
InfoGAIL: Intepretable Imitation Learning from Visual...
15
InfoGAIL: Intepretable Imitation Learning from Visual Demonstrations (NIPS 2017) Nayeong Kim ([email protected]) Machine Learning Group, Department of Computer Science and Engineering, POSTECH, 77 Cheongam-ro, Nam-gu, Pohang-si 37673, Gyungsangbuk-do, Republic of Korea Feb 20, 2018
Transcript of InfoGAIL: Intepretable Imitation Learning from Visual...

InfoGAIL: Intepretable
Imitation Learning from Visual
Demonstrations
(NIPS 2017)
Nayeong Kim ([email protected])
Machine Learning Group,
Department of Computer Science and Engineering,
POSTECH, 77 Cheongam-ro, Nam-gu, Pohang-si 37673,
Gyungsangbuk-do, Republic of Korea
Feb 20, 2018

Introduction
• Imitation Learning
: mimic expert behavior without access to an explicit reward signal.
Inverse reinforcement learning(IRL): the process of deriving a reward function from observed behavior.
Apperenticeship learning(AL): there is no obvious reward function intuitively.
2

Generative Adversarial Imitation Learning
• Discriminator D tries to distinguish between expert
trajectories and ones from policy 𝜋.
min𝜋
max𝐷
𝔼𝜋 𝑙𝑜𝑔𝐷 𝑠, 𝑎 + 𝔼𝜋𝐸 log 1 − 𝐷 𝑠, 𝑎 − 𝜆𝐻(𝜋)
• Generator G samples trajectories from policy
𝜏𝑖~𝜋𝜃𝑖(𝑐𝑖)
3
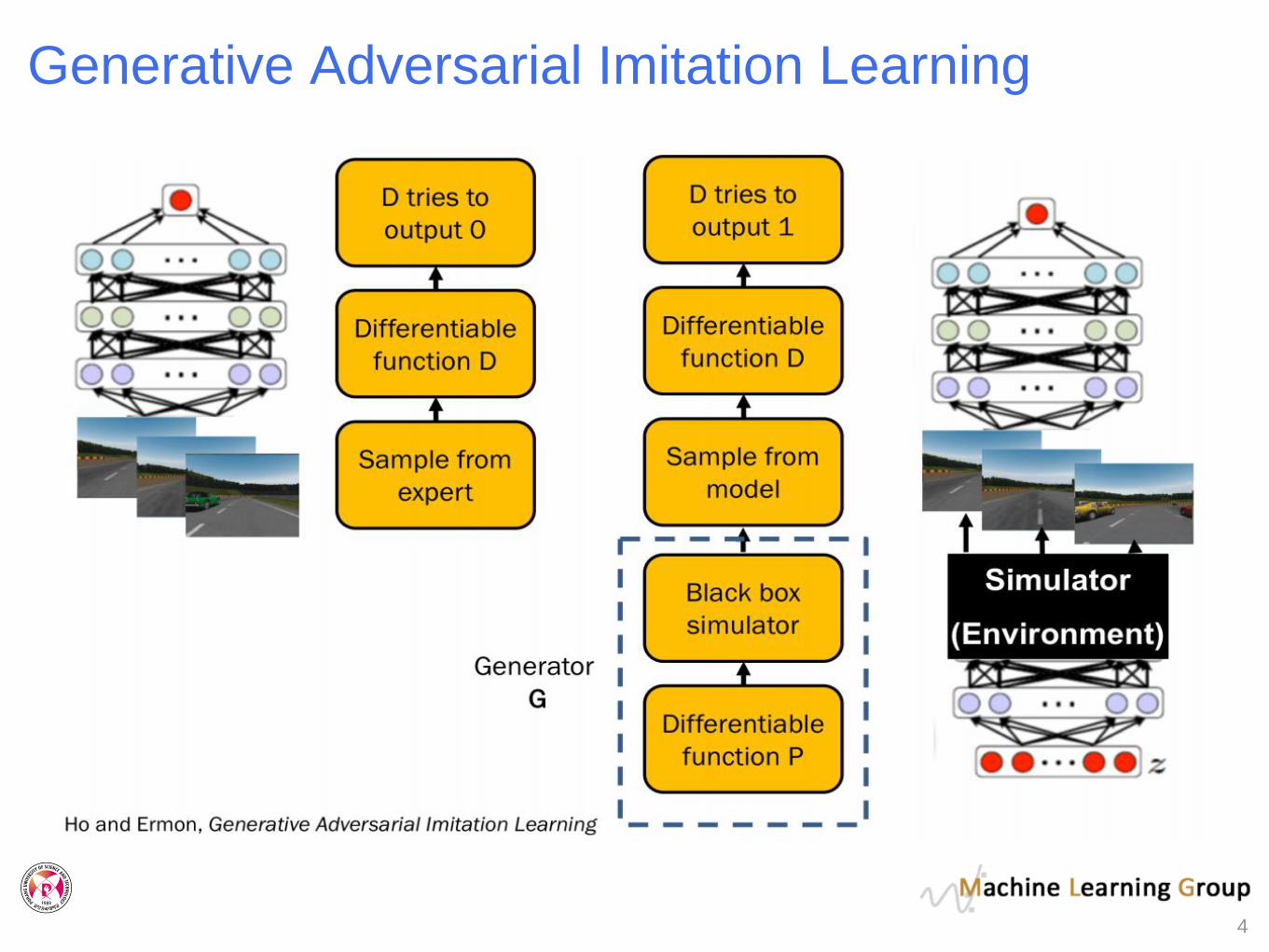
Generative Adversarial Imitation Learning
4

