これからのコンピューティングとJava(Hacker Tackle)
76
これからの コンピューティングの変化と Java 2015/9/26 きしだ なおき Hacker Tackle
Transcript of これからのコンピューティングとJava(Hacker Tackle)

これからのコンピューティングの変化と
Java
2015/9/26 きしだ なおき
Hacker Tackle

自己紹介● 最近ガッチャマンクラウズを見ました。

今日の話● ハードウェアが変わっていく● Javaも変わらないとね

最近こんな経験ありますか?● サーバーが遅いから速いCPUが載ったマシンに
買い換えよう

最近こんな経験ありますか?● サーバーが遅いからサーバーを増やそう

最近こんな経験ありますか?● サーバーが遅いからデータベースをメモリに
キャッシュしよう

処理を速くするには● 並列度をあげる● より近いところにデータを置く
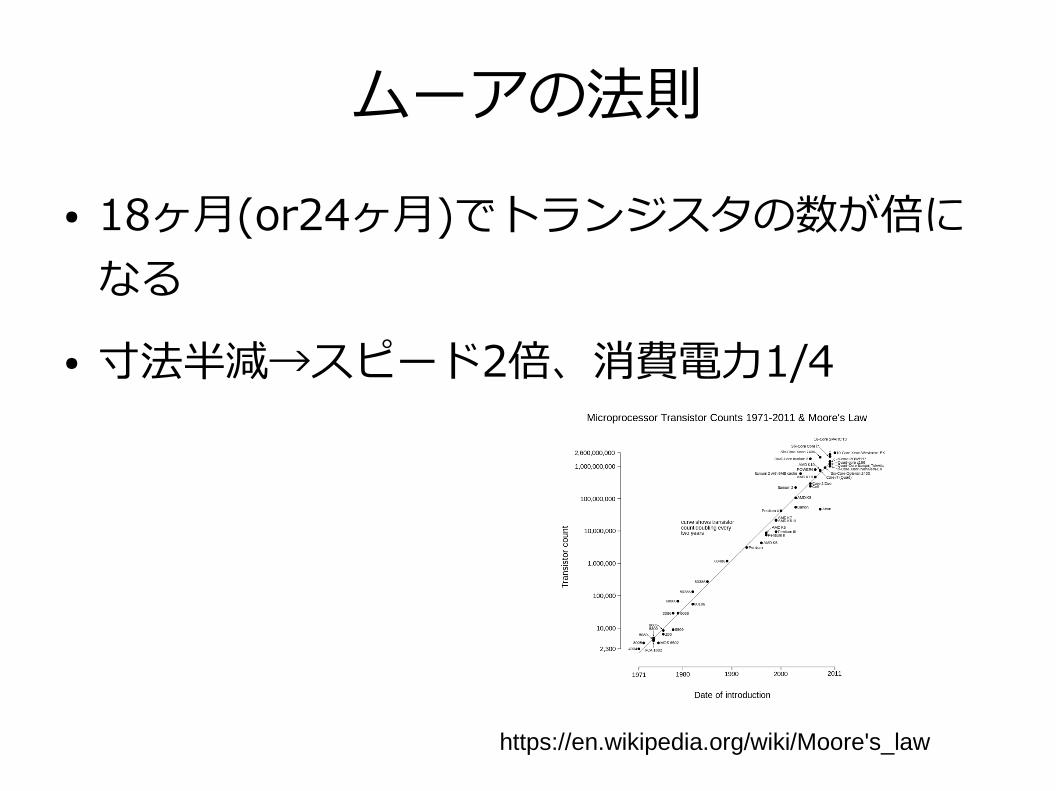
ムーアの法則● 18ヶ月(or24ヶ月)でトランジスタの数が倍に
なる● 寸法半減→スピード2倍、消費電力1/4
https://en.wikipedia.org/wiki/Moore's_law

ムーアの法則の終焉● 物理的に配置できない
– 5nm=水素原子50個分● 電子が漏洩する● 歩留まりがあがらない
– 製造コスト増

微細化が進んでも今までとは違う● コストが下がらない● 低消費電力と高速化を同時に実現できない

データ・セントリック・システム● データの移動に電力や時間が食われている
– ストレージ→メインメモリ→キャッシュ● データの移動を減らす必要がある● データの近くで処理を行う● 処理を行うのはCPUだけではなくなる

コンピュータの種類● ノイマン型アーキテクチャ● 非ノイマン型アーキテクチャ

ノイマン型アーキテクチャ● メモリから命令をよびだして、命令にしたがっ
た回路で処理を行う● CPU● GPU

CPU● 高機能・高性能・高粒度● 割り込み、権限制御、仮想化、など実行以外の機能● OSが実行できる● 演算器はコアあたり10個程度
– 一チップに100個程度● 明示的にメモリを制御できない
– いかにキャッシュに載せるか● = いかにメモリをまとめて扱うか

GPU● GPU
– ちょうたくさんコアがある– 同じ処理を行う– 行列計算に向いてる
● GTX 970
– 1664コア!– 衝動買い!

