
Indexing Strategies for the Linguist’s Search Engine Aaron Elkiss and Philip Resnik UMIACS.
43
Indexing Strategies for the Linguist’s Search Engine Aaron Elkiss and Philip Resnik UMIACS
-
Upload
abram-bayse -
Category
Documents
-
view
219 -
download
0
Transcript of Indexing Strategies for the Linguist’s Search Engine Aaron Elkiss and Philip Resnik UMIACS.

Indexing Strategies for the Linguist’s Search Engine
Aaron Elkiss and Philip Resnik
UMIACS

Why a Linguist’s Search Engine?
• Goal for linguists: Use naturally occurring data to support theories
• “Bag of word” searches not sufficient• Structural searches of parse trees would be better

Constituency Parse

• Database
• Must permit real-time interaction
• Must permit large-scale searches
• Must allow search on linguistic criteria
• Interface
• Must have linguist-friendly “look and feel”
• Must minimize learning/ramp-up time
• Must be reliable
• Must evolve with real use
A Web Search Tool for the Ordinary Working Linguist

Querying Parse Trees• Find all trees containing a particular subtree
• We use Query by Example to edit an example sentence
• to the structure we’re interested in

Query Properties
• Typically concerned with structure near the leaves of the tree
• Relationship can be ancestorship rather than immediate dominance

LSE Design Criteria
• Must permit arbitrary structural searches– multiple branches with wildcards
• in realtime
• on a large collection of sentences– 1GB scaling up to 10GB or more

Existing Techniques
• Convert data to a relational model
• Streaming techniques (tgrep2 (Rohde), XSQ (Chawathe et al.))
• Index, but permit only simple searches (DataGuides – Widom et al.)
• Indexing techniques work best with a simple schema

Goals
• Must handle a dataset with a very large schema– 17 million paths from root to terminal
– Xmark 1GB has 2.4 million
– Path lengths also longer in LSE
– Set of paths from root to preterminal fixed in Xmark, grows without bound in LSE
• Must handle queries with wildcards well• Must retrieve all results (100% recall)

Assumptions
• Indexing can be slow (overnight)
• Doesn’t need to support online update
• Can overgenerate results– < 100% precision– Use tgrep2 as a filter

Baseline Solution
• VIST: A dynamic index method for querying XML data by tree structures (Wang et al (IBM Watson), SIGMOD 2003)
• Suffix-tree based approach
• Indexes structure and content together
• Supports branching queries well

Suffix Trees
• Index all suffixes of a given string

Structure Encoded Sequences• Represent each node in DFS order with the
complete path from the root to the node• One parse tree = one document = one structure
encoded sequence
S1 S_S1 NP_S_S1 NNP_S_S1 Jared_NNP_NP_S_S1 VP_S_S1 VBD_S_S1 laughed_VBD_VP_S_S1

VIST Trees• Insert structure encoded sequences instead
of suffixes of a string

Node Identification• (DFS order / node ID , number of descendants) = (n, d)
• DFS order uniquely identifies a node
• with number of descendants, identifies which nodes are descendants of a given node
• can produce without using a lot of memory using perl and UNIX sort utility
(0,12)
(1,11)
(2,10)
(3,4)
(4,3)
(5,2)
(6,1)
(7,0)
(8,4)
(10,2)
(11,1)
(12,0)
(9,3)

VIST Indexes
• Two Btree indexes using BerkeleyDB
• Structural Sequence Index
• Document Index

Structural Sequence Index
• Structural Sequence Element (n, d)
– S1 (0,12)
– VP_S_S1 (5,2), (10,2)(0,12)
(1,11)
(2,10)
(3,4)
(4,3)
(5,2)
(6,1)
(7,0)
(8,4)
(10,2)
(11,1)
(12,0)
(9,3)

Document Index
• documents inserted at node ID of last element
(0,12)
(1,11)
(2,10)
(3,4)
(4,3)
(5,2)
(6,1)
(7,0)
(8,4)
(10,2)
(11,1)
(12,0)
(9,3)
7 12

Search
(0,12)
(1,11)
(2,10)
(3,4)
(4,3)
(5,2)
(6,1)
(7,0)
(8,4)
(10,2)
(11,1)
(12,0)
(9,3)
Query:
• Select everything matching the first branch of the query
•Order of branches in query is important
•For each item, recurse on items that match the next branch and are descendants in the tree - those with [n2, n2 + d2] contained in [n1, n1 + d1]
[3,7] contains [5,7]

