Introduction to OpenMP Eric Aubanel Advanced Computational Research Laboratory Faculty of Computer...
22
Introduction to OpenMP Eric Aubanel Advanced Computational Research Laboratory Faculty of Computer Science, UNB Fredericton, New Brunswick
-
Upload
ilene-matthews -
Category
Documents
-
view
220 -
download
1
Transcript of Introduction to OpenMP Eric Aubanel Advanced Computational Research Laboratory Faculty of Computer...

Introduction to OpenMP
Eric AubanelAdvanced Computational Research Laboratory
Faculty of Computer Science, UNB
Fredericton, New Brunswick

Shared Memory
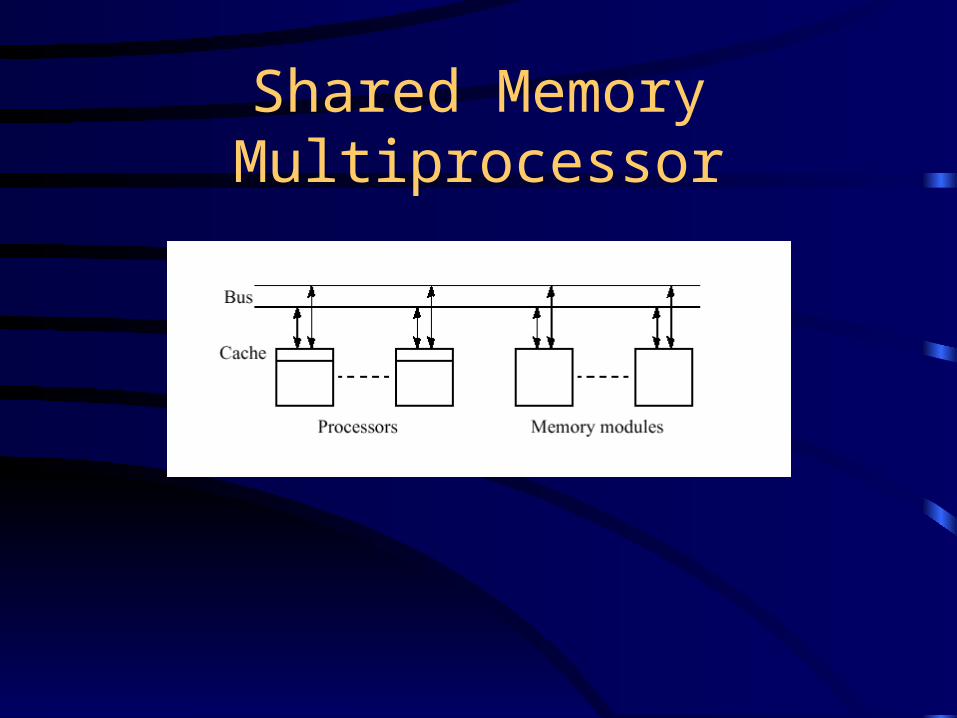
Address space
Processes
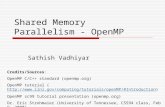
Shared Memory Multiprocessor
Distributed vs. DSM
Address space
Processes
Address space
Processes
Address space
Processes
Network
Memory
Processes
Memory
Processes
Memory
Processes
Network - Global address space

Parallel Programming Alternatives
• Use a new programming language
• Use a existing sequential language modified to handle parallelism
• Use a parallelizing compiler
• Use library routines/compiler directives with an existing sequential language– Shared memory (OpenMP) vs. distributed
memory (MPI)

What is Shared Memory Parallelization?
• All processors can access all the memory in the parallel system (one address space).
• The time to access the memory may not be equal for all processors– not necessarily a flat memory
• Parallelizing on a SMP does not reduce CPU time– it reduces wallclock time
• Parallel execution is achieved by generating multiple threads which execute in parallel
• Number of threads (in principle) is independent of the number of processors

