
Integrating monolithic and free-parts representations for improved face verification in the presence...
9
Integrating monolithic and free-parts representations for improved face verification in the presence of pose mismatch Simon Lucey * , Tsuhan Chen Advanced Multimedia Processing Laboratory, Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA 15213, USA Received 23 February 2005; received in revised form 10 October 2006 Available online 23 December 2006 Communicated by P.J. Flynn Abstract This paper concentrates specifically on the task of verifying faces when the gallery set stems from frontal face images with the probe set stemming from a number of alternate poses (i.e. pose mismatch). An argument is put forward for attempting to recognize faces through integrating holistic/monolithic and free-parts representations of the face. A contribution is made via the analysis of what traits, in a face, are most useful for each representation. As a result we are able to demonstrate that there is: (a) benefit in combining free-parts and monolithic representations, and (b) further benefit can be obtained by varying the weight placed on each representation as a function of viewpoint. Ó 2006 Elsevier B.V. All rights reserved. Keywords: Face recognition; Pose mismatch; Gaussian mixture models; Monolithic representation; Parts representation 1. Introduction Face verification with a change in viewpoint, between 2D gallery and 2D probe images, is inherently a difficult task. Images taken of the face from one pose, for the same subject, are markedly different to images captured under another pose. One can tell from visual inspection that pixel variation due to pose change is far greater than the varia- tion seen due to changes in identity. An example of this problem can be seen in Fig. 1. In this paper we will be deal- ing specifically with the problem of trying to verify clients from non-frontal viewpoint probe images given that only a single frontal view image of that client exists in the gallery. In cognitive science, theories abound over whether humans recognize faces based on component parts or holis- tic representations. In fact there is a large amount of liter- ature (Tanaka and Farah, 2003; Murray et al., 2003) indicating that both types of representations of the face are important in human face recognition in the presence of pose mismatch. We use the term monolithic in this paper to describe the holistic vectorized representation of the face based purely on pixel values within an image array, which can be associated with the holistic mechanism used in a human face recognition system. Similarly, we use the term parts to denote a representation of the face that can be con- sidered as an ensemble of image patches of the image array. The employment of parts representations for object/face detection has recently gained much attention and success in machine vision literature (Schneiderman et al., 2000; Weber et al., 2000a,b). For the task of face recognition we additionally categorize parts representations into two subsets namely rigid- and free-parts. Rigid-parts represen- tations assume the position/structure of the patches within the image is preserved. Free-parts representations assume that the position/structure of patches within the image can be relaxed so they can ‘‘freely’’ move to varying 0167-8655/$ - see front matter Ó 2006 Elsevier B.V. All rights reserved. doi:10.1016/j.patrec.2006.12.006 * Corresponding author. Tel.: +1 412 268 2889; fax: +1 412 268 3890. E-mail addresses: [email protected] (S. Lucey), [email protected] (T. Chen). www.elsevier.com/locate/patrec Pattern Recognition Letters 28 (2007) 895–903
-
Upload
simon-lucey -
Category
Documents
-
view
215 -
download
0
Transcript of Integrating monolithic and free-parts representations for improved face verification in the presence...

www.elsevier.com/locate/patrec
Pattern Recognition Letters 28 (2007) 895–903
Integrating monolithic and free-parts representations for improvedface verification in the presence of pose mismatch
Simon Lucey *, Tsuhan Chen
Advanced Multimedia Processing Laboratory, Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA 15213, USA
Received 23 February 2005; received in revised form 10 October 2006Available online 23 December 2006
Communicated by P.J. Flynn
Abstract
This paper concentrates specifically on the task of verifying faces when the gallery set stems from frontal face images with the probeset stemming from a number of alternate poses (i.e. pose mismatch). An argument is put forward for attempting to recognize facesthrough integrating holistic/monolithic and free-parts representations of the face. A contribution is made via the analysis of what traits,in a face, are most useful for each representation. As a result we are able to demonstrate that there is: (a) benefit in combining free-partsand monolithic representations, and (b) further benefit can be obtained by varying the weight placed on each representation as a functionof viewpoint.� 2006 Elsevier B.V. All rights reserved.
Keywords: Face recognition; Pose mismatch; Gaussian mixture models; Monolithic representation; Parts representation
1. Introduction
Face verification with a change in viewpoint, between2D gallery and 2D probe images, is inherently a difficulttask. Images taken of the face from one pose, for the samesubject, are markedly different to images captured underanother pose. One can tell from visual inspection that pixelvariation due to pose change is far greater than the varia-tion seen due to changes in identity. An example of thisproblem can be seen in Fig. 1. In this paper we will be deal-ing specifically with the problem of trying to verify clientsfrom non-frontal viewpoint probe images given that onlya single frontal view image of that client exists in thegallery.
In cognitive science, theories abound over whetherhumans recognize faces based on component parts or holis-
0167-8655/$ - see front matter � 2006 Elsevier B.V. All rights reserved.
doi:10.1016/j.patrec.2006.12.006
* Corresponding author. Tel.: +1 412 268 2889; fax: +1 412 268 3890.E-mail addresses: [email protected] (S. Lucey), [email protected]
(T. Chen).
tic representations. In fact there is a large amount of liter-ature (Tanaka and Farah, 2003; Murray et al., 2003)indicating that both types of representations of the faceare important in human face recognition in the presenceof pose mismatch. We use the term monolithic in this paperto describe the holistic vectorized representation of the facebased purely on pixel values within an image array, whichcan be associated with the holistic mechanism used in ahuman face recognition system. Similarly, we use the termparts to denote a representation of the face that can be con-sidered as an ensemble of image patches of the image array.The employment of parts representations for object/facedetection has recently gained much attention and successin machine vision literature (Schneiderman et al., 2000;Weber et al., 2000a,b). For the task of face recognitionwe additionally categorize parts representations into twosubsets namely rigid- and free-parts. Rigid-parts represen-tations assume the position/structure of the patches withinthe image is preserved. Free-parts representations assumethat the position/structure of patches within the imagecan be relaxed so they can ‘‘freely’’ move to varying

Gallery image
Probe set
Similar
identity
Similarappearance
Fig. 1. Example of the difficulty in recognizing subjects from a differentpose as images from the same pose, irrespective of identity, are moresimilar in terms of their pixel representation.
