
Introduction to Cassandra
13
Cassandra History ● Created at Facebook ● Open-sourced since 2008 ● Current version = 3.3 ● Column-oriented ☞ distributed table NoSQL database Cluster Layer ● Amazon DynamoDB paper ● Masterless architecture Data-store layer ● Google Big Table paper ● Columns/columns family
-
Upload
artur-mkrtchyan -
Category
Technology
-
view
276 -
download
0
Transcript of Introduction to Cassandra
Cassandra History
● Created at Facebook● Open-sourced since 2008 ● Current version = 3.3● Column-oriented ☞ distributed table
NoSQL database Cluster Layer● Amazon DynamoDB paper● Masterless architecture
Data-store layer● Google Big Table paper● Columns/columns family
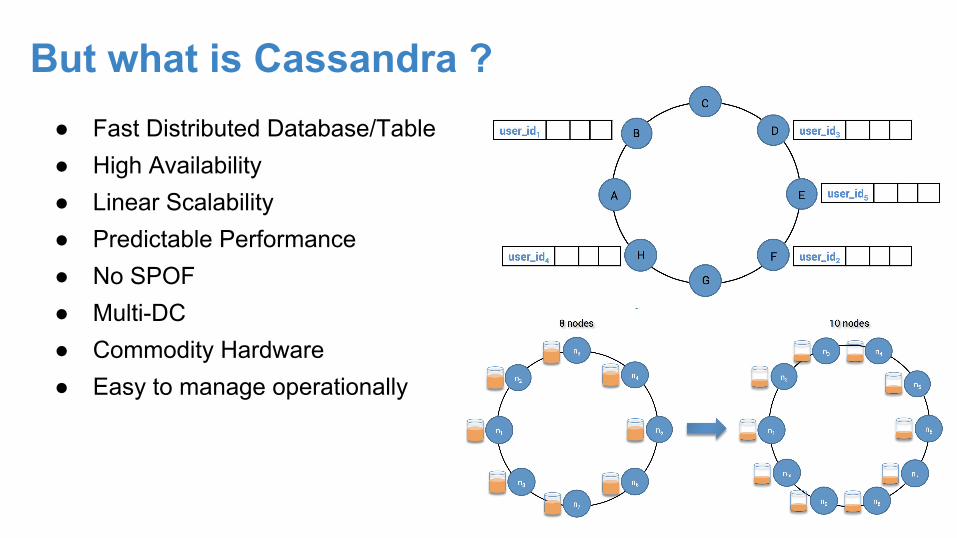
But what is Cassandra ?● Fast Distributed Database/Table● High Availability● Linear Scalability● Predictable Performance● No SPOF● Multi-DC● Commodity Hardware● Easy to manage operationally
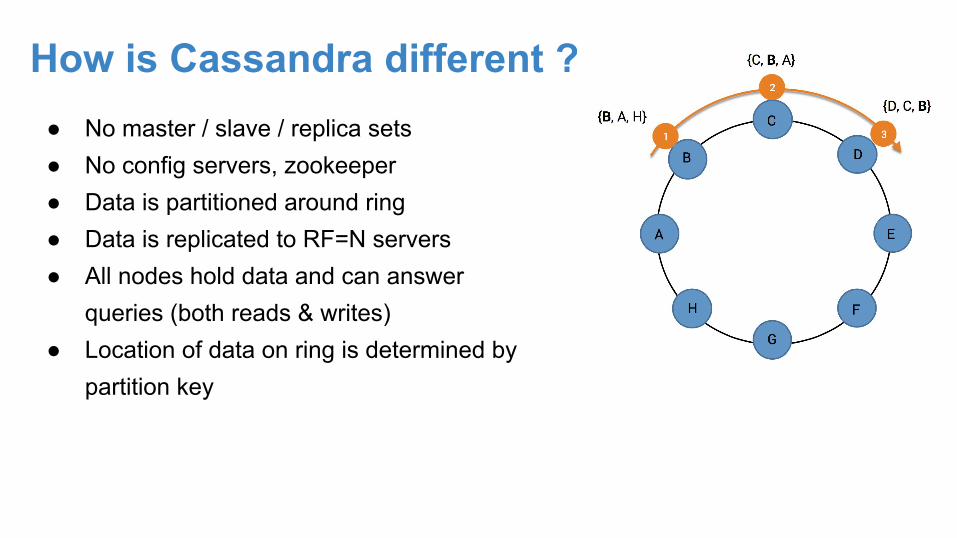
