habitant” apporte plus d’informationi sur le niveau de développement socio-économique d’un pays que, par exemple, l’indicateur “Durée de vie moyenne
Première conclusion E n augmentant le nombre d’in-
24
des habitants”. Si la quantité d’information contenue dans un indicateur de développement est mesurable, on pourra établir un classement de ces indicateurs d’après leur importance.
Deuxième conclusion : Des ensembles d’indicateurs de m ê m e taille ( m ê m e nombre d’indicateurs) ne contiennent pas, en général, la m ê m e quantité dhformation sur le ni- veau de développement d’un pays.
Les indicateurs du développement ne sont, en général, pas indépendants les uns des autres, de sorte que l’information fournie par un indicateur est contenue, en partie, dans l’information qui a déjà été fournie par les autres indica- teurs. En prenant donc en considération tout l’ensemble des indicateurs choisis, il se pourrait que certaines quan- tités d’information se répètent deux ou plusieurs fois. Il va sans dire qu’il faudrait soustraire ces redoublements dans l’information globale et ne retenir que l’information propre contenue dans cet ensemble d’indicateurs.
Troisième conclusion : L ’information globale (sans redoublements) d’un ensemble d’indicateurs est, en géné- ral, inférieure à la somme des quantités d’information contenues individuellement dans chaque indicateur de cet ensemble.
Comme exemple, prenons le cas de deux indicateurs dont la dépendance mutuelle est totale. Si nous rangeons les pays observés par rapport aux valeurs correspondantes de l’un ou de l’autre indicateur, nous obtiendrons deux classements identiques. Cela signifie que les deux indica- teurs contiennent la même information sur le niveau de développement des pays observés et que, par conséquent, il suffit d’en prendre un seul, l’autre étant superflu.
Quatrième conclusion : E n dépit du fait que deux indi- cateurs observés peuvent être très importants du point de vue de l’information qui’ls donnent, séparément, sur le niveau de développement d’un pays, la contribution de 1 ’un d jeux est insignifiante s’il existe une forte corrélation entre les deux.
dont la qualité d’information est entièrement contenue dans 1 iizformtion globale des indicateurs déjà pris en con- sidération.
Il s’ensuit qu’un petit nombre relatif d’indicateurs, judi- cieusement choisis, pourrait contenir une plus grande infor- mation globale qu’un grand nombre d’indicateurs mal choisis. Par conséquent, pour avoir une idée aussi complète que
possible du niveau du développement des pays observés, il ne suffit pas d’augmenter le nombre des indicateurs. Pour augmenter l’information globale, il faut tenir compte de l’ÿnportance de chaque indicateur, exprimée sous la forme d’une quantité d’information, ainsi que des redoublements dans l’information, exprimés sous la forme des dépendances mutuelles entre les indicateurs.
Pour faire un choix optimal d’un nombre limité d’indi- cateurs de développement, la quantité d’information globale (sans redoublements) devrait être maximum tandis que la somme des redoublements devrait être minimum. La contribution d’un indicateur dans l’évaluation du
niveau de développement d’un pays est d’autant plus élevée
Cinquième conclusion : Il faut supprimer les indicateurs

que la quantité d’information non contenue dans l’informa- tion globale des indicateurs plus importants que lui est grande. Cependant, même s’il s’agit d’un indicateur dont la contribution propre est non négligeable, il ne nous sera guère utile si sa valeur ne varie presque pas dans l’ensemble des pays observés. Ainsi, par exemple, l’indicateur “Pour- centage d’analphabètes dans la population âgée de 10 ans ou plus” n’a aucune signification dans l’ensemble des pays riches où sa valeur est stabilisée entre 1% et 3%. Par contre, dans l’ensemble des pays pauvres, cette valeur varie entre 5% et 99%, de sorte que ce même indicateur est très discri- minatif lorsqu’il s’agit d’évaluer le niveau de développement des pays en voie de développement. La situation serait in- verse si nous prenions la “Part de la production industrielle dans le PIB” comme indicateur de développement. Sixième conclusion : Un bon indicateur de dévebppe-
ment devrait être discriminatif dans l’ensemble des pays observés.
indicateur de développement pour un ensemble de pays observés, de la façon suivante :
La contribution d’un indicateur dans l’évaluation du niveau de développement d’un pays est d’autant plus élevée que sa puissance de discrimination est forte dans l’ensemble des pays observés et que sa quantité d’information non contenue dans I ’information globale des indicateurs plus importants que celui déjà pris en considération est grande.