896 S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903
extents. Both rigid- and free-parts representations assumethere is minimal dependence between the appearance ofother patches within the image.
Considerable work has already been performed withmonolithic face representations, for automatic face recog-nition, in the presence of pose mismatch. Most notablytechniques like Tensorfaces (Vasilescu and Terzopoulos,2002), Eigenlight fields (Gross et al., 2004) and Fisherfaces(Lee and Kim, 2004) have been employed with varyingdegrees of success. There has also been some preliminarywork by Kanade and Yamada (2003) demonstrating thebenefit of a rigid-parts representation. In this methodweightings for each patch in the face are learnt off-line,from a world set, as a function of pose. Hitherto, the ben-efit of employing a free-parts representation has not beenfully investigated for the task of automated face verifica-tion in the presence of pose mismatch. Free-parts represen-tations have an inherent advantage over monolithic andrigid-parts representations in that they compare ‘‘distribu-tions’’ which are naturally able to cope with appearancevariation. In this paper we will be focussing on comparingfree-parts and monolithic representations as they are repre-sentative of ‘‘point’’ and ‘‘distribution’’ style classificationmechanisms for verification.
Recent work (Lucey et al., 2004; Sanderson and Paliwal,2003; Eickeler et al., 2000) has been conducted demonstrat-ing that good performance can be attained by employing afree-parts representation in the task of frontal view faceverification. Some generative models that have been previ-ously employed to model these free-parts face distributionsare: pseudo 2-D hidden Markov models (HMMs) (Eickeleret al., 2000) and Gaussian mixture models (GMMs) (Luceyet al., 2004; Sanderson and Paliwal, 2003). GMMs can bethought of as a special subset of HMMs where no posi-tional constraints are placed on the patch observationswhatsoever. This is a highly desirable characteristic whentrying to verify clients across pose as patch positions canvary wildly across viewpoints.
In this paper we will attempt to address the followingtwo questions with respect to face verification via mono-lithic and free-parts representations:
Q1: Are areas of the face which are often associated withbeing the most salient and discriminative (i.e. eyes,nose and mouth) equally important for all represen-tations of the face? Or can other traits such as skintexture play a larger role depending on the represen-tation employed?
Q2: Is there any benefit in combining the match-scoresresulting from a free-parts and monolithic representa-tion? Can additional benefit be gained by combiningthese scores in an unequal manner?
As a result of answering the above questions we will alsobe presenting an algorithm which we refer to as the free-parts and holistic integration (FHI) strategy. The FHIstrategy is able to give substantial performance improve-ment in comparison to current monolithic and free-partsapproaches in the presence of pose mismatch.
2. Monolithic representations
It is outside the scope of this paper to perform a largescale evaluation of all possible monolithic approaches.Instead we will be taking a sample of techniques that arerepresentative of current paradigms in pose robust face rec-ognition. These paradigms differ largely by how theyemploy the world set in their off-line training. We definethe world set as the set of observations used to obtainany data-dependent aspects of the verification algorithm(e.g. subspace, distribution, classifier, etc.), but does not
provide any client specific information like those found inthe on-line gallery and probe sets.
Specifically, we will be considering the Eigenface algo-rithm (Turk and Pentland, 1991) as a baseline due to itsubiquitous nature in face recognition literature. The Eigen-face algorithm can be thought of as being representative ofa paradigm that make matches based purely on pixelappearance. The Fisherface algorithm (Belhumeur et al.,1997) is also considered as a baseline due to its simplicityand high performance in recent evaluations (Navarreteand Ruiz-del-Solar, 2002; Ruiz-del-Solar and Navarrete,2002; Sadeghi et al., 2003). This algorithm can be thoughtof as being representative of a paradigm that attempts tolearn the within-class and between-class differencesbetween poses in the world set. Finally, the Eigenlight-fields technique will be used as a baseline due to its speci-ficity to pose and its similar nature to other popularapproaches such as Tensorfaces (Vasilescu and Terzopou-los, 2002) as well as the pose transformation technique ofLee and Kim (2004). These types of algorithms are repre-sentative of a paradigm that attempts to learn the relation-ships/transformations between each pose in the world set.
2.1. Eigen and Fisherfaces
Eigen and Fisherface approaches have been around forquite some time and have enjoyed much success in frontalpose face recognition. In this paper we will be evaluating a

S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903 897
specific type of Eigen and Fisherface strategy. The first,which will be referred to as MON-PCA, is the baselineEigenface (Turk and Pentland, 1991) technique whichemploys principal component analysis (PCA) to generatea subspace preserving the K = 89 most energy preservingmodes. The whitened cosine distance is then employed togain a measure of similarity between the gallery and probeobservation vectors which result after mapping the originalpixel images into the PCA generated subspace. We definethe whitened cosine distance as the cosine distance betweentwo vectors that have been whitened (see Duda et al., 2001for more details). The second technique which we shallrefer to as MON-LDA, is a variant on the Fisherface(Belhumeur et al., 1997) technique which employs lineardiscriminant analysis (LDA), after PCA, to generate asubspace preserving the K = 89 most discriminant modes.As suggested by (Navarrete and Ruiz-del-Solar, 2002;Ruiz-del-Solar and Navarrete, 2002; Sadeghi et al., 2003)good performance can be attained if we employ the cosinedistance to gain a measure of similarity.