GPUの構成● いくつかのコアでグループを作る
– 同時に同じ命令を実行する– グループだけからアクセスできるメモリをもつ
● コアのグループが多数ある● コアあたり数個の演算器
– 数千から数万の演算器

非ノイマン型アーキテクチャ● ノイマン型じゃないコンピュータ全体
– FPGA– ニューラルネット型コンピュータ– 量子コンピュータ

FPGA● Field Programmable Gate Array
– Field 現場で– Programmable プログラム可能な– Gate 論理素子が– Array いっぱい並んだやつ
● 現場でプログラムできる論理回路

回路の入出力の組み合わせ
入力 出力
000 0
100 0
010 0
110 1
001 1
101 1
011 1
111 1

LUT(LookUp Table)● 入出力をあらかじめメモリにもっておく● 製品としては4入力LUTや6入力LUT
入力 出力
000 0
100 0
010 0
110 1
001 1
101 1
011 1
111 1

論理ブロック
● Logical Element(LE) Altera● Logical Cell(LC) Xilinx

配線
● 論理ブロックが格子状に配置● 周囲に配線● アイランドスタイル

乗算回路とメモリ● 乗算やメモリを論理ブロックの組み合わせで
実現すると効率がわるい● 乗算回路やメモリ(SRAM)がのってる
– 演算器は数百から数千

FPGAの構成

FPGAなら● 命令を読み込む必要なく、回路をやりたい処
理のとおり並べることができる

FPGAの利点● 命令を読み込む必要がない
– 処理を行うまでのタイムラグが少ない● 低レイテンシ
– 命令解析のための回路が不要● 余分な回路がないので低消費電力
● 細かな並列化

Javaでいろいろやってみる● JavaでCPU(並列)● JavaでGPU● JavaでFPGA

JavaでCPU(並列)● Stream
int elementCount = 1_444_477;float[] inputA = new float[elementCount];float[] inputB = new float[elementCount];float[] output = new float[elementCount];IntStream.range(0, elementCount).parallel().forEach(i -> { output[i] = inputA[i] * inputB[i];});

JavaでGPU● Aparapi
– JavaコードをOpenCLに変換● OpenCLを呼び出す
– OpenCL:並列計算フレームワーク● AMD始め、IntelやNVIDIAなどが参加
– JOCL(jogamp.org)– JOCL(jocl.org)– JavaCL
● Project Sumatra– Stream処理を自動的にGPUで行う– Java VMに組み込む

Aparapi● A PARalell API● 実行時にJavaコードをOpenCLに変換● https://code.google.com/p/aparapi/

Aparapiコードpublic class AparapiKernel extends Kernel{ float[] inputA; float[] inputB; float[] output; @Override public void run() { int gid = getGlobalId(); output[gid] = inputA[gid] * inputB[gid]; } public static void main(String[] args) { AparapiKernel kernel = new AparapiKernel(); int elementCount = 1_444_477; kernel.inputA = new float[elementCount]; kernel.inputB = new float[elementCount]; kernel.output = new float[elementCount]; fillBuffer(kernel.inputA); fillBuffer(kernel.inputB); kernel.execute(elementCount); }}

バグがある・・・• 三項演算子のカッコが反映されない
– (修正してプルリクなげてとりこまれてます)• CPUとの結果と比較するテストを用意したほうがいい
– けど、丸めの違いを考慮するの面倒
void proc(int fxy) { float d = (result[fxy] >= 0 ? 1 : 0) * delta[fxy]; tempBiasDelta[fxy] = learningRate * d;}
void kishida_cnn_kernels_ConvolutionBackwordBiasKernel__proc(This *this, int fxy){ float d = (float)(this->result[fxy]>=0.0f)?1:0 * this->delta[fxy]; this->tempBiasDelta[fxy] = this->learningRate * d; return;}
↓

