

Introduction to Spark SQL training workshop
22
SPARK SQL Xinh Huynh Women in Big Data training workshop August, 2016
-
Upload
susan-xinh-huynh -
Category
Software
-
view
238 -
download
2
Transcript of Introduction to Spark SQL training workshop

SPARK SQLXinh Huynh Women in Big Data training workshop August, 2016

Audience poll
https://commons.wikimedia.org/wiki/File:PEO-happy_person_raising_one_hand.svg

Outline• Part 1: Spark SQL Overview, SQL Queries • Part 2: DataFrame Queries • Part 3: Additional DataFrame Functions

Outline• Part 1: Spark SQL Overview, SQL Queries • Part 2: DataFrame Queries • Part 3: Additional DataFrame Functions
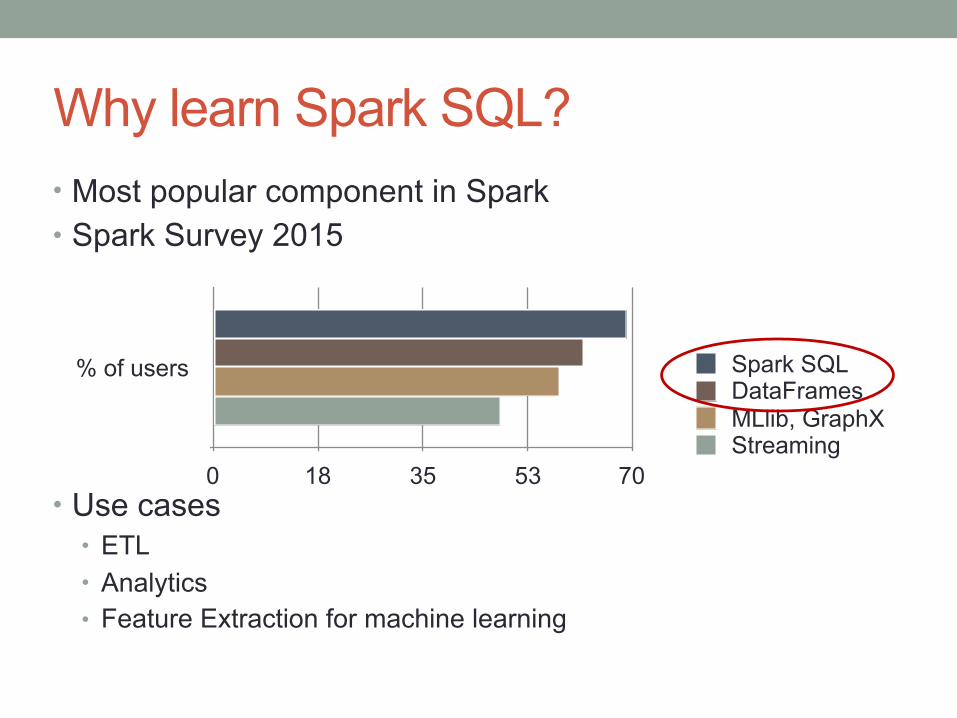
Why learn Spark SQL?• Most popular component in Spark • Spark Survey 2015
• Use cases • ETL • Analytics • Feature Extraction for machine learning
% of users
0 18 35 53 70
Spark SQLDataFramesMLlib, GraphXStreaming

