

Introduction to Emerging Methods for Imputation in Official Statistics Ventspils 08/2006 Pasi Piela.
38
Introduction to Emerging Methods for Imputation in Official Statistics Ventspils 08/2006 Pasi Piela
-
Upload
lucas-chapman -
Category
Documents
-
view
225 -
download
1
Transcript of Introduction to Emerging Methods for Imputation in Official Statistics Ventspils 08/2006 Pasi Piela.

Introduction to Emerging Methods for Imputation in Official Statistics
Ventspils 08/2006
Pasi Piela

25.08.2006 2Pasi Piela
Overview
1. Imputation in the quality framework of official statistics 2. Classes of imputation methods 3. Requirements for imputation in official statistics 4. Past research work 5. Statistical clustering 6. Best imputation methods 7. Processing imputation (and editing) 8. New research plans 9. Multiple imputation 10. Fractional imputation 11. Multilevel model based imputation

25.08.2006 3Pasi Piela
Overview
1. Imputation in the quality framework of official statistics 2. Classes of imputation methods 3. Requirements for imputation in official statistics 4. Past research work 5. Statistical clustering 6. Best imputation methods 7. Processing imputation (and editing) 8. New research plans 9. Multiple imputation 10. Fractional imputation 11. Multilevel model based imputation

25.08.2006 4Pasi Piela
Imputation is defined as the process of statistical replacement of missing values
Editing and imputation are undertaken as part of a quality improvement strategy to improve accuracy, consistency and completeness.

25.08.2006 5Pasi Piela
Classes of imputation methods
A1. Deterministic imputation, orA2. Stochastic imputation
B1. Logical imputation,B2. Real donor imputation, orB3. Model donor imputation
C1. Single imputation, orC2. Multiple imputation
D1. Hot-deck D2. Cold-deck

25.08.2006 6Pasi Piela
Five requirements for imputation in official statistics (Chambers, 2001)
Predictive Accuracy: The imputation procedure should maximise the preservation of true values.
Distributional Accuracy: The preservation of the distribution of the true values is also important.
Estimation Accuracy: The imputation procedure should reproduce the lower order moments of the distributions of the true values.
Imputation Plausibility: The imputation procedure should lead to imputed values that are plausible.
Ranking Accuracy: The imputation procedure should maximise the preservation of order in the imputed values.

25.08.2006 7Pasi Piela
Past research work
traditional methods: cell-mean imputation, regression imputation, random donor, nearest neighbour, etc.
advanced imputation techniquesbased on statistical clustering (e.g. K-means)homogenous imputation classeshierarchical clustering (e.g. classification and regression
trees)”modern” statistical pattern recognition methods

25.08.2006 8Pasi Piela
Statistical clustering for imputation
imputation classes, cells, clusters, groups
average point locating the cluster
Computational methods?
...or searching appropriate imputation cells by using categorical sorting variables?

