
Java/Scala Lab 2016. Александр Конопко: Машинное обучение в Spark.
25
MACHINE LEARNING WITH APACHE SPARK
Transcript of Java/Scala Lab 2016. Александр Конопко: Машинное обучение в Spark.

MACHINE LEARNING WITH APACHE SPARK
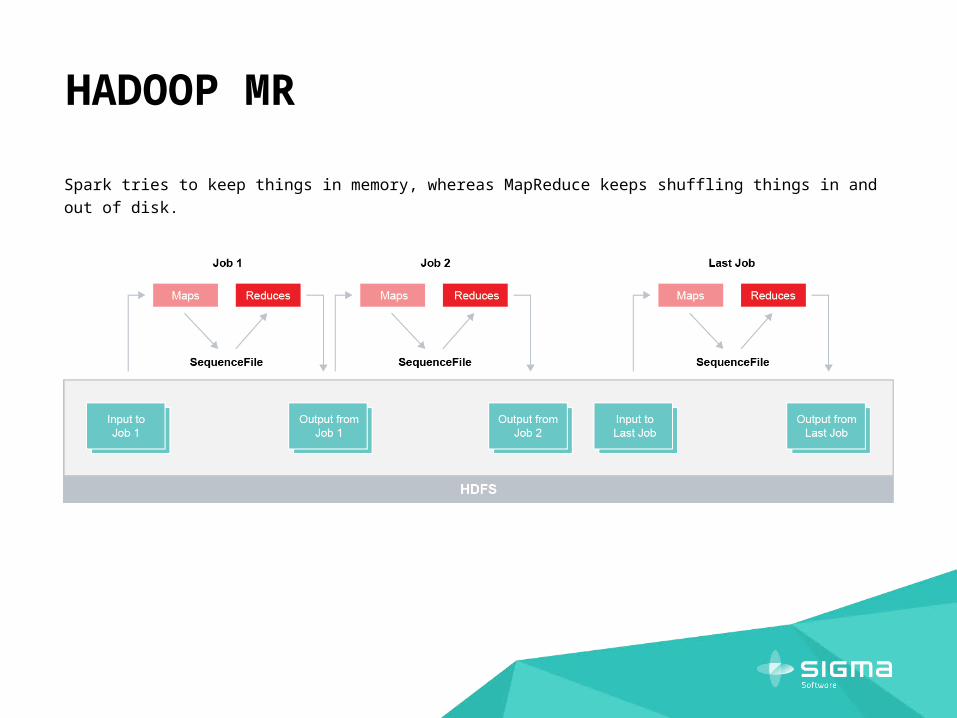
HADOOP MR
Spark tries to keep things in memory, whereas MapReduce keeps shuffling things in and out of disk.

Spark is much faster and more convenient that Hadoop• Caches data in memory• Pipelines calculations through RDDs with optional caching• Organizes calculations with DAG• Provides user-friendly Scala, Python and Java APIs• Gives a number of useful Spark libs: GraphX, MLib etc
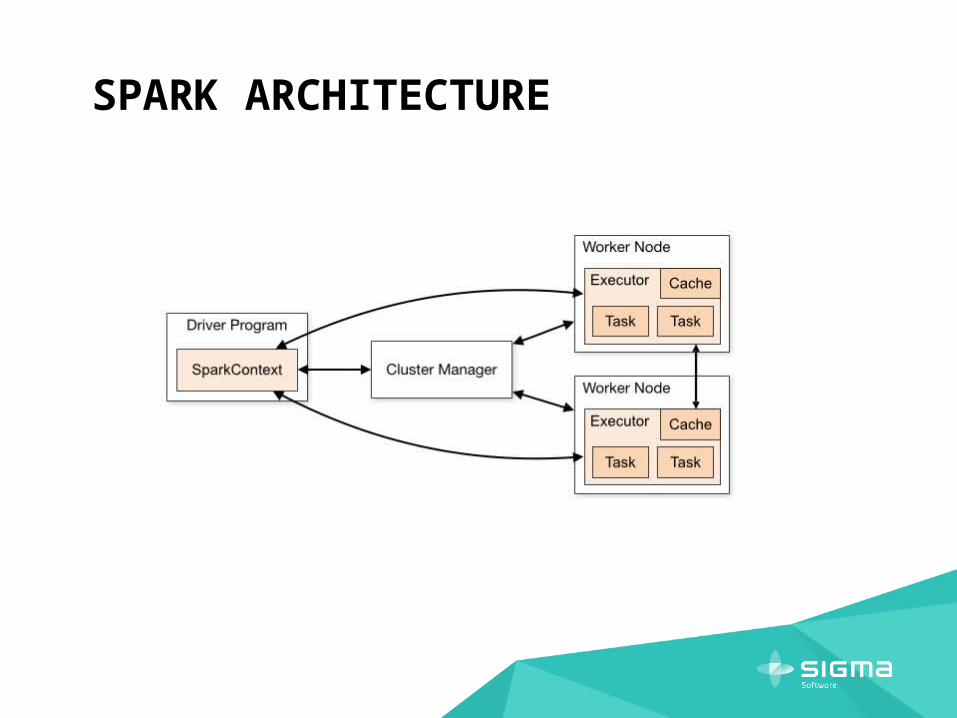
SPARK ARCHITECTURE

