
Lecture 4: Learning Theory (cont.) and optimization … · Lecture 4: Learning Theory (cont.) and...
32
Lecture 4: Learning Theory (cont.) and optimization (start) Sanjeev Arora Elad Hazan COS 402 – Machine Learning and Artificial Intelligence Fall 2016
Transcript of Lecture 4: Learning Theory (cont.) and optimization … · Lecture 4: Learning Theory (cont.) and...

Lecture4:LearningTheory(cont.)andoptimization(start)
SanjeevArora EladHazan
COS402– MachineLearningand
ArtificialIntelligenceFall2016

Admin
• Exercise1– duetoday• Exercise2(implementation)nextTue,inclass• Enrolment…• Latepolicy(exercises)• Literature(free!)

Recap
Lastlecture:• ShiftfromAIbyintrospection(Naïvemethods)tostatistical/computational learningtheory
• Fundamentaltheoremofstatisticallearning• Samplecomplexity,overfitting,generalization

Agenda
• (Review)statistical&computationallearningtheoriesforlearningfromexamples
• (Review)Fundamentaltheoremofstatisticallearningforfinitehypothesisclasses
• Theroleofoptimizationinlearningfromexamples• Linearclassificationandtheperceptron• SVM andconvexrelaxations

Definition:learningfromexamplesw.r.t.hypothesisclassAlearningproblem:𝐿 = (𝑋,𝑌, 𝑐, ℓ,𝐻)• X=Domainofexamples(emails,pictures,documents,…)• Y=labelspace(forthistalk,binaryY={0,1})• D=distributionover(X,Y)(theworld)• Dataaccessmodel:learnercanobtaini.i.d samplesfromD• Concept=mapping𝑐:𝑋 ↦ 𝑌• Lossfunctionℓ: 𝑌, 𝑌 ↦ 𝑅,suchasℓ 𝑦/, 𝑦0 = 123425• H=classofhypothesis:𝐻 ⊆ {𝑋 ↦ 𝑌}• Goal:producehypothesish∈ 𝐻withlowgeneralizationerror
𝑒𝑟𝑟 ℎ = 𝐸 ?,2 ∼A[ℓ(ℎ 𝑥 , 𝑐 𝑥 )]

agnosticPAClearnability
Learningproblem𝐿 = (𝑋,𝑌,𝐻, 𝑐, ℓ)isagnosticallyPAC-learnable ifthereexistsalearningalgorithms.t.forevery𝛿, 𝜖 > 0,thereexistsm = 𝑓 𝜖, 𝛿,𝐻 < ∞,s.t. afterobservingSexamples,for 𝑆 = 𝑚,returnsahypothesisℎ ∈ 𝐻,suchthatwithprobabilityatleast
1 − 𝛿itholdsthat
𝑒𝑟𝑟 ℎ ≤ minZ∗∈\
𝑒𝑟𝑟 ℎ∗ + 𝜖
Equalszeroforrealizableconcepts

Themeaningoflearningfromexamples
Theorem:Everyrealizablelearningproblem𝐿 = (𝑋,𝑌,𝐻, 𝑐, ℓ)forfiniteH,isPAC-learnablewithsample
complexity𝑆 = 𝑂_`a\b_`a3c
d usingtheERMalgorithm.
Noamchomesky, June2011:“It'struethere'sbeenalotofworkontrying toapplystatisticalmodelstovariouslinguisticproblems.Ithinktherehavebeensomesuccesses,butalotoffailures.Thereisanotion ofsuccess...whichIthinkisnovelinthehistoryofscience.Itinterpretssuccessasapproximatingunanalyzeddata.”

Examples– statisticallearningtheorem
Theorem:Everyrealizablelearningproblem𝐿 = (𝑋,𝑌,𝐻, 𝑐, ℓ)forfiniteH,isPAC-learnablewithsample
complexity𝑆 = 𝑂_`a\b_`a3c
d usingtheERMalgorithm.
• Applefactory:Wt.ismeasuredingrams,100-400scale.Diameter:centimeters,3-20
• Spamclassificationusingdecisiontreesofsize20nodes• 200Kwords

Infinitehypothesisclasses
VC-dimension:correspondingto“effectivesize”ofhypothesisclass(infiniteorfinite)• Finiteclasses,𝑉𝐶𝑑𝑖𝑚 𝐻 = log𝐻• Axis-alignedrectanglesin𝑅j ,𝑉𝐶𝑑𝑖𝑚 𝐻 = 𝑂(𝑑)• Hyperplanesin𝑅j ,𝑉𝐶𝑑𝑖𝑚 𝐻 = 𝑑 + 1• Polygonsintheplane,𝑉𝐶𝑑𝑖𝑚 𝐻 = ∞
Fundamentaltheoremofstatisticallearning:Arealizablelearningproblem𝐿 = (𝑋, 𝑌, 𝐻, 𝑐, ℓ) isPAC-learnable ifanonlyifitsVCdimensionisfinite,
inwhichitislearnablewithsamplecomplexity𝑆 = 𝑂klmno(\)_`a3c
d usingtheERMalgorithm.