How is Cassandra different ?● No master / slave / replica sets● No config servers, zookeeper● Data is partitioned around ring● Data is replicated to RF=N servers● All nodes hold data and can answer
queries (both reads & writes)● Location of data on ring is determined by
partition key

● Cassandra chooses Availability & Partition Tolerance over Consistency
● Queries have tunable consistency level● ALL, QUORUM, ONE● Hinted Handoff to deal with failed nodes
CAP Theorem
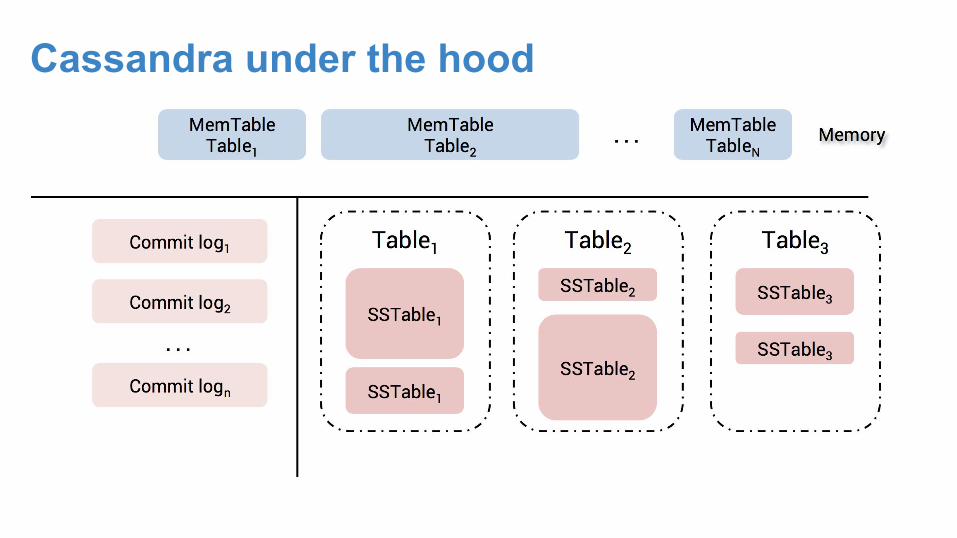
Cassandra under the hood
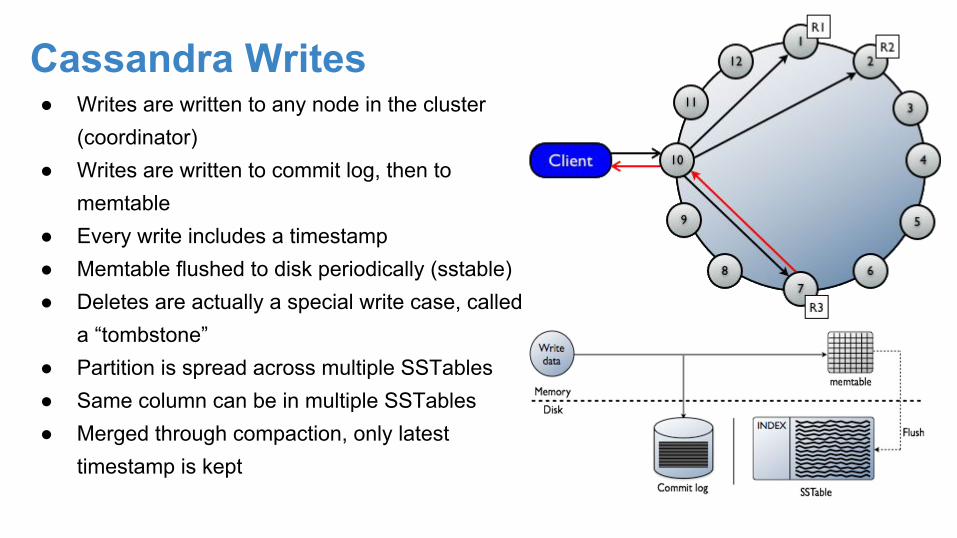
Cassandra Writes● Writes are written to any node in the cluster
(coordinator)● Writes are written to commit log, then to
memtable● Every write includes a timestamp● Memtable flushed to disk periodically (sstable)● Deletes are actually a special write case, called
a “tombstone”● Partition is spread across multiple SSTables● Same column can be in multiple SSTables● Merged through compaction, only latest
