
Laboratorio d’impresa “Conoscere e interpretare per ... · • Indagini più mirate e...
25
UNIVERSITÀ DEGLI STUDI DI BERGAMO UNIVERSITÀ DEGLI STUDI DI BERGAMO Laboratorio d’impresa “Conoscere e interpretare per governare il mercato… anche usando la Statistica” Prof.ssa Michela Cameletti 24 Ottobre 2017
Transcript of Laboratorio d’impresa “Conoscere e interpretare per ... · • Indagini più mirate e...

UNIVERSITÀ DEGLI STUDI DI BERGAMO
UNIVERSITÀ DEGLI STUDI DI BERGAMO
Laboratorio d’impresa“Conoscere e interpretare per
governare il mercato…anche usando la Statistica”
Prof.ssa Michela Cameletti
24 Ottobre 2017

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Ricerche di mercato e di marketing• Capire i bisogni, i comportamenti, le opinioni e le
aspettative dei consumatori/clienti.
• Rilevare i concorrenti presenti sul mercato.
• Verificare le reazioni dei consumatori e del del mercato ad
una nuova linea di prodotti, campagna pubblicitaria, ecc..
I risultati supportano il processo decisionale e
l’attività di controllo.
2

UNIVERSITÀ DEGLI STUDI DI BERGAMO
L’era dei big data
3

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipologie di ricerche di mercato
• Esplorative: per chiarire la natura di un problema
aziendale e ottenere informazioni generali sui
propri consumatori (à indagini qualitative).
• Descrittive (o osservazionali): per stimare la
dimensione quantitativa e per validare un’ipotesi
numerica circa il comportamento dei consumatori
(à indagini quantitative longitudinali/sezionali).
• Causali: per valutare gli effetti di un cambiamento
o di una campagna promozionale sui
comportamenti di acquisto dei consumatori.
4

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipologie di ricerche di mercato
• Qualitative: svolte su poche unità statistiche
(focus group) mirano a studiare in profondità gli
atteggiamenti, i comportamenti e le dinamiche
psicologiche dei consumatori.
• Quantitative: si realizzano tramite campioni
rappresentativi della popolazione e mirano a
misurare caratteri di interesse.
• Integrate: qualitative + quantitative
5

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Terminologia essenziale• Unità statistica: unità elementare di una popolazione su cui vengono osservati i
caratteri di interesse (es: studente, famiglia, azienda, ecc.).
• Popolazione: insieme delle N unità statistiche omogenee rispetto ad un fattore.
• Carattere (o variabile): caratteristica o aspetto oggetto di rilevazione nelle unità
statistiche del collettivo (es: peso, numero di addetti, ecc.).
• Modalità del carattere: modi di manifestarsi (manifestazioni) del carattere nelle unità
statistiche del collettivo (es: il carattere “stato occupazionale” si manifesta con le
modalità “occupato”, “disoccupato”, …).
• Tipi di carattere:
• Qualitativo sconnesso • Qualitativo ordinale• Quantitativo discreto• Quantitativo continuo
6

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Indagine censuarieDato un insieme di caratteri di interesse e una popolazione di riferimento, l’indagine va aosservare/misurare le manifestazioni (o modalità) dei caratteri sulle singole unitàstatistiche.
Se l’indagine è totale o censuaria i caratteri sono rilevati su tutte le unità statistichedella popolazione target.
Pregi: • Ricchezza delle informazioni raccolte• Esaustività
Difetti:• Costo elevato• Tempi molto lunghi • Qualità dei dati non sempre elevata
(errori di osservazione/trascrizione)• Infattibile se la popolazione target è
“infinita” o se la rilevazione comporta la distruzione delle unità statistiche
7