2.2. Eigenlight field approach
Eigenlight fields were proposed by Gross et al. (2004) asa technique for learning the dependencies that existbetween monolithic representations of the face from differ-ent viewpoints. In their paper, Gross et al. (2004) arguethat a face’s light field is an ideal representation to performface recognition under varying pose as the representationnaturally encompasses all viewpoints. A face was assumedto stem from only a finite set of poses 1,2, . . . ,P. In theirwork a light field was represented as the concatenation ofthe vectorized viewpoint images xp such that f‘ ¼½xT
1 ; . . . ; xTP �
T (i.e. the light field was assumed to be repre-sented accurately from P sample viewpoints). From anensemble of K training light fields f‘kgK
k¼1 a set of eigenvec-tors V ¼ fvkgK
k¼1 (i.e. Eigenlight fields) can be foundthrough PCA that satisfy,
‘ ¼XK
k¼1
akvk þ �‘ ¼ vaþ �‘ ð1Þ
where �‘ is the sample mean of the light fields. As long as ‘lies in the same approximate subspace as the Eigenlightfields the vector a can be used as a compact pose-invariantrepresentation of that subject’s face. In practice however,one rarely has all possible viewpoints to construct a com-plete light field. In fact, it is quite common to only havea single gallery viewpoint. In this common scenario a leastsquares approximation of a can be found by
a � vþp xp þ �xp ð2Þ
where vp is the submatrix, referring to pose p, of the com-plete matrix of Eigenlight fields v = [v1, . . . ,vp, . . . ,vP]T. TheMoore–Penrose inverse, denoted by the + superscript, of vp
needs to be found to gain the least squares solution as theset of vectors contained in vp are not assured of being
orthonormal. Once the vector a is estimated the cosine dis-tance is used to gain a match-score between gallery andprobe images. Throughout the experimental portion of thispaper we shall refer to this specific technique as LF-PCA.
3. Free-parts representation
As mentioned earlier, a rigid-parts representation of theface employs a strict alignment between gallery and probeimage patches based on their spatial location. A free-partsrepresentation, however, has no strict alignment and allowspatches within both the gallery and probe images to vary‘‘freely’’. Due to this freedom in spatial position it is moreconvenient and computationally tractable (see Lucey et al.,2004 for more details) to match gallery and probe imagesbased on distributions rather than individual patches.
Learning the face as a distribution (i.e. many observa-tions), as opposed to a single observation, has manyappealing properties for face classification tasks. First,the many observations (representing the face) can exist ina low dimensional space circumventing problems associ-ated with the ‘‘curse of dimensionality’’ (Duda et al.,2001) when training a classifier with high dimensionalobservations. Second, by representing a face with manyobservation points one naturally has more observations(of a lower dimensionality) to aid in the estimation of aclassifier’s parameters. Through the use of GMMs tomodel the face distribution, it has been shown (Luceyet al., 2004; Sanderson and Paliwal, 2003) that good verifi-cation performance can be attained by throwing away mostposition/structure information. We refer to this type of facemodel as a free-parts GMM (FP-GMM). In this subsectionwe briefly explain what features we use to estimate the FP-GMM, how it is estimated and how we evaluate the GMMduring verification.
3.1. Free-parts GMM
To estimate or evaluate a FP-GMM for a subject, thesubject’s geometrically and statistically normalized imagesare first decomposed into 16 · 16 pixel image patches witha 75% overlap between horizontally and vertically adjacentpatches. Each image patch has a 2D-DCT applied to it inorder to compact the 256 elements into a feature vector oof dimensionality D. Based on preliminary experiments,we have chosen D = 35. Additional information aboutthe generation of the feature representations can beobtained from (Lucey et al., 2004; Sanderson and Paliwal,2003).
A GMM models the probability distribution of a D
dimensional random variable o as the sum of M multivar-iate Gaussian functions,
f ðojkÞ ¼XM
m¼1
wmNðo; lm;RmÞ ð3Þ

898 S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903
where Nðo; l;RÞ denotes the evaluation of a normal distri-bution for observation o with mean vector l and covari-ance matrix R. The weighting of each mixture componentis denoted by wm and must sum to unity across all compo-nents. In our work the covariance matrices in k areassumed to be diagonal such that R = diag{r}, as substan-tial benefit can be attained by reducing the number ofparameters that need to be estimated.
GMM parameters for a client are estimated through rel-evance adaptation (RA) (Lucey et al., 2004). RA is essen-tial for estimating a reasonable client GMM as theapproach employs both the on-line client’s single galleryimage and the off-line world set during estimation. WithoutRA, the client’s GMM would be too ‘‘tuned’’ to the client’straining observations due to the number of parameters thatmust typically be estimated within a GMM. Through RA itis possible to estimate a robust and discriminate GMMfrom a single gallery image.
The off-line world set is incorporated into RA through aworld model kw ¼ fwwm ; lwm
;RwmgMm¼1. A world model is a
single GMM trained from a large number of off-line sub-ject faces representative of the general population (i.e. theworld set). In our work we have found best performancewas attained when the world model was estimated usingfrontal observations only. This was done to ensure the finalclient model was discriminating against subject identityonly, and not other poses present in the world model. Thisis in stark contrast to other face recognition algorithmswhich typically need the off-line world set to match theon-line evaluation set in terms of the pose variation seen.