Overfitting??
samplecomplexity𝑆 = 𝑂_`a\b_`a3c
d
Itistight!

Reminder:classifyingfuelefficiency
• 40datapoints
• Goal:predictMPG
mpg cylinders displacement horsepower weight acceleration modelyear maker
good 4 low low low high 75to78 asiabad 6 medium medium medium medium 70to74 americabad 4 medium medium medium low 75to78 europebad 8 high high high low 70to74 americabad 6 medium medium medium medium 70to74 americabad 4 low medium low medium 70to74 asiabad 4 low medium low low 70to74 asiabad 8 high high high low 75to78 america: : : : : : : :: : : : : : : :: : : : : : : :bad 8 high high high low 70to74 americagood 8 high medium high high 79to83 americabad 8 high high high low 75to78 americagood 4 low low low low 79to83 americabad 6 medium medium medium high 75to78 americagood 4 medium low low low 79to83 americagood 4 low low medium high 79to83 americabad 8 high high high low 70to74 americagood 4 low medium low medium 75to78 europebad 5 medium medium medium medium 75to78 europe
X Y

The test set error is much worse than the training set error…
…why?

Figure fromMachineLearningandPatternRecognition,Bishop
𝑡 = sin 2𝜋𝑥 + 𝜖

𝑡 = sin 2𝜋𝑥 + 𝜖
Figure fromMachineLearningandPatternRecognition,Bishop

Figure fromMachineLearningandPatternRecognition,Bishop

Occam’srazor
WilliamofOccam c. 1287– 1347:controversialtheologian:“pluralityshouldnotbepositedwithoutnecessity”,i.e.“thesimplestexplanationisbest”
Theorem:Everyrealizablelearningproblem𝐿 = (𝑋,𝑌,𝐻, 𝑐, ℓ)forfiniteH,isPAC-learnablewithsample
complexity𝑆 = 𝑂_`a\b_`a3c
d usingtheERMalgorithm.

Otherhypothesisclasses?
1. Pythonprogramsof<=10000wordsH ≈ 10000/uuuu
à samplecomplexityis𝑂_`a\b_`a3c
d = 𝑂(vuwd ) - nottoobad!
2. Efficientalgorithm?3. (Haltingproblem…)
4. TheMAINissuewithPAClearningiscomputationalefficiency!5. Nexttopic:MOREHYPOTHESISCLASSESthatpermitefficientOPTIMIZATION

Booleanhypothesis
Monomialonabooleanfeaturevector:
𝑀 𝑥/, . . , 𝑥z = �̅�z ∧ 𝑥0 ∧ 𝑥/
(homeworkexercise…)
x1 x2 x3 x4 y
1 0 0 1 0
0 1 0 0 1
0 1 1 0 1
1 1 1 0 0

Linearclassifiers
Domain=vectorsoverEuclideanspaceRm
Hypothesisclass:allhyperplanesthatclassifyaccordingto:
ℎ 𝑥 = 𝑠𝑖𝑔𝑛(𝑤�𝑥 − 𝑏)
(weusuallyignoreb– thebias,itis0almostw.l.o.g.)

Empirically:theworldismanytimeslinearly-separable

Thestatisticsoflinearseparators
Hyperplanesinddimensionswithnormatmost1,andaccuracyof𝜖:
𝐻 ≈1𝜖
j
VCdimensionisd+1
è Samplecomplexity𝑂(jb_`a3c
d )

Findingthebestlinearclassifier:LinearClassification
TheERMalgorithmreducesto:
n vectorsind dimensions: x/,x0, … , x� ∈ 𝑅j
Labelsy/,𝑦0, … , 𝑦� ∈ −1,1 Findvectorwsuchthat:
∀𝑖. 𝑠𝑖𝑔𝑛 𝑤�𝑥� = 𝑦�
Assume: w ≤ 1, 𝑥� ≤ 1

𝜖= margin
The margin
Margin 𝜖 = max � �/
min�{𝑤�𝑥� ⋅ 𝑦�}

The Perceptron Algorithm[Rosenblatt 1957, Novikoff 1962, Minsky&Papert 1969]

The Perceptron Algorithm
Iteratively:1. Find vector 𝑥� for which sig𝑛 𝑤�𝑥� ≠ 𝑦�2. Add 𝑥� to w:
𝑤�b/ ← 𝑤� + 𝑦�𝑥�

The Perceptron Algorithm
Thm [Novikoff 1962]: for data with margin 𝜖, perceptron
returns separating hyperplane in /d5 iterations

Thm [Novikoff 1962]: converges in 1/ 𝜖0 iterationsProof:
Let w* be the optimal hyperplane, s.t. ∀𝑖, ynxn�w∗ ≥ 𝜖
1. Observation 1: w�b/� w∗ = w� + y�x� w∗ ≥ 𝑤��𝑤∗ + 𝜖
2. Observation 2: |w�b/
� |0 = |w��|0 + 𝑦�𝑥��𝑤� + 𝑦�𝑥� 0 ≤ |w�
�|0+1Thus:
1 ≥𝑤�|𝑤�|
⋅ w∗ ≥𝑡𝜖𝑡= 𝑡𝜖
And hence: t ≤ /d5
Perceptron:𝑤�b/ ← 𝑤� +𝑦�𝑥�

Noise?

