
Indexing 3-dimensional trajectories: Apache Spark and Cassandra integration
27
Indexing 3-dimensional trajectories: Apache Spark and Cassandra integration Cesare Cugnasco: 8 th of April 2015
-
Upload
cesare-cugnasco -
Category
Data & Analytics
-
view
437 -
download
4
Transcript of Indexing 3-dimensional trajectories: Apache Spark and Cassandra integration

Indexing 3-dimensional trajectories:Apache Spark and Cassandra integration
Cesare Cugnasco: 8th of April 2015

Who am I ?
• Research Support Engineer @
in the Autonomic Systems and e-Business Platforms group since 2012
– Bachelor thesis on social network databases in 2011
– Master thesis: “Design and implementation of a Benchmarking Platform for Cassandra Data Base” in 2013
– Conference paper : “Aeneas: A tool to enable applications to
effectively use non-relational databases”, C. Cugnasco, R. Hernandez, Y. Becerra, J. Torres, E. Ayguadé - ICCS 2013
– Aeneas: https://github.com/cugni/aeneas
2

Use case: Nose simulation

Nice render, but how to work with it?
Simulation needs to be visualized, explored, queried with a human bearable response time.
One can’t wait 1 hour to see how a trajectory looks like!

First approaches
• Trajectory size ~ 60GB:
– MySQL:
• Days to load the data
• Queries are very slow – cat tryectory|awk ‘{ if ($12> -0.2…. was faster
– Impala on HDFS:scales extremely, run at top CPU: still, reads all data in memory for each query
– Cassandra+SOLR:some trick for 2D, no true support for 3D

We have to find our own solution!

NoSQL databases
• Built from scratch to cope with Big-Data by scaling linearly and always being available.
• How big Big-Data?
– Apple: over 75,000 nodes storing over 10 PetaBytes
– Netflix: 2,500 nodes, 420 TB, over 1 trillion requests per day
– eBay: over 100 nodes, 250 TB.
7

How did they scale up
• Compared to Relational databases, they have a reduced set of functionalities:
– No distributed locks
• No isolation
• Limited atomicity
– Eventual consistency
– No memory intensive operations:• JOINs
• GROUP BYs
• ARBITRARY FILTERING
8
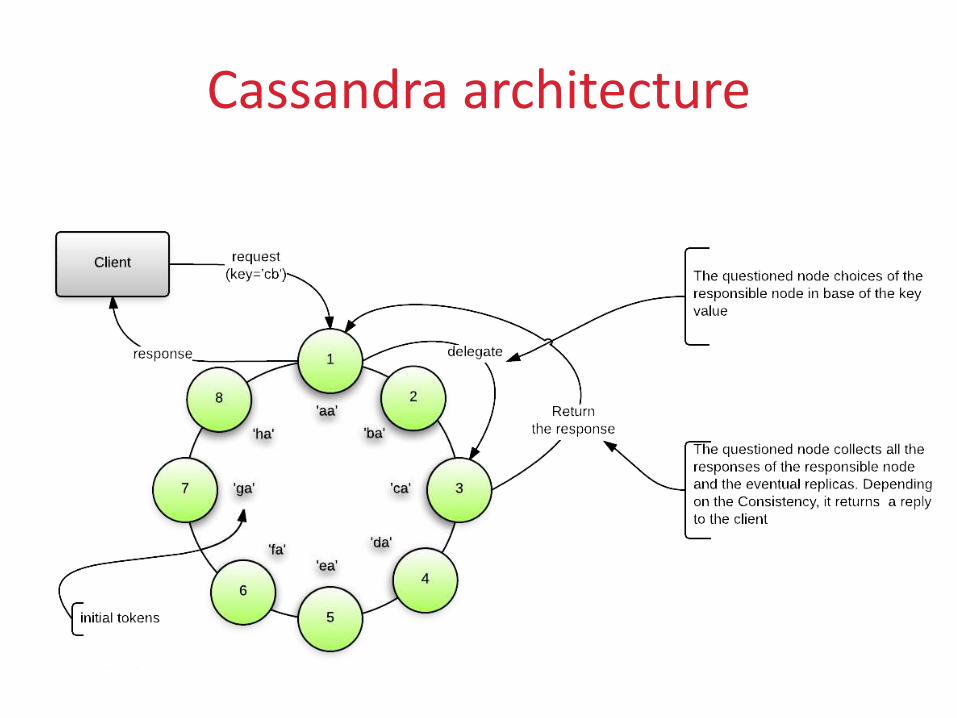
Cassandra architecture