The world model’s parameters are estimated using theexpectation maximization (EM) algorithm (Dempsteret al., 1977) configured to maximize the likelihood of train-ing data. RA is an instance of the EM algorithm configuredfor maximum a posteriori (MAP) estimation, rather thansimply maximum likelihood (ML). It has been noted thatgreat benefit can be obtained, in terms of estimating highperformance robust FP-GMMs, by employing RA whenonly small amounts of client specific observations exist(e.g. a single enrollment image). Using RA, parametersfor client c are obtained using the following updateequations:
wcm ¼ b ð1� awmÞwwm þ aw
m
PRr¼1cmðorÞPM
m¼1
PRr¼1cmðorÞ
" #ð4Þ
lcm¼ ð1� al
mÞlwmþ al
m
PRr¼1cmðorÞorPR
r¼1cmðorÞð5Þ
rcm ¼ ð1� armÞ rwm þ l2
wm
� �þ ar
m
PRr¼1cmðorÞo2
rPRr¼1cmðorÞ
� l2cm
ð6Þ
where cm(o) is the occupation probability for mixture com-ponent m, l2 indicates that each element in l is squared,and aq
m is a weight used to tune the relative importanceof the prior; it is defined as
aqm ¼
PRr¼1cmðorÞ
sq þPR
r¼1cmðorÞð7Þ
where sq is a relevance factor. The above definition of aqm
can limit the adaptation to only the Gaussians for whichthere is sufficient data. We have found effective perfor-mance can be attained by using a single relevance factor(s = sw = sl = sr). Based on empirical evaluation on manydata sets, we have chosen s = 10. The scale factor, b, in Eq.(4) is computed to ensure that all the adapted compo-nent weights sum to unity. The adaptation procedure isiterative, thus an initial client model is required. This isaccomplished by copying the world model. Additionalinformation on RA can be found in (Lucey et al., 2004).
3.2. Evaluating a FP-GMM
To evaluate a sequence of observations, generated froma claimant’s probe image, we obtain the average log-likelihood,
LðojkcÞ ¼1
R
XR
r¼1
log f ðorjkcÞ ð8Þ
Given the average log-likelihood, for the client and worldmodels, one can then calculate the log-likelihood ratio,
KðoÞ ¼LðojkcÞ �LðojkwÞ ð9Þ
For our work we found good performance across posecould be attained if we employed GMMs with 512components.
4. Face database and verification
Experiments were performed on a subset of the FERETdatabase (Phillips et al., 2000), specifically images stem-ming from the ba, bb, bc, bd, be, bf, bg, bh, and bi subsets;which approximately refer to rotation’s about the verticalaxis of 0�, +60�, +40�, +25�, +15�, �15�, �25�, �40�,�60�, respectively. The database contains 200 subjectswhich were randomly divided into an evaluation and worldset both containing 90 subjects. When dealing with a finitedataset, typically a leave-one-out strategy is then used togenerate imposters from the evaluation set. Specifically,when one is evaluating the ith client model of N subjectsin the evaluation set the other N � 1 subjects are used asimposters. In many cases, however, this strategy is undesir-able when one is trying to gauge the ‘‘actual’’ verificationperformance of an algorithm as the imposter set is chang-ing for each subject’s model. To circumvent this problemwe have used the remaining 20 subjects of the FERETdatabase subset as a separate imposter set so as to ensurethe imposter set does not change. As mentioned previously,the world set is used to obtain any data-dependent aspectsof the verification system (e.g. subspace, world models,etc.). The evaluation and imposter sets are where the per-formance rates for the verification system are obtained. It

Probe Image
Gallery Im
age
OfflineLearning
Probe World Set
…..
Offline Online
…..
…..
…..
…..
Gal
lery
Wor
ld S
et
FaceVerifier
Yes/No?
Fig. 2. In any face recognition system there is an off-line and on-linecomponent. The off-line component trains the face verifier on a world set,which is representative of the non-client variation we anticipate seeing inthe gallery and probe images. It is usually easy to anticipate the galleryworld set, however it is usually an impossible task to anticipate all possibleprobe variations in the world probe set. A major advantage of the FP-GMM approach discussed in this paper is that it only requires the galleryportion of the world set for good performance. This ability is highlyadvantageous when having to verify faces from previously unseen poses.
Table 1Comparison of monolithic paradigms in the presence of a pose mismatchin terms of EER (%)
Pose MON-PCA LF-PCA MON-LDA
�60 26.67 14.58 13.33�40 17.78 12.20 9.93�25 10.22 11.27 6.64�15 6.67 10.00 4.56
15 6.67 11.11 6.4925 8.89 11.19 5.5840 15.55 14.24 9.0560 24.44 13.56 11.11
Average 14.61 12.27 8.34
In these results one can see for a modest world set size of 90 subjects acrossnine poses a strategy of learning the within-class differences, throughLDA, performs best overall.
S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903 899
must be emphasized that for all experiments in this paperthere is only a single gallery and probe image per subject.
Traditionally, before performing the act of face recogni-tion, some sort of geometric pre-processing has to go on toremove variations in the face due to rotation and scale. Thedistance and angle between the eyes has long been regardedas an accurate measure of scale and rotation in a face.However, this type of geometric normalization, basedpurely on the eye position, becomes problematic whenfaced with depth pose rotation due to a stretching of theimage in the y-axis. In our work we chose to employ thedistance from the eye line to the nose tip vertically to rem-edy the stretching problem. The final geometrically normal-ized cropped faces formed an 98 · 115 array of pixels (seeFig. 2 for example images used).
The face verification task is the binary process of accept-ing or rejecting the identity claim (i.e. the log-likelihoodratio or cosine distance match-score from the free-partsand monolithic recognizers respectively) made by a subjectunder test. A threshold Th needs to be found so as to makethe decision. Face verification performance is evaluated interms of two types of error: (a) being false rejection (FR)error, where a true client is rejected against their ownclaim, and (b) false acceptance (FA) errors, where animpostor is accepted as the falsely claimed subject. TheFA and FR errors increase or decrease in contrast to eachother based on the decision threshold Th set within the sys-tem. A simple measure for overall performance of a verifi-cation system is found by determining the equal error rate(EER) for the system, where FA = FR.