Threads: The Basis of SMP Parallelization
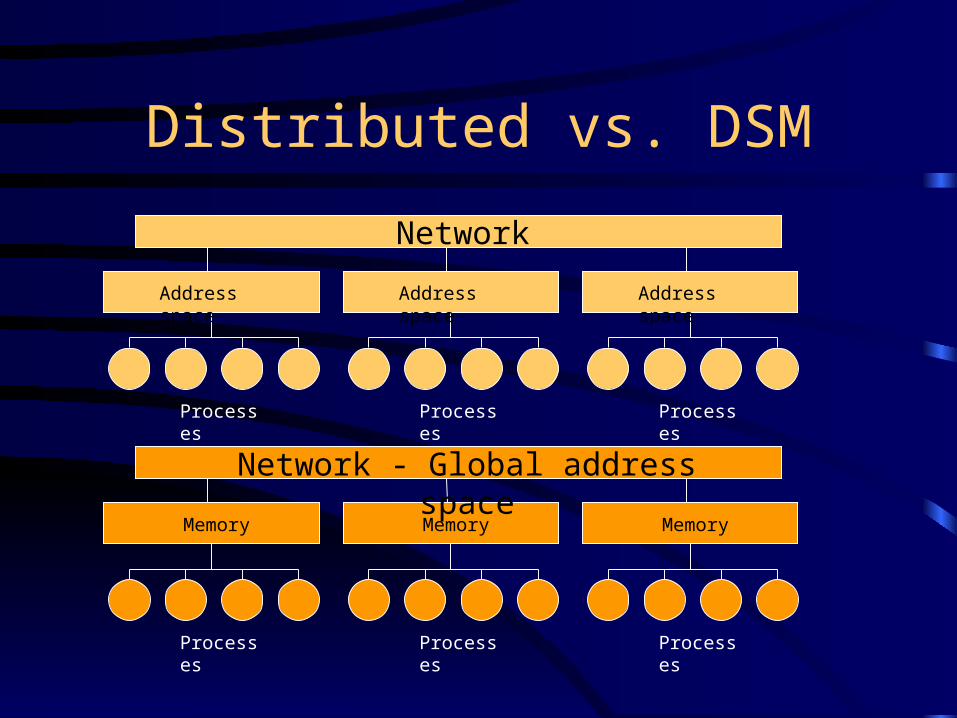
• Threads are not full UNIX processes. They are lightweight, independent "collections of instructions" that execute within a UNIX process.
• All threads created by the same process share the same address space.– a blessing and a curse: "inter-thread" communication is efficient, but it is easy to
stomp on memory and create race conditions.
• Because they are lightweight, they are (relatively) inexpensive to create and destroy.– Creation of a thread can take three orders of magnitude less time than process
creation!
• Threads can be created and assigned to multiple processors: This is the basis of SMP parallelism!
Processes vs. Threads
ProcessIP
stack
code
heap
IP
stack
code
heap
IP
stack
Threads

Methods of SMP Parallelism
1. Explicit use of threads
• Pthreads: see "Pthreads Programming" from O'Reilly & Associates, Inc.
2. Using a parallelizing compiler and its directives, you can generate pthreads "under the covers."
• can use vendor-specific directives (e.g. !SMP$)
• can use industry-standard directives (e.g. !$OMP and OpenMP)
OpenMP• 1997: group of hardware and software vendors announced
their support for OpenMP, a new API for multi-platform shared-memory programming (SMP) on UNIX and Microsoft Windows NT platforms.– www.openmp.org
• OpenMP provides comment-line directives, embedded in C/C++ or Fortran source code, for – scoping data
– specifying work load
– synchronization of threads
• OpenMP provides function calls for obtaining information about threads.– e.g., omp_num_threads(), omp_get_thread_num()

OpenMP example
Subroutine saxpy(z, a, x, y, n)integer i, nreal z(n), a, x(n), y!$omp parallel dodo i = 1, n z(i) = a * x(i) + yend doreturnend

OpenMP Threads1.All OpenMP programs begin as a single process: the master thread
2.FORK: the master thread then creates a team of parallel threads
3.Parallel region statements executed in parallel among the various team threads
4.JOIN: threads synchronize and terminate, leaving only the master thread