Ainsi, nous pouvons compléter le critère de choix d’un
3. EVALUATION OBJECTIVE DU DEGRE D’ IMPORTANCE D’UN INDICATEUR DE DEVELOPPEMENT
Le degré d’importance ou de signification d’un indicateur de développement pourrait être conçu comme la quantité d’information sur le niveau de développement d’un pays contenue dans cet indicateur. Il va sans dire qu’il n’est pas question d’exprimer d’une manière absolue cette quantité d’information. Ce que nous pouvons déterminer, c’est plutôt une quantité relative qui dépendrait de l’ensemble de tous les pays observés et de l’ensemble des autres indi- cateurs choisis.
S’il existe une dépendance totale entre l’indicateur observé et le niveau de développement d’un pays, nous aurons le même classement de pays en les rangeant soit par rapport à leur valeur de cet indicateur, soit par rapport à leur niveau de développement. Nous pouvons dire, dans ce cas, que toute l’information sur le niveau de développe- ment des pays est contenue dans ce seul indicateur, car il suffit d’établir une liste de classification des pays observés par rapport aux valeurs correspondantes de cet indicateur pour obtenir, en même temps, la liste de classification de ces pays par rapport à leur niveau de développement.
Si la dépendance est partielle, l’information contenue dans l’indicateur observé n’est qu’une partie de l’informa- tion totale sur le niveau de développement des pays.
JI s’ensuit que nous pouvons admettre que le degré dlmportance d’un indicateur de développement corres-
pond au degré de dépendance entre cet indicateur et le niveau de développement.
En prenant la 1-distance D’ comme mesure relative du niveau de développement d’un pays et en exprimant le degré de dépendance entre l’indicateur 5 et le niveau de développement par le coefficient de corrélation simple ri, cette valeur ri sera considérée comme degré de l’importance de Xi.
En rangeant les indicateurs observés d’après l’ordre de grandeur de leurs coefficients de corrélation simple avec la 1-distance, nous obtiendrons le classement des indicateurs de développement d’après leur importance. On pourrait ainsi classer objectivement les indicateurs
de développement, d’après la corrélation entre les diffé- rents indicateurs effectivement utilisés et l’indice global contenant le maximum d’information. Cependant, le calcul des coefficients de corrélation ne peut pas être effectué directement puisqu’au moment où nous devrions calculer la valeur de ces coefficients, nous ne disposons pas encore de la série des 1-distances dont le calcul néces- site la connaissance du classement des indicateurs que nous ne sommes qu’en train de rechercher.
En se trouvant ainsi dans un cercle fermé, nous nous demanderons s’il est au moins possible de résoudre le pro- blème du classement des indicateurs de développement en appliquant la méthode d’itération approximative.
Remarquons, tout d’abord, que dans notre problème peuvent apparaître deux cas extrêmes. Dans le premier cas, tous les indicateurs sont indépendants et le problème de la multiplication des mêmes quantités d’information ne se pose plus. Dans l’autre, la dépendance de tous les indicateurs choisis par rapport à l’un d’eux est totale. Les quantités d’information de tous les indicateurs sont alors contenues dans celui de l’indicateur dominant. Dans les deux cas, on peut sans aucune difficulté établir la série des 1-distances et déterminer ensuite l’ordre des indicateurs par rapport à leur degré d’importance.
Cependant, dans la pratique, on se trouve générale- ment entre ces deux extrémités. Mais on peut dire qu’on se trouve toujours, soit dans la situation où un indi- cateur contient la plus grande partie de l’information globale sur le niveau de développement des pays, soit dans la situation où l’on ne peut pas affirmer qu’un indi- cateur est, d’une façon évidente, dominant par rapport aux autres. Le premier cas est plus proche du cas extrême de la
dépendance totale de tous les indicateurs par rapport à l’indicateur dominant que du cas extrême de l’indépen- dance totale de tous les indicateurs. C’est pourquoi, en première approximation, nous supposerons que I’indica- teur dominant contient la totalité de l’information globale existant dans l’ensemble de tous les indicateurs observés. En d’autres termes, nous supposerons provisoirement que le niveau de développement d’un pays correspond à la valeur de l’indicateur dominant pour ce pays.
1. Voir Research Memorandum 11’41 du 5 novembre 1970 (CNUCED) .
25

En calculant la matrice de corrélation et en rangeant les indicateurs observés d’après l’ordre de grandeur de leurs coefficients de corrélation avec l’indicateur dominant, nous obtiendrons un classement provisoire des indicateurs de développement d’après leur degré d’importance. On dira qu’il s’agit du classement de la première étape. En utilisant donc, provisoirement, cet ordre d’indica-
teurs, nous pouvons calculer les valeurs de la 1-distance pour tous les pays considérés. Etant donné que cette 1-distance, basée sur tous les indicateurs observés, contient plus d’information sur le niveau de développement des pays que l’indicateur dominant, nous déterminerons, dans la deuxième étape, l’ordre des indicateurs d’après la gran- deur de leurs coefficients de corrélation avec la 1-distance de la première étape. Ce serait le classement de la deuxième étape. En calculant la série des 1-distances d’après le classement
de la deuxième étape et en calculant les coefficients de corrélation entre les indicateurs observés et la 1-distance ainsi obtenue, nous obtiendrons le classement des indica- teurs de la troisième étape. On continue ce procédé itératif jusqu’au moment où le
classement des indicateurs est identique avec celui de l’étape précédente. Ce classement d’indicateurs est définitif, car il reste invariable dans toutes les étapes postérieures.
