intro python II - Columbia Universitysh553/dip2014/intro python II.pdf · modules are re-usable...
24
Python II Shlomo Hershkop July 2014
Transcript of intro python II - Columbia Universitysh553/dip2014/intro python II.pdf · modules are re-usable...

Python IIShlomo Hershkop
July 2014

clean up time
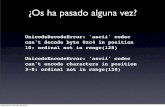
python allows easy clean up of input
string
lstrip
rstrip
remove trailing whitespace before/after/both from string

Regular Expressions
import re
language to describe patterns
find matches
replace matches
very flexible, need to understand how system works so can optimize it
re.search(pattern, str)

re.match(regexp,str,mod)
get match object
re.findall(regexp,str.mod)
find all matches
re.sub(regex, repl, string, n)
do replacement

building up a regular expression
basic string
‘shlomo’
re.findall(‘shlomo’,str,re.I)

character ranges
[aeiou]
[^aeiou]
flip it around
[a-z]
\d
[0-9]
\D
\s
whitespace
\w
alphanumeric

grouping
using parenthesis in the pattern
.group()
.group(n)
nth group, 1..n from left to right (opening)
can also name (?P<name> )

?
one or none {0,1}
+
at least one {1,}
*
zero or more {0,}
\d{3,5}

greedy matching
default is to match as wide as possible
inefficient
non greedy
.?
+?
*?

can limit:
^
start of str
$
end of str
quantifies
.
*
+
?

pat = re.compile(r”\s*(?P<header>[^:]+)\s*:(?P<value>.*?)\s*$")
!
bit hard to read
can use the verbose to allow you to inject whitespaces

pat = re.compile(r"""
\s* # Skip leading whitespace
(?P<header>[^:]+) # Header name
\s* : # Whitespace, and a colon
(?P<value>.*?) # The header's value -- *? used to
# lose the following trailing whitespace
\s*$ # Trailing whitespace to end-of-line
""", re.VERBOSE)

will do a lot more regular expressions
will get lots of practice

ip address
www.cnn.com
what happens when you type into the browser
x.x.x.x
!
how to write a regular expression to match ipv4 ?

pat = re.compile(“\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}")
but the problem will match 999.22.999.999
!
need extra function:

def valid_ip(address):
try:
host_bytes = address.split(‘.')
valid = [int(b) for b in host_bytes]
valid = [b for b in valid if b >= 0 and b<=255]
return len(host_bytes) == 4 and len(valid) == 4
except:
return False

sockets
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect(('www.py4inf.com', 80))
mysock.send('GET http://www.py4inf.com/code/romeo.txt HTTP/1.0\n\n')
while True:
data = mysock.recv(512)
if ( len(data) < 1 ) :
break
print data;
mysock.close()

import urllib
counts = dict()
fhand = urllib.urlopen('http://www.py4inf.com/code/romeo.txt')
for line in fhand:
words = line.split()
for word in words:
counts[word] = counts.get(word,0) + 1
print counts

command line programs
import os
os.system(‘run something’)
!
or
!
fh = os.popen(‘ls -la’)
s = fh.read()

more on modules
modules are re-usable pieces of python
import x
will look for x.py
x.foo - will look for foo in x
from x import foo, foo2
allows you to simply say foo or foo2

pyc
to improve running time, python will pre-compile modules into .pyc
be careful if you delete module, but its still being accessed :)

namespace
default code begins on __main__ namespace

md5
>>> import hashlib
>>> m = hashlib.md5()
>>> m.update("shlomo")
>>> m.digest()
'a\x11\xa4\xd2\xc5\xe5\xbd\x82\x9a\xdf2Y\x0c\x08\x8a\x93'
>>> m.hexdigest()
'6111a4d2c5e5bd829adf32590c088a93'

for file
import hashlib
def hashfile(afile, hasher, blocksize=65536):
buf = afile.read(blocksize)
while len(buf) > 0:
hasher.update(buf)
buf = afile.read(blocksize)
return hasher.digest()
[(fname, hashfile(open(fname, 'rb'), hashlib.md5()) for fname in fnamelst]