5. Leading monolithic techniques
Before embarking on our analysis of the differencesbetween leading monolithic representations and our pro-
posed free-parts representation algorithm (i.e. FP-GMMs)it is first important to establish which monolithic techniqueperforms best in the presence of pose mismatch for ourexperimental framework. Interesting work has alreadybeen conducted by Lee and Kim (2004) concerning whetherit is better to: (a) learn the within-class and between-classdifferences between poses (i.e. discriminant analysis), or(b) learn the relationships (i.e. transformations) betweeneach possible within-class variation/viewpoint.
The technique (Lee and Kim, 2004) employed to learntransformations between poses, although not explicitlythe same, is very similar to previous techniques like Eigen-light fields (Gross et al., 2004) and Tensorfaces (Vasilescuand Terzopoulos, 2002). In all three techniques a leastsquares linear mapping is learnt to transform from a previ-ously unseen pose of the claimant to one or many view-points (in the case of light fields) that have been seen inenrollment. In (Lee and Kim, 2004)’s work a combinationbetween the two paradigms seemed to work best, whereone first transformed the probe image to a frontal viewand then applied discriminant analysis to the result. Thisapproach was however, dependent on having ample devel-opment observations (they used over 245 subjects in theirworld set with only five poses) to learn both the transfor-mation and discriminant analysis subspace.
In our work we opted to only compare the paradigms ofdiscriminant analysis and transformation through theMON-LDA and LF-PCA approaches respectively, as theworld set we were employing (only 90 subjects with nineposes) gave poor results when trying to combine both par-adigms. In Table 1 one can see the results for all the mono-lithic approaches outlined in this paper.
Although by no means comprehensive, this analysis isinformative as it demonstrates that a monolithic paradigmthat attempts to learn the within-class and between-classdifferences (e.g. MON-LDA), as opposed to learning thewithin-class relationships/transformations (e.g. LF-PCA)tends to perform better with our pre-defined worldset. As expected, both techniques on average performedbetter than simple appearance techniques like Eigenfaces

900 S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903
(MON-PCA). An open issue for further investigation ishow the size and variation of the world set can affect whichmonolithic paradigm to employ.
6. Q1: Face traits and representation?
In the plethora of work that has been performed withmonolithic and rigid-parts approaches, for frontal viewface recognition, it has been demonstrated that the eye,nose and mouth regions are considered most salient forthe purposes of face recognition. Most notably the workby Moghaddam and Pentland (1997) concerning modularEigenspaces depicted the superior performance attainedby individually modeling components of the face (eyes,nose, mouth) and discarding the residual part of the face.A problem with face recognition across pose however,using monolithic and rigid-parts techniques, is that thesesalient areas are often the most warped and distorted dur-ing pose variation due to their 3D nature (e.g. the nose).An important question was raised during the developmentof our work: do free-parts representations of the face rely on
these same salient areas prone to large non-linear variation
from pose change?In Fig. 3 one can see a number of evaluation images, in
the first column, along with their associated log-likelihoodratio (LLR) score maps. The LLR-maps were generated byevaluating the a client’s FP-GMM at each patch within theimage. If one was to take the sum of the LLR values in themap, they would result in the final LLR values for that
Images LLR-map
= 0.1850
= 0.0152
= -0.0206
Fig. 3. Depiction of grayscale images in column 1 with their respectiveFP-GMM log-likelihood ratio (LLR) maps in column 2. Row 1 depictsthe client’s train image used to estimate the FP-GMM. Row 2 depicts theclient in a non-frontal pose, which was not employed in training. Row 3depicts an imposter in frontal view. To the right of column 2 one can seethe total LLR values for each image demonstrating the pose-invariantproperties of the FP-GMM algorithm (i.e. row 2 has a higher total LLRthan row 3).
claimant image which is consistent with Eqs. (8) and (9).Inspecting the LLR-maps in Fig. 3 one can see that regionsof the face that are often associated with being most salientfor recognition in monolithic and rigid-parts representa-tions (i.e. the eye and nose regions) are extremely dark.The darkness of a patch indicates their minimal contribu-tion to the free-parts verification process. Other areas ofthe face which have often thought to be of minimal benefitin monolithic and rigid-parts representations such as thebrow, cheeks and nose bridge demonstrate a very high con-tribution to the free-parts verification process. This leads usto propose a hypothesis. Do free-parts techniques, like theone employed by the FP-GMM, actually learn the client’sskin texture and not other traits (i.e. eyes and nose) of theface long thought to be essential for good face recognition?
There is strong evidence to support this hypothesis. Inprevious work (Lucey, 2004), for the task of frontal faceverification, a complimentary relationship between mono-lithic and free-parts based representations was first estab-lished. In those experiments we were able to demonstratethat monolithic type approaches like Fisherfaces operatepredominantly on the lower-frequency information con-tained in the face. Free-parts based techniques, however,like our own FP-GMM technique are quite dependent onhigher-frequency traits, like skin texture, contained in theface while largely ignoring the global structure of the faceimage. In Fig. 4 we have extended that experiment forthe specific pose mismatch of +15�. In this experiment wecompare free-parts (FP-GMM) and monolithic (MON-LDA) approaches as a function of r which is the varianceof the Gaussian kernel being used as a low-pass filter.Results again demonstrate that the free-parts algorithm isvery sensitive to the amount of high-frequency information
0.5 1 1.5 2 2.5 32
3
4
5
6
7
8
Gaussian Blurring Kernel (σ)
EE
R (
%)
Free–Parts
Monolithic
Fig. 4. Effect of varying r on free-parts (FP-GMM) and monolithic(MON-LDA) algorithms in terms of EER. The r variable is the varianceof the Gaussian kernel being used to blur the face images. Results aredepicted for pose mismatch +15�.