Dans le deuxième cas (sans indicateur dominant), on est plus proche du cas extrême de l’indépendance totale de tous les indicateurs que du cas extrême de la dépendance totale de tous les indicateurs par rapport à l’indicateur dominant. Alors, nous supposerons, dans la première ap- proximation, que tous les indicateurs sont indépendants et que, par conséquent, il n’y a pas de redoublements dans l’information. La 1-distance se réduit dans ce cas à la distance F de
Fréchet dont le calcul n’exige aucun ordre des indicateurs puisqu’ils entrent avec le même droit dans la formule de F. En calculant les valeurs de la distance F pour tous les
pays considérés et en déterminant ensuite les coefficients de corrélation entre les indicateurs observés et la distance F, nous obtiendrons le classement de la première étape des indicateurs de développement d’après leur degré d’impor- tance.
dans le premier cas, pour arriver au classement définitif des indicateurs.
Remarquons que, dans le problème du choix des indica- teurs du développement socio-économique, on se trouve dans le premier cas, l’indicateur “PIB par habitant” étant, sans aucun doute, dominant.
Par la suite, on utilise la même méthode itérative, comme
Si les indicateurs de développement observés {xi,X2, ..., %) sont rangés d’après le classement
définitif et si la 1-distance D pour chaque pays est calculée d’après ce classement, la mesure quantitative de l’impor- tance de l’indicateur Xi sera donnée par la formule
Ii = r (X, ; D) Leur ordre de grandeur correspond au classement
définitif, c’est-à-dire :
r (Xi ; D) >, r (X2 ; D) >... >, r (Xn ; DI. En prenant le groupe des pays en voie de développe-
ment et en se limitant à 12 indicateurs de développement, l’ordre d’importance de ces indicateurs était le suivant en 1968 : Ordre
1 2
3
4
5
6
7
8
9 10 11
12
4.
Indicateur Degré d’importance
Le PIB par habitant 0,97 La consommation d’énergie par 0,95
0,81
0,81
habitant
dans l’agriculture
100.000 habitants
1 .O00 habitants
non agricole
d’après l’âge de la mère
manufacturés par habitant
Le PIB de la population active
Le nombre de médecins par
Le tirage des journaux par O ,80
Le pourcentage de la population 0,79
La concentration des naissances 0,77
Les exportations d’articles 0,76
La durée de vie moyenne 0,71 La proportion d’alphabètes 0,69 La part des industries manufacturières 0,66
Le taux d’inscriptions scolaires 0,64 dans le PIB
DETERMINATION QUANTITATIVE DE LA CONTRIBUTION D’UN INDICATEUR A
PEMENT D’UN PAYS L’EVALUATION DU NIVEAU DE DEVELOP-
4.1 Paramètres statistiques
Soit X = { XI, ..., X, 1 un ensemble de n indicateurs dont l’utilisation est envisageable pour l’évaluation du niveau de développement de tous les pays observés, repré- senté par P = En supposant qu’il existe des statistiques pour chaque
indicateur de X et pour chaque pays de P, si la valeur de l’indicateur 5 pour le pays P. est exprimée par la formule 3 x.., ces statistiques peuvent être présentées sous la forme d’une matrice M = [ xij/ ,i = 1, ..., n, j = 1, ..., m.
Il est nécessaire de pondérer les valeurs x.. pour calculer les paramètres statistiques des indicateurs X,. En représen- tant la matrice des coefficients de pondération par la for- mule N = [ n.. ] par la formule
p1, ..., Pml
4
11
, la moyenne arithmétique sera définie 13
1 m xi = - 1 nij xij -
, i = 1 , ...., n C nij j=1 J
26

et les écarts-types par
En utilisant lh covariance wic des indicateurs x, et xc, il est possible de calculer des coefficients de corrélation
Wic . normaux : , i,c=l, ..., n, ric = -
ai OC des coefficients de corrélation partielle:
ric - ris rcs rit' = 1-
pour i<c, i, c=l, ..., nandsfi,~, et des coefficients de corrélation multiple :
où R représente le déterminant de la matrice de corrélation et R1 la mineure de R correspondant à l’élément R11.
