
Lecture 8 The Principle of Maximum Likelihood. Syllabus Lecture 01Describing Inverse Problems...
55
Lecture 8 The Principle of Maximum Likelihood
-
date post
20-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of Lecture 8 The Principle of Maximum Likelihood. Syllabus Lecture 01Describing Inverse Problems...

Lecture 8
The Principle of Maximum Likelihood

SyllabusLecture 01 Describing Inverse ProblemsLecture 02 Probability and Measurement Error, Part 1Lecture 03 Probability and Measurement Error, Part 2 Lecture 04 The L2 Norm and Simple Least SquaresLecture 05 A Priori Information and Weighted Least SquaredLecture 06 Resolution and Generalized InversesLecture 07 Backus-Gilbert Inverse and the Trade Off of Resolution and VarianceLecture 08 The Principle of Maximum LikelihoodLecture 09 Inexact TheoriesLecture 10 Nonuniqueness and Localized AveragesLecture 11 Vector Spaces and Singular Value DecompositionLecture 12 Equality and Inequality ConstraintsLecture 13 L1 , L∞ Norm Problems and Linear ProgrammingLecture 14 Nonlinear Problems: Grid and Monte Carlo Searches Lecture 15 Nonlinear Problems: Newton’s Method Lecture 16 Nonlinear Problems: Simulated Annealing and Bootstrap Confidence Intervals Lecture 17 Factor AnalysisLecture 18 Varimax Factors, Empircal Orthogonal FunctionsLecture 19 Backus-Gilbert Theory for Continuous Problems; Radon’s ProblemLecture 20 Linear Operators and Their AdjointsLecture 21 Fréchet DerivativesLecture 22 Exemplary Inverse Problems, incl. Filter DesignLecture 23 Exemplary Inverse Problems, incl. Earthquake LocationLecture 24 Exemplary Inverse Problems, incl. Vibrational Problems

Purpose of the Lecture
Introduce the spaces of all possible data,all possible models and the idea of likelihood
Use maximization of likelihood as a guiding principle for solving inverse problems

Part 1
The spaces of all possible data,all possible models and the idea of
likelihood

viewpoint
the observed data is one point in the space of all possible observations
or
dobs is a point in S(d)

d2
d3
d1O
plot of dobs

d2
d3
d1O
dobs
plot of dobs

now suppose …the data are independent
each is drawn from a Gaussian distribution
with the same mean m1 and variance σ2
(but m1 and σ unknown)

d2
d3
d1O
plot of p(d)

d2
d3
d1O
plot of p(d)
cloud centered on d1=d2=d3with radius proportional to σ

now interpret …
p(dobs)as the probability that the observed data was in
fact observed
L = log p(dobs)called the likelihood

find parameters in the distribution
maximizep(dobs)with respect to m1 and σ
maximize the probability that the observed data
were in fact observed
the
Principle of Maximum Likelihood

Example

solving the two equations

solving the two equations
usual formula for the
sample mean
almost the usual formula for the sample standard
deviation