0° 15° 25° 40° 60°
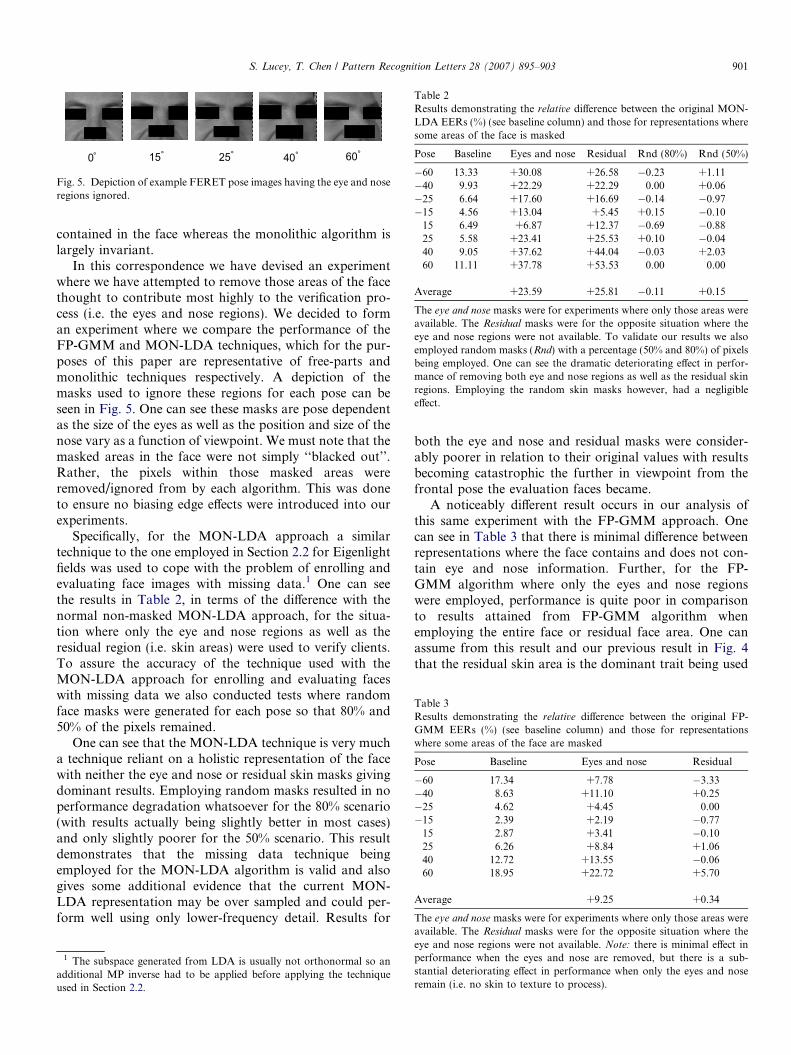
Fig. 5. Depiction of example FERET pose images having the eye and noseregions ignored.
Table 2Results demonstrating the relative difference between the original MON-LDA EERs (%) (see baseline column) and those for representations wheresome areas of the face is masked
Pose Baseline Eyes and nose Residual Rnd (80%) Rnd (50%)
�60 13.33 +30.08 +26.58 �0.23 +1.11�40 9.93 +22.29 +22.29 0.00 +0.06�25 6.64 +17.60 +16.69 �0.14 �0.97�15 4.56 +13.04 +5.45 +0.15 �0.10
15 6.49 +6.87 +12.37 �0.69 �0.8825 5.58 +23.41 +25.53 +0.10 �0.0440 9.05 +37.62 +44.04 �0.03 +2.0360 11.11 +37.78 +53.53 0.00 0.00
Average +23.59 +25.81 �0.11 +0.15
The eye and nose masks were for experiments where only those areas wereavailable. The Residual masks were for the opposite situation where theeye and nose regions were not available. To validate our results we alsoemployed random masks (Rnd) with a percentage (50% and 80%) of pixelsbeing employed. One can see the dramatic deteriorating effect in perfor-mance of removing both eye and nose regions as well as the residual skinregions. Employing the random skin masks however, had a negligibleeffect.
Table 3Results demonstrating the relative difference between the original FP-GMM EERs (%) (see baseline column) and those for representationswhere some areas of the face are masked
Pose Baseline Eyes and nose Residual
�60 17.34 +7.78 �3.33�40 8.63 +11.10 +0.25�25 4.62 +4.45 0.00�15 2.39 +2.19 �0.77
15 2.87 +3.41 �0.1025 6.26 +8.84 +1.0640 12.72 +13.55 �0.0660 18.95 +22.72 +5.70
Average +9.25 +0.34
The eye and nose masks were for experiments where only those areas were
S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903 901
contained in the face whereas the monolithic algorithm islargely invariant.
In this correspondence we have devised an experimentwhere we have attempted to remove those areas of the facethought to contribute most highly to the verification pro-cess (i.e. the eyes and nose regions). We decided to forman experiment where we compare the performance of theFP-GMM and MON-LDA techniques, which for the pur-poses of this paper are representative of free-parts andmonolithic techniques respectively. A depiction of themasks used to ignore these regions for each pose can beseen in Fig. 5. One can see these masks are pose dependentas the size of the eyes as well as the position and size of thenose vary as a function of viewpoint. We must note that themasked areas in the face were not simply ‘‘blacked out’’.Rather, the pixels within those masked areas wereremoved/ignored from by each algorithm. This was doneto ensure no biasing edge effects were introduced into ourexperiments.