4.2 Puissance discriminative d’un indicateur
Comme mesure de la puissance discriminative de l’indica- teur 5 dans l’ensemble des pays P, nous proposons le coefficient de discrimination dont l’expression algébrique aurait la forme suivante :
ou
Remarquons que ce coefficient n’a pas la même signifi- cation que le coefficient de variation, qui mesure la disper- sion moyenne relative de Xi dans P.
Ainsi, dans notre exemple illustratif de trois répartitions où la diversité de la puissance de discrimination est évidente (avec les coefficients de discrimination respectifs 3.22, 3.00 et 2.67), la dispersion est presque constante (2.88,2.86 et 2.83).
f i o f i XI WWW
L 1 I I I I I I I I I 1 1 I I I X C 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
4.3 Information globale d’un groupe d’indicateurs de développement
Pour déterminer la quantité de l’information globale, con- tenue dans l’ensemble de k indicateurs choisis XI, X2, ..., xk, il faut s’en tenir au critère relatif au choix des indicateurs de développement qui a été formulé au para- graphe 2 et qui nous impose de tenir compte du degré d’importance de chaque indicateur, des redoublements dans l’information contenus dans les différents indicateurs et de la puissance discriminative de chaque indicateur.
soient déjà ordonnés d’après leur degré d’importance, la contribution globale de cet ensemble d’indicateurs dans l’évaluation du niveau de développement des pays observés est donnée par l’expression
Supposons que les indicateurs X1, X2, ..., Xk
k i- 1
i =1 j =1 (4.3.1) C(i,2 ,... ,k)= C CDi(P) n (l-rji.12 ... j-1) où CDi (P) représente le coefficient de discrimination de l’indicateur Xi dans l’ensemble des pays P et rji.12 ... 1-1 le coefficient de corrélation partielle entre les indicateurs
et Xj. Cette expression est croissante et homogène par rapport
aux puissances discriminatives des indicateurs choisis. Chaque puissance est pondérée de telle façon que la contri- bution de l’indicateur correspondant dans l’information globale est d’autant plus importante que le rang de l’indi- cateur est plus élevé et les corrélations partielles, entre cet indicateur et ceux qui le précèdent, plus faibles.
Si tous les indicateurs sont mutuellement indépendants, l’information globale devient la somme des puissances discriminatives de tous les indicateurs choisis, c’est-à-dire :
(4.3 .2 .) C(1,2, ..., k)= C CDi(P) , k
i=l
et s’il existe entre eux une dépendance fonctionnelle- linéaire, l’information globale se réduit à la puissance discriminative du premier indicateur, c’est-à-dire à
(4.3.3) C (1,2, ..., k) = CD1 (P). Si l’ensemble des indicateurs choisis peut être partagé
en deux groupes mutuellement indépendants, l’informa- tion globale sera la somme des informations globales correspondant à ces deux groupes d’indicateurs.
Il faut encore souligner que, d’après l’expression ana- lytique de l’information globale (S.l), les puissances dis- criminatives de tous les indicateurs représentent des quantités additives et que l’utilisation du facteur de
fait soustraire la quantité d’information de l’indicateur Xi déjà contenue dans l’information des indicateurs qui le précèdent par ordre de leur importance.
pondération (l-rli) (1-‘2i.1) (1-r3i.12) ... (1-ri-1,ia12 ...i-2)
21

4.4 Liste optimale d’un nombre réduit d’indicateurs du développement
La question fondamentale qui se pose dans le problème du choix d’une liste d’indicateurs de développement est la suivante : si nous disposons d’une liste maximale de n indicateurs, comment la réduire en une liste de k indicateurs (k < n), mais de telle façon que l’ensemble de ces k indicateurs contienne une quantité d’information globale sur le niveau de développement des pays observés plus élevée que n’importe quel autre ensemble de k indica- teurs choisis parmi les n indicateurs de la liste maximale?
soient déjà rangés d’après le classement définitif et que Supposons que les indicateurs f X1, X2, ..., Xn 1
soit un sous-ensemble ordonné de k indicateurs, où
La contribution globale de cet ensemble d‘indicateurs à l’évaluation du niveau de développement des pays est, d’après (4.3.1.),
La liste optimale de k indicateurs sera constituée alors
1 xa, xfi y ... xk 1 qui maximise l’expres- par le groupe
sion (4.4.1). En d’autres termes, la liste optimale sera formée par les indicateurs x,, xh, ... xk , si
Même en utilisant un ordinateur, la détermination de cette liste optimale ne sera pas facile si la liste maximale contient un grand nombre d’indicateurs.
Cependant, dans la pratique, de hautes instances - telles que, par exemple, l’Assemblée générale des Nations Unies, le Conseil pour le commerce et le développement de la CNUCED ou I’ECOSOC, etc. - qui, en définitive, décident et adoptent une liste d’indicateurs de développement, pour- raient imposer d’avance un certain nombre d’indicateurs et laisser aux expertsle soin de compléter cette liste afin de la rendre optimale. Cette liste ne serait peut-être plus la meilleure possible, mais, sur le plan technique, il serait bien plus facile d’exécuter des calculs.
