
Lecture 13: Integer Arithmetic and Floating Point cont.
43
Lecture 13: Integer Arithmetic and Floating Point cont. CS 2011 Fall 2014, Dr. Rozier
-
Upload
signe-vaughn -
Category
Documents
-
view
42 -
download
2
description
Lecture 13: Integer Arithmetic and Floating Point cont. CS 2011. Fall 2014, Dr. Rozier. BOMB LAB STATUS. MIDTERM II. Midterm II. November 13 th Plan for remaining time. FLOATING POINT. Representation Bits to right of “ binary point ” represent fractional powers of 2 - PowerPoint PPT Presentation
Transcript of Lecture 13: Integer Arithmetic and Floating Point cont.

Lecture 13: Integer Arithmetic and Floating Point cont.
CS 2011
Fall 2014, Dr. Rozier

BOMB LAB STATUS

MIDTERM II

Midterm II
November 13th
Plan for remaining time

FLOATING POINT

2i
2i-1
421
1/21/41/8
2-j
bibi-
1
•••
b2 b1 b0 b-1 b-2 b-3•••
b-j
Carnegie Mellon
• • •
Fractional Binary Numbers
• Representation– Bits to right of “binary point” represent fractional powers of
2– Represents rational number:
• • •

Carnegie Mellon
Representable Numbers
• Limitation– Can only exactly represent numbers of the form x/2k
– Other rational numbers have repeating bit representations
• Value Representation– 1/3 0.0101010101[01]…2
– 1/5 0.001100110011[0011]…2
– 1/10 0.0001100110011[0011]…2

Floating Point Standard
• Defined by IEEE Std 754-1985• Developed in response to divergence of
representations– Portability issues for scientific code
• Now almost universally adopted• Two representations
– Single precision (32-bit)– Double precision (64-bit)

IEEE Floating-Point Format
• S: sign bit (0 non-negative, 1 negative)• Normalize significand: 1.0 ≤ |significand| < 2.0
– Always has a leading pre-binary-point 1 bit, so no need to represent it explicitly (hidden bit)
– Significand is Fraction with the “1.” restored• Exponent: excess representation: actual exponent + Bias
– Ensures exponent is unsigned– Single: Bias = 127; Double: Bias = 1203
S Exponent Fraction
single: 8 bitsdouble: 11 bits
single: 23 bitsdouble: 52 bits
Bias)(ExponentS 2Fraction)(11)(x

Floating-Point Addition
• Consider a 4-digit decimal example– 9.999 × 101 + 1.610 × 10–1
• 1. Align decimal points– Shift number with smaller exponent– 9.999 × 101 + 0.016 × 101
• 2. Add significands– 9.999 × 101 + 0.016 × 101 = 10.015 × 101
• 3. Normalize result & check for over/underflow– 1.0015 × 102
• 4. Round and renormalize if necessary– 1.002 × 102

Floating-Point Addition
• Now consider a 4-digit binary example– 1.0002 × 2–1 + –1.1102 × 2–2 (0.5 + –0.4375)
• 1. Align binary points– Shift number with smaller exponent– 1.0002 × 2–1 + –0.1112 × 2–1
• 2. Add significands– 1.0002 × 2–1 + –0.1112 × 2–1 = 0.0012 × 2–1
• 3. Normalize result & check for over/underflow– 1.0002 × 2–4, with no over/underflow
• 4. Round and renormalize if necessary– 1.0002 × 2–4 (no change) = 0.0625
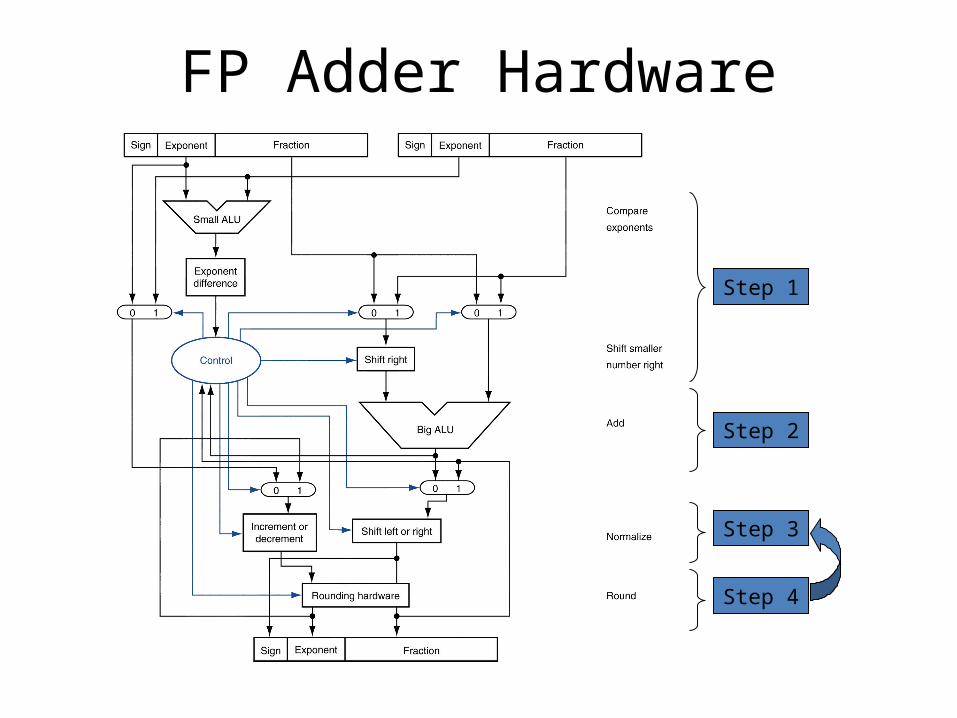
FP Adder Hardware
Step 1
Step 2
Step 3
Step 4

