
Laboratorio di analisi di dati linguistici
143
Laboratorio di analisi di dati linguistici Laurea specialistica in Linguistica Teorica e Applicata, Università di Pavia Andrea Sansò [email protected] A.A. 2005-2006 Corso progredito 10 CFU
description
Laboratorio di analisi di dati linguistici. Laurea specialistica in Linguistica Teorica e Applicata, Università di Pavia Andrea Sansò [email protected] A.A. 2005-2006 Corso progredito 10 CFU. Laboratorio di analisi di risorse linguistiche. Parte quinta Elementi di XML - PowerPoint PPT Presentation
Transcript of Laboratorio di analisi di dati linguistici

Laboratorio di analisi di dati linguistici
Laurea specialistica in Linguistica Teorica e Applicata, Università di Pavia
Andrea Sansò[email protected]
A.A. 2005-2006
Corso progredito
10 CFU

Laboratorio di analisi di risorse linguistiche
Parte quinta
Elementi di XML
La standardizzazione

Sommario
XML e HTML XML e SGML La sintassi di XML: tags, nesting,
commenti, elementi e attributi, la pianificazione
Creazione di documenti XML ben formati: la DTD

Un sito di riferimento
http://www.w3schools.com

XML e HTML

XML e HTML
XML was designed to carry data.XML is not a replacement for HTML.
XML and HTML were designed with different goals:
XML was designed to describe data and to focus on what data is.
HTML was designed to display data and to focus on how data looks.
HTML is about displaying information, while XML is about describing information.

XML e HTML
XML (eXtensible Markup Language) è un linguaggio di markup come HTML (Hyper Text Markup Language), ma a differenza di HTML può essere personalizzato per applicarlo a dati di qualsiasi natura.
Un file HTML è un testo contenente dei tag di markup che indicano al browser come visualizzare la pagina:
Esempio

Che cosa significa etichettatura?
Da www.tei-c.org:
… we define markup, or (synonymously) encoding, as any means of making explicit an interpretation of a text. Of course, all printed texts are implicitly encoded (or marked up) in this sense: punctuation marks, use of capitalization, disposition of letters around the page, even the spaces between words, might be regarded as a kind of markup, the function of which is to help the human reader determine where one word ends and another begins, or how to identify gross structural features such as headings or simple syntactic units such as dependent clauses or sentences. Encoding a text for computer processing is in principle … a process of making explicit what is conjectural or implicit, a process of directing the user as to how the content of the text should be (or has been) interpreted.

Che cosa significa etichettatura?
Da www.tei-c.org:
By markup language we mean a set of markup conventions used together for encoding texts. A markup language must specify what markup is allowed, what markup is required, how markup is to be distinguished from text, and what the markup means.

HTML
Che cosa contiene un file HTML
• tags di apertura e di chiusura <head> </head>
• attributi contenuti all’interno delle tags <body text="#000000" bgcolor="#3333FF" link="#000099" vlink="#666600” alink="#006600” background="unipvBK.gif"> bla bla bla</body>
Esempio

HTML
Che cosa contiene un file HTML
• heading tags <h1>Title</h1> <h2>Subtitle</h2>, …• paragraph tags <p>This is a paragraph</p>• line breaks <br>
Una lista comoda di tutti i tipi di tag si trova all’indirizzo:
http://www.w3schools.com/html/html_quick.asp
Esempio

HTML
I tags (e in generale la sintassi) di HTML contengono esclusivamente informazioni relative alla visualizzazione del documento attraverso un browser. HTML, a differenza di XML, rimedia autonomamente ad alcuni errori facili da riconoscere (esempio). L’esistenza di applicazioni di tipo WYSIWYG come FrontPage ha reso non indispensabile la conoscenza della sintassi di HTML per la creazione di pagine web. Lo stesso non può dirsi di XML!
Inoltre, HTML è utilizzato per la visualizzazione e consultazione di file XML, e quindi è utile conoscerne il funzionamento (anche perché FrontPage non permette operazioni complesse come l’inserimento di dati codificati in XML all’interno di un documento HTML!).

HTML
Un breve corso di HTML è online al seguente indirizzo:
http://www.w3schools.com/html/default.asp
Un quiz per verificare la propria competenza in HTML si trova all’indirizzo:
http://www.w3schools.com/html/html_quiz.asp
Esempi semplici di pagine HTML all’indirizzo:
http://www.w3schools.com/html/html_examples.asp

HTML
Alcuni documenti non sono comodamente descrivibili con HTML. Le pagine HTML consentono ad esempio di archiviare e visualizzare informazioni di database statici, ma se si desidera ordinare, filtrare e trovare informazioni o elaborarle in altri modi, HTML diventa insufficiente.
XML non sostituisce HTML. Come vedremo, nella gran parte dei casi i metodi di visualizzazione dei documenti XML richiedono l’uso di HTML. Più che sostituirlo, XML si utilizza correntemente con HTML aumentando notevolmente la capacità delle pagine web di presentare informazioni molto strutturate.

2
XML e SGML

XML e SGML
XML e HTML si fondano su SGML (Standard Generalized Markup Language), un linguaggio sviluppato per fornire un metodo di identificazione delle parti e del contenuto di un documento sulla base delle informazioni contenute. SGML e XML, a differenza di HTML, sono entrambi degli insiemi di regole usate per controllare la creazione di linguaggi di markup che identificano il contenuto dei documenti. XML e SGML sono entrambi particolarmente adatti a documenti che contengono grandi quantità di informazioni organizzate in modo simile, come cataloghi o database. SGML e XML consentono inoltre la lettura del documento da parte di qualunque tipo di software, e l’autore del documento è in grado di specificare come ogni porzione del documento verrà interpretata da tutti i software.

SGML
SGML è stato sviluppato avendo come finalità la predisposizione di un sistema di rappresentazione e gestione documentale in grado di consentire l’illimitato trasferimento dei dati codificati tra differenti piattaforme informatiche (hardware e software) senza perdite di informazione.
Inoltre, SGML è indipendente dalle applicazioni, cioè permette la rappresentazione di qualsiasi tipo di testo e di qualsiasi caratteristica testuale, indipendentemente dalle finalità per le quali il testo è stato memorizzato e codificato.
Infine, SGML è indipendente dalle lingue nazionali e dai relativi sistemi di scrittura, permettendo la rappresentazione di testi redatti in qualsiasi sistema alfabetico latino e non latino.

XML e SGML
SGML può sembrare il linguaggio perfetto per descrivere l’informazione contenuta nei documenti, ma è sempre stato considerato troppo complesso per diventare il linguaggio universale del web. Nel 1996, l’XML Working Group del W3 Consortium ha sviluppato un sottoinsieme di SGML chiamato XML. XML è quindi una versione semplificata di SGML ottimizzata per il web, che mantiene tutti i vantaggi di SGML. Come SGML, XML consente di creare un insieme proprio di etichette da utilizzare nella descrizione di un determinato documento o insieme di documenti.

3
La sintassi di XML:tags, nesting, commenti, elementi e attributi, la
pianificazione

Perché XML?
• XML is a cross-platform, software and hardware independent tool for transmitting information.• XML will be as important to the future of the Web as HTML has been to the foundation of the Web.• XML will be the most common tool for all data manipulation and data transmission.