Soit X1, X2, ..., X les p indicateurs fixés d’avance et P
les (k-p) indicateurs qu’il faut choisir parmi les (n-p) indi- cateurs de la liste maximale. Pour une combinaison de
(k-p) indicateurs, nous pouvons ordonner l’ensemble formé par l’union de cette combinaison et les p indicateurs fixés d’avance, c’est-à-dire
L’ordre de ces indices sera établi d’après le degré d’im-
La liste optimale sera maintenant constituée par les p portance des indicateurs correspondants.
indicateurs fixés d’avance et les (k-p) indicateurs
(4.4.3)
c [ < 1 1, 2, ...> p/UI~.p,...,k
Enfin, si les k indicateurs sont déjà choisis, soit en les fmant d’avance soit en les identifiant par le procédé (6.2) ou par le procédé (6.3), on pourrait se poser la question de savoir comment identifier l’indicateur xk+l, qui apporterait l’accroissement maximum à l’information globale C (1,2, ..., k). Ce sera l’indicateur X O si
Macc ik+l [< 11.2 ,...A/ U Iik+l/>]
1 pour ik+l E k+l, k+2, ..., n 1 5. CONCLUSION
Dans cette étude, nous avons essayé de présenter un pro- cédé permettant d’établir une liste optimale d’indicateurs du développement dont les statistiques serviraient.pour l’évaluation et les prévisions du développement dans la Deuxième décennie.
On commence par l’établissement de la liste maximale des indicateurs de développement en réunissant les diffé- rentes listes utilisées jusqu’à présent ainsi que d’autres indi- cateurs qui ont été négligés ou ignorés dans le passé. Le procédé consiste, ensuite, à évaluer quantitativement
la puissance discriminative ainsi que l’importance de chaque indicateur de cette liste maximale.
On définit l’information globale d’un groupe d’indica- teurs comme une somme de coefficients de la puissance discriminative de tous les indicateurs de ce groupe dont les cœfficients de pondération correspondent à l’impor- tance des indicateurs et éliminent les redoublements des
28

mêmes quantités d’information. La liste optimale d’un nombre réduit d’indicateurs de développement sera alors formée par les indicateurs qui maximisent la quantité de l’information globale.
statistiques d’un grand nombre d’indicateurs de la liste
maximale, et le coût et le temps nécessaires pour introduire de nouveaux indicateurs dans le système statistique des pays en voie de développement, ce procédé permet d’adopter un plan rationnel dans la détermination de la liste d’un nombre limité d’indicateurs dont l’infor- mation globale est optimale.
Etant donné l’absence ou la mauvaise qualité des données
29

Annexe
Progress Report 1 on the Methodology of Human Re- sources Indicators. (Unesco/COM/(SHC)CS/194/5).
Study II. An Analytical Approach to Educational Attain- ment Indicators Based on the Analysis of School En- rolment by Grade.
Study III. Procedure of Evaluating High-Level Manpower Data and Typology of Countries by means of the Taxonomic Method, by Zdzislaw Hellwig.
Study IV. On the Definition and Theory of Development with a View to the Application of Rank Order Indi- cators in the Elaboration of a Composite Index of Human Resources (Paper prepared for the Unesco Expert Meeting on the Methodology of Human Re- sources Indicators, held in Warsaw 11-16 December 1967. The paper can also be identified as PRIO- publication Nb. 6-4 from the International Peace Research Institute, Oslo), by Johan Galtung & Tord Hoivik.
problem areas and difficulties connected with the elaboration of coherent systems of indices of human resources, by Zygmunt Gostkowski.
Study VI. On the Optimal Choice of Predictors, by Zdzislaw Hellwig.
Study VII. On the Problem of Weighting in Internation- al Comparisons, by Zdzislaw Hellwig.
Study VIII. Indices of Development for Selected Latin American and Middle African Countries. An Experi- mental Exercise using the Hellwig Taxonomic Method, by Frederick H. Harbison, Joan Maruhnic, Jane R. Resnick.
sources Components as Predictors of Economic Growth in Latin America, by The Higher School of Economics, Wroclaw, Poland.
Study X. Concerning Data Availability and Conceptual Validity , Selected Latin American and African Coun- tries, by Frederick H. Harbison, Joan Maruhnic and Jane R. Resnick.
Resources Indicators by means of a Cobb-Douglas
Study V. Discussion of methodological guidelines,
Study IX. Alternative Combinations of Human Re-
Study XI. The Assessment of the Validity of Human
Type Production Function, by H.V. Mulisam, Hebrew University, Jerusalem, Israel.