Private vs Shared Variables
z a x y n iGlobal shared memory
Serial executionAll data references to global shared memory
z a x y nGlobal shared memory
Parallel execution References to z, a, x, y, n are to global shared memory
i i i i
Each thread has a private copy of i
References to i are to the private copy
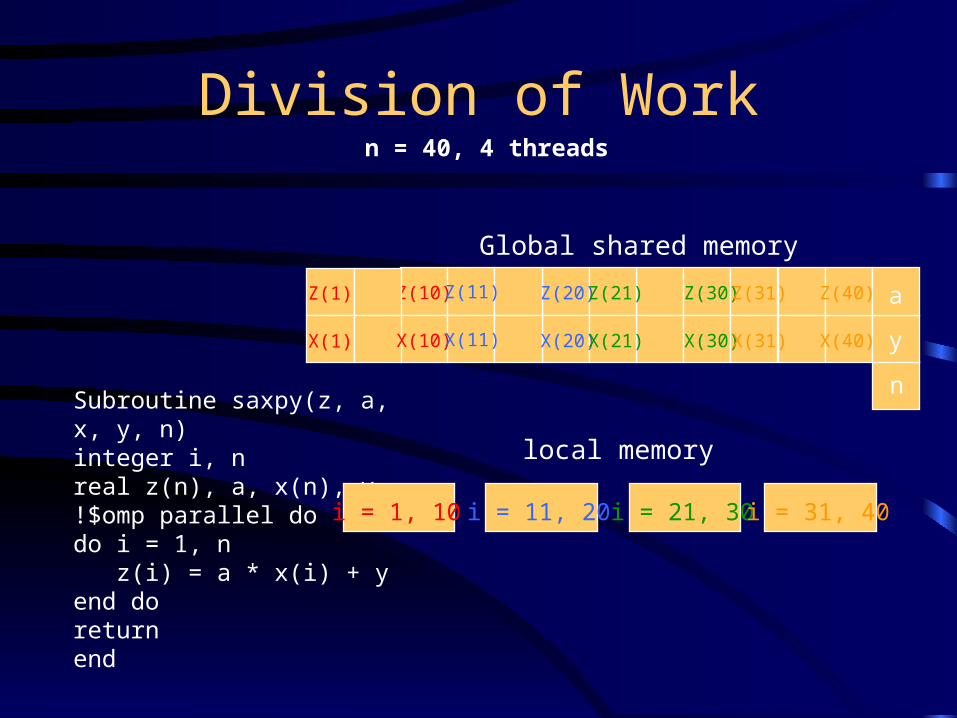
Division of Work
Subroutine saxpy(z, a, x, y, n)integer i, nreal z(n), a, x(n), y!$omp parallel dodo i = 1, n z(i) = a * x(i) + yend doreturnend
i = 11, 20
n = 40, 4 threads
i = 21, 30 i = 31, 40i = 1, 10
Z(10)
n
Z(11) Z(20) Z(21)Z(1) Z(30) a
y
Z(31) Z(40)
X(10) X(11) X(20)X(21)X(1) X(30)X(31) X(40)
Global shared memory
local memory

Variable Scoping• The most difficult part of shared memory parallelization.
– What memory is shared
– What memory is private (i.e. each processor has its own copy)
– How private memory is treated vis à vis the global address space.
• Variables are shared by default, except for loop index in parallel do
• This must mesh with the Fortran view of memory– Global: shared by all routines
– Local: local to a given routine
• saved vs. non-saved variables (through the SAVE statement or -save option)

Static vs. Automatic Variables
• Fortran 77 standard allows subprogram local variables to become undefined between calls, unless saved with a SAVE statement
STATIC AUTOMATIC
AIX (default) -qnosave
IRIX -static -automatic (default)
SunOS (default) -statckvar

OpenMP Directives in Fortran
Line continuation:
Fixed form:!$OMP PARALLEL DO
!$OMP&PRIVATE (JMAX)
!$OMP&SHARED(A, B)
Free form:!$OMP PARALLEL DO &
!$OMP PRIVATE (JMAX) &
!$OMP SHARED(A, B)

OpenMP in C• Same functionality as OpenMP for FORTRAN• Differences in syntax:
– #pragma omp for
• Differences in variable scoping:– variables "visible" when #pragma omp parallel encountered are
shared by default
• static variables declared within a parallel region are also shared• heap allocated memory (malloc) is shared (but pointer can be
private)• automatic storage declared within a parallel region is private (ie,
on the stack)

OpenMP Overhead
• Overhead for parallelization is large (eg. 8000 cycles for parallel do over 16 processors of SGI Origin 2000) – size of parallel work construct must be
significant enough to overcome overhead– rule of thumb: it takes 10 kFLOPS to amortize
overhead

OpenMP Use
How is OpenMP typically used?
• OpenMP is usually used to parallelize loops:– Find your most time consuming loops.– Split them up between threads.
• Better scaling can be obtained using OpenMP parallel regions, but can be tricky!

OpenMP vs. MPI• Only for shared memory
computers
• Easy to incrementally parallelize– More difficult to write highly
scalable programs
• Small API based on compiler directives and limited library routines
• Same program can be used for sequential and parallel execution
• Shared vs private variables can cause confusion
• Portable to all platforms
• Parallelize all or nothing
• Vast collection of library routines
• Possible but difficult to use same program for serial and parallel execution
• variables are local to each processor

References
• Parallel Programming in OpenMP, by Chandra et al. (Morgan Kauffman)
• www.openmp.org
• Multimedia tutorial at Boston University:– scv.bu.edu/SCV/Tutorials/OpenMP/
• Lawrence Livemore online tutorial– www.llnl.gov/computing/training/
• European workshop on OpenMP (EWOMP)– www.epcc.ed.ac.uk/ewomp2000/