
Interconnect-Oriented Architecture and Circuits
18
Architecture and Circuits: 1 February 12, 1999 Interconnect-Oriented Architecture and Circuits William J. Dally Computer Systems Laboratory Stanford University February 12, 1998
-
Upload
desiree-bowers -
Category
Documents
-
view
49 -
download
2
description
Interconnect-Oriented Architecture and Circuits. William J. Dally Computer Systems Laboratory Stanford University February 12, 1998. On-chip wires. 0.0mm. 2.5mm. Minimum width wire in an 0.35 m m process. 5.0mm. 7.5mm. 10.0mm. On-chip wires are getting slower. x 2 = s x 1 0.5x - PowerPoint PPT Presentation
Transcript of Interconnect-Oriented Architecture and Circuits

Architecture and Circuits: 1 February 12, 1999
Interconnect-OrientedArchitecture and Circuits
William J. DallyComputer Systems Laboratory
Stanford UniversityFebruary 12, 1998

Architecture and Circuits: 2 February 12, 1999
On-chip wires
0.0mm
2.5mm
5.0mm
7.5mm
10.0mm
Minimum width wire in an 0.35m process

Architecture and Circuits: 3 February 12, 1999
On-chip wires are getting slower
x1 x2
y
y
x2 = s x1 0.5x
R2 = R1/s2 4x
C2 = C1 1x
tw2 = R2C2y2 = tw1/s2 4x
tw2/tg2= tw1/(tg1s3) 8x
v = 0.5(tgRC)-1/2 (m/s)
v2 = v1s1/2 0.7x
vtg = 0.5(tg/RC)1/2 (m/gate)
v2tg2 = v1tg1s3/2 0.35x
tw = RCy2 RCy2 RCy2
tg tg tg

Architecture and Circuits: 4 February 12, 1999
Technology scaling makes communication the scarce resource
0.35m64Mb DRAM
16 64b FP Proc400MHz
0.10m4Gb DRAM
1K 64b FP Proc2.5GHz
1998 2008
18mm12,000 tracks
1 clockrepeaters every 3mm
32mm90,000 tracks
20 clocksrepeaters every 0.4mm
P

Architecture and Circuits: 5 February 12, 1999
Architecture Must Evolve to Fit the Landscape
20 Clocks
90,000tracks
Local, parallel operations High bandwidthLow latency &Low power
Global operations Low bandwidthHigh latency &High power

Architecture and Circuits: 6 February 12, 1999
Architecture Today Depends on Fast Global Communication
Regs
I-Unit
• All instructions issued from single global instruction unit
• All data passes through global register file
• This won’t work when global accesses cost 20 clocks of latency
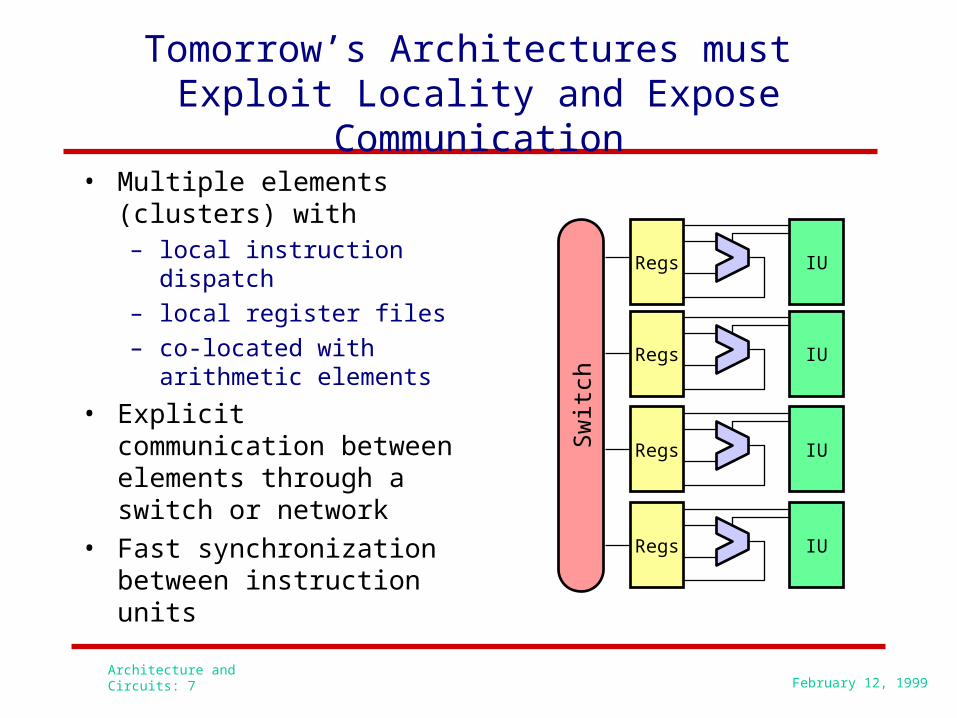
Architecture and Circuits: 7 February 12, 1999
Tomorrow’s Architectures must Exploit Locality and Expose
Communication• Multiple elements
(clusters) with – local instruction dispatch– local register files– co-located with
arithmetic elements
• Explicit communication between elements through a switch or network
• Fast synchronization between instruction units
Regs IU
Regs IU
Regs IU
Regs IU
Sw
itch