SPARK GENERAL FLOW
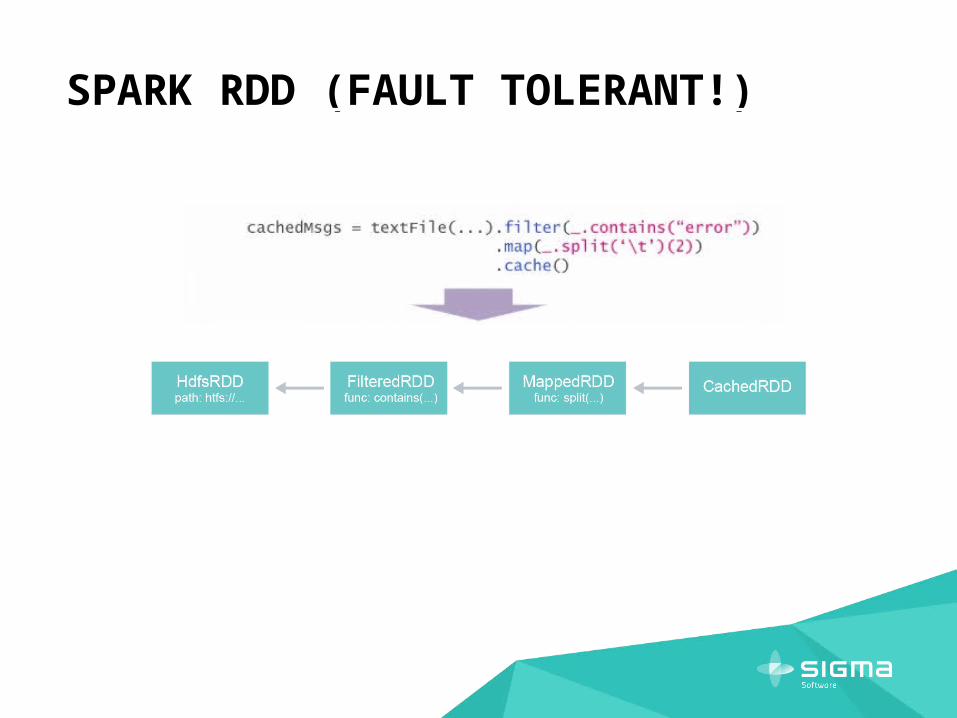
SPARK RDD (FAULT TOLERANT!)
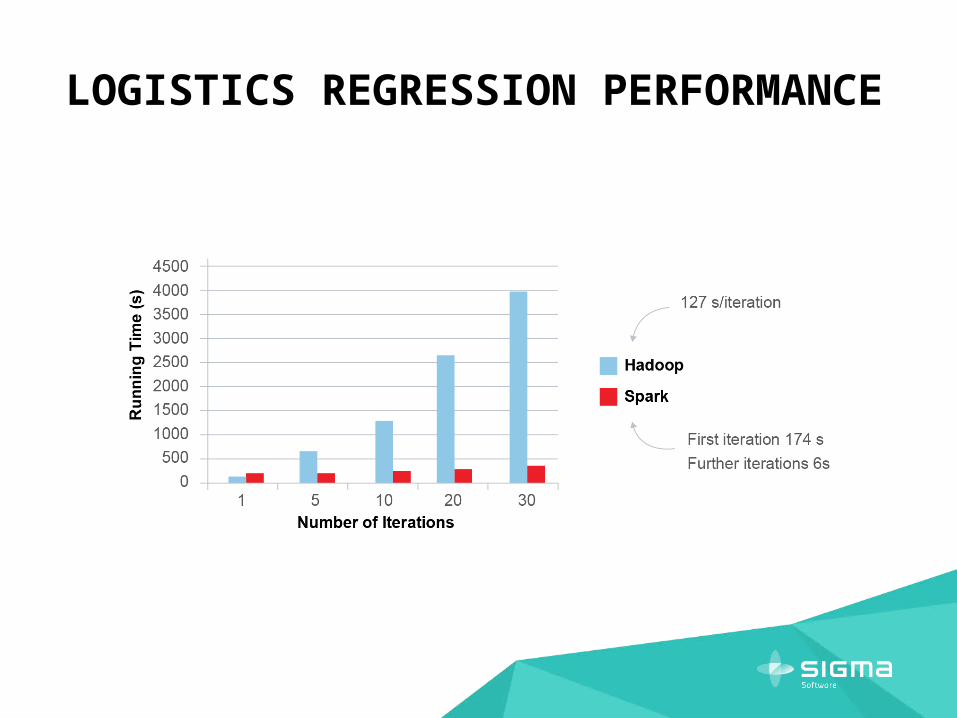
LOGISTICS REGRESSION PERFORMANCE