INTEGER MULTIPLICATION

Multiplication• Start with long-multiplication approach
1000× 1001 1000 0000 0000 1000 1001000
Length of product is the sum of operand lengths
multiplicand
multiplier
product

Multiplication• Start with long-multiplication approach
1000× 1001 1000 0000 0000 1000 1001000
Length of product is the sum of operand lengths
multiplicand
multiplier
product
Why?

How could we implement this in a better way?
• What is unique about binary multiplication?
1000× 1001 1000 0000 0000 1000 1001000

Multiplication Hardware
Initially 0

Multiplying
1000× 1001 1000
1000
Add

Multiplying
1000× 100 10000 0000
10000
AddShift!
Shift!

Multiplying
1000× 10 100000 0000
100000
AddShift!
Shift!

Multiplying
1000× 11000000 1000
1001000
AddShift!
Shift!

Multiplying
1000×
1001000
Done!Shift!

Optimized Multiplier• Perform steps in parallel: add/shift
One cycle per partial-product addition That’s ok, if frequency of multiplications is low

Faster Multiplier• Uses multiple adders
– Cost/performance tradeoff
Can be pipelined Several multiplication performed in parallel

Multiplication• Computing Exact Product of w-bit numbers x, y
– Either signed or unsigned• Ranges
– Unsigned: 0 ≤ x * y ≤ (2w – 1) 2 = 22w – 2w+1 + 1• Up to 2w bits
– Two’s complement min: x * y ≥ (–2w–1)*(2w–1–1) = –22w–2 + 2w–1
• Up to 2w–1 bits– Two’s complement max: x * y ≤ (–2w–1) 2 = 22w–2
• Up to 2w bits, but only for (TMinw)2
• Maintaining Exact Results– Would need to keep expanding word size with each product computed– Done in software by “arbitrary precision” arithmetic packages

Unsigned Multiplication in C
• Standard Multiplication Function– Ignores high order w bits
• Implements Modular ArithmeticUMultw(u , v) = u · v mod 2w
• • •
• • •
u
v*
• • •u · v
• • •
True Product: 2*w bits
Operands: w bits
Discard w bits: w bitsUMultw(u , v)
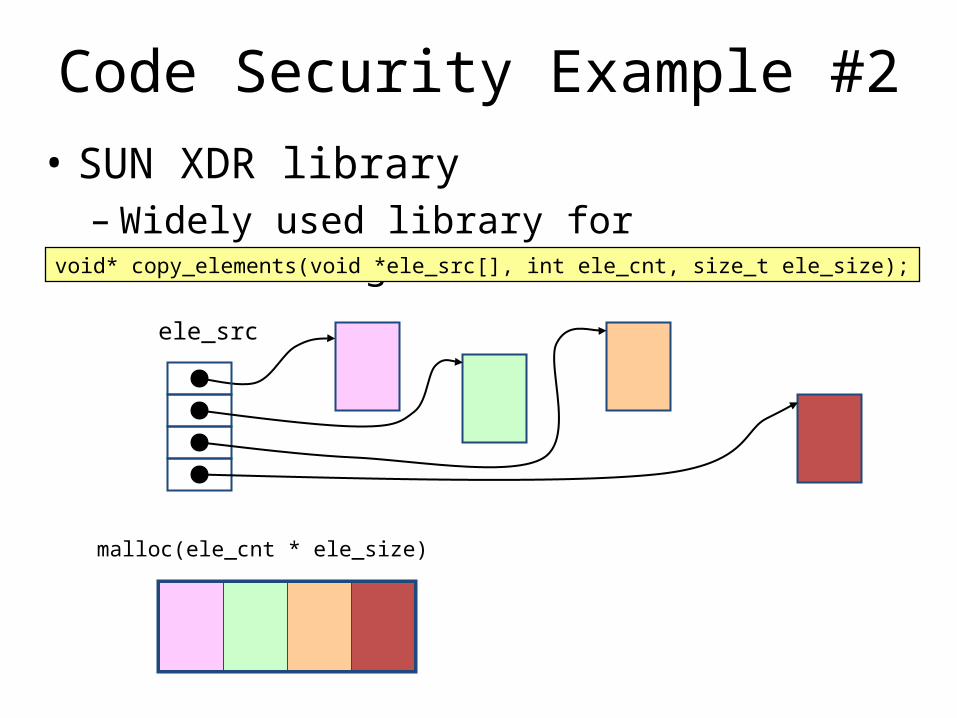
Code Security Example #2• SUN XDR library
– Widely used library for transferring data between machinesvoid* copy_elements(void *ele_src[], int ele_cnt, size_t ele_size);
ele_src
malloc(ele_cnt * ele_size)