Che cos’è XML?
Un semplice documento XML:
<note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>

Che cos’è XML?
I tag XML descrivono la struttura del documento, oltre ad identificarne il contenuto. Proprio come i tag HTML, essi vengono aperti e chiusi con parentesi angolari. Dopo il tag di apertura verrà collocato il contenuto effettivo e infine il tag di chiusura (che si distingue per l’aggiunta di una barra trasversale alla parentesi angolare aperta).

Che cos’è XML?
<note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
Forse è difficile da comprendere immediatamente, ma XML non serve a “fare” niente. Serve soltanto a strutturare, immagazzinare e diffondere informazione. Questo semplice documento XML rappresenta informazione pura “codificata” attraverso i tags XML. Perché XML sia utile a qualcosa, bisogna trovare un sistema per diffondere questa informazione o semplicemente per visualizzarla.

Che cos’è XML?
<note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
I tags di XML non sono predefiniti, ma devono essere inventati. Gli autori di documenti HTML possono usare solo i tags predefiniti nello standard HTML (come <p>, <h1>, ecc.).

Che cos’è XML?
Quando si usa HTML per visualizzare dei dati, i dati sono contenuti all’interno del file HTML. Utilizzando XML i dati si possono immagazzinare in files separati. In questo modo si può utilizzare HTML solo per il layout e la visualizzazione, essendo sicuri che i cambiamenti nel file XML non richiedono alcun adattamento del file HTML ausiliario.

Che cos’è XML?
I file XML possono essere compilati con un semplice editor di testo, e pertanto possono essere condivisi indipendentemente dal software e dall’hardware.
È possibile creare documenti XML utilizzando il proprio editor preferito (Microsoft Word, Notepad, ecc.), anche se esistono editor che facilitano la scrittura di XML (XMLSpy, JEdit, ecc.).

Che cos’è XML?
Esempi di editors:
•XMetaL: è possibile prelevarne una versione dimostrativa (30 giorni) sul sito di SoftQuad (www.softquad.com)
• XML Spy: è possibile prelevare una demo di questo software, funzionante per trenta giorni, dal sito web di Icon Information Systems (www.xmlspy.com)

Il primo documento XML
Se si salva un file in Notepad, l’estensione che viene automaticamente assegnata è .txt. Per assegnare una diversa estensione, si deve racchiudere il nome del file + l’estensione tra virgolette (es. “inventario.xml”). Quando andremo a riaprire il file salvato con estensione .xml, bisognerà aprire prima Notepad e poi scegliere “Apri” dal menu “File” (non è possibile aprirlo facendo doppio clic come si fa normalmente per i files .txt).

Il primo documento XML
<?xml version=“1.0” encoding=“UTF-8”?><note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
Dichiarazione XML
Root element
Child elements
End of the root element

Il primo documento XML
<?xml version="1.0" encoding=“UTF-8"?>
Dichiarazione XML
La dichiarazione XML indica che si tratta di un documento XML (e include il numero di versione, specificando che il documento utilizza l’insieme di caratteri UTF-8).

Il primo documento XML
<note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
Root element
Child elements
End of the root element
L’elemento radice del documento specifica di che tipo di documento si tratta. Tra i due tag <note> e </note> si collocano gli elementi annidati.

Il primo documento XML
In XML non è possibile omettere dei tag di chiusura, mentre in HTML in taluni casi è possibile:
<p>This is a paragraph<p>This is another paragraph
HTML
<p>This is a paragraph</p><p>This is another paragraph</p>
XML

Il primo documento XML
La dichiarazione XML non ha un tag di chiusura. Non si tratta di un errore, perché la dichiarazione non è parte del documento in senso stretto e non si può ritenere un elemento (n.b.: ogni tag identifica un elemento)
<?xml version="1.0" encoding=“UTF-8”?>

Il primo documento XML
I tags di XML, a differenza di quelli di HTML sono case sensitive. Il tag <Letter> è pertanto diverso dal tag <letter>, e ovviamente è necessario che i tag di apertura e di chiusura siano scritti ESATTAMENTE allo stesso modo
<Message>This is incorrect</message><message>This is correct</message>

Il primo documento XML
Tutti gli elementi devono essere annidati in maniera corretta (a differenza di HTML, che permette un certo grado di libertà).
<b><i>This text is bold and italic</b></i>
HTML
<name><family-name> Brambilla</family-name></name>
XML

Il primo documento XML
L’elemento radice è obbligatorio. Tutti gli altri elementi devono essere annidati all’interno di questo elemento, e all’interno di ogni elemento figlio possono essere annidati a loro volta altri elementi
<root><child><subchild>.....</subchild></child></root>

Il primo documento XML
<?xml version="1.0" encoding="ISO-8859-1"?><CD>
<TITLE>Empire Burlesque</TITLE><ARTIST>Bob Dylan</ARTIST><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR>
</CD><CD>
<TITLE>Hide your heart</TITLE><ARTIST>Bonnie Tyler</ARTIST><COMPANY>CBS Records</COMPANY><PRICE>9.90</PRICE><YEAR>1988</YEAR>
</CD>
Documento non ben strutturato perché ha due elementi radice anziché uno

Il primo documento XML
Possiamo concludere che XML è molto più rigido di HTML. Le applicazioni che leggono XML non possono ignorare gli errori, ma si fermano esattamente in corrispondenza dell’errore del documento e inviano un messaggio d’errore al visualizzatore. Ciò rende relativamente semplice il debugging dei documenti XML perché è sempre possibile sapere con precisione quale linea sta provocando l’errore quando si visualizza il documento.
Esempio

Esempio
<?xml version="1.0"?><INVENTORY><BOOK><TITLE>Il fauno di marmo</TITLE><AUTHOR>Nathaniel Hawthorne</AUTHOR><BINDING>tascabile</BINDING><PAGES>473</PAGES><PRICE>EURO 10,95</PRICE></BOOK><BOOK><TITLE>Moby Dick</TITLE><AUTHOR>Herman Melville</AUTHOR><BINDING>copertina rigida</BINDING><PAGES>724</PAGES><PRICE>EURO 9,95</PRICE></BOOK></INVENTORY>

Inserimento di commenti
In un documento XML è possibile inserire dei commenti, che verranno ignorati dal visualizzatore, ma che possono avere una funzione fondamentale (ad esempio, possono brevemente segnalare le scelte del creatore del file, o la data dell’ultima modifica). Un commento inizia con i caratteri <!-- e termina con i caratteri -->. Tra questi due gruppi di caratteri è possibile digitare un qualsiasi testo, tranne i caratteri --, che verrebbero intesi dal browser come chiusura del commento.
<?xml version="1.0" encoding="ISO-8859-1"?><!-- Edited with XML Spy v4.2 --><CATALOG><CD>...