these two estimates linked to the assumption of the data being Gaussian-distributed
might get a different formula for a different p.d.f.
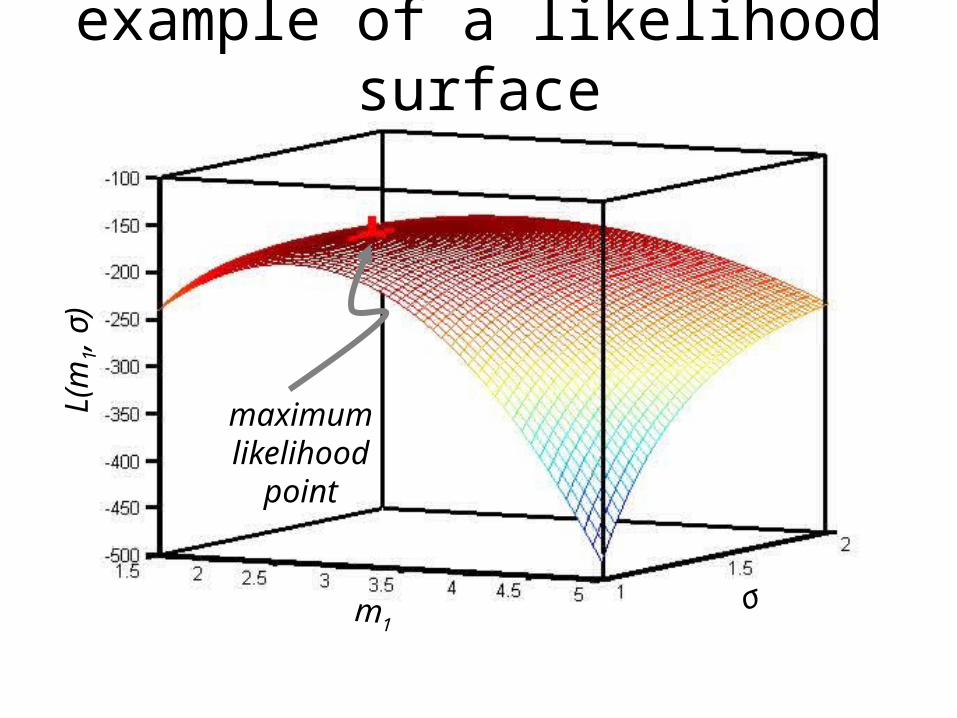
L(m 1,
σ)
σm1
maximumlikelihoodpoint
example of a likelihood surface

d1d 2 d 2d1
p(d1, ,d1 ) p(d1, ,d1 )(A) (B)
likelihood maximization process will fail if p.d.f. has no well-defined peak

Part 2
Using the maximization of likelihood as a guiding principle for
solving inverse problems

linear inverse problem for with Gaussian-distibuted data
with known covariance [cov d]assumeGm=d
gives the mean dT

principle of maximum likelihood
maximize L = log p(dobs)minimize
with respect to m
T

principle of maximum likelihood
maximize L = log p(dobs)minimize
This is just weighted least squares
E = T

principle of maximum likelihood
when data Gaussian-distributedsolve Gm=d with weighted least squares
with weighting of

special case of uncorrelated dataeach datum with a different variance[cov d]ii = σdi2
minimize

special case of uncorrelated dataeach datum with a different variance[cov d]ii = σdi2
minimize
errors weighted by their certainty

but what about a priori information?

probabilistic representation of a priori information
probability that the model parameters are
near mgiven by p.d.f.
pA(m)

probabilistic representation of a priori information
probability that the model parameters are
near mgiven by p.d.f.
pA(m)centered at a priori value
<m>

probabilistic representation of a priori information
probability that the model parameters are
near mgiven by p.d.f.
pA(m)variance reflects uncertainty in a
priori information
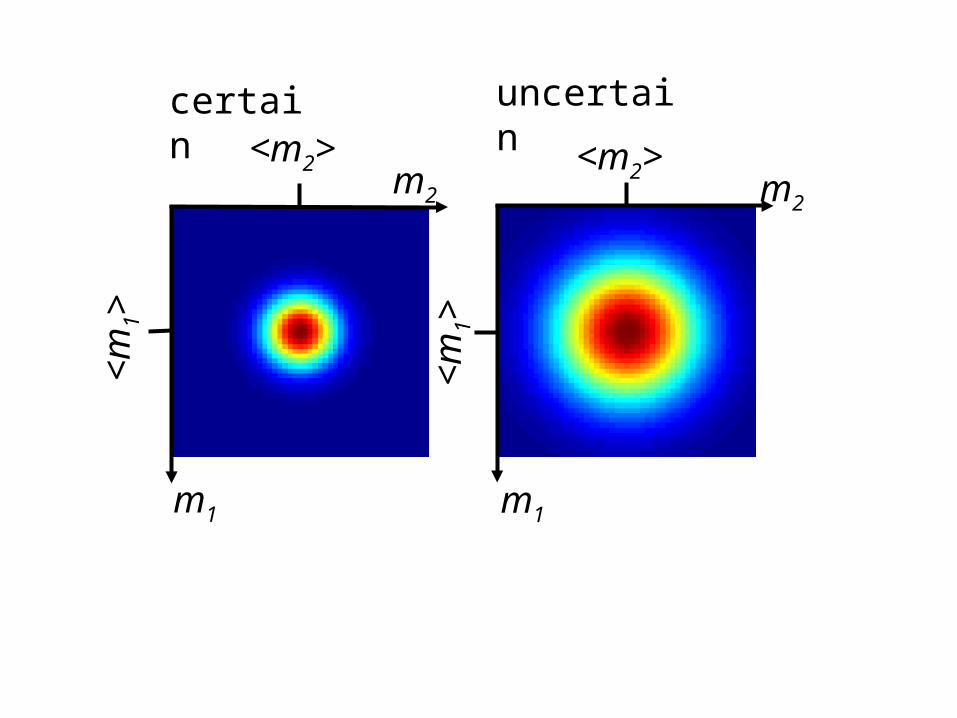
certain uncertain<m2> <m2><m 1> <m 1>
m1 m1
m2 m2