XDR Codevoid* copy_elements(void *ele_src[], int ele_cnt, size_t ele_size) { /* * Allocate buffer for ele_cnt objects, each of ele_size bytes * and copy from locations designated by ele_src */ void *result = malloc(ele_cnt * ele_size); if (result == NULL)
/* malloc failed */return NULL;
void *next = result; int i; for (i = 0; i < ele_cnt; i++) { /* Copy object i to destination */ memcpy(next, ele_src[i], ele_size);
/* Move pointer to next memory region */next += ele_size;
} return result;}

XDR Vulnerability
• What if:– ele_cnt = 220 + 1– ele_size = 4096 = 212
– Allocation = ??
• How can I make this function secure?
malloc(ele_cnt * ele_size)

Signed Multiplication in C
• Standard Multiplication Function– Ignores high order w bits– Some of which are different for signed vs.
unsigned multiplication– Lower bits are the same
• • •
• • •
u
v*
• • •u · v
• • •
True Product: 2*w bits
Operands: w bits
Discard w bits: w bitsTMultw(u , v)
• • •

Power-of-2 Multiply with Shift• Operation
– u << k gives u * 2k
– Both signed and unsigned
• Examples– u << 3 == u * 8– u << 5 - u << 3 == u * 24– Most machines shift and add faster than multiply
• Compiler generates this code automatically
• • •
0 0 1 0 0 0•••
u
2k*
u · 2kTrue Product: w+k bits
Operands: w bits
Discard k bits: w bits UMultw(u , 2k)
•••
k
• • • 0 0 0•••
TMultw(u , 2k)0 0 0••••••

Multiply on ARM
MUL{<cond>}{S} Rd, Rm, RsRd = Rm * Rs
MLA{<cond>}{S} Rd, Rm, Rs, RnRd = Rm * Rs + Rn

Division• Check for 0 divisor• Long division approach
– If divisor ≤ dividend bits• 1 bit in quotient, subtract
– Otherwise• 0 bit in quotient, bring down next
dividend bit
• Restoring division– Do the subtract, and if remainder goes <
0, add divisor back• Signed division
– Divide using absolute values– Adjust sign of quotient and remainder as
required
10011000 1001010 -1000 10 101 1010 -1000 10
n-bit operands yield n-bitquotient and remainder
quotient
dividend
remainder
divisor

Division Hardware
Initially dividend
Initially divisor in left half

Optimized Divider
• One cycle per partial-remainder subtraction• Looks a lot like a multiplier!
– Same hardware can be used for both

Faster Division
• Can’t use parallel hardware as in multiplier– Subtraction is conditional on sign of remainder
• Faster dividers (e.g. SRT devision) generate multiple quotient bits per step– Still require multiple steps

Division in ARM
• ARMv6 has no DIV instruction.

Division in ARM
• ARMv6 has no DIV instruction.
N = D x Q + Rwith 0 <= |R| < |D|
N/D = Q + R

An Algorithm for Division

An Algorithm for Division

An Algorithm for Division

WRAP UP

For next time
Homework Exercises: 3.4.2, 3.4.4
3.10.1 – 3.10.5
Due Tuesday 11/4
Read Chapter 4.1-4.4


