Elementi
<TITLE>Moby Dick <SUBTITLE> o la balena </SUBTITLE></TITLE>
Nome dell’elemento
Contenuto dell’elemento TITLE
Elemento annidatoDati carattere

Elementi
Quando si aggiunge un elemento al documento XML, è possibile selezionare qualsiasi nome, purché venga rispettata la seguente regola:
Il nome deve iniziare con una lettera o un carattere di sottolineatura (_), seguito da zero o più lettere, cifre, punti, trattini o caratteri di sottolineatura.
Esempi di nomi non validi:
<1stplace> non si può iniziare con un numero
<B section> non sono ammessi spazi vuoti
<B/section> non è ammesso il carattere “barra”
<:Chapter> non si può cominciare con i due punti

Elementi
Alcuni caratteri non sono ammessi all’interno del contenuto degli elementi. Ad esempio la parentesi angolare sinistra non è ammessa. Per risolvere il problema, bisogna sostituire il carattere illegale con un riferimento a un’entità predefinita
<message>if salary < 1000 then</message>Sostituire con<message>if salary < 1000 then</message>
Entità predefinite< <> >& &' '" "

Elementi vuoti
È possibile immettere degli elementi vuoti all’interno di un documento. L’importanza degli elementi vuoti è fondamentale: essi ci permettono di mantenere la simmetria strutturale, ad esempio nei vari item di una lista o rubrica, come nell’esempio seguente, in cui non conosciamo il prezzo di uno degli item della lista. L’elemento vuoto ha un tag proprio (oppure si possono usare i tag di apertura e chiusura uno subito dopo l’altro; le due notazioni sono del tutto equivalenti).
<PRICE></PRICE> oppure
<PRICE/>

Esempio<?xml version="1.0" encoding="ISO-8859-1"?><CATALOG>
<CD><TITLE>Empire Burlesque</TITLE><ARTIST>Bob Dylan</ARTIST><COMPANY>Columbia</COMPANY><PRICE>10.90</PRICE><YEAR>1985</YEAR>
</CD><CD>
<TITLE>Hide your heart</TITLE><ARTIST>Bonnie Tyler</ARTIST><COMPANY>CBS Records</COMPANY><PRICE/><YEAR>1988</YEAR>
</CD></CATALOG>

Inserimento di attributi
Nel tag iniziale di ciascun elemento è possibile includere uno o più attributi. Una specifica di un attributo è rappresentata da una coppia nome-valore associata all’elemento. Gli attributi rappresentano un metodo alternativo per includere informazioni in un documento.
<BOOK category=“fiction” binding=“paperback”>...</BOOK>
Attributi

Inserimento di attributi
L’aggiunta di un attributo offre diversi vantaggi. Come vedremo, se si scrive un documento valido utilizzando una DTD, è possibile limitare i valori che possono essere assegnati a un attributo, ed è possibile specificare un valore predefinito che verrà assegnato all’attributo nel caso venga omessa la specifica. Al contrario, utilizzando una DTD non è possibile specificare un valore predefinito per il contenuto di un elemento.
Non esistono regole obbligatorie riguardo a ciò che deve essere memorizzato all’interno degli attributi o come contenuto di un elemento.

Inserimento di attributi
Il valore assegnato ad un attributo è una serie di caratteri delimitato da virgolette. È possibile assegnare qualsiasi valore letterale ad un attributo, purché si rispettino le regole seguenti:
• La stringa può essere delimitata da virgolette singole (‘’) o doppie (“”);
• la stringa non può contenere lo stesso carattere utilizzato per delimitarla (quindi se si vogliono includere nella stringa le virgolette singole, si dovrà delimitare la stringa stessa con virgolette doppie, e viceversa);
• la stringa non può includere la parentesi angolare sinistra, se non attraverso il riferimento ad un’entità generale.

Inserimento di attributi: esempio
<?xml version="1.0"?><INVENTORY><BOOK Binding="tascabile economico"><TITLE>Le avventure di Huckleberry Finn</TITLE><AUTHOR Born="1835">Mark Twain</AUTHOR><PAGES>298</PAGES></BOOK><BOOK Binding="copertina rigida"><TITLE>Foglie d'erba</TITLE><AUTHOR Born="1819">Walt Whitman</AUTHOR><PAGES>462</PAGES></BOOK></INVENTORY>

La pianificazione
Quando si utilizza XML non conviene procedere a lume di naso. L’approccio ottimale quando si hanno dei dati da marcare con XML richiede un minimo di pianificazione.
• Prima fase: stabilire il livello di dettaglio (che cosa va negli attributi e che cosa negli elementi? Entrambi sono accessibili a una query, ma si tende a limitare la proliferazione degli attributi…). Inoltre, un elemento può essere semplice o comprendere diversi elementi annidati.
• Seconda fase: creare il template di un documento XML prima di inserire il contenuto è sempre utile. Ciò non significa che non si debbano escogitare sempre nuove modifiche in corso d’opera...

La pianificazione
Si tenga presente che:
• Gli elementi possono essere più facilmente estesi in un secondo tempo
• Gli attributi NON CONTENGONO UNA STRUTTURA e non sono estensibili
• Inserendo tutte le informazioni negli attributi, si pongono dei seri limiti all’utilizzabilità dei dati e alla quantità dei dati che possono essere aggiunti al documento
• I valori degli attributi possono contenere un riferimento a un altro file

La pianificazione
<note date="12/11/2002"><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
3 alternative: il corso online di XML consiglia la terza!
Prima alternativa

La pianificazione
<note><date>12/11/2002</date><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
Seconda alternativa

La pianificazione
Terza alternativa
<note><date><day>12</day><month>11</month><year>2002</year></date><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>

La pianificazione
In alcuni casi è preferibile utilizzare gli attributi invece degli elementi. Se abbiamo ad esempio un elenco e a ogni item vogliamo assegnare un’identità numerica è consigliabile farlo attraverso gli attributi.
<messages><note id="p501"><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note><note id="p502"><to>Jane</to><from>Paul</from><heading>Re: Reminder</heading><body>I will not!</body></note> </messages>

La pianificazione
Gli attributi possono sembrare eleganti e economici, ma bisogna evitare di creare documenti che somiglino al seguente:
<note day="12" month="11" year="2002"to=”Paul" from="Jane" heading="Reminder" body="Don't forget me this weekend!"></note>