25.08.2006 9Pasi Piela
K-means Clustering The basic variance minimization clustering algorithm. The ”Voronoi region” (as part of the tesselation) for cluster i is
given by
where || refers to the Euclidean norm (distance). At the iteration time t + 1 the weight wi is updated by
where #Vi refers to the number of units xk in Vi.
,,#
1)1(i
kk
i
ti Vkx
Vw
jiwxwxxV jii ,22
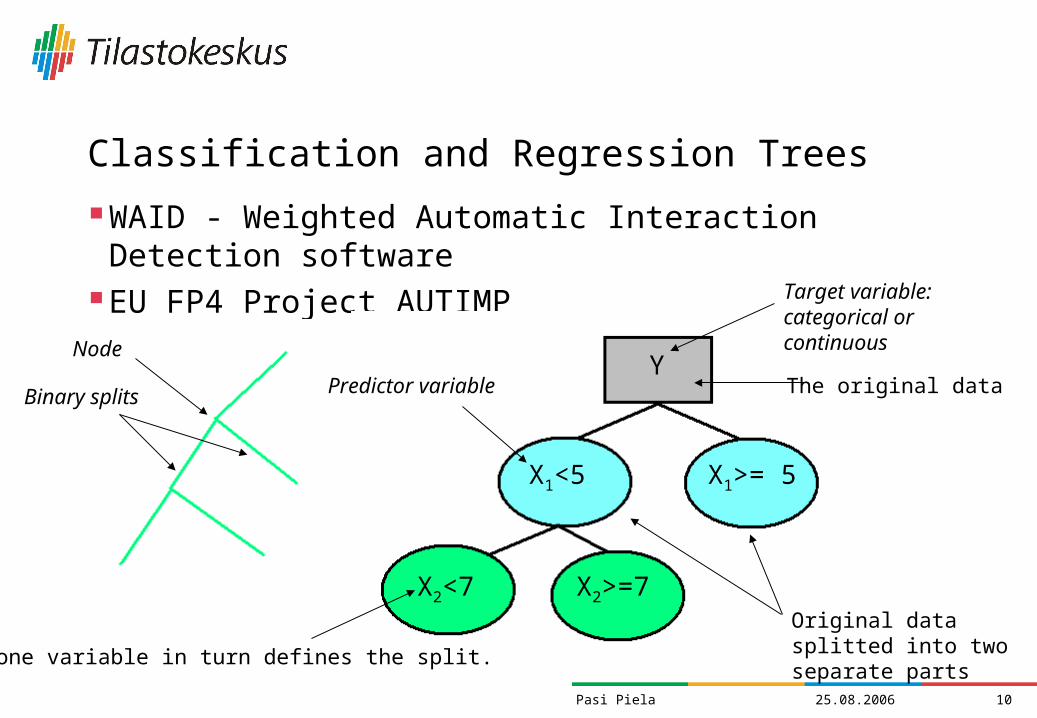
25.08.2006 10Pasi Piela
Classification and Regression Trees
WAID - Weighted Automatic Interaction Detection software EU FP4 Project AUTIMP
NodeY
X1<5 X1>= 5
X2<7 X2>=7
Binary splits
Target variable: categorical or continuous
Predictor variable The original data
Original data splitted into two separate partsOnly one variable in turn defines the split.

Neural networks for clustering: Self-Organizing Maps, SOM
The basic SOM defines a mapping from the input data space Rn onto a latent space consisted typically of a two-dimensional array of nodes or neurons.

25.08.2006 12Pasi Piela
Best methods
Nearest neighbour (hot-deck) by Euclidean distance metrics
The best method is actually a system that includes several competitive imputation methods
The development and evaluation of new imputation methods is closely connected to the software development.

25.08.2006 13Pasi Piela
Processing imputation (and editing)
The Banff system of Statistics Canada is a good example about computerized editing and imputation process. It is a collection of specialized SAS® procedures "each of which can be used independently or put together in order to satisfy the edit and imputation requirements of a survey" as stated in the Banff manual (Statistics Canada, 2006).
successor to more well-known GEIS
currently Statistics Finland is evaluating Banff

25.08.2006 14Pasi Piela

25.08.2006 15Pasi Piela
Verifying edits, generating implied edits and extremal
points

25.08.2006 16Pasi Piela
(Pre-)view of failure rates, fine-tuning the edits

25.08.2006 17Pasi Piela
Three basic outlier detection methods

25.08.2006 18Pasi Piela
Identifying which fields require imputation and
how to satisfy edits.

25.08.2006 19Pasi Piela
Here : logical imputation
(one possible value allowing
to pass the edits).

25.08.2006 20Pasi Piela
Nearest neighbour
via constructing
a k-dimensional
tree.

25.08.2006 21Pasi Piela
Using user-defined or
some of the 20 hard-coded
algorithms.

25.08.2006 22Pasi Piela
Adjusting and rounding the data so
that they add to a specific totals.

25.08.2006 23Pasi Piela
Mass imputation procedure (not handled in this presentation)

25.08.2006 24Pasi Piela

25.08.2006 25Pasi Piela
Plans for future research - intro
Multiple imputation, MI, was not handled here because of the context of the research. But also detailed research in imputation variance and careful analysis of the datasets with hierarchical, multilevel nature (note the difference to the previously mentioned hierarchical clustering methods) containing cross-classifications and missingness were also excluded. This will lead us to the forthcoming research that will be next outlined.