JOCL(jogamp.org)● OpenCLを薄くラップ● https://jogamp.org/jocl/www/

JOCLのコード String KERNEL_CODE = "kernel void add(global const float* inputA," + " global const float* inputB," + " global float* output," + " uint numElements){" + " size_t gid = get_global_id(0);" + " if(gid >= numElements){" + " return;" + " }" + " output[gid] = inputA[gid] + inputB[gid];" + "}"; CLContext ctx = CLContext.create(); CLDevice device = ctx.getMaxFlopsDevice(); CLCommandQueue queue = device.createCommandQueue(); CLProgram program = ctx.createProgram(KERNEL_CODE).build();
int elementCount = 1_444_477; int localWorkSize = Math.min(device.getMaxWorkGroupSize(), 256); int globalWorkSize = ((elementCount + localWorkSize - 1) / localWorkSize) * localWorkSize; CLBuffer<FloatBuffer> clBufferA = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_ONLY); CLBuffer<FloatBuffer> clBufferB = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_ONLY); CLBuffer<FloatBuffer> clBufferC = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_WRITE);
fillBuffer(clBufferA.getBuffer()); fillBuffer(clBufferB.getBuffer());
CLKernel kernel = program.createCLKernel("add"); kernel .putArgs(clBufferA, clBufferB, clBufferC) .putArg(elementCount);
queue.putWriteBuffer(clBufferA, false) .putWriteBuffer(clBufferB, false) .put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize) .putReadBuffer(clBufferC, true);

比較● Aparapi
– めちゃ楽– GPUの性能出しにくい
● JOCL– ちょっと面倒– GPUの性能出しやすい
ところでディープラーニング実装してみました
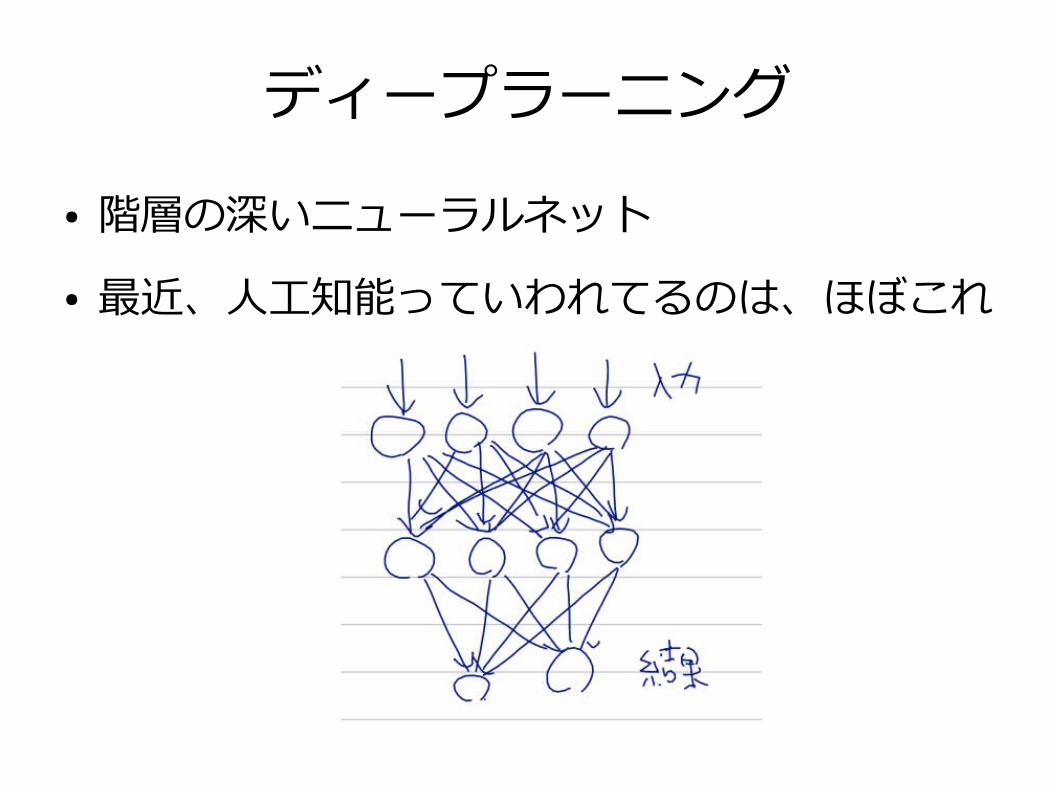
ディープラーニング● 階層の深いニューラルネット● 最近、人工知能っていわれてるのは、ほぼこれ

Aparapiを使う● 15枚/分→90枚/分● 1400万枚の画像処理が600日→100日!