4
Namespaces e CDATA

Namespaces
Unire dati XML da diverse fonti può causare conflitti tra i nomi di elementi e attributi. Immaginiamo il caso di un elenco di CD e un elenco di libri. In entrambi ho utilizzato i tag <ITEM>, <TITLE>, <PRICE>, ecc. per riferirmi a entità differenti. Se volessi unificare in un unico documento chiamato Collection questi insiemi di dati, una eventuale applicazione non potrebbe distinguere tra libri e CD, o calcolare il prezzo medio dei CD. Per risolvere questo conflitto si può riscrivere il documento, oppure utilizzare una soluzione più comoda e meno dispendiosa, e cioè il meccanismo dello spazio dei nomi. Attraverso lo spazio dei nomi, ogni elemento di un libro è assegnato allo spazio dei nomi book, mentre ogni elemento di un CD è assegnato allo spazio dei nomi cd.
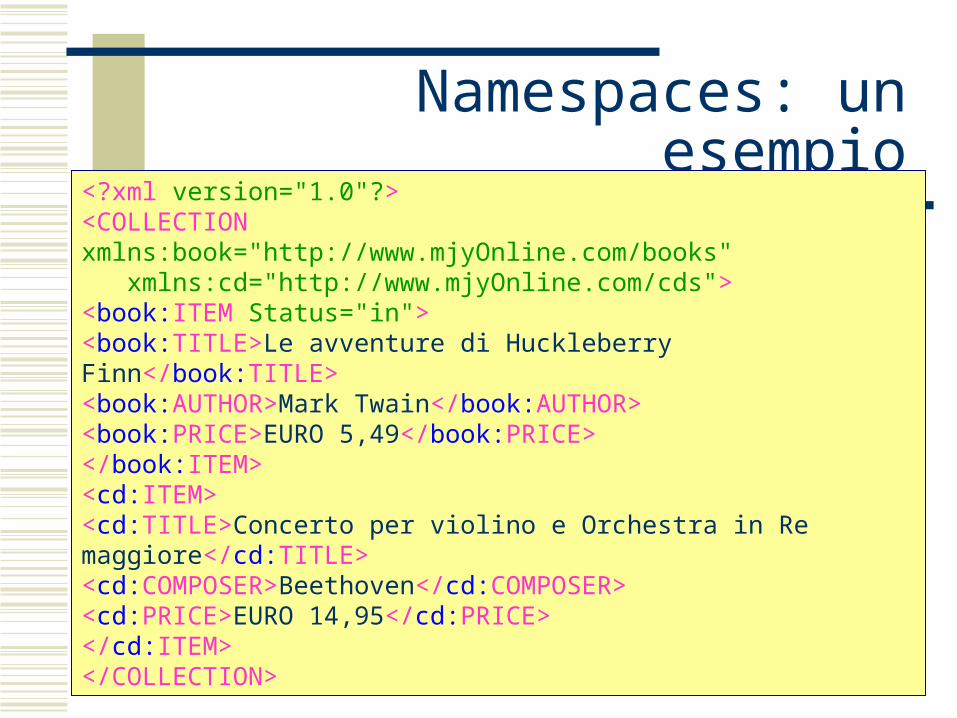
Namespaces: un esempio<?xml version="1.0"?><COLLECTION xmlns:book="http://www.mjyOnline.com/books" xmlns:cd="http://www.mjyOnline.com/cds"><book:ITEM Status="in"><book:TITLE>Le avventure di Huckleberry Finn</book:TITLE><book:AUTHOR>Mark Twain</book:AUTHOR><book:PRICE>EURO 5,49</book:PRICE></book:ITEM><cd:ITEM><cd:TITLE>Concerto per violino e Orchestra in Re maggiore</cd:TITLE><cd:COMPOSER>Beethoven</cd:COMPOSER><cd:PRICE>EURO 14,95</cd:PRICE></cd:ITEM></COLLECTION>

Namespaces
L’esempio completo
Per utilizzare uno spazio dei nomi, occorre dichiararlo all’interno del tag iniziale. Lo si fa aggiungendo un attributo speciale, che ha la sintassi seguente:
xmlns:namespace-prefix="namespace"

Namespaces
<COLLECTION xmlns:book="http://www.mjyOnline.com/books" xmlns:cd="http://www.mjyOnline.com/cds">
Lo spazio dei nomi è definito attraverso un indirizzo URI (Uniform Resource Identifier), come richiesto dalle
specifiche del consorzio W3C. L’indirizzo non è utilizzato dal parser per cercare informazioni, ma solo per
assegnare a ogni spazio dei nomi un’identità univoca.

Default Namespaces
<COLLECTION xmlns:book="http://www.mjyOnline.com/books" xmlns:cd="http://www.mjyOnline.com/cds">
<COLLECTION xmlns="http://www.mjyOnline.com/books" xmlns:cd="http://www.mjyOnline.com/cds">
Se eliminiamo uno dei prefissi (in questo caso book), vuol dire che questo spazio dei nomi è quello di default, per cui ogni nuovo inserimento di un elemento book non avrà bisogno del prefisso all’inizio del tag, mentre ogni inserimento di un nuovo CD richiede la presenza del prefisso cd:

CDATA
Se il testo contiene molti caratteri illegali, può essere opportuno evitare che il browser lo analizzi. Si può ottenere questo scopo racchiudendo il testo in questione in una sezione CDATA. Una sezione CDATA comincia con la stringa <![CDATA[ e termina con]]>.
<script><![CDATA[{if (a < b && a < 0) then {return 1} else {return 0}} ]]></script>

5
Creazione di documenti XML validi

La DTD
Finora ci siamo occupati di documenti XML ben strutturati. I documenti XML che utilizziamo devono avere qualcosa in più, e cioè devono essere validi. Un documento XML valido è un documento ben strutturato che risponde a uno dei seguenti requisiti:
• Il prologo del documento deve contenere una DTD (Document Type Definition, ossia definizione del tipo di documento) in grado di definire la struttura del documento XML, mentre la parte restante del documento deve essere conforme alla struttura definita nella DTD.
• Il documento è conforme alla struttura definita in uno schema XML compreso in un file separato.

La DTD
Quando si utilizza una DTD, si fornisce al browser una copia standard del documento, cosicchè, durante la verifica della validità del documento, questo possa garantire che il documento corrisponda agli standard richiesti. Se una qualsiasi parte del documento non è conforme alla specifica della DTD il processore visualizzerà un messaggio di errore consentendo la modifica del documento per renderlo conforme.
L’uso della DTD favorisce la coerenza all’interno del documento o tra più documenti (pertanto è fondamentale in lavori di gruppo in cui gli utenti che marcano i dati sono diversi o quando lo stesso utente lavora a uno stesso documento in due fasi diverse), e può evitare che chi immette dati aggiunga arbitrariamente nuovi elementi, collochi informazioni nell’ordine sbagliato, o assegni valori scorretti agli attributi, ecc.

La DTD
Una DTD è un blocco di tag XML che deve essere aggiunto al prologo di un documento XML valido.
Essa ha la seguente forma astratta:
<!DOCTYPE root-element DTD>
Tag standard (DOCTYPE va scritto sempre in lettere
maiuscole)
Nome dell’elemento RADICE la cui
struttura si intende
descrivere
Va sostituito con un
insieme di regole

Una DTD molto semplice
<?xml version”1.0”?>
<!DOCTYPE SIMPLE
[
<!ELEMENT SIMPLE ANY>
]
>
<SIMPLE>Questo è un documento molto semplice</SIMPLE>
La DTD di questo semplice documento
specifica che il documento può contenere solo elementi di tipo <SIMPLE>, e,
mediante la parola chiave ANY che un
elemento <SIMPLE> può avere qualsiasi
tipo di contenuto

La DTD
Una DTD può contenere, fra le altre, le seguenti dichiarazioni:
• Dichiarazioni del tipo di elementi (definiscono i tipi di elementi che posono essere contenuti in un documento, così come il contenuto e l’ordine degli elementi);
• Dichiarazioni dell’elenco di attributi (definiscono i nomi degli attributi che posono essere associati a ciascun elemento, così come i valori - liberi o predefiniti - che possono essere assegnati a questi attributi);
Un tutorial specifico sulla DTD si trova all’indirizzo:
http://www.w3schools.com/dtd/

La DTD
Dichiarazioni del tipo di elementi
<!ELEMENT TITLE (#PCDATA)>
Elemento di cui si descrive la
struttura
(#PCDATA)indica che l’elemento TITLE può contenere soltanto caratteri, senza alcun elemento annidato

La DTD
Dichiarazioni del tipo di elementi
<!DOCTYPE COLLECTION
[
<!ELEMENT COLLECTION(CD)+>
<!ELEMENT CD (#PCDATA)>
]
>
In questa DTD si specifica che l’elemento radice <COLLECTION> può contenere uno o più elementi <CD>, e che ciascun elemento <CD> può contenere solo caratteri.