Architecture and Circuits: 8 February 12, 1999
Multi-ALU Processor Chip

Architecture and Circuits: 9 February 12, 1999
1x 1.64x 5.25x
Standard-CellFull-Custom Crafted-Cell80 Different Cells 7 Different Cells 17 Different Cells
Design
IRRDP
ADDSUB
Full-Custom
Crafted-Cell
Standard Cell
2.23x
2.7x
1.11x
1.17x
1.0x
1.0x
Performance
Area
-Results courtesy of Andrew Chang
Crafted-Cell Design

Architecture and Circuits: 10 February 12, 1999
Interconnect: repeaters with switching
• Need repeaters every 1mm or less
• Easy to insert switching– zero-cost reconfiguration
• Can’t afford decision time– static routing
• fixed or regular pattern
– source routing • on-demand• requires arbitration and
fanout
• Queuing and flow-control• Pipelining control
1mm
1mm
Arb LUT

Flit Interleave vs Virtual Channels(flow control through control layer) (6-flit message)
0
20
40
60
80
100
120
140
160
180
200
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Wormhole: 40bufs
Wormhole: 80bufs
Wormhole: 160bufs
VirtualChannels: 2vcsX4bufs = 40bufs
VirtualChannels: 4vcsX4bufs = 80bufs
VirtualChannels: 8vcsX4bufs=160bufs
VirtualChannels: 8vcsX8bufs=320bufs
Interleave: 40bufs
Interleave: 80bufs
Interleave: 160bufs

Architecture and Circuits: 12 February 12, 1999
Bandwidth Hierarchy
• Provide lots of bandwidth where its inexpensive– short wires between
ALUs
• Moderate bandwidth with intermediate cost– local RAM associated
with each ALU cluster
• Low bandwidth where its expensive– Global RAM with long
wires
• Very low bandwidth off chip
Globalon-chip
RAM
LocalRAM
LocalRAM
LocalRAM
LocalRAM
ALUCluster
ALUCluster
ALUCluster
ALUCluster
off chipglobal30mm
medium4mm
local1mm

Architecture and Circuits: 13 February 12, 1999
Bandwidth Hierarchy
• A key problem is to match the demands of an application to the bandwidth available at each level of the hierarchy
• Casting applications in a streaming model exposes much of the locality necessary to exploit the hierarchy
Globalon-chip
RAM
LocalRAM
LocalRAM
LocalRAM
LocalRAM
ALUCluster
ALUCluster
ALUCluster
ALUCluster

Architecture and Circuits: 14 February 12, 1999
Architecture Research Issues
• Processor architecture– configuration of ALUs
• clustered vs distributed
– method for controlling ALUs
• distributed control, VLIW, SIMD
– communication aware instruction sets
• how to hide details while exposing communication
• Memory architecture– methods for exploiting
2D spatial locality– communication aware
cache organizations
• Communication Architecture– on-chip interconnection
networks– the use of repeaters with
switching– the use of hierarchy and
selective ‘fat’ wires

Architecture and Circuits: 15 February 12, 1999
Circuit Challenges of Slow Interconnect
• The clock cycle is dominated by wire delay– novel circuits to improve
effective signal velocity
• Power is largely used to drive wires– low-swing on-chip
signaling methods– reject rather than
overpower noise
• Its difficult to distribute a global clock– locally synchronous
design methods– fast synchronizers
• no wait for metastable decay

Architecture and Circuits: 16 February 12, 1999
Overdrive gives 3x improvement in RC wire latency

Architecture and Circuits: 17 February 12, 1999
0 0.5 1 1.5 2 2.5 3 3.5 41.5
2
2.5
0 0.5 1 1.5 2 2.5 3 3.5 42.2
2.4
2.6
0 0.5 1 1.5 2 2.5 3 3.5 40
1
2
Low-Swing Overdrive Signaling
indata
reference
pc
+–x
x
x/2
x/2en
clk
1V Swing at Source
300mV Swing at Receiver
Recovered Signal

Architecture and Circuits: 18 February 12, 1999
ConclusionExploit, Don’t Fight, The Technology
• Interconnect is rapidly dominating the delay, power, and area of ICs
• Traditional architectures rely on global communication– they are ill-suited for an interconnect-dominated
technology
• Emerging architectures expose communication and exploit locality– distributed register files and instruction dispatch– bandwidth hierarchy
• Novel circuits can mitigate effects of slow wires– overdrive, low-swing signaling, locally synchronous
design
![Optical Interconnect [호환 모드] - High-Speed Circuits & …tera.yonsei.ac.kr/.../lecture/Optical_Interconnect.pdf · · 2012-12-05Optical interconnect based on dielectric waveguides](https://static.fdocuments.net/doc/165x107/5aa0e4367f8b9a67178ee41e/optical-interconnect-high-speed-circuits-tera-interconnect.jpg)

