Use case: ETL & analytics• Example: restaurant finder app
• Log data: Timestamp, UserID, Location, RestaurantType • [ 4/24/2014 6:22:51 PM, 1000618, -85.5750, 42.2959, Pizza ]
• Analytics • What time of day do users use the app? • What is the most popular restaurant type in San Jose, CA?
Logs ETL Analytics
Spark SQL Spark SQL
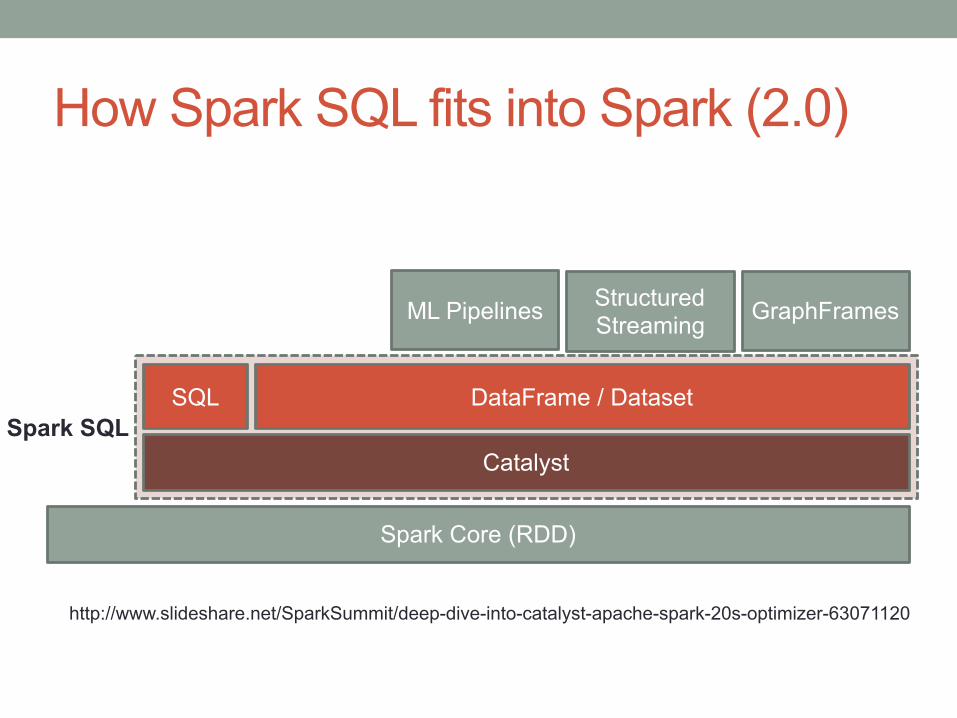
How Spark SQL fits into Spark (2.0)
Spark Core (RDD)
Catalyst
SQL DataFrame / Dataset
ML Pipelines Structured Streaming GraphFrames
Spark SQL
http://www.slideshare.net/SparkSummit/deep-dive-into-catalyst-apache-spark-20s-optimizer-63071120
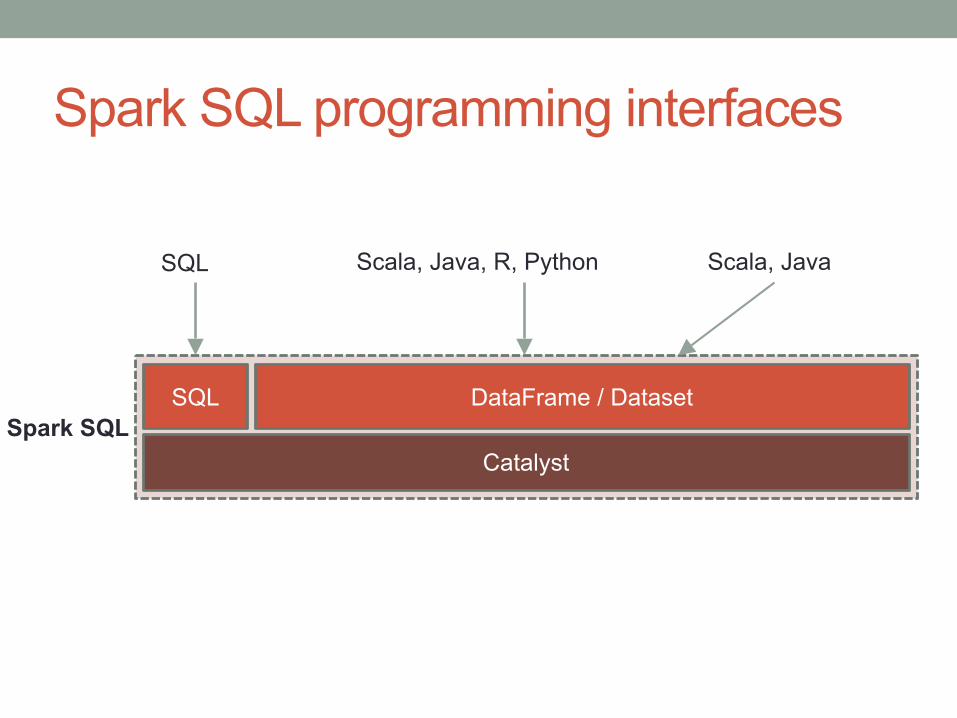
Spark SQL programming interfaces
Catalyst
SQL DataFrame / DatasetSpark SQL
SQL Scala, Java, R, Python Scala, Java