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Indagine campionarie
Pregi: • Economicità• Tempistiche• Indagini più mirate e approfondite• Costi ridotti• Continuità della rilevazione (panel)
Difetti:• Errore di campionamento (variabilità
campionaria)• Errori di copertura (campione non
rappresentativo)
Campione (sample)di n=5 unità stat.
In generale il campione deve essererappresentativo della popolazione diriferimento, ovvero presenta alcunecaratteristiche della popolazione inproporzioni analoghe.
Come costruisco il campione?
8
UNIVERSITÀ DEGLI STUDI DI BERGAMO
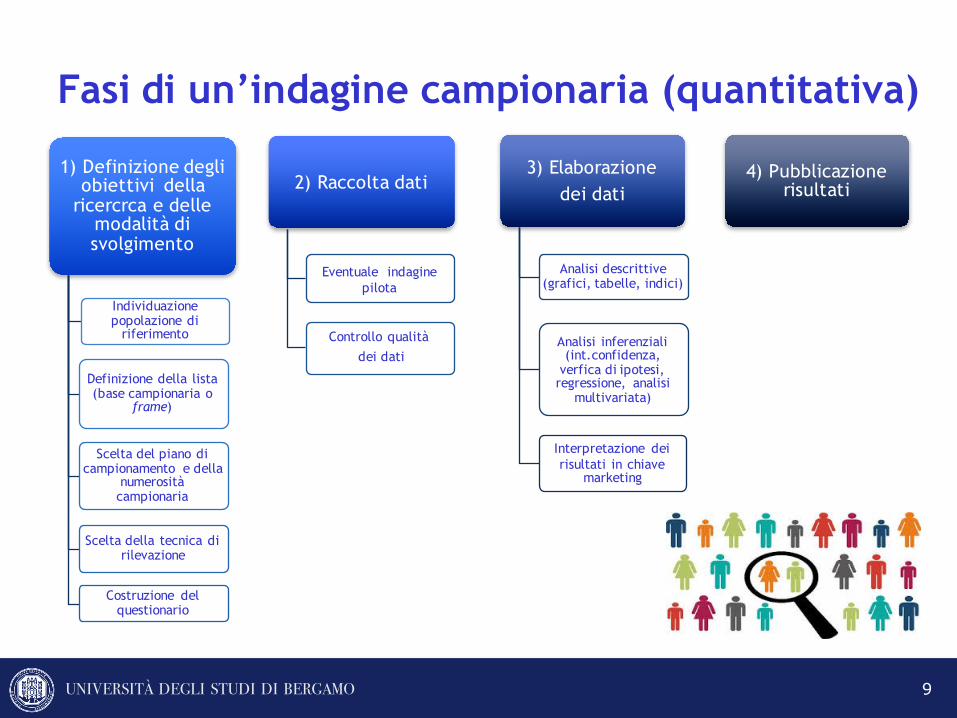
Fasi di un’indagine campionaria (quantitativa)
1) Definizione degliobiettivi della
ricercrca e dellemodalità di svolgimento
Individuazionepopolazione di
riferimento
Definizione della lista(base campionaria o
frame)
Scelta del piano di campionamento e della
numerositàcampionaria
Scelta della tecnica di rilevazione
Costruzione del questionario
2) Raccolta dati
Controllo qualitàdei dati
Eventuale indaginepilota
3) Elaborazionedei dati
Analisi descrittive(grafici, tabelle, indici)
Analisi inferenziali(int.confidenza,
verfica di ipotesi, regressione, analisi
multivariata)
Interpretazione deirisultati in chiave
marketing
4) Pubblicazionerisultati
9

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipi di campione
10
1. Campione probabilistico (o statistico)• Deve essere disponibile una lista delle unità della popolazione.• La scelta delle unità campionarie avviene con criteri di casualità.• Ogni unità statistica è associata a una probabilità (positiva) di essere inclusa nel
campione.• E’ possibile utilizzare i risultati per fare inferenza statistica (stima puntuale,
intervallare, verifica di ipotesi).• Sono soggetti all’errore campionario.
2. Campione non probabilistico• Non serve (o non è disponibile) una lista delle unità della popolazione.• Non è possibile attribuire una probabilità di estrazione alle unità della
popolazione di riferimento.• La scelta delle unità campionarie è lasciata all’arbitrio del rilevatore in base a
ragioni di comodo e praticità (la selezione non è casuale).• Danno risultati di massima non generalizzabili alla popolazione di riferimento e
non consentono di valutare l’attendibilità delle stime campionarie.• Utilizzati per indagini quantitative (preliminari) o per indagini qualitative.
10

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipi di campione non probabilistico
11
1. Campione a scelta ragionata• La scelta delle unità campionarie è effettuata sulla base delle conoscenze del
ricercatore o da esperti (criteri soggettivi).
2. Campione di comodo o di convenienza• Le unità campionarie vengono scelte arbitrariamente dagli intervistatori tra
quanti si trovano in una determinata situazione (es. in un certo negozio).• Distorsioni: autoselezione, postazione intervistatore, momento intervista.
3. Campione per quote• La dimensione del campione – nota a priori – viene ripartita in classi definite da
caratteri socio-demografici o economici.• Vengono definite le quote, ovvero il numero di interviste per ogni classe. Date le
quote gli intervistatori scelgono discrezionalmente le unità da contattare.
4. Campione a valanga• Per indagini su popolazioni rare• Ai soggetti intervistati si chiedono nominativi di altri soggetti appartenenti alla
popolazione di interesse
11