Specifically, for the MON-LDA approach a similartechnique to the one employed in Section 2.2 for Eigenlightfields was used to cope with the problem of enrolling andevaluating face images with missing data.1 One can seethe results in Table 2, in terms of the difference with thenormal non-masked MON-LDA approach, for the situa-tion where only the eye and nose regions as well as theresidual region (i.e. skin areas) were used to verify clients.To assure the accuracy of the technique used with theMON-LDA approach for enrolling and evaluating faceswith missing data we also conducted tests where randomface masks were generated for each pose so that 80% and50% of the pixels remained.
One can see that the MON-LDA technique is very mucha technique reliant on a holistic representation of the facewith neither the eye and nose or residual skin masks givingdominant results. Employing random masks resulted in noperformance degradation whatsoever for the 80% scenario(with results actually being slightly better in most cases)and only slightly poorer for the 50% scenario. This resultdemonstrates that the missing data technique beingemployed for the MON-LDA algorithm is valid and alsogives some additional evidence that the current MON-LDA representation may be over sampled and could per-form well using only lower-frequency detail. Results for
1 The subspace generated from LDA is usually not orthonormal so anadditional MP inverse had to be applied before applying the techniqueused in Section 2.2.
both the eye and nose and residual masks were consider-ably poorer in relation to their original values with resultsbecoming catastrophic the further in viewpoint from thefrontal pose the evaluation faces became.
A noticeably different result occurs in our analysis ofthis same experiment with the FP-GMM approach. Onecan see in Table 3 that there is minimal difference betweenrepresentations where the face contains and does not con-tain eye and nose information. Further, for the FP-GMM algorithm where only the eyes and nose regionswere employed, performance is quite poor in comparisonto results attained from FP-GMM algorithm whenemploying the entire face or residual face area. One canassume from this result and our previous result in Fig. 4that the residual skin area is the dominant trait being used
available. The Residual masks were for the opposite situation where theeye and nose regions were not available. Note: there is minimal effect inperformance when the eyes and nose are removed, but there is a sub-stantial deteriorating effect in performance when only the eyes and noseremain (i.e. no skin to texture to process).

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
2
4
6
8
10
12
14
16
18
EE
R (
%)
α
60°
40°
25°
15°
Fig. 6. Effect of varying a in the FHI strategy for various poses. Note:minimum EERs are achieved at different values of a depending on pose.Larger non-frontal pose angles are far more sensitive to the correctselection of a than smaller non-frontal pose angles.
0
5
10
15
20
25
-60 -40 -20 0 20 40 60
Pose (degrees)
EER (%)
MonolithicFree PartsFHI (α = 0.75)FHI (α = 0.5)
Fig. 7. Final results demonstrating the benefit of a FHI strategy across allposes compared with monolithic (MON-LDA) and free-parts (FP-GMM)representations. Results also demonstrate that an unequal weighting ofa = 0.75 between monolithic and free-parts match-scores producesimproved results at the larger non-frontal viewpoints.
902 S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903
for verification with the FP-GMM approach. Interestinglyhowever, the eye and nose only performance is still compa-rable with the leading monolithic technique (i.e. MON-LDA) for slightly off frontal viewpoints. One hypothesisfor this result could be that there is some benefit in obtain-ing different FP-GMM representations for different salientregions of the face; as their may be a tendency for the FP-GMM algorithm to learn the most dominating trait (i.e.the skin texture) and not other traits when learning is donein an unsupervised manner.
7. Q2: A rationale for integration?
One can see from the previous section that there isstrong evidence that the monolithic and free-parts repre-sentations employ different or at least place unequalweights on different traits of the face. Heuristically wehypothesize that there should be some benefit in combiningthese two representations, which the concluding experi-ments of the paper attempt to explore. We refer to the com-bination of these two representations as a free-parts andholistic integration (FHI) strategy.
We employ the sum rule for combining the match-scoresfrom the classifiers of the two representations. Kittler et al.(1998) demonstrated that the sum rule can obtain goodperformance in classifier combination, when the two classi-fiers are diverse and produce match-scores approximatelyrepresentative of their true a posteriori probabilities. Thefinal combined match-score is generated by
ms ¼ a logsigðKÞ|fflfflfflfflfflffl{zfflfflfflfflfflffl}free parts
þð1� aÞ logsigðdCOSÞ|fflfflfflfflfflfflfflfflffl{zfflfflfflfflfflfflfflfflffl}monolithic
ð10Þ
where logsig(a) = 1/(1 + exp(�a)) is used to try and makethe match-scores obtained from the MON-LDA and FP-GMM algorithms more representative of their true a poste-riori probabilities. The employment of the logsig operationresults in the synergetic combination of match-scores fromthe MON-LDA and FP-GMM algorithms. A weightingfactor a, which was allowed to vary between zero andone, was employed with the sum rule so as to place moreemphasis on one representation over another as a functionof pose. One can see in Fig. 6 an example of how the var-iation of a can affect performance of the FHI algorithm.Through a cross-validation process the performance seenin Fig. 6 tended to vary however, one could see two trendsemerge. First, that the weighting factor should be greaterthan 0.5 for all poses, indicating more emphasis shouldnearly always be placed on the free-parts representationthan the monolithic representation in the presence of posemismatch. Second, the further in viewpoint from the fron-tal pose the probe image becomes the more sensitive theFHI algorithm becomes to the correct selection of a, asdepicted in Fig. 6. From cross-validation we found ana = 0.75 performed best at the larger viewpoints of ±45�and 60� with the smaller viewpoints being largely insensi-tive to the selection.