La DTD
Dichiarazioni del tipo di elementi
<?xml version=“1.0”>
<!DOCTYPE COLLECTION
[<!ELEMENT COLLECTION(CD)+><!ELEMENT CD (#PCDATA)>]
>
<COLLECTION>
<CD>Concerti per violino</CD>
<CD>Concerti per tromba</CD>
</COLLECTION>
Questo documento è conforme alla DTD precedente

La DTD
Dichiarazioni del tipo di elementi
<!ELEMENT COLLECTION EMPTY> EMPTY indica che l’elemento deve essere vuoto
<!ELEMENT COLLECTION ANY>ANY indica che l’elemento può avere qualsiasi tipo di contenuto valido

La DTD
Dichiarazioni del tipo di elementi (elementi con figli)
<!DOCTYPE BOOK
[
<!ELEMENT BOOK (TITLE, AUTHOR)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT AUTHOR (#PCDATA)>
]
>
In questa DTD, si specifica che l’elemento <BOOK> contiene non caratteri ma due elementi annidati, <TITLE> e <AUTHOR>, i quali a loro volta contengono solo caratteri

La DTD
Dichiarazioni del tipo di elementi
<!ELEMENT note (message)>In questa DTD si specifica che l’elemento figlio <message> può occorrere solo una volta all’interno dell’elemento padre <note>
<!ELEMENT note (message+)>
In questa DTD si specifica che l’elemento figlio <message> deve occorrere almeno una volta all’interno dell’elemento padre <note>
<!ELEMENT note (message*)>
In questa DTD si specifica che l’elemento figlio <message> può occorrere zero o più volte all’interno dell’elemento padre <note>

La DTD
Dichiarazioni del tipo di elementi
<!ELEMENT note (message?)>In questa DTD si specifica che l’elemento figlio <message> può occorrere zero o una volta all’interno dell’elemento padre <note>
<!ELEMENT note (to,from,header,(message|body))>
In questa DTD si specifica che l’elemento <note> deve comprendere un elemento <to>, un elemento <from>, un elemento <header>, e infine, o un elemento <message> o un elemento <body>. L’ordine della DTD è quello in cui gli elementi annidati devono comparire (come indicato dall’uso delle virgole)

La DTD
Dichiarazioni del tipo di elementi
<!ELEMENT note (#PCDATA|to|from|header|message)*>
In questa DTD si specifica che l’elemento <note> può contenere caratteri, e qualsiasi numero di elementi <to>, <from>, <header>, e/o <message>.

La DTD
Dichiarazioni degli attributi (segue sempre quella dell’elemento a cui si riferisce)
<!ELEMENT FILM (STAR | NARRATOR | INSTRUCTOR)><!ATTLIST FILM Class CDATA “fiction” Year CDATA #REQUIRED>
Dichiarazione dell’elenco di
attributi
Nome dell’elemento
a cui sono associati gli
attributi
Nome dell’attributo
Tipo di attributo
Valore predefinito
Nome dell’attributo
Tipo di attributo
Status dell’attributo

La DTD
Value ExplanationCDATA The value is character data(en1|en2|..) The value must be one from an enumerated listID The value is a unique id IDREF The value is the id of another elementIDREFS The value is a list of other idsNMTOKEN The value is a valid XML nameNMTOKENS The value is a list of valid XML namesENTITY The value is an entity ENTITIES The value is a list of entitiesNOTATION The value is a name of a notationxml: The value is a predefined xml value
Il tipo di attributo può avere i valori seguenti:

La DTD
Value Explanationvalue The default value of the attribute#REQUIRED The attribute value must be included in the element#IMPLIED The attribute does not have to be included#FIXED value The attribute value is fixed
Il valore predefinito può essere espresso nei modi seguenti:

La DTD
DTD:<!ELEMENT square EMPTY><!ATTLIST square width CDATA "0">
Valid XML:<square width="100" />
Nell’esempio seguente, l’elemento <square> è un elemento vuoto con un attributo width che ha come valore una stringa di caratteri. Se non è specificato alcun valore, è assegnato il valore di default di “0”

La DTD
DTD:<!ATTLIST contact fax CDATA #IMPLIED>
Valid XML:<contact fax="555-667788" />
Valid XML:<contact />
Si utilizza #IMPLIED se non si vuole obbligare l’autore a includere l’attributo fax

La DTD
DTD:<!ATTLIST person number CDATA #REQUIRED>
Valid XML:<person number="5677" />
Invalid XML:<person />
Si utilizza #REQUIRED se non si ha a disposizione un valore predefinito, ma si vuole comunque obbligare l’autore a includere l’attributo number

La DTD
DTD:<!ATTLIST sender company CDATA #FIXED "Microsoft">
Valid XML:<sender company="Microsoft" />
Invalid XML:<sender company="W3Schools" />
Si utilizza #FIXED se non si vuole che l’autore includa un valore a piacere per un dato attributo

La DTD
Syntax:<!ATTLIST element-name attribute-name (en1|en2|..) default-value>
DTD example:<!ATTLIST payment type (check|cash) "cash">
XML example:<payment type="check" />or<payment type="cash" />
Nell’esempio seguente si dichiara che il valore dell’attributo type deve essere scelto all’interno di una lista predefinita, all’interno della quale c’è un valore di default

La DTD
<!DOCTYPE root-element SYSTEM "filename">
Con questa notazione si può accedere a una DTD esterna senza
bisogno di inserirla all’interno del documento. Questo semplifica le
cose, purchè il file (salvato in formato DTD) sia contenuto nella stessa
cartella del documento XML

La DTD
<?xml version="1.0"?><!DOCTYPE note SYSTEM "note.dtd"><note><to>Paul</to><from>Jane</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
<!ELEMENT note (to,from,heading,body)><!ELEMENT to (#PCDATA)><!ELEMENT from (#PCDATA)><!ELEMENT heading (#PCDATA)> <!ELEMENT body (#PCDATA)>
File “note.dtd”File “note.xml”

Laboratorio di analisi di risorse linguistiche
3.2.
L’annotazione dei dati linguistici: esempi e
standardizzazioni

Come annotare i dati linguistici: un problema di standardizzazione
A più riprese abbiamo detto che XML consente la massima libertà nella creazione di propri tag per etichettare qualsiasi tipo di informazione. Ovviamente, avendo a che fare con dati linguistici e ambendo alla massima riusabilità dei nostri dati, dobbiamo porci il problema dell’adeguamento a standard esistenti per la codifica di dati linguistici.
Esistono importanti iniziative che hanno come obiettivo la standardizzazione e la creazione di best practices nell’etichettatura dei dati linguistici.

Come annotare i dati linguistici: un problema di standardizzazione
La possibilità di creare DTD è la chiave di volta per raggiungere l’obiettivo della standardizzazione. La DTD è ciò che differenzia un documento XML ben formato da un documento XML valido.
Documento XML ben formato:
i tag sono sintatticamente corretti
ogni tag di apertura ha un tag di chiusura
i tag sono annidati in maniera corretta
Documento XML valido:
sono utilizzati soltanto i tag dichiarati
tutte le occorrenze dei tag sono conformi ad alcune restrizioni posizionali descritte dalla DTD.