InfoGAIL
• Can disentangle different behaviors (modes).
• Can do imitation learning from raw images.
• Can be used to anticipate actions.
5

Interpretable Imitation Learning
• Introduce a latent variable/code c.
𝜋𝐸 = {𝜋𝐸0, 𝜋𝐸
1 , … }
𝒄~𝒑 𝒄 , 𝝅~𝒑 𝝅 𝒄 , 𝑠0~𝜌0, 𝑠𝑡+1~𝑃 𝑠𝑡+1 𝑎𝑡 , 𝑠𝑡 , 𝑎𝑡~𝜋(𝑎𝑡|𝑠𝑡)
• Imitate while maximizing the mutual information(MI) between
(1) the latent code
(2) the observed trajectories
6

Interpretable Imitation Learning
𝐼 𝑐; 𝜏 = 𝐻 𝑐 − 𝐻 𝑐 𝜏
= 𝔼𝑎~𝜏 𝔼𝑐′~𝑝 𝑐 𝑥 log 𝑃 𝑐′ 𝑥 + 𝐻 𝑐
= 𝔼𝑎~𝜏 𝐾𝐿 𝑝 ∙ 𝑎 𝑄 ∙ 𝑎 + 𝔼𝑐′~𝑝 𝑐 𝑎 𝑙𝑜𝑔𝑄 𝑐′ 𝑎 + 𝐻 𝑐
≥ 𝔼𝑎~𝜏,𝑐~𝑝 𝑐 𝑙𝑜𝑔𝑄 𝑐 𝑎 + 𝐻 𝑐
= 𝐿𝐼 𝜋, 𝑄
7
≥ 𝟎

Interpretable Imitation Learning
• 𝐿𝐼(𝜋, 𝑄) is a variational lower bound of MI
𝐿𝐼 𝜋, 𝑄 = 𝔼𝑐~𝑝 𝑐 ,𝑎~𝜋 ∙ 𝑠, 𝑐 log𝑄 𝑐 𝜏 + 𝐻(𝑐)
where Q is an approximation to the posterior.
• Objective function
min𝜋,𝑄
max𝐷
𝔼𝜋 𝑙𝑜𝑔𝐷 𝑠, 𝑎 + 𝔼𝜋𝐸 log 1 − 𝐷 𝑠, 𝑎 − 𝝀𝟏𝑳𝑰(𝝅,𝑸) − 𝜆2𝐻(𝜋)
8

Interpretable Imitation Learning
9
Part of
discriminator
Part of
posterior approximation
Part of policy

InfoGAIL training
• Reward Augmentation
Incorporate prior knowledge by adding state-based incentives
𝜂 𝜋𝜃 = 𝔼𝑠~𝜋𝜃 𝑟 𝑥 .
• Improved Objective
Using WGAN to alleviate the problems of
(1) Vanishing gradient
(2) Mode collapse
min𝜃,𝜓
max𝜔
𝔼𝜋𝜃 𝐷𝜔 𝑠, 𝑎 − 𝔼𝜋𝐸 𝐷𝜔 𝑠, 𝑎 − 𝜆0𝜂 𝜋𝜃 − 𝜆1𝐿𝐼(𝜋𝜃 , 𝑄𝜓)
• Variance Reduction
Baselines, Replay Buffers, etc.
• Transfer Learning for Visual Inputs
Extract features from a pre-trained network.
10