Recursion Base Case
• After the last branch of the query
• Retrieve documents with descendant node IDs
(0,12)
(1,11)
(2,10)
(3,4)
(4,3)
(5,2)
(6,1)
(7,0)
(8,4)
(10,2)
(11,1)
(12,0)
(9,3)
7

Peculiarities of VIST
• Precision is not 100%!
• Query
• matches both these documents

Problematic Query - Wildcards
• Wildcards can still be a problem– Recursion isn’t deep but can be very wide– End up looking at same nodes over and over
again with different wildcard instantiations from previous branches

Problematic Query - Wildcards
For every way we instantiate the first branchrobot_nn_np_vp_vp_s_vp_s_sbar_vp_s_vp_s_sbar_vp_s_vp_s_s1robot_nn_np_vp_vp_s_vp_vp_s_s1robot_nn_np_vp_vp_s_vp_vp_s_sbar_np_pp_adjp_vp_s_sbar_vp_vp_s_sbar_np_s1… 254 more
we have to look at every way to instantiate the second branchlaughs_vbz_vp_vp_s_sbar_np_pp_np_pp_vp_s_s1laughs_vbz_vp_vp_s_sbar_vp_s_s_s1laughs_vbz_vp_vp_s_sbar_vp_s_s1… 98 more

Problematic Query – Common Terminal
•VIST’s structural index actually stores
terminal length root … preterminal
the 6 S1 S VP FRAG X DT
to find instantiated prefixes of structural sequence elements
•We’d look for
JJR 5 S1 S VP FRAG X

Problematic Query – Common Terminal
•To find structural sequence elements like the_DT_X_FRAG_… we have to look at every element with the terminal ‘the’
• 220284 for the_… vs. 121 for the_DT_X_frag_…

Solution Overview
• Ignore insufficiently selective query branches• Reorder processing of query branches• Different ordering for structural index• Create in-memory tree for the query• Memoization of nodes matching subtree of query

Ignore query branches
• Generate statistics for each pair of tokens
• Calculate estimated selectivity of each branch
• Discard insufficiently selective branches
• Use tgrep2 as filter
Still problematic:

Reorder query branches
• Start processing with most selective branch
• Join to proceeding branches, then following branches

Reorder structural index
• Store as
terminal preterminal … root
the DT X FRAG VP S S1
• Immediately find paths with particular suffix
• Terminals occurring in similar contexts are clustered together

Reorder structural index
• Now we have to look at every JJR_X_FRAG_… instead of just those with the same prefix as the_DT_X_FRAG_…
• But we’ll only do so once, and only keep those the_DT_X_FRAG_… and JJR_X_FRAG_… who have matching prefixes

Create Query Tree
• Keep relevant instantiations of each branch in memory
S1_*_NP_*_robot robot_NN_NP_NP_S_SBAR_S_X_X_S1 robot_NN_NP_NP_S_SBAR_VP_FRAG_S1 robot_NN_NP_NP_S_SBAR_VP_S_S_S1S1_*_VP
VP_S_S1 *_laughs laughs_VBZ_VP_VP_S_SBAR_NP_PP_NP_PP *_us us_PRP_NP
VP_VP_S_SBAR_NP_PP_NP_PP_VP_S_S1 *_laughs laughs_VBZ
*_us us_PRP_NP

Subtree Memoization
S1_*_NP_*_robotrobot_NN_NP_NP_S_SBAR_S_X_X_S1
(1,15) (30,10)S1_*_VP
VP_S_S1 *_laughs laughs_VBZ_VP_VP_S_SBAR_NP_PP_NP_PP (5,5)
VP_VP_S_SBAR_NP_PP_NP_PP_VP_S_S1 *_laughs laughs_VBZ
(20,0)
S1_*_VP_*_laughs (5,5) (20,0)
•Create sorted list of all nodes for a particular branch of the query

Subtree Memoization
S1_*_VPVP_S_S1
*_laughs laughs_VBZ_VP_VP_S_SBAR_NP_PP_NP_PP
(5,5) (10,0) *_us us_PRP_NP (6,0) us_PRP_NP_NP (50,0)
VP_VP_S_SBAR_NP_PP_NP_PP_VP_S_S1 *_laughs laughs_VBZ
(20,20) *_us us_PRP_NP (60,0)
S1_*_VP_*_us / VP_S_S1 (6,0) (50,0)
•Specifier for memoized list includes wildcard instantiations
S1_*_VP_*_us / VP_VP_S_SBAR_NP_PP_NP_PP_VP_S_S1 (60,0)