JOCLを使う● 90枚/分→298枚/分● 1400万枚の画像処理が100日→34日!

GPUローカルメモリを使う● 298枚/分→300枚/分● 1400万枚の画像処理が34日→33日

FPGAでやったら?● Microsoftの実装
– GPUの半分のスループット– 1/10の消費電力– 電力あたりの性能は3倍– http://techon.nikkeibp.co.jp/article/MAG/20150311/408682/

Sumatra● Java VMに組み込むことを目標● 実装難しそう● コード書くのもわかりにくそう● 性能出しにくそう● Java VMに組み込むほどメリットなさそう
– 性能欲しい人はOpenCL使うよね

と思ったら● 「Sumatra is not in active development for
now.(2015/5/1) 」
http://mail.openjdk.java.net/pipermail/sumatra-dev/2015-May/000310.html

JavaでFPGA● Synthesijer
– JavaコードからVHDL/VerirogHDLを生成

Synthesijer● みよしさんが作ってるオープンソース
http://synthesijer.github.io/web/
public class Test { public boolean flag; private int count;
public void run(){ while(true){ count++; if(count > 5_000_000){ count = 0; flag = !flag; } } }}
@synthesijerhdlpublic class Top {
private final Test test = new Test(); @auto public boolean flag(){ return test.flag; }
@auto public void main(){ test.run(); }
}

Synthesijerが出力したコードmodule Test( input clk, input reset, input flag_in, input flag_we, output flag_out, output run_busy, input run_req);
wire clk_sig; wire reset_sig; wire flag_in_sig; wire flag_we_sig; wire flag_out_sig; reg run_busy_sig = 1'b1; wire run_req_sig;
reg class_flag_0000 = 1'b0; wire class_flag_0000_mux; wire tmp_0001; reg signed [32-1 : 0] class_count_0001 = 0; reg signed [32-1 : 0] unary_expr_00005 = 0; reg binary_expr_00007 = 1'b0; reg unary_expr_00011 = 1'b0; wire run_req_flag; reg run_req_local = 1'b0; wire tmp_0002; localparam run_method_IDLE = 32'd0; localparam run_method_S_0000 = 32'd1; localparam run_method_S_0001 = 32'd2; localparam run_method_S_0002 = 32'd3; localparam run_method_S_0003 = 32'd4; localparam run_method_S_0004 = 32'd5; localparam run_method_S_0005 = 32'd6; localparam run_method_S_0006 = 32'd7; localparam run_method_S_0007 = 32'd8; localparam run_method_S_0008 = 32'd9; localparam run_method_S_0009 = 32'd10; localparam run_method_S_0011 = 32'd11; localparam run_method_S_0012 = 32'd12; localparam run_method_S_0013 = 32'd13;
すごく長い

Javaは今のままで足りるの?

足りない● オブジェクトのメモリ効率が悪い● さまざまなアーキテクチャに対応した値が扱えない
– 256bit整数型、float x 4型(SIMD命令用)● 高機能データ構造がメモリにやさしくない
– Genericsが基本型を扱えない● 配列がハードウェアにやさしくない
– 多次元配列– 21億(int上限)を超える要素– 読み込み専用配列

Valhallaへの道

Project Valhalla● Value Type● Specialization
http://openjdk.java.net/projects/valhalla/

Value Type● ユーザー定義基本型● Codes like a class, works like an int!

