
Introduction to apache spark
11
INTRODUCTION TO APACHE SPARK JUGBD MEETUP #5.0 MAY 23, 2015 MUKTADIUR RAHMAN TEAM LEAD, M&H INFORMATICS(BD) LTD.
-
Upload
muktadiur-sajib -
Category
Technology
-
view
85 -
download
0
Transcript of Introduction to apache spark

INTRODUCTION TO APACHE SPARK JUGBD MEETUP #5.0MAY 23, 2015
MUKTADIUR RAHMAN TEAM LEAD, M&H INFORMATICS(BD) LTD.

OVERVIEW• Apache Spark is a cluster computing framework that provide :
• fast and general engine for large-scale data processing
• Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk
• Simple API in Scala, Java, Python
• This talk will cover :
• Components of Spark Stack
• Resilient Distributed DataSet(RDD)
• Programming with Spark

A BRIEF HISTORY OF SPARK
• Spark started by Matei Zaharia in 2009 as a research project in the UC Berkeley RAD Lab, later to become the AMPLab.
• Spark was first open sourced in March 2010 and transferred to the Apache Software Foundation in June 2013
• Spark had over 465 contributors in 2014,making it the most active project in the Apache Software Foundation and among Big Data open source projects
• Spark 1.3.1, released on April 17, 2015(http://www.apache.org/dyn/closer.cgi/spark/spark-1.3.1/spark-1.3.1-bin-hadoop2.6.tgz)
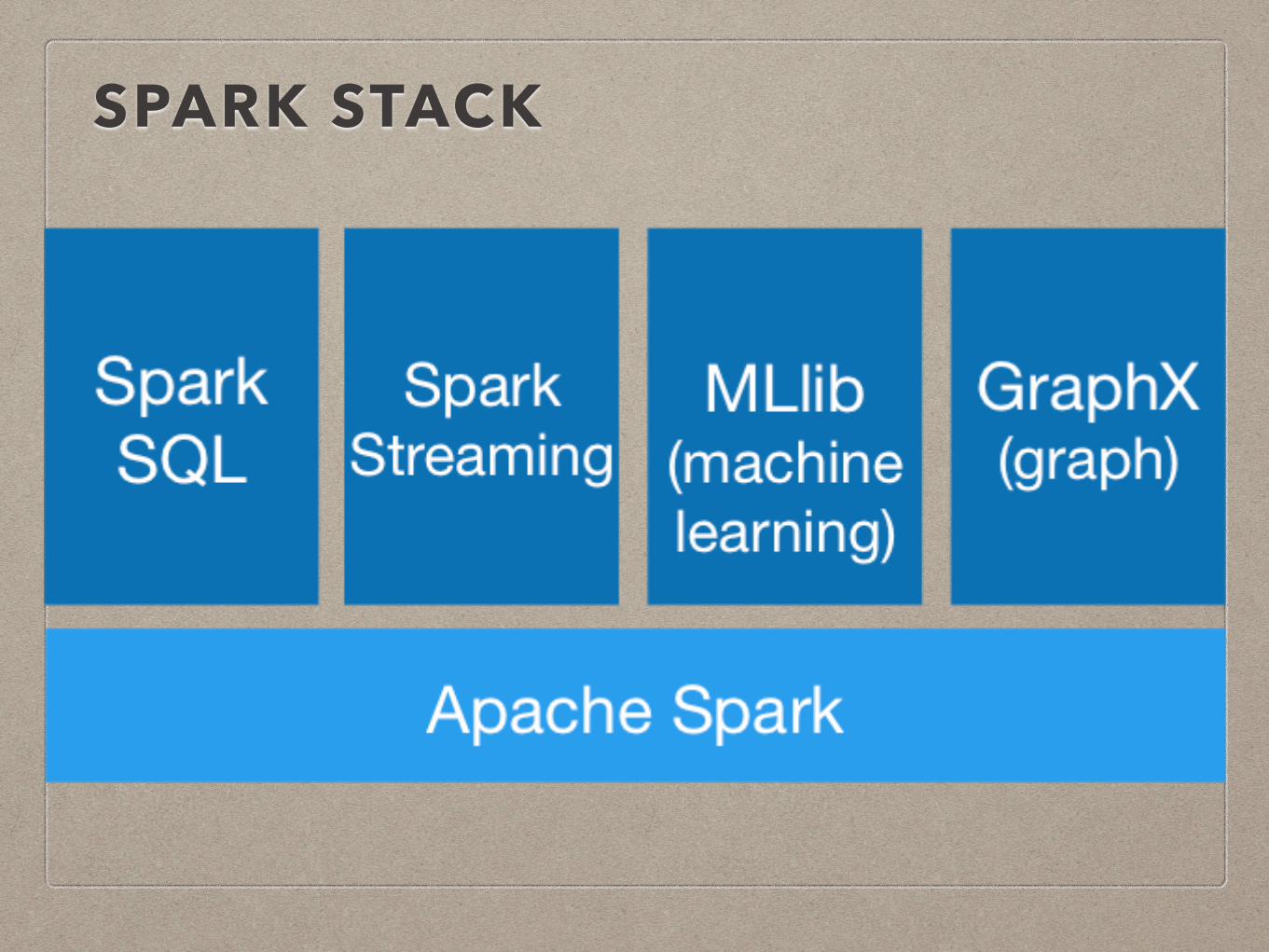
SPARK STACK

Resilient Distributed Datasets (RDD)
An RDD in Spark is simply an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster.
RDDs can be created in two ways: • by loading an external dataset
•scala> val reads = sc.textFile(“README.md”)
• by distributing a collection of objects•scala> val data = sc.parallelize(1 to 100000)

RDDOnce created, RDDs offer two types of operations:
• transformations • actions
Example : Step 1 : Create a RDD scala> val data = sc.textFile(“README.md")
Step 2: Transformation scala> val lines = data.filter(line=>line.contains(“Spark"))
Step 3: Action scala> lines.count()

RDDPersisting an RDD in memory Example : Step 1 : Create a RDDscala> val data = sc.textFile(“README.md")
Step 2: Transformation scala> val lines = data.filter(line=>line.contains(“Spark"))
Step 3: Persistent in memory scala> lines.cache() or lines.persist()
Step 4: Unpersist memory scala> lines.unpersist()
Step 5: Action scala> lines.count()

SPARK EXAMPLE : WORD COUNT
Scala>>
var data = sc.textFile(“README.md")
var counts = data.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)
counts.saveAsTextFile("/tmp/output")

SPARK EXAMPLE : WORD COUNT
Java 8>>
JavaRDD<String> data = sc.textFile(“README.md");
JavaRDD<String> words = data.flatMap(line -> Arrays.asList(line.split(" “)));
JavaPairRDD<String, Integer> counts = words.mapToPair(w -> new Tuple2<String, Integer>(w, 1))
.reduceByKey((x, y) -> x + y);
counts.saveAsTextFile(“/tmp/output“);

RESOURCES
• https://spark.apache.org/docs/latest/
• http://shop.oreilly.com/product/0636920028512.do
• https://www.edx.org/course/introduction-big-data-apache-spark-uc-berkeleyx-cs100-1x
• https://www.edx.org/course/scalable-machine-learning-uc-berkeleyx-cs190-1x
• https://www.facebook.com/groups/898580040204667/

Q/A
Thank YOU!


