Evaluation
• Original VIST scalability
• XMark
• LSE data

Original VIST scalability
Random queries over a synthetic data setFrom Haixun Wang, Sanghyun Park, Wei Fan, and Philip S Yu. VIST: A dynamic index method for querying XML data by tree structures. In SIGMOD, 2003. http://citeseer.nj.nec.com/wang03vist.html
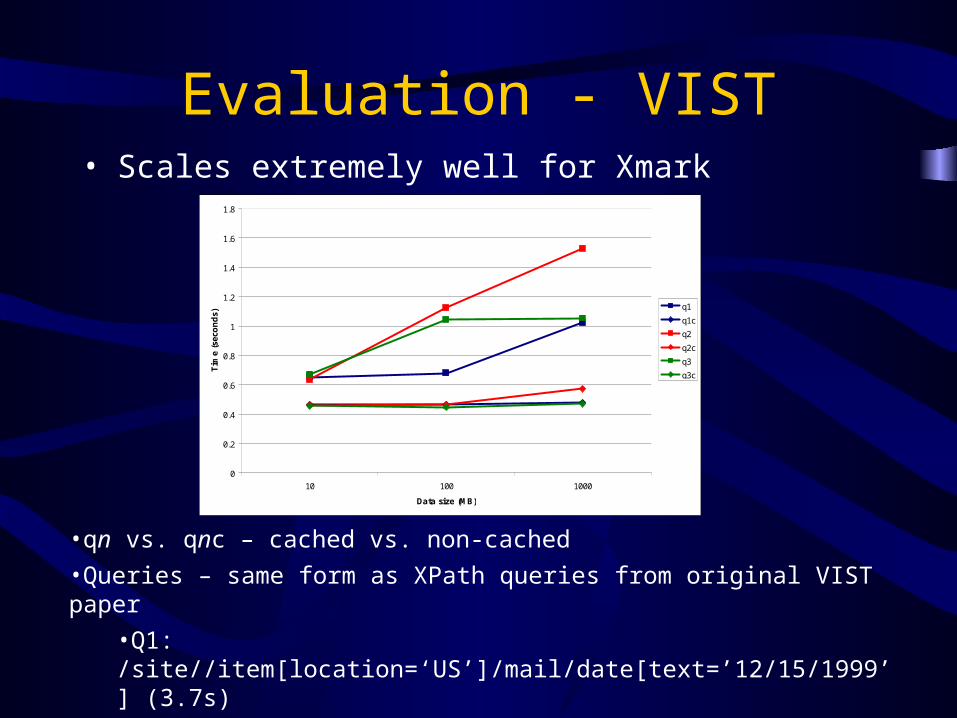
Evaluation - VIST• Scales extremely well for Xmark
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
10 100 1000
Data size (MB)
Tim
e (s
eco
nd
s)
q1
q1c
q2
q2c
q3
q3c
•qn vs. qnc – cached vs. non-cached
•Queries – same form as XPath queries from original VIST paper
•Q1: /site//item[location=‘US’]/mail/date[text=’12/15/1999’] (3.7s)
•Q2: /site//person/*/city[text=‘Pocatello’] (2.5s)
•Q3: //closed_auction[*[person=‘person1’]]/date[text=’12/15/1999’] (4.1s)

Evaluation - LSE• Need more data
0
0.5
1
1.5
2
2.5
3
3.5
10 100 1000
Data size (MB)
Tim
e (
se
co
nd
s)
q1
q1c
q2
q2c
•Queries – two forms of a real LSE query
Q1: Q2:

Evaluation – Index Size
0.1
1
10
100
1000
10000
10 100 1000
Data size (MB)
Tim
e (
se
co
nd
s)
Xmark Schema
Xmark Structural
Xmark Document
LSE Schema
LSE Structural
LSE Document

Future Directions
• Reimplement this + original VIST in C
• Scale up to 10gb
• Improved query planning
• Ranking & efficient top-k results
• Investigate usefulness for structural search of HTML documents

HTML Structural Search
• Similar properties to LSE data– no fixed schema– no maximum path depth
• “Whole Web” search probably not yet feasible

Ranking & efficient top-k results
• Assign score to possible result– Closer to matrix level = higher score?
• Look for results with highest score first

Improved Query Planning
• “Dynamic Ignorance”– choose whether to use a query branch based on
wildcard instantiations
• Full reordering of query branches

Acknowledgments
• Philip Resnik, of course!
• Saurabh Khandelwal – tree editor
• Doug Rohde – tgrep2• This work is supported by NSF ITR grant
IIS0113641 .


