timestamp is kept
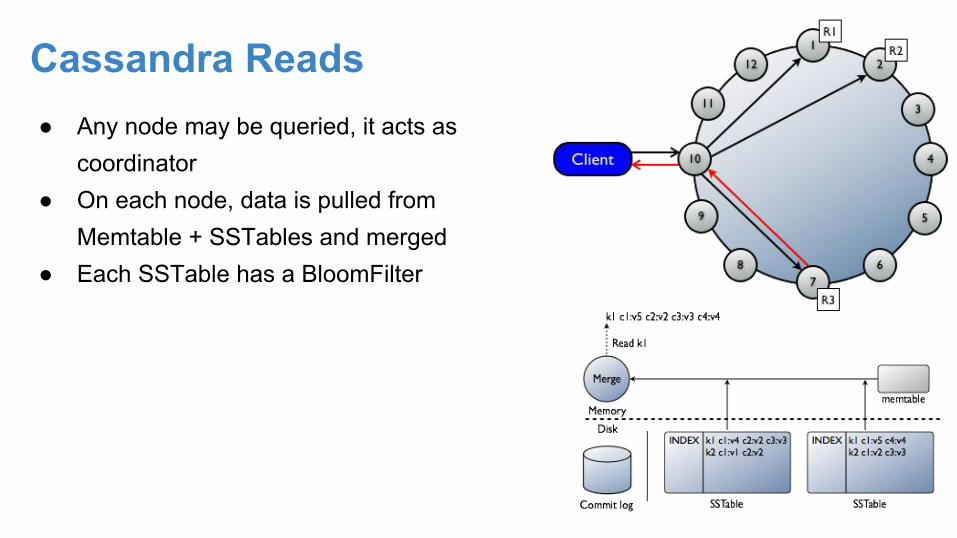
Cassandra Reads● Any node may be queried, it acts as
coordinator● On each node, data is pulled from
Memtable + SSTables and merged● Each SSTable has a BloomFilter

Cassandra is not...
● An In-Memory database
● A Key-Value storage (it has schema)
● A magical unicorn database that farts rainbow
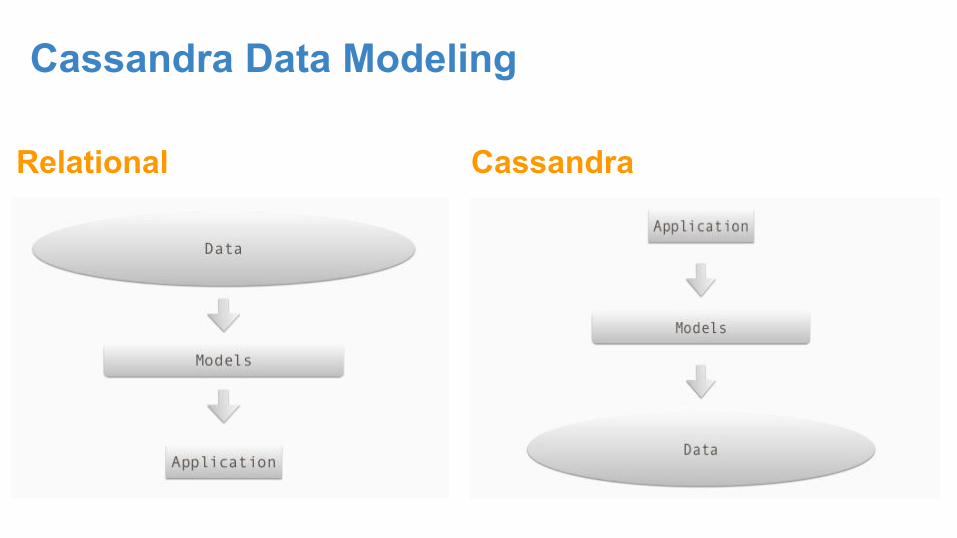
Cassandra Data Modeling
Relational Cassandra

CQL vs SQL
● no Sequences○ Natural Keys - email etc…○ Surrogate Keys - UUID
● no Order By - during select

Clustering Key// Comments for a given videoCREATE TABLE comments_by_video ( videoid uuid, comment_time timestamp, userid uuid, comment text, PRIMARY KEY (videoid, comment_time)) WITH CLUSTERING ORDER BY (comment_time DESC);
SELECT * FROM comments_by_video
videoid commendid userid comment
Video1 Dec 13, 11:00 user1 comment3
Video1 Dec 12, 15:00 user2 comment2
Video1 Dec 12, 12:00 user1 comment1
... ... ... ...