Come annotare i dati linguistici: un problema di standardizzazione
Necessità di standardizzazione:
• gli elementi SGML (e XML) hanno una semantica leggera;
• «one man's <p> is another's <para>»;
• l’uso “libero” di XML è un rimedio ai limiti di HTML peggiore del male!
• le DTD devono essere significative all’interno di una comunità di utenti.

5 massime (Leech 1993)
• l’annotazione deve poter essere rimossa preferenza per annotazioni di tipo “stand-off” (v. oltre);
• le informazioni relative allo schema di annotazione devono essere messe a disposizione dell’utente;
• deve essere sempre chiaro chi e come ha annotato il testo (numero di annotatori, tecnica di annotazione – manuale, automatica, mista, …);
• l’utente deve essere consapevole che l’annotazione non è infallibile, e che è soltanto un utile strumento di lavoro;
• lo schema di annotazione deve essere basato su procedure quanto più possibile condivise.

Come annotare i dati linguistici: un problema di standardizzazione
Text Encoding Initiative: http://www.tei-c.org/
Dalla pagina web:
«Initially launched in 1987, the TEI is an international and interdisciplinary standard that helps libraries, museums, publishers, and individual scholars represent all kinds of literary and linguistic texts for online research and teaching, using an encoding scheme that is maximally expressive and minimally obsolescent»
Una presentazione online su “Encoding a language corpus”:
http://www.tei-c.org/Talks/ESS2001/index.html

Come annotare i dati linguistici: un problema di standardizzazione
Goals of the TEI
• better interchange and integration of scholarly data
• support for all texts, in all languages, from all periods
• guidance for the perplexed: what to encode --- hence, a user-driven codification of existing best practice
• assistance for the specialist: how to encode --- hence, a loose framework into which unpredictable extensions can be fitted

Come annotare i dati linguistici: un problema di standardizzazione
Scopo della TEI: creare delle DTD standard per la codifica dei testi; queste DTD devono essere il più possibile modulari, in modo da minimizzare lo sforzo e massimizzare l’applicabilità ai dati reali.

Come annotare i dati linguistici: un problema di standardizzazione
Il protocollo TEI indica dei tag standard per le seguenti entità che sono comuni in ogni tipo di testo:
• paragraphs
• highlighted phrases
• names, dates, number, abbreviations...
• editorial tags
• notes, cross-references, bibliography
• verse and drama

Come annotare i dati linguistici: un problema di standardizzazione
Il protocollo TEI indica poi dei tag aggiuntivi per le seguenti entità che sono da marcare solo se lo si ritiene necessario:
• linking and alignment; analysis; feature structures;
• certainty; physical transcription; textual criticism,
• names and dates; graphs and trees; figures and tables;







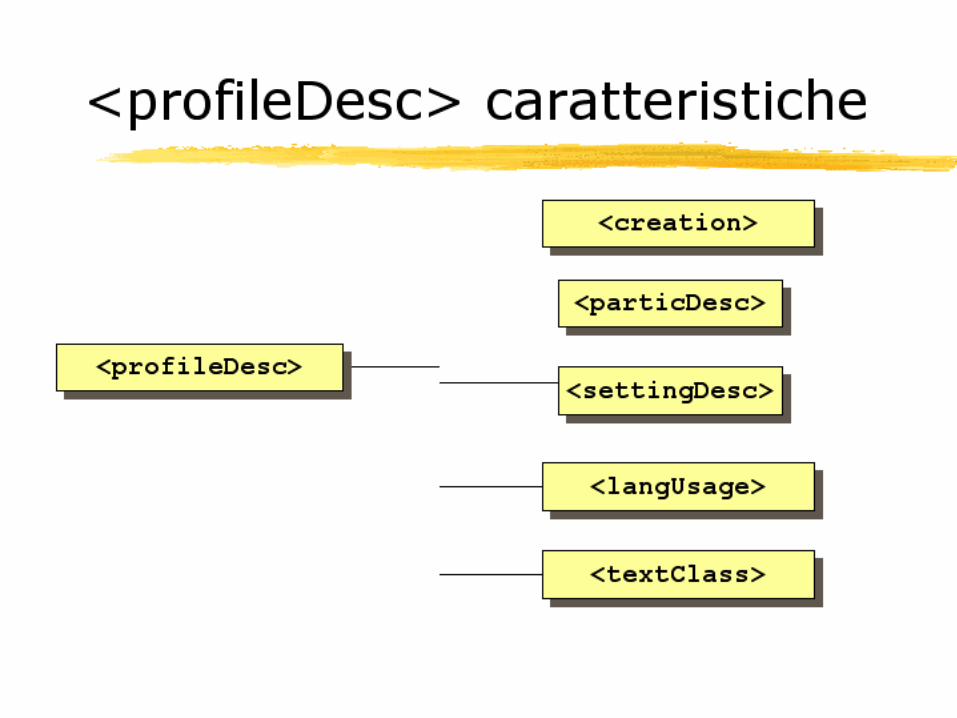




TEI: nozioni generali
The TEI encoding scheme consists of a number of modules or DTD fragments (tag sets).Selected tag sets may be combined in many different ways, according to some principles, within the framework of the TEI main DTD.

TEI: nozioni generali
Core tag sets: standard components of the TEI main DTD in all its forms; these are always included without any special action by the encoder; Base tag sets: basic building blocks for specific text types; exactly one base must be selected by the encoder Additional tag sets: extra tags useful for particular purposes. All additional tag sets are compatible with all bases and with each other; an encoder may therefore add them to the selected base in any combination desired.

TEI: nozioni generali
Se si sceglie un tag set di base per marcare un documento, lo si dichiara nella DTD del documento tramite il riferimento a un’entità predefinita dal consorzio TEI:
<!ENTITY % TEI.prose 'INCLUDE' >

TEI: nozioni generali
Altri tag sets di base:
TEI.prose selects the base tag set for prose, contained in teipros2.dtd. TEI.verse selects the base tag set for verse, contained in teivers2.dtd and teivers2.ent. TEI.drama selects the base tag set for drama, contained in teidram2.dtd and teidram2.ent. TEI.spoken selects the base tag set for transcriptions of spoken texts, contained in teispok2.dtd and teispok2.ent. TEI.mixed selects the base tag set for free mixed-mode texts, contained in teimix2.dtd.