Fig. 7 compares four strategies: FHI with a = 0.5, FHIwith a = 0.75, MON-LDA and FP-GMM. One can seethe FHI strategy outperforms both monolithic and free-parts algorithms across all poses and in most cases by asubstantial margin. One can also see that the accurateselection of an appropriate weight a makes a difference inverification performance for larger non-frontal viewpoints.
8. Summary and conclusions
The FHI results presented in this paper give convincingevidence that there is benefit in combining monolithic and

S. Lucey, T. Chen / Pattern Recognition Letters 28 (2007) 895–903 903
free-parts representations for the purposes of automaticface verification in the presence of pose mismatch. We haveadditionally made the novel contribution in offering evi-dence that free-parts representations of the face may beplacing greater emphasis on traits of the face, such as skintexture, that canonical monolithic representations at themoment do not employ. This insight gives further explana-tion into why these two representations are able to be inte-grated in such a synergetic manner, as they are attemptingto verify subjects based on two different and diverse traitsof the face.
Currently our FHI framework uses an ad hoc techniqueto calculate an appropriate weighting factor for use acrossall poses. In future work we would like to explore a moreempirical and pose-dependent weighting strategy for largerviewpoints. In additional future work we would like toincorporate a rigid-parts based algorithm into our integra-tion strategy to see if further synergetic performance can beattained.
References
Belhumeur, P.N., Hespanha, J.P., Kriegman, D.J., 1997. Eigenfaces vs.fisherfaces: Recognition using class specific linear projection. IEEETrans. PAMI 19 (7), 711–720.
Dempster, A., Laird, N., Rubin, D., 1977. Maximum likelihood fromincomplete data via the EM algorithm. Roy. Statist. Soc. 39, 1–38.
Duda, R.O., Hart, P.E., Stork, D.G., 2001. Pattern Classification, seconded. John Wiley & Sons, New York, NY, USA.
Eickeler, S., Muller, S., Rigoll, S., 2000. Recognition of JPEG compressedface images based on statistical methods. Image Vision Comput. 18 (4),279–287.
Gross, R., Matthews, I., Baker, S., 2004. Appearance-based face recog-nition and light-fields. IEEE Trans. PAMI 26 (4), 449–465.
Kanade, T., Yamada, A., 2003. Multi-subregion based probabilisticapproach toward pose-invariant face recognition. In: IEEE Interna-tional Symposium on Computational Intelligence in Robotics andAutomation. Kobe, Japan, pp. 954–958.
Kittler, J., Hatef, M., Duin, R., Matas, J., 1998. On combining classifiers.IEEE Trans. PAMI 20 (3), 226–239.
Lee, H., Kim, D., 2004. Pose invariant face recognition using linear posetransformation in feature space. In: European Conference on Com-puter Vision (ECCV).
Lucey, S., June 2004. The symbiotic relationship of parts and monolithicface representations in verification. In: International Workshop onFace Processing in Video (FPIV), Washington DC.
Lucey, S., Chen, T., June 2004. A GMM parts based face representationfor improved verification through relevance adaptation. In: IEEEConference on Computer Vision and Pattern Recognition (CVPR),vol. II, Washington DC, pp. 855–861.
Moghaddam, B., Pentland, A., 1997. Probabilistic visual learning forobject recognition. IEEE Trans. PAMI 19 (7), 696–710.
Murray, J.E., Rhodes, G., Schuchinsky, M., 2003. When is a face not aface. In: Peterson, M.A., Rhodes, G. (Eds.), Perception of Faces,Objects, and Scenes. Oxford University Press, pp. 75–91 (Chapter 3).
Navarrete, P., Ruiz-del-Solar, J., 2002. Analysis and comparison ofeigenspace-based face recognition approaches. Int. J. Pattern Recog-nition Artificial Intell. 16 (7), 817–830.
Phillips, P.J., Moon, H., Rizvi, S.A., Rauss, P.J., 2000. The FERETevaluation methodology for face-recognition algorithms. IEEE Trans.PAMI 10 (22), 1090–1104.
Ruiz-del-Solar, J., Navarrete, P., August 2002. Towards a generalizedeigenspace-based face recognition framework. In: 4th Int. Workshopon Statistical Techniques in Pattern Recognition, Windsor, Canada.
Sadeghi, M., Kittler, J., Kostin, A., Messer, K., 2003. A comparativestudy of automatic face verification algorithms on the BANCAdatabase. In: AVBPA. pp. 35–43.
Sanderson, C., Paliwal, K., 2003. Fast features for face authenticationunder illumination direction changes. Pattern Recognition Lett. 24(14), 2409–2419.
Schneiderman, H., Kanade, T., September 2000. A histogram-basedmethod for detection of faces and cars. In: IEEE Conference onComputer Vision and Pattern Recognition (CVPR). pp. 504–507.
Tanaka, J.W., Farah, M.J., 2003. The holistic representation of faces. In:Peterson, M.A., Rhodes, G. (Eds.), Perception of Faces, Objects, andScenes. Oxford University Press, pp. 53–74 (Chapter 2).
Turk, M., Pentland, A., 1991. Eigenfaces for recognition. J. Cogn.Neurosci. 3 (1).
Vasilescu, M.A.O., Terzopoulos, D., 2002. Multilinear analysis of imageensembles: TensorFaces. In: European Conference on ComputerVision (ECCV) of Lecture Notes in Computer Science, vol. 2350.Springer-Verlag, Berlin, pp. 447–460.
Weber, M., Welling, M., Perona, P., June 2000a. Towards automaticdiscovery of object categories. In: IEEE Conference on ComputerVision and Pattern Recognition (CVPR). pp. 101–108.
Weber, M., Welling, M., Perona, P., 2000b. Unsupervised learning ofmodels for recognition. In: European Conference on Computer Vision(ECCV). pp. 18–32.


