WORDCOUNT WITH HADOOP

WORDCOUNT WITH SPARK
It’s easier to develop for Spark.
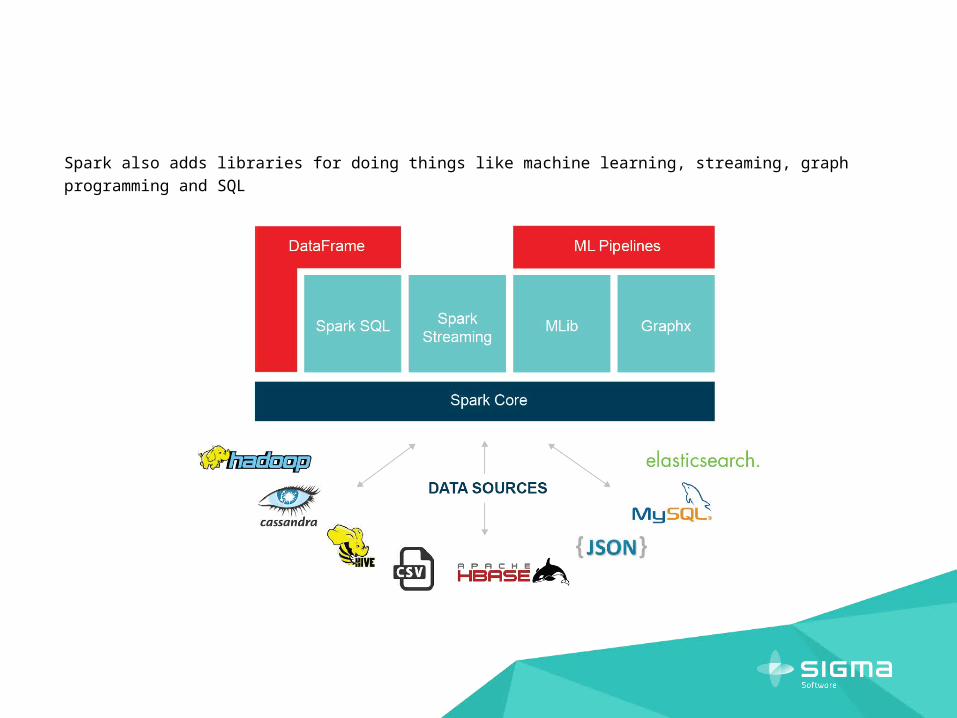
Spark also adds libraries for doing things like machine learning, streaming, graph programming and SQL

SOME ACTIONS AND TRANSFORMATIONS
map(func)flatMap(func)froupByKey()reduceByKey(func)mapValues(func)sample(…)union(other)distinct()sortByKey()..
reduce(func)collect()count()first()take(n)saveAsTextFile(path)countByKey()foreach(func)…