TEI: nozioni generali
Tag sets aggiuntivi:
TEI.linking with tags for linking, segmentation, and alignment TEI.analysis with tags for simple analytic mechanisms TEI.fs with tags for feature structure analysis TEI.certainty with tags for indicating uncertainty and probability in the markup TEI.transcr with tags for manuscripts, analytic bibliography, and transcription of primary sources
Questi tag sets possono essere evocati esattamente allo stesso modo, e sono legati a specifiche esigenze di chi marca
il testo

TEI: nozioni generali
Un semplice documento TEI deve cominciare con una DTD. La versione più semplice della DTD TEI cita il file .dtd TEI come file esterno, e specifica un singolo tag set di base da utilizzare nel documento. Ad esempio, un documento che utilizza il tag set per la prosa comincia con una DTD come la seguente:
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4//DTD Main Document Type//EN" "tei2.dtd" [<!ENTITY % TEI.XML 'INCLUDE' ><!ENTITY % TEI.prose 'INCLUDE' > ]>

TEI: nozioni generali
Nel caso di documenti misti (es. prosa e versi), si può voler includere più tag sets. In questo caso si utilizza la seguente DTD:
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4//DTD Main Document Type//EN" "tei2.dtd" [<!ENTITY % TEI.XML 'INCLUDE' ><!ENTITY % TEI.mixed 'INCLUDE' ><!ENTITY % TEI.prose 'INCLUDE' ><!ENTITY % TEI.verse 'INCLUDE' >]>

TEI: nozioni generali
Oppure la seguente:
<!DOCTYPE TEI.2 PUBLIC "-//TEI P4//DTD Main Document Type//EN" "tei2.dtd" [<!ENTITY % TEI.XML 'INCLUDE' ><!ENTITY % TEI.general 'INCLUDE' ><!ENTITY % TEI.prose 'INCLUDE' ><!ENTITY % TEI.verse 'INCLUDE' >]>
La differenza consiste nel fatto che con questa DTD (che invoca l’entità TEI.general) ogni divisione del testo può usare uno ed un solo tag set di base (o prosa o versi)

TEI: nozioni generali
Attributi globali (e cioè attributi che sono validi per ogni elemento di un documento TEI)
id provides a unique identifier for the element bearing the ID value.Values: any valid name.Default: #IMPLIED
ngives a number (or other label) for an element, which is not necessarily unique within the document.Values: any string of characters; often, but not necessarily, numeric.Default: #IMPLIED

TEI: nozioni generali
Attributi globali (e cioè attributi che sono validi per ogni elemento di un documento TEI)
langindicates the language of the element content, usually using a two- or three-letter code from ISO 639.Values: The value must be the identifier of a <language> element supplied in the TEI Header of the current document; Default: %INHERITED.

TEI: nozioni generali
Attributi globali (e cioè attributi che sono validi per ogni elemento di un documento TEI)
TEIformindicates the standard TEI name (generic identifier) for a given element.Values: must be a valid name; by default, the canonical name of this element as defined in the TEI Guidelines.Default: #IMPLIEDExample: <fn TEIform="note">This is a footnote; its tag uses a non-standard name defined by the user; the attribute TEIform indicates thatthe normal TEI name for the element is NOTE.</fn>

TEI: nozioni generali
Ogni elemento di un documento conforme alle specifiche TEI può avere gli attributi precedenti!
Quanto all’attributo lang, le Guidelines TEI raccomandano che ogni “cambio” di lingua in un testo sia segnalato esplicitamente.
<p lang="en">The constitution declares <q>that no bill of attainder or <term lang="la">ex post facto</term> law shall be passed.</q> ... </p>

TEI: nozioni generali
La DTD TEI definisce oltre 400 tipi di elementi. Questi sono raggruppati in classi per quanto possibile, in modo da facilitare la comprensione. Gli elementi appartenenti a una classe possono avere in comune un set di attributi.

TEI: alcuni elementi
<text> contains a single text of any kind, whether unitary or composite. <front> contains any prefatory matter (headers, title page, prefaces, dedications, etc.) found at the start of a document, before the main body.<body> contains the whole body of a single unitary text, excluding any front or back matter.<group> contains the body of a composite text, grouping together a sequence of distinct texts (or groups of such texts) which are regarded as a unit for some purpose, for example the collected works of an author, etc.<back> contains any appendixes, etc. following the main part of a text.

TEI: alcuni elementi
Tutte le suddivisioni testuali, secondo lo standard TEI devono essere considerate come occorrenze dello stesso elemento “neutro”, con un attributo “type”.
<div> contains a subdivision of the front, body, or back of a text.Attributes: those globally available; this element has the following additional attribute: type: specifies a name conventionally used for this level of subdivision, e.g. act, volume, book, section, canto, etc.Values: any string of charactersDefault: #IMPLIED

La codifica del dialogo:MATE
http://mate.nis.sdu.dk/
Progetto Europeo (9 partners), con l’obiettivo di facilitare la riusabilità delle risorse linguistiche e di proporre standard per l’annotazione linguistica a più livelli. Approccio multi-lingual e focus su multi-level issues.
Breve presentazione:
http://mate.nis.sdu.dk/about/lux-slides2-13/sld001.htm
Guidelines scaricabili:
http://www.ims.uni-stuttgart.de/projekte/mate/mdag/

La codifica del dialogo:MATE
Annotazione del dialogo, ma NON SONO ESCLUSE APPLICAZIONI DEGLI STANDARD MATE AD ALTRI TIPI DI TESTO.
Livelli considerati:
• Prosodia
• Morfosintassi
• Atti dialogici
• Coreferenza
• Problemi di comunicazione
• Cross-level issues

La codifica del dialogo:MATE
Livello morfosintattico (V. Pirrelli & C. Soria)
“Word analysis, chunking and representation of syntactic functional relations” più “guidelines to the edited transcription of a dialogue” “Conceptually independent, though inter-connected sub-levels of morpho-syntactic analysis”
“not intended to give instructions for marking up an exhaustive list of language-specific facts: … we do not provide language-specific recommendations concerning problems of segmentation due to fusional phenomena or truncated stems, as in provide provision or truncate truncation”.

La codifica del dialogo:MATE
Livello morfosintattico (V. Pirrelli & C. Soria)
Parola chiave: MODULARITÀ
“For all sub-levels of annotation considered here, the meta-scheme consists of two subsets of tags. The first subset, or core scheme, supplies basic means for annotating obligatory information. The second subset, or periphery tag set, serves the purpose of making provision for further linguistic annotation to be added on top of obligatory information, whenever this is required by the annotator. In its turn, the periphery tag set parts into two further subsets: a recommended set and an optional one. This makes the meta-scheme highly modular, and open to further augmentation, both in terms of more granular information and of further independent dimensions of analysis.”

La codifica del dialogo:MATE
Livello morfosintattico (V. Pirrelli & C. Soria)
Sottolivelli:
• Edited transcription level
• Morphological word-level
• Chunk level
• Functional level
Per ogni livello sono forniti un esempio di annotazione (dello stesso testo di base) e una DTD

La codifica del dialogo:MATE
Edited transcription level
Elementi (in relazione gerarchica) che marcano speech repairs:
<seg><dys>
<repair><reparandum><signal>

La codifica del dialogo:MATE
Edited transcription level
<seg> è un elemento generico che marca ogni porzione non fluente di un dialogo e le possibili riformulazioni (se presenti); la porzione non fluente del testo marcata con <seg> viene ignorata dai successivi livelli morfologico e sintattico.
Bisogna distinguere due tipi di materiale non fluente: i) materiale che viene riformulato dal parlante all’interno del testo (ripetizioni, riformulazioni, false partenze, ecc.); ii) materiale non fluente che non viene riformulato., e per il quale l’annotatore può voler segnalare una forma target standard.