25.08.2006 26Pasi Piela
Multiple imputation
Donald Rubin, 1987 Bayesian framework very famous and popular family of the imputation methods rarely used in official statistics several imputed datasets are combined to reach an
estimate for the imputation variance assumptions are strict and there also exist some difficulties
with MI variance estimation as discussed by Rao (2005) and Kim et al. (2004)

25.08.2006 27Pasi Piela
Fractional imputation
a sort of mixed real donor and model donor “hot-deck” imputation method for a population divided into imputation cells
involves using more than one donor for a recipient simply: three imputed values might be assigned to each
missing value, with each entry allocated a weight of 1/3 of the nonrespondent's original weight
Kim and Fuller (2004): superior to MI designed to reduce the imputation variance while MI gives
only a simple way to estimate it

25.08.2006 28Pasi Piela
Fractional imputation
a sort of mixed real donor and model donor “hot-deck” imputation method for a population divided into imputation cells
involves using more than one donor for a recipient simply: three imputed values might be assigned to each
missing value, with each entry allocated a weight of 1/3 of the nonrespondent's original weight
Kim and Fuller (2004): superior to MI designed to reduce the imputation variance while MI gives
only a simple way to estimate it
Assume the within-cell uniform response model in which the responses in a cell g are equivalent to a Bernoulli sample sample selected from the elements ng.

25.08.2006 29Pasi Piela
Fractional imputation 2
Formulating the fractionally imputed
estimator:
Ai
ii yw .̂
RAi
iijIj ywY *
R
ijAi
iAj
jI yww .θ̂ *
ARAM
A
sample respondents
sample non-respondents
R*iiRij AiwAjijiw for1and,,for0*
imputation fractionpopulation quantity of interest

25.08.2006 30Pasi Piela
Fractional imputation 3
Kim and Fuller (2004) showed also how fractional imputation combined with the proposed replication variance estimator gives a set of replication weights that can be used to construct unbiased variance estimators for estimators based on imputed data (and for estimators based on the completely responding variables).
fully efficient fractional imputation, FEFIproduces zero imputation variance

25.08.2006 31Pasi Piela
Fractional imputation 3
Kim and Fuller (2004) showed also how fractional imputation combined with the proposed replication variance estimator gives a set of replication weights that can be used to construct unbiased variance estimators for estimators based on imputed data (and for estimators based on the completely responding variables).
fully efficient fractional imputation, FEFIproduces zero imputation variance
Approximations to FEFI by fixed number of donors.-- e.g. systematic sampling with probability proportional to the weights to select donors for each recipient. After the donors are assigned, the initial fractions are adjusted so that the sum of the weights gives the fully efficient fractionally imputed estimator.

25.08.2006 32Pasi Piela
Multilevel modeling for imputation
Many kinds of data have a hierarchical or clustered nature. We refer to a hierarchy as consisting of units grouped at
different levels. Thus children may be the level 1 units in a 2-level structure where the level 2 units are the families and students may be the level 1 units clustered within schools that are the level 2 units.
More recently there has been a growing awareness that many data structures are not purely hierarchical but contain cross-classifications of higher level units and multiple membership patterns.

25.08.2006 33Pasi Piela
Multilevel modeling for imputation 2
Multilevel models (Goldstein, 2003) take advantage of the correlation structure between different levels of hierarchy.
Correlation structures and connections between the study variables can be a challenge in imputation tasks as well.
Currently in literature, there are some papers about the use of multiple imputation with multilevel models.
Carpenter and Goldstein (2004): if a dataset is multilevel then the imputation model should be multilevel too.
MLwiN

25.08.2006 34Pasi Piela
Plans for future research
new imputation methods and the analysis of imputed and missing data when data structures are complex
use of multilevel imputation models in which clusters in the cluster sampling design can be incorporated in an imputation model as random effects
information on the complex sampling design can be incorporated, for example, by using strata indicators as fixed covariates
modified fractional and single imputation will be considered

25.08.2006 35Pasi Piela
Plans for future research 2
Another new avenue of research is the use of multilevel models and imputation in the context of small area estimation (Rao, 2003).