Interpretable Imitation Learning
11
WGAN
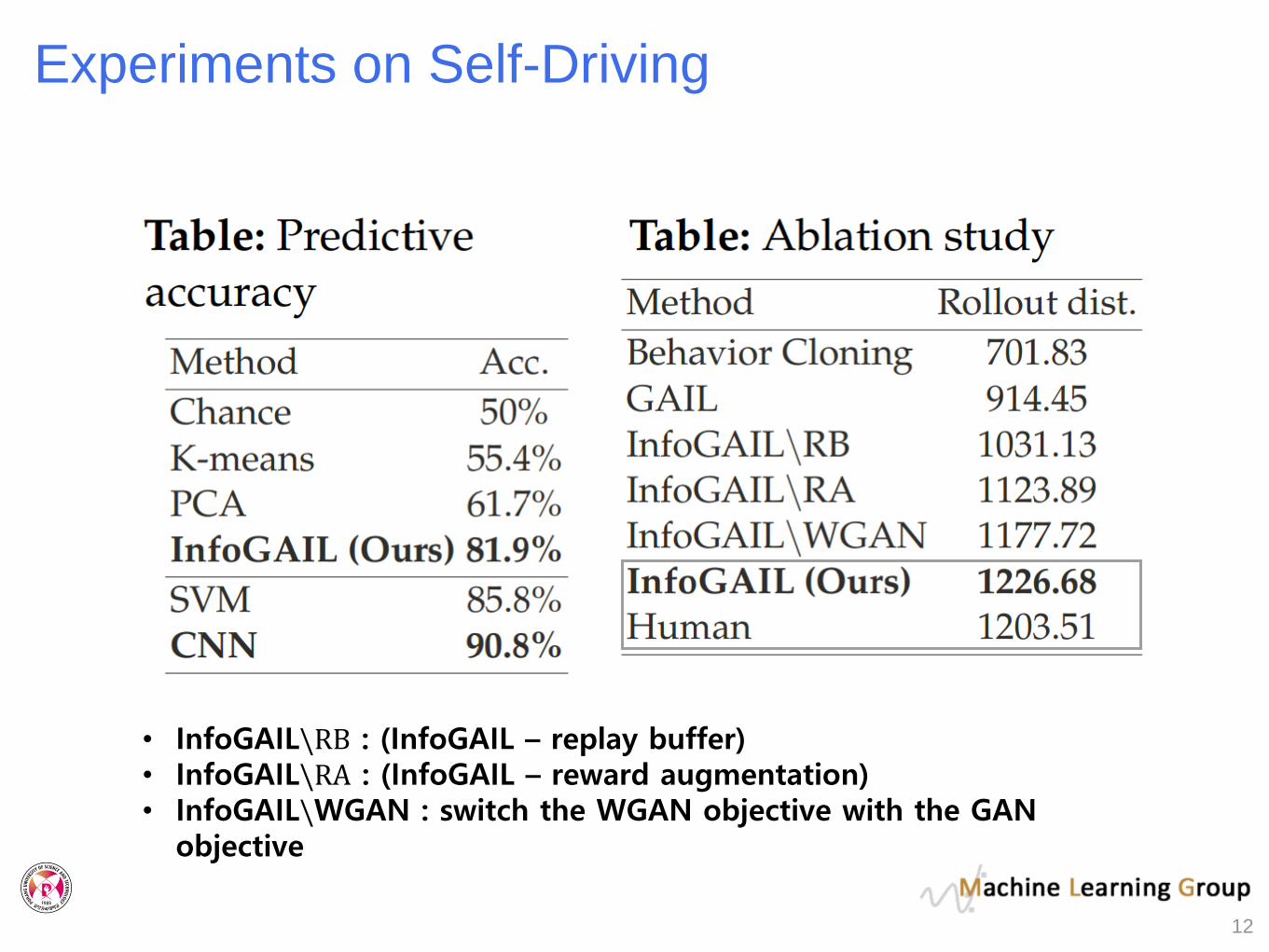
Experiments on Self-Driving
12
• InfoGAIL\RB : (InfoGAIL – replay buffer)• InfoGAIL\RA : (InfoGAIL – reward augmentation)• InfoGAIL\WGAN : switch the WGAN objective with the GAN
objective
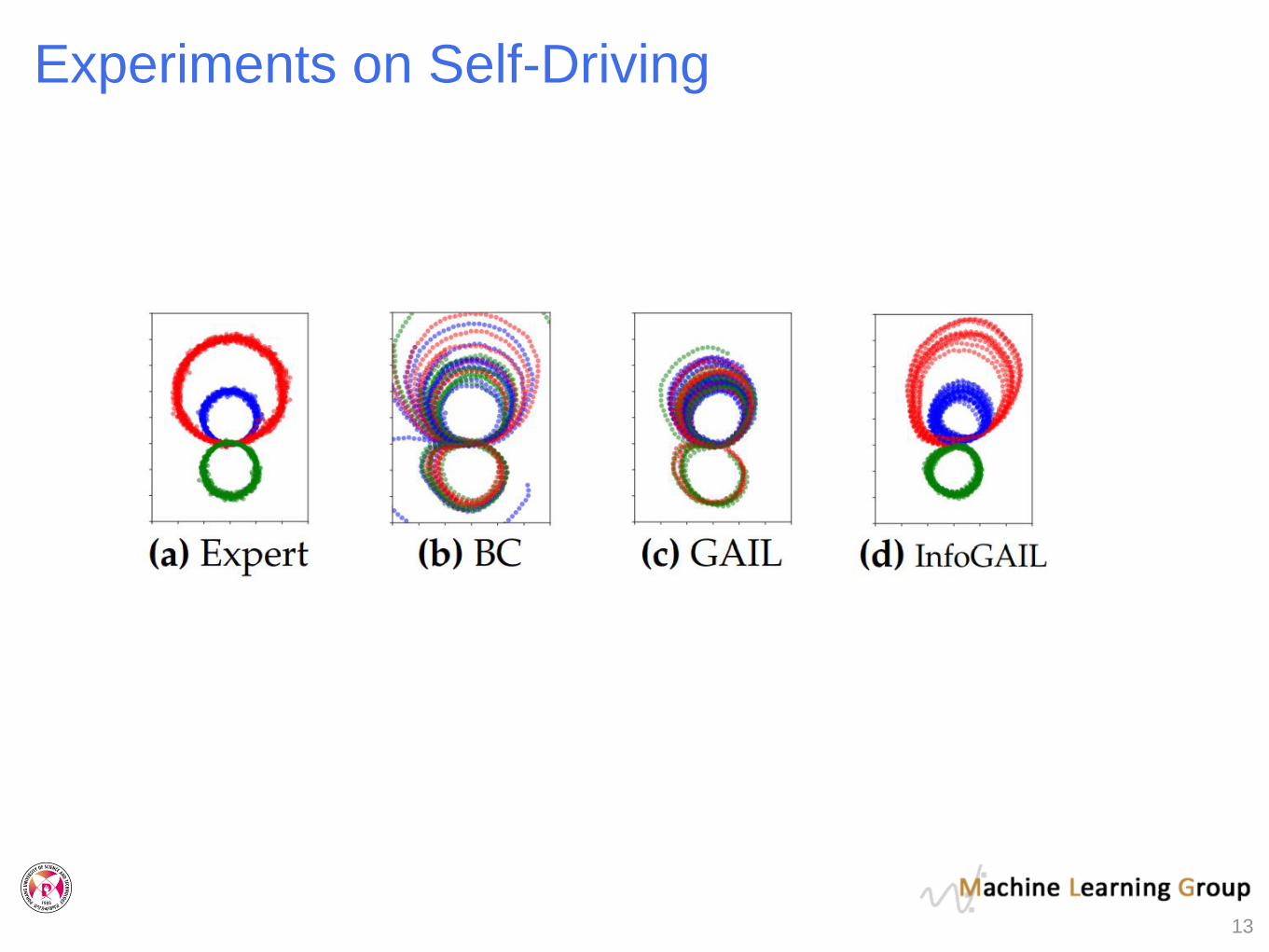
Experiments on Self-Driving
13
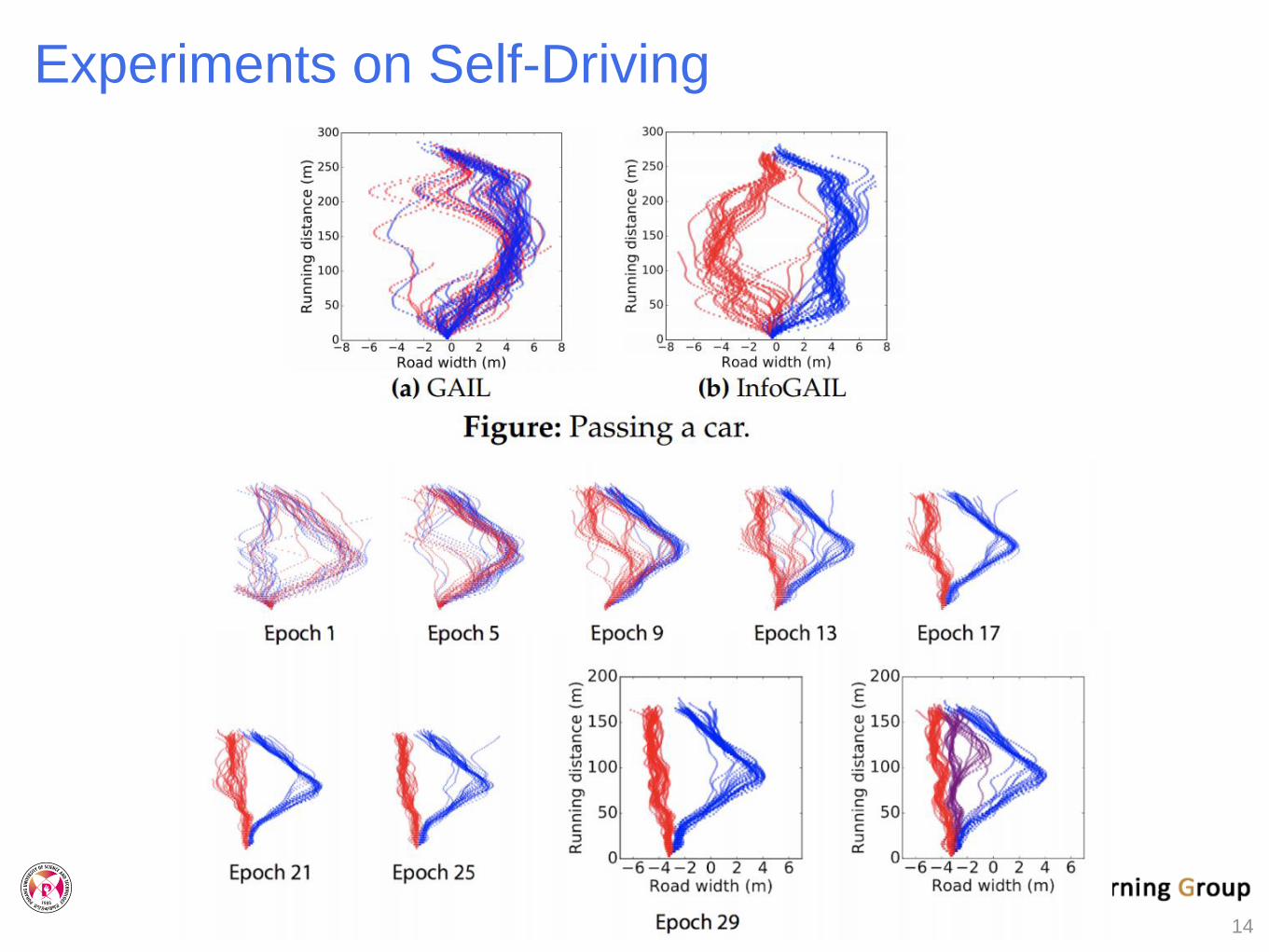
Experiments on Self-Driving
14

Experiments on Self-Driving
15
https://www.youtube.com/watch?v=YtNPBAW6h5k
Pass from left 𝒄 = 𝟏, 𝟎


![imitation trunk [イミテーショントランク] - JCD · 製品名称 imitation trunk エントリーNO. 1821 imitation trunk[イミテーショントランク] デザイン自在](https://static.fdocuments.net/doc/165x107/5f89cfa3f220b314941082d7/imitation-trunk-ffffffff-ec-imitation-trunk.jpg)

![InfoGAIL: Interpretable Imitation Learning from Visual ......of uncovering style, shape, and color in generative modeling of images [14], we aim to automatically learn similar interpretable](https://static.fdocuments.net/doc/165x107/60bbc3ac63efdd105c4fc48d/infogail-interpretable-imitation-learning-from-visual-of-uncovering-style.jpg)