Cassandra datamodel
• Essentially a HashMap where each entry contains a SortedMap.
CREATE SCHEMA particles(part_id Int,time Float,x Float,y Float,z Float,PRIMARY KEY(part_id, time)
);
HashMap<Int,SortedMap<Float,Point>> particles = new ..
Partition Key Clustering Key
An example of how to store the position of particles in time.
10

queries
SELECT * FROM particlesWHERE part_id=10
particles.get(10)
SELECT * FROM particlesWHERE part_id=10 AND time>=1.234AND time<2.345
particles.get(10).subMap(1.234,2.345)
POSSIBLE
IMPOSSIBLE
SELECT * FROM particlesWHERE time=1.234
SELECT * FROM particlesWHERE x>=1.0 AND x<2.0 AND y>=1.0 AND y<2.0 AND z>=1.0 AND z<2.0
Needs a different model
Needs a multidimensional index 11

Wait! We have secondary indexes!
Cassandra allows to have multiple secondary indexes on attributes of a column, but
1. they work correctly only when indexing few discrete values.
SELECT * FROM userWHERE mail=‘[email protected]’ NO!
SELECT * FROM userWHERE country=‘ES’ Better

Wait! We have secondary indexes!
2. You can create multiple secondary indexes and use filtering conditions on them, but only the most selective index will be used, the other will be filtered in memory=>BAD!
SELECT * FROM userWHERE state=‘UK’AND sex=‘M’AND month=‘April’
The query will read from disk all the UKusers, and then it will filter them in memory by sex and month
It will crash!
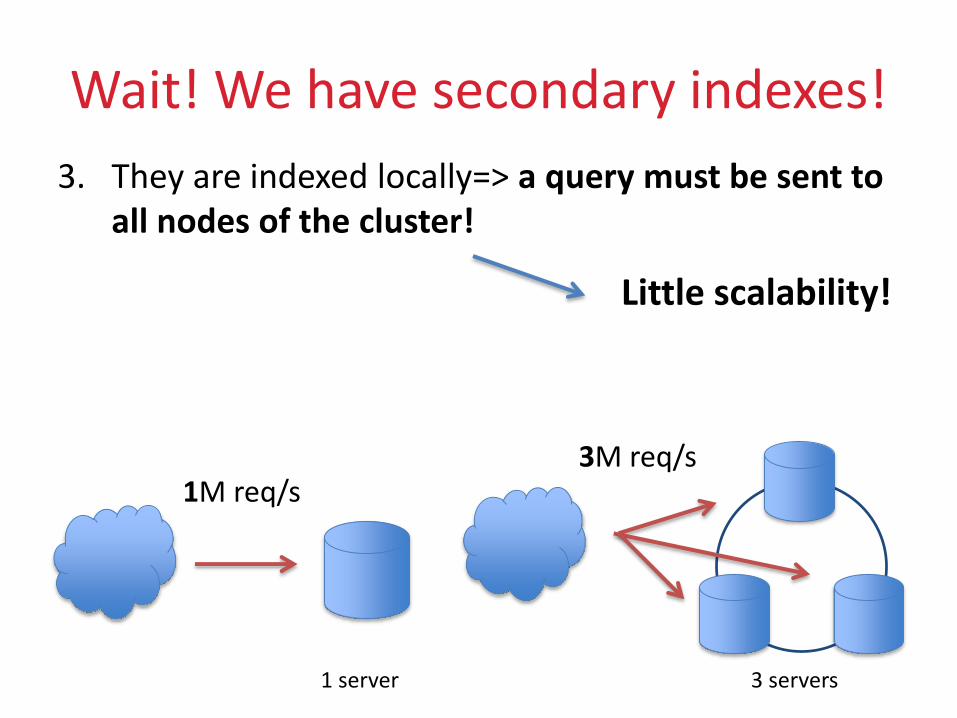
Wait! We have secondary indexes!
3. They are indexed locally=> a query must be sent to all nodes of the cluster!
Little scalability!
1M req/s3M req/s
1 server 3 servers
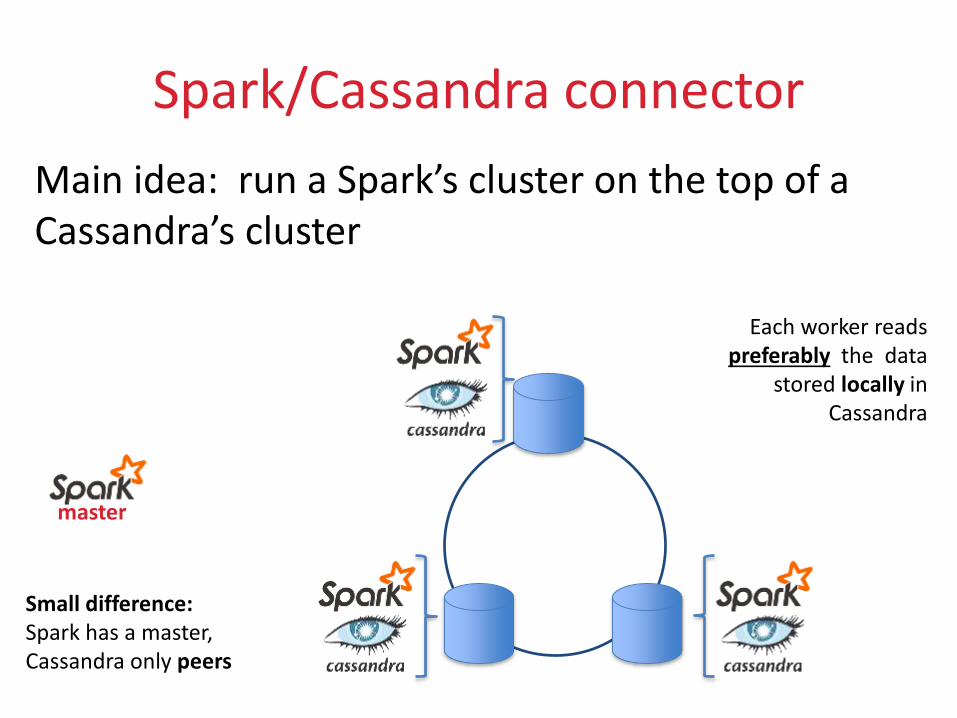
Spark/Cassandra connector
Main idea: run a Spark’s cluster on the top of a Cassandra’s cluster
Small difference:Spark has a master, Cassandra only peers
master
Each worker reads preferably the data
stored locally in Cassandra