<m2><m 1>
m1
m2

linear relationship approximation with Gaussian<m2>
<m 1 >m1 m1
m2 m2

m1
m2 p=constantp=0

assessing the information contentin pA(m)
Do we know a little about mor
a lot about m ?

Information Gain, S
-S called Relative Entropy,

Relative Entropy, Salso called Information Gain
null p.d.f.state of no knowledge

Relative Entropy, Salso called Information Gain
uniform p.d.f. might work for this

probabilistic representation of data
probability that the data are
near dgiven by p.d.f.
pA(d)

probabilistic representation of data
probability that the data are
near dgiven by p.d.f.
p(d)centered at
observed data dobs

probabilistic representation of data
probability that the data are
near dgiven by p.d.f.
p(d)variance reflects
uncertainty in measurements

probabilistic representation of both prior information and observed data
assume observations and a priori information are uncorrelated
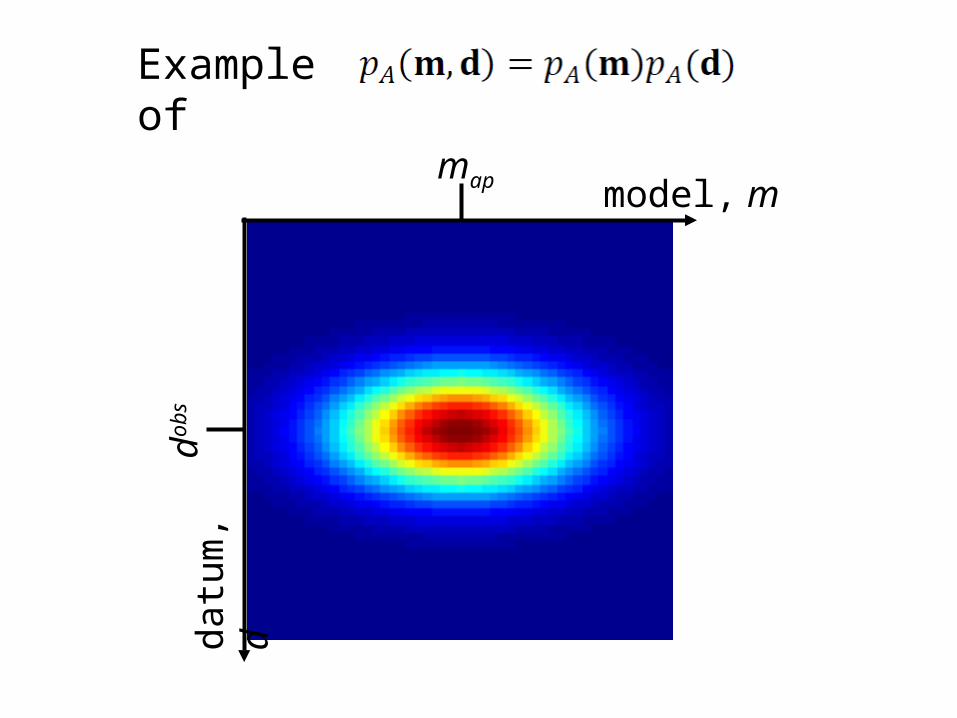
dobs model, m
datu
m,
d map
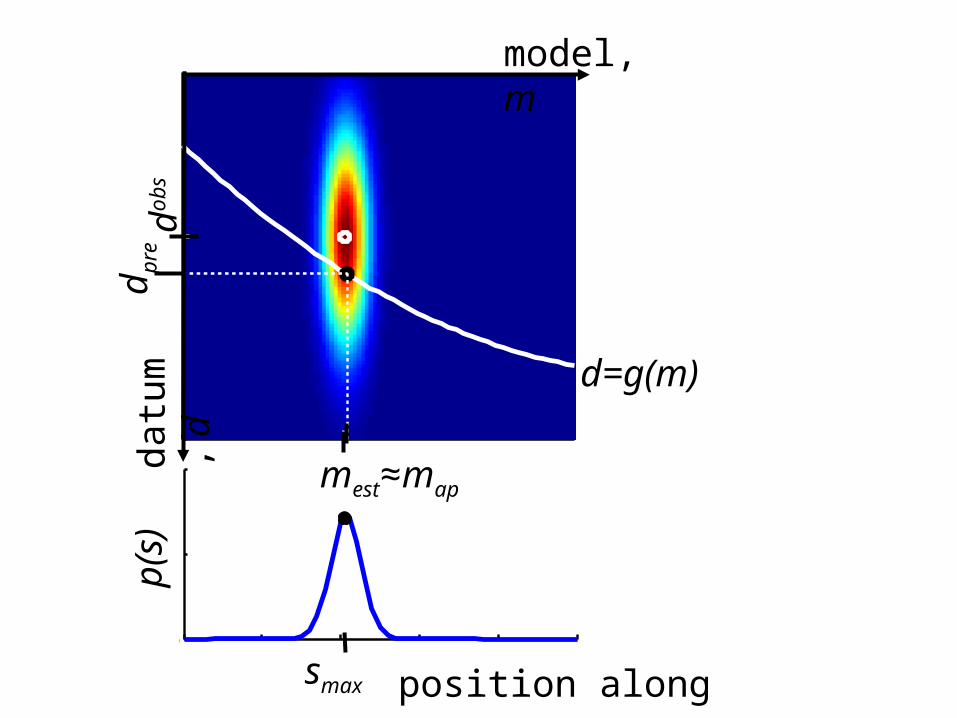
Example of

the theoryd = g(m)is a surface in the combined space of
data and model parameters
on which the estimated model parameters and predicted data must lie

the theoryd = g(m)is a surface in the combined space of
data and model parameters
on which the estimated model parameters and predicted data must lie