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipi di campione probabilistico
12
3. Campione stratificato• Sulla base del fenomeno di interesse o di
variabili ausiliarie la popolazione viene divisa inH strati omogenei da ciascuno dei qualivengono estratte le unità campionarie con CCS
• I sottocampioni (da ogni strato) possono avereuguale numerosità (n/H) o numerositàproporzionale alla composizione degli stratidella popolazione (Nh/N)
Popolazione
p rimo strato s econdo strato t erzo strato
campione
estrazione casuale
Variabile di stratificazione
1. Campione casuale semplice (CCS)• Le unità della popolazione hanno tutte la stessa probabilità di essere incluse nel
campione.• Nelle indagini di mercato si usa il CCS senza ripetizione.• È opportuno su popolazioni relativamente piccole, in un’area ristretta, dove si
può disporre di liste complete.2. Campione sistematico
• Si calcola il tasso di campionamento (o passo) k=n/N• Data un’unità di partenza scelta casualmente, le restanti unità campionarie
vengono scelte prelevando un elemento ogni k.

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Tipi di campione probabilistico
13
4. Campione a grappoli• La popolazione viene suddivisa in sottoinsiemi detti grappoli eterogenei al loro
interno (ad esempio, comuni, asl, palazzi di un comune, ecc.).• Viene estratto con CCS un certo numero di grappoli (primo stadio).
a) Vengono analizzate tutte le unità statistiche appartenenti ai grappoliestratti.
b) Vengono estratte con CCS un certo numero di unità statistiche (secondostadio).
Popolazione
campione di unità elementari
estrazione casuale delle unità dai grappoli
Criterio di raggruppamento
grappolo 1 grappolo 2 grappolo 3 grappolo k
estrazione casuale dei grappoli
unità primarie
unità secondarie

UNIVERSITÀ DEGLI STUDI DI BERGAMO 14
La numerosità campionaria (campioni prob.)Variabilità nella popolazione
• Una maggiore variabilità nella popolazione richiede un campione più ampio.• Per una popolazione con individui aventi tutti le medesime caratteristiche basta
una sola persona per rappresentarli.Precisione dei risultati campionari (stime)
• Il margine di errore che si è disposti a tollerare viene stabilito a priori.• Una maggiore precisione richiede un campione più ampio.
Livello di fiducia (confidenza)• Di solito fissata in 1-α=0.95 o 0.99.• Per avere una maggiore fiducia nei risultati campionari è necessario aumentare la
numerosità campionaria.
Costi• Un aumento della numerosità campionaria porta ad un aumento dei costi• Vincolo di bilancio
TEORIA DEI CAMPIONI

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Calcolo della numerosità campionaria: CCSUn rapido ripasso
15
• È la numerosità che permette alle stime campionarie di raggiungere il livello diprecisione che ci attendiamo.
Parametro (incognito) della popolazione 𝜃• Media 𝜇• Proporzione 𝜋
Stime campionarie• Media campionaria• Proporzione campionaria
La stima è la determinazione di uncorrispondente stimatore che gode dicerte proprietà (correttezza,consistenza, efficienza) che siricavano teoricamente ipotizzando dipoter estrarre da una popolazionetutti i possibili campioni distinti di unadeterminata dimensione.
Campione
Popolazione(finita)

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Calcolo della numerosità campionaria: CCSUn rapido ripasso
16
• Si ipotizzi di voler stimare la MEDIA della popolazione 𝜇 per un certo carattere X che sisuppone distribuito Normalmente.
• Lo stimatore ottimale è la media campionaria𝑋% =∑ ()*)+,- di cui è noto che
𝐸(𝑋%) = 𝜇 (stimatore corretto)
𝑉𝑎𝑟(𝑋%) = 45
-67-678
(67-678è il fattore di correzione per campion. senza reinserimento. Circa 1 se N>>n).

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Calcolo della numerosità campionaria: CCSUn rapido ripasso
17
• L’intervallo di confidenza a livello 1- 𝛼(di solito 0.95 o 0.99) per la media 𝜇è dato da
𝑿< − 𝒛𝟏7𝜶/𝟐𝝈𝟐
𝒏𝑁− 𝑛𝑁 − 1
≤ 𝝁 ≤ 𝑿< + 𝒛𝟏7𝜶/𝟐𝝈𝟐
𝒏𝑁 −𝑛𝑁 − 1
• L’errore campionarioΔ coincide con la semiampiezza (precisione della stima).
• In una lunga serie di campioni di n elementi da una popolazione distribuitanormalmente si può affermare che il 95/99% degli intervalli di confidenza include lamedia ignota della popolazione.
• Fissato l’errore campionario massimo Δ che si vuole commettere e il livello di confidenza 1- 𝛼 si trova
𝑛 =𝑵𝝈𝟐𝒛𝟏7𝜶/𝟐𝟐
ΔM 𝑁 − 1 + 𝒛𝟏7𝜶/𝟐𝟐 𝝈𝟐
Errore campionario Δ Errore campionario Δ