25.08.2006 37Pasi Piela
References 1/2 Aitkin, M., Anderson, D., and Hinde, J. (1981): Statistical Modelling of Data on Teaching Styles (with discussion). Journal of the Royal Statistical Society, A 144, 148-1461.
Breiman, L., Friedman, J.H., Olsen, R.A., and Stone, C.J. (1984): Classification and Regression Trees. Wadsworth, Belmont, CA.
Carpenter, J.R., and Goldstein, H. (2004): Multiple Imputation Using MLwiN, Multilevel Modelling Newsletter, 16, 2. **
Charlton, J. (2003): Editing and Imputation Issues. Towards Effective Statistical Editing and Imputation Strategies - Findings of the Euredit project. *
Chambers, R. (2001): Evaluation Criteria for Statistical Editing and Imputation. National Statistics Methodological Series, United Kingdom, 28, 1-41. *
Eurostat (2002): Quality in the European Statistical System - the Way Forward. European Comission.
Goldstein, H. (2003). Multilevel Statistical Models (Third Edition). Edward Arnold, London.
Hill, P.W., and Goldstein, H. (1998): Multilevel Modelling of Educational Data with Cross Classification and Missing Indentification of Units, Journal of Educational and Behavioural Statistics, 23, 117-128.
Kalton, G., and Kish, L. (1984): Some Efficient Random Imputation Methods. Communications in Statistics, A13, 1919-1939.
Kim, J.K., and Fuller, W.A. (2004): Fractional hot deck imputation, Biometrika, 91, 559-578.
Fuller, W.A., and Kim, J.K. (2005): Hot Deck Imputation for the Response Model, Survey Methodology, 31, 2, 139-149.
Kim, J.K., Brick, J.M., Fuller, W.A. and Kalton, G. (2004): On the Bias of the Multiple Imputation Variance Estimator in Survey Sampling . Technical Report.
Kohonen, T. (1997): Self-Organizing Maps. Springer Verlag, New York.
Koikkalainen, P., Horppu, I., and Piela P. (2003): Evaluation of SOM based Editing and Imputation. Towards Effective Statistical Editing and Imputation Strategies - Findings of the Euredit project. *
Lehtonen, R., Särndal, C.-E., and Veijanen, A. (2003): The Effect of Model Choice in Estimation for Domains, Including Small Domains, Survey Methodology, 29, 33-44.
Lehtonen, R., Särndal, C.-E., and Veijanen, A. (2005): Does the Model Matter? Comparing Model-assisted and Model-dependent Estimators of Class Frequencies for Domains, Statistics in Transition, 7, 649-673.

25.08.2006 38Pasi Piela
References 2/2 Piela, P., and Laaksonen, S. (2001): Automatic Interaction Detection for Imputation – Tests with the WAID Software Package. In: Proceedings of Federal Committee on
Statistical Methodology Research Conference, Statistical Policy Working paper, 34, 2, 49-59, Washington, DC.
Piela, P. (2002): Introduction to Self-Organizing Maps Modelling for Imputation - Techniques and Technology. Research in Official Statistics, 2, 5-19.
Piela, P. (2004): Neuroverkot ja virallinen tilastotoimi, Suomen Tilastoseuran Vuosikirja 2004. Helsinki.
Piela, P. (2005): On Emerging Methods for Imputation in Official Statistics. Licentiate Thesis. University of Jyväskylä.
Rasbash, J., Steele, F., Browne, W., and Prosser, B. (2004): A User’s Guide to MLwiN (version 2.0). London. **
Rao, J.N.K. (2003): Small Area Estimation. Wiley, New York.
Rao, J.N.K. (2005): Interplay Between Sample Survey Theory and Practice: An Appraisal, Survey Methodology, Statistics Canada, 31, 2, 117-138.
Ritter, H., Martinez, T., and Schulten, K. (1992): Neural Computation and Self-Organizing Maps: An Introduction. Addison-Wesley, Reading, MA.
Schafer, J.L., and Graham, J.W. (2002): Missing Data: Our View of the State of the Art, Psychological Methods 7, 2, 147-177.
Statistics Canada (2003): Statistics Canada Quality Guidelines. Catalogue no. 12-539-XIE.
Statistics Canada (2006): Functional Description of the Banff System for Edit and Imputation. Statistics Canada.
Rubin, D. (1987): Multiple Imputation in Surveys. John Wiley & Sons, New York.
*) The Euredit project: http://www.cs.york.ac.uk/euredit/
**) Centre for Multilevel Modelling: http://www.mlwin.com/


