for a linear theorythe surface is planar

the principle of maximum likelihood says
maximize
on the surface d=g(m)

0 1 2 3 4 5
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
m
d
dobs model, m
datu
m, d
mapmest
d pred=g(m)
0 1 2 3 4 50
0.1
0.2
s
P(s
)
position along curve, sp(s)
(B)
smax
(A)
0 1 2 3 4 50
0.5
1
s
P(s
)
0 1 2 3 4 5
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
m
d
dobs model, m
datu
m,
d mest≈map
d pre
d=g(m)
position along curve, s
p(s)
smax

0 1 2 3 4 50
0.5
1
s
P(s
)
0 1 2 3 4 5
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
m
dd pre ≈dob s model, m
datu
m,
d mestd=g(m)
position along curve, s
p(s)
map
smax
(A)
(B)

principle of maximum likelihoodwith
Gaussian-distributed dataGaussian-distributed a priori information
minimize

this is just weighted least squareswith
so we already know the solution

solve Fm=f with simple least squares

when [cov d]=σd2I and [cov m]=σm2I

this provides and answer to the question
What should be the value of ε2in damped least squares?
The answer
it should be set to the ratio of variances of the data and the a priori model parameters

if the a priori information is
Hm=hwith covariance [cov h]Athen the Fm=f becomes

Gm=dobs with covariance [cov d]Hm=h with covariance [cov h]Amest = (FTF)-1FTdobs
with
the most useful formula in inverse theory


