Setting Based on International Comparisons, by Zygmunt Gostkowski.
The Case of Mexico, by Tord Hoivik, International Peace Research Institute, Oslo.
Development: 1. Theory, Methods and Data; II. The Case of Japan, by Johan Galtung.
Development: The Case of Venezuela, by Kristin Tornes, Internaitonal Peace Research Institute, Oslo.
Study XVI. Approximative Methods of Selection of an Optimal Set of Predictors, by Zdzislaw Hellwig.
Study XVII. Mathematical Methods in the Unesco Project on Human Resources Indicators: (i) An evaluation (ii) Alternative Analytical Methods. by Ludovic Lebart (SHC/WS/219).
ment. Some Problems of Measurement by Prof. Wilfred Beckerman (University College, London).
Study XIX. Distance-based analysis, numerical taxonomy and classification of countries according to selected areas of socio-economic development, by Serge Fanchette, Methods and Analysis Division, Unesco.
Study XX. Diachronic Analysis of Relationships between Human Resources Components and the Rate of Economic Growth in Selected Countries (COM/WS/l3 1) by Johan Galtung.
of Socio-Economic Development, by Zdzislaw Hellwig and Serge Fanchette.
Developing Countries and its Relationship to the Work on Human Resources Indicators, by H.W. Singer (Institute of Development Studies, The University of Sussex, UK).
Study XII. The Use of Taxonomic Measures in Target
Study XIII. Human Resources and Economic Growth:
Study >(IV. Human Resources and Socio-Economic
Study XV. Human Resources and Socio-Economic
Study XVIII. Human Resources and Economic Develop-
Study XXI. The Selection of a Set of “Core” Indicators
Study XXII. The Quest for an Employment Strategy in
31

Study XXIII. “Synchronic and Diachronic Approaches in the Unesco Project on Hurnan Resources Indicators. Wroclaw Taxonomy and Bivariate Diachronic Analysis” (SHC/WS/209), by Serge Fanchette - Methods and Analysis Division, Unesco.
Study XXIV. A method of establishing a list of develop- ment indicators, by B. Ivanovic (Director of the Office of Statistics of UNCTAD).
Study XXV. Grouping and ranking of 30 countries of Sub-Saharan Africa. Two distance-based methods compared, by B. Ivanovic and Serge Fanchette.
Study XXVI. Aspects of the distribution of incorne and
wealth in Kenya, by H.W. Singer and Stuart D. Reynolds (The Institute of Development Studies, University of Sussex, UK).
Study XXVII. Distributional patterns of development and welfare: A case study of Zambia, by Charles Elliott (Overseas Development Group, School of Development Studies, University of East Anglia).
Study XXVIII. Typological study using the Wroclaw Taxonornic Method (A study of regional disparities in Venezuela), by José F. Silvio-Pomenta (Centro de Eçtudios del Desarrollo (CENDES), Universidad Central de Venezuela.
32

PUBLICATIONS DE L’UNESCO : AGENTS GENÉRAUX
Albanie Aigérie
Alluname (Rép. féd.1
Rbp. dém. allemande Antilles françaises
Argentine Autriche Belgique Brbil
Bulgarie Cameroun
Canada
Chypre Congo
are-d’Ivoire Dahomey Danemark
Égypte
Espagne
rats-Unis d’Amérique Finlande France Grke Haïti
Haute-Volta Hongrie
Inde
Indonhie Irak
Iran
Irlande Israel
Italie Japon
Rbpublique khmère Liban
Luxembourg MadagascPr