Pointクラス
class Point{ final int x; final int y;}

Pointクラスの配列

Pointクラスの配列の効率化

ValueType版Point
value class Point{ final int x; final int y;}
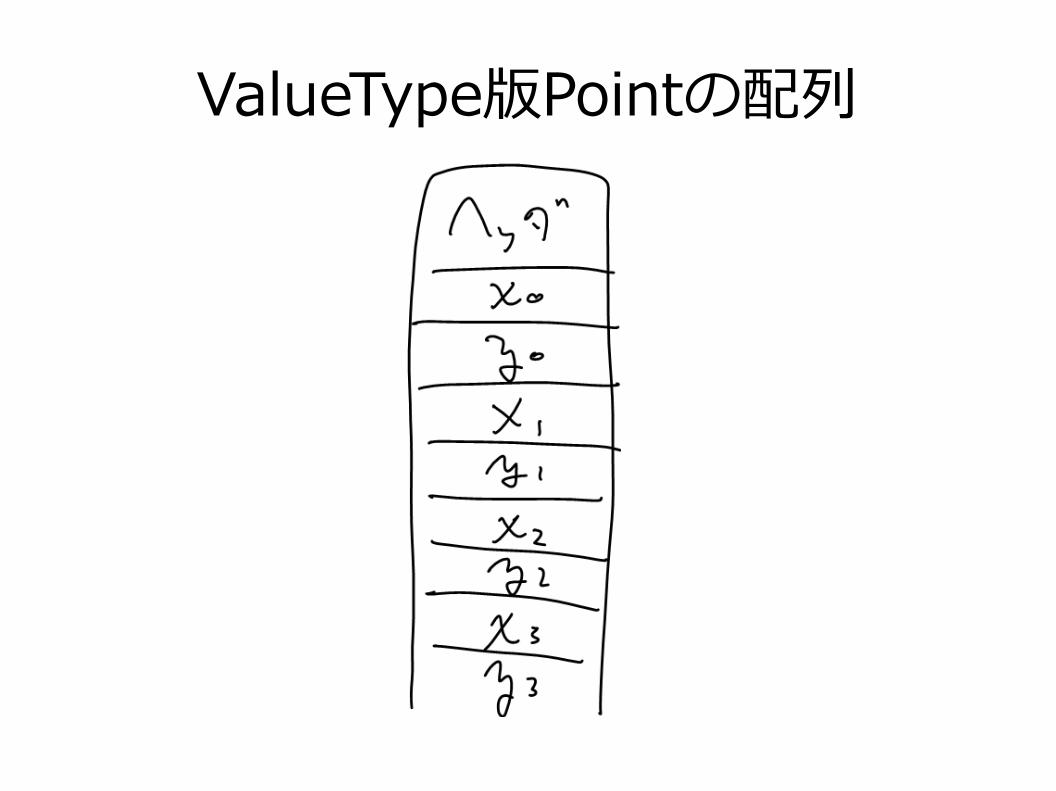
ValueType版Pointの配列

Specialization
ArrayList<int>

Java8の美しくないクラス● StreamとIntStream● OptionalとOptionalInt

ValueType対応● それぞれのValueTypeにあわせたコレクショ
ンを作るのは無理

Genericなクラス
class Box<T>{ T value; Box(T v){ value = v; } T getValue(){ return T; }}

現在のコンパイル結果
class Box{ Object value; Box(Object v){ value = v; } Object getValue(){ return value; }}

Specialize対応のコンパイル結果
class Box{ Object*T value; Box(Object*T v){ value = v; } Object*T getValue(){ return value; }}

Box<int>の場合
class Box{t=int}{ int value; Box(int v){ value = v; } int getValue(){ return value; }}

条件付きメソッド
class Box<T>{ T value; T<int> getTwice(){ return value * 2; }}

Foo<?>をどうするか● Bar<any T> <: Foo<?> なら● こうなってほしい
– Foo<int> <: Foo<?>– Bar<int> <: Foo<int>

anyとref● Foo<any>
– intでもObjectでも● Foo<ref>
– いままでのFoo<?>と同じ

可視性● Foo<int>からFoo<Object>のprivateメソッ
ドを呼びたい● ソース上は同じクラス● 実際はspecializeされた別クラス● privateメソッドが呼べない!● JavaVM助けて!

配列● Object[]とint[]は違う● Arrays2.0助けて!

Java VMはどうするか

Javaのバイトコード● aload/iload/lload/fload/dload● astore/istore/lstore/fstore/dstore● areturn/ireturn/lreturn/freturn/dreturn

演算のバイトコード● iadd/isub/imul/idiv● ladd/lsub/lmul/ldiv● dadd/dsub/dmul/ddiv● fadd/fsub/fmul/fdiv

バイトコードの統一● 型をもったまま汎用の構文● 新しい型を自然に拡張できる● vload/vstore/vreturn● vadd/vsub/vmul/vdiv

既存コードは省略形● iload → vload :I● daload → vaload :D
– さらにinvokeinterface Array.getElementの略にできるかも!

Arrays 2.0● 配列をインターフェイスに!public interface Array<any X extends Ordinal, any E> { X arrayLength(); E getElement(X n); void setElement(X n, E e); Array<X,E> clone(); Array<X,E> freeze(); Array<X,E> slice(X from, X to); // creates shared view Array<X,E> copyOf(X length); // Arrays.copyOf Array<X,E> copyOfRange(X from, X to); // Arrays.copyOfRange boolean arrayEquals(Array<E> that); // Arrays.equals int arrayHashCode(); // Arrays.hashCode String arrayToString(); // Arrays.toString

Threadは古い● fiberの導入

まとめ● コンピュータは変わる● Javaも変わる● あんたはどうだい?