ERMfornoisylinearseparators?
Givenasample𝑆 = 𝑥/,𝑦/ , … , 𝑥�,𝑦� ,findhyperplane(throughtheoriginw.l.o.g)suchthat:
𝑤 = arg min� �/
𝑖s. 𝑡. 𝑠𝑖𝑔𝑛(𝑤�𝑥� ≠ 𝑦� |
• NP-hard!
• à convexrelaxation+optimization!
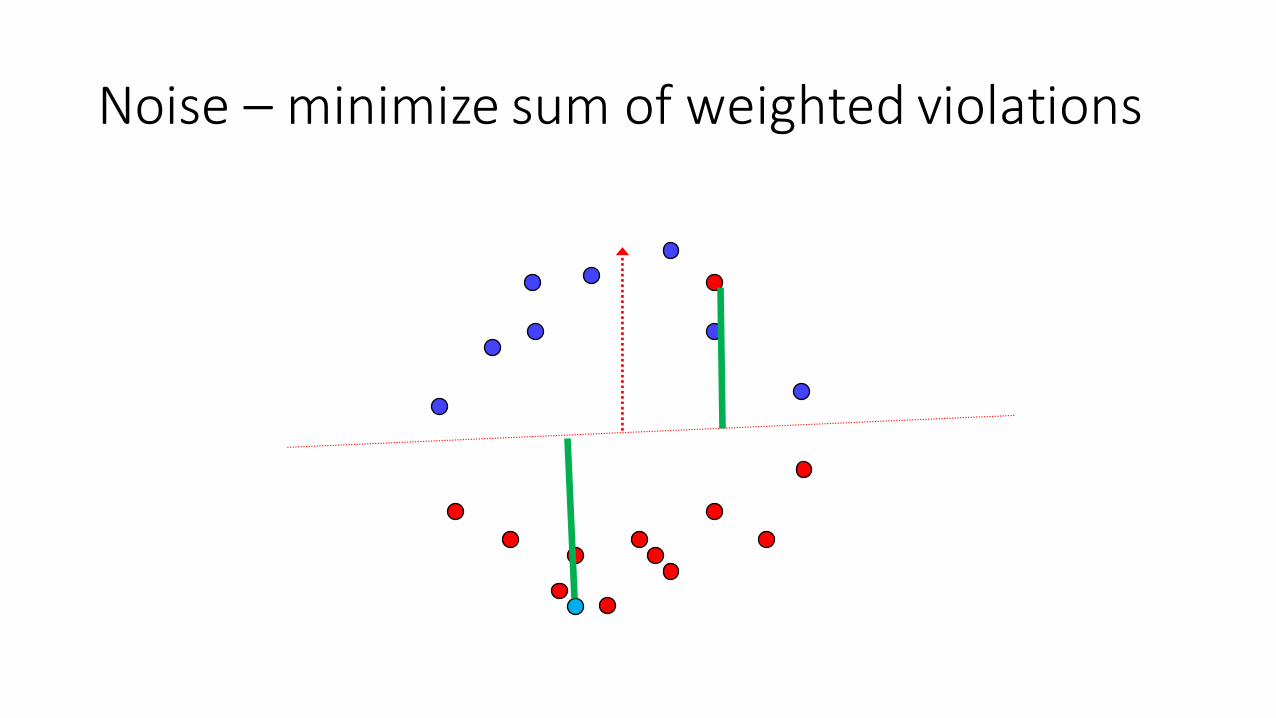
Noise– minimizesumofweightedviolations

Soft-marginSVM(supportvectormachines)
Givenasample𝑆 = 𝑥/,𝑦/ , … , 𝑥�,𝑦� ,findhyperplane(throughtheoriginw.l.o.g)suchthat:
𝑤 = arg min� �/
{1𝑚�max{0,1 −𝑦�𝑤�𝑥�}
�}
• Efficientlysolvablebygreedyalgorithm– gradientdescent• Moregeneralmethodology:convexoptimization

Summary
PAC/Statisticallearningtheory:• Precisedefinitionoflearningfromexample
• Powerful&verygeneralmodel• Exactcharacterizationof#ofexamplestolearn(samplecomplexity)• Reductionfromlearningtooptimization• Arguedfinitehypothesisclassesarewonderful(Python)• Motivatedefficientoptimization• LinearclassificationandthePerceptron+analysis• SVMà convexoptimization(nexttime!)


