Mali Maroc
RCp. arabe libyenn
Maurice Monaco
Mozambique Niger
Norvège
Nouvelle-Calédonie Payn-Ban
Pologne Portugal
Roumanie
Royaume-Uni
Sbnégal
Suède
N. Sh. Botimeve Naim Franheri. TIFIANA. Institut pédagogique national. II, rue Ali-Haddad (=-rue Zaétcha). ALGER. Société nationale d’éditioo et de diffusion (SNED). 3, boulevard Zirout Youcef. ALGER. Verlag Dokumentation, Poatfacb 1.48. Jaiserntranne. 13. 8023 MONCHEN-PLILLACH. N Le Courrier B, &‘rion ailemande seulmnf : Bahrenfelder Chaussee 160. HAMBURG-BMFSIWLD. CCP : 27-66-50. Par les cmtes scienfifques seuleauni: GE0 CENTER D1 STVITCART 80, Postfach 800 830. Deutscher Buch-Export und Imporr G m b H . Leninstrnsse 16. 701 LEIPZIG. Librairie 1 A u Boul’Mich -.. 1, rue Perrhon et 66, avenue du Parquet, wa FORT-DE-FRANCE (Martinique). Editorial Losada. S.A., Abina 1131, Brno8 Atm. Verlag Georg Fromme & Co.. Arbeitergaise 1-7, 1051 Wrm. Jean D e Lannoy, 1x2. rue du Trône, BRUSELLB~ 5, CCP 708 23. Fundach Genilio Varm. Service de Publicaç&. cairn postalsrxzo.Praia de Botafogo 188. Rio DB JANBIRO. GB. Hemun. Kaniora Literarura. bd. Rousky 6, SOFIJA. Le secrétaire général de In Commission nationale de la République fédérale du Cpmemun pour l’Unesco, B. P. 1061. YAOlND$. Information Conada. OITAWA (Ont.). Librairies: 640 Ouest. rue Sainte-Catherine, MO- III (Qué.); 1683 Barrington St., HALIPAX (N.S.); 393 Portage Ave., WlNNlPEct (Manitoba); 171, rue Slater. OITAWA (Ont.); ZZI Yonge Si.. TOUONTO (Ont.); 800 Granville St., VANCOUVER (B.C.). a MAM * Archbiihop Makarim. 3rd Avenue, P. O. Bor 1722. NICOSIA. Librairie populaire, B. P. 577# B r U W V i U Centre d‘édition et de ditfusion africuinea, B. P. 4541. ABIDJAN P u m u . Librairie nationale, B. P. 294. PORTO Novo. Ejnar MunLsgaard Ltd.. 6 Nnrregade. 1165 K e n m m K. Librairie Knsr El Nil. 38, rue Kasr El Nil. LB CUM. National Centre for Unesco Publicatioos. I Talaai Harb Street. Tohrir Square. CAIRO. Tartes les @&licolions : Ediciones Iberoameriunas. S. A., caiie de Ohte 15. MADRID 20. Distribucion de Publicaciones del Consejo Superior de Investigaciones Cientificas. Vitrubio 16. MADRID 6. Libreria del Consejo Superior de Inveutigaciones Cientiiïcas, Egipciacas 15, BARCELONA. s Lc Carnier seulorBent : Ediciones Liber, apartado 17, ONDARROA (Viscpya). Unesco Publications Center. P. O. Bor 433, NEW YORK, N. Y. 10016. Akateemhen Kirjakauppa. z Keskrukatu. ~ I N K I . Librairie de l’Unesco. 7. place de Fontenoy, 75700 Paria; CCP 12598-&3. An&-Helienic Agency, 5 Koumpari Street, A m M 138. Librairie * A la Caravelle I, 36. rue Roux. B. P. III, PORT-AU-PRINCE. Librairie Aitie. B. P. 64, OUAGADOUGOU; Librairie catholique I Jeunesse d’Afrique ., OUAGADOU~OU. Akadémiai Konyveabolt. VIU u. 12. BUDAPDT V. A.K.V. Ktinyvtkœok Boltja. Népt&tiria& utja 16. BUDAPBT VI. Orient Longman Ltd. : Niwl Road. Baiinrd Estnte, BOMBAY I; 17 Chittaranjan Avenue, CALCUTTA 13; 36 A Anna Salai, Mount Road, M A D M 2; B 317 Aiaf Ali Road. NEW DELHI I. Sous-dcpbfs : Oxford Book and Stationery Co.. 17 Park Street. C A L c m A 16. ef Scindia House. NEW DELHI; Publications Section. Minintrv of Educntion and Social Welfare. 7 2 Theatre Communication Buildinn. _. . .