SPARK STREAMING
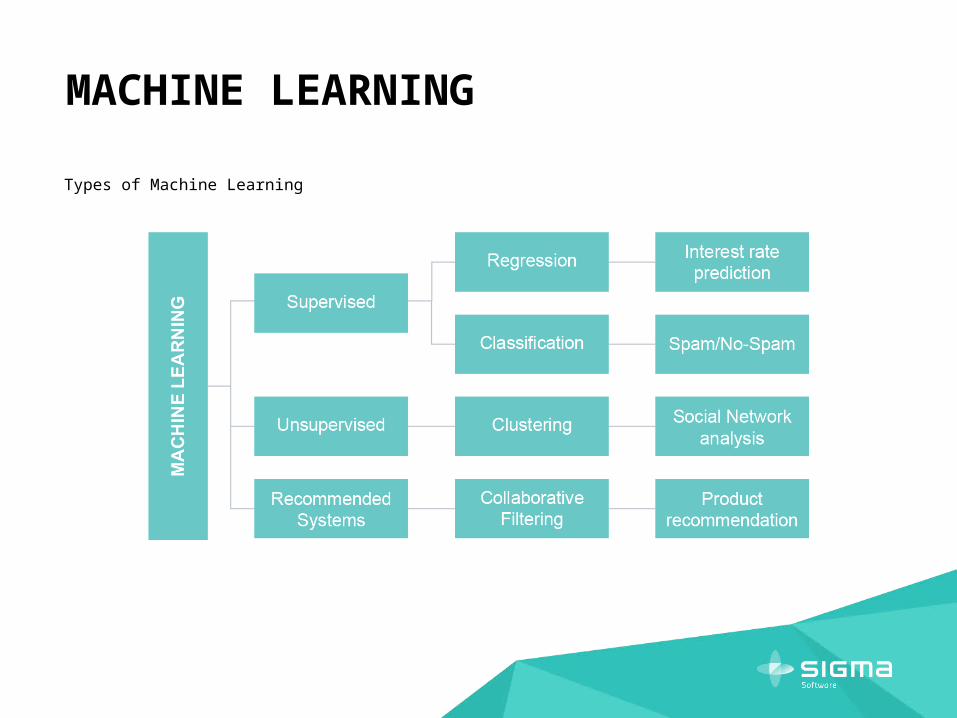
MACHINE LEARNING
Types of Machine Learning

ALS Algorithm

ALS MODEL AND ALGORITHM
Model Ratings as product of User (A) and Movie Feature (B) matrices of size UxK and MxK
Alternating Least Squares (ALS)• Start with random A nd B vectors• Optimize user vectors (A) based on campaigns• Optimize campaign vectors (B) based on users• Repeat until converged

ALS ALGORITHM

CREATE INPUT RDDs

SPLIT INTO TRAINING,VALIDATION AND TEST DATASETS
FIND OUT OPTIMAL RANK ANDNUMBER OF ITERATIONS

RMSE (ROOT MEAN SQUARE ERROR)CALCULATION METHOD
EVALUATE THE BEST MODELON THE TEST SET

CREATE A NAIVE BASELINE AND COMPARE IT WITH THE BEST MODEL
OUTPUT

RECOMMEND SOME NEW PRODUCTS FOR USER WITH ID #150
AND SOME OUTPUT...

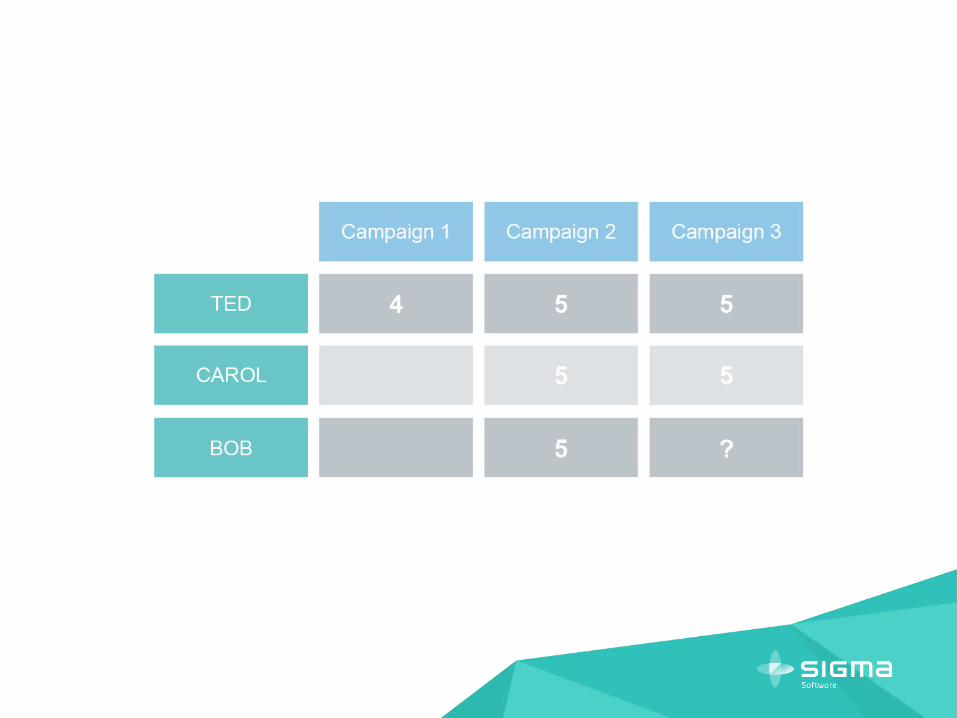
USER ALREADY REACTED ON SOME CAMPAIGNS

USE THIS INFORMATION FOR PREDICTION
AND SOME OUTPUT...

Q&A


