SQL or DataFrame?• Use SQL if you are already familiar with SQL
• Use DataFrame • To write queries in a general-purpose programming language
(Scala, Python, …). • Use DataFrame to catch syntax errors earlier:
SQL DataFrame
Syntax Error Example
“SELEECT id FROM table” df.seleect(“id”)
Caught at Runtime Compile Time

Loading and examining a table, Query with SQL
• See Notebook: http://tinyurl.com/spark-nb1

Setup for Hands-on Training1. Sign on to WiFi with your assigned access code
1. See slip of paper in front of your seat 2. Sign in to https://community.cloud.databricks.com/ 3. Go to "Clusters" and create a Spark 2.0 cluster
1. This may take a minute. 4. Go to “Workspace” -> Users -> Home -> Create ->
Notebook 1. Select Language = Scala 2. Create

Outline• Part 1: Spark SQL Overview, SQL Queries • Part 2: DataFrame Queries • Part 3: Additional DataFrame Functions

Lazy Execution• DataFrame operations are lazy
• Work is delayed until the last possible moment
• Transformations: DF -> DF • select, groupBy; no computation done
• Actions: DF -> console or disk output • show, collect, count, write; computation is done
https://www.flickr.com/photos/mtch3l/24491625352

Lazy Execution Example1. val df1 = df.select(…)
2. val df2 = df1.groupBy (…) 3. .sum()
4. if (cond) 5. df2.show()
• Benefits of laziness • Query optimization across lines 1-3 • If step 5 is not executed, then no unnecessary work was done
Transformation: no computation done
Transformation: no computation done
Action: performs the select, groupBy at this time, then shows the results
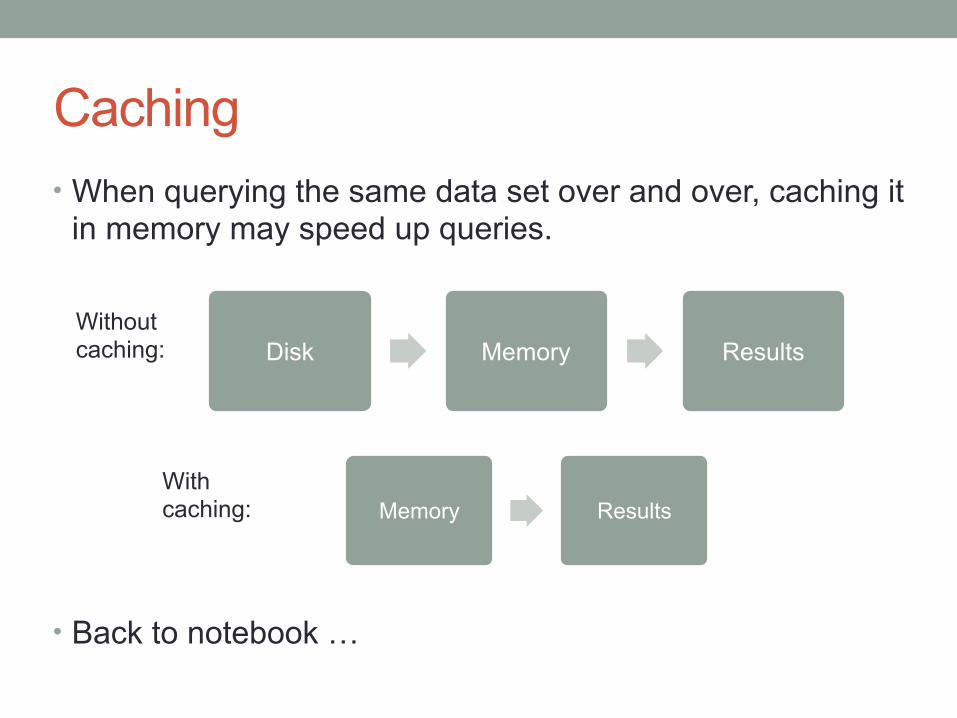
Caching• When querying the same data set over and over, caching it
in memory may speed up queries.
• Back to notebook …
Disk Memory Results
Memory Results
Without caching:
With caching:

Outline• Part 1: Spark SQL Overview, SQL Queries • Part 2: DataFrame Queries • Part 3: Additional DataFrame Functions
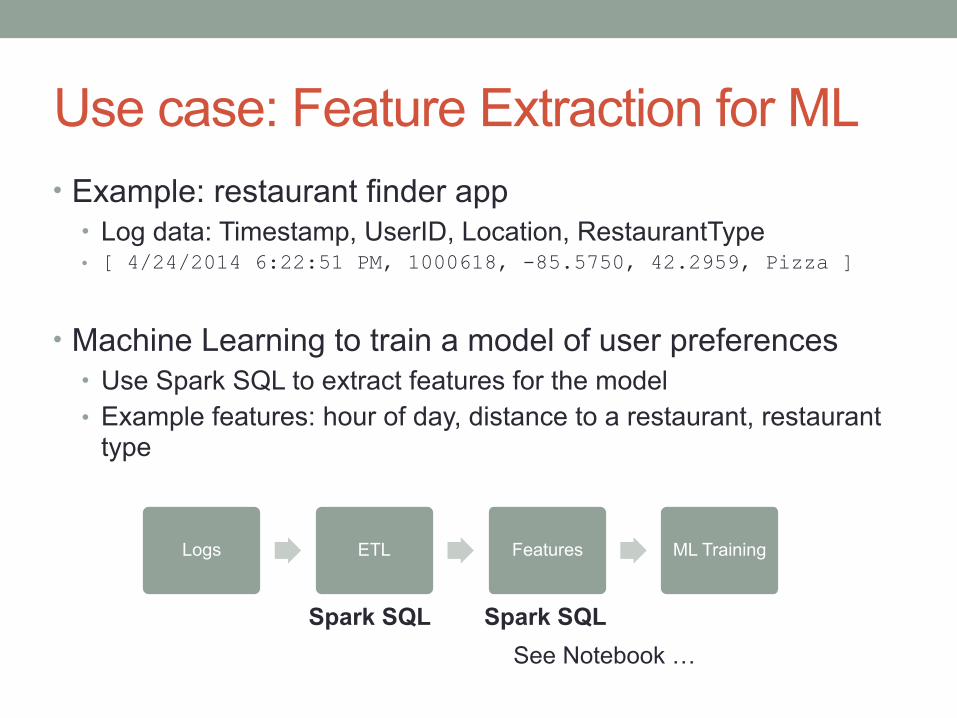
Use case: Feature Extraction for ML• Example: restaurant finder app
• Log data: Timestamp, UserID, Location, RestaurantType • [ 4/24/2014 6:22:51 PM, 1000618, -85.5750, 42.2959, Pizza ]
• Machine Learning to train a model of user preferences • Use Spark SQL to extract features for the model • Example features: hour of day, distance to a restaurant, restaurant
type
Logs ETL Features ML Training
Spark SQL Spark SQLSee Notebook …

Dataset (new in 2.0)• DataFrames are untyped
• df.select($”col1” + 3)
• Useful when exploring new data • Datasets are typed
• Dataset[T] • Associates an object of type T with each row
• Catches type mismatches at compile time • DataFrame = Dataset[Row]
• A DataFrame is one specific type of Dataset[T]
case class FarmersMarket(FMID: Int, MarketName: String) val ds : Dataset[FarmersMarket] …
Numerical type assumed, but not checked at compile time

Review• Part 1: Spark SQL Overview, SQL Queries √ • Part 2: DataFrame Queries √ • Part 3: Additional DataFrame Functions √
References• Spark SQL: http://spark.apache.org/docs/latest/sql-
programming-guide.html • Spark Scala API docs: http://spark.apache.org/docs/latest/
api/scala/index.html#org.apache.spark.package • Overview of DataFrames: http://
xinhstechblog.blogspot.com/2016/05/overview-of-spark-dataframe-api.html
• Questions, comments: • Spark user list: [email protected] • Xinh’s contact: https://www.linkedin.com/in/xinh-huynh-317608 • Women in Big Data: https://www.womeninbigdata.org/


