Connaught Place, N k v DELHÏ 1. Indira P.T., JI. Dr. Sam Ratuiangie, JAKARTA. McKenzie’i BooL~~oD. Al-Rsshid Street. BAGHDAD. University Bookstore. University of Banhdad. P. O. - . ~~
BOX~75. BAG~AD. Commission nationale iranienne pour l’Unesco, avenue Iranchaht Chomali no 300, B.P. 1533. TÉH~RAN. Kharazmie Publishing and Distribution Co.. zz9 Daneshgahe Street, Shah Avenue, P. O. Bor 1411486 T6HÉRAN. The Educational Company of Ireland Ltd., Ballymount Road. Walkinstown, DUBLIN 12. Emanuel Brown, formerly Blumstein’s Booksiores: 35 Allenby Road ef 48 Nacbiat Benjamin Street, TEL Aviv: 9 Shlomzion Hnmaka Street, JERUSALEM. LICOSA (Libreria Commissionaria Sansoni S.p.A.), via Lamannora 45, cndh postale 55s. 5 0 1 ~ 1 FIRENZE Maruzen Co. Ltd.. P. O. Box 5050, TOKYO iNTWNAnONAL. 100-31. Librairie Albert Portail, 14, avenue Bodochc. PHNOM-PENH. Librairiea Antoine A. Naufal et Frèru. B. P. 656. Bmoviw. Agency for Development of Publication and Diitribution. P. O. Bor 34-35. TRxWU. Librairie Paul Bru&. zz. Grand-Rue. LUXEMBOURG., Cornmiasion nationale de la République malp.Che. Miniitère de I’éducntion nationale. TANANARIVE. Librairie populaire du Mali, B. P. zE, B-O. Tarfer les @&lÙutionr: Librairie n Aux W e s Images D. 181, avenueMohimmed-V, RABAT (CCP 68-74). Le COU& I J C U h t C n l (POU? kJ +?fU&lUtItS) : COmlIUN ’ ion n a t i d e muocsine pour I’Unuco. 20. Zenkat Mourabitine. Rmm (CCP 324-45). Nilanda Co. Ltd.. 30 Bourbon Street, PORT-Louis. Britiah Library. 30, boulevard d u Moulinm. M o m C W . Salema & Carmiho Ltda., airs pcatnl 192. BPIM. Librairie Mauclert. B. P. 868, N-. s Lc Carrri.r rn sedement : AIS Narireseni Litterohinjenute. Box 6125. Oao 6. Reprer. SARL, B. P. 1~72. Nom&\. N. V. Martinui Nijhoff, Lange Voorhout 9, ’#-GRAVENHAGE. Sptcmui Kcesing, Rupdeelstrut 71-75,
Tartu kJ PublÙufionr: John Gnindt Tanum. Karl Johrni Pte 41-43, OWO 1.
.bmmDm. 06mdek Rozpowaiechniania Wydawnictw Naukowych PAN, Palac Kuinrrg i Nauki. W-WA. Dias & Andrade Ltda.. Livraria Portugal, rua do h o 70, LISBOA. I.C.E. Libri. cala Victoriei. nr. 126. P. O. B. 134-135. BücURWm. Abonnements aux pén’oàiques: Rompresfilatelia, calea Vinoriei nr. +9. BüCvRBQTI. H. M. Stntionery O5ce. P. O. Box 569, LONDON SEI 9NH. Goversment bookshow: London, Belfuit, Birmingham, Bristol. Cardin. Edinburgh. Minchenter. La Maison du livre. 13. avenue Roume, B.P. 20-60. DAKAR. Librairie Clairafnque. B. P. -5. Librairie * Le Sénégal I B. P. 15% D-. TouteJ les @ublicafionr : ‘AIBC. E. Friaea Kungl. Hovbokhandel. Frcdsgatrn 2. Box 16356, STOCKHOLM 16. Le Caarin m seulement: SvcnoLn FN-Forbmdet. Skolgrbd 2. Box 150 50, S STOCXHOLM.
DAM
103 -104

SuiMie R~P. arabe syrienne
Tchécoslovaquie
Europa Verlag. Rbnistrasae 5. ZURICH. LibrairiePayot, 6. rue Grenus. IZII G ~ m h II. Librairie Sayegh Immeuble Diab rue du Parlement, B. P. 704, D W . SNTL. Spdena ;I, PRAHA I (Exj>miiion p m n a f e ) . Zahranicni literatura. II Scukenickn. PRAHA 1. Pav la Slowpuic seulement: Alfa Verlag. Publinbers, Hurbmovo nam. 6, 893 31, BRATISLAVA.
Togo Librairie évangélique, B. P. 378. Lod; Librairie du Bon Paiteur. B P. 1164. LosaB; Librairie moderne, B. P. 777, Lod. Société hiniaienne de diffusion, 5. avenue de CPrthage, Tmiâ. Librairie Hachette, 469 Istikld Cnddesi, Beyoglu. IWANBUL.
Librairicpspeterie Xdn-Thu, 185-193. NC Tu-Do, B. P. 283. SAIGON. Jugoelovuiska Knjiga, Terazije 27, BBOGIUD. Dns~nn Zdozba Siovenije. Mentni Trg. 26. LJUBLJANA. La fibrairie. Inatitut narioail d‘étuda, politiqua. B. P. 2307,, KPIBHMIA. Commission nationale de In RCoubliaue du Znln pour I‘Uncrco. mi nu th^ de i’6ducahm ninonaie. KINnHARA.
Tunisie Turquie
Rhublique du Viêt-nam Yougoslavie
ZnIre
URÇS Mdhdunarodnaja Knip, MOSEVA G-zoo.
ISBN 92-3-201161-1














![Rapport de gestion 2018 - Spitalzentrum Biel [Home]...guin dans le cerveau, de détecter des micro déchirures du ménisque, de suivre le déve loppement d’un fœtus, de dépister](https://static.fdocuments.net/doc/165x107/6147a35dafbe1968d37a2e0e/rapport-de-gestion-2018-spitalzentrum-biel-home-guin-dans-le-cerveau-de.jpg)