La codifica del dialogo:MATE
Edited transcription level
<seg> marca inoltre tutte le forme non-standard, e, possibilmente, fornisce un’indicazione della forma standard target.Inoltre, <seg> marca anche le parole necessarie omesse nel dialogo, come nell’esempio seguente:
oh she was shouting at him at dinner time Steven oh god dinner time she was shouting him

La codifica del dialogo:MATE
Edited transcription level
<seg> marca anche enunciati incompleti (e cioè sia spezzati tra due turni dello stesso interlocutore sia completati da un altro interlocutore)
A: so after the tower B: yeah A: I go straight ahead A: if Bill had known B: he would have come

La codifica del dialogo:MATE
Edited transcription level
<seg> marca infine anche sequenze dette retrace-and-repair sia con auto-correzione che senza. In questo caso entrambi i segmenti sono marcati da <seg>; il primo è segnalato come l’elemento interrotto e il secondo come l’elemento target.
I wanted I wanted to invite Margie
I wanted uh I thought I wanted to invite Margie
All of my friends had uh we had decided to go home for lunch

La codifica del dialogo:MATE
Edited transcription level
Attributi dell’elemento <seg>:
id: a unique identifier type: whether the annotated segment is interrupted, or contains a non-standard form, or is followed by an omission, or elseis a completion of a previously interrupted sequence rep (mnemonic for "replace"): a place for providing indication of the target form when the annotated segment contains anon-standard form ins (mnemonic for "insert"): a place for providing indication of the missing form when the annotated segment contains a gap. href: a sequence of <w> identifiers.

La codifica del dialogo:MATE
Valori dell’attributo type
broken segnala che la porzione marcata con <seg> è una porzione interrotta di testoEsempio: [I wanted]broken I wanted to invite Margie sic segnala che la porzione marcata da <seg> è un elemento non standardEsempio: the dog is [eat]sic gap segnala che la porzione marcata con <seg> contiene del materiale omessoEsempio: go in the sitting room until I [shout you]gap for tea

La codifica del dialogo:MATE
Valori dell’attributo type
scomp segnala che il parlante stesso completa un’interruzioneEsempio: A: [I'll do it if]broken B: Yeah A: [you wish]scomp
ocomp segnala che è un altro interlocutore a completare l’enunciatoEsempio:A: [if Bill had known]broken B: [he would have come]ocomp

La codifica del dialogo:MATE
Valori dell’attributo rep
Questo attributo consente all’annotatore di segnalare la forma target standard. Perché questo attributo sia praticabile, l’attributo type della porzione marcata con <seg> deve avere il valore sic.

La codifica del dialogo:MATE
Valori dell’attributo ins
Questo attributo ha come valore una stringa che segnala la categoria grammaticale della forma mancante. Se è invece possibile stabilire con certezza qual è la parola mancante, si utilizza un elemento figlio dell’elemento <seg>.
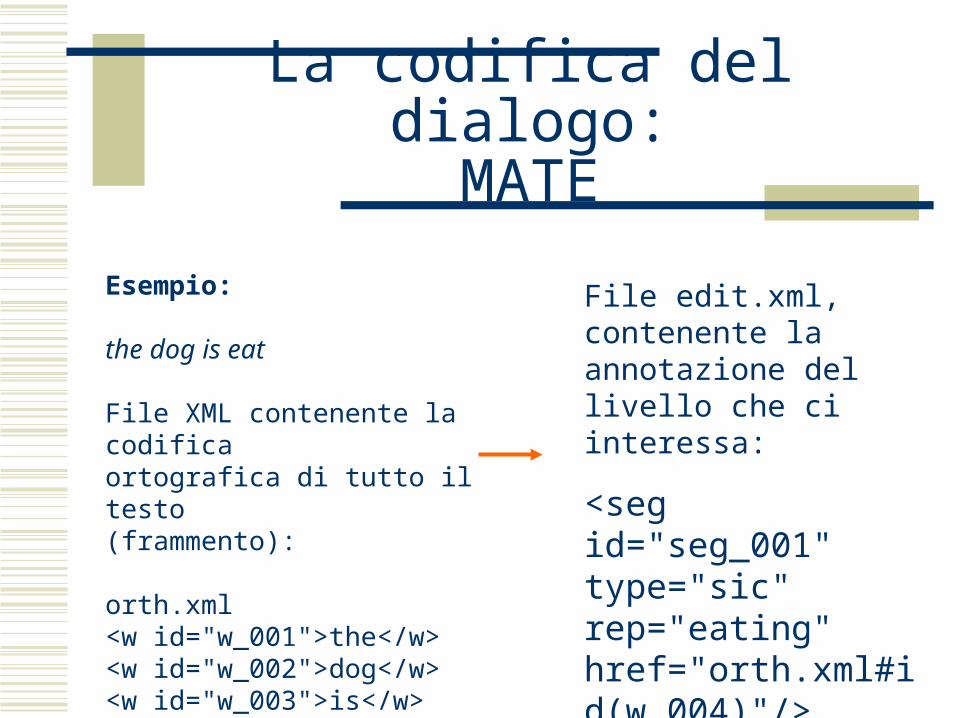
La codifica del dialogo:MATE
Esempio:
the dog is eat
File XML contenente la codifica ortografica di tutto il testo (frammento):
orth.xml<w id="w_001">the</w> <w id="w_002">dog</w> <w id="w_003">is</w> <w id="w_004">eat</w>
File edit.xml, contenente la annotazione del livello che ci interessa:
<seg id="seg_001" type="sic" rep="eating" href="orth.xml#id(w_004)"/>

La codifica del dialogo:MATE
Esempio:
go in the sitting room until I shout you for tea
File XML
<w id="w_001">go</w> <w id="w_002">in</w> <w id="w_003">the</w> <w id="w_004">sitting</w> <w id="w_005">room</w> <w id="w_006">until</w> <w id="w_007">I</w> <w id="w_008">shout</w> <w id="w_009">you</w> <w id="w_010">for</w> <w id="w_011">tea</w>
File edit.xml, contenente la annotazione del livello che ci interessa:
<seg id="seg_001" type="gap" href="orth.xml#id(w_008)..id(w_009)">at</seg>

Standards
XML Corpus Encoding Standard (XCES):
http://www.cs.vassar.edu/CES/
Standard utilizzato per l’American National Corpus (http://americannationalcorpus.org/FirstRelease; N. Ide, K. Suderman), un progetto mirato a creare, per l’inglese americano, una risorsa pari per mole al British National Corpus: 11 milioni di parole (3 milioni di parole di parlato; 8 milioni di parole di scritto).

Standards
XML Corpus Encoding Standard (XCES):
• Annotazione stand-off: il collegamento tra i documenti è conforme alle specifiche del linguaggio XPointer proposte dal consorzio W3.
<p id="p3"><s id="p3s1">
Ireland has been inhabited since very ancient times, but Irish history really
begins with the arrival of the Celts around the 6th century b.c.</s>
<chunk type="sentence" xml:base="#p3s1">
<tok xlink:href="xpointer(string-range('',0,7))"><msd>np++++</msd><base>ireland</base></tok>
<tok xlink:href="xpointer(string-range('',8,11))"><msd>vbz+hvz+aux++</msd><base>have</base></tok>
<tok xlink:href="xpointer(string-range('',12,16))"><msd>vprf+ben+aux+xvbnx+</msd><base>be</base></tok>


