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Calcolo della numerosità campionaria: CCS
18
𝑛 =𝑵𝝈𝟐𝒛𝟏7𝜶/𝟐𝟐
ΔM 𝑁 − 1 + 𝒛𝟏7𝜶/𝟐𝟐 𝝈𝟐
Per l’ignota varianza 𝝈𝟐 della popolazione si può utilizzare:
• una stima preliminare della variabilità del carattere, proveniente, per esempio, daconoscenze a priori sulla popolazione in questione.
• una stima ottenuta nella fase di pre-test del questionario, sottoposto al vaglio di unpiccolo campione ragionato di intervistati.
• la relazione 𝜎 ≤ OP-QRM .

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Calcolo della numerosità campionaria: CCSUn rapido ripasso
19
E’ possibile ricavare la numerosità campionaria anche per altri parametri (proporzione) eper gli altri piani di campionamento probabilistici.
Esempio:
Con una popolazione di 5000 clienti, si fissail livello di confidenza in 1-α=0.95 perstimare la proporzione di clienti soddisfattidel prodotto con un margine di errore del +/-2.5%.La numerosità n che soddisfa tali requisiti èdi 1176 clienti da scegliere casualmente conCCS.

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Gli errori di un’indagine
20
Alta precisione e correttezza
Bassa precisionee correttezza
Alta precisione e distorsione
Bassa precisione edistorsione
Precisione:Varianzastimatore
Correttezza/Distorsione: valore attesostimatore
MSE=Var+B2
(errore quadratico mediodi uno stimatore =varianza+distorsione2)

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Gli errori di un’indagine
Errore totale
Errore campionario
Errore non campionario
Errori di mancataosservazione
Errore di copertura(overcoverageo undercoverage)
Errore di mancatarisposta (totale o
parziale)
Errore di misura o di osservazione
Nella raccolta deidati
Nell’elaborazionedei dati
21

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Indagini on-line
• Si è passati dalle interviste personali PAPI (Paper And Pencil Interview) e CAPI(Computer Assisted Personal Interview) e postali alle interviste telefoniche CATI(Computer Assisted Telephone Interview) e più recentemente a sondaggi di tipo CAWI(Computer Assisted Web Interview), detti anche online surveys o web surveys.
• Viene spedito un messaggio di posta elettronica alle unità statistiche corredato dilettera di presentazione della ricerca e con l’indicazione del sito a cui collegarsi percompilare il questionario.
• In alternativa viene creato un banner che rimanda al sito del questionario(campionamento non probabilistico – self-selection survey).
• L’intervistato compila il questionario on-line e i dati vengono automaticamentememorizzati in un database.
22

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Indagini on-line
23
Vantaggi: •Bassi costi•Velocità di realizzazione indagine (Google Forms, SurveyMonkey)•Possibilità di includere immagini, video, ecc.
Svantaggi:
•Undercoverage (persone senza internet*)
•Errore di selezione (self-selection)
•Mancate risposte
*Su una popolazione di quasi 60 milioni di abitanti, oltre 39 milioni utilizzano internet e 31 milioni sono attivi sui social media,
ovvero il 52% del totale. http://www.dailyonline.it/digital-italia-social-internet/
** The Importance of Selection Bias in Internet Surveys, https://file.scirp.org/pdf/OJS_2016061415351120.pdf
Esistono metodi statistici per correggere ladistorsione delle stime tramiteaggiustamenti a posteriori delle stime percercare di rendere il campionerappresentativo (post-stratificazione,adjustment weightingmethods)**.

UNIVERSITÀ DEGLI STUDI DI BERGAMO 24
Grazie per la vostra attenzione

UNIVERSITÀ DEGLI STUDI DI BERGAMO
Bibliografia• J. Bethlehem, Applied Survey Methods. A statistical perspective, 2009, Wiley.
• S. Borra, A. Di Ciaccio, Statistica – Metodologie per le scienze economiche e
sociali, 2014, McGraw Hill
• A. De Luca, Le ricerche di mercato. Guida partica e teorica. 2006, Franco Angeli.
• B. Kolb, Marketing research. A practical Approach. 2008, Sage.
25


![La georeferenziazione delle informazioni territoriali ...lps16.esa.int/posterfiles/paper1213/[RD9]_Georeferenziazione.pdf · utilizzazione anche da parte di chi non abbia approfondite](https://static.fdocuments.net/doc/165x107/5c69850c09d3f2f5638d4f59/la-georeferenziazione-delle-informazioni-territoriali-lps16esaintposterfilespaper1213rd9.jpg)