more comments more columns ...Dec 13, 11:00
user1, comment3Dec 12, 15:00user2, comment2
Dec 12, 12:00user1, comment3
Video1 Up to 2 Billion
New Data

Example: KillrVideo.comCREATE TABLE user_videos (
userid uuid,added_date timestamp,videoid uuid,name text,priview_image_location text,PRIMARY KEY (userid, added_date, video_id)
) WITH CLUSTERING ORDER BY (added_date DESC, video_id ASC);
// Index for tag keywordCREATE TABLE videos_by_tag (
tag text,videoid uuid,added_date timestamp,name text,priview_image_location text,tagged_date timestampPRIMARY KEY (tag, video_id)
);
// Index for tag keywordCREATE TABLE tags_by_letter (
first_letter text,tag text,PRIMARY KEY (first_letter, tag)
);
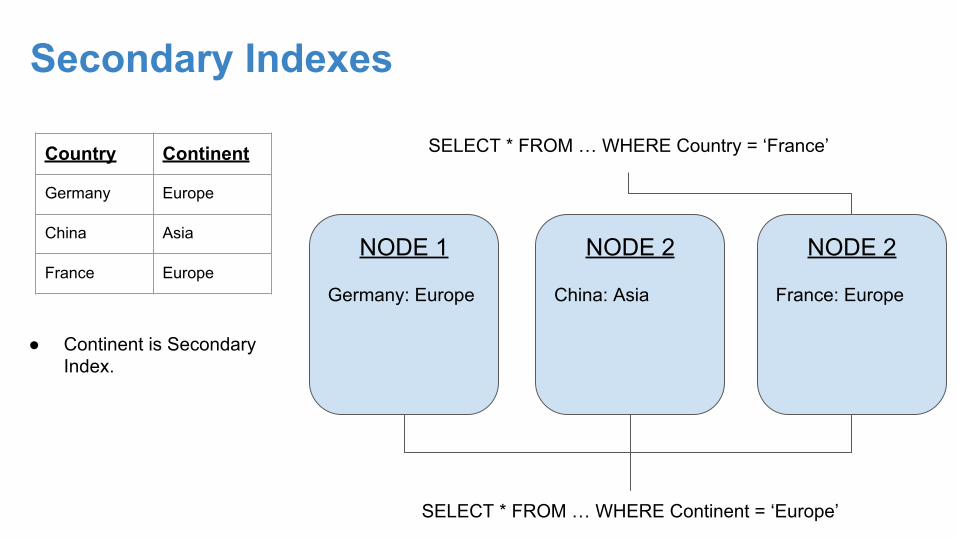
Secondary Indexes
Country Continent
Germany Europe
China Asia
France EuropeNODE 1
Germany: Europe
NODE 2
China: Asia
NODE 2
France: Europe
SELECT * FROM … WHERE Continent = ‘Europe’
SELECT * FROM … WHERE Country = ‘France’
● Continent is Secondary Index.


