Spark/Cassandra connector
The queries are partitioned using the Cassandra node token
SELECT * FROM particles
client
SELECT * FROM particlesWHERE TOKEN(id)>= 1AND TOKEN(id)< 2
SELECT * FROM particlesWHERE TOKEN(id)>= 3AND TOKEN(id)< 1
SELECT * FROM particlesWHERE TOKEN(id)>= 2AND TOKEN(id)< 3
Actual tokens are spread between 0 and 264
1
23

Spark/Cassandra connector: benefits
• Push down filtering – Currently stable
• Select : vertical filtering• where (“country = ‘es’”)
=> it uses C* secondary indexes, the predicate is appended to the token filtering predicate
– Since 1.2, still in RC – not stable
• joinWithCassandraTable && repartitionByCassandraReplica
You can use an RDD to access all the matching rows in Cassandra.You don’t need a full table scan for doing the join BUT you perform a request for each line!

Spark/Cassandra connector: benefits
• Spark SQL integration!Yes, you read right, SQL on NoSQL!
• Spark Streaming integration
• Mapping between Cassandra’s rows and Object
• Implicitly save to Cassandra –saveToCassandra

Multidimensional indexes
• Hierarchical structures that allow an efficient lookup of information when we set constraints based on two or more attributes.
• Most famous algorithms are: • Quad-trees• KD-trees• R-trees
• What is important to take into consideration is that:
1. Each algorithm fits better for some use cases.2. They all organize data hierarchically in trees.
19

Quad-tree


Time for code
• Find some examples at
– https://github.com/cugni/meetupExamples

No shortcut: make our own index
We finally decided to create our own index on the top of key-value data store.
• We create indexes with Spark
• We store indexed data on Cassandra
• Queries:
– Low latency ones: done by simply reading from Cassandra
– Aggregation, complex ones: executed with Spark

Application architecture
Entry point
Simple query direct to Cassandra
Aggregation sent to Spark
Thrift RPC connection

Lesson learnt
• Heap can be a problem, with Cassandra and Spark on the same node
• Compaction can be a problem
• if your data is not uniformly distributed, neither will spark's work load
• The fact that API allows you, doesn’t mean you have to!

Future works
• Spark SQL integration
– we can instruct Spark to create a query plan using our indexes. It must understand when it’s useful to use the index and when it is not
• Streaming indexing
– indexing and visualizing data while the simulations are being created

Special thanks
• A special thanks to the people of CASE, especially Antoni Artigues who is working with me on this project on the C/C++ Paraviewside and on the simulations generated with Alya (http://www.bsc.es/alya)


















